用于构建人单细胞BCR测序文库的试剂盒及其应用
文献发布时间:2023-06-19 11:37:30
技术领域
本发明涉及一种试剂盒,具体涉及一种人源单细胞BCR(B细胞受体)测序文库的构建方法、用于构建人源单细胞BCR测序文库的试剂盒及人源BCR测序方法,属于分子生物学领域。
背景技术
免疫组库(immune repertoire,IR)是指在任何指定时间,某个个体的循环系统中所有功能多样性B细胞和T细胞的总和。传统的免疫组库研究技术往往只能检测TCR(T细胞受体)和BCR一条链的序列信息,而单细胞免疫组库测序可以同时获取TCRα链和β链、BCR的重链和轻链以及一个细胞内的组合信息。
单细胞免疫组库测序技术是一种在单个细胞水平同时对适应性免疫受体库进行高通量测序的新技术,为免疫组学研究提供更具扩展性的平台。
传统的一些单细胞测序技术各有不足,例如,基于流式细胞仪的测序方法样本需求量大,需要精准控制,对细胞有损伤,对于后续建库要求高;基于C1系统(Fluidigm公司)的测序技术使用微阀分离单细胞,通量较低,最多只能做938个细胞,且成本高;基于Microwell(微孔板)方式的测序技术细胞捕获率低,污染高;基于现有的其他微流控平台的测序技术操作繁琐,时间长。
目前,单细胞免疫组库测序一般是基于10X Genomics平台进行的,其一次性能够分离500~10000个单细胞,并可以同时获取5’基因表达的数据和TCR/BCR的V(D)J全长序列。然而,10X Genomics平台在分离单细胞的个数上有局限性,且对细胞活性要求较高。同时,基于10X Genomics的单细胞免疫组库测序的价格昂贵。
发明内容
本发明的主要目的在于提供一种用于构建人单细胞BCR测序文库的试剂盒及其应用,从而克服现有技术的不足。
为了达到前述发明目的,本发明采用了以下方案:
本发明实施例提供了一种用于构建人单细胞BCR测序文库的试剂盒,其包括:
微流控芯片,至少用于捕获人源B细胞单细胞并进行包装,从而生成油包水反应液滴,所述油包水反应液滴包括油相和被油相包裹的细胞液相,并且所述油包水反应液滴中包含有RNA反转录组件和细胞裂解试剂;
用于形成所述油相的油、细胞裂解试剂;
细胞标签,包括可变形微珠和连接在可变形微珠上的分子标签,所述分子标签用于标识细胞;
RNA反转录组件,包含SEQ ID NO:17所示的反转录引物、RNA反转录酶、RNA反转录酶抑制剂和RNA反转录缓冲液;
cDNA预扩增组件,包含SEQ ID NO:18所示的cDNA预扩增引物、DNA聚合酶和扩增缓冲液;
第一扩增组件,包含SEQ ID NO:1~SEQ ID NO:8所示的引物、DNA聚合酶和扩增缓冲液;
第二扩增组件,包含SEQ ID NO:9~SEQ ID NO:16所示的引物、DNA聚合酶和扩增缓冲液;
转座片段化组件,包含转座酶、转座酶反应缓冲液和转座反应终止液;
第三扩增组件,包含两个测序接头、DNA聚合酶和扩增缓冲液。
本发明实施例还提供了一种人单细胞BCR测序文库的构建方法,其包括:
利用微流控芯片进行人源B细胞单细胞捕获并进行包装,从而生成包含单细胞的油包水反应液滴;
对所述油包水反应液滴中的细胞进行裂解、反转录,获得反转录产物;
对所述反转录产物进行预扩增,之后依次进行第一次扩增、第二次扩增,获得扩增产物;
对所述扩增产物进行片段化、扩增、纯化处理,生成测序文库;
其中,所述第一次扩增所用的引物组合物包含SEQ ID NO:1~SEQ ID NO:8所示的引物,所述第二次扩增所用的引物组合物包含SEQ ID NO:9~SEQ ID NO:16所示的引物。
