一种服务设备及人机交互方法
文献发布时间:2023-06-19 10:32:14
技术领域
本申请涉及计算机视觉技术领域,特别涉及一种服务设备及人机交互方法。
背景技术
目前智能交互设备被看作万物联网的交互入口,因此语音交互获得了迅速发展,诸多语音交互系统出现在大众生活中。然而,单模态的语音交互系统抗干扰能力不强,在有背景噪音的场景下性能会明显下降,在距离较大的远场场景中会遇到唤醒困难的问题。此外,声音监听通道被占用时,单模态语音交互系统会彻底失效。
为了解决以上系统缺陷,相关技术中一方面可以依靠语音降噪和麦克风阵列等技术,来最大程度上消除背景噪音和远场环境对交互过程的影响,另一方面则可以借助多模态交互技术,赋予交互设备多模态的信号来扩充处理通路,借此解决单一模态语音交互在特定场景下遇到的问题,增强交互系统的适用性和稳定性。
然而,在相关技术中,如何采用多模态的信号来提高人机交互的适用性和稳定性的问题有待解决。
发明内容
本申请的目的是提供一种唇语识别设备及方法,用于解决以下问题:采用多模态的信号来提高人机交互的适用性和稳定性。
第一方面,本申请实施例提供一种人机交互方法,所述方法包括:
从视频数据的多帧图像中提取目标对象的唇部图像,并将提取的唇部图像按时序存储到唇部图像集合中;
根据预设的滑动窗口从所述唇部图像集合中截取多帧唇部图像,得到待处理唇部图像序列;
基于所述待处理唇部图像序列进行唇语识别,得到唇语识别结果;
若所述唇语识别结果中包括控制指令,则控制人机交互设备执行所述控制指令对应的操作。
在一个实施例中,从视频数据的多帧图像中提取目标对象的唇部图像,并将提取的唇部图像按时序存储到唇部图像集合中,包括:
对所述多帧图像中的每帧图像分别执行以下操作:
对所述图像进行人脸检测,获取所述图像的人脸关键点;
根据所述人脸关键点,从所述图像中截取所述目标对象的唇部图像;
按照所述图像在所述视频中的时序位置,将所述唇部图像存储到所述唇部图像集合中。
在一个实施例中,所述基于所述待处理唇部图像序列进行唇语识别,得到唇语识别结果之前,所述方法还包括:
对不同帧的唇部图像进行对齐处理。
在一个实施例中,所述对不同帧的唇部图像进行对齐处理,包括以下中的任一种或组合:
采用平移变换和/或旋转变换处理方式调整唇部边界、以使不同唇部图像的唇部边界平行于指定方向;
将不同唇部图像放缩到指定尺寸;
采用仿射变换方法处理不同帧的唇部图像,以使不同帧的唇部图像相对采集所述视频数据的镜头方位为预设方位。
在一个实施例中,所述滑动窗口的参数包括:步长和抽帧数量,所述抽帧数量用于确定所述多帧唇部图像的帧数;所述根据预设的滑动窗口从所述唇部图像集合中的唇部图像序列中截取多帧唇部图像,得到待处理唇部图像序列之前,所述方法还包括:
调整所述滑动窗口的抽帧数量;并,
调整所述滑动窗口的步长以确定相邻两滑动窗口之间的帧间隔。
在一个实施例中,所述调整所述滑动窗口的抽帧数量,包括:
根据所述目标对象的语速来确定所述抽帧数量;其中,所述抽帧数量与所述语速具有反比关系。
在一个实施例中,所述基于所述待处理唇部图像序列进行唇语识别之前,所述方法还包括:
根据二分类模型,对所述唇部图像序列进行二分类处理,确定所述唇部图像序列是否为噪音序列;
若非噪音序列,则执行对所述唇部图像序列进行唇语识别的步骤;
若是噪音序列,则对所述唇部图像序列进行丢弃处理。
在一个实施例中,所述根据预设的滑动窗口从所述唇部图像集合中的唇部图像序列中截取多帧唇部图像,得到待处理唇部图像序列之后,所述方法还包括:
从指定的采样起始点开始对所述待处理唇部图像序列进行等间隔采样,获取目标数量的待处理唇部图像序列。
第二方面,本申请实施例提供一种服务设备,所述服务设备包括处理器和存储器:
所述存储器,用于存储计算机程序;
所述控制器与所述存储器连接,被配置为基于所述计算机程序执行:
从视频数据的多帧图像中提取目标对象的唇部图像,并将提取的唇部图像按时序存储到唇部图像集合中;
根据预设的滑动窗口从所述唇部图像集合中截取多帧唇部图像,得到待处理唇部图像序列;
基于所述待处理唇部图像序列进行唇语识别,得到唇语识别结果;
若所述唇语识别结果中包括控制指令,则控制人机交互设备执行所述控制指令对应的操作。
在一个实施例中,从视频数据的多帧图像中提取目标对象的唇部图像,并将提取的唇部图像按时序存储到唇部图像集合中,包括:
对所述多帧图像中的每帧图像分别执行以下操作:
对所述图像进行人脸检测,获取所述图像的人脸关键点;
根据所述人脸关键点,从所述图像中截取所述目标对象的唇部图像;
按照所述图像在所述视频中的时序位置,将所述唇部图像存储到所述唇部图像集合中。
对视频数据中的目标对象进行人脸识别,截取唇部关键点并按照时序存储,使得后续在进行唇语识别时可以按照时序进行识别。
在一个实施例中,所述基于所述待处理唇部图像序列进行唇语识别,得到唇语识别结果之前,所述控制器还被配置为:
对不同帧的唇部图像进行对齐处理。
在一个实施例中,所述对不同帧的唇部图像进行对齐处理,包括以下中的任一种或组合:
采用平移变换和/或旋转变换处理方式调整唇部边界、以使不同唇部图像的唇部边界平行于指定方向;
将不同唇部图像放缩到指定尺寸;
采用仿射变换方法处理不同帧的唇部图像,以使不同帧的唇部图像相对采集所述视频数据的镜头方位为预设方位。
目标对象相对于摄像头并不是静止的,从而会导致视频数据中的目标对象的唇部图像的大小和位置并不相同,因此对唇部图像进行对齐处理可以降低甚至克服采用不同拍摄角度拍摄目标对象时导致对目标对象的唇部尺寸的识别造成的偏差。
在一个实施例中,所述滑动窗口的参数包括:步长和抽帧数量,所述抽帧数量用于确定所述多帧唇部图像的帧数;所述根据预设的滑动窗口从所述唇部图像集合中的唇部图像序列中截取多帧唇部图像,得到待处理唇部图像序列,包括:
调整所述滑动窗口的抽帧数量;并,
调整所述滑动窗口的步长以确定相邻两滑动窗口之间的帧间隔。
为了能够适应不同的情况提高唇语位置定位的精度,可以通过实时调整滑动窗口的参数来调整滑动窗口。
在一个实施例中,所述调整所述滑动窗口的抽帧数量,包括:
根据所述目标对象的语速来确定所述抽帧数量;其中,所述抽帧数量与所述语速具有反比关系。
在一个实施例中,所述基于所述待处理唇部图像序列进行唇语识别之前,所述控制器还被配置为:
根据二分类模型,对所述唇部图像序列进行二分类处理,确定所述唇部图像序列中是否为噪音序列;
若非噪音序列,则执行对所述唇部图像序列进行唇语识别的步骤;
若是噪音序列,则对所述唇部图像序列进行丢弃处理。
由于无法控制使用者只说支持的唇语,为了避免将无法支持的唇语送入识别阶段进而导致资源浪费,可以去除唇部序列中掺杂的不支持的唇语,大大增加了唇语识别的准确率。
在一个实施例中,所述基于所述待处理唇部图像序列进行唇语识别,得到唇语识别结果,包括:
对所述唇部图像序列中的每帧唇部图像进行二维特征提取,得到每帧唇部图像分别对应的二维唇部特征;
基于所述每帧唇部图像分别对应的二维唇部特征之间的关联关系,确定所述唇部图像序列的三维唇部特征;
对所述三维唇部特征进行多分类识别,得到唇语识别结果;或者,
对所述唇部图像序列进行分块处理,其中,每个分块中包括三维信息,所述三维信息包括图像宽度方向信息、图像高度方向信息以及时序信息;对所述三维信息中任意两个维度构成的平面信息分别进行特征提取,得到LBP-top特征,并基于所述唇部图像序列的LBP-top特征进行多分类识别,得到唇语识别结果。
在一个实施例中,所述根据预设的滑动窗口从所述唇部图像集合中的唇部图像序列中截取多帧唇部图像,得到待处理唇部图像序列之后,所述控制器还被配置为:
从指定的采样起始点开始对所述待处理唇部图像序列进行等间隔采样,获取目标数量的待处理唇部图像序列。
第三方面,本申请一实施例提供了一种计算机存储介质,其上存储有计算机程序指令,该计算机程序指令在计算机上运行时,使得所述计算机执行如第二方面所述的任一种方法。
本申请实施例中,服务设备首先对目标对象进行视频采集,然后对需要提取唇部信息的每帧目标图像分别执行采用人脸检测的方法从视频数据中提取每帧图像中的目标对象;并采用人脸特征点检测算法获取该目标对象的唇部图像;采用滑动窗口以及对齐处理等操作对唇部图像进行处理,得到待处理唇部图像序列;对待处理唇部图像序列进行初步粗分类,筛选掉虽有耦合性但不支持的唇语;对筛选过后唇部图像序列进行唇语识别,得到唇语识别结果;根据唇语识别的结果,执行相应的操作。从而可以在除语音交互外,增加基于唇语识别结果的多模态的信号提高人机交互的适用性和稳定性。
附图说明
为了更清楚地说明本申请实施例或相关技术中的技术方案,下面将对实施例或相关技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1中示例性示出了根据一些实施例的人机交互设备的使用场景的示意图;
图2中示例性示出了根据一些实施例的控制装置100的硬件配置框图;
图3中示例性示出了根据一些实施例的服务设备200的硬件配置框图;
图4中示例性示出了根据一些实施例的服务设备200中软件配置示意图;
图5中示例性示出了根据一些实施例的服务设备200中应用程序的图标控件界面显示示意图;
图6中示例性示出了本申请实施例提供的服务设备在语音交互场景的一种应用示意图;
图7为本申请实施例提供的人机交互方法的应用场景图;
图8a为本申请实施例提供的人机交互方法的整体流程图;
图8b为本申请实施例提供的人机交互方法的另一流程图;
图9为本申请实施例提供的人机交互方法的人脸关键点示意图;
图10a为本申请实施例提供的人机交互方法的唇部对齐处理示意图;
图10b为本申请实施例提供的人机交互方法的唇部对齐处理示意图;
图10c为本申请实施例提供的人机交互方法的唇部对齐处理示意图;
图11中示例性示出了根据唇部样本图像对应的语音信号对唇部样本图像进行标注的流程示意图;
图12中示例性示出了唇部图像标记的示意图;
图13中示例性示出了定位结束帧的位置的流程示意图;
图14a中示例性示出了多张视频帧输入2D卷积神经网络模型的示意图;
图14b中示例性示出了多张视频帧输入3D卷积神经网络模型的示意图;
图14c中示例性示出了根据一些实施例的服务设备200的应用场景。
具体实施方式
为使本申请的目的和实施方式更加清楚,下面将结合本申请示例性实施例中的附图,对本申请示例性实施方式进行清楚、完整地描述,显然,描述的示例性实施例仅是本申请一部分实施例,而不是全部的实施例。
需要说明的是,本申请中对于术语的简要说明,仅是为了方便理解接下来描述的实施方式,而不是意图限定本申请的实施方式。除非另有说明,这些术语应当按照其普通和通常的含义理解。
本申请中说明书和权利要求书及上述附图中的术语″第一″、″第二″、″第三″等是用于区别类似或同类的对象或实体,而不必然意味着限定特定的顺序或先后次序,除非另外注明。应该理解这样使用的用语在适当情况下可以互换。
术语″包括″和″具有″以及他们的任何变形,意图在于覆盖但不排他的包含,例如,包含了一系列组件的产品或设备不必限于清楚地列出的所有组件,而是可包括没有清楚地列出的或对于这些产品或设备固有的其它组件。
术语″模块″是指任何已知或后来开发的硬件、软件、固件、人工智能、模糊逻辑或硬件或/和软件代码的组合,能够执行与该元件相关的功能。
图1为根据实施例中人机交互设备的使用场景的示意图。如图1所示,人机交互设备200还与服务器400进行数据通信,用户可通过智能设备300或控制装置100操作人机交互设备200。
在一些实施例中,控制装置100可以是遥控器,遥控器和人机交互设备的通信包括红外协议通信或蓝牙协议通信,及其他短距离通信方式中的至少一种,通过无线或有线方式来控制人机交互设备200。用户可以通过遥控器上按键、语音输入、控制面板输入等至少一种输入用户指令,来控制人机交互设备200。
在一些实施例中,智能设备300可以包括移动终端、平板电脑、计算机、笔记本电脑,AR/VR设备等中的任意一种。
在一些实施例中,也可以使用智能设备300以控制人机交互设备200。例如,使用在智能设备上运行的应用程序控制人机交互设备200。
在一些实施例中,也可以使用智能设备300和人机交互设备进行数据的通信。
在一些实施例中,人机交互设备200还可以采用除了控制装置100和智能设备300之外的方式进行控制,例如,可以通过人机交互设备200设备内部配置的获取语音指令的模块直接接收用户的语音指令控制,也可以通过人机交互设备200设备外部设置的语音控制装置来接收用户的语音指令控制。
在一些实施例中,人机交互设备200还与服务器400进行数据通信。可允许人机交互设备200通过局域网(LAN)、无线局域网(WLAN)和其他网络进行通信连接。服务器400可以向人机交互设备200提供各种内容和互动。服务器400可以是一个集群,也可以是多个集群,可以包括一类或多类服务器。
在一些实施例中,一个步骤执行主体执行的软件步骤可以随需求迁移到与之进行数据通信的另一步骤执行主体上进行执行。示例性的,服务器执行的软件步骤可以随需求迁移到与之数据通信的人机交互设备上执行,反之亦然。
图2示例性示出了根据示例性实施例中控制装置100的配置框图。如图2所示,控制装置100包括控制器110、通信接口130、用户输入/输出接口140、存储器、供电电源。控制装置100可接收用户的输入操作指令,且将操作指令转换为人机交互设备200可识别和响应的指令,起用用户与人机交互设备200之间交互中介作用。
在一些实施例中,通信接口130用于和外部通信,包含WIFI芯片,蓝牙模块,NFC或可替代模块中的至少一种。
在一些实施例中,用户输入/输出接口140包含麦克风,触摸板,传感器,按键或可替代模块中的至少一种。
