离子浓度依赖性结合分子文库
文献发布时间:2023-06-19 11:42:32
本申请是国际申请号PCT/JP2012/006254,国际申请日2012年9月28日,中国申请号201280058080.5,发明名称为“离子浓度依赖性结合分子文库”的专利申请的分案申请。
技术领域
相关申请
本申请基于日本专利申请2011-218006(2011年9月30日申请)及2012-123479(2012年5月30日申请)主张优先权,日本专利申请2011-218006及2012-123479的内容作为参考并入本说明书中。
发明的领域
本发明涉及针对抗原的结合活性根据离子浓度的条件而变化的抗原结合分子的文库及其制造方法、此类抗原结合分子的选择方法及制造方法、以及包含此类抗原结合分子的医药组合物。
背景技术
抗体在血浆中的稳定性高、副作用少,因此作为医药品备受关注。其中IgG型的抗体医药有多种已上市,现在还在开发多种抗体医药(非专利文献1、非专利文献2)。另一方面,作为可适用于第二代抗体医药的技术,已开发了各种各样的技术,报道了提高效应器功能、抗原结合能力、药物动力学、稳定性、或降低免疫原性风险的技术等(非专利文献3)。因为抗体医药通常给药量非常高,所以认为存在难于制作皮下给药制剂、制造成本高等问题。作为降低抗体医药的给药量的方法,考虑了提高抗体的药物动力学的方法和提高抗体与抗原的亲和性(affinity)的方法。
作为使抗体的药物动力学提高的方法,报道了恒定区的人工氨基酸取代(非专利文献4、5)。作为增强抗原结合能力、抗原中和能力的技术,已报道了亲和性成熟化技术(非专利文献6),通过对可变区的CDR区等的氨基酸导入突变,能够增强对抗原的结合活性。通过增强抗原结合能力,可以提高体外的生物活性、或降低给药量,还可进一步提高体内的药效(非专利文献7)。
另一方面,每个抗体分子能中和的抗原量依赖于亲和性,通过增强亲和性,能够以较少的抗体量来中和抗原,可通过各种各样的方法增强抗体的亲和性(非专利文献6)。进而,如果能够与抗原以共价键结合、使得亲和性无限大的话,则能够以一分子的抗体中和一分子的抗原(2价的情况下为2个抗原)。但是,迄今为止的方法中,以一分子的抗体中和一分子的抗原(2价的情况下为2个抗原)的化学计量上的中和反应为界限,不可能以抗原量以下的抗体量完全中和抗原。即,增强亲和性的效果存在界限(非专利文献9)。中和抗体的情况下,为了使其中和效果持续一定时间,必须要给予该时间内生物体内产生的抗原量以上的抗体量,而仅通过上述的提高抗体药物动力学或者亲和性成熟化技术,对于必需抗体给药量的降低存在界限。因此,为了在目标时间内以抗原量以下的抗体量保持抗原中和效果,需要以一个抗体中和多个抗原。
作为达成此目的的新方法,最近报道了对抗原以pH依赖性方式结合的抗体(专利文献1)。该文献公开了,通过在抗原结合分子中导入组氨酸而在pH中性区域和pH酸性区域性质变化的pH依赖性抗原结合抗体。对于在血浆中的中性条件下对抗原强结合、在核内体内的酸性条件下从抗原离解的pH依赖性抗原结合抗体,能够在核内体内从抗原离解。pH依赖性抗原结合抗体在离解抗原后,抗体可通过FcRn再循环进血浆中,再度与抗原结合,因此,能够以一个抗体与多个抗原重复结合。
此外,抗原的血浆滞留性较之结合至FcRn并被再循环的抗体而言非常短。血浆滞留性长的抗体与这类血浆滞留性短的抗原结合的话,抗体抗原复合体的血浆滞留性将变得与抗体同样长。因此,抗原通过与抗体结合,血浆滞留性变长,而且血浆中抗原浓度上升。这种情况下,即使提高抗体对抗原的亲和性,也不能促进抗原从血浆中消失。有报道称,较之通常的抗体而言,上述pH依赖性的抗原结合抗体作为促进抗原从血浆中消失的方法是有效的(专利文献1)。
如上所述,pH依赖性抗原结合抗体以一个抗体与多个抗原结合,较之通常抗体而言能够促进抗原从血浆中消失,因此具有以通常的抗体无法获得的作用。通过对现有的抗体序列进行取代,能够赋予针对抗原的pH依赖性结合活性。另一方面,通常认为,为了新获得这样的抗体,在从免疫动物获得抗体的方法或从人抗体文库获得抗体的方法中有下述限制。
免疫非人动物的方法中,虽然存在获得pH依赖性结合抗体的可能性,但是有时难于在短期内获得针对多种抗原的pH依赖性抗原结合抗体、或者选择性获得特异性地结合至特定表位的抗体。此外,可以以pH依赖性的针对抗原的结合能力作为指标,从人抗体文库中浓缩抗体。但是,一般而言,对于(Kabat数据中所登记的)人抗体的抗体可变区部分中组氨酸残基的出现频率,已知重链CDR1中为5.9%,重链CDR2中为1.4%,重链CDR3中为1.6%,轻链CDR1中为1.5%,轻链CDR2中为0.5%,轻链CDR3中为2.2%,均不高,认为人抗体文库中可具有pH依赖性的抗原结合能力的序列非常少。因此,希望提供下述抗体文库,其中含有较多的可具有pH依赖性的针对抗原的结合能力的序列,所述序列与抗原的结合部位中组氨酸出现频率被提高。
另一方面认为,如果能够向针对抗原的结合能力赋予对除pH以外的、血浆中与早期核内体内的环境间不同的要素的依赖性,就能达成促进抗原从血浆中消失等的效果。
需要说明的是,本发明的现有技术文献如下所示。
[专利文献1]WO2009125825
[非专利文献1]Janice M Reichert,Clark J Rosensweig,Laura B Faden&Matthew C Dewitz,Monoclonal antibody successes in the clinic,Nat.Biotechnol.(2005)23,1073-1078
[非专利文献2]Pavlou AK,Belsey MJ.,The therapeutic antibodies marketto 2008,Eur J Pharm Biopharm.(2005)59(3),389-396.
[非专利文献3]Kim SJ,Park Y,Hong HJ.,Antibody engineering for thedevelopment of therapeutic antibodies.,Mol Cells.(2005)20(1),17-29
[非专利文献4]Hinton PR,Xiong JM,Johlfs MG,Tang MT,Keller S,TsurushitaN.,An engineered human IgG1 antibody with longer serum half-life,J Immunol.(2006)176(1),346-356
[非专利文献5]Ghetie V,Popov S,Borvak J,Radu C,Matesoi D,Medesan C,Ober RJ,Ward ES.,Increasing the serum persistence of an IgG fragment byrandom mutagenesis,Nat.Biotechnol.(1997)15(7),637-640
[非专利文献6]Rajpal A,Beyaz N,Haber L,Cappuccilli G,Yee H,Bhatt RR,Takeuchi T,Lerner RA,Crea R.,A general method for greatly improving theaffinity of antibodies by using combinatorial libraries,Proc.Natl.Acad.Sci.USA.(2005)102(24),8466-8471
[非专利文献7]Wu H,Pfarr DS,Johnson S,Brewah YA,Woods RM,Patel NK,White WI,Young JF,Kiener PA.Development of Motavizumab,an Ultra-potentAntibody for the Prevention of Respiratory Syncytial Virus Infection in theUpper and Lower Respiratory Tract,J.Mol.Biol.(2007)368,652-665
[非专利文献8]Hanson CV,Nishiyama Y,Paul S.Catalytic antibodies andtheir applications.Curr Opin Biotechnol,(2005)16(6),631-6
[非专利文献9]Rathanaswami P,Roalstad S,Roskos L,Su QJ,Lackie S,Babcook J.Demonstration of an in vivo generated sub-picomolar affinity fullyhuman monoclonal antibody to interleukin-8,Biochem.Biophys.Res.Commun.(2005)334(4),1004-13.
发明内容
本发明是考虑到上述状况而做出的,本发明的目的是提供:主要由互相之间序列不同的多个抗原结合分子构成的文库,所述抗原结合分子的抗原结合结构域中包含至少一个下述氨基酸残基,所述氨基酸残基使得抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化,以及提供包含多个编码所述抗原结合分子的多核苷酸分子的组合物、包含多个含有所述多核苷酸分子的载体的组合物、所述抗原结合分子的选择方法、所述多核苷酸分子的分离方法、所述抗原结合分子的制造方法、包含所述抗原结合分子的医药组合物。
本发明的发明人等对下述文库进行了锐意研究,所述文库包含互相之间序列不同的多个抗原结合分子,所述抗原结合分子的抗原结合结构域中包含至少一个下述氨基酸残基,所述氨基酸残基使得抗原结合分子针对抗原的结合活性根据生物体内环境要素的不同而变化。结果,本发明的发明人等发现,通过关注血浆中与早期核内体内的离子浓度(特别是钙离子浓度)的差异和pH,使用具有钙依赖性或pH依赖性的具有针对抗原的结合活性的抗原结合分子,能够制作主要由下述抗原结合分子构成的文库,通过所述抗原结合分子可促进抗原向细胞内的掺入、减少血浆中的抗原浓度。
即,本发明涉及主要由互相之间序列不同的多个抗原结合分子构成的文库,所述抗原结合分子的抗原结合结构域中包含至少一个下述氨基酸残基,所述氨基酸残基使得抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化,还涉及包含多个编码所述抗原结合分子的多核苷酸分子的组合物、包含多个含有所述多核苷酸分子的载体的组合物、所述抗原结合分子的选择方法、所述多核苷酸分子的分离方法、所述抗原结合分子的制造方法、包含所述抗原结合分子的医药组合物。更具体而言,涉及以下这些。本发明提供了:
(1)一种文库,主要由互相之间序列不同的多个抗原结合分子构成,其特征在于,所述抗原结合分子中的抗原结合结构域包含至少一个下述氨基酸残基,所述氨基酸残基使得抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化。
(2)如(1)所述的文库,其中,离子浓度为钙离子浓度。
(3)如(2)所述的文库,其中,所述氨基酸残基被包含在所述抗原结合分子的重链的抗原结合结构域中。
(4)如(3)所述的文库,其中,重链的抗原结合结构域为重链可变区。
(5)如(4)所述的文库,其中,所述氨基酸残基被包含在重链可变区的CDR3中。
(6)如(2)~(5)中任一项所述的文库,其中,所述氨基酸残基被包含于重链CDR3的以Kabat编号法表示的第95位、96位、100a位和/或101位处。
(7)如(2)~(6)中任一项所述的文库,其中,所述氨基酸残基以外的氨基酸序列包含天然序列的氨基酸序列。
(8)如(3)~(7)中任一项所述的文库,其中,所述抗原结合分子的轻链可变区包含天然序列的氨基酸序列。
(9)如(2)所述的文库,其中,所述氨基酸残基被包含在所述抗原结合分子的轻链的抗原结合结构域中。
(10)如(9)所述的文库,其中,轻链的抗原结合结构域为轻链可变区。
(11)如(10)所述的文库,其中,所述氨基酸残基被包含在轻链可变区的CDR1中。
(12)如(11)所述的文库,其中,所述氨基酸残基被包含于CDR1的以Kabat编号法表示的第30位、31位和/或32位处。
(13)如(10)~(12)中任一项所述的文库,其中,所述氨基酸残基被包含在轻链可变区的CDR2中。
(14)如(13)所述的文库,其中,所述氨基酸残基被包含于轻链的CDR2的以Kabat编号法表示的第50位处。
(15)如(10)~(14)中任一项所述的文库,其中,所述氨基酸残基为轻链的CDR3。
(16)如(15)所述的文库,其中,所述氨基酸残基被包含于轻链的CDR3的以Kabat编号法表示的第92位处。
(17)如(2)或(9)~(16)中任一项所述的文库,其中,所述抗原结合分子的轻链的框架包含生殖细胞系(germline)的框架序列。
(18)如(2)或(9)~(17)中任一项所述的文库,其中,所述抗原结合分子的重链可变区包含天然序列的氨基酸序列。
(19)如(1)~(18)中任一项所述的文库,其中,所述氨基酸残基形成钙结合基序。
(20)如(19)所述的文库,其中,钙结合基序为钙粘蛋白结构域、EF-HAND、C2结构域、Gla结构域、C型凝集素、结构域、膜联蛋白、血小板反应蛋白3型结构域及EGF样结构域、Vk5的部分、序列号10、序列号11中的任意的钙结合基序。
(21)如(2)~(22)中任一项所述的文库,其中,所述氨基酸残基为具有金属螯合作用的氨基酸。
(22)如(21)所述的文库,其中,具有金属螯合作用的氨基酸为丝氨酸、苏氨酸、天冬酰胺、谷氨酰胺、天冬氨酸或谷氨酸中的任意一种以上的氨基酸。
(23)如(1)所述的文库,其中,离子浓度的条件为pH。
(24)如(23)所述的文库,其中,所述氨基酸残基被包含在所述抗原结合分子的重链的抗原结合结构域中。
(25)如(24)所述的文库,其中,重链的抗原结合结构域为重链可变区。
(26)如(25)所述的文库,其中,所述氨基酸残基被包含于重链可变区的以Kabat编号法表示的第27位、31位、32位、33位、35位、50位、52位、53位、55位、57位、58位、59位、61位、62位、95位、96位、97位、98位、99位、100a位、100b位、100d位、100f位、100h位、102位或107位的任意一处以上。
(27)如(26)所述的文库,其中,重链可变区的以Kabat编号法表示的第27位、31位、32位、33位、35位、50位、52位、53位、55位、57位、58位、59位、61位、62位、95位、96位、97位、98位、99位、100a位、100b位、100d位、100f位、100h位、102位或107位的任一的氨基酸残基以外的氨基酸序列包含天然序列的氨基酸序列。
(28)如(23)~(27)中任一项所述的文库,其中,所述抗原结合分子的轻链可变区包含生殖细胞系的序列。
(29)如(23)所述的文库,其中,所述氨基酸残基被包含在所述抗原结合分子的轻链的抗原结合结构域中。
(30)如(29)所述的文库,其中,轻链的抗原结合结构域为轻链可变区。
(31)如(30)所述的文库,其中,所述氨基酸残基被包含于轻链可变区的以Kabat编号法表示的第24位、27位、28位、30位、31位、32位、34位、50位、51位、52位、53位、54位、55位、56位、89位、90位、91位、92位、93位、94位或95a位的任意一处以上。
(32)如(30)或(31)所述的文库,其中,所述氨基酸残基被包含在轻链可变区的CDR1中。
(33)如(32)所述的文库,其中,所述氨基酸残基被包含于轻链的CDR1的以Kabat编号法表示的第24位、27位、28位、30位、31位、32位或34位的任意一处以上。
(34)如(30)~(33)中任一项所述的文库,其中,所述氨基酸残基被包含在轻链的CDR2中。
(35)如(34)所述的文库,其中,所述氨基酸残基被包含于轻链的CDR2的以Kabat编号法表示的第50位、51位、52位、53位、54位、55位或56位的任意一处以上。
(36)如(30)~(35)中任一项所述的文库,其中,所述氨基酸残基被包含在轻链的CDR3中。
(37)如(36)所述的文库,其中,所述氨基酸残基被包含在轻链的CDR3的以Kabat编号法表示的第89位、90位、91位、92位、93、94位或95a位的任意一处以上。
(38)如(29)~(37)中任一项所述的文库,其中,轻链的框架包含生殖细胞系的框架序列。
(39)如(29)~(38)中任一项所述的文库,其中,重链可变区为天然序列。
(40)如(23)~(39)中任一项所述的文库,其中,所述氨基酸残基为侧链的pKa为4.0-8.0的氨基酸。
(41)如(23)~(40)中任一项所述的文库,其中,所述氨基酸残基为谷氨酸。
(42)如(23)~(39)中任一项所述的文库,其中,所述氨基酸残基为侧链的pKa为5.5-7.0的氨基酸。
(43)如(23)~(40)或(42)的任一项所述的文库,其中,所述氨基酸残基为组氨酸。
(44)一种文库,主要由多个包含(1)~(43)任一项中记载的抗原结合分子的融合多肽构成,其特征在于,所述融合多肽为抗原结合分子的重链可变区与病毒外壳蛋白质的至少一部分融合而成的。
(45)如(44)所述的文库,其中,所述病毒外壳蛋白质选自由蛋白质pIII、主外壳蛋白质pVIII、pVII、pIX、Soc、Hoc、gpD、pv1及其变体构成的组。
(46)一种组合物,其包含多个多核苷酸分子,所述多个多核苷酸分子分别编码(1)~(43)中记载的互相之间序列不同的抗原结合分子或(44)或(45)中记载的互相之间序列不同的融合多肽。
(47)一种组合物,其包含多种载体,所述多种载体分别包含处于被可作用地连接的状态的、(46)中记载的多个多核苷酸分子。
(48)如(47)所述的组合物,其中,载体为可复制的表达载体。
(49)如(48)所述的组合物,其中,可复制的表达载体中,所述多核苷酸被可作用地连接至lac Z启动子系、碱性磷酸酶pho A启动子(Ap)、噬菌体λPL启动子(温度感受性启动子)、tac启动子、色氨酸启动子、pBAD启动子及噬菌体T7启动子构成的组的启动子区域。
(50)如(48)或(49)所述的组合物,其中,可复制的表达载体为M13、fl、fd、Pf3噬菌体或其衍生物、或λ型噬菌体或其衍生物。
(51)一种组合物,其包含多种病毒,所述多种病毒分别包含(47)~(50)任一项中记载的载体。
(52)一种组合物,其包含多种病毒,所述多种病毒在表面分别提呈(1)~(43)中记载的互相之间序列不同的抗原结合分子或(44)或(45)中记载的互相之间序列不同的融合多肽。
(53)一种文库,其包含(1)~(43)中记载的互相之间序列不同的抗原结合分子或(44)或(45)中记载的互相之间序列不同的融合多肽,所述文库具有1×10
(54)如(53)所述的文库,其具有1×10
(55)一种文库的制作方法,所述文库主要由互相之间序列不同的多个抗原结合分子构成,所述方法包括制造多个抗原结合分子,所述抗原结合分子被设计为:所述抗原结合分子中的抗原结合结构域包含至少一个下述氨基酸残基,所述氨基酸残基使得抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化。
(56)如(55)所述的制作方法,其中,所述抗原结合分子为(2)~(43)任一项中记载的抗原结合分子。
(57)如(55)或(56)所述的制作方法,其中,所述抗原结合分子的重链可变区与病毒外壳蛋白质的至少一部分融合。
(58)如(55)~(57)中任一项所述的制作方法,其中,所述病毒外壳蛋白质选自由蛋白质pIII、主外壳蛋白质pVIII、pVII、pIX、Soc、Hoc、gpD、pv1及其变体构成的组。
(59)一种选择下述抗原结合分子的方法,所述抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化,所述方法包括:
a)制作文库的步骤,所述文库主要由(1)~(43)任一项中记载的互相之间序列不同的抗原结合分子或(44)或(45)任一项中记载的互相之间序列不同的融合多肽构成,
b)步骤,使所述文库在离子浓度不同的两种以上的条件下与抗原接触,
c)步骤,从所述文库中分级分离针对抗原的结合活性根据离子浓度的条件而变化的抗原结合分子的集群,
d)步骤,从在c)中分级分离的集群中分离针对抗原的结合活性根据离子浓度的条件而变化的抗原结合分子。
(60)一种分离下述多核苷酸的方法,所述多核苷酸编码针对抗原的结合活性根据离子浓度的条件而变化的抗原结合分子,所述方法包括下述步骤:
a)制作文库的步骤,所述文库包含多个可复制的表达载体,所述多个可复制的表达载体分别包含处于被可作用地连接的状态的多个多核苷酸,所述多个多核苷酸分别编码(1)~(43)任一项中记载的互相之间序列不同的抗原结合分子或(44)或(45)任一项中记载的互相之间序列不同的融合多肽,
b)步骤,在已经导入了所述文库中包含的各表达载体的多种病毒的表面、表达通过所述多核苷酸编码的所述互相之间序列不同的抗原结合分子或融合多肽,
c)步骤,将所述的多种病毒在离子浓度不同的两种以上的条件下与抗原接触,
d)步骤,从所述文库中分级分离针对抗原的结合活性根据离子浓度的条件而变化的病毒的集群,
e)步骤,从在d)中分级分离的病毒的集群中分离针对抗原的结合活性根据离子浓度的条件而变化的病毒,
f)步骤,从分离的病毒中分离多核苷酸。
(61)如(60)所述的方法,其中,所述c)至d)的步骤追加反复至少1次。
(62)如(59)~(61)中任一项所述的方法,其中,离子浓度为钙离子浓度。
(63)如(62)所述的方法,其中,选择在低钙浓度的条件下针对抗原的结合活性比在高钙浓度的条件下的结合活性低的抗原结合分子。
(64)如(63)所述的方法,其中,低钙浓度的条件为0.1μM~30μM。
(65)如(63)或(64)所述的方法,其中,高钙浓度的条件为100μM~10mM。
(66)如(59)~(61)中任一项所述的方法,其中,离子浓度的条件为pH。
(67)如(66)所述的方法,其中,选择在pH酸性区域条件下针对抗原的结合活性比在pH中性区域条件下的结合活性低的抗原结合分子。
(68)如(66)所述的方法,其中,pH酸性区域条件为pH 4.0~6.5。
(69)如(67)或(68)所述的方法,其中,pH中性区域条件为pH 6.7~10.0。
(70)一种抗原结合分子的制造方法,所述抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化,所述制造方法包含下述步骤:
a)制作文库的步骤,所述文库包含多个可复制的表达载体,所述多个可复制的表达载体分别包含处于被可作用地连接的状态的多个多核苷酸,所述多个多核苷酸分别编码(1)~(43)任一项中记载的互相之间序列不同的抗原结合分子或(44)或(45)任一项中记载的互相之间序列不同的融合多肽,
b)步骤,在已经导入了所述文库中包含的各表达载体的多种病毒的表面、表达通过所述多核苷酸编码的所述互相之间序列不同的抗原结合分子或融合多肽,
c)步骤,将所述的多种病毒在离子浓度不同的两种以上的条件下与抗原接触,
d)步骤,从所述文库中分级分离针对抗原的结合活性根据离子浓度的条件而变化的病毒的集群,
e)步骤,从在d)中分级分离的病毒的集群中分离针对抗原的结合活性根据离子浓度的条件而变化的病毒,
f)步骤,从分离的病毒中分离多核苷酸,
g)步骤,培养导入了下述载体的宿主细胞,所述载体中插入了经分离的多核苷酸,所述多核苷酸以处于被可作用地连接的状态被插入,
h)步骤,从在g)中培养的培养液中回收抗原结合分子。
(71)一种抗原结合分子的制造方法,所述抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化,所述制造方法包含下述步骤:
a)制作文库的步骤,所述文库包含多个可复制的表达载体,所述多个可复制的表达载体分别包含处于被可操作连接的状态的多个多核苷酸,所述多个多核苷酸分别编码(1)~(43)任一项中记载的互相之间序列不同的抗原结合分子或(44)或(45)任一项中记载的互相之间序列不同的融合多肽,
b)步骤,在已经导入了所述文库中包含的各表达载体的多种病毒的表面、表达通过所述多核苷酸编码的所述互相之间序列不同的抗原结合分子或融合多肽,
c)步骤,将所述的多种病毒在离子浓度不同的两种以上的条件下与抗原接触,
d)步骤,从所述文库中分级分离针对抗原的结合活性根据离子浓度的条件而变化的病毒的集群,
e)步骤,从在d)中分级分离的病毒的集群中分离针对抗原的结合活性根据离子浓度的条件而变化的病毒,
f)步骤,从分离的病毒中分离多核苷酸,
g)步骤,将经分离的多核苷酸以符合读码框的方式与编码抗体恒定区的多核苷酸连接,
h)步骤,培养导入了下述载体的宿主细胞,所述载体中插入了在g)中被连接的多核苷酸,所述多核苷酸以处于被可作用地连接的状态被插入,
i)步骤,从在h)中培养的培养液中回收抗原结合分子。
(72)如(70)或(71)所述的制造方法,其中,所述c)至d)的步骤追加反复至少1次。
(73)如(70)~(72)中任一项所述的制造方法,其中,离子浓度为钙离子浓度。
(74)如(73)所述的制造方法,其中,选择在低钙浓度的条件下针对抗原的结合活性比在高钙浓度的条件下的结合活性低的抗原结合分子。
(75)如(74)所述的方法,其中,低钙浓度的条件为0.1μM~30μM。
(76)如(74)或(75)所述的方法,其中,高钙浓度的条件为100μM~10mM。
(77)如(70)~(72)中任一项所述的方法,其中,离子浓度的条件为pH。
(78)如(77)所述的方法,其中,选择在pH酸性区域条件下针对抗原的结合活性比在pH中性区域条件下的结合活性低的抗原结合分子。
(79)如(78)所述的方法,其中,pH酸性区域条件为pH 4.0~6.5。
(80)如(78)或(79)所述的方法,其中,pH中性区域条件为pH 6.7~10.0。
(81)根据(70)~(80)中任一项所述的制造方法制造的抗原结合分子。
(82)一种医药组合物,包含(81)所述的抗原结合分子或其经修饰体。
附图说明
[图1]图1为展示从大肠杆菌(所述大肠杆菌导入有以pH依赖性方式结合抗原的抗体基因文库)分离的132个克隆的序列信息的氨基酸分布(表示为“文库”)和设计的氨基酸分布(表示为“设计”)的关系的图。横轴表示以Kabat编号法表示的氨基酸的位点。纵轴表示氨基酸的分布的比率。
[图2]图2表示抗IL-6R抗体(托珠单抗(Tocilizumab))、6RpH#01抗体、6RpH#02抗体及6RpH#03抗体在pH 7.4处的传感图(sensorgram)。横轴表示时间,纵轴表示RU值。
[图3]图3表示抗IL-6R抗体(托珠单抗)、6RpH#01抗体、6RpH#02抗体及6RpH#03抗体在pH 6.0处的传感图。横轴表示时间,纵轴表示RU值。
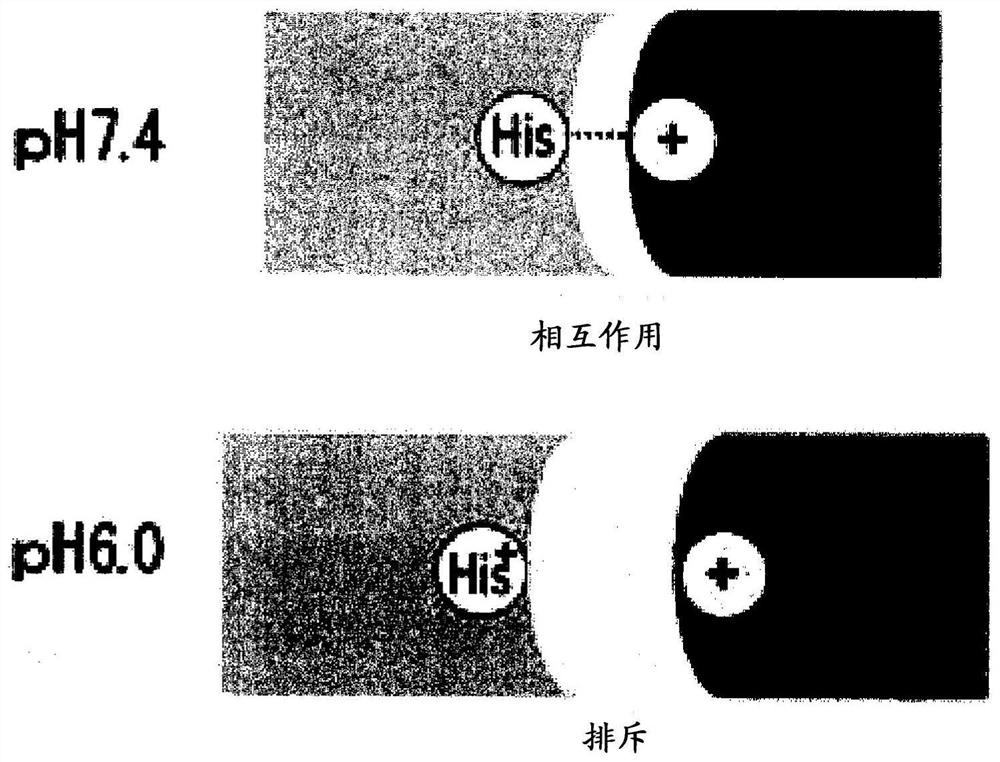
[图4A]图4A为表示pH依赖性结合抗体在血浆中(pH 7.4)和核内体内(pH 6.0)与抗原的相互作用的模式的图。
[图4B]图4B为表示钙依赖性结合抗体在血浆中(Ca
[图4C]图4C为表示pH和钙依赖性结合抗体在血浆中(Ca
[图5]图5为包含人Vk5-2序列的抗体和包含h Vk5-2_L65序列(所述h Vk5-2_L65序列是人Vk5-2序列中糖链附加序列经修饰的序列)的抗体的离子交换色谱。实线表示包含人Vk5-2序列的抗体(重链:CIM_H(序列号:4)和轻链:hVk5-2(序列号:1)上融合了序列号:26而得的)的色谱图,虚线表示具有hVk5-2_L65的序列的抗体(重链:CIM_H(序列号:4)、轻链:hVk5-2_L65(序列号:5))的色谱图。
[图6]图6为包含LfVk1_Ca序列的抗体(重链:GC_H、序列号:48,以及轻链:LfVk1_Ca、序列号:43)、与包含LfVk1_Ca序列中的Asp(D)残基被修饰为Ala(A)残基的序列的抗体在5℃保存后(实线)或在50℃保存后(虚线)的离子交换色谱。分别地,其为将5℃保存后的离子交换色谱中最高的峰作为主峰、通过主峰进行了y轴归一化的图。
[图7]图7为包含LfVk1_Ca序列的抗体(重链:GC_H、序列号:48,以及轻链:LfVk1_Ca、序列号:43)、与包含LfVk1_Ca序列中的第30位(Kabat编号)的Asp(D)残基被修饰为Ser(S)残基的LfVk1_Ca6序列(重链:GC_H、序列号:48,以及轻链:LfVk1_Ca6、序列号:49)的抗体在5℃保存后(实线)或50℃保存后(虚线)的离子交换色谱。分别地,其为将5℃保存后的离子交换色谱中最高的峰作为主峰、通过主峰进行了y轴归一化的图。
[图8]图8为展示从大肠杆菌(该大肠杆菌导入了以Ca依赖性方式结合抗原的抗体基因文库)分离的290个克隆的序列信息的氨基酸分布(表示为“文库”)和设计的氨基酸分布(表示为“设计”)的关系的图。横轴表示以Kabat编号法表示的氨基酸的位点。纵轴表示氨基酸的分布的比率。
[图9]图9表示高钙离子浓度的条件(1.2mM)下抗IL-6R抗体(托珠单抗)、6RC1IgG_010抗体、6RC1IgG_012抗体及6RC1IgG_019抗体的传感图。横轴表示时间,纵轴表示RU值。
[图10]图10表示低钙离子浓度的条件(3μM)下抗IL-6R抗体(托珠单抗)、6RC1IgG_010抗体、6RC1IgG_012抗体及6RC1IgG_019抗体的传感图。横轴表示时间,纵轴表示RU值。
[图11]图11表示通过X射线结晶结构分析确定的6RL#9抗体的Fab片段的重链CDR3的结构。(i)为表示在存在钙离子的结晶化条件下得到的结晶结构的重链CDR3的图,(ii)为表示在不存在钙离子的结晶化条件下得到的结晶结构的重链CDR3的图。
[图12]图12为表示使用Biacore的传感图,所述传感图表示抗人IgA抗体在Ca
[图13]图13为使用ELISA法的、表示抗人磷脂酰肌醇蛋白聚糖3(glypican3)抗体在Ca
[图14]图14为表示使用Biacore的传感图,所述传感图表示抗小鼠IgA抗体在pH7.4及pH 5.8时与小鼠IgA的相互作用。实线表示pH 7.4的条件,虚线表示pH 5.8的条件。
[图15]图15为表示使用Biacore的传感图,所述传感图表示抗人HMGB1抗体在pH7.4及pH 5.8时与人HMGB1的相互作用。实线表示pH 7.4的条件,虚线表示pH 5.8的条件。
[图16]图16为表示H54/L28-IgG1抗体、FH4-IgG1抗体及6RL#9-IgG1抗体在正常小鼠的血浆中的抗体浓度的推移的图。
[图17]图17为表示给予了H54/L28-IgG1抗体、FH4-IgG1抗体及6RL#9-IgG1抗体的正常小鼠的血浆中可溶性人IL-6受体(hsIL-6R)的浓度的推移的图。
[图18]图18为表示H54/L28-N434W抗体、FH4-N434W抗体及6RL#9-N434W抗体在正常小鼠的血浆中的抗体浓度的推移的图。
[图19]图19为表示给予了H54/L28-N434W抗体、FH4-N434W抗体及6RL#9-N434W抗体的正常小鼠的血浆中可溶型人IL-6受体(hsIL-6R)浓度的推移的图。