在本发明前述实施例的一些实施方案中,所述微流控芯片包括细胞微流道、细胞隔离介质微流道、细胞标签微流道和单细胞样本收集口,所述细胞微流道具有细胞悬液入口和单细胞悬液出口,所述细胞隔离介质微流道具有细胞标签悬液入口和细胞标签悬液出口,并且所述单细胞悬液出口与细胞标签悬液出口交会,使所述细胞微流道输出的单细胞悬液能够与所述细胞标签微流道输出的细胞标签悬液混合形成细胞载液,所述细胞载液的流动路径与所述细胞隔离介质微流道交叉,从而使在所述细胞隔离介质微流道内流动的细胞隔离介质能够剪切并包裹细胞载液,从而形成包含单细胞的油包水反应液滴,所述包含单细胞的油包水反应液滴由单细胞样本收集口输出。
本发明实施例还提供了一种人源BCR测序方法,其包括:采用前述的任一种方法构建人单细胞BCR测序文库,之后进行测序分析。
较之现有技术,本发明利用微流控技术设计了一种人源单细胞BCR分离、测序文库的构建方法及试剂盒,其在应用于免疫细胞的免疫组库测序时,单次实验可以分离500-30000个细胞,从根本上解决了单细胞免疫组库的通量问题,在肿瘤微环境、感染性疾病、器官移植后排斥、免疫治疗等领域中有着广泛的应用前景。
附图说明
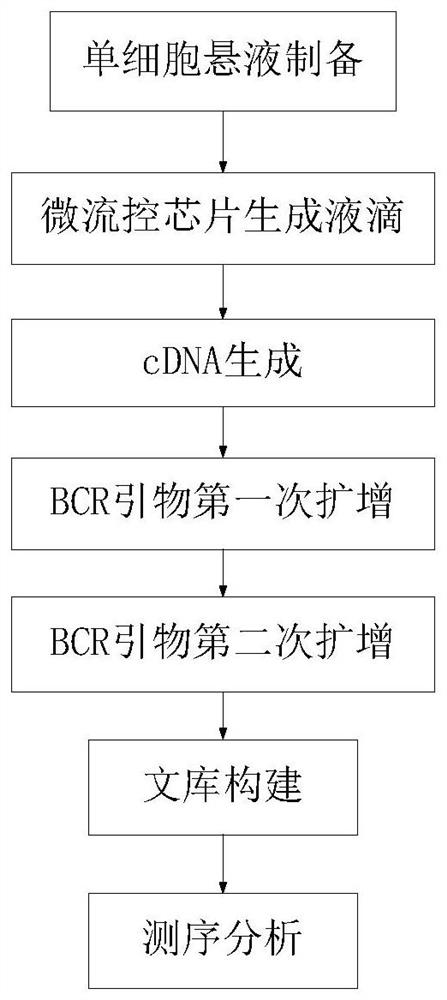
图1是本发明一典型实施方案中一种人源单细胞BCR测序文库的构建工艺流程图;
图2是本发明一典型实施方案中一种微流控芯片的结构示意图;
图3是本发明一具体实施案例中于微流控芯片中生成油包水反应液滴时的光学照片;
图4是本发明一具体实施案例中一种测序文库的质控结果图;
图5是本发明一具体实施案例中一种生物信息分析流程图;
图6是本发明一具体实施案例中的Clonotypes丰度图。
具体实施方式
本发明实施例的一个方面提供了一种用于构建人单细胞BCR测序文库的试剂盒,其包括:
微流控芯片,至少用于捕获人源B细胞单细胞并进行包装,从而生成油包水反应液滴,所述油包水反应液滴包括油相和被油相包裹的细胞液相,并且所述油包水反应液滴中包含有RNA反转录组件和细胞裂解试剂;
用于形成所述油相的油、细胞裂解试剂;
细胞标签,包括可变形微珠和连接在可变形微珠上的分子标签,所述分子标签用于标识细胞;
RNA反转录组件,包含SEQ ID NO:17所示的反转录引物、RNA反转录酶、RNA反转录酶抑制剂和RNA反转录缓冲液;
cDNA预扩增组件,包含SEQ ID NO:18所示的cDNA预扩增引物、DNA聚合酶和扩增缓冲液;
第一扩增组件,包含引物、DNA聚合酶和扩增缓冲液;
第二扩增组件,包含引物、DNA聚合酶和扩增缓冲液;
转座片段化组件,包含转座酶、转座酶反应缓冲液和转座反应终止液;
第三扩增组件,包含两个测序接头、DNA聚合酶和扩增缓冲液。
在一些实施方案中,所述微流控芯片包括细胞微流道、细胞隔离介质微流道、细胞标签微流道和单细胞样本收集口,所述细胞微流道具有细胞悬液入口和单细胞悬液出口,所述细胞隔离介质微流道具有细胞标签悬液入口和细胞标签悬液出口,并且所述单细胞悬液出口与细胞标签悬液出口交会,使所述细胞微流道输出的单细胞悬液能够与所述细胞标签微流道输出的细胞标签悬液混合形成细胞载液,所述细胞载液的流动路径与所述细胞隔离介质微流道交叉,从而使在所述细胞隔离介质微流道内流动的细胞隔离介质能够剪切并包裹细胞载液,从而形成包含单细胞的油包水反应液滴,所述包含单细胞的油包水反应液滴由单细胞样本收集口输出。
当然,还可以在所述单细胞悬液出口和细胞标签悬液出口的交会处与细胞隔离介质微流道之间设置供细胞载液流动的一个过渡段,其可以命名为细胞载液微流道(参阅图2中的附图标记13),该细胞载液微流道与细胞隔离介质微流道交叉。
进一步的,所述细胞微流道的尾部区域设置为单细胞通道,所述单细胞通道的宽度等于或稍大于单细胞直径,所述单细胞通道的出口与细胞标签微流道的出口交会,使得从所述细胞微流道输出的单细胞悬液与从所述细胞标签微流道输出的细胞标签悬液混合形成细胞载液,所述细胞载液的连续流动路径与所述细胞隔离介质微流道交叉,使得流经所述细胞隔离介质微流道的细胞隔离介质能够将连续的细胞载液剪切为离散液滴状的细胞液相并使每一细胞液相包含单细胞和单个细胞标签,同时使所述细胞隔离介质作为油相对所述细胞液相进行包裹,从而形成所述油包水反应液滴。
