基于增量式发育深度强化学习的无人机路径规划方法
文献发布时间:2023-06-19 18:30:43
技术领域
本发明属于无人机路径规划技术领域,具体涉及一种基于增量式发育深度强化学习的无人机路径规划方法。
背景技术
随着UAV(Unmanned Aerial Vehicle,简称:UAV)领域的进一步开放,城市、山地等复杂环境中的密集动态障碍使UAV的飞行安全受到了极大威胁。传统的路径规划算法,如A
不同于上述传统路径规划方法,基于强化学习的导航方法借鉴生物后天感知发育的学习方式,通过与环境的不断交互持续优化避障策略,不仅避免了对障碍建模和专家监督的依赖,而且具备较强的泛化能力和鲁棒性。特别是近年来深度强化学习(deepreinforcement learning,简称:DRL)取得了快速发展,DRL利用深度学习强大的感知与拟合能力,有效解决了高维环境“指数爆炸”的问题,从而获得更优的避障策略,这为UAV在密集动态障碍环境下的路径规划问题提供了新思路。Sliver、Google DeepMind团队、伯克利大学的John Schulman博士以及OpenAI相继提出了DDPG(Deep deterministic policygradient,深度确定性策略梯度)算法、异步优势AC(Asynchronous Advantage ActorCritic,简称:A3C)算法、置信域策略优化(Trust Region Policy Optimization,简称:TRPO)算法和近端策略优化(proximal policy optimization,简称:PPO)等深度强化学习算法。
尽管这些方法在UAV路径规划方面有明显优势,但在训练阶段往往需要探索大量随机障碍环境样本,导致离线训练时间过长,收敛速度慢。因此,有必要引入新的学习机制。
发明内容
为了克服现有技术中的问题,本发明提出基于增量式发育深度强化学习的无人机路径规划方法。
本发明解决上述技术问题的技术方案如下:
一种基于增量式发育深度强化学习的无人机路径规划方法,包括以下步骤:
步骤1.构建UAV运动模型;
步骤2.以DDPG网络模型为基础,采用Actor-Critic架构,利用DDPG神经网络架构连续输出决策动作;
步骤3.引入了增量式发育知识库,训练改进DDPG网络模型,更新DDPG网络模型网络参数,规划出无碰撞飞行路径。
进一步地,所述步骤1中构建UAV运动模型包括以下步骤:
在执行任务过程中,UAV飞行轨迹通过航向角、爬升角和飞行速度调整,运动学方程为:
式中,
UAV的飞行速度、航向角、航向角速度和爬升角、爬升角速度变化范围为:
式中,
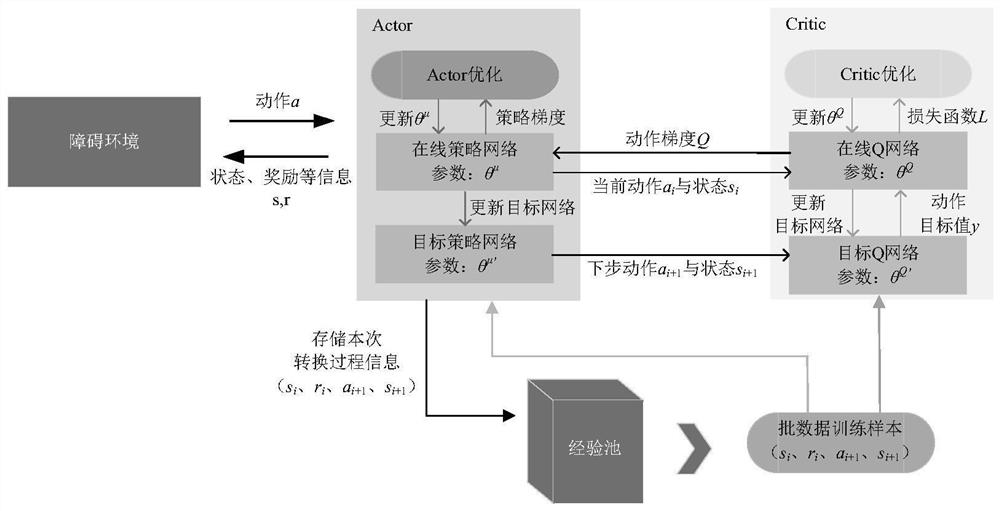
进一步地,所述步骤2中DDPG神经网络架构包含在线Actor网络、目标Actor网络、在线Critic网络和目标Critic网络四个网络。
进一步地,在Actor网络中,在线Actor网络基于从环境中获取的状态信息s
在Critic网络中,在线Critic网络根据状态s
进一步地,所述步骤3中增量式发育知识库包括威胁模式知识库B
进一步地,三个知识库构成以下映射关系:
当UAV探测到威胁模式后,如果在威胁模式知识库中存在与探测到的障碍环境B
对于威胁模式知识库中不存在的威胁模式,即首次进行训练的威胁模式,则需要根据DDPG算法进行网络参数的训练,并将学习到的威胁模式、避障策略、映射关系作为新知识加入到知识库中。
进一步地,威胁模式知识库B
进一步地,所述根据增量判断函数判断知识库中是否存在相似威胁模式,具体步骤如下:
假设UAV遇到突发威胁环境B,该环境内存在多个动静态障碍物,其中任一单个障碍物可由式(4)表示:
b=[d,ψ