图3示出了根据示例性实施例中人机交互设备200的硬件配置框图。
在一些实施例中,人机交互设备200包括调谐解调器210、通信器220、检测器230、外部装置接口240、控制器250、显示器260、音频输出接口270、存储器、供电电源、用户接口中的至少一种。
在一些实施例中控制器包括中央处理器,视频处理器,音频处理器,图形处理器,RAM,ROM,用于输入/输出的第一接口至第n接口。
在一些实施例中,显示器260包括用于呈现画面的显示屏组件,以及驱动图像显示的驱动组件,用于接收源自控制器输出的图像信号,进行显示视频内容、图像内容以及菜单操控界面的组件以及用户操控UI界面等。
在一些实施例中,显示器260可为液晶显示器、OLED显示器、以及投影显示器中的至少一种,还可以为一种投影装置和投影屏幕。
在一些实施例中,调谐解调器210通过有线或无线接收方式接收广播电视信号,以及从多个无线或有线广播电视信号中解调出音视频信号,如以及EPG数据信号。
在一些实施例中,通信器220是用于根据各种通信协议类型与外部设备或服务器进行通信的组件。例如:通信器可以包括Wifi模块,蓝牙模块,有线以太网模块等其他网络通信协议芯片或近场通信协议芯片,以及红外接收器中的至少一种。人机交互设备200可以通过通信器220与控制装置100或服务器400建立控制信号和数据信号的发送和接收。
在一些实施例中,检测器230用于采集外部环境或与外部交互的信号。例如,检测器230包括光接收器,用于采集环境光线强度的传感器;或者,检测器230包括图像采集器,如摄像头,可以用于采集外部环境场景、用户的属性或用户交互手势,再或者,检测器230包括声音采集器,如麦克风等,用于接收外部声音。
在一些实施例中,外部装置接口240可以包括但不限于如下:高清多媒体接口(HDMI)、模拟或数据高清分量输入接口(分量)、复合视频输入接口(CVBS)、USB输入接口(USB)、RGB端口等任一个或多个接口。也可以是上述多个接口形成的复合性的输入/输出接口。
在一些实施例中,控制器250和调谐解调器210可以位于不同的分体设备中,即调谐解调器210也可在控制器250所在的主体设备的外置设备中,如外置机顶盒等。
在一些实施例中,控制器250,通过存储在存储器上中各种软件控制程序,来控制人机交互设备的工作和响应用户的操作。控制器250控制人机交互设备200的整体操作。例如:响应于接收到用于选择在显示器260上显示UI对象的用户命令,控制器250便可以执行与由用户命令选择的对象有关的操作。
在一些实施例中,所述对象可以是可选对象中的任何一个,例如超链接、图标或其他可操作的控件。与所选择的对象有关操作有:显示连接到超链接页面、文档、图像等操作,或者执行与所述图标相对应程序的操作。
在一些实施例中控制器包括中央处理器(Central Processing Unit,CPU),视频处理器,音频处理器,图形处理器(Graphics Processing Unit,GPU),RAM Random AccessMemory,RAM),ROM(Read-Only Memory,ROM),用于输入/输出的第一接口至第n接口,通信总线(Bus)等中的至少一种。
CPU处理器。用于执行存储在存储器中操作系统和应用程序指令,以及根据接收外部输入的各种交互指令,来执行各种应用程序、数据和内容,以便最终显示和播放各种音视频内容。CPU处理器,可以包括多个处理器。如,包括一个主处理器以及一个或多个子处理器。
在一些实施例中,图形处理器,用于产生各种图形对象,如:图标、操作菜单、以及用户输入指令显示图形等中的至少一种。图形处理器包括运算器,通过接收用户输入各种交互指令进行运算,根据显示属性显示各种对象;还包括渲染器,对基于运算器得到的各种对象,进行渲染,上述渲染后的对象用于显示在显示器上。
在一些实施例中,视频处理器,用于将接收外部视频信号,根据输入信号的标准编解码协议,进行解压缩、解码、缩放、降噪、帧率转换、分辨率转换、图像合成等视频处理中的至少一种,可得到直接可人机交互设备200上显示或播放的信号。
在一些实施例中,视频处理器,包括解复用模块、视频解码模块、图像合成模块、帧率转换模块、显示格式化模块等中的至少一种。其中,解复用模块,用于对输入音视频数据流进行解复用处理。视频解码模块,用于对解复用后的视频信号进行处理,包括解码和缩放处理等。图像合成模块,如图像合成器,其用于将图形生成器根据用户输入或自身生成的GUI信号,与缩放处理后视频图像进行叠加混合处理,以生成可供显示的图像信号。帧率转换模块,用于对转换输入视频帧率。显示格式化模块,用于将接收帧率转换后视频输出信号,改变信号以符合显示格式的信号,如输出RGB数据信号。
在一些实施例中,音频处理器,用于接收外部的音频信号,根据输入信号的标准编解码协议,进行解压缩和解码,以及降噪、数模转换、和放大处理等处理中的至少一种,得到可以在扬声器中播放的声音信号。
在一些实施例中,用户可在显示器260上显示的图形用户界面(GUI)输入用户命令,则用户输入接口通过图形用户界面(GUI)接收用户输入命令。或者,用户可通过输入特定的声音或手势进行输入用户命令,则用户输入接口通过传感器识别出声音或手势,来接收用户输入命令。
在一些实施例中,″用户界面″,是应用程序或操作系统与用户之间进行交互和信息交换的介质接口,它实现信息的内部形式与用户可以接受形式之间的转换。用户界面常用的表现形式是图形用户界面(Graphic User Interface,GUI),是指采用图形方式显示的与计算机操作相关的用户界面。它可以是在电子设备的显示屏中显示的一个图标、窗口、控件等界面元素,其中控件可以包括图标、按钮、菜单、选项卡、文本框、对话框、状态栏、导航栏、Widget等可视的界面元素中的至少一种。
在一些实施例中,用户接口280,为可用于接收控制输入的接口(如:人机交互设备本体上的实体按键,或其他等)。
在一些实施例中,人机交互设备的系统可以包括内核(Kernel)、命令解析器(shell)、文件系统和应用程序。内核、shelI和文件系统一起组成了基本的操作系统结构,它们让用户可以管理文件、运行程序并使用系统。上电后,内核启动,激活内核空间,抽象硬件、初始化硬件参数等,运行并维护虚拟内存、调度器、信号及进程间通信(IPC)。内核启动后,再加载Shell和用户应用程序。应用程序在启动后被编译成机器码,形成一个进程。
参见图4,在一些实施例中,将系统分为四层,从上至下分别为应用程序(Applications)层(简称″应用层″),应用程序框架(Application Framework)层(简称″框架层″),安卓运行时(Android runtime)和系统库层(简称″系统运行库层″),以及内核层。