进一步的,所述油包水反应液滴是作为油包水微反应器,其大小可以是皮升级的。
进一步的,所述微流控芯片还包括分别与所述细胞微流道、细胞隔离介质微流道、细胞标签微流道连通的细胞悬液加样杯、细胞隔离介质加样杯、细胞标签加样杯。
在一些实施方案中,所述单细胞样本收集口处设置有负压动力生成装置。所述负压动力生成装置可以采用空气泵等,其可以在微流控芯片内产生负压,从而驱使各微流道中的流体流动。例如,可以在单细胞样本收集口处用空气泵向外抽取空气,给微流控芯片整体施加-4K~-10K Pa的负压。通过采用此种负压方式,且设置芯片为3通道,不需要用动力驱使,相比现有技术中的正压驱动、多通道(4通道以上),操作更方便,时间也大大缩短,可以做微量样本,灵活性更高,可以同时做1到8个样本。
进一步的,前述实施方案中的一种微流控芯片的结构可以参阅图2所示,包括细胞悬液加样杯1、细胞标签加样杯2、细胞隔离介质加样杯4,该细胞悬液加样杯1、细胞标签加样杯2、细胞隔离介质加样杯4分别与细胞微流道11、细胞标签微流道12、细胞隔离介质微流道14连通,同时所述微流控芯片还设有单细胞样本收集口3。其中,细胞微流道11、细胞标签微流道12相互交叉后,还与细胞隔离介质微流道14交叉,进而与单细胞样本收集口3连通。
在本发明的以上实施例中,微流控芯片的细胞微流道为用于形成细胞液相的一个组分的细胞悬液的流动通道,细胞标签通道为用于形成细胞液相的另一个组分的细胞标签悬液的流动通道,细胞隔离介质微流道为作为油相的组份的流动通道,所有组份均在芯片上增加压力的情况下,随其流动通道按一定速度流动,且细胞悬液和细胞标签悬液混合形成的细胞载液并被作为油相的细胞隔离介质切割,形成物理隔离,通过控制压力和流阻设计,实现细胞隔离介质对单个细胞和细胞标签进行切割,实现了单个细胞和凝胶微珠的分离,确保每个油包水反应液滴作为一个微反应体系且包含一个细胞和一个细胞标签。
在一些实施方案中,所述油相包含油和细胞裂解试剂,所述细胞液相包含RNA反转录组件。
在一些实施方案中,所述油与细胞裂解试剂的体积比为100:1~500:1,例如可以为100:1、200:1、300:1、500:1等,但不限于此。
进一步的,所述分子标签还包含用于标识细胞的条形码。
更进一步的,所述条形码的长度可以为4-30nt,但不仅限于此的碱基序列及一定顺序排列组合。
更进一步的,所述条形码可以包含3段但不仅限于3段的恒定碱基序列。
更进一步的,所述条形码可以包含3nt的但不仅限于3nt的riboG碱基。
更进一步的,所述分子标签总长度可以为50nt-200nt不等,且不限于此。
在一些实施方案中,所述分子标签可以通过化学和/或物理方式与微球连接。例如,所述分子标签与微珠可以通过共价键、化学聚合、抗原抗体结合、酶催化的连接反应等方式进行连接,且不限于此。
在一些实施方案中,所述分子标签能够在物理和/或化学作用下与所述可变形微珠分离。进一步的,所述物理和/或化学作用包括光照、特异性酶切等,且不限于此。
例如,作为所述分子标签的寡核酸链可以标记为紫外敏感、光照敏感或者可以被特异性酶切的,且不限于此。在本发明中优选采用紫外光照等方式使分子标签脱离可变形微珠,其不仅非常便捷,而且还不会向微反应体系内引入其它化学物质,从而可以避免潜在的污染风险,另外,游离的分子标签捕获目的产物效率更高,可以消除固定在微珠上的引物捕获目的产物时因微珠的空间位阻效应而导致的捕获效率低等问题。
在一些实施方案中,所述可变形微珠可以是有机材质或者无机-有机复合材质的,例如可以为聚丙烯酰胺凝胶微珠、琼脂糖凝胶微珠、琼脂糖包裹的磁性微珠、硅珠、惰性材料制备的微珠等,且不限于此。优选的,所述可变形微珠可以选用凝胶微珠(例如水凝胶微球),其有利于进一步提高所述微流控芯片进行油包水反应液滴包装的效率,以及协同微流控芯片而大幅提升细胞通量。前述的这些微珠可以从市场购得或者依照已知文献自制。进一步的,在本发明中优选采用多孔的聚丙烯酰胺微珠,因其具有远大于其它微珠,例如树脂或磁性微珠等硬微珠的比表面积,故所携带的引物远远多于其它微珠。合成所述聚丙烯酰胺微珠时,使用的丙烯酰胺单体浓度可以为1%-10%。