具体实施方式
根据本发明的公开内容,提供了主要由互相之间序列不同的多个抗原结合分子构成的文库,所述抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化。此外,根据本发明的公开内容,提供了下述文库的新颖的系统性制造方法,所述文库主要由互相之间序列不同的多个抗原结合分子构成,所述抗原结合分子针对抗原的结合活性根据金属离子浓度和/或氢离子浓度的条件而变化。这样的文库可作为对于选择和/或筛选具有下述活性的合成的抗原结合分子的克隆有用的组合文库使用,所述活性为例如针对金属离子浓度和/或氢离子浓度的条件而期望的活性,例如结合亲和性(affinity)和亲和力(avidity)。
这些文库可用于鉴定抗原结合分子的多肽的序列,所述抗原结合分子能与任意的多种多样的对象抗原发生相互作用。例如,以噬菌体展示的方式表达的本发明的包含经多样化的抗原结合分子的多肽的文库,对于选择和/或筛选目标抗原结合分子特别有用,此外,根据本发明还提供了用于此的高通量、高效的、可自动化的系统。根据本发明的方法,可提供针对对象抗原以条件依赖性方式结合的抗原结合分子。进而,通过本发明,还提供含有该抗原结合分子作为有效成分的医药组合物。
本说明书中,氨基酸以单字母编码或三字母编码或这两种方式来表示,例如表示为Ala/A、Leu/L、Arg/R、Lys/K、Asn/N、Met/M、Asp/D、Phe/F、Cys/C、Pro/P、Gln/Q、Ser/S、Glu/E、Thr/T、Gly/G、Trp/W、His/H、Tyr/Y、Ile/I、Val/V。
根据本发明中使用的方法,被分配为抗体的CDR和FR的氨基酸位置是按照Kabat规定的(Sequences of Proteins of Immunological Interest(National Institute ofHealth,Bethesda,Md.,1987年和1991年)。本说明书中,抗原结合分子为抗体或抗原结合片断的情况下,可变区的氨基酸按照Kabat编号表示,恒定区的氨基酸按照遵循Kabat的氨基酸位置的EU编号来表示。
为了对抗原结合分子的氨基酸序列中的氨基酸进行修饰,可适当地采用位点特异性的突变诱导法(Kunkel等人(Proc.Natl.Acad.Sci.USA(1985)82,488-492))或重叠延伸PCR(Overlap extension PCR)等公知的方法。此外,作为取代为天然氨基酸以外的氨基酸的氨基酸修饰方法,可采用多种公知的方法(Annu.Rev.Biophys.Biomol.Struct.(2006)35,225-249,Proc.Natl.Acad.Sci.U.S.A.(2003)100(11),6353-6357)。例如,还可适合地使用含有tRNA的无细胞翻译系统(Clover Direct(Protein Express))等,所述无细胞翻译系统中,非天然氨基酸结合至作为终止密码子之一的UAG密码子(琥珀密码子)的互补的琥珀抑制基因tRNA上。此外,作为显示氨基酸的修饰的表示方式,可适当地使用下述表示方式:其中,在表示特定位置的数字前后使用修饰前和修饰后的氨基酸的单字母编码。例如,在抗体恒定区含有的Fc区域中施加氨基酸取代时使用的P238D这样的修饰,表示以EU编号表示的第238位的Pro被取代为Asp。即,数字表示以EU编号表示的氨基酸位置,其之前记载的氨基酸单字母编码表示取代前的氨基酸,其之后记载的氨基酸单字母编码表示取代后的氨基酸。
本说明书中,“和/或”的用语的意义包括“和”与“或”适当组合而得的所有组合。具体而言,例如,“第33位、55位和/或96位的氨基酸被取代”表示包括以下的氨基酸修饰的变化:(a)第33位,(b)第55位,(c)第96位,(d)第33位和第55位,(e)第33位和第96位,(f)第55位和第96位,(g)第33位和第55位和第96位。
本说明书中,用语“抗原结合分子”以表示包含抗原结合结构域的最广义的含义来使用,具体而言,只要显示出对抗原的结合活性,各种各样的分子形式都包括在内。例如,作为抗原结合结构域与FcRn结合结构域结合的分子的例子,可举出抗体。抗体可包括单一的单克隆抗体(包括激动性抗体和拮抗性抗体)、人抗体、人源化抗体、嵌合抗体等。此外,在以抗体片断的形式使用的情况下,可优选举出抗原结合结构域和抗原结合片断(例如,Fab、F(ab’)2、scFv和Fv)。使用已有的稳定的α/β桶状蛋白质(barrel protein)结构等立体结构作为支架结构(scaffold;基础)、仅其一部分结构为了构建抗原结合结构域而被文库化的支架分子,也包括在本发明的抗原结合分子内。
本说明书中,关于“抗原结合结构域”,只要能与目标抗原结合,则可使用任何结构的结构域。作为这样的结构域的例子,可优选举出例如:抗体的重链和轻链的可变区;存在于生物体内的细胞膜蛋白即Avimer中含有的35个氨基酸左右的被称为A结构域的模块(WO2004044011、WO2005040229);包含10Fn3结构域的Adnectin,所述10Fn3结构域为与纤连蛋白(fibronectin)中的蛋白质结合的结构域,所述纤连蛋白为细胞膜上表达的糖蛋白(WO2002032925);以构成3螺旋束(bundle)的IgG结合结构域作为支架结构的Affibody(WO1995001937),所述3螺旋束包含蛋白质A的58个氨基酸;DARPins(Designed AnkyrinRepeat proteins),其为ankyrin重复(ankyrin repeat:AR)在分子表面露出的区域,所述ankyrin重复具有包含33个氨基酸残基的转角与2个逆平行螺旋及环的亚单位反复重叠而成的结构(WO2002020565);Anticalin等,其为支承下述桶状结构的单侧的四个环区域,所述桶状结构为嗜中性粒细胞明胶酶结合载脂蛋白(neutrophil gelatinase-associatedlipocalin(NGAL))等载脂蛋白中高度保守的8条逆平行链向中央方向弯曲而成的(WO2003029462);作为七鳃鳗、盲鳗等无颚类动物的获得性免疫系统不具有免疫球蛋白结构的可变淋巴细胞受体(variable lymphocyte receptor(VLR))的富含亮氨酸残基的重复(leucine-rich-repeat(LRR))模块反复重叠而成的马鞍形结构的内部的平行片层结构的凹陷区域(WO2008016854)。作为本发明的抗原结合结构域的优选例,可举出包含抗体的重链可变区和轻链可变区的抗原结合结构域。
本说明书中,“抗体”表示天然存在的、或者部分或完全通过合成而制造的免疫球蛋白。抗体可从天然存在的血浆或血清等天然来源分离得到、或从产生抗体的杂交瘤细胞的培养上清液分离得到、或者可通过使用基因重组等手段部分或完全地合成获得。作为抗体的例子,可优选举出免疫球蛋白的同种型及这些同种型的亚类。作为人的免疫球蛋白,已知IgG1、IgG2、IgG3、IgG4、IgA1、IgA2、IgD、IgE、IgM这9个类别(同种型)。本发明的抗体可包含这些同种型中的IgG1、IgG2、IgG3、IgG4。作为人IgG1、人IgG2、人IgG3、人IgG4恒定区,在Sequences of proteins of immunological interest,NIH Publication No.91-3242中记载了由于基因多态性产生的多个同种异型(allotype)序列,其中任意的序列均可用于本发明中。特别地,作为人IgG1的序列,以EU编号表示的356-358位的氨基酸序列可以为DEL也可以为EEM。作为人IgK(Kappa)恒定区与人IgL7(Lambda)恒定区,在Sequences ofDroteins of immunological interest,NIH Publication No.91-3242中记载了由于基因多态性产生的多个同种异型序列,其中任意的序列均可用于本发明中。制作具有期望的结合活性的抗体的方法也是本领域技术人员公知的。
抗体可使用公知的手段以多克隆抗体或单克隆抗体的形式获得。作为单克隆抗体,可适合地制作来源于哺乳动物的单克隆抗体。来源于哺乳动物的单克隆抗体包括通过杂交瘤产生的单克隆抗体,以及通过宿主细胞产生的单克隆抗体等,所述宿主细胞利用基因工程手段用包含抗体基因的表达载体进行了转化。
单克隆抗体产生杂交瘤可使用公知技术来制作。即,通过致敏性(sensitive)抗原按照通常的免疫方法对哺乳动物进行免疫。将得到的免疫细胞通过通常的细胞融合法与公知的亲本细胞融合。接着,利用通常的筛选法,对单克隆的抗体产生细胞进行筛选,由此能够选择出产生对该致敏性抗原的抗体的杂交瘤。
作为使用该致敏性抗原免疫的哺乳动物,不限于特定的动物,优选考虑与用于细胞融合的亲本细胞的相容性来进行选择。一般而言,优选使用啮齿类动物,例如小鼠、大鼠、仓鼠或兔,猴等。
按照公知的方法,通过致敏性抗原对上述动物进行免疫。例如,作为一般的方法,通过将致敏性抗原注射至哺乳动物的腹腔内或皮下进行给药来实施免疫。具体而言,将经PBS(磷酸缓冲盐水)、生理盐水等以适当稀释倍率稀释的致敏性抗原根据需要与通常的佐剂(例如弗氏完全佐剂)混合、乳化后,将该致敏性抗原以每4~21天向哺乳动物给予数次。此外,在致敏性抗原的免疫时可使用合适的载体。特别地,将分子量小的部分肽作为致敏性抗原时,有时也优选对与清蛋白、钥孔戚血蓝蛋白(keyhole limpet hemocyanin)等载体蛋白结合的该致敏性抗原肽进行免疫。
此外,针对希望的多肽产生抗体的杂交瘤还可通过使用DNA免疫按照下文所述来制作。DNA免疫为下述免疫方法:以使得编码抗原蛋白质的基因在免疫动物中能够表达的形式构建载体DNA,将该载体DNA给予该免疫动物,通过致敏性抗原在该免疫动物的生物体内表达,从而在该免疫动物中给予免疫刺激。与向免疫动物给予蛋白质抗原的一般性免疫方法相比,DNA免疫具有下述优势:
-抗原为膜蛋白质的情况下,能够维持该结构并给予免疫刺激,
-不需要纯化免疫抗原。
作为与所述免疫细胞融合的细胞,可使用哺乳动物的骨髓瘤细胞。骨髓瘤细胞优选具备用于筛选的合适的选择性标志物。所谓选择性标志物,表示在特定的培养条件下能够存活(或者不能存活)的特性。选择性标志物中,次黄嘌呤鸟嘌呤磷酸核糖转移酶缺陷(以下简称为HGPRT缺陷)或胸苷激酶缺陷(以下简称为TK)等是公知的。具有HGPRT或TK缺陷的细胞具有次黄嘌呤-氨基蝶呤-胸苷敏感性(以下简称为HAT敏感性)。HAT敏感性的细胞在HAT选择性培养基中死亡,不能进行DNA合成,但与正常的细胞融合的话则能够利用正常细胞的救济途径(salvage pathway)继续DNA合成,因此能够在HAT选择性培养基中生长。
HGPRT缺陷或TK缺陷的细胞分别可以通过包含6-硫杂鸟嘌呤、8-氮杂鸟嘌呤(以下简称为8AG)或5’-溴脱氧尿苷的培养基来选择。在DNA中掺入这些嘧啶类似物的正常细胞将死亡。另一方面,不掺入这些嘧啶类似物的、上述酶缺陷的细胞则能够在选择性培养基中存活。除此之外,被称为G418抗性的选择性标志物通过新霉素抗性基因而赋予针对2-脱氧链霉胺类抗生素(庆大霉素类似物)的抗性。适合于细胞融合的各种骨髓瘤细胞是公知的。
作为这类骨髓瘤细胞,例如,可优选使用P3(P3x63Ag8.653)(J.Immunol.(1979)123(4),1548-1550)、P3x63Ag8U.1(Current Topics in Microbiology and Immunology(1978)81,1-7)、NS-1(C.Eur.J.Immunol.(1976)6(7),511-519)、MPC-11(Cell(1976)8(3),405-415)、SP2/0(Nature(1978)276(5685),269-270)、FO(J.Immunol.Methods(1980)35(1-2),1-21)、S194/5.XX0.BU.1(J.Exp.Med.(1978)148(1),313-323)、R210(Nature(1979)277(5692),131-133)等。
基本而言,可按照公知的方法,例如kohler和Milstein等人的方法(MethodsEnzymol.(1981)73,3-46),来进行所述免疫细胞与骨髓瘤细胞的细胞融合。
更具体而言,例如,可在细胞融合促进剂的存在下,在通常的营养培养液中,实施所述细胞融合。作为融合促进,例如使用聚乙二醇(PEG)、仙台病毒(HVJ)等,为了进一步提高融合效率根据需要还可添加二甲亚砜等助剂。
免疫细胞和骨髓瘤细胞的使用比例可任意设定。例如,对于骨髓瘤细胞而言,免疫细胞优选为1~10倍。作为用于所述细胞融合的培养,例如,可使用适用于所述骨髓瘤细胞株的生长的RPMI1640培养液、MEM培养液,以及用于该种细胞培养的通常的培养液,进而,还可合适地添加胎牛血清(FCS)等血清补充液。
细胞融合中,将所述免疫细胞与骨髓瘤细胞以给定量在所述培养液中良好地混合,将预先加热至37℃左右的PEG溶液(例如平均分子量为1000~6000左右)以通常30~60%(w/v)的浓度添加。通过对混合液缓慢混合,形成期望的融合细胞(杂交瘤)。接着,顺次添加上文举出的合适的培养液,可通过反复进行离心除去上清液的操作,除去对于杂交瘤的生长来说不利的细胞融合剂等。
可使用通常的选择性培养液,例如HAT培养液(包含次黄嘌呤、氨基蝶呤和胸苷的培养液)进行培养,来对上述得到的杂交瘤加以选择。可使用上述HAT培养液继续进行培养充分的时间(通常,所述足够的时间为数天至数周)以使得期望的杂交瘤以外的细胞(非融合细胞)死亡。接着,通过通常的有限稀释法,实施对产生期望的抗体的杂交瘤的筛选以及单一克隆。
可通过利用与细胞融合中使用的骨髓瘤所具有的选择性标志物相应的选择性培养液,对上述得到的杂交瘤进行选择。例如,可通过用HAT培养液(包含次黄嘌呤、氨基蝶呤和胸苷的培养液)进行培养,选择具有HGPRT或TK的缺陷的细胞。即,将HAT感受性的骨髓瘤细胞用于细胞融合的情况下,可在HAT培养液中使与正常细胞的细胞融合成功的细胞选择性地生长。可使用上述HAT培养液继续进行培养充分的时间以使得期望的杂交瘤以外的细胞(非融合细胞)死亡。具体而言,一般,通过数天至数周的培养,可以选择得到所希望的杂交瘤。接着,通过通常的有限稀释法,实施对产生期望的抗体的杂交瘤的筛选以及单一克隆。
对期望的抗体的筛选以及单一克隆,可以根据基于公知的抗原抗体反应的筛选方法适当地实施。这样的单克隆抗体例如可通过FACS(fluorescence activated cellsorting,荧光激活细胞分选)来筛选得到。FACS是能够通过激光对与荧光抗体接触的细胞进行分析、通过测定各细胞发出的荧光来测定抗体与细胞表面的结合的系统。
或者,可基于ELISA的原理来评价抗体对被固定化的抗原的结合活性。例如,抗原被固定于ELISA板的孔中。将杂交瘤的培养上清液与孔内的抗原接触,检测结合至抗原的抗体。单克隆抗体来自小鼠的情况下,结合至抗原的抗体可通过抗小鼠免疫球蛋白抗体来检测。产生所期望的抗体(通过这些筛选选择到的、具有针对抗原的结合能力)的杂交瘤可通过有限稀释法等来克隆。这样制作的产生单克隆抗体的杂交瘤可在通常的培养液中传代培养。此外,该杂交瘤可在液氮中经历长期保存。
可按照通常的方法培养该杂交瘤,从其培养上清液获得期望的单克隆抗体。或者,可将杂交瘤给予与其具有相容性的哺乳动物并使其生长,从哺乳动物的腹水获得单克隆抗体。前者的方法对于获得高纯度来说是合适的方法。
还可优选地利用通过由该杂交瘤等的抗体产生细胞克隆的抗体基因编码的抗体。将克隆的抗体基因并入适当的载体并导入宿主中,由此该基因编码的抗体得以表达。用于抗体基因的分离和向载体的导入以及对宿主细胞的转化的方法已由例如Vandamme等人确立(Eur.J.Biochem.(1990)192(3),767-775)。如下文所述,重组抗体的制造方法也已公知。
例如,从产生目标抗体的杂交瘤细胞获得编码该抗体的可变区(V区)的cDNA。为此,通常,首先从杂交瘤提取总RNA。作为从细胞提取mRNA的方法,例如可利用下述方法。
-胍超离心法(Biochemistry(1979)18(24),5294-5299)
-AGPC法(Anal.Biochem.(1987)162(1),156-159)
提取的mRNA可使用mRNA纯化试剂盒(GE Healthcare Bioscience)等来纯化。或者,如QuickPrep mRNA纯化试剂盒(GE HEALTHCARE BIOSCIENCE)等那样、用于从细胞直接提取总mRNA的试剂盒也已市售。使用这样的试剂盒,可从杂交瘤获得mRNA。可使用逆转录酶从得到的mRNA合成编码抗体V区的cDNA。cDNA可通过AMV逆转录酶第一链cDNA合成试剂盒(AMV Reverse Transcriptase First-strand cDNA Synthesis Kit(生化学工业社))等来合成。此外,为了cDNA的合成及扩增,可合适地利用SMART RACE cDNA扩增试剂盒(Clontech)及使用PCR的5’-RACE法(Proc.Natl.Acad.Sci.USA(1988)85(23),8998-9002、Nucleic Acids Res.(1989)17(8),2919-2932)。此外,在这样的cDNA的合成过程中,可向cDNA的两个末端导入下文所述的适当的限制性酶位点。
从得到的PCR产物纯化作为目标的cDNA片断,接着与载体DNA连接。如上所述制作重组载体,导入大肠杆菌等,对菌落加以选择,之后可从形成了该菌落的大肠杆菌制备期望的重组载体。然后,针对该重组载体是否具有作为目标的cDNA的碱基序列,可通过公知的方法,例如,双脱氧核苷酸链终止法等来确认。
为了获得编码可变区的基因,利用使用了可变区基因扩增用的引物的5’-RACE法是简便的。首先,将从杂交瘤细胞提取出的RNA作为模板合成cDNA,得到5’-RACE cDNA文库。5’-RACE cDNA文库的合成中,可合适地使用SMART RACE cDNA扩增试剂盒等市售的试剂盒。
将得到的5’-RACE cDNA文库作为模板,通过PCR法扩增抗体基因。可基于公知的抗体基因序列来设计用于扩增小鼠抗体基因的引物。这些引物的碱基序列与免疫球蛋白的每个亚类不同。因此,优选地,使用Iso Strip小鼠单克隆抗体Isotyping试剂盒(RocheDiagnostics)等市售的试剂盒预先确定亚类。
具体而言,例如以获得编码小鼠IgG的基因为目的时,可利用可能扩增下述基因的引物,所述基因是编码作为重链的γ1、γ2a、γ2b、γ3、作为轻链的κ链和λ链的基因。为了扩增IgG的可变区基因,对于3’侧的引物而言,一般利用在与接近可变区的恒定区相当的部分进行退火的引物。另一方面,对于5’侧的引物而言,利用附属于5’RACE cDNA文库制作试剂盒中的引物。
利用如上所述进行了扩增的PCR产物,可对由重链和轻链的组合构成的免疫球蛋白改型。以改型的免疫球蛋白的对抗原的结合活性作为指标,可对期望的抗体加以筛选。例如,以获得针对抗原的抗体为目的时,关于抗体向抗原的结合而言,特异性结合是进一步优选的。可例如按照下文所述来筛选与抗原结合的抗体:
(1)步骤,将包含V区的抗体与抗原接触,所述V区由从杂交瘤得到的cDNA编码;
(2)步骤,检测抗原与抗体的结合,及
(3)步骤,选择与抗原结合的抗体。
检测抗体与抗原的结合的方法是公知的。具体而言,可通过前文描述过的FACS、ELISA等手段,检测抗体与抗原的结合。
得到编码目标抗体的V区的cDNA之后,通过识别向该cDNA的两个末端插入的限制性酶位点的限制性酶,来消化该cDNA。优选的限制性酶对构成抗体基因的碱基序列中出现频率低的碱基序列加以识别并消化。进而,为了将1个拷贝的消化片断以正确的方向插入载体中,优选插入能够赋予粘末端的限制性酶。通过如上文所述消化的编码抗体的V区的cDNA插入适当的表达载体中,能够获得抗体表达载体。此时,编码抗体恒定区(C区)的基因和编码所述V区的基因以符合读码框的方式融合的话,则获得嵌合抗体。此处,嵌合抗体表示恒定区与可变区的来源不同。因此,除了小鼠-人等异源嵌合抗体之外,人-人同种嵌合抗体也包括在本发明的嵌合抗体中。通过向预先具有恒定区的表达载体中插入所述V区基因,能够构建嵌合抗体表达载体。具体而言,例如,可在保持有DNA(该DNA编码期望的抗体恒定区(C区))的表达载体的5’侧,适当地配置消化所述V区基因的限制性酶的限制性酶识别序列。通过将经相同组合的限制性酶消化的两者以符合读码框的方式融合,嵌合抗体表达载体得以被构建。
为制造期望的抗体,抗体基因与控制序列可作用地连接,且并入表达载体中。用于表达抗体的控制序列包含例如增强子、启动子。此外,可在氨基末端添加合适的信号序列,以使得表达的抗体分泌到细胞外。例如,作为信号序列,可使用具有氨基酸序列MGWSCIILFLVATATGVHS(序列号13)的肽,但除此之外合适的信号序列也可被添加。表达的多肽在上述序列的羧基末端部分被切断,切断的多肽可作为成熟多肽分泌到细胞外。接着,通过利用该表达载体转化合适的宿主细胞,能够获得表达DNA(其编码期望的抗体)的重组细胞。
为了表达基因,编码抗体的重链(H链)和轻链(L链)的DNA分别被并入不同的表达载体。利用并入了重链和轻链的载体共转染相同的宿主细胞,由此可表达具有重链和轻链的抗体分子。或者,可通过将编码重链和轻链的DNA并入单一表达载体,来对宿主细胞进行转化(参照WO19994011523)
用于通过将分离的抗体基因导入合适的宿主来制作抗体的宿主细胞和表达载体的多种组合是公知的。这些表达系统均可应用于分离本发明的抗原结合分子。使用真核细胞作为宿主细胞的情况下,可适当地使用动物细胞、植物细胞或者真菌细胞。具体而言,作为动物细胞,可举例下述细胞。
(1)哺乳类细胞:CHO(中国仓鼠卵巢细胞系)、COS(猴肾细胞系)、骨髓瘤(Sp2/O、NS0等)、BHK(幼仓鼠肾细胞)、HEK293(具有经剪切的腺病毒(Ad)5DNA的人胚胎肾细胞)、PER.C6细胞(经5型(Ad5)腺病毒E1A和E1B基因转化的人胚胎视网膜细胞)、Hela、Vero等(Current Protocols in Protein Science(May,2001,Unit 5.9,Table 5.9.1)),
(2)两栖类细胞:非洲爪蟾卵母细胞等,
(3)昆虫细胞:sf9、sf21、Tn5等。
或者,作为植物细胞,利用来自烟草(Nicotiana tabacum)等烟草(Nicotiana)属的细胞的抗体基因表达系统是公知的。植物细胞的转化可适当地利用愈伤组织培养的细胞。
此外,作为真菌细胞,可利用下述细胞。
-酵母:酿酒酵母(Saccharomyces serevisiae)等酵母(Saccharomyces)属、甲醇同化酵母(巴斯德毕赤酵母,Pichia pastoris)等毕赤酵母属
-丝状菌:黑曲霉(Aspergillus niger)等曲霉(Aspergillus)属
此外,利用原核细胞的抗体基因表达系统也是公知的。例如,使用细菌细胞的情况下,可适当地利用大肠杆菌(E.coli)、枯草芽孢杆菌等细菌细胞。这些细胞中,可通过转化导入包含目标抗体基因的表达载体。通过体外培养经转化的细胞,可从该转化细胞的培养物获得期望的抗体。
对重组抗体的产生而言,除了上述宿主细胞之外,还可利用转基因动物。即,可从导入了基因(其编码期望的抗体)的动物获得该抗体。例如,将抗体基因以符合读码框的方式插入编码蛋白质(在乳汁中固有地产生)的基因内部,由此抗体基因可作为融合基因而被构建。作为分泌进乳汁中的蛋白质,例如可利用山羊β酪蛋白。将包含插入了抗体基因的融合基因的DNA片断注入山羊胚胎,将该经注入的胚胎导入雌性山羊。从由接受了胚胎的山羊生育的转基因山羊(或者其子孙)所产生的乳汁中,期望的抗体能够以与乳汁蛋白质的融合蛋白质的形式获得。此外,为了增加由转基因山羊产生的包含期望的抗体的乳汁的量,可向转基因山羊给予激素(Bio/Technology(1994),12(7),699-702)。
本说明书中记载的抗原结合分子给予人的情况下,作为该分子中的抗原结合结构域,可当适地采用来自基因重组型抗体(其是为了降低对人的异源抗原性等而经过人工改变的基因重组型抗体)的抗原结合结构域。基因重组型抗体中包含例如人化(Humanized)抗体等。这些改变的抗体可使用公知的方法合适地制造。
用于制作本说明书中记载的抗原结合分子中的抗原结合结构域的抗体的可变区,通常由在4个框架区(FR)中夹的3个互补性决定区(complementarity-determiningregion;CDR)而构成。CDR是实质上决定抗体的结合特异性的区域。CDR的氨基酸序列富含多样性。另一方面,构成FR的氨基酸序列即使在具有不同结合特异性的抗体之间也多显示出较高的同一性。因此,一般可通过CDR的移植将某抗体的结合特异性移植给其它抗体。
人源化抗体也被称为改型(reshaped)人抗体。具体而言,将除人之外的动物、例如小鼠抗体的CDR移植给人抗体的人源化抗体等是公知的。用于获得人源化抗体的一般性的基因重组手段也是已知的。具体而言,作为用于将小鼠的抗体的CDR移植至人的FR的方法,例如重叠·延伸(Overlap Extension)PCR是公知的。重叠·延伸PCR中,向用于合成人抗体的FR的引物中添加碱基序列,该碱基序列编码将被移植的小鼠抗体的CDR。针对4个FR分别准备引物。一般而言,在小鼠的CDR向人FR的移植中,选择与小鼠的FR具有较高同一性的人FR,在CDR的功能的维持中被认为是有利的。即,一般而言,优选利用包含下述氨基酸序列的人FR,该氨基酸序列与将移植的小鼠CDR邻近的FR的氨基酸序列具有较高同一性。
此外,连接的碱基序列被设计为互相以符合读码框的方式连结。通过各引物而个别地合成人FR。结果,可获得向各FR添加了编码小鼠CDR的DNA的产物。各产物的编码小鼠CDR的碱基序列被设计为互相重叠。接着,使将人抗体基因作为模板合成的产物的重叠的CDR部分互相退火,进行互补链合成反应。通过该反应,将人FR经由小鼠CDR的序列连接起来。
最终3个CDR和4个FR连接而得的V区域基因,通过向其5’末端和3’末端退火并添加了合适的限制性酶识别序列的引物而被全长扩增。通过将如上文所述获得的DNA与编码人抗体C区的DNA以符合读码框的方式融合的方式插入到表达载体中,能够制作用于表达人化抗体的载体。将该具有并入物的载体导入宿主建立重组细胞后,通过培养该重组细胞、使得编码该人源化抗体的DNA表达,该人源化抗体被产生于该培养细胞的培养物中(EP239400、WO1996002576)。
对上文所述制作的人源化抗体与抗原的结合活性进行定性或定量测定、评价,由此能够合适地选择下述人抗体的FR,其使得在经由CDR而被连接时该CDR能形成良好的抗原结合位点。根据需要,还可取代FR的氨基酸序列,以使得改型人抗体的CDR形成合适的抗原结合位点。例如,应用在将小鼠CDR向人FR的移植中使用的PCR法,可向FR中导入氨基酸序列的突变。具体而言,可向对FR进行退火的引物中导入部分碱基序列的突变。通过这样的引物合成的FR中就导入了碱基序列的突变。通过用上述方法对经氨基酸取代的突变型抗体对抗原的结合活性进行测定和评价,可选择具有期望的性质的突变FR序列(Sato等人,CancerRes(1993)53,851-856)。
此外,将具有人抗体基因的全部结构(repertoires)的转基因动物(参照WO1993012227、WO1992003918、WO1994002602、WO1994025585、WO1996034096、WO1996033735)作为免疫动物,通过DNA免疫,可获得期望的人抗体。
此外,使用人抗体文库、通过淘选(panning)获得人抗体的技术也是已知的。例如,人抗体的V区作为单链抗体(scFc)通过噬菌体展示法而表达于噬菌体的表面。可选择出表达与抗原结合的scFv的噬菌体。通过对选择的噬菌体的基因进行分析,能够确定编码与抗原结合的人抗体的V区的DNA序列。确定与抗原结合的scFv的DNA序列后,可通过将该V区序列与期望的人抗体C区的序列以符合读码框的方式融合后插入到适当的表达载体中,来制作表达载体。将该表达载体导入上文举出的那样的合适的表达细胞中,通过使得编码该人抗体的基因表达,获得该人抗体。这些方法已是公知的(参照WO1992001047、WO1992020791、WO1993006213、WO1993011236、WO1993019172、WO1995001438、WO1995015388)。
本说明书中,“抗原结合结构域”指与抗原的一部分或全部特异性结合且互补的区域。作为抗原结合结构域的例子,可举出具有抗体的抗原结合结构域的结构域。作为抗体的抗原结合结构域的例子,可举出CDR、可变区。抗体的抗原结合结构域为CDR的情况下,其可含有抗体中包含的全部6个CDR,也可含有1个或两个以上的CDR。作为抗体的结合区域含有CDR的情况下,只要具有对抗原的结合活性,可对含有的CDR进行氨基酸的缺失、取代、添加和/或插入等,或者还可使用CDR的一部分。抗原的分子量大的情况下,抗体可仅与抗原的特定部分结合。该特定部分被称为表位。抗原结合结构域可通过一个或多个抗体的可变结构域来提供。优选地,抗原结合结构域含有抗体轻链可变区(VL)和抗体重链可变区(VH)。作为这样的抗原结合结构域的例子,可优选举出“scFv(single chain Fv)”、“单链抗体(singlechain antibody)”、“Fv”、“scFv2(single chain Fv2)”、“Fab”、“二价抗体”、“线性抗体”或“F(ab’)2”等。
如在本说明书中使用的那样,“抗体可变区”指包含互补性决定区(CDR;即CDR1、CDR2和CDR3)以及框架区(FR)的氨基酸序列的、抗体分子的轻链和重链的部分。VH指重链的可变区(重链可变区,Heavy chain vaFiable region)。VL指轻链的可变区(轻链可变区,Light chain variableregion)。通过本发明中使用的方法,被分配为CDR和FR的氨基酸位置是遵循Kabat规定的(Sequences of Proteins of Immunological Interest(NationalInstitute of Health,Bethesda,Md.,1987年和1991年)。本说明书中,抗体或抗原结合片断的氨基酸编号也是采用以Kabat的氨基酸位置为基准的Kabat编号法表示的。
如在本说明书中使用的那样,用语“互补性决定区(CDR;即CDR1、CDR2和CDR3)”指为了抗原结合而必须存在的抗体可变区的氨基酸残基。各可变区一般包含表示为CDR1、CDR2和CDR3的3个CDR区。各互补性决定区可含有来自如Kabat所记载那样的“互补性决定区”的氨基酸残基(即,轻链可变区的约第24~34位的残基(CDR1)、第50~56位的残基(CDR2)、及第89~97位的残基(CDR3),以及重链可变区的第31~35位氨基酸(CDR1)、第50~65位残基(CDR2)及第95~102位残基(CDR3);Kabat等人,Sequences of Proteins ofImmunological Interest,第5版,Public Health Service,National InstituteofHealth,Bethesda,MD.(1991))、和/或来自“超可变环”的残基(即,轻链可变区的约第26~32位的残基(CDR1)、第50~52位的残基(CDR2)及第91~96位的残基(CDR3),以及重链可变区的第26~32位残基(CDR1)、第53~55位的残基(CDR2)及第96~101位的残基(CDR3);Chothia和Lesk,J.Mol.Biol.(1987)196,901-917)。某些情况下,互补性决定区可包含来自根据Kabat的记载所定义的CDR区和超可变环的两者的氨基酸。