在一些实施例中,应用程序层中运行有至少一个应用程序,这些应用程序可以是操作系统自带的窗口(Window)程序、系统设置程序或时钟程序等;也可以是第三方开发者所开发的应用程序。在具体实施时,应用程序层中的应用程序包不限于以上举例。
框架层为应用程序层的应用程序提供应用编程接口(application programminginterface,API)和编程框架。应用程序框架层包括一些预先定义的函数。应用程序框架层相当于一个处理中心,这个中心决定让应用层中的应用程序做出动作。应用程序通过API接口,可在执行中访问系统中的资源和取得系统的服务。
如图4所示,本申请实施例中应用程序框架层包括管理器(Managers),内容提供者(Content Provider)等,其中管理器包括以下模块中的至少一个:活动管理器(ActivityManager)用与和系统中正在运行的所有活动进行交互;位置管理器(Location Manager)用于给系统服务或应用提供了系统位置服务的访问;文件包管理器(Package Manager)用于检索当前安装在设备上的应用程序包相关的各种信息;通知管理器(NotificationManager)用于控制通知消息的显示和清除;窗口管理器(Window Manager)用于管理用户界面上的括图标、窗口、工具栏、壁纸和桌面部件。
在一些实施例中,活动管理器用于管理各个应用程序的生命周期以及通常的导航回退功能,比如控制应用程序的退出、打开、后退等。窗口管理器用于管理所有的窗口程序,比如获取显示屏大小,判断是否有状态栏,锁定屏幕,截取屏幕,控制显示窗口变化(例如将显示窗口缩小显示、抖动显示、扭曲变形显示等)等。
在一些实施例中,系统运行库层为上层即框架层提供支撑,当框架层被使用时,安卓操作系统会运行系统运行库层中包含的C/C++库以实现框架层要实现的功能。
在一些实施例中,内核层是硬件和软件之间的层。如图4所示,内核层至少包含以下驱动中的至少一种:音频驱动、显示驱动、蓝牙驱动、摄像头驱动、WIFI驱动、USB驱动、HDMI驱动、传感器驱动(如指纹传感器,温度传感器,压力传感器等)、以及电源驱动等。
在一些实施例中,人机交互设备启动后可以直接进入预置的视频点播程序的界面,视频点播程序的界面可以如图5中所示,至少包括导航栏510和位于导航栏510下方的内容显示区,内容显示区中显示的内容会随导航栏中被选中控件的变化而变化。应用程序层中的程序可以被集成在视频点播程序中通过导航栏的一个控件进行展示,也可以在导航栏中的应用控件被选中后进行进一步显示。
在一些实施例中,人机交互设备启动后可以直接进入上次选择的信号源的显示界面,或者信号源选择界面,其中信号源可以是预置的视频点播程序,还可以是HDMI接口,直播电视接口等中的至少一种,用户选择不同的信号源后,显示器可以显示从不同信号源获得的内容中的应用程序可以。
在一些实施例中,图6为人机交互设备在唇语交互场景的一种应用示意图,其中,用户1可以通过唇语说出希望人机交互设备200执行的指令,则人机交互设备200可以实时采集用户影像数据,并对用户影像数据中包括的用户1的指令进行识别,并在识别出用户1的指令后,直接执行该指令,在整个过程中,用户1没有实际对人机交互设备200或者其他设备进行操作,只是简单地说出了指令。
在一些实施例中,当如图2所示的人机交互设备200应用在如图6所示的场景中,人机交互设备200可以通过其图像采集器232实时采集用户影像数据,随后图像采集器232将采集得到的用户影像数据发送给控制器250,最终由控制器250对用户影像数据中包括的指令进行识别。
目前智能交互设备被看作万物联网的交互入口,因此语音交互获得了迅速发展,诸多语音交互系统出现在大众生活中。然而,单模态的语音交互系统抗干扰能力不强,在有背景噪音的场景下性能会明显下降,在距离较大的远场场景中会遇到唤醒困难的问题。此外,声音监听通道被占用时,单模态语音交互系统会彻底失效。为了解决以上系统缺陷,一方面可以依靠语音降噪和麦克风阵列等技术,来最大程度上消除背景噪音和远场环境对交互过程的影响,另一方面则可以借助多模态交互技术,赋予交互设备多模态的信号来获取处理通路,借此解决单一模态语音交互在特定场景下遇到的问题,增强交互系统的适用性和稳定性。
上述模态即感官,多模态即将多种感官进行融合。除语音交互外,多模态还包括机器视觉(自然物体识别,人脸识别,肢体动作识别,唇语识别等)和传感器智能(人工智能(Artificial Intelligence,AI)对热量、红外捕捉信号、空间信号的阅读与理解)两类。相关技术中希望通过多模态交互模式+先进的AI算法赋予智能交互设备更″类人″的属性,增加机器理解能力和主动服务的″意识″。
如何结合多模态交互提高人机交互的适用性和稳定性是业内一直关心的问题。
在诸多模态中,唇语识别是除了声音识别外,机器识别人发音内容之外比较简单有效的方式。将唇语识别引入智能交互过程中将有效解决单一语音模态交互在噪音场景、远场场景及声音监听通道占用场景中遇到的问题。
然而,唇语识别目前也面临挑战,如相关技术中唇语识别精度不高,导致唇语识别应用场景受限。发明人研究发现,唇语识别精度不高的原因是复杂且多方面的。
一方面的问题是唇部识别受环境影响较大,不同的说话人的唇形,说话人相对于摄像头的位置以及光照强弱等都会对识别结果产生很大影响;在本申请中采用对齐处理来对唇部图像进行处理,使得唇部图像在水平方向、所占比例和拍摄角度方面保持一致来尽可能规避唇形和摄像头位置带来的误差。
另一方面的问题是说话人的发音位置,关键词的出现位置的确定,在纯依靠图像信息情况下仍然面临很大挑战;在本申请中采用对唇语图像进行分类识别后,定位唇语图像中唇语的起止位置对应的图像帧进行处理,得到能够包含唇语的唇部图像序列,结合后续并对唇部图像序列进行处理,解决了说话人的发音位置,关键词的出现位置的不同导致的唇语识别不正确的问题。
再一方面的问题是唇语识别依靠唇部图像的时间序列特征,然而存在发音不同但唇部序列耦合性较强情况;在本申请中通过对唇部图像发音位置的定位,以及后续根据二分类模型判断唇部图像是否为噪音序列,若非噪音序列则进行后续的唇语识别操作,结合选择合适的唇语识别模型来提高唇语识别的准确性。整个流程中,通过定位发音位置,基于二分类模型来实现支持的唇语的进一步定位,筛选掉虽有耦合性但不支持的唇语,进一步结合唇语识别模型来兼容识别不同发音的唇语进一步提高对耦合性较强的唇语的识别。
基于上述发明构思,对本申请实施例提供的唇语识别的方法的另一应用场景进行说明,如图7所示,图中包括:服务器701,目标对象702,人机交互设备703;
其中,服务器701可以是一台服务器、若干台服务器组成的服务器集群或云计算中心。服务器701可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间服务、域名服务、安全服务、CDN、以及大数据和人工智能平台等基础云计算服务的云服务器。