在一些实施方案中,所述微珠的直径可以为10μM-200μM。
在本发明的前述实施例中,利用所述微流控芯片,在相同浓度细胞的情况下,单口双包率是双口的1/2,不同细胞大小可以通过调整压力(例如,以负压动力生成装置产生的压力作为动力)来实现包裹,特别是在利用负压动力生成装置作为动力源时,还可以快速高效地完成细胞包裹,以及,利用凝胶微珠形成细胞标签时,其悬液流速有冲击力,流速可控,可以实现90%以上的包裹率。
以及,在本发明的前述实施例中,通过微流控芯片技术可以实现皮升级的油包水微反应器,相较于现有技术中在96孔板中进行分离等方式,在相同数量的反转录组份的情况下,可以检测数量更多的细胞,极大地降低的单个细胞的检测成本,并且通过增加了负载在凝胶微珠上的分子标签,还可实现多达30000个细胞的分离和检测。
在本发明的前述实施例中,所述单细胞裂解组件可以选用本领域技术人员所熟知的细胞裂解试剂,其包含本领域技术人员所熟知的任何适用于细胞裂解的蛋白酶和蛋白变性试剂以及裂解缓冲体系。
在本发明的前述实施例中,所述RNA反转录组件包含RNA反转录引物和本领域技术人员所熟知的RNA反转录酶、RNA反转录酶抑制剂和RNA反转录缓冲液等。其中,所述RNA反转录引物的序列如SEQ ID NO:17所示。
例如,所述反转录酶可以包括M-MLV反转录酶,其是一种RNA模板依赖性DNA聚合酶。
例如,所述反转录缓冲液的主要成分可以为Tris-HCl、KCl、MgCl
本发明通过采用模版转换方式在油包水反应液滴内进行逆转录反应,同时在液滴外结合转座酶建库的方式,逆转录整体流程耗时小于8小时,而与之形成鲜明对比的是,现有技术中所采用的体外转录方式耗时一般都超过30小时。并且,本发明采用的逆转录反应方式,还可避免在液滴外进行逆转录而导致的交叉污染,有效降低双包率,减少假阳性结果。以及,还利于简化后续的建库操作,例如,无需采用操作复杂且耗时的末端加A建库方式。
本发明中所述破乳处理优选采用超声等物理破乳方式,避免化学破乳方式存在的化学组分如PFO对后续反应的影响。
在本发明的前述实施例中,所述cDNA预扩增组件包含cDNA预扩增引物和本领域技术人员所熟知的DNA聚合酶和扩增缓冲液。例如,所述扩增缓冲液即cDNA预扩增反应液的主要成分可以包括:KCl、NH
其中,所述cDNA预扩增引物的序列如SEQ ID NO:18所示。
在本发明的前述实施例中,所述第一扩增组件包含SEQ ID NO:1~SEQ ID NO:8所示的引物和本领域技术人员所熟知的DNA聚合酶及扩增缓冲液。
在本发明的前述实施例中,所述第二扩增组件包含SEQ ID NO:9~SEQ ID NO:16所示的引物和本领域技术人员所熟知的DNA聚合酶及扩增缓冲液。
进一步的,所述第一扩增组件、第二扩增组件所含的均是多种引物的混合物,其中任一种引物的使用浓度优选为0.1~0.5μmol/L。所述第一扩增组件、第二扩增组件中采用的多种引物的组合是从众多引物序列及其组合中特别筛选的,其保障了非常高的扩增效率。
在本发明的前述实施例中,所述DNA聚合酶可以是本领域技术人员所熟知的任何热稳定的DNA聚合酶,例如:LA-Taq,rTaq,Phusion,Deep Vent,Deep Vent(exo-),Gold360,Platinum Taq,KAPA 2G Robust等,且不限于此。
在本发明的前述实施例中,所述转座片段化组件可以包含本领域技术人员所熟知的转座酶、转座酶反应缓冲液和转座反应终止液。例如,所述转座酶可以选用Tn5等,且不限于此。