用语“Fab”片断包含轻链的可变区及恒定区以及重链的可变区以及第1恒定区(CH1)。F(ab’)2抗体片断包含一对Fab片断,通常它们通过位于它们之间的铰链区中的半胱氨酸在它们的羧基末端附近经由共价键而连接。抗体片断的其它化学键也是本发明所属的技术领域中公知的。
用语“单链Fv”或“scFv”抗体片断包含抗体的VH和VL区,这些区域形成单一的多肽链。通常,Fv多肽在VH和VL区之间进一步包含多肽接头,该接头使得scFv能够形成对于结合抗原来说优选的结构。关于scFv的综述,例如被记载于Pluckthun,The Pharmacology ofMonoclonal Antibodies(1994)Vol.113,269-315(Rosenburg和Moore编辑,Springer-Verlag,New York)等中。
用语“二价抗体(diabody)”指具有两个抗原结合位点的小的抗体片断,该抗体片断在相同多肽链(VH和VL)中包含与轻链可变区(VL)连接的重链可变区(VH)。使用过短而无法配对相同链上的2个区域的短接头,将该区域与其它链的互补性区域强制配对,形成两个抗原结合位点。二价抗体例如被详细记载于第404097号欧洲专利、WO1993011161等专利文献以及Holliger等(Proc.Natl.Acad.Sci.USA(1993)90,6444-6448)等非专利文献中。
用语“线性抗体”指被记载于Zapata et al.,Protein Eng.(1995)8(10),1057-1062中的抗体。也就是说,这些抗体与互补性的轻链多肽一起形成一对抗原结合结构域,包含一对串联Fd片断(VH-CH1-VH-CH1).线性抗体可为双特异性的或单特异性的。
本说明书中,“抗原”只要包含抗原结合结构域结合的表位即可,其结构不限于特定的结构。换句话说,抗原可以是无机物也可以是有机物。作为抗原,可举例如下分子:17-IA、4-1BB、4Dc、6-酮-PGF1a、8-异-PGF2a、8-氧代-dG、A1腺苷受体、A33、ACE、ACE-2、激活素(activin)、激活素A、激活素AB、激活素B、激活素C、激活素RIA、激活素RIA ALK-2、激活素RIB ALK-4、激活素RIIA、激活素RIIB、ADAM、ADAM10、ADAM12、ADAM15、ADAM17/TACE、ADAM8、ADAM9、ADAMTS、ADAMTS4、ADAMTS5、地址素(addressin)、aFGF、ALCAM、ALK、ALK-1、ALK-7、α-1-抗胰蛋白酶、α-V/β-1拮抗剂、ANG、Ang、APAF-1、APE、APJ、APP、APRIL、AR、ARC、ART、Artemin、抗Id、ASPARTIC、心房性钠利尿因子(利钠肽,atrial natriuretic factor)、av/b3整合素、Axl、b2M、B7-1、B7-2、B7-H、B-淋巴细胞刺激因子(BlyS)、BACE、BACE-1、Bad、BAFF、BAFF-R、Bag-1、BAK、Bax、BCA-1、BCAM、Bcl、BCMA、BDNF、b-ECGF、bFGF、BID、Bik、BIM、BLC、BL-CAM、BLK、BMP、BMP-2BMP-2a、BMP-3成骨素(Osteogenin)、BMP-4BMP-2b、BMP-5、BMP-6Vgr-1、BMP-7(OP-1)、BMP-8(BMP-8a、OP-2)、BMPR、BMPR-IA(ALK-3)、BMPR-IB(ALK-6)、BRK-2、RPK-1、BMPR-II(BRK-3)、BMP、b-NGF、BOK、蛙皮素(bombesin)、骨源性神经营养因子、BPDE、BPDE-DNA、BTC、补体因子3(C3)、C3a、C4、C5、C5a、C10、CA125、CAD-8、降钙素(calcitonin)、cAMP、癌胚抗原(CEA)、癌相关抗原、组织蛋白酶(cathepsin)A、组织蛋白酶B、组织蛋白酶C/DPPI、组织蛋白酶D、组织蛋白酶E、组织蛋白酶H、组织蛋白酶L、组织蛋白酶O、组织蛋白酶S、组织蛋白酶V、组织蛋白酶X/Z/P、CBL、CCI、CCK2、CCL、CCL1、CCL11、CCL12、CCL13、CCL14、CCL15、CCL16、CCL17、CCL18、CCL19、CCL2、CCL20、CCL21、CCL22、CCL23、CCL24、CCL25、CCL26、CCL27、CCL28、CCL3、CCL4、CCL5、CCL6、CCL7、CCL8、CCL9/10、CCR、CCR1、CCR10、CCR10、CCR2、CCR3、CCR4、CCR5、CCR6、CCR7、CCR8、CCR9、CD1、CD2、CD3、CD3E、CD4、CD5、CD6、CD7、CD8、CD10、CD11a、CD11b、CD11c、CD13、CD14、CD15、CD16、CD18、CD19、CD20、CD21、CD22、CD23、CD25、CD27L、CD28、CD29、CD30、CD30L、CD32、CD33(p67蛋白质)、CD34、CD38、CD40、CD40L、CD44、CD45、CD46、CD49a、CD52、CD54、CD55、CD56、CD61、CD64、CD66e、CD74、CD80(B7-1)、CD89、CD95、CD123、CD137、CD138、CD140a、CD146、CD147、CD148、CD152、CD164、CEACAM5、CFTR、cGMP、CINC、肉毒杆菌毒素、产气荚膜梭菌毒素、CKb8-1、CLC、CMV、CMV UL、CNTF、CNTN-1、COX、C-Ret、CRG-2、CT-1、CTACK、CTGF、CTLA-4、CX3CL1、CX3CR1、CXCL、CXCL1、CXCL2、CXCL3、CXCL4、CXCL5、CXCL6、CXCL7、CXCL8、CXCL9、CXCL10、CXCL11、CXCL12、CXCL13、CXCL14、CXCL15、CXCL16、CXCR、CXCR1、CXCR2、CXCR3、CXCR4、CXCR5、CXCR6、细胞角蛋白肿瘤相关抗原、DAN、DCC、DcR3、DC-SIGN、补体控制因子(Decay accelerating factor)、des(1-3)-IGF-I(脑IGF-1)、Dhh、地高辛、DNAM-1、Dnase、Dpp、DPPIV/CD26、Dtk、ECAD、EDA、EDA-A1、EDA-A2、EDAR、EGF、EGFR(ErbB-1)、EMA、EMMPRIN、ENA、内皮素受体、脑啡肽酶、eNOS、Eot、嗜酸性粒细胞活化趋化因子1(Eotaxin1)、EpCAM、Ephrin B2/EphB4、EPO、ERCC、E-选择素、ET-1、因子IIa、因子VII、因子VIIIc、因子IX、成纤维细胞活化蛋白质(FAP)、Fas、FcR1、FEN-1、铁蛋白、FGF、FGF-19、FGF-2、FGF3、FGF-8、FGFR、FGFR-3、纤维蛋白(fibrin)、FL、FLIP、Flt-3、Flt-4、促卵泡成熟激素、不规则趋化因子(Fractalkine)、FZD1、FZD2、FZD3、FZD4、FZD5、FZD6、FZD7、FZD8、FZD9、FZD10、G250、Gas6、GCP-2、GCSF、GD2、GD3、GDF、GDF-1、GDF-3(Vgr-2)、GDF-5(BMP-14、CDMP-1)、GDF-6(BMP-13、CDMP-2)、GDF-7(BMP-12、CDMP-3)、GDF-8(肌抑素(myoStatin))、GDF-9、GDF-15(MIC-1)、GDNF、GDNF、GFAP、GFRa-1、GFR-α1、GFR-α2、GFR-α3、GITR、胰高血糖素、Glut4、糖蛋白IIb/IIIa(GPIIb/IIIa)、GM-CSF、gp130、gp72、GRO、生长激素释放因子、半抗原(NP-cap或NIP-cap)、HB-EGF、HCC、HCMV gB包膜糖蛋白、HCMV gH包膜糖蛋白、HCMV UL、造血生长因子(HGF)、Hep B gp120、肝素酶、Her2、Her2/neu(ErbB-2)、Her3(ErbB-3)、Her4(ErbB-4)、单纯疱疹病毒(HSV)gB糖蛋白、HSV gD糖蛋白、HGFA、高分子量黑素瘤相关抗原(HMW-MAA)、HIV gpl20、HIV IIIB gp 120 V3环、HLA、HLA-DR、HM1.24、HMFGPEM、HRG、Hrk、人心脏肌球蛋白、人巨细胞病毒(HCMV)、人生长因子(HGH)、HVEM、I-309、IAP、ICAM、ICAM-1、ICAM-3、ICE、ICOS、IFNg、Ig、IgA受体、IgE、IGF、IGF结合蛋白质、IGF-1R、IGFBP、IGF-I、IGF-II、IL、IL-1、IL-1R、IL-2、IL-2R、IL-4、IL-4R、IL-5、IL-5R、IL-6、IL-6R、IL-8、IL-9、IL-10、IL-12、IL-13、IL-15、IL-18、IL-18R、IL-23、干扰素(INF)-α、INF-β、INF-γ、抑制素(inhibin)、iNOS、胰岛素A链、胰岛素B链、胰岛素样生长因子1、整合素α2、整合素α3、整合素α4、整合素α4/β1、整合素α4/β7、整合素α5(αV)、整合素α5/β1、整合素α5/β3、整合素α6、整合素β1、整合素β2、干扰素γ、IP-10、I-TAC、JE、激肽释放酶(kallikrein)2、激肽释放酶5、激肽释放酶6、激肽释放酶11、激肽释放酶12、激肽释放酶14、激肽释放酶15、激肽释放酶L1、激肽释放酶L2、激肽释放酶L3、激肽释放酶L4、KC、KDR、角化细胞生长因子(KGF)、层粘连蛋白(laminin)5、LAMP、LAP、LAP(TGF-1)、潜在的TGF-1、潜在的TGF-1bp1、LBP、LDGF、LECT2、Lefty、Lewis-Y抗原、Lewis-Y相关抗原、LFA-1、LFA-3、Lfo、LIF、LIGHT、脂蛋白、LIX、LKN、Lptn、L-选择素、LT-a、LT-b、LTB4、LTBP-1、肺表面、黄体形成激素、淋巴毒素β受体、Mac-1、MAdCAM、MAG、MAP2、MARC、MCAM、MCAM、MCK-2、MCP、M-CSF、MDC、Mer、金属蛋白酶、MGDF受体、MGMT、MHC(HLA-DR)、MIF、MIG、MIP、MIP-1-α、MK、MMAC1、MMP、MMP-1、MMP-10、MMP-11、MMP-12、MMP-13、MMP-14、MMP-15、MMP-2、MMP-24、MMP-3、MMP-7、MMP-8、MMP-9、MPIF、Mpo、MSK、MSP、粘蛋白(Muc1)、MUC18、苗勒管抑制物质(mullerian-inhibiting substance)、Mug、MuSK、NAIP、NAP、NCAD、N-C adherin、NCA 90、NCAM、NCAM、脑啡肽酶、神经营养因子-3、神经营养因子-4或神经营养因子-6、neurturin、神经生长因子(NGF)、NGFR、NGF-β、nNOS、NO、NOS、Npn、NRG-3、NT、NTN、OB、OGG1、OPG、OPN、OSM、OX40L、OX40R、p150、p95、PADPr、副甲状腺激素、PARC、PARP、PBR、PBSF、PCAD、P-钙粘蛋白、PCNA、PDGF、PDGF、PDK-1、PECAM、PEM、PF4、PGE、PGF、PGI2、PGJ2、PIN、PLA2、胎盘碱性磷酸酶(PLAP)、PlGF、PLP、PP14、胰岛素原、松弛素原(prorelaxin)、蛋白质C、PS、PSA、PSCA、前列腺特异性膜抗原(PSMA)、PTEN、PTHrp、Ptk、PTN、R51、RANK、RANKL、RANTES、RANTES、松弛素A链、松弛素B链、肾素、呼吸道合胞体病毒(RSV)F、RSV Fgp、Ret、风湿因子、RLIP76、RPA2、RSK、S100、SCF/KL、SDF-1、SERINE、血清清蛋白、sFRP-3、Shh、SIGIRR、SK-1、SLAM、SLPI、SMAC、SMDF、SMOH、SOD、SPARC、Stat、STEAP、STEAP-II、TACE、TACI、TAG-72(肿瘤相关糖蛋白-72)、TARC、TCA-3、T细胞受体(例如,T细胞受体α/β)、TdT、TECK、TEM1、TEM5、TEM7、TEM8、TERT、睾丸PLAP样碱性磷酸酶、TfR、TGF、TGF-α、TGF-β、TGF-β Pan Specific、TGF-βRI(ALK-5)、TGF-βRII、TGF-βRIIb、TGF-βRIII、TGF-β1、TGF-β2、TGF-β3、TGF-β4、TGF-β5、凝血酶、胸腺Ck-1、甲状腺刺激激素、Tie、TIMP、TIQ、组织因子、TMEFF2、Tmpo、TMPRSS2、TNF、TNF-α、TNF-αβ、TNF-β2、TNFc、TNF-RI、TNF-RII、TNFRSF10A(TRAIL R1 Apo-2、DR4)、TNFRSF10B(TRAIL R2 DR5、KILLER、TRICK-2A、TRICK-B)、TNFRSF10C(TRAIL R3 DcR1、LIT、TRID)、TNFRSF10D(TRAIL R4 DcR2、TRUNDD)、TNFRSF11A(RANK ODF R、TRANCER)、TNFRSF11B(OPG OCIF、TR1)、TNFRSF12(TWEAK R FN14)、TNFRSF13B(TACI)、TNFRSF13C(BAFF R)、TNFRSF14(HVEM ATAR、HveA、LIGHT R、TR2)、TNFRSF16(NGFR p75NTR)、TNFRSF17(BCMA)、TNFRSF18(GITR AITR)、TNFRSF19(TROY TAJ、TRADE)、TNFRSF19L(RELT)、TNFRSF1A(TNF RI CD120a、p55-60)、TNFRSF1B(TNF RIICD120b、p75-80)、TNFRSF26(TNFRH3)、TNFRSF3(LTbR TNF RIII、TNFC R)、TNFRSF4(OX40ACT35、TXGP1 R)、TNFRSF5(CD40 p50)、TNFRSF6(Fas Apo-1、APT1、CD95)、TNFRSF6B(DcR3M68、TR6)、TNFRSF7(CD27)、TNFRSF8(CD30)、TNFRSF9(4-1BB CD137、ILA)、TNFRSF21(DR6)、TNFRSF22(DcTRAIL R2 TNFRH2)、TNFRST23(DcTRAIL R1 TNFRH1)、TNFRSF25(DR3 Apo-3、LARD、TR-3、TRAMP、WSL-1)、TNFSF10(TRAIL Apo-2配体,TL2)、TNFSF11(TRANCE/RANK配体ODF、OPG配体)、TNFSF12(TWEAK Apo-3配体、DR3配体)、TNFSF13(APRIL TALL2)、TNFSF13B(BAFF BLYS、TALL1、THANK、TNFSF20)、TNFSF14(LIGHT HVEM配体、LTg)、TNFSF15(TL1A/VEGI)、TNFSF18(GITR配体AITR配体、TL6)、TNFSF1A(TNF-a连接素(Conectin)、DIF、TNFSF2)、TNFSF1B(TNF-b LTa、TNFSF1)、TNFSF3(LTb TNFC、p33)、TNFSF4(OX40配体gp34、TXGP1)、TNFSF5(CD40配体CD154、gp39、HIGM1、IMD3、TRAP)、TNFSF6(Fas配体Apo-1配体、APT1配体)、TNFSF7(CD27配体CD70)、TNFSF8(CD30配体CD153)、TNFSF9(4-1BB配体CD137配体)、TP-1、t-PA、Tpo、TRAIL、TRAIL R、TRAIL-R1、TRAIL-R2、TRANCE、转铁蛋白受体、TRF、Trk、TROP-2、TSG、TSLP、肿瘤相关抗原CA125、肿瘤相关抗原表达LewisY相关碳水化合物、TWEAK、TXB2、Ung、uPAR、uPAR-1、尿激酶、VCAM、VCAM-1、VECAD、VE-钙粘蛋白、VE-钙粘蛋白-2、VEFGR-1(flt-1)、VEGF、VEGFR、VEGFR-3(flt-4)、VEGI、VIM、病毒抗原、VLA、VLA-1、VLA-4、VNR整合素、von Willebrand因子、WIF-1、WNT1、WNT2、WNT2B/13、WNT3、WNT3A、WNT4、WNT5A、WNT5B、WNT6、WNT7A、WNT7B、WNT8A、WNT8B、WNT9A、WNT9A、WNT9B、WNT10A、WNT10B、WNT11、WNT16、XCL1、XCL2、XCR1、XCR1、XEDAR、XIAP、XPD、HMGB1、IgA、Aβ、CD81、CD97、CD98、DDR1、DKK1、EREG、Hsp90、IL-17/IL-17R、IL-20/IL-20R、酸化LDL、PCSK9、前激肽释放酶、RON、TMEM16F、SOD1、嗜铬粒蛋白A、嗜铬粒蛋白B、tau、VAP1、高分子量激肽原、IL-31、IL-31R、Nav1.1、Nav1.2、Nav1.3、Nav1.4、Nav1.5、Nav1.6、Nav1.7、Nav1.8、NaV1.9、EPCR、C1、C1q、C1r、C1s、C2、C2a、C2b、C3、C3a、C3b、C4、C4a、C4b、C5、C5a、C5b、C6、C7、C8、C9、因子B、因子D、因子H、备解素(properdin)、硬骨素(sclerostin)、纤维蛋白原、纤维蛋白、凝血酶原、凝血酶、组织因子、因子V、因子Va、因子VII、因子VIIa、因子VIII、因子VIIIa、因子IX、因子IXa、因子X、因子Xa、因子XI、因子XIa、因子XII、因子XIIa、因子XIII、因子XIIIa、TFPI、抗凝血酶III、EPCR、血栓调节素(thrombomodulin)、TAPI、tPA、血纤维蛋白溶酶原(plasminogen)、血纤维蛋白溶酶、PAI-1、PAI-2、GPC3、Syndecan-1、Syndecan-2、Syndecan-3、Syndecan-4、LPA、S1P、乙酰胆碱受体、AdipoR1、AdipoR2、ADP核糖环化酶-1、α-4/β-7整合素、α-5/β-1整合素、α-v/β-6整合素、αvβ1整合素、血管生成素配体-2、Angptl2、炭疽(Anthrax)、钙粘蛋白、碳酸酐酶-IX、CD105、CD155、CD158a、CD37、CD49b、CD51、CD70、CD72、紧密连接蛋白(Claudin)18、艰难梭菌毒素、CS1、Delta样蛋白配体4、DHICA氧化酶、Dickkopf-1配体、二肽基肽酶IV、EPOR、RSV的F蛋白、因子Ia、FasL、叶酸受体α、胰高血糖素受体、胰高血糖素样肽1受体、谷氨酸羧肽酶II、GMCSFR、丙型肝炎病毒E2糖蛋白、铁调素(Hepcidin)、IL-17受体、IL-22受体、IL-23受体、IL-3受体、Kit酪氨酸激酶、富亮氨酸α-2-糖蛋白1(LRG1)、溶血鞘脂(Lysosphingolipid)受体、膜糖蛋白OX2、间皮素(Mesothelin)、MET、MICA、MUC-16、髓磷脂相关糖蛋白、神经纤毛蛋白-1、神经纤毛蛋白-2、Nogo受体、PLXNA1、PLXNA2、PLXNA3、PLXNA4A、PLXNA4B、PLXNB1、PLXNB2、PLXNB3、PLXNC1、PLXND1、程序化细胞死亡配体1、前蛋白转化酶PC9、P-选择素糖蛋白配体-1、RAGE、Reticulon 4、RF、RON-8、SEMA3A、SEMA3B、SEMA3C、SEMA3D、SEMA3E、SEMA3F、SEMA3G、SEMA4A、SEMA4B、SEMA4C、SEMA4D、SEMA4F、SEMA4G、SEMA5A、SEMA5B、SEMA6A、SEMA6B、SEMA6C、SEMA6D、SEMA7A、Shiga样毒素II、鞘氨醇-1-磷酸盐受体-1、ST2、葡萄球菌脂磷壁酸、腱蛋白(Tenascin)、TG2、胸腺基质淋巴细胞生成素蛋白(thymic stromal lymphopoietin)受体、TNF超家族受体12A、跨膜糖蛋白NMB、TREM-1、TREM-2、滋养层(Trophoblast)糖蛋白、TSH受体、TTR、微管蛋白、ULBP2以及激素及生长因子的受体。此外,还可举例为所述受体中在生物体的体液中不锚定于细胞上而是以可溶形式存在的分子。
表示抗原中存在的抗原决定基的表位,是指本说明书中公开的抗原结合分子中的抗原结合结构域所结合的抗原上的部位。因此,例如,表位是根据其结构而被定义的。此外,还可根据识别该表位的抗原结合分子中针对抗原的活性,来对表位进行定义。抗原为肽或多肽的情况下,还可通过构成表位的氨基酸残基来对表位进行特定。此外,表位为糖链的情况下,还可通过特定的糖链结构来对表位进行特定。
线性表位是包含识别氨基酸一级序列的表位的表位。线性表位典型地在固有的序列中含有至少3个氨基酸,最常见而言在固有的序列中含有至少5个、例如约8个~约10个、6个~20个氨基酸。
与线性表位相对,立体构象表位为下述表位:其中包含表位的氨基酸的一级序列并非被识别的表位的单一规定成分(例如,其氨基酸的一级序列不一定能被规定表位的抗体识别的表位)。立体构象表位有可能包含对于线性表位而言增加的数量的氨基酸。与立体构象表位的识别相关,抗体识别肽或蛋白质的三级结构。例如,蛋白质分子折叠形成三级结构的情况下,形成立体构象表位的某氨基酸和/或多肽主链成为平行排列的状态,抗体得以能够识别表位。确定表位的立体结构的方法包括例如X射线结晶法、二维核磁共振分光法以及位点特异性自旋标记及电子顺磁共振分光法,但不限于这些。例如,参照EpitopeMapping Protocols in Methods in Molecular Biology(1996),第66卷,Morris(编著)。
用语“密码子组合”指用于编码期望的氨基酸的一组不同的核苷酸三联体序列。一组寡核苷酸包括编码期望的氨基酸群的序列,所述序列表示由密码子组合提供的核苷酸三联体的全部组合。这样的一组寡核苷酸例如可通过固相法来合成。标准的密码子指定形式为IUB编码的那样,该编码是本技术领域公知的。密码子组合一般表示为3个大写字母,例如NNK、NNS、DVK、DVD等。
IUB编码
G:鸟嘌呤
A:腺嘌呤
T:胸腺嘧啶
C:胞嘧啶
R(A或G)
Y(C或T)
M(A或C)
K(G或T)
S(C或G)
W(A或T)
H(A、C或T)
B(C、G或T)
V(A、C或G)
D(A、G或T)
N(A、C、G或T)
例如,密码子组合DVK中,D为核苷酸A或G或T、V为A或G或C、K为G或T。该密码子组合表示18个不同的密码子,可编码氨基酸Ala、Trp、Tyr、Lys、Thr、Asn、Lys、Ser、Arg、Asp、Glu、Gly和Cys。
在特定的位置具有“简并”核苷酸的寡核苷酸的设计方法是本发明所属的技术领域中公知的(例如Garrard and Henner,Gene(1993)128,103-109等)。具有这样的某种密码子组合的寡核苷酸组合可使用市售的核酸合成仪(可从Applied Biosystems,FosterCity,CA获得)合成,或者可购买市售品(例如Life Technologies,Rockville,MD)。因此,具有特定的密码子组合的合成寡核苷酸组合一般含有不同序列的多个寡核苷酸。此外,作为本发明的非限定性的方式,例如还可包含对克隆有用的限制性酶位点。
“细胞”、“细胞系”和“细胞培养”在本说明书中可作为相同含义使用,这样的称呼中也包含细胞系的全部后代。由此,例如,“转化体”或“转化细胞”这样的用语包含与传代数无关的来自它们的一级目标细胞和培养物。还应当理解,由于刻意或偶然的突变,全部后代中DNA的内容不一定完全相同。对最初的转化细胞进行筛选而得的具有实质上相同的功能或生物学活性的变体的后代也可包括在内。在记载了意指不同的称呼的情况下,将从该记载的上下文关系中明白其意指。
提到编码序列的表达的情况下的用语“控制序列”,是指为了在特定的宿主生物中可作用地连接的编码序列的表达而必需的DNA碱基序列。例如,适用于原核生物的控制序列包括启动子、根据需要的操纵子序列、核糖体结合位点、以及可能还有尚未被完全理解的其它序列。真核细胞中,为表达编码序列,利用启动子、聚腺苷化信号以及增强子是公知的。
与核酸相关的“可作用地连接”表示该核酸与其它核酸序列在功能上相关。例如,前序列(presequence)或分泌引导序列的DNA作为与某多肽的分泌相关的前体蛋白质表达的情况下,与该多肽的DNA以可发挥作用的方式结合。启动子或增强子在影响某编码序列的转录的情况下与该序列可作用地连接。此外,核糖体结合部在其位于翻译容易的位置的情况下与编码序列可作用地连接。通常,“可作用地连接”表示结合的DNA序列连续、在分泌引导序列的情况下连续且位于读码框内。但是,增强子则没有连续的必要。连接通过在限制性位点连接而实现。不存在这样的位点的情况下,按照惯常的方法使用合成寡核苷酸适体(adapter)或接头。此外,还可通过前述重叠·延伸PCR的手段制作连接的核酸。
“连接”指在两条核酸片断之间形成磷酸二酯键的方法。为了连接两条片断,片断的末端必须要相互适合。根据情况,进行内切核酸酶消化之后其末端即具有适合性。但是为了使其适合连接,首先,必须要将内切核酸酶消化之后形成的粘附末端变为平末端。为了成为平末端,将在合适的缓冲液中,于15℃、在4种脱氧核糖核苷酸三磷酸存在下、用约10单位的DNA聚合酶I或T4 DNA聚合酶的Klenow片断对DNA处理至少15分钟。接着,通过苯酚·氯仿提取和乙醇沉淀或者二氧化硅纯化,对DNA进行纯化。将待连接的DNA片断以等摩尔量加入到溶液中。该溶液中除了ATP、连接酶缓冲液之外,T4 DNA连接酶那样的连接酶以相对于每0.5μg DNA而言约10个单位被含有。将DNA连接于载体的情况下,首先利用合适的限制性内切核酸酶通过消化作用使载体线性化。接着通过用细菌的碱性磷酸或幼牛肠道磷酸酶对线性化的片断进行处理,防止该片断在连接步骤中自身连接。
用语“外壳蛋白质”指蛋白质中至少一部分存在于病毒粒子表面的蛋白质。从功能上的观点来看,外壳蛋白指在病毒于宿主细胞中的构建过程中与病毒粒子结合的任何蛋白质,在直到病毒感染其它宿主细胞之前保持与病毒的结合状态。外壳蛋白质可以是主要外壳蛋白质,也可以是次要外壳蛋白质。次要外壳蛋白质为通常存在于病毒衣壳中的外壳蛋白质,优选地,每1个病毒粒(virion)中存在至少约5个、更优选至少约7个、更优选至少约10个上述蛋白质的拷贝。主要外壳蛋白质可以以相对1个病毒粒而言数十个、数百个或者数千个的拷贝存在。作为主要外壳蛋白指的例子,可举出纤维状噬菌体的p8蛋白质。
特定的测定中,某化学无机物质、有机物质、生物等物体的“检测限”指在该测定中以高于背景水平而被检测到的该物体的最小限度的浓度。例如,噬菌体ELISA中,呈示特定抗原结合片断的特定噬菌体的“检测限”指特定噬菌体产生比由不呈示该抗原结合片断的对照噬菌体所产生ELISA信号多的ELISA信号的噬菌体浓度。
“噬菌体展示”是将变体多肽在噬菌体、例如纤维桩噬菌体的粒子表面作为与外壳蛋白质的至少一部分融合的蛋白质呈示的手段。噬菌体展示的有用性体现在:能从随机化蛋白质变体的大文库迅速、高效地选择辨别出与对象抗原以高亲和性结合的序列。肽和蛋白质文库在噬菌体上的呈示,被用于对数百万量级的多肽与特异性结合特性相关地进行筛选。多价噬菌体展示方法,被用于通过与纤维状噬菌体的基因III或基因VIII的融合来呈示小的随机肽和小蛋白质(Wells及Lowman(Curr.Opin.Struct.Biol.(1992)3,355-362)和其中的引用文献)。一价噬菌体展示中,蛋白质或肽的文库与基因III或其一部分融合,噬菌体粒子在野生型基因III蛋白质的存在下以低水平表达,以呈示融合蛋白质的1个或0个拷贝。因为亲和力效果比多价噬菌体低,因此筛选是基于内在的配体亲和性、使用噬粒载体进行的,该载体使得DNA操作单纯化(Lowman和Wells、Methods:A Companion to Methods inEnzymology(1991)3,205-216)。
“噬粒”为具有细菌的复制起点、例如Co1E1和噬菌体的基因间区域的拷贝的质粒载体。关于噬粒,还可适当地使用任何公知的噬菌体、例如纤维状噬菌体以及λ型噬菌体。质粒通常也包含抗生素耐性的选择标志物。在这些载体中克隆的DNA片断能够作为质粒增殖。导入了这些载体的细胞具备噬菌体粒子的生产所必需的全部基因时,质粒的复制模式变化为滚环型(rolling cycle)复制,生成质粒DNA的一条链的拷贝与包装噬菌体粒子。噬粒能够形成感染性或非感染性噬菌体粒子。该用语包括下述噬粒,所述噬粒包含:以基因融合的方式与该异源多肽的基因结合以使异源多肽在噬菌体粒子的表面呈示的、噬菌体外壳蛋白质基因或其片断。
用语“噬菌体载体”意指含有异源基因并能够复制的噬菌体的双链复制型。噬菌体载体具有使得噬菌体能够复制并且噬菌体粒子能够形成的噬菌体复制起点。噬菌体优选为纤维状噬菌体,例如M13、f1、fd、Pf3噬菌体或其衍生物,或λ型噬菌体,例如λ、21、phi80、phi81、82、424、434等或其衍生物。
“寡核苷酸”为通过公知的方法(例如,利用固相手段、例如EP266032中记载的手段的磷酸三酯、亚磷酸盐或亚磷酰胺化学法,或Froeshler等人(Nucl.Acids.Res.(1986)14,5399-5407)中记载的通过脱氧核苷酸H-膦酸盐中间体的方法)化学合成的短的单链或双链的多聚脱氧核苷酸。其它方法包括下文记载的聚合酶链式反应或其它自动引物法以及在固体载体上的寡核苷酸合成。这些方法全部被记载于Engels等(Agnew.Chem.Int.Ed.Engl.(1989)28,716-734)中。基因的全部核酸序列是公知的话,或者能够利用与编码链互补的核酸的序列的话,则可使用这些方法。或者,对象氨基酸序列是公知的话,则可使用各氨基酸残基的公知优选的编码残基适当地推测可能的核酸序列。寡核苷酸可通过聚丙烯酰胺凝胶或分子尺寸排除色谱、或通过沉淀法来纯化。
用语“融合蛋白质”和“融合多肽”指具有以共价键相互键合的2个部分的多肽,其为各部分具有不同特性的多肽。该特性可为例如体外或体内活性等生物学性质。此外,该特性可为单一的化学性质或物理性质,例如与对象抗原的结合、反应的催化剂等。该2个部分可通过单一的肽键直接键合,或经由包含1个或多个氨基酸残基的肽接头而键合。通常、该2个部分与接头存在于相同读码框中。优选地,多肽的2个部分是从异源或不同的多肽获得的。