人机交互设备703可以为各种智能设备。包括但不限于计算机、笔记本电脑、智能电话、平板电脑、智能冰箱、智能空调、智能电视等设备。
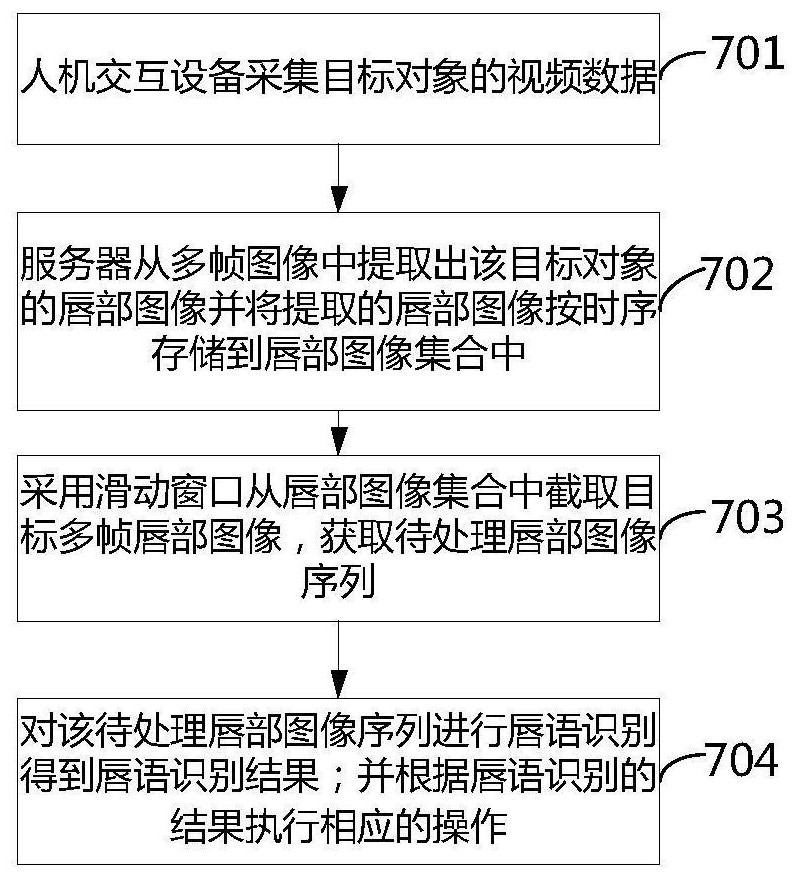
其中,目标对象702可通过人机交互设备703进行虚拟会议,若目标对象702需要调大音量,但现在声音监听通道被占用,目标对象702可通过唇语来说″大声一点″,人机交互设备703采集到目标对象702的视频数据,可发送给服务器701进行唇语识别。当然具体实施时,也可以由人机交互设备完成唇语识别。下面以服务器进行唇语识别为例进行说明,如图8a所示:
在步骤701中:人机交互设备采集目标对象的视频数据,即采集目标对象的视频数据;其中目标对象为上述虚拟会议中的参会人员;
在步骤702中:服务器701从多帧图像中提取出该目标对象的唇部图像,并将提取的唇部图像按时序存储到唇部图像集合中;
在步骤703中:采用滑动窗口从唇部图像集合中截取多帧唇部图像,获取待处理唇部图像序列;
在步骤704中:对该待处理唇部图像序列进行唇语识别,得到唇语识别结果;并根据唇语识别的结果执行相应的操作。
由此,本申请实施例中,从视频中截取唇部图像以便于对唇部特征进行分析,通过滑动窗口能够截取到含有唇语的唇部图像序列,能够有效的取得唇语所在的图像序列,然后采用唇语识别得到唇语识别结果以便于控制人机交互设备。
在另一实施例中,除了采用滑动窗口来获取唇部图像序列,本申请实施例中应用于图7应用场景的唇语识别方法如图8b所示:
在步骤801中:对目标对象进行视频采集;其中目标对象可以是参会人员中的任意一个。
在步骤802中:对需要提取唇部信息的每帧目标图像分别执行:从目标图像中提取出目标对象的唇部图像;并对唇部图像进行分类识别,将唇部图像划分为发音帧或静默帧。
在步骤803中:若连续多帧唇部图像的分类识别结果满足从静默帧到发音帧再到静默帧的变化规律,则基于变化规律从连续多帧唇部图像中定位唇语的起止位置。
在步骤804中:获取起止位置之间的唇部图像序列,进行唇语识别,得到唇语识别结果。
由此,本申请实施例中,从视频中截取唇部图像以便于对唇部特征进行分析,通过定位唇语的起止位置获得唇部图像序列,然后采用唇语识别得到唇语识别结果以便于控制人机交互设备。
例如:由服务器对唇语进行识别时,服务器根据唇语识别的结果,生成用于控制智能设备的指令,例如″大声一点″;由智能设备对唇语进行识别时,智能设备根据唇语识别的结果直接执行唇语识别结果对应的指令。
本申请实施例中提出一种唇语识别的方法及服务设备,本申请实施例可以在除语音交互外,增加基于唇语识别结果的多模态的信号提高人机交互的适用性和稳定性。本申请中的唇语识别方法可包括以下几部分内容:采用滑动窗口提取唇部图像序列、为了能够提高唇语识别的精度可以对唇部图像进行对齐处理、唇部图像起止位置的定位和后续的唇语识别几部分内容。下面对这几个主要部分分别进行说明:
一、采用滑动窗口提取唇部图像序列
该部分可包括获取唇部图像和采用滑动窗口截取唇部图像序列两部分内容:
1、获取唇部图像
从视频数据的多帧图像中提取目标对象的唇部图像,并将提取的唇部图像按时序存储到唇部图像集合中。
实施时,可以基于分类识别和位置检测技术定位出唇部图像区域。当然为了提高唇部识别的准确性,本申请实施例中,可以基于人脸关键点来提取唇部图像。故此,可实施为:对视频数据中的每帧图像分别执行以下操作:
对视频数据中的每帧图像进行人脸检测,获取图像的人脸关键点。其中,在一个实施例中,传统人脸检测算法空分复用(Security Device Manager,SDM)中采用方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取器和线性回归器对人脸的关键点进行提取,在本申请中采用卷积神经网络(Convolutional Neural Networks,CNN)代替上述人脸检测算法SDM中的HOG特征提取器和线性回归器,在人脸检测算法SDM中采用CNN提取人脸关键点,该算法将人脸用68个关键点进行标记,如图9所示,该68个关键点定位了人脸的基本轮廓,眉毛/眼睛/鼻子/唇部等特征轮廓。然后可以根据上述人脸关键点中唇部的关键点,从每帧图像中截取目标对象的唇部图像。如图9所示,图9中采用20个关键点定位嘴巴轮廓,则可以根据该20个关键点在图像中截取唇部图像。然后按照图像在视频中的时序位置,将唇部图像存储到唇部图像集合中。
本领域的技术人员需要知道的是,上述的关键点总数并不是唯一值,可根据具体情况具体设置,在其他的人脸关键点识别技术中,可采用比68关键点更多或更少的关键点来表达人脸图像各个五官的区域,同样适用于本申请提供的唇语识别方法。
在一个实施例中,若视频数据中有多个人脸,对视频中的多张人脸采用上述关键点的方法进行关键点标记,并检测唇部的状态,由于唇语识别是基于唇部动作产生的,因此将多个人脸中唇部处于开口状态的人脸确定为目标对象;在另一实施例中,由于在人机交互的过程中,目标对象会正对摄像头,其视觉焦点往往会落到人机交互设备上,故此还可以通过视觉焦点定位的方法来识别目标对象。例如可以计算视频数据中多张人脸中每个人脸的视线焦点与人机交互设备的位置关系,将视觉焦点位于人机交互设备上的用户作为目标对象。
此外,在又一个实施例中,还可以判断多个人脸与人机交互设备的位置关系。例如多个人脸中,仅有一个人脸正面面对人机交互设备,则将该人脸对应的用户作为目标对象。若有多个人脸均正面面对人机交互设备,则这多个人脸对应的用户均作为目标对象。之后,可基于后续的唇语识别来进一步筛选出做出唇语指示的目标对象。
2、采用滑动窗口截取唇部图像序列
该部分又可分为获取图像序列和下采样两部分。下采样在实施时可作为可选方案。
2-1、获取图像序列
在一个实施例中,由于唇语具有一定的连续性且短时间内的图像序列即包括唇语。故此,可以采用滑动窗口从唇部图像集合中截取多帧的唇部图像,得到待处理唇部图像序列。滑动窗口的大小可以根据实验结果来确定,实验表明采用滑动窗口的方式能够方便简洁的获取到包含唇语的图像序列,从而实现对唇语位置的定位。
在另一个实施例中,为了能够适应不同的情况提高唇语位置的定位精度。本申请实施例中,滑动窗口可具有两个可动态调整的参数。其中一个参数为抽帧数量,另一个参数为步长。
其中,抽帧数量用于确定多帧唇部图像的帧数,步长用于决定相邻两滑动窗口之间间隔的帧数。故此,实施时,可以根据需求调整滑动窗口的抽帧数量来确定从唇部图像集合中截取的唇部图像的帧数,基于调整滑动窗口的步长,来调整相邻两滑动窗口之间的帧间隔,也即如果将使用一次滑动窗口截取唇部图像序列视为对视频进行一次采样,则通过调整滑动窗口的步长相当于实现了对视频的采样频率的调整。