式中:d为障碍物相对UAV的欧式距离;ψ
将上述参数用A
b=[A
式中,A
引入模糊控制算法计算两个障碍间的相似度;分别将障碍物k与障碍物j的6个属性A
将上述两个障碍的障碍模式间的比较转换为模糊集之间的比较:如果障碍物k与障碍物j的所有属性均在同一模糊集内,则认为这两个障碍是相似的,可对照贴近度函数定量评估相似度数值;根据格贴近度算法构建贴近度函数如下:
式中:A
进一步地,对于知识库中未存储的威胁模式B
定义威胁模式为当前障碍环境中,UAV感知范围内所有障碍物障碍模式的集合,即
B=[b
假设有障碍环境B
得到威胁模式知识库存储的知识为DDPG算法训练过程中遇到的所有威胁模式的集合:
B
进一步地,在DDPG神经网络训练威胁模式B
A
其中,θ
与现有技术相比,本发明具有如下技术效果:
为了克服深度强化学习训练时间长、收敛速度慢的问题,本发明针对密集动态障碍环境下的无人机路径规划,引入了增量式发育知识库,对深度确定性策略梯度算法进行改进。首先,根据模糊匹配的思想建立威胁模式知识库,将飞行过程中遇到的密集动态障碍作为知识进行增量式存储,避免对相似障碍环境的重复训练。其次,在底层DDPG算法规划安全航路的基础上构建避障策略知识库,根据威胁模式直接输出避障策略,缩短训练时间。最后,搭建发育式的威胁–避障映射关系,实现“线上实时避障,线下自主寻优”,不断提升UAV避障性能。
附图说明
图1为本发明的任务环境示意图;
图2为本发明的DDPG算法训练框架示意图;
图3为本发明的输入量d
图4为本发明的输出量r
图5为本发明的改进后的威胁-避障映射关系知识库结构图;
图6为本发明的障碍环境样本图;
图7为本发明的知识数与障碍环境样本数关系图;
图8为本发明在仿真场景中测试UAV避障效果图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
为了克服深度强化学习训练时间长、收敛速度慢的问题,本发明提出了一种新的基于增量式发育深度强化学习的UAV路径规划算法,在底层DDPG算法规划安全航路的基础上,搭建威胁模式知识库、避障策略知识库以及威胁–避障映射关系知识库,减少对相似障碍环境的重复计算,从而缩短离线训练时间。首先,在DDPG离线训练阶段,引入模糊匹配的思想,通过增量判断函数判断威胁模式知识库中是否存在相似障碍环境,对于已经存在的障碍场景,则直接跳过,无需再次训练;其次,UAV根据在威胁模式知识库中匹配到的相似威胁模式,直接输出对应的避障策略,而无需经过底层避障算法,实现UAV实时避障;最后,UAV每进行完一次避障行为,在线下继续搜索更优避障策略,建立发育式的威胁–避障映射关系,实现“线上实时避障,线下自主寻优”。通过密集动态障碍环境下的大量仿真避障训练,知识库不断发育,最终使得UAV不通过底层耗时较长的DDPG算法就规划出无碰撞飞行路径,从而缩短训练时间,极大提升UAV应对密集动态障碍环境的避障能力。
本发明建立的密集动态障碍环境如图1所示。设飞行任务环境
UAV在密集动态障碍环境中的路径规划任务可以分为两个子任务:
第一个是UAV在飞行过程中突然探测到未知障碍时如何机动使其在飞行约束条件内完成避障;
第二个任务是利用既往避障经验建立并不断扩充知识库,再次遇见相似障碍场景时,UAV直接调取避障策略而无需经过底层耗时过长的避障算法,避免对相似障碍场景的重复计算。
步骤1.构建UAV运动模型。
在执行任务过程中,UAV飞行轨迹可通过航向角、爬升角和飞行速度调整,运动学方程为:
式中,
考虑到飞行性能限制,UAV的飞行速度、航向角、航向角速度和爬升角、爬升角速度都必须在一定范围内变化:
式中,
步骤2.以DDPG网络模型为基础,采用Actor-Critic架构,利用深度神经网络连续输出决策动作。