本发明实施例的另一个方面提供了一种人单细胞BCR测序文库的构建方法。概括的讲,该方法包括利用微流控芯片进行单细胞及细胞标签的包裹,使单细胞被唯一类型的细胞标签所捕获的步骤,进而进行单个细胞的裂解,唯一细胞标签的加载,RNA反转录和cDNA预扩增,实现对低浓度cDNA的富集,之后通过BCR特异性一次扩增,实现对BCR的特异性富集,继而通过BCR特异性二次扩增,避免第一次富集的特异性不够,进行第二次特异性富集,然后进行转座酶片段化、扩增、纯化等步骤。
详细的讲,参阅图1所示,在本发明的一些实施方案中,所述的构建方法可以包括:
利用微流控芯片进行人源B细胞单细胞捕获并进行包装,从而生成包含单细胞的油包水反应液滴;
对所述油包水反应液滴中的单细胞进行裂解、反转录,获得反转录产物;
对所述反转录产物进行预扩增,之后依次进行第一次扩增、第二次扩增,获得扩增产物;
对所述扩增产物进行片段化、扩增、纯化处理,生成测序文库;
其中,所述第一次扩增所用的引物组合物包含SEQ ID NO:1~SEQ ID NO:8所示的引物,所述第二次扩增所用的引物组合物包含SEQ ID NO:9~SEQ ID NO:16所示的引物。
在一些实施方案中,所述的构建方法具体包括:
提供前述实施例中的任一种试剂盒;
将细胞悬液、细胞标签悬液、细胞隔离介质分别注入微流控芯片,并使细胞悬液、细胞标签悬液在分别流经细胞微流道、细胞标签微流道后相互混合形成细胞载液,且使所述细胞载液被在细胞隔离介质微流道内流动的细胞隔离介质剪切、包裹,从而形成包含单细胞和单个细胞标签的油包水反应液滴;
以及,从单细胞样本收集口处收集包含单细胞的油包水反应液滴。
在一些实施方式中,所述的构建方法具体包括:通过负压动力生成装置驱使细胞悬液、细胞标签悬液、细胞载液、细胞隔离介质在微流控芯片内连续流动,并使形成的油包水反应液滴从单细胞样本收集口输出。
在一些实施方案中,所述油包水反应液滴还包含单细胞裂解组件和RNA反转录组件,所述单细胞裂解组件包含用于对单细胞进行裂解的裂解酶和裂解缓冲液。
其中,所述单细胞裂解组件、RNA反转录组件的组成可以如上文所述,此处不再赘述。
在一些实施方案中,所述油包水反应液滴还包含单个细胞标签。所述细胞标签可以包括固定连接在微球等固相载体上的分子标签。关于所述细胞标签,其详见上文。
在一些实施方案中,所述的构建方法还可以包括:在所述的反转录完成后,对所述油包水反应液滴进行破乳处理,之后进行纯化处理,再对纯化后的反转录产物进行预扩增。
在一些实施方案中,所述的构建方法具体包括:选择转座酶建库方式,使用Tn5对第二次扩增产物进行随机打断建库,加入文库构建接头。
更具体的,可以采用Tn5转座酶进行所述的片段化处理,之后对所获片段化产物进行扩增,其中所采用的一个测序接头引物如SEQ ID NO:19所示,另一个测序接头引物的序列可以参考下文。
在一些实施方案中,所述的构建方法还可以包括对“待测样本”或“待测样品”进行前处理的步骤。但是,应用本发明实施例提供的方法,对前处理的要求较低,例如,可以根据人源B细胞的物理特性进行初步富集,或根据人源B细胞的生物特性进行初步富集,所获得的含有人源B细胞的样本即可用于后续步骤。本发明的方法中,这种初步的富集允许样品中仍包含一定量的人源B细胞以外的其他细胞。
在本说明书中,“待测样本”或“待测样品”是指包含人源B细胞的物质,其可以来自于个体(如人的血液、生物组织等),也可以是其它来源的,例如一些经处理或未经处理的实验室材料。另外,在本说明书中,对于“样本”或“样品”的检测并非仅涉及诊断目的,还可涉及其它非诊断目的。本发明允许样品中包含一定量的其他类型细胞,对检测结果没有影响。
本发明实施例的另一个方面还提供了一种人源BCR测序方法,其可以包括:
利用前述的方法构建人源单细胞BCR测序文库;以及
进行测序分析。
进一步的,所述测序分析亦可以是依照本领域技术人员熟知的方式操作。例如可以参考图4,其可以包括基本分析、标准分析和高级分析。例如可以进行人源B细胞BCR CDR3受体库的测序分析,等等。