实施时,由于后期唇语识别时,语速不同对应的采样帧数可不同,例如语速较快时采样帧数可适当变少。故此为了合理截取唇部图像序列,对滑动窗口的抽帧数量的动态调整可基于语速来实现。实施时,抽帧数量与语速可具有反比关系。
为了能够简便的使用语速来调整抽帧数量,本申请实施例中可提供以下方法进行举例说明:
一种实施方式为,基于目标对象的音视频数据来确定用户的语速;例如,预先采集多个用户的音视频数据,从视频中分析多个用户的人脸特征并根据音频数据分析用户的语速,(例如将单位时间说出的字符数量表示语速)。之后,将用户的人脸特征与用户的语速进行关联并存储到数据库中。然后使用的时候,对用户进行人脸检测然后基于数据库中存储的人脸特征,对该用户进行人脸识别。得到数据库中存储的与该用户匹配的人脸特征,进而可得到该匹配的人脸特征关联的语速。然后基于预设语速和抽帧数量的对应关系,来确定该用户的抽帧数量。其中,实施时不同语速与抽帧数量的对应关系可根据实验获得。
另一种实施方式为,基于视觉技术来确定语速。例如在目标对象在视频会议时,采用视觉技术分析唇部的动作的变化频率,变化频率越高表明语速越快,然后根据语速确定抽帧数量。
关于滑动窗口的步长,例如:唇部图像集合中有30帧图像,抽帧数量为20,步长为5,第一个滑动窗口抽取了1-20帧,则第二个滑动窗口从第26帧开始抽取直至抽取20帧为止。在本申请实施例中,可以基于以下方法来动态调整步长:
一种实施方式为,步长与唇部识别的精度成正相关,步长越小精度越准确,计算量越高,可以由本领域的工作人员在多次测试后根据经验值确定;用户可根据自己的精度需求设置步长。
另一种实施方式为,根据用户的年龄与音准来调整步长;例如:用户的音准越精确,则步长越大;用户的年龄越大则步长越小。
2-2、下采样
在本申请实施例中,根据预设的滑动窗口从唇部图像集合中的唇部图像序列中截取多帧的唇部图像,得到待处理唇部图像序列之后;为了简化计算可以从指定的采样起始点开始对待处理唇部图像序列进行等间隔采样,获取目标数量的待处理唇部图像序列用于进行唇语识别。
例如:根据预设的滑动窗口从唇部图像集合中的唇部图像序列中截取了20帧的唇部图像;在对该20帧唇部图像进行等间隔采样,若指定起始点为第2帧,则从第2帧开始到第20帧进行等间隔采样。
若根据预设的滑动窗口从唇部图像集合中的唇部图像序列中截取了20帧的唇部图像;指定起始点为第1帧,则从第1帧开始到第20帧进行等间隔采样。
上述指定起始点的选择是随机的,即可以从第1帧开始等间隔采样也可以从第2帧开始等间隔采样。
二、对唇部图像进行对齐处理
对唇部图像的对齐处理作为一种可选的方案,其中采用滑动窗口获取图像序列与对齐处理的执行时机不受限定,即可以先采用滑动窗口获取图像序列再执行对齐处理;也可以先执行对齐处理再采用滑动窗口获取图像序列。
在本申请实施例中,在有下采样需求时可以进行下采样处理,在没有下采样需求时,也可以不执行下采样步骤。选择执行下采样时,下采样与对齐处理的执行时机不作限定,但下采样要在采用滑动窗口获取图像序列之后进行。
由于目标对象相对于摄像头并不是静止的,从而会导致视频数据中的目标对象的唇部图像的大小和位置并不相同,因此需要对唇部图像进行对齐处理来降低甚至克服采用不同拍摄角度拍摄目标对象时导致对目标对象的唇部尺寸的识别造成的偏差。本申请实施例中,为了解决目标对象在摄像头中左右或上下晃动造成的偏差采用平行于指定方向的方式;为了解决目标对象距离摄像头的距离不固定导致的对目标对象唇部尺寸识别造成的偏差,采用调整唇部图像所占比例的方式;为了解决由于目标对象相对于摄像头发生头部左右转动导致对目标对象的唇部尺寸的识别造成的偏差,采用调整唇部图像的角度的方式;下面对上述三种方式进行说明:
如图10a中处理前所示,目标对象相对于摄像头发生左右或上下晃动,则会导致目标对象的唇部图像不在同一水平方向;
在本申请实施例中,预先在唇部图像中选择一帧图像作为参考帧,并将该参考帧唇部左右端点的延展方向作为指定方向,当然也可以采用唇部上下两个端点的延展方向作为指定方向。之后,采用平移变换处理方式调整不同帧的唇部图像中的唇部边界平行于指定方向。以唇部左右两端点的延展方向作为指定方向为例,即通过对不同帧的唇部图像进行平移变换,使得不同帧的唇部左右两端点的延展方向几乎平行,如图10a中处理后所示。
实施时,可以计算参考帧唇部关键点与非参考帧的唇部关键点之间的距离,并根据唇部关键点之间的距离确定平移变换矩阵,利用平移变换矩阵对不同帧的唇部关键点进行平移变换处理,使得不同帧的唇部左右两端点的延展方向几乎平行。
(2)所占比例
如图10b处理前所示,目标对象在说话过程中相对于摄像头前后移动时,会导致目标对象的唇部图像在指定范围内所占比例不同;
在本申请实施例中,预先在唇部图像中选择一帧图像作为参考帧,按照预设比例对非参考帧的唇部图像进行缩放,然后利用旋转矩阵调整不同帧的唇部图像,以使不同帧的唇部图像放缩到指定尺寸。例如,识别唇部关键点之后,基于唇部的上下左右顶点从原图中裁剪出唇部图像,然后将不同帧唇部图像放缩到等到,如图10b所示为处理前后的效果示意图。
如图10c处理前所示,目标图像在摄像头中头部左右转动时,会导致唇部图像相对于镜头的角度发生变化;
在本申请实施例中,预先在唇部图像中选择一帧图像作为参考帧,计算参考帧中唇部关键点分别与除参考帧之外的唇部图像中唇部关键点之间的距离和角度,并根据该距离与角度确定仿射矩阵,利用仿射矩阵调整不同帧的唇部图像,以使不同帧的唇部图像相对采集视频数据的镜头方位与参考帧相同,如图10c处理后所示。
在本申请中采用上述的对齐方法,对唇部图像进行对齐处理,使得唇部图像集合中的唇部图像的大小、角度均相同。
三、唇部图像起止位置的定位
通常情况下,用户在使用唇语交互时,需要张口来传递唇语,所以传递唇语的图像中唇部一般处于开口状态而不是闭合状态。有鉴于此,本申请实施例中可通过检测唇部的开合状态来定位唇部图像的起止位置。
在一个实施例中,可以对获取到的唇部图像对齐处理之后,通过分类识别来检测唇语的开合状态,以便于将唇部图像划分为发音帧或静默帧。
其中,发音帧指传递唇语的图像中目标对象的唇部处于发音状态。静默帧指传递唇语的图像中目标对象的唇部处于静默状态。实施时,为了提高分类的准确性,发音帧和静默帧均是通过包含相关帧的图像序列来识别的。例如,采用当前帧和当前帧前的至少一帧历史帧划分当前帧是否为发音帧。实施时,可以提取当前帧和至少一帧历史帧的ImageDynamics然后进行分类识别,该至少一帧历史帧可以为连续的多帧图像。亦或者可以提取当前帧和至少一帧历史帧的光流特征进行分类识别,该至少一帧历史帧可以为当前帧的前一帧图像,亦或者与当前帧间隔多帧的历史帧。
亦或者,在另一个实施例中,还可以采用2D CNN(2维卷积神经网络)+shift的形式,典型的shift为temporalshiftmodule(TSM)方式对包含当前帧的多帧图像进行分类,将当前帧划分为发音帧或静默帧。