用语“异源DNA”指导入宿主细胞中的任意的DNA。DNA可来自各种各样的来源,包括基因组DNA、cDNA、合成DNA以及它们的融合或组合。DNA可包括来自与宿主或受体细胞相同的细胞或细胞型的DNA或者来自不同的细胞型、例如哺乳类或植物的DNA。DNA可任选地包括标志物或选择性基因,例如抗生素耐性基因、耐热性基因等。
如本说明书中使用的,用语“非常多样化的位置”是指:与公知的和/或天然抗体或抗原结合片断的氨基酸序列进行比较时,在该位置中具有数个不同的氨基酸的轻链和重链可变区上的氨基酸的位置。非常多样化的位置一般存在于CDR区。在一种实施方式中,确定公知的和/或天然抗体的非常多样化的位置时,Kabat,Sequences of Proteins ofImmunological Interest(National Institute of Health Bethesda Md.)(1987年和1991年)提供的数据是有效的。此外,互联网上的多个数据库(http://vbase.mrc-cpe.cam.ac.uk/、http://www.bioinf.org.uk/abs/index.html)中提供了收集的多种人轻链和重链的序列及其配置,这些序列及其配置的信息对于确定本发明中非常多样化的位置是有用的。根据本发明,氨基酸在某个位置上具有优选约2~约20、优选约3~约19、优选约4~18、优选约5~17、优选为6~16、优选约7~15、优选约8~14、优选约9~13、优选约10~12个可能的不同氨基酸残基的多样性的情况下,该位置可被称为非常多样。在数个实施方式中,某个氨基酸位置上可具有优选至少约2、优选至少约4、优选至少约6、优选至少约8、优选约10、优选约12个可能的不同氨基酸残基的多样性。本说明书中,这样的氨基酸残基也可被称为灵活(flexible)残基。用语“非随机密码子组合”指编码下述氨基酸的密码子组合,所述氨基酸是部分地或优选完全地满足本说明书中记载的用于氨基酸选择的标准而选择出的氨基酸。此外,如本说明书中使用的,用语“随机密码子组合”是指将编码下述氨基酸的密码子被组合而得的密码子组合,所述氨基酸是20个氨基酸(Ala/A、Leu/L、Arg/R、Lys/K、Asn/N、Met/M、Asp/D、Phe/F、Cys/C、Pro/P、Gln/Q、Ser/S、Glu/E、Thr/T、Gly/G、Trp/W、His/H、Tyr/Y、Ile/I、Val/V)中任意的氨基酸。
根据某一实施方式,本发明提供了主要由互相之间序列不同的多个抗原结合分子构成的文库,所述抗原结合分子中的抗原结合结构域包含至少一个下述氨基酸残基,所述氨基酸残基使得抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化。作为离子浓度的例子可优选举出金属离子浓度、氢离子浓度。
本说明书中,“文库”指多个抗原结合分子或多个包含抗原结合分子的融合多肽,或者编码这些序列的核酸、多核苷酸。文库中包含的多个抗原结合分子或多个包含抗原结合分子的融合多肽的序列并非单一的序列,而是互相之间序列不同的抗原结合分子或包含抗原结合分子的融合多肽。
本说明书中,“金属离子”指除氢以外的碱金属以及铜族等的第I族、碱土金属和锌族等的第II族、除硼之外的第III族、除碳和硅以外的第IV族、铁族和铂族等的第VIII族、属于V、VI和VII族的各A亚族中的元素、和锑、铋、钋等的金属元素的离子。金属原子具有释放原子价电子成为阳离子的性质,这被称为离子化倾向。离子化倾向大的金属被认为富有化学活性。
作为本发明中优选的金属离子的例子,可举出钙离子。钙离子与对多种生命现象的调节相关,钙离子参与骨骼肌、平滑肌和心肌等肌肉的收缩、白细胞的运动和吞噬等的活化、血小板的变形和分泌等的活化、淋巴细胞的活化、组氨酸的分泌等肥大细胞的活化、由儿茶酚胺α受体、乙酰胆碱受体介导的细胞的应答、胞吐作用、从神经元末梢的递质释放、神经元的轴突流。作为细胞内的钙离子受体,已知有具有多个钙离子结合位点、被认为在分子进化上来自共同起源的肌钙蛋白C、钙调蛋白、小清蛋白、肌球蛋白轻链等,其结合基序多数也是已知的。例如熟知的有:钙粘蛋白结构域、钙调蛋白中含有的EF-HAND、蛋白激酶C中含有的C2结构域、血液凝固蛋白质因子IX中含有的Gla结构域、无唾液酸糖蛋白受体和甘露糖结合受体中含有的C型凝集素、LDL受体中含有的A结构域、膜联蛋白、血小板反应蛋白3型结构域和EGF样结构域。
本发明中,金属离子为钙离子的情况下,作为钙离子浓度的条件,可举出低钙离子浓度的条件和高钙离子浓度的条件。结合活性根据钙离子浓度的条件而变化指:抗原结合分子针对抗原的结合活性根据低钙离子浓度和高钙离子浓度的条件不同而变化。例如可举出:较之在低钙离子浓度的条件下抗原结合分子针对抗原的结合活性而言,在高钙离子浓度的条件下抗原结合分子针对抗原的结合活性更高的情况。此外,也还可举出:较之在高钙离子浓度的条件下抗原结合分子针对抗原的结合活性而言,在低钙离子浓度的条件下抗原结合分子针对抗原的结合活性更高的情况。
本说明书中,高钙离子浓度并不被特别限定为某个明确的数值,但优选可为选自100μM~10mM之间的浓度。此外,在一些其它方式中,也可为选自200μM~5mM之间的浓度。此外,在不同的实施方式中,还可为选自500μM~2.5mM之间的浓度,在另外的实施方式中,还可为选自200μM~2mM之间的浓度。此外,还可为选自400μM~1.5mM之间的浓度。特别地,可优选举出选自与生物体内的血浆中(血中)的钙离子浓度接近的、500μM~2.5mM之间的浓度。
本说明书中,低钙离子浓度并不被特别限定为某个明确的数值,但优选可为选自0.1μM~30μM之间的浓度。此外,在一些其它实施方式中,也可为选自0.2μM~20μM之间的浓度。此外,在不同的实施方式中,还可为选自0.5μM~10μM之间的浓度,在另外的实施方式中,还可为选自1μM~5μM之间的浓度。此外,还可为选自2μM~4μM之间的浓度。特别地,可优选举出选自与生物体内的早期核内体内的钙离子浓度接近的、1μM~5μM之间的浓度。
本发明中,“抗原结合分子在低钙离子浓度条件下针对抗原的结合活性比在高钙离子浓度条件下针对抗原的结合活性低”表示:抗原结合分子在选自0.1μM~30μM之间的钙离子浓度下针对抗原的结合活性比在选自100μM~10mM之间的钙离子浓度下针对抗原的结合活性弱。优选表示:抗原结合分子在0.5μM~10μM之间的钙离子浓度下针对抗原的结合活性比在选自200μM~5mM之间的钙离子浓度下针对抗原的结合活性弱,特别优选表示:在生物体内的早期核内体内的钙离子浓度下的抗原结合活性比在生物体内的血浆中的钙离子浓度下的抗原结合活性弱,具体而言,表示:抗原结合分子在选自1μM~5μM之间的钙离子浓度下针对抗原的结合活性比在选自500μM~2.5mM之间的钙离子浓度下针对抗原的结合活性弱。
抗原结合分子针对抗原的结合活性是否根据离子浓度的条件而变化可使用公知的测定方法来确定。例如,为了确认到较之在低钙离子浓度的条件下抗原结合分子针对抗原的结合活性而言、在高钙离子浓度的条件下抗原结合分子针对抗原的结合活性变高,可以对低钙离子浓度和高钙离子浓度的条件下抗原结合分子针对抗原的结合活性进行比较。
进而,本发明中,“抗原结合分子在低钙离子浓度条件下针对抗原的结合活性比在高钙离子浓度条件下针对抗原的结合活性低”这样的表述也表示:抗原结合分子在高钙离子浓度条件下针对抗原的结合活性比在低钙离子浓度条件下的针对抗原的结合活性高。需要说明的是,本发明中,“在低钙离子浓度条件下的抗原结合活性比在高钙离子浓度条件下针对抗原的结合活性低”有时也记载为“在低钙离子浓度条件下的抗原结合能力比在高钙离子浓度条件下针对抗原的结合能力弱”,此外,“使在低钙离子浓度条件下的抗原结合活性与在高钙离子浓度条件下针对抗原的结合活性相比较低”有时也记载为“使在低钙离子浓度条件下的抗原结合能力比在高钙离子浓度条件下针对抗原的结合能力弱”。
测定对抗原的结合活性时除钙离子浓度以外的条件是本领域技术人员可适当选择的,没有特别限定。例如,可在HEPES缓冲液、37℃的条件下进行测定。例如,可使用Biacore(GE Healthcare)等进行测定。关于对抗原结合分子与抗原的结合活性的测定,当抗原为可溶型抗原时,可通过向固定化有抗原结合分子的芯片流动作为待分析物的抗原,来评价对可溶型抗原的结合活性,当抗原为膜型抗原时,可通过向固定化有抗原的芯片流动作为待分析物的抗原结合分子,来评价对膜型抗原的结合活性。
本发明的抗原结合分子中,只要在低钙离子浓度条件下针对抗原的结合活性比在高钙离子浓度条件下针对抗原的结合活性弱即可,对低钙离子浓度条件下针对抗原的结合活性和高钙离子浓度条件下针对抗原的结合活性之比没有特别限定,优选针对抗原而言在低钙离子浓度条件下的KD(Dissociation constant:解离常数)与在高钙离子浓度条件下的KD之比KD(Ca 3μM)/KD(Ca 2mM)的值为2以上,进一步优选KD(Ca 3μM)/KD(Ca 2mM)的值为10以上,进一步优选KD(Ca 3μM)/KD(Ca 2mM)的值为40以上。KD(Ca 3μM)/KD(Ca 2mM)的值的上限没有特别限定,只要本领域技术人员的技术可制作,则可为400、1000、10000等、或任意值。此外,还可对KD(Ca 3μM)/KD(Ca 1.2mM)的值加以特定。即,KD(Ca 3μM)/KD(Ca1.2mM)的值为2以上,进一步优选KD(Ca 3μM)/KD(Ca 1.2mM)的值为10以上,进一步优选KD(Ca 3μM)/KD(Ca 1.2mM)的值为40以上。KD(Ca 3μM)/KD(Ca 1.2mM)的值的上限没有特别限定,只要本领域技术人员的技术可制作,则可为400、1000、10000等、或任意值。
作为针对抗原的结合活性的值,在抗原为可溶型抗原的情况下可使用KD(解离常数),但在抗原为膜型抗原的情况下可使用表观KD(Apparent dissociation constant:表观解离常数)。KD(解离常数)以及表观KD(表观解离常数)可通过本领域技术人员公知的方法来测定,例如可以使用Biacore(GE healthcare)、Scatchard作图、或流式细胞仪等。
此外,作为表示本发明的抗原结合分子在低钙浓度条件下针对抗原的结合活性与在高钙浓度条件下针对抗原的结合活性之比的其它指标,例如还可优选使用解离速度常数kd(Dissociation rate constant:解离速度常数)。作为表示结合活性之比的指标使用kd(解离速度常数)代替KD(解离常数)的情况下,针对抗原而言低钙浓度条件下的kd(解离速度常数)与高钙浓度条件下的kd(解离速度常数)之比、即kd(低钙浓度条件下)/kd(高钙浓度条件下)的值优选为2以上,进一步优选为5以上,进一步优选为10以上,更优选为30以上。kd(低钙浓度条件下)/kd(高钙浓度条件下)的值的上限没有特别限定,只要根据本领域技术人员的技术常识可制作,则可为50、100、200等、或任意值。
作为抗原结合活性的值,在抗原为可溶型抗原的情况下可使用kd(解离速度常数),在抗原为膜型抗原的情况下可使用表观kd(Apparent dissociation rate constant:表观解离速度常数)。kd(解离速度常数)和表观kd(表观解离速度常数)可使用本领域技术人员公知的方法进行测定,例如可使用Biacore(GE healthcare)、流式细胞仪等。需要说明的是,本发明中,对不同的钙离子浓度下抗原结合分子针对抗原的结合活性进行测定时,钙浓度以外的条件优选为相同。
本发明中,质子即氢原子的原子核的浓度的条件与氢指数(pH)的条件被视为相同含义。水溶液中的氢离子的活性量以a
本发明中,作为氢离子浓度的条件使用pH的条件的情况下,作为pH的条件可举出pH酸性区域的条件和pH中性区域的条件。结合活性根据pH的条件而变化是指:抗原结合分子针对抗原的结合活性根据pH酸性区域和pH中性区域的条件不同而变化。例如可举出:较之在pH酸性区域的条件下抗原结合分子针对抗原的结合活性而言,在pH中性区域的条件下抗原结合分子针对抗原的结合活性更高的情况。此外,也还可举出:较之在pH中性区域的条件下抗原结合分子针对抗原的结合活性而言,在pH酸性区域的条件下抗原结合分子针对抗原的结合活性更高的情况。
本说明书中,pH中性区域并不被特别限定为某个明确的数值,但优选可选自pH6.7~pH10.0之间。此外,在一些其它实施方式中,可选自pH6.7~pH9.5之间。此外,在不同的实施方式中,还可选自pH7.0~pH9.0之间,在另外的实施方式中,还可选自pH7.0~pH8.0之间。特别地,可优选举出选自与生物体内的血浆中(血中)的pH接近的pH 7.4。
本说明书中,pH酸性区域并不被特别限定为某个明确的数值,但优选可选自pH4.0~pH6.5之间。此外,在一些其它实施方式中,可选自pH4.5~pH6.5之间。此外,在不同的实施方式中,还可选自pH5.0~pH6.5之间,在另外的实施方式中,还可选自pH5.5~pH6.5之间。特别地,可优选举出选自与生物体内的早期核内体内的pH接近的pH 5.8。
本发明中,抗原结合分子在pH酸性区域条件下针对抗原的结合活性比在pH中性区域条件下针对抗原的结合活性低表示:抗原结合分子在选自pH4.0~pH6.5之间的pH下针对抗原的结合活性比在选自pH6.7~pH10.0之间的pH下针对抗原的结合活性弱。优选表示:抗原结合分子在选自pH4.5~pH6.5之间的pH下针对抗原的结合活性比在选自pH6.7~pH9.5之间的pH下针对抗原的结合活性弱,更优选表示:抗原结合分子在选自pH5.0~pH6.5之间的pH下针对抗原的结合活性比在选自pH7.0~pH9.0之间的pH下针对抗原的结合活性弱。此外,优选表示:抗原结合分子在选自pH5.5~pH6.5之间pH下针对抗原的结合活性比在选自pH7.0~pH8.0之间的pH下针对抗原的结合活性弱。特别优选表示:在生物体内的早期核内体内的pH下的抗原结合活性比在生物体内的血浆中的pH下的抗原结合活性弱,具体而言,抗原结合分子在pH5.8下针对抗原的结合活性比在pH7.4下针对抗原的结合活性弱。
关于抗原结合分子针对抗原的结合活性是否根据pH的条件而变化,可例如通过测定在前述不同的pH的条件下的结合活性的方法来实施。例如,为了确认到较之在pH酸性区域的条件下抗原结合分子针对抗原的结合活性而言、在pH中性区域的条件下抗原结合分子针对抗原的结合活性变高,对pH酸性区域和pH中性区域的条件下抗原结合分子针对抗原的结合活性进行比较。
进而,本发明中,“抗原结合分子在pH酸性区域的条件下针对抗原的结合活性比在pH中性区域的条件下针对抗原的结合活性低”这样的表述也表示:抗原结合分子在pH中性区域的条件下针对抗原的结合活性比在pH酸性区域的条件下的针对抗原的结合活性高。需要说明的是,本发明中,“在pH酸性区域的条件下的抗原结合活性比在pH中性区域的条件下针对抗原的结合活性低”有时也记载为“在pH酸性区域的条件下的抗原结合能力比在pH中性区域的条件下针对抗原的结合能力弱”,此外,“使在pH酸性区域的条件下的抗原结合活性与在pH中性区域的条件下针对抗原的结合活性相比较低”有时也记载为“使在pH酸性区域的条件下的抗原结合能力比在pH中性区域的条件下针对抗原的结合能力弱”。
作为如上文所述使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的氨基酸残基的例子,例如,金属离子为钙离子的情况下,为形成钙结合基序的氨基酸即可,其种类不被限定。钙结合基序是本领域技术人员公知的,其已被详细记载(例如Springer等人(Cell(2000)102,275-277)、Kawasaki和Kretsinger(Protein Prof.(1995)2,305-490)、Moncrief等人(J.Mol.Evol.(1990)30,522-562)、Chauvaux等人(Biochem.J.(1990)265,261-265)、Bairoch和Cox(FEBS Lett.(1990)269,454-456)、Davis(New Biol.(1990)2,410-419)、Schaefer等人(Genomics(1995)25,638~643)、Economou等人(EMBO J.(1990)9,349-354)、Wurzburg等人(Structure.(2006)14,6,1049-1058))。即,ASGPR、CD23、MBR、DC-SIGN等C型凝集素等任意的公知的钙结合基序包含在本发明的抗原结合分子中。上述之外,作为这样的钙结合基序的优选例子,如下文所述,还可举出具有Vk5-2等生殖细胞系的序列的抗体的轻链可变区中存在的Vk5的部分中包含的钙结合基序。
此外,作为使抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化的氨基酸残基的例子,还可优选使用具有金属螯合作用的氨基酸。作为具有金属螯合作用的氨基酸的例子,可优选举出例如丝氨酸(Ser(S))、苏氨酸(Thr(T))、天冬酰胺(Asn(N))、谷氨酰胺(Gln(Q))、天冬氨酸(Asp(D))和谷氨酸(Glu(E))等。
所述的包含氨基酸残基的抗原结合结构域的位置不限定于特定的位置,只要使得抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化即可,可为形成抗原结合结构域的重链可变区或轻链可变区中的任何位置。即,本发明的一种实施方式中,提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,使抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化的氨基酸残基被包含在重链的抗原结合结构域中。此外,其它一些实施方式中,提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,所述氨基酸残基被包含在重链的CDR3中。另一些实施方式中,提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,所述氨基酸残基被包含在重链的CDR3的Kabat编号法表示的第95位、96位、100a位和/或101位处。
此外,本发明的一种实施方式中,提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,使抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化的氨基酸残基被包含在轻链的抗原结合结构域中。此外,其它一些实施方式中,提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,所述氨基酸残基被包含在轻链的CDR1中。另一些实施方式中,提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,所述氨基酸残基被包含在轻链的CDR1的Kabat编号法表示的第30位、31位、和/或32位处。
此外,其它一些实施方式中,提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,所述氨基酸残基被包含在轻链的CDR2中。另一些实施方式中,提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,所述氨基酸残基被包含在轻链的CDR2的Kabat编号法表示的第50位处。
此外,其它一些实施方式中,提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,所述氨基酸残基被包含在轻链的CDR3中。另一些实施方式中,提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,所述氨基酸残基被包含在轻链的CDR3的Kabat编号法表示的第92位处。
此外,作为本发明的不同实施方式,还提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,所述氨基酸残基被包含在选自上文所述的轻链的CDR1、CDR2和CDR3中的2个或3个CDR中。此外,还提供了主要由互相之间序列不同的下述抗原结合分子构成的文库,所述抗原结合分子中,所述氨基酸残基被包含在轻链的以Kabat编号法表示的第30位、31位、32位、50位和/或92位中的任一处以上。
一种特别优选的实施方式中,抗原结合分子的轻链和/或重链可变区的框架序列优选具有人的生殖细胞系框架序列。因此,本发明的一种实施方式中,如果框架序列完全为人的序列的话,则认为在给予人的情况下(例如对疾病的治疗),本发明的抗原结合分子基本不或完全不引起免疫原性反应。从上述意义来看,本发明的“包含生殖细胞系的序列”表示本发明的框架序列的一部分与任何的人的生殖细胞系框架序列的一部分相同。例如,本发明的抗原结合分子的重链FR2的序列为多个不同的人的生殖细胞系框架序列的重链FR2序列组合而得的序列的情况下,其仍是本发明的“包含生殖细胞系的序列”的抗原结合分子。
作为框架的例子,可优选举出例如V-Base(http://vbase.mrc-cpe.cam.ac.uk/)等网站中包含的现在已知的完全人源性的框架区的序列。这些框架区的序列可作为本发明的抗原结合分子中包含的生殖细胞系的序列适当地使用。生殖细胞系的序列可基于其相似性被分类(Tomlinson等人(J.Mol.Biol.(1992)227,776-798)、Williams和Winter(Eur.J.Immunol.(1993)23,1456-1461)、以及Cox等人(Nat.Genetics(1994)7,162-168))。可从分类进分为7个亚组的Vκ10的亚组中的Vλ、分成7个亚组的VH中适当地选择优选的生殖细胞系的序列。
完全人源性的VH序列不仅限于下述这些,但例如可优选举出VH1亚组(例如、VH1-2、VH1-3、VH1-8、VH1-18、VH1-24、VH1-45、VH1-46、VH1-58、VH1-69)、VH2亚组(例如、VH2-5、VH2-26、VH2-70)、VH3亚组(VH3-7、VH3-9、VH3-11、VH3-13、VH3-15、VH3-16、VH3-20、VH3-21、VH3-23、VH3-30、VH3-33、VH3-35、VH3-38、VH3-43、VH3-48、VH3-49、VH3-53、VH3-64、VH3-66、VH3-72、VH3-73、VH3-74)、VH4亚组(VH4-4、VH4-28、VH4-31、VH4-34、VH4-39、VH4-59、VH4-61)、VH5亚组(VH5-51)、VH6亚组(VH6-1)、VH7亚组(VH7-4、VH7-81)的VH序列等。这些也被记载于公知文献(Matsuda等人(J.Exp.Med.(1998)188,1973-1975))等中,本领域技术人员能够根据这些序列信息来适当地设计本发明的抗原结合分子。这些以外的完全人源性的框架或准框架区也可优选被使用。
完全人源性的VK序列不仅限于下述这些,但例如可优选举出分类为Vk1亚组中的A20、A30、L1、L4、L5、L8、L9、L11、L12、L14、L15、L18、L19、L22、L23、L24、O2、O4、O8、O12、O14、O18,分类为Vk2亚组中的A1、A2、A3、A5、A7、A17、A18、A19、A23、O1、O11,分类为Vk3亚组中的A11、A27、L2、L6、L10、L16、L20、L25,分类为Vk4亚组中的B3、分类为Vk5亚组中的B2(本说明书中还称为Vk5-2)、分类为Vk6亚组中的A10、A14、A26等(Kawasaki等人(Eur.J.Immunol.(2001)31,1017-1028)、Schable和Zachau(Biol.Chem.Hoppe Seyler(1993)374,1001-1022)和Brensing-Kuppers等人(Gene(1997)191,173-181))。
完全人源性的VL序列不仅限于下述这些,但例如可优选举出分类为VL1亚组中的V1-2、V1-3、V1-4、V1-5、V1-7、V1-9、V1-11、V1-13、V1-16、V1-17、V1-18、V1-19、V1-20、V1-22,分类为VL2亚组中的V2-1、V2-6、V2-7、V2-8、V2-11、V2-13、V2-14、V2-15、V2-17、V2-19,分类VL3亚组中的V3-2、V3-3、V3-4,分类为VL4亚组中的V4-1、V4-2、V4-3、V4-4、V4-6,分类为VL5亚组中的V5-1、V5-2、V5-4、V5-6等(Kawasaki等人(Genome Res.(1997)7,250-261))。
通常,这些框架序列因一个或更多个的氨基酸残基的不同而互相不同。这些框架序列可与“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”共同使用。作为与本发明的“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”共同使用的完全人源性的框架的例子,不仅限于这些,除此之外还可举出KOL、NEWM、REI、EU、TUR、TEI、LAY、POM等(例如,Kabat等人(1991)和Wu等人(J.Exp.Med.(1970)132,211-250))。
虽然本发明不受特定理论束缚,但对使用生殖细胞系的序列排除几乎所有对个人有害的免疫反应有所期待的理由之一如下文所考虑的那样。作为通常的免疫反应中产生的亲和性成熟步骤的结果,免疫球蛋白的可变区中频繁发生体细胞的突变。虽然这些突变主要在序列为高度可变的CDR的周边产生,但是也会影响到框架区的残基。通常也认为这些框架的突变不存在于生殖细胞系的基因中、另外其导致患者免疫原性的可能性低。另一方面,通常的人群暴露给生殖细胞系的基因表达的框架序列中的大多数,因此预想:作为免疫耐性的结果,这些生殖细胞系的框架在患者中免疫原性低或者为非免疫原性的。为了使得免疫耐性的可能性最大,对可变区编码化的基因可选自通常存在的功能性的生殖细胞系基因簇。
为了制作本发明的“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”包含在所述框架序列中的抗原结合分子,可合适地采用位点特异性诱变法(Kunkel等人(Proc.Natl.Acad.Sci.USA(1985)82,488-492))、重叠·延伸PCR等公知的方法。
例如,通过将作为预先包含“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”的框架序列而选择的轻链可变区以及作为随机化可变区序列文库制作的重链可变区组合起来,可制作本发明的包含多个互相之间序列不同的抗原结合分子的文库。作为这样的非限定性的例子,离子浓度为钙离子浓度的情况下,例如,可优选举出将序列号1(Vk5-2)中记载的轻链可变区序列与作为随机化可变区序列文库而制作的重链可变区组合而得的文库。作为包含在具有上述Vk5-2等生殖细胞系序列的抗体轻链可变区中存在的Vk5结构域的轻链可变区序列的优选例,除了序列号1(Vk5-2)中记载的轻链可变区序列以外,还可合适地使用下文所述的序列号2表示的Vk5-2变体1或序列号3表示的Vk5-2变体2等。这些分子中包含的含有“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”的Vk5-2的部分,可作为本发明的包含钙结合基序的结构域使用。本发明的一种非限定性的实施方式中,形成钙结合基序的至少一个氨基酸可作为本发明的“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”而使用。
此外,所述作为预先包含“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”的框架序列而选择的轻链可变区的序列中,还可涉及为含有多样的氨基酸作为该氨基酸残基以外的残基。本发明中,这样的残基被称为灵活残基。只要本发明的抗原结合分子的针对抗原的结合活性根据离子浓度的条件而变化即可,对该灵活残基的数量和位置没有特定的方式上的限定。即,重链和/或轻链的CDR序列和/或FR序列中可包含一个或多个灵活残基。例如,离子浓度为钙离子的浓度的情况下,作为向序列号1(Vk5-2)记载的轻链可变区序列中导入的灵活残基的非限定性的例子,可举出表13、表14、表17或表18记载的氨基酸残基。
此外,也可将导入了所述“使得抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”的轻链可变区和作为随机化可变区序列文库制作的重链可变区组合起来,由此制作本发明的包含互相之间序列不同的多个抗原结合分子的文库。作为这样的非限定性的例子,离子浓度为钙离子浓度的情况下,优选可举出例如序列号6(Vk1)、序列号7(Vk2)、序列号8(Vk3)、序列号9(Vk4)等的生殖细胞系的特定的残基被“使抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化的至少一个氨基酸残基”取代而得的轻链可变区序列与作为随机化可变区序列文库制作的重链可变区组合而得的文库。作为该氨基酸残基的非限定性例子,可例示轻链的CDR1中含有的氨基酸残基。此外,作为该氨基酸残基的非限定性例子,还可例示轻链的CDR2中含有的氨基酸残基。此外,作为该氨基酸残基的非限定性的其它例子,还可例示轻链的CDR3中含有的氨基酸残基。
如前文所述,作为该氨基酸残基为包含在轻链的CDR1中的氨基酸残基的非限定性例子,可举出轻链可变区的CDR1中以Kabat编号法表示的第30位、31位和/或32位的氨基酸残基。此外,作为该氨基酸残基为包含在轻链的CDR2中的氨基酸残基的非限定性例子,可举出轻链可变区的CDR2中以Kabat编号法表示的第50位的氨基酸残基。进而,作为该氨基酸残基为包含在轻链的CDR2中的氨基酸残基的非限定性例子,可举出轻链可变区的CDR3中的以Kabat编号法表示的第92位的氨基酸残基。此外,这些氨基酸残基只要能形成钙结合基序、和/或、抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化即可,这些氨基酸残基可被单独含有,或者这些氨基酸可两个以上组合而被含有。此外,具有多个钙离子结合位点、被认为在分子进化上来自共同起源的肌钙蛋白C、钙调蛋白、小清蛋白、肌球蛋白轻链等是已知的,因此也可以以包含其结合基序的方式设计轻链CDR1、CDR2和/或CDR3。例如,为了上述目的,可适当地使用钙粘蛋白结构域、钙调蛋白中含有的EF-HAND、蛋白激酶C中含有的C2结构域、血液凝固蛋白质因子IX中含有的Gla结构域、无唾液酸糖蛋白受体和甘露糖结合受体中含有的C型凝集素、LDL受体中含有的A结构域、膜联蛋白、血小板反应蛋白3型结构域和EGF样结构域。