本发明前述实施例提供的人源单细胞BCR测序文库构建方法及试剂盒可以应用于免疫细胞的免疫组库测序,单次实验可以分离500-30000个细胞,从根本上解决了单细胞免疫组库的通量问题,并且还具有操作简便、成本低廉(是基于dropseq、10X等平台的测序方式的三分之一以下)、测序结果准确性高等优点,在多个领域具有广阔应用前景。
下面结合具体实施例进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。若非特别说明,则下列实施例中使用的各种试剂均是本领域技术人员熟知的,并可以通过市场购买等途径获取。而下列实施例中未注明具体条件的实验方法,通常按照常规条件如J.萨姆布鲁克等编著,分子克隆实验指南,第三版,科学出版社,2002中所述的条件,或按照制造厂商所建议的条件。
如下实施例所使用的一种用于构建人单细胞BCR测序文库的试剂盒包含有单细胞免疫组库文库构建所需的试剂及耗材,例如:具有单细胞分离和油包水反应液滴生成功能的微流控芯片;生成所述反应液滴所需的油l;细胞标签(包括水凝胶微珠和连接在水凝胶微珠上的分子标签);RNA反转录酶;RNA反转录缓冲液;无核酸酶水;Taq聚合酶反应液;BCR引物混合物I(SEQ ID NO:1~SEQ ID NO:8,其中每种引物的浓度为0.1-0.5μM);BCR引物混合物II(SEQ ID NO:9~SEQ ID NO:16,其中每种引物的浓度为0.1-0.5μM);含有恒定序列的polyT寡核苷酸(SEQ ID NO:17,其中TACACGACGCTCTTCAGA为恒定区域);cDNA扩增反应缓冲液;cDNA扩增引物混合物;cDNA扩增酶;转座酶反应缓冲液;转座酶;转座反应终止液;用于双链DNA纯化的磁珠;用于文库扩增的接头,等等,且不限于此。若非特别说明,前述这些试剂均可以从市场购得。例如,如下实施例所用的纯化磁珠可以优选为Beckman公司的Ampure XP beads、Beckman公司的SPRI beads等,且不限于此。
1.实验准备
1.1油相(细胞隔离介质)(详见表1)
表1油相组分
1.2细胞悬液(详见表2)
表2细胞悬液组分
注:细胞相细胞使用荧光细胞分析仪检测出浓度和活性后,根据实验需要计算出所需体积。
1.3细胞标签悬液(详见表3)
表3细胞标签相组分
构成该细胞标签的凝胶微珠可以选自直径为10μM-200μM的聚丙烯酰胺凝胶微珠、琼脂糖凝胶微珠等,连接于凝胶微珠上的分子标签为紫外敏感的寡核酸链,其长度可以为50nt-200nt,其中包含长度为4-30nt左右的分子条形码,该分子条形码可以包含3段或更多恒定碱基序列,以及该分子条形码可以包含3nt或更多的riboG碱基。例如,分子标签序列结构可以为:5’-TACACGACGCTCTTCCGATCT-(4-30nt碱基条形码序列)-GTGATTGCTTGTGAC(也可为其他序列,恒定序列)–(4-30nt碱基条形码序列)CGACTCACACTACACGC(也可为其他序列,恒定序列)-(4-30nt碱基条形码序列)-NNNNNNNNN-rGrGrG-3’。其中N所示片段可以是随机序列。其中条码序列可以是本领域熟知的。
二.实验操作及结果展示
2.1细胞准备
2.1.1根据处理样本数量的需求取适量PBS溶液提前半小时放入水浴锅中预热,取适量PBS溶液提前半小时放入冰上预冷。
2.1.2对于新鲜培养的细胞/分离的组织:收集新鲜培养细胞/组织,酶消化获取单细胞,常温300g离心5min。
对于在细胞冻存液中冻存的细胞:水浴锅提前预热到37℃,取出冻存细胞,将冻存细胞在37℃水浴锅内1min内融化,然后收取细胞至离心管,常温300g离心5min。
2.1.3油包水:将细胞悬液、细胞标签悬液分别注入细胞加样杯、细胞标签加样杯,并使细胞悬液、细胞标签悬液在分别流经细胞微流道、细胞标签微流道后相互混合形成细胞载液;
向细胞隔离介质加样杯注入细胞隔离介质,并使细胞隔离介质在流经细胞隔离介质微流道后与细胞载液接触,并通过剪切作用将细胞载液由连续液相分散隔离为分散液相,形成包含单细胞的油包水反应液滴。