DDPG网络以确定性策略梯度(DPG)算法为基础,采用Actor-Critic架构,利用深度神经网络连续输出决策动作,算法训练框架如图2所示。
DDPG神经网络架构包含在线Actor网络、目标Actor网络、在线Critic网络和目标Critic网络四个网络。
在Actor网络中,在线Actor网络基于从环境中获取的状态信息s
在Critic网络中,在线Critic网络根据状态s
步骤3.引入了增量式发育知识库,训练改进DDPG网络模型,更新DDPG网络模型网络参数。
DDPG算法从障碍环境中获取状态信息s后选取避障动作a,进而更新网络参数。也就是说,经过DDPG网络训练后,一个障碍环境对应一组最优网络参数。为了训练出适用于绝大部分障碍环境的网络,UAV需要在上万个随机障碍环境中进行训练,而随机障碍环境存在一定的重复概率,容易造成对相似障碍环境的重复训练,因此,引入了增量式发育知识库,对DDPG算法进行改进,缩短离线训练时间。
将UAV避障飞行中学习到的知识分别存储在威胁模式知识库B
其中,威胁模式知识库存储此次飞行任务的障碍环境,包括障碍物的相对距离、运动速度等,避障策略知识库存储该障碍环境经过训练得到的DDPG网络参数,威胁–避障映射关系知识库用来管理两者之间的映射关系,为后续基于增量式发育知识库的避碰提供决策策略,确保UAV及时有效且安全地规避潜在威胁。
步骤3-1.构建威胁模式知识库B
假设UAV遇到突发威胁环境B,该环境内存在多个动静态障碍物,其中任一单个障碍物可由式(4)表示:
b=[d,ψ
式中:d为障碍物相对UAV的欧式距离;ψ
b=[A
式中,A
知识库的核心是设计知识库增量判断函数。为比较单个障碍物k与单个障碍物j是否属于同一障碍模式,引入模糊控制算法计算两个障碍间的相似度。分别将障碍物k与障碍物j的6个属性A
以属性A
Rule_o1:IF D is NS THEN R
Rule_o2:IF D is PS THEN R
Rule_o3:IF D is PM THEN R
Rule_o4:IF D is PB THEN R
模糊系统的输入、输出隶属度函数如图3、图4所给出。
如果障碍物k与障碍物j的输出量r
根据上述原理,可以将上述两个障碍的障碍模式间的比较转换为模糊集之间的比较:如果障碍物k与障碍物j的所有属性均在同一模糊集内,则认为这两个障碍是相似的,可对照贴近度函数定量评估相似度数值。根据格贴近度算法构建贴近度函数如下:
式中:A
由于障碍环境中往往有不止一个障碍物,因此引入威胁模式的概念。定义威胁模式为当前障碍环境中,UAV感知范围内所有障碍物障碍模式的集合,即
B=[b
假设有障碍环境B
易得威胁模式知识库存储的知识为DDPG算法训练过程中遇到的所有威胁模式的集合:
B
步骤3-2.构建避障策略知识库A
在通过底层DDPG算法训练障碍环境的基础上,构建UAV的避障策略知识库。在DDPG神经网络训练威胁模式B
A
其中,θ
本发明所构建的避障策略知识库并不是所规划最优路线中基础飞行动作的简单组合,这是因为威胁模式有相似性,却并不是一成不变,针对当前威胁模式规划的安全飞行动作选择序列集并不完全适用于相似障碍环境。将网络参数进行存储可移植性适用性更强,占用的内存空间少,当UAV遇到与B
在UAV避障飞行过程中,网络参数不断调整,并将最终确定的网络参数作为避障策略加入到避障策略知识库中,从而实现对避障策略知识库的增量式发育。易得避障策略知识库存储的知识为DDPG网络训练过程中生成的所有最优避障策略的集合:
A
步骤3-3.构建威胁–避障映射关系知识库BA
DDPG算法离线训练过程如图5所示,在数据规模较少的初始阶段,UAV实时感知障碍环境,根据底层DDPG算法迭代训练,规划避障路径。此时,威胁模式与避障策略为一一对应的映射关系,即对于新增加的威胁模式B