在将导入了前述“使抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化的至少一个氨基酸残基”的轻链可变区序列与作为随机化可变区序列文库制作的重链可变区组合的情况下,与前述相同,也可设计为使灵活残基被包含在该轻链可变区的序列中。本发明的抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化即可,对该灵活残基的数量和位置没有特定的方式上的限定。即,重链和/或轻链的CDR序列和/或FR序列中可包含一个或多个灵活残基。例如,离子浓度为钙离子的浓度的情况下,作为向轻链可变区序列中导入的灵活残基的非限定性的例子,可举出表13、表14、表17或表18记载的氨基酸残基。
作为被组合的重链可变区的例子,可优选举出随机化可变区文库。关于随机化可变区文库的制作方法,可适当地组合公知的方法。本发明的一种非限定性的实施方式中,基于下述抗体基因构建的免疫文库,可优选地作为随机化可变区文库而使用,所述抗体基因来自经特定抗原免疫的动物、感染症的患者和经疫苗接种从而血中抗体价数上升的人、癌患者、自身免疫性疾病患者的淋巴细胞。
此外,本发明的一种非限定性的实施方式中,基因组DNA中的V基因和改型的功能性V基因的CDR序列被包含编码适当长的密码子组合的合成寡核苷酸组合取代而得的合成文库也可作为随机化可变区文库而优选地使用。该情况下,因为观察到重链的CDR3的基因序列的多样性,因此还可仅取代CDR3的序列。抗原结合分子的可变区中氨基酸的多样性的产生基于使暴露于抗原结合分子表面的位置的氨基酸残基具有多样性。暴露于表面的位置是指:被判断为基于抗原结合分子的结构、结构的集合和/或模型化的结构从而可能暴露于表面、和/或可能与抗原接触的位置,一般而言是其CDR。优选地,可使用InsightII程序(Accelrys)这样的计算机程序,使用来自抗原结合分子的三维模型的坐标来确定暴露于表面的位置。暴露于表面的位置可使用本技术领域中公知的算法(例如、Lee和Richards(J.Mol.Biol.(1971)55,379-400)、Connolly(J.Appl.Cryst.(1983)16,548-558))来确定。暴露于表面的位置的确定可使用适合蛋白质建模的软件以及从抗体得到的三维结构信息来进行。作为能用于这样的目的的软件,可优选举出SYBYL生物体高分子模块软件(TriposAssociates)。一般而言,优选在算法需要用户输入尺寸参数的情况下,计算中使用的探针(proble)的“尺寸(size)”被设定为半径约1.4埃以下。进而,Pacios(Comput.Chem.(1994)18(4),377-386和J.Mol.Model.(1995)1,46-53)中记载了使用个人电脑用的软件来确定暴露于表面的区域及面积的确定方法。
进而,在本发明的非限定性的一种实施方式中,由来自健康人的淋巴细胞的抗体基因构建的、由在其所有组成成分(repertoire)中不含偏差的抗体序列即天然序列(Naive序列)构成的天然文库(Naive文库),也特别优选地作为随机化可变区文库使用(Gejima等人(Human Antibodies(2002)11,121-129)、和Cardoso等人(Scand.J.Immunol.(2000)51,337-344))。包含本发明中记载的天然序列的氨基酸序列是指:可从这样的天然文库获得的氨基酸序列。
本发明的一种实施方式中,将作为预先包含“使抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化的至少一个氨基酸残基”的框架序列而选择的重链可变区、与作为随机化可变区序列文库而制作的轻链可变区组合,由此制作本发明的包含多个互相之间序列不同的抗原结合分子的文库。作为这样的非限定性的例子,离子浓度为钙离子浓度的情况下,例如可优选举出将序列号10(6RL#9H-IgG1)或序列号11(6KC4-1#85H-IgG1)记载的重链可变区序列和作为随机化可变区序列文库制作的轻链可变区组合而得的文库。此外,代替作为随机化可变区序列文库而制作的轻链可变区,可通过从具有生殖细胞系的序列的轻链可变区中适当选择来制作文库。例如,可优选举出序列号10(6RL#9H-IgG1)或序列号11(6KC4-1#85H-IgG1)记载的重链可变区序列和具有生殖细胞系的序列的轻链可变区组合而得的文库。
此外,上述的作为预先包含“使抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化的至少一个氨基酸残基”的框架序列而选择的重链可变区的序列中,还可设计为含有灵活残基。只要本发明的抗原结合分子的针对抗原的结合活性根据离子浓度的条件而变化即可,对该灵活残基的数量和位置不限于特定方式。即,重链和/或轻链的CDR序列和/或FR序列中可包含一个或多个灵活残基。例如,离子浓度为钙离子的浓度的情况下,作为向序列号10(6RL#9H-IgG1)记载的重链可变区序列中导入的灵活残基的非限定性的例子,除重链CDR1和CDR2的全部氨基酸残基之外还可举出重链CDR3中除了第95位、96位和/或100a位以外的CDR3的氨基酸残基。此外,作为向序列号11(6KC4-1#85H-IgG1)记载的重链可变区序列中导入的灵活残基的非限定性的例子,除重链CDR1和CDR2的全部氨基酸残基之外还可举出重链CDR3中除了第95位和/或101位以外的CDR3的氨基酸残基。
此外,也可将上述的导入了“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”的重链可变区和作为随机化可变区序列文库制作的轻链可变区或具有生殖细胞系的序列的轻链可变区组合起来,由此制作本发明的包含互相之间序列不同的多个抗原结合分子的文库。作为这样的非限定性的例子,离子浓度为钙离子浓度的情况下,例如,可优选举出下述文库,即,重链可变区的特定的残基被“使抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化的至少一个氨基酸残基”取代的重链可变区序列与作为随机化可变区序列文库而制作的轻链可变区或具有生殖细胞系的序列的轻链可变区组合而得的文库。作为该氨基酸残基的非限定性例子,可例示重链的CDR1中含有的氨基酸残基。此外,作为该氨基酸残基的非限定性例子,还可例示重链的CDR2中含有的氨基酸残基。此外,作为该氨基酸残基的非限定性的其它例子,还可例示重链的CDR3中含有的氨基酸残基。作为该氨基酸残基为包含在重链的CDR3中的氨基酸残基的非限定性例子,可举出重链可变区的CDR3中以Kabat编号法表示的第95位、96位、100a位和/或101位的氨基酸残基。此外,这些氨基酸残基只要能形成钙结合基序、和/或、抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化即可,这些氨基酸残基可被单独含有,或者这些氨基酸可两个以上组合而被含有。
将上述的导入了“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”的重链可变区和作为随机化可变区序列文库制作的轻链可变区或具有生殖细胞系的序列的轻链可变区组合的情况下,与前述相同,也可设计为在该重链可变区的序列中含有灵活残基。只要本发明的抗原结合分子的针对抗原的结合活性根据离子浓度的条件而变化即可,对该灵活残基的数量和位置没有特定方式上的限定。即,重链和/或轻链的CDR序列和/或FR序列中可包含一个或多个灵活残基。此外,作为“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的氨基酸残基”以外的重链可变区的CDR1、CDR2和/或CDR3的氨基酸序列,还可优选使用随机化可变区文库。使用生殖细胞系的序列作为轻链可变区的情况下,作为非限定性的例子,可举出序列号6(Vk1)、序列号7(Vk2)、序列号8(Vk3)、序列号9(Vk4)等的生殖细胞系的序列。
作为上述的使抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化的氨基酸残基,只要能形成钙结合基序即可,可优选使用任何的氨基酸残基,作为这样的氨基酸残基,具体可举出具有电子供给性的氨基酸。作为这样具有电子供给性的氨基酸,可优选例示丝氨酸、苏氨酸、天冬酰胺、谷氨酰胺、天冬氨酸或谷氨酸。
作为本发明的一种实施方式,还可通过将导入了“使抗原结合分子针对抗原的结合活性根据氢离子浓度的条件而变化的至少一个氨基酸残基”的轻链可变区与作为随机化可变区序列文库而制作的重链可变区组合起来,来制作本发明的包含互相之间序列不同的多个抗原结合分子的文库。
作为该氨基酸残基的非限定性例子,可例示轻链的CDR1中包含的氨基酸残基。此外,作为该氨基酸残基的非限定性例子,可例示轻链的CDR2中包含的氨基酸残基。此外,作为该氨基酸残基的非限定性的其它例子,还可例示轻链的CDR3中包含的氨基酸残基。
如前文所述,作为该氨基酸残基为轻链的CDR1中包含的氨基酸残基的非限定性例子,可举出轻链可变区的CDR1中以Kabat编号法表示的第24位、27位、28位、30位、31位、32位和/或34位的氨基酸残基。此外,作为该氨基酸残基为轻链的CDR2中包含的氨基酸残基的非限定性例子,可举出轻链可变区的CDR2中以Kabat编号法表示的第50位、51位、52位、53位、54位、55位和/或56位的氨基酸残基。此外,作为该氨基酸残基为轻链的CDR3中包含的氨基酸残基的非限定性例子,可举出轻链可变区的CDR3中以Kabat编号法表示的第89位、90位、91位、92位、93位、94和/或95a位的氨基酸残基。此外,这些氨基酸残基只要能使抗原结合分子针对抗原的结合活性根据氢离子浓度的条件而变化即可,这些氨基酸残基可被单独含有,或者这些氨基酸可两个以上组合而被含有。
将上述的导入了“使抗原结合分子针对抗原的结合活性根据氢离子浓度的条件而变化的至少一个氨基酸残基”的轻链可变区和作为随机化可变区序列文库制作的重链可变区组合的情况下,与前述相同,也可设计为在该轻链可变区的序列中含有灵活残基。只要本发明的抗原结合分子的针对抗原的结合活性根据氢离子浓度的条件而变化即可,对该灵活残基的数量和位置不限于特定方式。即,重链和/或轻链的CDR序列和/或FR序列中可包含一个或多个灵活残基。例如,作为向轻链可变区序列中导入的灵活残基的非限定性例例子,可举出表4或表5中记载的氨基酸残基。此外,作为使抗原结合分子针对抗原的结合活性根据氢离子浓度的条件而变化的氨基酸残基、或灵活残基以外的轻链可变区的氨基酸序列,作为非限定性的例子,可优选使用Vk1(序列号6)、Vk2(序列号7)、Vk3(序列号8)、Vk4(序列号9)等的生殖细胞系的序列。
作为被组合的重链可变区的例子,可优选举出随机化可变区文库。关于随机化可变区文库的制作方法,可适当地组合公知的方法。本发明的一种非限定性的实施方式中,基于下述抗体基因构建的免疫文库,可优选地作为随机化可变区文库而使用,所述抗体基因来自经特定抗原免疫的动物、感染症的患者和经疫苗接种从而血中抗体价数上升的人、癌患者、自身免疫性疾病患者的淋巴细胞。
此外,本发明的非限定性的一种实施方式中,与前述相同,基因组DNA中的V基因和改型的功能性V基因的CDR序列被合成寡核苷酸组合(包含编码适当长的密码子组合的序列)取代而得的合成文库,也可作为随机化可变区文库而优选地使用。
此外,本发明的非限定性的一种实施方式中,由来自健康人的淋巴细胞的抗体基因构建、由在其所有组成成分中不含偏差的抗体序列即天然序列构成的天然文库,也可作为随机化可变区文库特别优选地使用(Gejima等人(Human Antibodies(2002)11,121-129)、和Cardoso等人(Scand.J.Immunol.(2000)51,337-344))。
作为本发明的其他方案,通过将上述的导入了“使抗原结合分子针对抗原的结合活性根据氢离子浓度的条件而变化的至少一个氨基酸残基”的重链可变区和作为随机化可变区序列文库制作的轻链可变区或具有生殖细胞系的序列的轻链可变区组合起来,来制作本发明的包含互相之间序列不同的多个抗原结合分子的文库。作为这样的非限定性的例子,可优选举出重链可变区的特定的残基被“使抗原结合分子针对抗原的结合活性根据氢离子浓度的条件而变化的至少一个氨基酸残基”取代的重链可变区序列与作为随机化可变区序列文库而制作的轻链可变区或具有生殖细胞系的序列的轻链可变区组合而得的文库。作为该氨基酸残基的非限定性例子,可例示重链的CDR1中含有的氨基酸残基。此外,作为该氨基酸残基的非限定性例子,还可例示重链的CDR2中含有的氨基酸残基。此外,作为该氨基酸残基的非限定性的其它例子,还可例示重链的CDR3中含有的氨基酸残基。
作为该氨基酸残基为包含在重链的CDR1中的氨基酸残基的非限定性例子,可举出重链可变区的CDR1中以Kabat编号法表示的第27位、31位、32位、33位和/或35位的氨基酸残基。作为该氨基酸残基为包含在重链的CDR2中的氨基酸残基的非限定性例子,可举出重链可变区的CDR2中以Kabat编号法表示的第50位、52位、53位、55位、57位、58位、59位、61位和/或62位的氨基酸残基。作为包含在重链的CDR3中的氨基酸残基的非限定性例子,可举出重链可变区的CDR3中以Kabat编号法表示的第95位、96位、97位、98位、99位、100a位、100b位、100d位、100f位、100h位、102位和/或107位的氨基酸残基。此外,这些氨基酸残基只要能使抗原结合分子针对抗原的结合活性根据氢离子浓度的条件而变化即可,这些氨基酸残基可被单独含有,或者这些氨基酸可两个以上组合而被含有。
将上述的导入了“使抗原结合分子针对抗原的结合活性根据氢离子浓度的条件而变化的至少一个氨基酸残基”的重链可变区和作为随机化可变区序列文库制作的轻链可变区或具有生殖细胞系的序列的轻链可变区组合的情况下,与前述相同,也可设计为在该重链可变区的序列中含有灵活残基。只要本发明的抗原结合分子的针对抗原的结合活性根据氢离子浓度的条件而变化即可,对该灵活残基的数量和位置没有特定方式上的限定。即,重链和/或轻链的CDR序列和/或FR序列中可包含一个或多个灵活残基。此外,作为“使抗原结合分子针对抗原的结合活性根据氢离子浓度的条件而变化的氨基酸残基”以外的重链可变区的CDR1、CDR2和/或CDR3的氨基酸序列,还可优选地使用随机化可变区文库。作为轻链可变区使用生殖细胞系的序列的情况下,作为限定性的例子,可举出序列号6(Vk1)、序列号7(Vk2)、序列号8(Vk3)、序列号9(Vk4)等的生殖细胞系的序列。
作为上述的使抗原结合分子针对抗原的结合活性根据氢离子浓度的条件而变化的氨基酸残基,可合适地使用任何氨基酸残基,作为这样的氨基酸残基,具体可举出侧链的pKa为4.0-8.0的氨基酸。作为这样具有电子供给性的氨基酸,除组氨酸或谷氨酸等天然的氨基酸以外,还可优选例示组氨酸类似物(US20090035836)或m-NO2-Tyr(pKa 7.45)、3,5-Br2-Tyr(pKa 7.21)或3,5-I2-Tyr(pKa 7.38)等的非天然的氨基酸(Bioorg.Med.Chem.(2003)11(17),3761-2768)。此外,作为该氨基酸残基的特别优选的例子,可举出侧链的pKa为5.5-7.0的氨基酸。作为这样的具有电子供给性的氨基酸,可优选例示组氨酸。
为了修饰抗原结合结构域的氨基酸,可适当地采用位点特异性诱变法(Kunkel等人(Proc.Natl.Acad.Sci.USA(1985)82,488-492))、重叠·延伸PCR等公知的方法。此外,作为取代为天然氨基酸以外的氨基酸的氨基酸修饰方法,也可采用多种公知的方法(Annu.Rev.Biophys.Biomol.Struct.(2006)35,225-249、Proc.Natl.Acad.Sci.U.S.A.(2003)100(11),6353-6357)。例如,还可优选地使用无细胞翻译系统(Clover Direct(Protein Express))等,所述无细胞翻译系统中,包含在作为终止密码子之一的UAG密码子(琥珀密码子)的互补琥珀抑制基因tRNA上结合了非天然氨基酸的tRNA。
作为被组合的轻链可变区的例子,可优选举出随机化可变区文库。关于随机化可变区文库的制作方法,可适当地组合公知的方法。本发明的一种非限定性的实施方式中,基于下述抗体基因构建的免疫文库,可优选地作为随机化可变区文库而使用,所述抗体基因来自经特定抗原免疫的动物、感染症的患者和经疫苗接种从而血中抗体价数上升的人、癌患者、自身免疫性疾病患者的淋巴细胞。
此外,本发明的一种非限定性的实施方式中,基因组DNA中的V基因和改型的功能性V基因的CDR序列被合成寡核苷酸组合(包含编码适当长的密码子组合的序列)取代而得的合成文库,也可作为随机化可变区文库而优选地使用。该情况下,观察到重链的CDR3的基因序列的多样性,因此还可仅取代CDR3的序列。抗原结合分子的可变区中产生氨基酸多样性的基准在于,使暴露于抗原结合分子表面的位置的氨基酸残基具有多样性。暴露于表面的位置是指:被判断为基于抗原结合分子的结构、结构的集合和/或模型化的结构从而可能暴露于表面、和/或可能与抗原接触的位置,一般而言是其CDR。优选地,可使用InsightII程序(Accelrys)这样的计算机程序,使用来自抗原结合分子的三维模型的坐标来确定暴露于表面的位置。暴露于表面的位置可使用本技术领域中公知的算法(例如、Lee和Richards(J.Mol.Biol.(1971)55,379-400)、Connolly(J.Appl.Cryst.(1983)16,548-558))来确定。暴露于表面的位置的确定可使用适合蛋白质建模的软件以及从抗体得到的三维结构信息来进行。作为能用于这样的目的的软件,可优选举出SYBYL生物体高分子模块软件(TriposAssociates)。一般而言,优选在算法需要用户输入尺寸参数的情况下,计算中使用的探针(proble)的“尺寸(size)”被设定为半径约1.4埃以下。进而,Pacios(Comput.Chem.(1994)18(4),377-386和J.Mol.Model.(1995)1,46-53)中记载了使用个人电脑用的软件来确定暴露于表面的区域及面积的确定方法。
此外,本发明的非限定性的一种实施方式中,由来自健康人的淋巴细胞的抗体基因构建、由其所有组成成分中不含偏差的抗体序列即天然序列构成的天然文库,也可作为随机化可变区文库特别优选地使用(Gejima等人(Human Antibodies(2002)11,121-129)、和Cardoso等人(Scand.J.Immunol.(2000)51,337-344))。
作为使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的氨基酸残基以外的氨基酸,只要本发明的抗原结合分子与抗原结合,则可使用任意的氨基酸,作为优选的例子,可适当地适用J.D.Marks等人(J.Mol.Biol.(1991)222,581-597)等的公知的抗体噬菌体展示文库技术。即,作为使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的氨基酸残基以外的氨基酸,可被采用于上述抗体噬菌体文库中。
本发明中的、在互相之间序列不同的多个抗原结合分子这样的记载中的“互相之间序列不同”的用语,表示文库中各抗原结合分子的序列相互之间不同。即,文库中互相之间不同的序列的数量反映了文库中的序列不同的独立克隆的数量,有时也被称为“文库大小”。通常的噬菌体展示文库为10
此外,本发明中的、主要由多个抗原结合分子构成的文库这样的记载中的“多个”的用语表示:例如,就本发明的抗原结合分子、融合多肽、多核苷酸分子、载体或病毒而言,通常该物质的2个以上的种类的集合。例如,某2个以上的物质在与特定的性状相关的方面互相之间不同的话,则表示该物质以2种以上存在。作为例子,可举出在氨基酸序列中的特定氨基酸位置观察到的变体氨基酸。例如,除了灵活残基以外、或者除了暴露于表面的非常多样化的氨基酸位置的特定的变体氨基酸以外,存在实质上相同、优选为同一序列的本发明的2条以上的抗原结合分子的情况下,本发明的抗原结合分子以多个存在。其它实施例中,除了编码灵活残基的碱基、或者除了编码暴露于表面的非常多样化的氨基酸位置的特定的变体氨基酸以外,存在实质上相同、优选为同一序列的本发明的2条以上的多核苷酸分子的情况下,本发明的多核苷酸分子以多个存在。
此外,本发明中的、主要由多个抗原结合分子构成的文库这样的记载中的“主要由……构成”的用语反映了文库中的序列不同的独立克隆的数量中、抗原结合分子针对抗原的结合活性根据离子浓度的条件而不同的抗原结合分子的数量。具体而言,优选地,显示这样的结合活性的抗原结合分子在文库中以至少10
本发明的一种实施方式中,可制作本发明的抗原结合分子和异源多肽的融合分子。某实施方式中,融合多肽可以是与病毒外壳蛋白质例如选自pIII、pVIII、pVII、pIX、Soc、Hoc、gpD、pVI及其变体构成的组的病毒外壳蛋白质的至少一部分融合而得的。
某实施方式中,本发明的抗原结合分子可以是ScFv、Fab片断、F(ab)2或F(ab’)2,在另一实施方式中,提供了主要由互相之间序列不同的多个融合分子构成的文库,所述融合分子为这些抗原结合分子和异源多肽的融合分子。具体而言,提供了主要由互相之间序列不同的多个融合分子构成的文库,所述融合分子为这些抗原结合分子和病毒外壳蛋白质例如选自pIII、pVIII、pVII、pIX、Soc、Hoc、gpD、pVI及其变体构成的组的病毒外壳蛋白质的至少一部分融合而得的融合蛋白质。本发明的抗原结合分子还可含有二聚体化结构域。某种实施方式中,所述二聚体化结构域可存在于抗体的重链或轻链的可变区与病毒外壳蛋白质的至少一部分之间。该二聚体化结构域中可包含二聚体化序列中的至少之一、和/或包含一个或多个半胱氨酸残基的序列。该二聚体化结构域优选可与重链可变区或恒定区的C末端连接。关于二聚体化结构域,基于所述抗体可变区是否作为与病毒的外壳蛋白质成分的融合蛋白质成分而被制作(二聚体化结构域之后没有琥珀终止密码子)、或者基于所述抗体可变区是否主要是以不含病毒外壳蛋白质成分的方式而被制作的(例如、二聚体化结构域之后具有琥珀终止密码子),其可以为各种各样的结构。所述抗体可变区主要作为与病毒的外壳蛋白质成分的融合蛋白质而被制作时,二价展示是通过1个或多个二硫键和/或单一的二聚体化序列而获得的。本发明的抗原结合分子主要是以不与病毒的外壳蛋白质成分融合的方式制作的抗体可变区(例如具有琥珀终止密码子)的情况下,优选具有包含半胱氨酸残基和二聚体化序列二者的二聚体化结构域。某种实施方式中,F(ab)2的重链为通过不含铰链区的二聚体化结构域二聚体化而成的。该二聚体化结构域中可包含例如公知的GCN4序列:GRMKQLEDKVEELLSKNYHLENEVARLKKLVGERG(序列号12)等的亮氨酸拉链序列。
用于制作编码抗原结合分子的多核苷酸的寡核苷酸或引物的组合可使用标准的方法来合成。例如,包含含有通过密码子组合可提供的核苷酸三联体的全部可能组合、编码期望的氨基酸群体的序列的一组寡核苷酸可通过固相法来合成。因此,具有特定的密码子组合的合成寡核苷酸组合通常包含不同序列的多个寡核苷酸,该不同是由于整条序列中的密码子组合而导致的。对于具有在某个位置上选择的“简并”核苷酸的寡核苷酸来说,其合成是本技术领域公知的。具有这样的某种密码子组合的核苷酸的组合可使用市售的核酸合成仪(Applied Biosystems)来合成,或者可购买其市售品(例如Life Technologies)。如在本发明中所使用的那样,寡核苷酸可具有可能与可变结构域核酸模板杂交的序列,并且包含对克隆有用的限制性酶位点。
文库可通过使用上游和下游的寡核苷酸组合来产生。各寡核苷酸组合具有多个寡核苷酸,所述多个寡核苷酸具有由寡核苷酸序列内提供的密码子组合确立的不同序列。上游和下游的寡核苷酸组合可与可变区模板核酸序列一起用于制作PCR产物的“文库”。可使用已建立的分子生物学手段,将PCR产物与其它相关或无关的核酸序列、例如编码病毒外壳蛋白质的构成成分以及二聚体化结构域的核酸序列融合,因此这样的寡核苷酸组合有时也被称为“核酸盒(cassette)”。
PCR引物序列包含针对暴露于抗原结合分子的表面、非常多样化的灵活残基而设计的一种或复数种密码子组合。如前文所述,密码子组合为用于编码期望的变体氨基酸的一组不同的核苷酸三联体序列。此外,寡核苷酸组合的序列的长度是足够长到能杂交至模板核酸的长度,此外,虽然并非必需,但其可包含限制性位点。DNA模板是通过来自噬菌体M13载体的载体、或Viera等人(Meth.Enzymol.(1987)153,3)记载的包含单链噬菌体的复制起点的载体生成的。这样,待突变的DNA被插入到这些载体中之一,以生成单链模板。单链模板的生产被记载Sambrook等教科书中。
此外,本发明的非限定性的一种实施方式中记载的、将选择的氨基酸导入抗原结合分子中的方法是本技术领域中已经建立的,其中一些被描述于本说明书中。例如,可使用Kunkel等人(Methods Enzymol.(1987)154,367-382)提供的Kunkel方法,通过暴露于至少一个抗原结合分子的表面、和/或导入“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”或非常多样化的灵活残基,来制作文库。例如,在通过将导入了本发明的“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”的轻链可变区与作为随机化可变区序列文库而制作的重链可变区组合起来、来制作本发明的包含互相之间序列不同的多个抗原结合分子的文库的情况下,可合适地采用这样的方法。作为这样的非限定性例子,在金属离子为钙离子的情况下,例如,可举例为:制作序列号6(Vk1)、序列号7(Vk2)、序列号8(Vk3)、序列号9(Vk4)等的生殖细胞系的特定的残基被“使抗原结合分子针对抗原的结合活性根据钙离子浓度的条件而变化的至少一个氨基酸残基”取代的轻链可变区序列,这样的轻链可变区的制作中可采用这样的方法。
该情况下,作为用于制作核酸盒的模板,可使用可变区的核酸模板(template)序列,作为PCR反应的引物,可使用寡核苷酸组合。可变区的模板序列,也可优选使用包含对象核酸序列(即,编码作为取代的对象的氨基酸的核酸序列)的免疫球蛋白的轻链或重链的任何部分。就前述的例子而言,序列号6(Vk1)、序列号7(Vk2)、序列号8(Vk3)、序列号9(Vk4)等的生殖细胞系的可变区可作为模板序列使用。可变区的模板序列包含至少一部分可变区、此外包含至少一个CDR。根据情况,可变区的模板序列包含多个CDR。可变区的模板序列的上游部分和下游部分可成为上游区域的寡核苷酸组合和下游区域的寡核苷酸组合的构成成员的杂交对象。上游的引物组合的第1寡核苷酸能与第1核酸链杂交,下游的引物组合的第2寡核苷酸能与第2核酸链杂交。寡核苷酸引物包含1个或多个的密码子组合,其可被设计为与可变区的模板序列的一部分杂交。通过使用这些寡核苷酸,可在PCR之后将2个以上的密码子组合导入PCR产物(即核酸盒)中。编码抗体可变区的核酸序列的区域中杂交的寡核苷酸引物可包含编码作为氨基酸取代的对象的CDR残基的部分。
此外,作为本发明的非限定性的一种实施方式中记载的、将选择的氨基酸导入抗原结合分子的方法,如本说明书中所记载的那样,还可合适地采用重叠·延伸PCR法(WO1993003151)。可通过暴露于至少一个抗原结合分子的表面、和/或导入“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”或非常多样化的灵活残基,来制作文库。用于重叠·延伸PCR法中的上游区域和下游区域的寡核苷酸组合中,除了包含“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”或非常多样化的灵活残基之外,还可包含用以杂交至可变区的模板序列的足够长的框架序列。
例如,为了制作作为本发明的非限定性的一种实施方式记载的、编码导入了“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”的轻链可变区的多核苷酸分子,制作编码所述氨基酸残基的密码子组合以及附加的灵活残基的密码子组合的寡核苷酸组合。该寡核苷酸组合中,为了杂交至可变区的模板序列,足够长的框架序列与其上游或下游以符合读码框的方式连接。
例如,向轻链可变区的CDR2和CDR3中导入所述氨基酸残基或添加的灵活残基的情况下,可制作如下引物,所述引物是向寡核苷酸组合的5’末端连接了编码与CDR2邻接的足够长的FR2的氨基酸序列的寡核苷酸、向3’末端连接了编码与CDR2邻接的FR3的氨基酸序列的寡核苷酸而得的。进而,还制作如下的互补引物,所述互补引物是向与寡核苷酸组合互补的寡核苷酸组合的5’末端连接了编码与CDR3邻接的足够长的FR4的氨基酸序列的寡核苷酸、向3’末端连接了编码与CDR3邻接的FR3的氨基酸序列的寡核苷酸而得的。在含有使得该引物的编码FR3的氨基酸的寡核苷酸与该互补引物的编码FR3的氨基酸的寡核苷酸互相杂交的长度的重叠序列的情况下,通过不存在模板序列的条件下的PCR反应,可制作向CDR2和CDR3导入了所述氨基酸残基或添加的灵活残基的轻链可变区。不含有这样的重叠序列的情况下,例如通过将序列号6(Vk1)、序列号7(Vk2)、序列号8(Vk3)、序列号9(Vk4)等的生殖细胞系的可变区作为模板序列进行PCR反应,同样可制作向CDR2和CDR3导入了所述氨基酸残基或添加的灵活残基的轻链可变区。
例如,制作向轻链可变区的CDR3中导入所述氨基酸残基或添加的灵活残基、CDR1和CDF2包含随机化的可变区的文库的情况下,通过使用向与寡核苷酸组合互补的寡核苷酸组合的5’末端连接了编码与CDR3邻接的足够长的FR4的氨基酸序列的寡核苷酸、向3’末端连接了编码与CDR3邻接的FR3的氨基酸序列的寡核苷酸而得的引物与具有编码FR1的核苷酸序列的引物,用包含天然序列等随机化的可变区的文库作为模板序列进行PCR,同样可制作向CDR2中导入了所述氨基酸残基和添加的灵活残基、CDR1和CDF2编码随机化的轻链可变区的多核苷酸的文库。向上述轻链中导入了“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”和/或灵活残基的多核苷酸文库的制作方法,也可合适地用于制作向重链中导入了所述氨基酸残基和添加的灵活残基的多核苷酸文库。
此外,上游区域和下游区域的寡核苷酸组合还可被合成为使寡核苷酸序列内包含限制性位点。这些限制性位点使得向具有额外的抗体序列的表达载体中插入核酸盒(即PCR反应生成物)变得容易。优选地,限制性位点被设计为不导入外来的核酸序列、或不除去原有的CDR或框架核酸序列而使得核酸盒的克隆变得容易。
为了表达构成所制作的本发明的抗原结合分子的轻链或重链的序列的一部分或全部,可将核酸盒克隆于合适的载体中。根据本发明中详述的方法,核酸盒被克隆进下述载体,所述载体能够生产与病毒外壳蛋白质的全部或一部分融合的轻链或重链序列的一部分或全部(即,形成融合蛋白质)。如下文所述,这样的载体可以是被设计为使得所述融合蛋白质在粒子或细胞的表面呈示的表达载体。为了这样的目的,可获得数种载体并将其用于本发明的实施中,但噬粒载体为本说明书中优选使用的载体。如本领域技术人员公知的那样,噬粒载体中通常可包含各种各样的构成成分,包括启动子、信号序列等控制序列、表型选择基因、复制起点部位和其它必要构成成分。