该油包水步骤可以基于图2所示的微流控芯片实施,其中产生油包水反应液滴的过程如图3所示。
2.1.4收集产生的油包水反转录体系到0.2mL离心管中,加入PCR仪运行42℃90min反应;
2.1.5向上述0.2mL离心管RT产物中加入PFO进行破乳,离心使水油分层,吸取水相;
2.1.6水相中加入0.6X的Beckman Ampure XP Beads纯化;
2.17纯化产物按照如下条件进行PCR预扩增
其中,cDNA预扩增引物的序列如SEQ ID NO:18所示
2.18扩增后产物用0.8X bead纯化;纯化产物用TCR引物混合物I进行扩增
扩增循环数:
其中X的取值范围为9-13。
2.19BCR引物混合物I扩增产物采用0.8Xbeads纯化,纯化产物用TCR引物混合物II进行扩增
扩增循环参数:
其中Y的取值范围为9-13。
2.20BCR引物混合物II的扩增产物用0.5X-0.8X beads进行片段筛选,得到的筛选产物进行建库
2.21采用转座酶Tn5打断建库
其中X的取值可以依据扩增产物浓度相应调整,Y可以依据扩增产物的加入量相应调整。
2.22转座酶打断温度条件
2.23终止片段化反应
反应结束后,加入10μL 1%的SDS溶液,吹吸混匀,室温孵育5min。
2.24分别用文库扩增引物进行PCR扩增
其中,接头1为通用接头,其序列如下:
AATGATACGGCGACCACCGAGATCTACACTCTTTCCCTACACGACGCTCTTCCGATCT
接头2包含了用于文库拆分的index,其序列如下:
CAAGCAGAAGACGGCATACGAGATNNNNNNNNGTGACTGGAGTTCAGACGTGT
其中NNNNNNNN为条形码。N所示可以为随机序列。
2.25文库构建热循环参数
2.26文库扩增产物用0.6X-0.75X beads进行片段筛选。其质控结果如图4。
3.测序分析
该测序流程可以在Illumina Nova Seq、Illumina Hiseq、Illumina Nextseq 500以及Illumina Miseq等平台上进行,相应操作方法及实验条件均是本领域技术人员熟知的。
具体分析流程见图5,包括对于测序原始数据首先通过质控得到clean data,然后进行数据的比对、筛选、注释等分析。统计质控信息、比对信息及注释信息,首先将cleandata与已知的V(D)J参考库进行比对,保留至少有20bp比对到该区段的配对reads。然后利用UMI进行筛选,如果400条配对reads支持该UMI则为有效UMI,保留有效UMI。对每个细胞进行Contig的拼接,注释Barcode并筛选去除非细胞序列,对Contig进行注释分析,对于注释后的contig进行筛选,对过滤后的Contig进一步拼接,得到样本VDJ支持的Consensus序列(一致序列),根据拼接得到的样本一致序列的VDJ氨基酸序列进行Clonotype分型,结果请参阅图6。
对BCR应用CDR3区氨基酸序列进行克隆亚型分型。其有效Barcode即为该亚型分型丰度,用于进行丰度分析。结果可通过Loupe V(D)J Browser进行查看导出。
利用与本发明实施例相同的细胞样本,并按照本领域技术人员已知的方式,基于10X Genomics平台进行对照的测序试验,将所获测序结果与本发明实施例的测序结果比对,可以发现,利用本发明实施例的方法,所获测序结果准确、灵敏度高,且效率、成本等均远远优于基于10X Genomics平台的测序方案。
在本发明提及的所有文献都在本申请中引用作为参考,就如同每一篇文献被单独引用作为参考那样。此外应理解,在阅读了本发明的上述讲授内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
序列表
<110> 苏州绘真生物科技有限公司