由于视频也是一个图像序列,故此通过划分为发音帧和静默帧能够定位到传递唇语的图像序列。
在一个实施例中,为了能够准确的对唇部图像进行分类识别,本申请实施例中可基于预先训练好的唇部图像分类模型,将唇部图像划分为发音帧或静默帧。其中,可根据以下方法得到唇部图像分类模型:
首先获取唇部样本图像,并为唇部样本图像标注类别标签。该类别标签用于指示唇部样本图像属于发音帧还是静默帧。
实施时,可以手工标注唇部样本图像的类别标签。为了提高标注的效率,本申请实施例中采用语音检测发音位置自动标注的方式。例如可采用音视频配合的方式自动进行标注。如录制一段或多段视频,从视频中每帧图像中提取唇部图像作为唇部样本图像。录制视频的同时录制了音频。则每帧唇部样本图像将有对应的语音信号。实施时,可基于语音信号来判断对应的唇部样本图像是否包含唇动。
如图11所示,可通过以下方法根据唇部样本图像对应的语音信号对唇部样本图像进行标注:
S1101,对唇部样本图像对应的语音信号进行声音活动检测(A-VAD,Audio VoiceActivity Detection),得到语音检测结果。
其中,为了提高检测的准确性,每帧唇部样本图像的语音信号为语音片段,该语音片段包括唇部样本图像以及该图像之前的多帧图像的语音内容。
S1102,判断语音检测结果是否为语音,若否,则执行步骤S1103,若是,则执行步骤S1104。
S1103,若不包含语音,则标注唇部样本图像为静默帧。
其中,在一个实施例中,若包含语音,可以标注对应的唇部样本图像为发音帧。但由于VAD检测技术的缺陷容易将噪声较大的语音信号的检测结果确定为语音,故此,本申请实施例中为了提高标注的准确性,进一步配合能量检测技术来准确的识别出发音帧。如可在步骤S1104中执行,若语音检测结果为语音,计算语音信号的能量值的归一化结果。
本申请一实施例中,通过能量检测技术确定语音信号的所有能量值之后,将每一个能量值均与该能量值中的最大值相除,得到语音信号的能量值的归一化结果。
执行步骤S1104之后,继续执行以下步骤:
S1105,判断语音信号的能量值的归一化结果是否大于预设阈值;若否,则执行步骤S1106,若是,则执行步骤S1107。
S1106,标注唇部样本图像为静默帧。
S1107,标注唇部样本图像为发音帧。
示例性地,如图12所示,为标注完成的唇部样本图像,其中,标号1、标号2、标号10、以及标号11为静默帧,标号3-标号9为发音帧。
这里,预设阈值可以是经过多次实验分析确定的。进一步地,还可以通过不同音色之间的区别,设置多个预设阈值,例如,根据男生、女生、老人、小孩等音色的不同,设置对应的预设阈值。
由此,通过准确确定唇部图像的发音帧以及静默帧,可以避免唇部发音过程中产生判断错误的情况,进而提高唇语识别的准确度。
在获得唇部样本图像及其关联的类别标签之后,本申请实施例中将唇部样本图像输入待训练的唇部图像分类模型,得到待训练的唇部图像分类模型输出的唇部样本图像的预测类别标签;根据预先设置的损失函数确定预测类别标签与类别标签之间的损失,训练待训练的唇部图像分类模型的参数,得到唇部图像分类模型。
其中,可以通过交叉熵等计算方式确定预测类别标签与类别标签之间的损失。唇部图像分类模型可以为卷积神经网络模型。在此并不限定唇部图像分类模型具体的模型结构,可根据实际应用情况进行调整。
可选地,在训练好唇部图像分类模型之后,可实现对多帧唇部图像的分类识别。由于唇语交互的规律,用户往往在短时间内通过唇语表述出完整意图。故此,唇语的图像序列一般应符合连续多帧图像均为发音帧的规律。由此,为了准确定位唇语起止位置,可定义包含唇语的图像序列的变化规律为分类识别结果中先识别到静默帧然后识别到连续的发音帧之后由于用户停止说话又识别到静默帧。故此,若连续多帧唇部图像的分类识别结果满足从静默帧到发音帧再到静默帧的变化规律,则基于该变化规律可从连续多帧唇部图像中定位唇语的起止位置。这样,从静默帧到发音帧的变化能够准确定位到唇语的起始位置,从发音帧到静默帧的变化能够准确定位到唇语的结束位置。
基于以上变化规律,在一个实施例中,可将连续多帧唇部图像中首次分类为发音帧的唇部图像确定为唇语的起始帧;并,将连续多帧唇部图像中最后分类为发音帧的唇部图像确定为唇语的结束帧。
示例性地,如图12中,将首次分类为发音帧的唇部图像(即标号3对应的图像)确定为唇语的起始帧,将最后分类为发音帧的唇部图像(即标号9对应的图像)确定为唇语的结束帧。
可选地,由于用户说话的随机性,也可能会出现误判为静默帧或用户发音缓慢导致唇语的发音帧之间会伴有静默帧的情况。故此,为了准确的识别唇语的结束帧,可基于结束帧之后的几帧的分类识别结果来协助定位结束帧的位置。如图13所示:
S1301,在检测发音帧之后首次出现静默帧。
S1302,检测首次出现的静默帧之后的预设帧数内是否存在发音帧,若不存在发音帧,则执行步骤S1303,若存在发音帧,则从发音帧开始返回执行步骤S1301。
S1303,将首次出现的静默帧的前一帧确定为最后分类为发音帧的唇部图像。
基于准确的定位唇语的起止位置,可获取含有唇语的唇部图像序列进行后续的唇语识别。
四、唇语识别
通常情况下,不同唇语的发音近似,且考虑到人机交互设备可能支持的唇语有限。本申请实施例中,可定义噪音序列。
故此,为了能够更好的定位出唇语的位置,并提高唇语识别的效率。本申请实施例中,在得到唇部图像序列之后,还可以实现噪声筛选,从而筛选掉含有噪音序列的唇部图像序列。
在一些实施例中,噪音序列筛选可以基于分类识别技术实现。如可以训练二分类模型对图像进行分类处理,得到的分类结果用于表示输入的唇部图像序列是否为噪音序列。若为噪音序列则交由候选的唇语识别模型进行唇语识别,否则可以丢弃该唇部图像序列,不作唇语识别。
在训练二分类模型的过程中,训练样本具有关联的标签,该标签用于指示该训练样本是否为噪音序列。在模型训练阶段,将训练样本输入给待训练的二分类模型以使该二分类模型预测该训练样本是否为噪音序列,并将预测结果和标签进行比对得到损失,然后基于该损失调整二分类模型的参数,直至二分类模型训练收敛为止。
在一个实施例中,可以采用HOG和LBP(Local Binary Pattern,局部二值模式)提取唇语图像的图像特征,并将该特征送入CNN模型中进行识别,从而确定唇部图像序列是否为噪音序列;直至CNN模型训练收敛。
在另一种实施方式中,二分类模型可用于识别唇部图像序列中发音帧的占比,若发音帧在唇部图像序列中的占比大于阈值则可以分类为非噪音序列,否则占比较小则分类为噪音序列。
在对唇部图像序列筛选之后,为了能够准确的识别用户意图,可通过以下方法进行唇语识别来确定后续需要执行的操作,本申请实施例中通过下面的实施例举例说明唇语识别的方法:
在一种实施例中,唇语识别可以基于3D卷积神经网络模型(3D ConvolutionalNeural Networks,3D CNN)实现。示例性地,将唇部图像序列中唇部图像的数量作为一个维度,将唇部图像中的像素点矩阵作为两个维度,对唇部图像序列进行处理,例如,唇部图像序列中包含30张唇部图像,并且唇部图像为64*64的像素点,则按照上述维度处理后,得到唇部图像序列对应的64*64*30*3的矩阵,其中64*64*30为维度值,3为通道数,将该矩阵输入预先训练好的3D卷积神经网络模型,得到3D卷积神经网络模型输出的11*1维度的向量(vector),这里,前10*1维度分别对应不同的命令词,最后一个值表示噪音数据。在一些实施例中,3D卷积神经网络模型中可以设置多个卷积层,在卷积层与卷积层之间可以设置池化层,在全连接层中还可以设置丢弃层(即dropout)。
在训练3D卷积神经网络模型的过程中,训练样本具有关联的标签,该标签用于指示该训练样本包含的命令词类别。在模型训练阶段,将训练样本输入至待训练的3D卷积神经网络模型以使该3D卷积神经网络模型预测该训练样本包含的命令词的类别,并将预测结果和标签进行比对得到损失,然后基于该损失调整3D卷积神经网络模型的参数,直至3D卷积神经网络模型训练收敛为止。
在另一个实施例中,由于应用3D卷积神经网络模型对唇语进行识别的过程计算量较大,资源需求也较高,响应速度还比较慢,实际应用过程中会出现压力测试阶段阻塞的情况,为解决该问题,可以采用2D卷积神经网络模型(2D Convolutional Neural Networks,2D CNN)对唇语进行识别,因为2D卷积神经网络模型对唇语进行识别的过程计算量较小,例如采用轻量级的2D卷积神经网络(SqueezeNet/MobileNet/ShuffleNet),但是识别唇语图像需要考虑唇语图像帧与帧之间的时间关联特征,例如,2D卷积神经网络模型输入的是三维数据,如图14a所示,图片对应的三维数据为[宽度,高度,输入通道数],需要的一个卷积核大小对应的是[卷积核长度1,卷积核长度2,输入通道数],一个卷积核得到的是一个特征图像,若需要输出多个特征图像,则可以定义多个卷积核。而3D卷积神经网络模型输入的是四维数据,如图14b所示,图片对应的四维数据为[深度,宽度,高度,输入通道数],也即相对2D卷积神经网络模型输入的三维数据来说,增加了一个维度(也即时间维度),那么3D卷积神经网络模型处理数据时,需要的一个卷积核大小对应的是[卷积核长度3,卷积核长度4,卷积核长度5,输入通道数],因此3D卷积神经网络模型在时间维度上可以对输入图像进行处理,但是2D卷积神经网络模型在时间维度上不能对输入图像进行处理,只采用2D卷积神经网络模型对唇语进行识别,不能解决该时间关联特征,因此,可以选用2D卷积神经网络模型与基于自注意力机制的神经网络模型(Transformer)结合,代替3D卷积神经网络模型进行唇语识别。
在一些实施例中,还可以利用2D CNN与TSM的结合或者利用2D CNN与LSTM(LongStort Term Memory,RNN(Recurrent Neural Networks)的一种,即循环神经网络)的结合,代替2D CNN与基于自注意力机制的神经网络模型结合的方案,在此并不限定具体的结合方式,可根据实际应用情况进行调整。
在一些实施例中,对唇部图像序列中的每帧唇部图像进行二维特征提取,得到每帧唇部图像分别对应的二维唇部特征;基于每帧唇部图像分别对应的二维唇部特征之间的关联关系,确定唇部图像序列的三维唇部特征;对三维唇部特征进行多分类识别,得到唇语识别结果。
示例性地,通过预先训练好的2D卷积神经网络模型提取唇部图像序列中的唇部特征(即为二维唇部特征),并将该唇部特征继续输入预先训练好的基于自注意力机制的神经网络模型中,输出唇部特征在时间序列中的排序结果(即为三维唇部特征),对三维唇部特征进行多分类识别处理,得到唇语识别结果,由此实现了一种在效率和精度上一种平衡折中的唇语识别方法。
在另一个实施例中,还可以对唇部图像序列进行分块处理,其中,每个分块中包括三维信息,三维信息包括图像宽度方向信息、图像高度方向信息以及时序信息;对三维信息中任意两个维度构成的平面信息分别进行特征提取,得到LBP-top(local binarypatterns fromthree orthogonal planes,LBP从二维空间到三维空间的拓展,也即LBP从三个正交平面中提取特征)特征,并基于唇部图像序列的LBP-top特征进行多分类识别,得到唇语识别结果。
示例性地,可以选用传统机器学习算法对唇部图像序列进行分类处理。例如:LBP结合SVM(support vector machines,支持向量机)进行分类处理。其中,LBP是一种描述图像局部纹理特征的算子,具有旋转不变性和灰度不变性等显著的优点,可以进行图像局部纹理特征的提取。由于唇语图像序列中包含唇动变化的时间信息和空间信息,因此利用LBP将唇部图像序列进行分块处理,然后进行特征提取,再将空间域提取的特征与时间域提取的特征进行压缩拼接,得到唇语图像序列的一维特征,最后对唇语图像序列的一维特征进行分类识别,得到唇语识别结果。本申请实施例中服务设备首先对目标对象进行视频采集,然后对需要提取唇部信息的每帧目标图像分别执行:从目标图像中提取出目标对象的唇部图像,并对唇部图像进行分类识别,将唇部图像划分为发音帧或静默帧,若连续多帧唇部图像的分类识别结果满足从静默帧到发音帧再到静默帧的变化规律,则基于该变化规律从连续多帧唇部图像中定位唇语的起止位置,在获取起始位置之间的唇部图像序列之后,进行唇语识别,得到唇语识别结果。从而可以在除语音交互外,增加基于唇语识别结果的多模态的信号提高人机交互的适用性和稳定性。
为了便于理解,下面对本申请实施例提供的服务设备的应用场景进行说明,如图14c所示,在步骤S1401中,服务设备200内的视频采集器232实时采集服务设备200所在周围环境中的视频数据,并将所采集到的视频数据发送给控制器250,控制器250将视频数据进一步通过通信器220发送给服务器400,在步骤S1402中,由服务器400识别视频数据中包括的指令,随后,服务器400将识别得到的指令发送回服务设备200,对应地,服务设备200通过通信器220接收指令后发送给控制器250,最终在步骤S1403中,控制器250可以直接执行所接收到的指令。
本发明实施例还提供一种计算机存储介质,所述计算机存储介质中存储有计算机程序指令,当所述指令在计算机上运行时,使得所述计算机执行上述设备响应的方法的步骤。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
- 一种车载功能的服务方法、人机交互系统及电子设备
- 一种通过人机交互技术实现自动客户服务的方法和设备