在表达特定的变体氨基酸的组合的非限定性实施方式中,核酸盒中可编码重链或轻链的可变区的全部或一部分。例如,作为本发明的非限定性的一种实施方式的、设计为将“使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的至少一个氨基酸残基”和/或灵活残基包含在重链的CDR3中的情况下,可在制作具有重链CDR3的序列多样性的核酸盒之后,将其连接至编码天然序列等随机化的可变区的核酸盒。在文库的情况下,为了制作包含这些变体氨基酸或变体氨基酸的组合的抗原结合分子,可将核酸盒插入包含额外的抗体序列、例如轻链和重链可变区的可变或恒定区的全部或一部分的表达载体中。这些额外的抗原结合分子的序列与其它核酸序列、例如编码病毒外壳蛋白质构成成分的序列融合,作为其结果,融合蛋白质得以被生产。
在本发明的非限定性的一种实施方式中,包含含有编码基因融合的核酸序列的可复制的表达载体,所述基因融合编码下述融合蛋白质,所述融合蛋白质与病毒外壳蛋白质的全部或一部分融合,并且包含一个抗原结合分子的可变区、或者1个抗原结合分子的可变区与1个恒定区。如前文所述,还包含可以以多种方式复制的表达载体的文库,所述文库包含编码多个不同的融合蛋白质的多个基因融合,所述融合蛋白质包含以多样化的序列生成的互相之间序列不同的多个抗原结合分子。载体可包含各种各样的构成成分,其优选地被构建为使得抗原结合分子的可变区可在不同的载体之间移动、和/或融合蛋白质可以以不同的形式呈示。
作为载体的例子,可优选举出噬菌体载体。噬菌体载体具有使得噬菌体复制和噬菌体粒子形成成为可能的噬菌体复制起点。关于噬菌体,作为优选例子,可优选举出包括M13、f1、fd、Pf3噬菌体或其衍生物的纤维状噬菌体、或包括λ、21、phi80、phi81、82、424、434等、或其衍生物的λ型噬菌体。
病毒外壳蛋白质的例子包含感染性蛋白质PIII、主外壳蛋白质PVIII、pVII、pIX、Soc(T4)、Hoc(T4)、gpD(噬菌体λ)、次要噬菌体外壳蛋白质6(pVI)(纤维状噬菌体(J.Immunol.Methods.(1999)231(1-2),39-51)、M13噬菌体主外壳蛋白质变体(P8)(Protein Sci.(2000)9(4),647-654))。融合蛋白质呈示于噬菌体的表面,合适的噬菌体系统包括M13KO7辅助(helper)噬菌体、M13R408、M13-VCS和Phi X 174、pJuFo噬菌体系统(J.Viro1.(2001)75(15),7107-7113)、Hyper噬菌体(Nat.Biotechnol.(2001)19(1),75-78)、KM13(Fold Des.(1998)3(5),321-328)。优选的辅助噬菌体为M13KO7,优选的外壳蛋白质为M13噬菌体基因III外壳蛋白质。优选的宿主为大肠杆菌、和大肠杆菌的蛋白酶缺失株。例如fth1载体(Nucleic Acids Res.(2001)29(10)e50)等载体可用于融合蛋白质的表达中。
表达载体可包含与编码抗原结合分子的重链可变区或轻链可变区或其片断的DNA融合的分泌信号序列。该序列典型地位于编码融合蛋白质的基因的邻接5’侧,因此在融合蛋白质的氨基末端被转录。但是,有些情况下证实信号序列在编码待分泌的蛋白质的基因的5’以外的位置。该序列以横跨细菌细胞的内膜而结合的蛋白质为对象。编码信号序列的DNA,可以以限制性内切核酸酶片断的形式、由编码具有信号序列的蛋白质的基因的任何一种而获得。关于原核生物的适当的信号序列,还可使用例如编码LamB或OmpF(Wong等人(Gene(1983),68(2),193-203)、MalE、PhoA的基因和其它基因。用于实施本发明的优选的原核生物信号序列为Chang等(Gene(1987)55(2-3),189-196)中记载的大肠杆菌耐热性肠毒素II(STII)信号序列、pelB和malE。
载体中一般包含启动子作为促进融合蛋白质的表达的控制序列。原核生物载体中一般使用的启动子包括lac Z启动子系、碱性磷酸酶pho A启动子(Ap)、噬菌体λPL启动子(温度感受性启动子)、tac启动子(由lac遏制子控制的杂种trp-lac启动子)、色氨酸启动子、pBAD启动子和噬菌体T7启动子。关于启动子的综述,被记载于前述Sambrook等教科书中。这些是最通常使用的启动子,但还同样可以使用其它合适的微生物启动子。
载体中还可含有其它核酸序列,例如编码gD标签、c-Myc表位、多聚组氨酸标签、荧光蛋白质(例如GFP)或用于检测或纯化在噬菌体或细胞的表面表达的融合蛋白质的β-半乳糖苷酶蛋白质的序列。例如通过编码gD标签的核酸序列,能够对表达融合蛋白质的细胞或病毒的正或负加以选择。若干实施方式中,gD标签优选与不融合至病毒外壳蛋白质的构成成分上的抗原结合分子的可变区融合。例如,编码多聚组氨酸标记的核酸序列有益于使用免疫组织化学手段、鉴定包含与特异性抗原结合的抗原结合分子的可变区的融合蛋白质。对抗原结合的检测有用的标签可与不融合至病毒外壳蛋白质构成成分上的抗原结合分子的可变区、或融合至病毒外壳蛋白质构成成分上的抗原结合分子的可变区融合。
作为用于实施本发明的载体的其它有用构成成分,可优选举出表型选择基因。典型的表型选择基因为编码向宿主细胞赋予抗生素耐性的蛋白质的基因。作为其例子,可优选使用氨苄青霉素耐性基因(ampr)和四环素耐性基因(tetr)等。
载体中还可包含含有独特的限制性位点和抑制性终止密码子的核酸序列。独特的限制性位点可用于使抗原结合分子的可变区在不同的载体和表达系统之间移动。特别地,对于通过细胞培养进行的对全长抗原结合分子或抗原结合片断的生产有用。抑制性终止密码子对调节融合蛋白质的表达水平有用,并使可溶型的抗原结合分子的片断的纯化变得容易。例如,琥珀终止密码子在能够进行噬菌体展示的supE宿主中可被翻译为Gln,而在非supE宿主中其被解释为终止密码子,产生与噬菌体外壳蛋白质不融合的可溶型的抗原结合分子的片断。这些合成序列可与载体内的1个或多个抗原结合分子的可变区融合。
可优选使用下述载体,所述载体使编码目标抗原结合分子的序列的核酸能容易地从载体取出、且并入其它载体中。例如,为了容易地取出编码本发明的抗原结合分子或其可变区的核酸序列,可向载体中并入合适的限制性位点。关于限制性序列,通常,为了使得高效切割和向新载体中的连接容易进行,可选择在载体内独特的限制性序列。抗原结合分子或其可变区可从作为下述分子的载体表达,所述分子具有不含之后外来的融合序列、例如病毒外壳蛋白质或其它序列标签的结构。
编码抗原结合分子的可变区或恒定区的核酸(基因1)和病毒的外壳蛋白质构成成分(基因2)之间,可插入编码终结或终止密码子的DNA。这样的终结密码子包括UAG(琥珀)、UAA(赭石)或UGA(蛋白石)(Davis等人(Microbiology(1980),237,245-247,374Harper&Row,New York))。在野生型宿主细胞中表达的终结或终止密码子使得能够合成与基因2蛋白质不结合的基因1的蛋白质产物。但是,融合蛋白质以能够通过在抑制性宿主细胞中的生长被检测到的量被合成。这样的抑制性宿主细胞是公知的,记载了大肠杆菌抑制基因株(Bullock等人(BioTechniques(1987)5,376-379))等。这样的终结密码子可插入编码融合多肽的mRNA中。
抑制性密码子可被插入到编码抗原结合分子的可变区或恒定区的第1基因和编码噬菌体外壳蛋白质的至少一部分的第2基因之间。或者,抑制性终结密码子可通过取代抗原结合分子的可变区的最后一个氨基酸三联体或噬菌体外壳蛋白质的第一个氨基酸而与融合位点邻接而插入。抑制性终结密码子可插入到二聚体化结构域的C末端或其之后。含有抑制性密码子的质粒在抑制基因宿主细胞中复制的情况下,将产生可被检测到的量的包含多肽和外壳蛋白质的融合多肽。质粒在非抑制基因宿主细胞中复制的情况下,为了使得在被插入的抑制性三联体UAG、UAA或UGA处的翻译终结,以实质上不与噬菌体外壳蛋白质融合的方式合成抗原结合分子的可变区。因此,因为不含宿主膜上固定的融合噬菌体外壳蛋白质,所以在非抑制基因细胞中表达的抗原结合分子的可变区在合成后从宿主细胞分泌。
抗原结合分子的轻链和/或重链的可变区或恒定区可进一步与下述肽序列融合,所述肽序列使得病毒粒子或细胞表面上1个或多个融合多肽的相互作用成为可能。这些肽序列在本说明书中被称为“二聚体化结构域”。二聚体化结构域可包含至少一个或多个二聚体化序列、或包含半胱氨酸残基的序列中的至少一者或者两者均包含。合适的二聚体化序列包含具有下述两亲性α螺旋的蛋白质的那些序列,所述两亲性α螺旋使得疏水残基以一定的间隔存在、通过各蛋白质的疏水残基的相互作用形成二聚体成为可能。这样的蛋白质和蛋白质部分中,含有例如亮氨酸拉链区。二聚体化结构域可包含1个或多个半胱氨酸残基(例如通过在二聚体化结构域内包含抗体铰链序列而提供的)。半胱氨酸残基使得通过1个或多个二硫键的形成而二聚体化成为可能。其中终止密码子存在于二聚体化结构域后方的一种实施方式中,二聚体化结构域包含至少一个半胱氨酸残基。二聚体化结构域优选位于抗体可变或恒定结构域与病毒外壳蛋白质构成成分之间。
根据情况,载体编码例如单链形式的单一抗原结合分子的噬菌体多肽,其中含有与外壳蛋白质融合的重链和轻链的可变区。这些情况下,认为载体为在某种启动子控制下表达一种转录产物的“单顺反子性”。例示下述载体:所述载体在重链可变区和轻链可变区之间具有接头肽,为促进编码VL和VH结构域的单顺反子性序列的表达利用碱性磷酸酶(AP)或Tac启动子。这类顺反子序列在5’末端连接至大肠杆菌的malE或耐热性肠毒素(STII)信号序列,在3’末端(例如PIII蛋白质等的)连接至病毒外壳蛋白质的全部或一部分上。若干实施方式中,载体可在第2可变区序列和病毒外壳蛋白质序列之间的其3’末端处,进一步包含编码(例如亮氨酸拉链等的)二聚体化结构域的序列号12所示的那样的序列。
其它情况下,重链和轻链的可变区作为各多肽而表达,这样的载体为“双顺反子性”,可能表达各种转录产物。这些载体中,为了促进双顺反子性mRNA的表达,可利用合适的启动子,例如tac或PhoA启动子。例如,编码轻链可变区和恒定区的第1顺反子在5’末端连接至大肠杆菌的malE、pelB或耐热性肠毒素(STII)信号序列,在3’末端连接至编码gD标签的核酸序列。例如,编码重链可变区和恒定区CH1的第2顺反子在5’末端连接至大肠杆菌的malE或耐热性肠毒素(STII)信号序列,在3’末端连接至病毒外壳蛋白质的全部或一部分。
生成双顺反子性mRNA、呈示F(ab’)2-pIII的载体中,合适的启动子,例如tac或PhoA(AP)启动子在5’末端可作用地连接至大肠杆菌的malE或耐热性肠毒素(STII)信号序列,在3’末端连接至编码gD标签的核酸序列,这促进由此得到的编码轻链可变区和恒定区的第1顺反子的表达。第2顺反子例如编码在5’末端与大肠杆菌的malE或耐热性肠毒素II(STII)信号序列可作用地连接而得的重链可变区和恒定区,在3’末端包含含有IgG铰链序列和亮氨酸拉链序列进而在其之后含有至少一部分病毒外壳蛋白质的二聚体化结构域。
抗原结合分子的可变区的融合多肽在细胞、病毒或噬粒粒子的表面以各种各样的形式呈示。这些形式中,包括单链Fv片断(scFv)、F(ab)片断以及这些片断的多价形式。多价形式优选为ScFv、Fab或F(ab’)的二聚体,它们在本说明书中分别被称为(ScFv)2、F(ab)2和F(ab’)2。多价形式的呈示为优选的理由之一被认为是:通过多价形式的呈示,通常可鉴定低亲和性克隆,或者,具有多个抗原结合位点,使得能够在选择过程中更高效地选择稀少的克隆。
在噬菌体的表面呈示含有抗体片断的融合多肽的方法是本技术领域中公知的,例如,如W01992001047和本说明书记载所示。此外,WO1992020791、WO1993006213、WO1993011236和1993019172中也记载了关联的方法,本领域技术人员可适当地使用这些方法。其它公知文献(H.R.Hoogenboom&G.Winter(1992)J.Mol.Biol.227,381-388、WO1993006213和WO1993011236)中,给出了针对噬菌体表面呈示的各种抗原、通过人工再配置的可变区基因贮库进行的抗体鉴定。
在构建用于以scFv的形式呈示的载体的情况下,编码抗原结合分子的轻链可变区和重链可变区的核酸序列包含在该载体中。一般而言,编码抗原结合分子的重链可变区的核酸序列与病毒外壳蛋白质构成成分融合。编码抗原结合分子的轻链可变区的核酸序列通过编码肽接头的核酸序列与抗原结合分子的重链可变区连接。肽接头一般包含约5~15个氨基酸。任意地,例如编码对纯化或检测有用的标记的其它序列可融合至编码抗原结合分子的轻链可变区或抗原结合分子的重链可变区中的任一或两者的核酸序列的3’末端。
在构建用于以F(ab)的形式呈示的载体的情况下,编码抗原结合分子的可变区和抗原结合分子的恒定区的核酸序列包含在该载体中。编码轻链可变区的核酸与编码轻链恒定区的核酸序列融合。编码抗原结合分子的重链可变区的核酸序列与编码重链恒定CH1区的核酸序列融合。一般而言,编码抗原结合分子的重链可变区和恒定区的核酸序列与编码病毒外壳蛋白质的全部或一部分的核酸序列融合。重链可变区和恒定区优选作为与病毒外壳蛋白质的至少一部分的融合体表达,轻链可变区和恒定区则与重链病毒外壳融合蛋白质分开表达。重链和轻链相互结合,该结合可以是共价结合也可以是非共价结合。任意地,例如编码对纯化或检测有用的多肽标记的其它序列可融合至编码抗原结合分子的轻链可变区或抗原结合分子的重链可变区中的任一或两者的核酸序列的3’末端。
为扩增和/或表达,按前文所述构建的载体被导入宿主细胞中。载体可通过包括电穿孔、磷酸钙沉淀等的公知转化法导入宿主细胞。载体为病毒这样的感染性粒子的情况下,载体自身侵入宿主细胞。利用插入了编码融合蛋白质的多核苷酸的可复制的表达载体转染宿主细胞、和利用公知的手段,产生噬菌体粒子,由此使融合蛋白质在噬菌体粒子的表面呈示。
可复制的表达载体可使用各种各样的方法导入宿主细胞中。在一种非限定性的实施方式中,按照WO2000106717所记载的那样,使用电穿孔法将载体导入细胞中。细胞在标准培养液中于37℃被培养任选约6~48小时(或者培养至600nm处的OD达到0.6~0.8),接着通过对培养液离心分离(例如通过倾析),取出培养上清液中。在纯化的初期阶段中,优选地,将细胞沉淀再悬浮于缓冲液(例如1.0mM的HEPES(pH7.4))中。接着通过再次离心分离,从悬浮液获得上清液。将得到的细胞沉淀再悬浮于例如稀释为5-20%V/V的甘油中。通过再次离心分离,从悬浮液获得上清液,由此得到细胞沉淀。通过将该细胞沉淀再悬浮于水或经稀释的甘油中,基于对得到的菌体浓度的测定值,使用水或经稀释的甘油,将最终的菌体浓度制备为期望的浓度。
例如,作为优选的受体细胞,可举出可应答电穿孔的大肠杆菌菌株SS320(Sidhu等人(Methods Enzymol.(2000)328,333-363))。大肠杆菌菌株SS320为在足以使得致育性附加体(F’质粒)或XL1-BLUE转移到MC1061细胞中的条件下,将MC1061细胞与XL1-BLUE细胞偶合而制备的。在ATCC(10801 University Boulevard,Manassas,Virginia)保藏的大肠杆菌菌株SS320被给予了保藏号98795。该菌株中使得噬菌体复制成为可能的任何F’附加体均可用于本发明。合适的附加体可从ATCC保藏的菌株获得,或者可从市售品获得(TG1、CJ236、CSH18、DHF’、ER2738、JM101、JM103、JM105、JM107、JM109、JM110、KS1000、XL1-BLUE、71-18等)。
在电穿孔中使用更高的DNA浓度(约10倍)的话,转化率提高,被转化进宿主细胞中的DNA的量增加。高菌体浓度的使用也提高效率(约10倍)。通过转移的DNA的量的增加,可以制作具有更高的多样性、序列不同的独立克隆数量更大的文库。通常可根据在含有抗生素的培养基上是否生长来选择转化细胞。
使用噬菌体展示以鉴定展示出针对抗原的期望结合活性的抗原结合分子的方法包括进行了各种各样的改变的方法,其是本技术领域中已经建立的。在一种非限定性的实施方式中,可复制载体的文库被构建为包含与编码融合多肽的基因融合体可作用地连接的转录调节因子,该可复制载体的文库被转化至合适的宿主细胞。培养经转化的细胞,形成所述融合多肽在噬菌体粒子表面呈示的噬菌体粒子。之后,为了使在选择过程中与抗原不结合的粒子群体相比与抗原结合的粒子的群体增加,可实施伴随选择、分选的“选择结合分子”的步骤,所述选择、分选通过将重组体噬菌体粒子与对象抗原接触来进行,使得粒子群体的至少一部分与抗原结合。为了在不同或相同反应条件下对相同群体再进行一次筛选,通过使已经分选的群体感染例如新鲜的XL1-Blue细胞等宿主细胞,来扩增该群体。接着,实施将得到的抗原结合分子被扩增了的群体在离子浓度不同的条件下与抗原接触的步骤,筛选出在期望的条件下结合抗原的抗原结合分子。此外,还可将在离子浓度不同的条件下与抗原接触的步骤作为前述选择方法的最初步骤来实施,“选择结合分子”的步骤与选择在离子浓度不同的条件下结合活性变化的结合分子的步骤的组合可被适当变更。此外,所述的选择和分选的步骤可实施数次。这些离子浓度不同的条件下与抗原结合的抗原结合分子,作为在给予生物体时具有从生物体快速除去作为病因的抗原的能力的治疗药物而有用。
本发明的、包含使抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的氨基酸和/或灵活残基的可变区或其一部分的融合多肽被表达于噬菌体、噬粒粒子或细胞的表面。接着可针对在离子浓度不同的条件下融合多肽的群体中构成成员对抗原的结合能力进行选择和/或分选。对融合多肽进行选择、分选和筛选的方法还包括在与抗原结合分子的可变区具有亲和性的一般的蛋白质(如蛋白质L或与在噬菌体上呈示的抗原结合分子或其片断结合的标记抗体)上进行选择、分选和筛选的方法。这样的方法可用于使得呈示被正确折叠的抗原结合分子(或包含它们的融合多肽)的片断的文库大小或文库当量数丰富。
为进行所述的选择、分选和筛选,可使用两种主要的策略。第1策略为固体载体方法或平板筛选或固定化抗原筛选,第2策略为溶液结合方法。
“固体载体方法”中,抗原可与本技术领域公知的合适的固体或半固体基质结合,所述基质例如琼脂糖珠粒、丙烯酰胺珠粒、玻璃珠粒、纤维素、各种各样的丙烯酸共聚物、甲基丙烯酸羟基烷基凝胶、聚丙烯酸和聚甲基丙烯酸共聚物、尼龙和中性和离子性载体。抗体对基质的结合可按照Methods in Enzymology(1976)44中记载的方法或本技术领域中公知的其它手段实现。
抗原结合至基质之后,在适于噬菌体粒子群体的至少一个亚组和固定化抗原的结合的条件下,将固定化的抗原与表达融合多肽的文库接触。通常,pH、离子强度、温度等条件选择为模拟生理学条件的条件。与所述固定化的抗原结合的粒子(“结合体”)通过水洗与未和对象结合的粒子分离。清洗条件可被调节,以使得高亲和性的结合体之外的全部物质均被除去。可通过各种各样的方法使得结合体从固定化的对象解离。这些方法包括例如使用过量抗原等的野生型配体的竞争性解离、pH和/或离子强度的变更以及本技术领域公知的方法。结合体可通过合适的溶出材料(一般而言,0.1M的HC1等酸或配体之类的)从亲和性基质溶出。通过使得配体的浓度上升并溶出,可能使得呈示的、亲和性更高结合分子溶出。
通过使分离的结合体、即病毒粒子(以及,例如病毒粒子为噬粒粒子的情况下,则根据需要为辅助噬菌体)感染细胞,可在合适的宿主细胞中再扩增结合体。在适合扩增粒子(该粒子呈示期望的融合多肽)的条件下培养由此得到的宿主细胞。接着,采集噬菌体粒子,重复进行1次或复数次选择工序,使得抗原的结合体占到相当的比例。选择或筛选可进行数次。作为选择或筛选方法之一,可包括分离与蛋白质L或针对被呈示的多肽中存在的多肽标签的抗体(例如针对gD蛋白质或多聚组氨酸标签的抗体)这样的一般的亲和性蛋白质结合的结合体。
作为本发明的一种实施方式,可合适地使用被称为“溶液结合方法”的溶液相筛选法。可使用溶液结合方法,以从随机的文库、或者从以改善期望的结合克隆或克隆群的结合活性为目的的文库发现改善的结合体。多种多肽、例如噬菌体或噬粒粒子(文库)上呈示的多肽和经标签分子标记的或与标签分子融合的抗原的接触也包括在该方法中。关于标签,可利用生物素或其它特异性的结合体。在第1溶液结合相中使用浓度梯度降低的经标记的或融合的抗原,可改变溶液相的严格性(stringency)。进而,为了提高严格性,还可合适地实施下述方法:在第1溶液相中与经最初的标签分子标记或与标记标签分子融合的抗原结合之后,与第2溶液相接触,所述第2溶液相具有未再经标签分子标记或未再与标记标签分子融合的高浓度的抗原。该情况下,通常,在第2相中使用标记对象的100~1000倍的量的未经标签分子标记的或未与标记标签分子融合的抗原。第1溶液相的孵育时间在2、3分钟到1、2个小时或更长的范围内,直至达到平衡。结合速度快的结合体具有在该第1相中的结合时间短的性质的倾向,因此采用结合时间较短的接触条件。第2相的孵育时间和温度可为了提高严格性而变化。通过这样的孵育条件的变化,产生对从对象脱离的速度(解离速度)慢的结合体的选择偏向。噬菌体/噬粒粒子上呈示的多种多肽与抗原接触后,与经标签分子标记的或与标记标签分子融合的抗原结合的噬菌体或噬粒粒子与未结合的噬菌体或噬粒粒子分离。通过在使得与经标签分子标记的或与标记标签分子融合的抗原的结合成为可能的范围内,使得噬菌体或噬粒粒子与抗原接触较短的时间(例如2~5分钟),噬菌体或噬粒粒子与抗原的混合可从溶液相被分离。经标签分子标记的或与标记标签分子融合的抗原的初期浓度的范围为约0.1nM~约1000nM。为了接着的筛选,可使得从该混合物溶出的粒子增殖。在各次的筛选中,优选使用经标签分子标记的或与标记标签分子融合的低浓度的抗原,重复多次筛选。如下文的实施例中记载的那样,作为标记标签分子使用生物素的情况下,涂布有链亲和素的磁性珠粒等可合适地用于溶液结合方法中。
固体载体方法与溶液结合方法的组合可单独或组合实施,以分离具有期望的特性的结合体。针对抗原重复进行2次、3次或4次选择和筛选,之后为了鉴定出具有期望的性质/特性的特异性结合体,通常可实施从选择的群体中进行对各个克隆的筛选。优选地,可通过使得针对文库的高通量筛选成为可能的自动化系统来实行筛选的过程。
通过针对抗原的结合鉴定结合体之后,可从该结合体提取核酸。提取的DNA接着可直接用于对大肠杆菌宿主细胞进行转化。或者,可例如通过PCR使用适当的引物来扩增其编码序列,再通过典型的测序方法来确定其序列。接着,为了表达其编码的抗原结合分子,编码结合体的可变区的DNA可被插入经限制性酶消化的载体中。
为了选择、筛选表达本发明的抗原结合分子针对抗原的结合活性根据离子浓度的条件而变化的抗原结合分子或其融合多肽的噬菌体粒子,通过改变将固定化的抗原与包含表达抗原结合分子或融合多肽的噬菌体粒子的文库接触的条件,可分选出针对抗原的结合活性发生变化的噬菌体粒子的群体。
例如,作为金属离子的优选例子而关注钙离子的情况下,作为钙离子浓度的条件,可举出低钙离子浓度的条件和高钙离子浓度的条件。结合活性根据钙离子浓度的条件而变化是指:抗原结合分子针对抗原的结合活性根据低钙离子浓度和高钙离子浓度的条件不同而变化。例如可举出:较之在低钙离子浓度的条件下抗原结合分子针对抗原的结合活性而言,在高钙离子浓度的条件下抗原结合分子针对抗原的结合活性更高的情况。此外,也还可举出:较之在高钙离子浓度的条件下抗原结合分子针对抗原的结合活性而言,在低钙离子浓度的条件下抗原结合分子针对抗原的结合活性更高的情况。
本说明书中,高钙离子浓度并不被特别限定为某个明确的数值,但优选可为选自100μM~10mM之间的浓度。此外,在一些其它实施方式中,也可为选自200μM~5mM之间的浓度。此外,在不同的实施方式中,还可为选自500μM~2.5mM之间的浓度,在另外的实施方式中,还可为选自200μM~2mM之间的浓度。此外,还可为选自400μM~1.5mM之间的浓度。特别地,可优选举出选自接近生物体内的血浆中(血中)的钙离子浓度的、500μM~2.5mM之间的浓度。
本说明书中,低钙离子浓度并不被特别限定为某个明确的数值,但优选可为选自0.1μM~30μM之间的浓度。此外,在一些其它实施方式中,也可为选自0.2μM~20μM之间的浓度。此外,在不同的实施方式中,还可为选自0.5μM~10μM之间的浓度,在另外的实施方式中,还可为选自1μM~5μM之间的浓度。此外,还可为选自2μM~4μM之间的浓度。特别地,可优选举出选自接近生物体内的早期核内体内的钙离子浓度的、1μM~5μM之间的浓度。
本发明中,抗原结合分子在低钙离子浓度条件下针对抗原的结合活性比在高钙离子浓度条件下针对抗原的结合活性低表示:抗原结合分子在选自0.1μM~30μM之间的钙离子浓度下针对抗原的结合活性比在选自100μM~10mM之间的钙离子浓度下针对抗原的结合活性弱。优选表示,抗原结合分子在0.5μM~10μM之间的钙离子浓度下针对抗原的结合活性比在选自200μM~5mM之间的钙离子浓度下针对抗原的结合活性弱,特别优选表示在生物体内的早期核内体内的钙离子浓度下的抗原结合活性比在生物体内的血浆中的钙离子浓度下的抗原结合活性弱,具体而言,表示抗原结合分子在选自1μM~5μM之间的钙离子浓度下针对抗原的结合活性比在选自500μM~2.5mM之间的钙离子浓度下针对抗原的结合活性弱。
例如,为了选择、筛选表达抗原结合分子(该抗原结合分子较之在低钙离子浓度的条件下抗原结合分子针对抗原的结合活性而言在高钙离子浓度的条件下抗原结合分子针对抗原的结合活性更高)或其融合多肽的噬菌体粒子,在高钙浓度的条件下与固定化的抗原结合的噬菌体粒子的群体首先被分选出之后,将该被分选出的群体和抗原与在低钙浓度的条件下固定化的抗原和包含表达抗原结合分子或融合多肽的噬菌体粒子的文库接触。未与低钙浓度的条件下固定化的抗原结合的噬菌体粒子被分选至上清液或之后的清洗液中。高钙浓度和低钙浓度的条件可在上文记载的范围内合适地采用。在非限定性的一种实施方式中,可基于选自0.1μM~30μM之间的钙离子浓度下针对抗原的结合与在选自100μM~10mM之间的钙离子浓度下针对抗原的结合的活性差异进行分选。此外,在其它的非限定的实施方式中,可基于选自0.5μM~10μM之间的钙离子浓度下针对抗原的结合与在选自200μM~5mM之间的钙离子浓度下针对抗原的结合的活性差异进行分选。此外,在其它非限定的实施方式中,可基于生物体内的早期核内体内的钙离子浓度下针对抗原的结合与生物体内的血浆中的钙离子浓度下针对抗原的结合的活性差异进行分选,具体而言,基于选自1μM~5μM之间的钙离子浓度下针对抗原的结合与在选自500μM~2.5mM之间的钙离子浓度下针对抗原的结合的活性差异进行分选。
例如,作为离子浓度的优选例子而关注氢离子浓度的情况下,作为氢离子浓度的条件可举出pH酸性区域的条件和pH中性区域的条件。结合活性根据pH的条件而变化是指:抗原结合分子针对抗原的结合活性根据pH酸性区域和pH中性区域的条件不同而变化。例如可举出:较之在pH酸性区域的条件下抗原结合分子针对抗原的结合活性而言,在pH中性区域的条件下抗原结合分子针对抗原的结合活性更高的情况。此外,也还可举出:较之在pH中性区域的条件下抗原结合分子针对抗原的结合活性而言,在pH酸性区域的条件下抗原结合分子针对抗原的结合活性更高的情况。
本说明书中,pH中性区域并不被特别限定为某个明确的数值,但优选可选自pH6.7~pH10.0之间。此外,在一些其它实施方式中,可选自pH6.7~pH9.5之间。此外,在不同的实施方式中,还可选自pH7.0~pH9.0之间,在另外的实施方式中,还可选自pH7.0~pH8.0之间。特别地,可优选举出选自与生物体内的血浆中(血中)的pH接近的pH 7.4。
本说明书中,pH酸性区域并不被特别限定为某个明确的数值,但优选可选自pH4.0~pH6.5之间。此外,在一些其它实施方式中,可选自pH4.5~pH6.5之间。此外,在不同的实施方式中,还可选自pH5.0~pH6.5之间,在另外的实施方式中,还可选自pH5.5~pH6.5之间。特别地,可优选举出选自与生物体内的早期核内体内的pH接近的pH 5.8。
本发明中,抗原结合分子在pH酸性区域条件下针对抗原的结合活性比在pH中性区域条件下针对抗原的结合活性低表示:抗原结合分子在选自pH4.0~pH6.5之间的pH下针对抗原的结合活性比在选自pH6.7~pH10.0之间的pH下针对抗原的结合活性弱。优选地表示抗原结合分子在选自pH4.5~pH6.5之间的pH下针对抗原的结合活性比在选自pH6.7~pH9.5之间的pH下针对抗原的结合活性弱,更优选表示抗原结合分子在选自pH5.0~pH6.5之间的pH下针对抗原的结合活性比在选自pH7.0~pH9.0之间的pH下针对抗原的结合活性弱。此外,优选地表示,抗原结合分子在选自pH5.5~pH6.5之间的pH下针对抗原的结合活性比在选自pH7.0~pH8.0之间的pH下针对抗原的结合活性弱。特别优选表示在生物体内的早期核内体内的pH下的抗原结合活性比在生物体内的血浆中的pH下的抗原结合活性弱,具体而言,抗原结合分子在pH5.8下针对抗原的结合活性比在pH7.4下针对抗原的结合活性弱。
关于抗原结合分子针对抗原的结合活性是否根据pH的条件而变化,可例如按照测定在前述不同的pH的条件下的结合活性的方法来实施。例如,为了确认到较之在pH酸性区域的条件下抗原结合分子针对抗原的结合活性而言、在pH中性区域的条件下抗原结合分子针对抗原的结合活性变高,对pH酸性区域和pH中性区域的条件下抗原结合分子针对抗原的结合活性进行比较。
例如,为了选择、筛选表达抗原结合分子(该抗原结合分子较之在pH酸性区域的条件下抗原结合分子针对抗原的结合活性而言在pH中性区域的条件下抗原结合分子针对抗原的结合活性更高)或其融合多肽的噬菌体粒子,在pH中性区域的条件下与固定化的抗原结合的噬菌体粒子的群体首先被分选出之后,将该被分选出的群体和抗原与在低钙浓度的条件下固定化的抗原和包含表达抗原结合分子或融合多肽的噬菌体粒子的文库接触。未与pH酸性区域的条件下固定化的抗原结合的噬菌体粒子被分选至上清液或之后的清洗液中。pH中性区域和pH酸性区域的条件可在上文记载的范围内合适地采用。在非限定性的一种实施方式中,可基于选自pH4.0~pH6.5之间的pH下针对抗原的结合与在选自pH6.7~pH10.0之间的pH下针对抗原的结合的活性差异进行分选。此外,在其它的非限定的实施方式中,可基于选自pH4.5~pH6.5之间的pH下的针对抗原的结合与在选自pH6.7~pH9.5之间的pH下针对抗原的结合的活性差异进行分选。此外,可基于选自pH5.0~pH6.5之间的pH下的针对抗原的结合与在选自pH7.0~pH9.0之间的pH下针对抗原的结合的活性差异进行分选。除此之外,可基于选自pH5.5~pH6.5之间的pH下的针对抗原的结合与在选自pH7.0~pH8.0之间的pH下针对抗原的结合的活性差异进行分选。此外,在其它非限定的实施方式中,可基于生物体内的早期核内体内的pH下的针对抗原的结合与生物体内的血浆中的pH下的针对抗原的结合的活性差异,具体而言,基于pH 5.8下的针对抗原的结合与在pH7.4下的针对抗原的结合的活性差异进行分选。