<120> 用于构建人单细胞BCR测序文库的试剂盒及其应用
<160> 19
<170> SIPOSequenceListing 1.0
<210> 1
<211> 22
<212> DNA
<213> 人工序列(人工序列)
<400> 1
gtgacctgga gcgaaagcgg ac 22
<210> 2
<211> 22
<212> DNA
<213> 人工序列(人工序列)
<400> 2
cttcccgctg agcctcgaca gc 22
<210> 3
<211> 22
<212> DNA
<213> 人工序列(人工序列)
<400> 3
cagctactac atgacaagca gc 22
<210> 4
<211> 25
<212> DNA
<213> 人工序列(人工序列)
<400> 4
acccaaagga taacagccct gtggt 25
<210> 5
<211> 26
<212> DNA
<213> 人工序列(人工序列)
<400> 5
ttccccttga cccgctgctg caaaaa 26
<210> 6
<211> 23
<212> DNA
<213> 人工序列(人工序列)
<400> 6
gccagcgcag ggagggaggg tgt 23
<210> 7
<211> 26
<212> DNA
<213> 人工序列(人工序列)
<400> 7
agcgtggccg ttggctgcct cgcaca 26
<210> 8
<211> 22
<212> DNA
<213> 人工序列(人工序列)
<400> 8
cgtggtgtgc aaagtccagc ac 22
<210> 9
<211> 21
<212> DNA
<213> 人工序列(人工序列)
<400> 9
tgtgaggtgg ctgcgtactt g 21
<210> 10
<211> 19
<212> DNA
<213> 人工序列(人工序列)
<400> 10
aggacagccg ggaaggtgt 19
<210> 11
<211> 21
<212> DNA
<213> 人工序列(人工序列)
<400> 11
cacgcatttg tactcgcctt g 21
<210> 12
<211> 21
<212> DNA
<213> 人工序列(人工序列)
<400> 12
ctggctrggt gggaagtttc t 21
<210> 13
<211> 20
<212> DNA
<213> 人工序列(人工序列)
<400> 13
ggtggcatag tgaccagaga 20
<210> 14
<211> 22
<212> DNA
<213> 人工序列(人工序列)
<400> 14
tattcagcag gcacacaaca ga 22
<210> 15
<211> 20
<212> DNA
<213> 人工序列(人工序列)
<400> 15
agtgtggcct tgttggcttg 20
<210> 16
<211> 21
<212> DNA
<213> 人工序列(人工序列)
<400> 16
tgtgaggtgg ctgcgtactt g 21
<210> 17
<211> 51
<212> DNA
<213> 人工序列(人工序列)
<400> 17
tacacgacgc tcttcagatc tttttttttt tttttttttt tttttttttt t 51
<210> 18
<211> 21
<212> DNA
<213> 人工序列(人工序列)
<400> 18
tacacgacgc tcttcagatc t 21
<210> 19
<211> 58
<212> DNA
<213> 人工序列(人工序列)
<400> 19
aatgatacgg cgaccaccga gatctacact ctttccctac acgacgctct tccgatct 58