增量式发育是指在DDPG算法离线避障训练的过程中,UAV不断规避障碍学习新的威胁模式和避障策略,并且将学习到的威胁模式加入到威胁模式知识库,将训练得到的网络参数作为避障策略加入到避障策略知识库,将两者之间的映射关系加入到威胁–避障映射关系知识库,持续扩充知识库规模。
具体来说,威胁模式知识库引入了模糊匹配的思想,根据增量判断函数判断知识库中是否存在相似威胁模式。对于知识库中未存储的威胁模式Bi,则将其作为新知识加入到知识库中,在不断积累知识的过程中实现威胁模式知识库的增量式发育。
UAV在规避障碍的过程中,根据DDPG算法不断迭代训练更新网络参数,将在线actor网络参数θ
威胁—避障映射关系知识库主要用于管理威胁模式和避障策略之间的映射关系,采用发育式增长的学习机制,不仅能够根据威胁模式直接输出对应的避障策略,还能够通过在线下搜寻最优避障策略,动态改善威胁–避障映射匹配结构。
在后续的避障过程中,当UAV探测到威胁模式后,如果在威胁模式知识库中存在与探测到的障碍环境B
为测试本发明改进的增量式发育深度强化学习算法的性能,在密集动态障碍环境中对改进前后的DDPG算法做对比实验,量化避障性能。
仿真实验环境为:Pyhton 3.7,2.42GHz主频的Inter Core i5处理器,以及Win10操作系统。首先需要在仿真环境中随机生成多个密集动态障碍环境并进行DDPG算法的离线训练,用于知识库初始避障经验的积累。假设障碍物属性A
表1贴近度阈值
部分障碍环境样本如图6所示,选取了9个不同的密集动态障碍环境进行训练,扩充威胁模式知识库。
训练完成后,三个知识库中的知识数量与障碍环境样本数的关系如图7所示。由于模糊匹配概念的引入,知识库根据威胁模式的相似程度,对3种知识进行了归纳整合,在持续扩充知识库的同时对重复数据进行降维,从而有效避免了对相似障碍环境的重复训练。训练完成后,知识库中的知识数量少于障碍环境样本数。如图6(a)和图6(b)的威胁模式相似度为0.85,图6(d)和图6(e)的相似度为0.92,高于相似度阈值,因此可以把以上两组威胁模式分别进行合并,共用避障策略,减少运算量。但图6(a)和图6(h)的威胁模式相似度仅为0.13,低于相似度阈值,此时则需要在威胁模式知识库中分别构建两组威胁模式信息。
发育完成后,在仿真环境下测试UAV避障性能。设仿真环境为500m×500m×500m的三维立体区域,区域内存在10个以不同运动速度沿不同航向角和爬升角方向运动的动态障碍。UAV从起点(0,0,0)起飞,最终到达目标点(500,500,500)。
本发明在设置相同障碍的仿真场景中,选取无碰撞飞行距离、无碰撞飞行时间、离线训练时长等指标,量化改进前后DDPG算法的避障性能。UAV避障结果如图8所示,量化的测试结果如表2所示。虽然改进前后的DDPG均能指导UAV有效避障,但是在密集动态障碍环境下,由于知识库提供了快速准确的避障策略参考,使用改进后的DDPG算法控制的UAV平均飞行速度提高了20.7%,网络训练时间缩短了62倍,极大提升了网络训练效率。
表2量化的避障性能对比
为了解决DDPG算法训练时间长、收敛速度慢的问题,本发明提出了一种基于增量式发育深度强化学习的UAV路径规划算法,通过在密集动态障碍环境下的仿真训练持续丰富知识库,将相似威胁模式进行合并归纳,避免了DDPG对相似障碍环境的重复训练。仿真对比实验表明,本发明改进的DDPG算法可以有效缩短训练时间,提升算法收敛效率。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于深度强化学习的无人机伪路径规划的方法
- 一种基于深度强化学习的两阶段无人机物流路径规划方法