在本发明的非限定性的一种实施方式中,分离出多核苷酸(该多核苷酸编码如前文所述选择的结合活性根据条件而变化的抗原结合分子)之后,将该多核苷酸插入合适的表达载体中。即,得到编码目标抗原结合分子的可变区的cDNA之后,通过识别向该cDNA的两个末端插入的限制性酶位点的限制性酶来消化该cDNA。优选的限制性酶对在构成抗原结合分子的基因的碱基序列中出现频率低的碱基序列加以识别并消化。进而,为了将1个拷贝的消化片断以正确的方向插入载体中,优选插入能够赋予粘末端的限制性酶。通过如上文所述消化的编码抗原结合分子的可变区的cDNA插入适当的表达载体中,能够获得本发明的抗原结合分子的表达载体。此时,编码抗体恒定区(C区)的基因和编码所述可变区的基因可以以符合读码框的方式融合。
为制造期望的抗原结合分子,编码抗原结合分子的多核苷酸以与控制序列可作用地连接的形式并入表达载体中。控制序列包含例如增强子、启动子。此外,可在氨基末端添加合适的信号序列,以使得表达的抗原结合分子分泌到细胞外。例如,作为信号序列,可使用具有氨基酸序列MGWSCIILFLVATATGVHS(序列号13)的肽,但除此之外合适的信号序列也可被添加。表达的多肽在上述序列的羧基末端部分被切断,切断的多肽可作为成熟多肽分泌到细胞外。接着,通过利用该表达载体转化合适的宿主细胞,能够获得表达编码期望的抗原结合分子的多核苷酸的重组细胞。
为表达编码抗原结合分子的多核苷酸,编码抗原结合分子的重链(H链)和轻链(L链)的多核苷酸分别被并入不同的表达载体。通过利用并入了重链和轻链的载体共转染相同的宿主细胞,可表达具有重链和轻链的抗原结合分子。或者,可通过将编码重链和轻链的多核苷酸并入单一表达载体,来对宿主细胞进行转化(参照WO19994011523)。
用于通过将分离的编码抗原结合分子的多核苷酸导入合适的宿主来制作抗原结合分子的宿主细胞和表达载体的多种组合是公知的。这些表达系统中的任何一个均可应用于分离本发明的抗原结合分子。使用真核细胞作为宿主细胞的情况下,可合适地使用动物细胞、植物细胞或者真菌细胞。具体而言,作为动物细胞,可举例下述细胞。
(1)哺乳类细胞:CHO(中国仓鼠卵巢细胞系)、COS(猴肾细胞系)、骨髓瘤(Sp2/O、NS0等)、BHK(幼仓鼠肾细胞)、HEK293(具有经剪切的腺病毒(Ad)5DNA的人胚胎肾细胞)、PER.C6细胞(经5型(Ad5)腺病毒E1A和E1B基因转化的人胚胎视网膜细胞)、Hela、Vero等(Current Protocols in Protein Science(May,2001,Unit 5.9,Table 5.9.1)),
(2)两栖类细胞:非洲爪蟾卵母细胞等,
(3)昆虫细胞:sf9、sf21、Tn5等。
或者,作为植物细胞,利用来自烟草(Nicotiana tabacum)等烟草(Nicotiana)属的细胞的抗体基因表达系统是公知的。植物细胞的转化可合适地利用愈伤组织培养的细胞。
此外,作为真菌细胞,可利用下述细胞。
-酵母:酿酒酵母(Saccharomyces serevisiae)等酵母(Saccharomyces)属、甲醇同化酵母(巴斯德毕赤酵母,Pichia pastoris)等毕赤酵母属
-丝状菌:黑曲霉等曲霉属
此外,利用原核细胞的、编码抗原结合分子的多核苷酸的表达系统也是公知的。例如,使用细菌细胞的情况下,可合适地利用大肠杆菌(E.coli)、枯草芽孢杆菌等细菌细胞。这些细胞中,可通过转化导入包含编码目标抗原结合分子的多核苷酸的表达载体。通过体外培养经转化的细胞,可从该转化细胞的培养物获得期望的抗原结合分子。
对重组抗原结合分子的产生而言,除了上述宿主细胞之外,还可利用转基因动物。即,可从导入了编码期望的抗原结合分子的多核苷酸的动物获得该抗原结合分子。例如,将编码抗原结合分子的多核苷酸以符合读码框的方式插入编码乳汁中固有地产生的蛋白质的基因内部,其可作为融合基因而被构建。作为分泌进乳汁中的蛋白质,可利用山羊β酪蛋白。将包含融合基因(其中插入了编码抗原结合分子的多核苷酸)的DNA片断注入山羊胚胎,将该经注入的胚胎导入雌性山羊。由接受了胚胎的山羊生育转基因山羊(或者其子孙),从由该转基因山羊(或者其子孙)产生的乳汁中,能够获得期望的抗原结合分子与乳汁蛋白质的融合蛋白质。此外,为了增加从转基因山羊产生的包含期望的抗原结合分子的乳汁的量,可向转基因山羊给予激素(Bio/Technology(1994),12(7),699-702)。
将本说明书中记载的抗原结合分子给予人的情况下,作为该分子中的抗原结合结构域,可合适地采用来自基因重组型抗体(该基因重组型抗体为了降低对人的异源抗原性等目的而进行了人工改变)的抗原结合结构域。基因重组型抗体中包含例如人化(Humanized)抗体等。这些改变的抗体可使用公知的方法合适地制造。
用于制作本说明书中记载的抗原结合分子中的抗原结合结构域的抗原结合分子的可变区通常以在4个框架区(FR)中夹的3个互补性决定区(complementarity-determining region;CDR)而构成。CDR是实质上决定抗原结合分子的结合特异性的区域。CDR的氨基酸序列富含多样性。另一方面,构成FR的氨基酸序列即使在具有不同结合特异性的抗原结合分子之间也多显示出较高的同一性。因此,一般可通过CDR的移植将某抗原结合分子的结合特异性移植给其它抗原结合分子。
人源化抗体也被称为改型(reshaped)人抗体。具体而言,将除人之外的动物、例如小鼠抗体的CDR移植给人抗体的人源化抗体等是公知的。用于获得人源化抗体的一般性的基因重组手段也是已知的。具体而言,作为用于将小鼠的抗体的CDR移植至人的FR的方法,例如重叠·延伸(Overlap Extension)PCR是公知的。重叠·延伸PCR中,向用于合成人抗体的FR的引物中添加编码将被移植的小鼠抗体的CDR的碱基序列。针对4个FR分别准备引物。一般而言,在小鼠的CDR向人FR的移植中,选择与小鼠的FR具有较高同一性的人FR,在CDR的功能的维持中被认为是有利的。即,一般而言,优选利用包含与将移植的小鼠CDR邻近的FR的氨基酸序列具有较高同一性的氨基酸序列的人FR。
此外,连接的碱基序列被设计为互相以符合读码框的方式连结。通过各引物而个别地合成人FR。结果,可获得向各FR添加了编码小鼠CDR的DNA的产物。各产物的编码小鼠CDR的碱基序列被设计为互相重叠。接着,使将人抗体基因作为模板合成的产物的重叠的CDR部分互相退火,进行互补链合成反应。通过该反应,将人FR经由小鼠CDR的序列连接起来。
最终,3个CDR和4个FR连接而得的V区域基因通过向其5’末端和3’末端退火并添加了合适的限制性酶识别序列的引物而被全长扩增。通过将如上文所述获得DNA与编码人抗体C区的DNA以符合读码框的方式融合的方式插入到表达载体中,能够制作获得用于表达人化抗体的载体。将该具有并入物的载体导入宿主建立重组细胞后,通过培养该重组细胞、使得编码该人源化抗体的DNA表达,该人源化抗体被产生于该培养细胞的培养物中(EP239400、WO1996002576)。
通过对上文所述制作的人源化抗体与抗原的结合活性进行定性或定量测定、评价,能够合适地选择下述人抗体的FR,其使得在经由CDR而被连接时该CDR能形成良好的抗原结合位点。根据需要,还可取代FR的氨基酸序列,以使得改型人抗体的CDR形成合适的抗原结合位点。例如,应用在将小鼠CDR向人FR的移植中使用的PCR法,可向FR中导入氨基酸序列的突变。具体而言,可向退火至FR的引物中导入部分碱基序列的突变。由这样的引物合成的FR中就导入了碱基序列的突变。通过用上述方法对经氨基酸取代的突变型抗体对抗原的结合活性进行测定和评价,可选择具有期望的性质的突变FR序列(Sato等人,Cancer Res(1993)53,851-856)。
本发明的非限定性的一种实施方式中,分离出编码抗原结合分子(如前文所述选择的结合活性根据条件而变化)的多核苷酸之后,将该多核苷酸的修饰体插入合适的表达载体中。作为这样的修饰体之一,可优选举出编码筛选出的本发明的抗原结合分子的多核苷酸分子被人化的修饰体,所述筛选是通过将合成文库、以非人动物作为起源制作的免疫文库用作为随机化可变区文库而进行的。人化的抗原结合分子的修饰体的制作方法可采用与前述人源化抗体的制作方法相同的方法。
此外,作为修饰体的其它方式,可优选举出向分离的多核苷酸序列施加了下述修饰的修饰体,所述修饰使通过使用合成文库或天然文库作为随机化可变区文库筛选出的本发明的抗原结合分子针对抗原的结合亲和性增强(亲和性成熟化)。这样的修饰体可通过各种亲和性成熟化的公知手段来获得,例如,CDR诱变(Yang等人(J.Mol.Biol.(1995)254,392-403))、链改组(Marks等人(Bio/Technology(1992)10,779-783))、大肠杆菌诱变株的使用(Low等人(J.Mol.Biol.(1996)250,359-368))、DNA改组(Patten等人(Curr.Opin.Biotechnol.(1997)8,724-733))、噬菌体展示(Thompson等人(J.Mol.Biol.(1996)256,77-88))和有性PCR(sexual PCR)(Clameri等人(Nature(1998)391,288-291))。
如前文所述,作为通过本发明的制造方法制作的抗原结合分子,可举出包含FcRn(特别是人FcRn)结合结构域的抗原结合分子,作为FcRn(特别是人FcRn)结合结构域,可使用各种各样的修饰体。作为本发明的修饰体的一种实施方式,还可优选举出编码下述抗原结合分子的多核苷酸,所述抗原结合分子具有编码上述FcRn(特别是人FcRn)结合结构域的修饰体的多核苷酸和编码如前文所述选择的结合活性根据条件而变化的抗原结合分子的多核苷酸以符合读码框的方式连接而得的重链。
本发明的非限定性的一种实施方式中,作为FcRn(特别地,人FcRn)结合结构域,可优选举出例如序列号14表示的IgG1(N末端添加了Ala的AAC82527.1)、序列号15表示的IgG2(N末端添加了Ala的AAB59393.1)、序列号16表示的IgG3(CAA27268.1)、序列号17表示的IgG4(N末端添加了Ala的AAB59394.1)等的抗体的恒定区。IgG分子在血浆中滞留性较长(从血浆中的消失较慢),这是因为作为IgG分子的补救受体已知的FcRn能发挥功能。通过胞饮作用并入核内体的IgG分子与在核内体内的酸性条件下表达于核内体内的FcRn结合。不能与FcRn结合的IgG分子将进入溶酶体并在此处分解,而与FcRn结合的IgG分子将移动到细胞表面,通过在血浆中的中性条件下从FcRn解离而再次回到血浆中。
在血浆中的高钙浓度的条件下针对抗原较强地结合、在核内体内的低钙浓度的条件下从抗原解离的本发明的“针对抗原的结合活性根据钙离子浓度的条件而变化的抗原结合分子”可在核内体内从抗原解离。在血浆中的高钙浓度的条件下针对抗原较强地结合、在核内体内的低钙浓度的条件下从抗原解离的本发明的“针对抗原的结合活性根据钙离子浓度的条件而变化的抗原结合分子”在解离抗原后通过FcRn再循环进血浆中的话,则有可能再次结合至抗原。即,1分子的该抗原结合分子可重复结合至多个抗原。此外,结合至抗原结合分子的抗原在核内体内解离而不再循环进血浆中,因此可促进通过抗原结合分子向细胞内并入抗原,通过给予抗原结合分子促进抗原的消失,使得血浆中的抗原浓度降低。
在血浆中的pH中性区域的条件下针对抗原较强地结合、在核内体内的酸性条件下从抗原解离的本发明的“针对抗原的结合活性根据pH的条件而变化的抗原结合分子”可在核内体内从抗原解离。在血浆中的pH中性区域的条件下针对抗原较强地结合、在核内体内的酸性条件下从抗原解离的本发明的“针对抗原的结合活性根据钙离子浓度的条件而变化的抗原结合分子”在解离抗原后通过FcRn再循环进血浆中的话,则有可能再次结合至抗原。即,1分子的该抗原结合分子可重复结合至多个抗原。此外,结合至抗原结合分子的抗原在核内体内解离而不再循环进血浆中,因此可促进通过抗原结合分子向细胞内并入抗原,通过给予抗原结合分子促进抗原的消失,使得血浆中的抗原浓度降低。
关于在血浆中的高钙浓度的条件下针对抗原较强地结合、在核内体内的低钙浓度的条件下从抗原解离的本发明的“针对抗原的结合活性根据钙离子浓度的条件而变化的抗原结合分子”,通过向其赋予在血浆中的高钙浓度的条件下针对FcRn的结合,促进该抗原结合分子与抗原的复合体向细胞内的并入。即,通过给予该抗原结合分子,可促进抗原从血浆中消失,降低血浆中的抗原浓度。
关于在血浆中的pH中性区域的条件下针对抗原较强地结合、在核内体内的pH酸性条件下从抗原解离的本发明的“针对抗原的结合活性根据pH的条件而变化的抗原结合分子”,通过向其赋予在血浆中的pH中性区域的条件下针对FcRn的结合,促进该抗原结合分子与抗原的复合体向细胞内的并入。即,通过给予该抗原结合分子,可促进抗原从血浆中消失,降低血浆中的抗原浓度。
因为通常的包含Fc区的抗体在血浆中的pH中性区域的条件下不具有针对FcRn的结合活性,因此通常的抗体和抗体-抗原复合体通过非特异性的内吞作用被并入细胞内,通过在核内体内的pH酸性区域的条件下结合至FcRn而被输送至细胞表面。FcRn将抗体从核内体内输送到细胞表面,因此认为FcRn的一部分也存在于细胞表面,但因为细胞表面的pH中性区域的条件下抗体从FcRn解离,抗体被再循环进血浆中。
考虑到所述的包含作为FcRn结合结构域的Fc区的抗体在生物体内的动态的话,在血浆中的高钙浓度的条件下针对抗原较强地结合、在核内体内的低钙浓度的条件下从抗原解离的本发明的“针对抗原的结合活性根据钙离子浓度的条件而变化的抗原结合分子”在血浆中结合至抗原、在核内体内解离结合的抗原,因此认为抗原的消失速度变得与非特异性的内吞作用导致的向细胞中的并入速度相同。抗原结合分子针对抗原的结合对钙离子浓度的依赖性不充分的情况下,核内体内未解离的抗原再循环进血浆中,而在抗原结合分子针对抗原的结合对钙离子浓度的依赖性充分的情况下,抗原的消失速度受非特异性的内吞作用导致的向细胞中的并入所限。
此外,在血浆中的pH中性区域的条件下针对抗原较强地结合、在核内体内的pH酸性条件下从抗原解离的本发明的“针对抗原的结合活性根据pH的条件而变化的抗原结合分子”在血浆中结合至抗原、在核内体内解离结合的抗原,因此认为抗原的消失速度变得与非特异性的内吞作用导致的向细胞中的并入速度相同。抗原结合分子针对抗原的结合的pH依赖性不充分的情况下,核内体内未解离的抗原再循环进血浆中,而在抗原结合分子针对抗原的结合的pH依赖性充分的情况下,抗原的消失速度取决于非特异性的内吞作用导致的向细胞中的并入速度。
因此,通过向包含FcRn结合结构域的抗原结合分子赋予在pH中性区域中的与FcRn的结合能力,结合至细胞表面存在的FcRn的该抗原结合分子以FcRn依赖性方式并入细胞中。FcRn介导的向细胞中的并入速度比非特异性的内吞作用导致的向细胞中并入速度更快,因此通过赋予在pH中性区域中与FcRn的结合能力,可进一步加速抗原从血浆中消失的速度。即,具有在pH中性区域中针对FcRn的结合能力的抗原结合分子比通常的(血浆中的pH中性区域的条件下没有针对FcRn的结合活性)包含Fc区的抗原结合分子更快地将抗原送入细胞内,在核内体内解离抗原,再次被再循环至细胞表面或血浆中,在此处再次结合至抗原,再由FcRn介导而并入细胞内。因为在pH中性区域中针对FcRn的结合能力变高,可加速该循环的运转速度,因此可加速使抗原从血浆中消失的速度。进而,通过使抗原结合分子在pH酸性区域中的抗原结合活性比在pH中性区域中的抗原结合活性降低,能够进一步提高该效率。此外认为,通过增加利用1分子的抗原结合分子的运转数,能够结合至1分子的抗原结合分子的抗原的数量也变多。
本发明的抗原结合分子包含抗原结合结构域和FcRn(特别是FcRn)结合结构域,FcRn结合结构域对与抗原的结合不产生影响,并且即使从上述机制来考虑其也不依赖于抗原的种类,认为通过使得抗原结合分子在低钙离子浓度的条件下的抗原结合活性(结合能力)较在高钙离子浓度的条件下的抗原结合活性降低、和/或、通过增加血浆中的pH中性区域中与FcRn的结合活性,可促进抗原结合分子向细胞内并入抗原,加速抗原的消失速度。
本发明的抗原结合分子包含抗原结合结构域和FcRn(特别是FcRn)结合结构域,FcRn结合结构域对与抗原的结合不产生影响,并且即使从上述机制来考虑其也不依赖于抗原的种类,认为通过使得抗原结合分子在pH酸性区域的条件下的抗原结合活性(结合能力)较在pH中性区域的条件下的抗原结合活性降低、和/或、通过增加血浆中的pH中性区域中与FcRn的结合活性,可促进抗原结合分子向细胞内并入抗原,加速抗原的消失速度。
如关于前述结合活性的项目中所述的那样,抗体恒定区等FcRn结合结构域对FcRn的结合活性可通过本领域技术人员公知的方法来测定,关于pH以外的条件,可由本领域技术人员合适地确定。抗原结合分子的抗原结合活性和人FcRn结合活性可作为KD(Dissociation constant:解离常数)、表观KD(Apparent dissociation constant:表观解离常数)、作为解离速度的kd(Dissociation rate:解离速度)、或表观kd(ApparentdiSSociation:表观解离速度)等而被评价。这些可通过本领域技术人员公知的方法测定。例如可使用Biacore(GE healthcare)、Scatchard作图、流式细胞仪等。
测定抗体恒定区等FcRn结合结构域针对人FcRn的结合活性时,pH以外的条件可由本领域技术人员合适地选择,没有特别限定。例如,如WO2009125825中记载的那样,可在MES缓冲液、37℃的条件下测定。此外,抗体恒定区等FcRn结合结构域针对人FcRn的结合活性的测定可通过本领域技术人员公知的方法来进行,例如,可使用Biacore(GE Healthcare)等测定。抗体恒定区等FcRn结合结构域与人FcRn的结合活性的测定可通过下述方法来评价:向固定化有FcRn结合结构域或包含FcRn结合结构域的本发明的抗原结合分子或人FcRn的芯片上分别流动作为待分析物的人FcRn或FcRn结合结构域或包含FcRn结合结构域的本发明的抗原结合分子。
作为具有结合活性(该结合活性是指抗体恒定区等FcRn结合结构域或包含FcRn结合结构域的抗原结合分子与FcRn的结合活性)的条件的pH中性区域,通常表示pH6.7~pH10.0。pH中性区域优选为通过pH7.0~pH8.0的任意pH值表示的范围,优选选自pH7.0、7.1、7.2、7.3、7.4、7.5、7.6、7.7、7.8、7.9和8.0,特别优选为接近体内的血浆中(血中)的pH的pH7.4。pH7.4处的人FcRn结合结构域与人FcRn的结合亲和性低,因此在难于评价该结合亲和性的情况下,可使用pH7.0代替pH7.4。本发明中,作为具有结合活性(该结合活性是指人FcRn结合结构域或包含人FcRn结合结构域的抗原结合分子与FcRn的结合活性)的条件的pH酸性区域,通常表示pH4.0~pH6.5。优选表示pH5.5~pH6.5,特别优选表示接近体内早期核内体内的pH的pH5.8~pH6.0。作为测定条件中使用的温度,人FcRn结合结构域或包含人FcRn结合结构域的抗原结合分子与FcRn的结合亲和性也可使用10℃~50℃中的任意温度来评价。优选地,为了确定人FcRn结合结构域或包含人FcRn结合结构域的抗原结合分子与FcRn的结合亲和性,使用15℃~40℃的温度。更优选地,20℃~35℃中的任意温度,例如20℃、21℃、22℃、23℃、24℃、25℃、26℃、27℃、28℃、29℃、30℃、31℃、32℃、33℃、34℃和35℃中的任一温度,也可同样用于确定人FcRn结合结构域或包含人FcRn结合结构域的抗原结合分子与FcRn的结合亲和性。25℃这样的温度是本发明的实施方式的一个非限定性例子。
根据The Journal of Immunology(2009)182:7663-7671,天然型人IgG1的人FcRn结合活性在pH酸性区域(pH6.0)下为KD 1.7μM,但在pH中性区域中则基本检测不到。因此,在优选的方式中,在pH酸性区域和pH中性区域中具有人FcRn结合活性的本发明的抗原结合分子(包括pH酸性区域中的人FcRn结合活性为KD 20μM或更强、pH中性区域中的人FcRn结合活性为与天然型人IgG同等或更强的抗原结合分子)可被筛选。在更优选的实施方式中,pH酸性区域中的人FcRn结合活性为KD 2.0μM或更强、pH中性区域中的人FcRn结合活性为KD40μM或更强的抗原结合分子可被筛选。在进一步更优选的实施方式中,pH酸性区域中的人FcRn结合活性为KD 0.5μM或更强、pH中性区域中的人FcRn结合活性为KD 15μM或更强的抗原结合分子可被筛选。上述KD值可根据The Journal of Immunology(2009)182:7663-7671中记载的方法(将抗原结合分子固定于芯片上,将人FcRn作为待分析物流动)来确定。
本发明中,优选在pH酸性区域和pH中性区域中具有人FcRn结合活性的FcRn结合结构域。该结构域如果本来就是在pH酸性区域和pH中性区域中具有人FcRn结合活性的FcRn结合结构域的话,则其可原样使用。该结构域在pH酸性区域和/或pH中性区域中没有人FcRn结合活性或者人FcRn结合活性弱的情况下,可通过修饰抗原结合分子中的氨基酸,来获得具有期望的对人FcRn的结合活性的FcRn结合结构域,但也可通过修饰人FcRn结合结构域中的氨基酸,来获得在pH酸性区域和/或pH中性区域中具有期望的对人FcRn的结合活性的FcRn结合结构域。另外,通过预先在pH酸性区域和/或pH中性区域中具有人FcRn的结合活性的FcRn结合结构域中的氨基酸的修饰,也可以获得具有所期望的对人FcRn的结合活性的FcRn结合结构域。这样的获得所期望的结合活性的人FcRn结合结构域的氨基酸修饰,可通过对氨基酸修饰前和修饰后的pH酸性区域和/或pH中性区域中的人FcRn结合活性加以比较来发现。本领域技术人员还可使用公知的手段来实施合适的氨基酸修饰。
本发明中,FcRn结合结构域的“氨基酸的修饰”或“氨基酸修饰”包括修饰为与起始FcRn结合结构域的氨基酸序列不同的氨基酸序列。起始FcRn结合结构域的修饰体能在pH酸性区域和/或中性区域中结合人FcRn即可(因此,起始FcRn结合结构域并不需要要有在pH酸性区域和/或中性区域的条件下对人FcRn的结合活性),任一FcRn结合结构域均可作为起始结构域使用。作为起始FcRn结合结构域的例子,可优选举出IgG抗体的恒定区,即序列号14~17中任一表示的天然型的恒定区。此外,将已经添加了修饰的FcRn结合结构域作为起始FcRn结合结构域、额外进行了修饰的修饰FcRn结合结构域也可优选作为本发明的修饰FcRn结合结构域而使用。起始FcRn结合结构域可表示多肽自身、包含起始FcRn结合结构域的组合物、或者编码起始FcRn结合结构域的氨基酸序列。起始FcRn结合结构域中可包含抗体的项目中概述的通过重组产生的公知的IgG抗体的FcRn结合结构域。起始FcRn结合结构域的来源没有限定,其可从非人动物的任意生物或从人获得。优选地,作为任意生物,可优选举出选自小鼠、大鼠、旱獭、仓鼠、沙鼠、猫、兔、狗、山羊、绵羊、牛、马、骆驼和非人灵长类的生物。其它形式中,起始FcRn结合结构域还可从食蟹猕猴、狨猴、猕、黑猩猩或人获得。虽然起始FcRn区优选从人IgG获得,但不限于IgG的特定类别。这表示可合适地使用人IgG1、IgG2、IgG3或IgG4的Fc区作为起始Fc区。作为人IgG1、IgG2、IgG3或IgG4的Fc区,由于基因多态性产生的多条异型(allotype)序列被记载于Sequences of proteins of immunologicalinterest,NIH Publication No.91-3242中,其任一均可用于本发明中。特别地,作为人IgG1的序列,EU编号356-358位的氨基酸序列可以为DEL也可以为EEM。同样,在本说明书中意味着来自前述任意生物的IgG的任意类别或亚类的FcRn结合结构域可优选作为起始FcRn结合结构域使用。天然存在的IgG的变体或经操作的形式的例子被记载于公知的文献(Curr.Opin.Biotechnol.(2009)20(6),685-91、Curr.Opin.Immunol.(2008)20(4),460-470、Protein Eng.Des.Sel.(2010)23(4),195-202、WO2009086320、WO2008092117、WO2007041635、和WO2006105338)中,但不限于那些。
为了向包含FcRn(特别是人FcRn)结合结构域的抗原结合分子赋予在pH中性区域中对FcRn(特别是人FcRn)的结合能力,可向与FcRn的结合相关的FcRn结合结构域中的氨基酸施加合适的变异。使用抗体IgG分子的恒定区作为FcRn结合结构域的情况下,可举出下述经修饰的恒定区,其中,以EU编号表示的第221位~225位、227位、228位、230位、232位、233~241位、243~252位、254~260位、262~272位、274位、276位、278~289位、291~312位、315~320位、324位、325位、327~339位、341位、343位、345位、360位、362位、370位、375~378位、380位、382位、385~387位、389位、396位、414位、416位、423位、424位、426~438位、440位和442位的位置处的氨基酸与天然型IgG的恒定区的相应氨基酸不同。更具体而言,可举出下述恒定区的修饰体,其中例如以EU编号表示的第256位的氨基酸为Pro、第280位的氨基酸为Lys、第339位的氨基酸为Thr、第385位的氨基酸为His、第428位的氨基酸为Leu、和/或第434位的氨基酸为Trp、Tyr、Phe、Ala或His中的任一个。通过使用这些修饰体,可使得IgG型免疫球蛋白的Fc区在pH中性区域中对人FcRn的结合活性变强。
此外,还可合适地使用能使得在pH酸性区域中对人FcRn的结合比天然型IgG的恒定区强的修饰体。这些修饰体中,可合适地选择即使在pH中性区域中对人FcRn的结合也能变强的修饰体,将其用于本发明中。作为这样的例子,可举出下述经修饰的恒定区,其中恒定区中以EU编号表示的氨基酸与天然型IgG的恒定区的相应氨基酸不同。作为这样的氨基酸的修饰例,可优选地使用包含表1中列举的氨基酸的恒定区的修饰体。
表1
作为特别优选的氨基酸的修饰,可举出例如EU编号第237位、238位、239位、248位、250位、252位、254位、255位、256位、257位、258位、265位、270位、286位、289位、297位、298位、303位、305位、307位、308位、309位、311位、312位、314位、315位、317位、325位、332位、334位、360位、376位、380位、382位、384位、385位、386位、387位、389位、424位、428位、433位、434位和436位表示的氨基酸被取代为与天然型IgG的恒定区中对应的氨基酸不同的氨基酸的修饰。通过将从这些氨基酸中选择的至少一个氨基酸修饰为其它氨基酸,能够提高FcRn结合结构域在pH中性区域下对人FcRn的结合活性。
作为特别优选的修饰,例如,可优选举出以天然型IgG的恒定区的EU编号表示的下述修饰:
第237位的氨基酸为Met,
第238位的氨基酸为Ala,
第239位的氨基酸为Lys,
第248位的氨基酸为Ile,
第250位的氨基酸为Ala、Phe、Ile、Met、Gln、Ser、Val、Trp或Tyr中的任一个,
第252位的氨基酸为Phe、Trp或Tyr中的任一个,
第254位的氨基酸为Thr,
第255位的氨基酸为Glu,
第256位的氨基酸为Asp、Glu或Gln中的任一个,
第257位的氨基酸为Ala、Gly、Ile、Leu、Met、Asn、Ser、Thr或Val中的任一个,
第258位的氨基酸为His,
第265位的氨基酸为Ala,
第270位的氨基酸为Phe,
第286位的氨基酸为Ala或Glu中的任一个,
第289位的氨基酸为His,
第297位的氨基酸为Ala,
第298位的氨基酸为Gly,
第303位的氨基酸为Ala,
第305位的氨基酸为Ala,
第307位的氨基酸为Ala、Asp、Phe、Gly、His、Ile、Lys、Leu、Met、Asn、Pro、Gln、Arg、Ser、Val、Trp或Tyr中的任一个,
第308位的氨基酸为Ala、Phe、Ile、Leu、Met、Pro、Gln或Thr中的任一个,
第309位的氨基酸为Ala、Asp、Glu、Pro或Arg中的任一个,
第311位的氨基酸为Ala、His或Ile中的任一个,
第312位的氨基酸为Ala或His中的任一个,
第314位的氨基酸为Lys或Arg中的任一个,
第315位的氨基酸为Ala或His中的任一个,
第317位的氨基酸为Ala,
第325位的氨基酸为Gly,
第332位的氨基酸为Val,
第334位的氨基酸为Leu,
第360位的氨基酸为His,
第376位的氨基酸为Ala,
第380位的氨基酸为Ala,
第382位的氨基酸为Ala,
第384位的氨基酸为Ala,
第385位的氨基酸为Asp或His中的任一个,
第386位的氨基酸为Pro,
第387位的氨基酸为Glu,
第389位的氨基酸为Ala或Ser中的任一个,
第424位的氨基酸为Ala,
第428位的氨基酸为Ala、Asp、Phe、Gly、His、Ile、Lys、Leu、Asn、Pro、Gln、Ser、Thr、Val、Trp或Tyr中的任一个,
第433位的氨基酸为Lys,
第434位的氨基酸为Ala、Phe、His、Ser、Trp或Tyr中的任一个,和
第436位的氨基酸为His。
此外,被修饰的氨基酸的数量没有特别限定,可以仅修饰一个位置的氨基酸,也可以修饰2个以上位置的氨基酸。作为2个以上位置的氨基酸的修饰的组合,可举出表2所示的那样的组合。
表2-1
表2-2
表2-3
表2-4
表2-5
表2-6
表2-7
表2-8
表2-9
表2-10
表2-11
表2-12
表2-13
表2-14
表2-15
表2-16
表2-17
表2-18
表2-19
表2-20
表2-21
表2-22
表2-23
表2-24
表2-25
表2-26
表2-27
表2-28
表2-29
作为修饰的例子,包括一个以上的突变,例如,被取代为与起始Fc区的氨基酸不同的氨基酸残基的突变,或对起始Fc区的氨基酸插入一个以上的氨基酸残基或者从起始Fc区的氨基酸缺失一个以上的氨基酸等。优选地,修饰后的Fc区的氨基酸序列中包含含有天然不产生的Fc区的至少部分的氨基酸序列。这类变体必然与起始Fc区具有不到100%的序列同一性或类似性。优选的实施方式中,变体与起始Fc区的氨基酸具有约75%~不到100%的氨基酸序列同一性或类似性,更优选约80%~不到100%,更优选约85%~不到100%,更优选约90%~不到100%,最优选约95%~不到100%的氨基酸序列同一性或类似性。在本发明的非限定的一种实施方式中,起始Fc区与本发明的经修饰的Fc区之间有至少一个氨基酸的差异。起始Fc区与修饰Fc区的氨基酸的区别,还可优选通过特别是以前述EU编号特定的氨基酸残基位置上的特定的氨基酸的区别来确定。
为了修饰Fc区的氨基酸,可适当地采用位点特异性的突变诱导法(Kunkel等人(Proe.Natl.Acad.Sci.USA(1985)82,488-492))或重叠·延伸PCR(Overlap extensionPCR)等公知的方法。此外,作为取代为天然氨基酸以外的氨基酸的氨基酸修饰方法,可采用多种公知的方法(Annu.Rev.Biophys.Biomol.Struct.(2006)35,225-249,Proc.Natl.Acad.Sci.U.S.A.(2003)100(11),6353-6357)。例如,还可适合地使用含有tRNA的无细胞翻译系统(Clover Direct(Protein Express))等,所述无细胞翻译系统中,非天然氨基酸结合至作为终止密码子之一的UAG密码子(琥珀密码子)的互补的琥珀抑制基因tRNA上。
编码下述抗原结合分子的多核苷酸也可作为本发明的修饰体的一种实施方式而制作,所述抗原结合分子具有编码前述这样添加了氨基酸的突变的Fc结合结构域的修饰体的多核苷酸、和编码前述这样结合活性根据选择的条件而变化的抗原结合分子的多核苷酸以符合读码框的方式连接而得的重链。
根据本发明,提供了制造抗原结合分子的方法,所述方法包括从下述细胞的培养液回收抗原结合分子,所述细胞中导入了下述载体,所述载体中可作用地连接了与编码FcRn结合结构域的多核苷酸以符合读码框的方式连接的、从本发明的病毒分离的多核苷酸。此外,本发明还提供了制造抗原结合分子的方法,所述方法包括从下述细胞的培养液回收抗原结合分子,所述细胞中导入了下述载体,所述载体中可作用地连接了与载体中预先可作用地连接的编码FcRn结合结构域的多核苷酸以符合读码框的方式连接的、从本发明的病毒分离的多核苷酸。
本发明不限于特定的理论,例如对于将下述抗原结合分子给予生物体时通过促进向生物体中的细胞中的并入从而1分子的抗原结合分子可结合的抗原数量增加的理由以及血浆中抗原浓度的消失被促进的理由,例如可如下文所述来说明,所述抗原结合分子包含:针对抗原的结合活性根据离子浓度的条件而变化、使得pH酸性区域中针对抗原的结合活性比pH中性区域的条件中针对抗原的结合活性更低的抗原结合结构域,以及额外地,在pH中性区域的条件下具有针对人FcRn的结合活性的抗体恒定区等的FcRn结合结构域。
例如,将抗原结合分子结合至膜抗原的抗体给予至生物体内的情况下,该抗体结合至抗原之后,保持结合至抗原的状态与抗原一起通过内化作用并入细胞内的核内体中。之后,以结合至抗原的状态转移到溶酶体的抗体与抗原一起被溶酶体分解。经由内化作用从血浆中的消失,被称为抗原依赖性消失,这在多种抗体分子中有所报道(Drug DiscovToday(2006)11(1-2),81-88)。1个分子的IgG抗体以2价结合至抗原的情况下,1个分子的抗体以结合至2个分子的抗原的状态被内化,就此被溶酶体分解。因此,对通常的抗体来说,1个分子的IgG抗体不可能结合至3个分子以上的抗原。例如,具有中和活性的1个分子的IgG抗体的情况下,不能中和3个分子以上的抗原。
IgG分子在血浆中滞留性较长(从血浆中的消失较慢),这是因为作为IgG分子的补救受体已知的FcRn能发挥功能。通过胞饮作用并入核内体的IgG分子与在核内体内的酸性条件下表达于核内体内的人FcRn结合。不能与人FcRn结合的IgG分子之后进入溶酶体并在其中分解。而与人FcRn结合的IgG分子将转移到细胞表面。在血浆中的中性条件下IgG分子从人FcRn解离,因此IgG分子再次回到血浆中。
此外抗原结合分子为结合至可溶型抗原的抗体的情况下,给予至生物体内的抗体结合至抗原,之后,抗体以与抗原结合的状态被并入细胞内。被并入细胞内的抗体中的大多数,在核内体内结合至FcRn之后转移到细胞表面。在血浆中的中性条件下抗体与人FcRn解离,因此被释放到细胞外。但是,包含针对抗原的结合活性不根据pH等离子浓度的条件而变化的通常的抗原结合结构域的抗体以与抗原结合的状态被释放到细胞外,因此,不能再次结合至抗原。因此,与结合至膜抗原的抗体相同,针对抗原的结合活性不根据pH等的离子浓度的条件而变化的通常的1分子IgG抗体不能结合至3分子以上的抗原。
在血浆中的pH中性区域的条件下与抗原较强地结合、在核内体内的酸性条件下从抗原解离的pH依赖性地与抗原结合的抗体(在pH中性区域的条件下与抗原结合、在pH酸性区域的条件下解离的抗体),或者,在血浆中的高钙浓度的条件下与抗原较强地结合、在核内体内的低钙浓度的条件下从抗原解离的钙离子浓度依赖性地与抗原结合的抗体(在高钙离子浓度的条件下与抗原结合、在低钙离子浓度的条件下解离的抗体)可在核内体内从抗原解离。pH依赖性地与抗原结合的抗体或钙离子浓度依赖性地与抗原结合的抗体,在解离抗原后通过FcRn再循环进血浆中的话,则有可能再次结合至抗原。因此,1分子的抗体可重复结合至多个抗原分子。此外,结合至抗原结合分子的抗原因在核内体内从抗体解离而不再循环进血浆中、而是于溶酶体内被分解。通过将这样的抗原结合分子给予生物体,可促进抗原向细胞内的并入,使得血浆中的抗原浓度降低。
在血浆中的pH中性区域的条件下与抗原较强地结合、在核内体内的酸性条件下从抗原解离的pH依赖性地与抗原结合的抗体(在pH中性区域的条件下与抗原结合、在pH酸性区域的条件下解离的抗体),或者,在血浆中的高钙浓度的条件下与抗原较强地结合、在核内体内的低钙浓度的条件下从抗原解离的钙离子浓度依赖性地与抗原结合的抗体(在高钙离子浓度的条件下与抗原结合、在低钙离子浓度的条件下解离的抗体),通过向其赋予在血浆中的pH中性区域的条下(pH 7.4)针对人FcRn的结合能力,进一步促进该抗原结合分子结合的抗原向细胞内的并入。即,通过将这样的抗原结合分子给予至生物体内,可促进抗原的消失、降低血浆中的抗原浓度。对于不具有pH依赖性的针对抗原的结合能力、或不具有钙离子浓度依赖性的针对抗原的结合能力的、通常的抗体及其抗体-抗原复合体来说,通过非特异性的内吞作用被并入细胞内,通过在核内体内的pH酸性区域的条件下结合至FcRn而被输送至细胞表面,通过在细胞表面的pH中性条件下从FcRn解离而被再循环进血浆中。因此,以充分pH依赖性与抗原结合(在pH中性区域的条件下结合、在pH酸性区域的条件下解离)、或以充分的钙离子浓度依赖性与抗原结合(在高钙离子浓度的条件下结合、在低钙离子浓度的条件下解离)的抗体在血浆中结合至抗原、在核内体内解离结合的抗原时,认为抗原的消失速度变得与非特异性的内吞作用导致的抗体及其抗体-抗原复合体向细胞中的并入速度相同。抗体和抗原间的结合的pH依赖性或钙离子浓度依赖性不充分的情况下,核内体内未从抗体解离的抗原也与抗体一起再循环进血浆中,而在pH依赖性充分的情况下,抗原的消失速度取决于非特异性的内吞作用导致的向细胞中的并入速度。此外,FcRn将抗体从核内体内输送到细胞表面,因此认为FcRn的一部分也存在于细胞表面。
通常,作为抗原结合分子的一种实施方式的IgG型免疫球蛋白基本不具有在pH中性区域中针对FcRn的结合活性。本发明的发明人认为,在pH中性区域中具有针对FcRn的结合活性的IgG型免疫球蛋白能结合至细胞表面存在的FcRn,通过结合至细胞表面存在的FcRn,该IgG型免疫球蛋白以FcRn依赖性方式被并入细胞。经由FcRn介导的并入细胞的速度比通过非特异性的内容作用导致的向细胞中的并入速度更快。因此认为,通过赋予在pH中性区域中针对FcRn的结合能力,能够进一步加快抗原结合分子导致的抗原消失的速度。即,在pH中性区域中具有针对FcRn的结合能力的抗原结合分子比通常的(天然型人)IgG型免疫球蛋白更快地将抗原并入细胞,在核内体内抗原解离,再循环至细胞表面或血浆中,在那里再次与抗原结合,并且经由FcRn介导而被并入细胞中。通过提高pH中性区域中针对FcRn的结合能力,能够加快该循环的运转速度,因此能加块使抗原从血浆中消失的速度。进而,通过使抗原结合分子在pH酸性区域中针对抗原的结合活性较之在pH中性区域中针对抗原的结合活性降低,可进一步提高使抗原从血浆中消失的速度。此外认为,该循环的运转速度加快,结果导致该循环的数量增加,由此1分子的抗原结合分子可能结合的抗原的分子数量也会增多。本发明的抗原结合分子包含抗原结合结构域和FcRn结合结构域,FcRn结合结构域对与抗原的结合不产生影响,并且即使从上述机制来考虑其也不依赖于抗原的种类,认为通过使抗原结合分子在pH酸性区域或低钙离子浓度等离子浓度的条件下的针对抗原的结合活性(结合能力)较在pH中性区域或高钙离子浓度的条件等离子浓度的条件下的抗原结合活性(结合能力)降低、和/或、通过增加血浆中的pH下与FcRn的结合活性,可促进抗原结合分子向细胞内并入抗原,加速抗原的消失速度。因此认为,本发明的抗原结合分子在抗原带来的副作用的降低、抗体给予量的上升、抗体在生物体内的动态的改善等方面较之以往的治疗用抗体能发挥更优异的效果。
即,本发明涉及包含本发明的抗原结合分子、通过本发明的筛选方法分离的抗原结合分子、或者通过本发明的制造方法制造的抗原结合分子的医药组合物。较之通常的抗原结合分子而言,本发明的抗原结合分子或者通过本发明的制造方法制造的抗原结合分子通过其给药而使得血浆中的抗原浓度降低的作用高,因此作为医药组合物有用。本发明的医药组合物可包含医药许可的载体。
本发明中的医药组合物,通常指用于疾病的治疗或预防、或用于检查·诊断的药剂。
本发明的医药组合物,可使用本领域技术人员公知的方法而被制剂化。例如,可以以和水或除水以外的药学上许可的液体的无菌性溶液、或悬浮液的注射液的形式以非经口的方式使用。例如,与药理学上许可的载体或介质(具体而言,灭菌水或生理盐水、植物油、乳化剂、悬浊剂、表面活性剂、稳定剂、香味及、赋形剂、媒介(vehicle)、防腐剂、粘合剂等)适当地组合,按照一般认可的制药操作所要求的单位用量形式混合,从而被制剂化。这些制剂中的有效成分量被设定,以在指示的范围内获得适当的容量。
用于注射的无菌组合物可以使用注射用蒸馏水这样的媒介,按照通常的制剂操作来配方。作为注射用水溶液,可举出例如生理盐水、包含葡萄糖或其它辅助药物(例如D-山梨醇、D-甘露糖、D-甘露醇、氯化钠)的等渗液。可以与适当的助溶剂,例如醇(乙醇等)、多元醇(丙二醇、聚乙二醇等)、非离子性表面活性剂(例如聚山梨糖酯80(TM)、HCO-50等)联合使用。
作为油性液体,可举出芝麻油、大豆油,还可与苯甲酸苄酯和/或苯甲醇(作为助溶剂)并用。此外,还可与缓冲剂(例如磷酸盐缓冲液和乙酸钠缓冲液)、镇痛剂(例如盐酸普鲁卡因)、稳定剂(例如苯甲醇和苯酚)、抗氧化剂配合。制备的注射液通常被填充于合适的安瓿中。
本发明的医药组合物优选通过非经口方式给药。例如,可给药注射剂型、经鼻给药剂型、经肺给药剂型、经皮给药型的组合物。例如,可通过静脉内注射、肌内注射、腹腔内注射、皮下注射等方式全身或局部给药。
给药方法可以根据患者的年龄、症状而合适地选择。含有抗原结合分子的医药组合物的给药量例如可以被设定为每次0.0001mg~1000mg/1kg体重的范围内。此外,例如,例如可以设定为每名患者0.001~100000mg的给药量,但本发明并不一定限于这些数值。给药量和给药方法根据患者的体重、年龄、症状等而变动,本领域技术人员可以考虑到这些条件来设定适当的给药量和给药方法。
需要说明的是,本发明中记载的氨基酸序列中包含的氨基酸有时在翻译后接受修饰(例如,N末端的谷氨酰胺通过焦谷氨酰化而成为焦谷氨酸的修饰是本领域技术人员熟知的修饰),即使是这样氨基酸在翻译后被修饰的情况,也当然包含在本发明记载的氨基酸序列中。
需要说明的是,在本说明书中引用的所有现有技术文献均通过参照并入本说明书中。
本说明书中使用的情况下,通过“包含、包括、含有(comprising)……”的表述来进行表达的形式,包括通过“基本上由……构成(essentially consisting of)”的表述来进行表达的形式以及通过“由……构成(consisting of)”的表述来进行表达的形式。
实施例以下,通过实施例具体说明本发明,但本发明不受限于这些实施例。
(1-1)pH依赖性结合抗体的获得方法
WO2009125825公开了通过向抗原结合分子导入组氨酸在pH中性区域和pH酸性区域中性质变化的pH依赖性的抗原结合抗体。公开的pH依赖性结合抗体是通过将期望的抗原结合分子的氨基酸序列的一部分取代为组氨酸的修饰而获得的。为了不预先获得修饰对象的抗原结合分子而更高效地获得pH依赖性结合抗体,考虑从向可变区(更优选为存在参与抗体结合的可能性的位置)导入了组氨酸的抗原结合分子的群体(称为His文库)获得与期望的抗原结合的抗原结合分子的方法。从His文库获得的抗原结合分子与通常的抗体文库相比组氨酸以高频率出现,因此认为能够有效地获得具有期望的性质的抗原结合分子。
(1-2)为了高效地获得pH依赖性地与抗原结合的结合抗体,设计向可变区导入组氨酸残基的抗体分子的群体(His文库)
首先,选择His文库中导入组氨酸的位置。WO2009125825中公开了通过将IL-6受体抗体、IL-6抗体和IL-31受体抗体的序列中的氨基酸残基取代为组氨酸,制作了pH依赖性的抗原结合抗体。进而,通过将抗原结合分子的氨基酸序列取代为组氨酸,制作具有pH依赖性的抗原结合能力的抗蛋清溶菌酶抗体(FEBS Letter 11483,309,1,85-88)及抗铁调素(hepcidin)抗体(WO2009139822)。IL-6受体抗体、IL-6抗体、IL-31受体抗体、蛋清溶菌酶抗体及铁调素抗体中导入组氨酸的位置如表3所示。表3中示出的位置,可作为能够控制抗原与抗体的结合的位置的候选列出。进而,即使在表3所示的位置以外,与抗原接触的可能性高的位置也被认为适合作为导入组氨酸的位置。
表3
由重链可变区和轻链可变区构成的His文库中,重链可变区使用人抗体序列,向轻链可变区中导入了组氨酸。作为在His文库中导入组氨酸的位置,可选择上文举出的位置和存在与抗原结合相关的可能性的位置,即,轻链的第30位、32位、50位、53位、91位、92位和93位(Kabat编号,Kabat EA et al.1991.Sequence of Proteins of ImmunologicalInterest.NIH)。此外,作为导入组氨酸的轻链可变区的模板序列,选择了Vk1序列。使得模板序列中出现多个氨基酸,构成文库的抗原结合分子的多样性得到扩展。关于使得多个氨基酸出现的位置,选择了与抗原的相互作用可能性高的、暴露于可变区的表面的位置。具体而言,作为上述灵活残基,可以选择轻链的第30位、31位、32位、34位、50位、53位、91位、92位、93位、94位和96位(Kabat编号,Kabat EA et al.1991.Sequence of Proteins ofImmunological Interest.NIH)。
接着,设定使得其出现的氨基酸残基的种类和出现频率。对Kabat数据库(KABAT,E.A.ET AL.:′Sequences of proteins of immunological interest′,vol.91,1991,NIHPUBLICATION)中登记的hVk1和hVk3的序列中的灵活残基处的氨基酸的出现频率进行了分析。基于分析结果,从在各位置出现频率高的氨基酸选择使得在His文库中出现的氨基酸的种类。此时,分析结果中被判定为出现频率低的氨基酸也被选择,以避免氨基酸的性质出现偏差。此外,关于选择的氨基酸的出现频率,参考Kabat数据库的分析结果而设定。
通过考虑如上文所述设定的氨基酸以及出现频率,作为His文库,设计了以组氨酸在各CDR中必有1个的方式固定的His文库1和比His文库1更重视序列多样性的His文库2。His文库1和His文库2的详细设计如表4和表5所示(各表中的位置表示Kabat编号)。此外,关于表4和表5中记载的氨基酸的出现频率,可排除在以Kabat编号法表示的第92位为Asn(N)时第94位为Ser(S)。
表4
表5
以从人PBMC制作的多聚A RNA或市售的人多聚A RNA等作为模板,通过PCR法扩增了抗体重链可变区的基因文库。使用PCR法扩增了作为实施例1中记载的His文库1而设计的抗体轻链可变区的基因文库。将这样制作的抗体重链可变区的基因文库和抗体轻链可变区的基因文库的组合插入至噬粒载体中,构建了呈示包含人抗体序列的Fab结构域的人抗体噬菌体展示文库。作为构建方法,参考(Methods Mol Biol.(2002)178,87-100)。构建上述文库之际,使用下述噬菌体展示文库的序列,其包含连接噬粒的Fab和噬菌体pIII蛋白质的接头部分以及在辅助噬菌体pIII蛋白质基因的N2结构域和CT结构域之间插入了胰蛋白酶(tryptic)切断序列而得的序列。从导入了抗体基因文库的大肠杆菌分离的抗体基因部分的序列被确认,获得了132个克隆的序列信息。设计的氨基酸分布和确认到的序列中的氨基酸的分布如图1所示。构建了包含与设计的氨基酸分布对应的多样化的序列的文库。
(3-1)通过珠粒淘选从文库获得pH依赖性地与抗原结合的抗体片断
对于从构建的His文库1中的最初的选拔,通过仅富集具有与抗原(IL-6R)的结合能力的抗体片断来实施。
从保持了构建的噬菌体展示用噬粒的大肠杆菌,进行噬菌体产生。通过向进行了噬菌体产生的大肠杆菌的培养液中添加2.5M NaCl/10%PEG而沉淀的噬菌体的群体被稀释于TBS中,由此获得噬菌体文库液。通过向噬菌体文库液中添加BSA和CaCl
具体而言,通过向制备的噬菌体文库液中添加250pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。用1mL的1.2mM CaCl
第2次以后的淘选中,以抗原结合能力或pH依赖性的结合能力为指标进行噬菌体的富集。具体而言,通过向制备的噬菌体文库液中添加40pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。以1mL的1.2mM CaCl
(3-2)通过噬菌体ELISA进行的评价
按照常规方法(Methods Mol.Biol.(2002)178,133-145)从按上述方法获得的大肠杆菌的单菌落回收了含有噬菌体的培养上清液。
将添加了BSA和CaCl
以抗原结合能力作为指标进行富集的情况下,进行2次淘选后实施噬菌体ELISA,结果在96个克隆中抗原特异性地成为ELISA阳性的有17个克隆,因此对实施3次淘选之后的克隆进行了分析。另一方面,以pH依赖性的抗原结合能力作为指标进行富集的情况下,针对进行过2次淘选的产物实施噬菌体ELISA,结果在94个克隆中ELISA阳性的有70个克隆,因此对进行过2次淘选的克隆进行了分析。
针对实施了上述噬菌体ELISA的克隆,分析了使用特异性引物扩增得到的基因的碱基序列。
噬菌体ELISA和序列分析的结果示于下表6中。
表6
通过同样的方法,从天然人抗体噬菌体展示文库获得了具有pH依赖性的抗原结合能力的抗体。以抗原结合能力作为指标进行富集的情况下,在88个克隆评价中,获得了13种pH依赖性地结合的抗体。此外,在以pH依赖性的抗原结合能力作为指标进行富集的情况下,在83个克隆评价中获得了27种的pH依赖性地结合的抗体。
通过以上结果,确认到:较之天然人抗体噬菌体展示文库,His文库1中得到的具有pH依赖性的抗原结合能力的克隆版本较多。
(3-3)抗体的表达和纯化
将在噬菌体ELISA的结果中被判断为具有pH依赖性的针对抗原的结合能力的克隆导入动物细胞表达用质粒。使用以下的方法进行抗体的表达。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293Expression Medium培养基(Invitrogen)中,以1.33x10
(3-4)对获得的抗体针对人IL-6受体的pH依赖性的结合能力的评价
为了判断(3-3)中获得的抗体6RpH#01(重链序列号18、轻链序列号19)和6RpH#02(重链序列号20、轻链序列号21)和6RpH#03(重链序列号22、轻链序列号23)针对人IL-6受体的结合活性是否为pH依赖性的,使用Biacore T100(GE Healthcare)分析了这些抗体与人IL-6受体的相互作用。作为对人IL-6受体没有pH依赖性的结合活性的对照抗体,使用了托珠单抗(重链序列号24、轻链序列号25)。作为中性区域pH和酸性区域pH的条件,分别在pH7.4和pH6.0的溶液中分析了抗原抗体反应的相互作用。在通过胺偶联法固定化了适当的量的蛋白质A/G(Invitrogen)的传感器芯片(Sensor chip)CM5(GE Healthcare)上,分别捕获了300RU左右的目标抗体。关于运行缓冲液,使用20mM ACES、150mM NaCl、0.05%(w/v)Tween20、1.2mM CaCl
在针对使用了对照抗体即托珠单抗、6RpH#01抗体和6RpH#02抗体和6RpH#03抗体的抗原抗体反应的相互作用进行分析时,通过以流速5μL/min、以3分钟注射IL-6受体的稀释液和作为空白的运行缓冲液,使得IL-6受体与被捕获于传感器芯片上的托珠单抗、6RpH#01抗体和6RpH#02抗体和6RpH#03抗体相互作用。之后,通过以流速30μL/min、以30秒注射10mM Glycine-HCl(pH1.5),传感器芯片被再生。
通过前述方法测定的pH7.4下的传感图示于图2。此外,以同样的方法获得的pH6.0的条件下的传感图示于图3。
从前述结果观察到:通过将缓冲液中的pH从pH7.4变为pH6.0,6RpH#01抗体、6RpH#02抗体和6RpH#03抗体针对IL6受体的结合能力大幅降低。
以从人PBMC制作的多聚A RNA或市售的人多聚A RNA等作为模板,通过PCR法扩增了抗体重链可变区的基因文库。如实施例1中记载的那样,为了提高具有pH依赖性的抗原结合能力的抗体的出现频率,抗体可变区轻链部分被设计为,在抗体可变区的轻链部分中,成为抗原接触位点的可能性高的位点处的组氨酸残基的出现频率被提高。此外,抗体轻链可变区的文库被设计为:作为灵活残基中导入了组氨酸的残基以外的氨基酸残基,使得由天然人抗体中的氨基酸出现频率的信息特定的出现频率高的氨基酸均等地分布。合成了经上述这样设计的抗体轻链可变区的基因文库。文库的合成可委托为商业性的受委托公司等来制作。将这样制作的抗体重链可变区的基因文库和抗体轻链可变区的基因文库的组合插入噬粒载体,按照公知的方法(Methods Mol Biol.(2002)178,87-100),构建了呈示包含人抗体序列的Fab结构域的人抗体噬菌体展示文库。按照实施例2记载的方法,确认了从导入了抗体基因文库的大肠杆菌分离出的抗体基因部分的序列。
(5-1)通过珠粒淘选从文库获得pH依赖性地与抗原结合的抗体片断
对于从构建的His文库2中的最初的选拔,通过仅富集具有与抗原(IL-6受体)的结合能力的抗体片断来实施。
从保持了构建的噬菌体展示用噬粒的大肠杆菌进行噬菌体的产生。通过向进行了噬菌体产生的大肠杆菌的培养液中添加2.5M NaCl/10%PEG而沉淀的噬菌体的群体被稀释于TBS中,由此获得噬菌体文库液。接着,作为封闭剂,向噬菌体文库液中添加BSA或脱脂奶。作为淘选方法,参照作为一般性方法的使用了固定化至磁性珠粒的抗原的淘选方法(J.Immunol.Methods.(2008)332(1-2),2-9、J.Immunol.Methods.(2001)247(1-2),191-203、Biotechnol.Prog.(2002)18(2)212-20、Mol.Cell Proteomics(2003)2(2),61-9)。作为磁性珠粒,使用涂布有NeutrAvidin的珠粒(Sera-Mag SpeedBeads NeutrAvi din-coated)或涂布有链亲和素的珠粒(Dynabeads M-280Streptavidin)。
具体而言,通过向制备的噬菌体文库液中添加250pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经封闭剂封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。用1mL的TBST对珠粒清洗3次,之后用1mL的TBS再清洗2次。之后,将添加了0.5mL的1mg/mL胰蛋白酶的珠粒在室温下悬浮15分钟,之后立即使用磁性表座分离珠粒,回收噬菌体溶液。回收的噬菌体溶液被添加至已达对数生长期(OD600为0.4-0.7)的10mL的大肠杆菌株ER2738中。通过于37℃对上述大肠杆菌缓缓进行1小时的搅拌培养,使得噬菌体感染大肠杆菌。经感染的大肠杆菌被接种至225mm x 225mm的板上。接着,通过从经接种的大肠杆菌的培养液回收噬菌体,制备了噬菌体文库液。
第2次以后的淘选中,以抗原结合能力或pH依赖性的结合能力为指标进行噬菌体的富集。具体而言,通过向制备的噬菌体文库液中添加40pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA或脱脂奶封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。以1mL的TBST和TBS对珠粒进行清洗。之后,以抗原结合能力作为指标进行富集的情况下,将添加了0.5mL的1mg/mL胰蛋白酶的珠粒在室温下悬浮15分钟,之后立即使用磁性表座分离珠粒,回收噬菌体溶液。在以pH依赖性的抗原结合能力作为指标进行富集的情况下,将添加了0.1mL的50mM MES/1.2mM CaCl
(5-2)通过噬菌体ELISA进行的评价
按照常规方法(Methods Mol.Biol.(2002)178,133-145)从按上述方法获得的大肠杆菌的单菌落回收了含有噬菌体的培养上清液。
将添加了BSA和CaCl
对将在上述噬菌体ELISA的结果中被判断为具有pH依赖性的与抗原的结合能力的抗体片断作为模板、利用特异性引物进行扩增而得的基因的碱基序列进行了分析。
(5-3)抗体的表达和纯化
将在噬菌体ELISA的结果中被判断为具有pH依赖性的与抗原的结合能力的克隆导入动物细胞表达用质粒。使用以下的方法进行抗体的表达。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293 Expression Medium培养基(Invitrogen)中,以1.33x10
(5-4)获得的抗体针对人IL-6受体的pH依赖性的结合能力的评价
为了判断实施例5中获得的抗体针对人IL-6受体的结合活性是否为pH依赖性的,使用Biacore T100(GE Healthcare)分析了这些抗体与人IL-6受体的相互作用。作为对人IL-6受体没有pH依赖性的结合活性的对照抗体,使用了托珠单抗(重链序列号24、轻链序列号25)。作为中性区域pH和酸性区域pH的条件,分别在pH7.4和pH6.0的溶液中分析了抗原抗体反应的相互作用。目标抗体被捕获于通过胺偶联法固定化了适当的量的蛋白质A/G(Invitrogen)的传感器芯片CM5(GE Healthcare)上。关于运行缓冲液,使用20mM ACES、150mM NaCl、0.05%(w/v)Tween20、1.2mM CaCl
在针对使用对照抗体即托珠单抗、实施例5中获得的抗体的抗原抗体反应的相互作用进行分析时,通过注射IL-6受体的稀释液和作为空白的运行缓冲液,使得IL-6受体与捕获于传感器芯片上的抗体上相互作用。之后,通过以流速30μL/min、以30秒注射10mMGlycine-HCl(pH1.5),传感器芯片被再生。pH 6.0的条件下的传感器也以同样的方法获得。
实施例6对与钙离子结合的人生殖细胞系序列的探索
(6-1)钙依赖性地与抗原结合的抗体
钙依赖性地与抗原结合的抗体(钙依赖性的抗原结合抗体)是其与抗原的相互作用根据钙的浓度而变化的抗体。因为认为钙依赖性的抗原结合抗体经由钙离子结合至抗原,所以形成抗原侧的表位的氨基酸为能够螯合钙离子的负电荷的氨基酸、或能成为氢结合受体的氨基酸(图4B)。由形成上述表位的氨基酸的性质,能够靶向通过图4A所示的导入组氨酸而制作的pH依赖性地结合至抗原的结合分子以外的表位。进而认为,如图4C所示,通过使用兼具钙依赖性地和pH依赖性地结合至抗原的性质的抗原结合分子,能够制作可分别靶向多样化表位(具有范围广阔的性质)的抗原结合分子。因此认为,构建包含结合钙的基序的分子的集合(Ca文库)、从该分子群体获得抗原结合分子的话,能够高效获得钙依赖性的抗原结合抗体。
(6-2)人生殖细胞系序列的获得
作为包含结合钙的基序的分子的集合的例子,可举出该分子为抗体的例子。换言之,认为有时包含结合钙的基序的抗体文库为Ca文库。
迄今为止没有报道过通过包含人生殖细胞系序列的抗体来结合钙离子。因此,为了判定包含人生殖细胞系序列的抗体是否结合钙离子,以从Human Fetal Spreen PolyRNA(Clontech)制备的cDNA作为模板,克隆了包含人生殖细胞系序列的抗体的生殖细胞系序列。克隆而得的DNA片断被插入至动物细胞表达载体中。得到的表达载体的碱基序列由本领域技术人员公知的方法确定,氨基酸序列的序列号如表7所示。通过PCR法将编码序列号6(Vk1)、序列号7(Vk2)、序列号8(Vk3)、序列号9(Vk4)以及序列号:1(Vk5)的多核苷酸与编码天然型Kappa链的恒定区(序列号26)的多核苷酸连接,将得到的DNA片断并入动物细胞表达用载体中。此外,通过PCR法将编码序列号27(Vk1)、序列号28(Vk2)、序列号29(Vk3)以及序列号30(Vk4)的重链可变区多核苷酸与编码序列号14的C末端的2个氨基酸缺失了的IgG1的多核苷酸连接,将得到的DNA片断并入动物细胞表达用载体中。通过本领域技术人员公知的方法确认了制作的修饰体的序列。需要说明的是,人的Vk1记载为hVk1,人的Vk2记载为hVk2,人的Vk3记载为hVk3,人的Vk4记载为hVk4。
表7
(6-3)抗体的表达和纯化
将插入了获得的5种包含人生殖细胞系序列的DNA片断的动物细胞表达载体导入动物细胞。使用以下的方法进行抗体的表达。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293Expression Medium培养基(Invitrogen)中,以1.33x10
(6-4)包含人生殖细胞系序列的抗体的钙离子结合活性的评价
对经纯化的抗体的钙离子结合活性进行了评价。作为对钙离子向抗体的结合的评价的指标,热变性中值温度(Tm值)通过示差扫描热量测定法(DSC)被测定(MicroCal VP-Capillary DSC、MicroCal)。热变性中值温度(Tm值)为稳定性的指标,如果蛋白质通过钙离子的结合而稳定化,则热变性中值温度(Tm值)将变得比未结合钙离子的情况高(J.Biol.Chem.(2008)283,37,25140-25149)。通过评价与抗体溶液中的钙离子浓度的变化相应的抗体Tm值的变化,评价了钙离子对抗体的结合活性。经纯化的抗体被供给至以20mMTris-HCl、150mM NaCl、2mM CaCl
表8
结果,包含hVk1、hVk2、hVk3、hVk4序列的抗体的Fab结构域的Tm值不基于包含该Fab结构域的溶液中的钙离子的浓度而变动。另一方面,包含hVk5序列的抗体的Fab结构域的Tm值基于包含该Fab结构域的抗体溶液中的钙离子的浓度而变动,这表明hVk5序列与钙离子结合。
(6-5)对hVk5-2序列的钙结合评价
实施例6的(6-2)中,除了Vk5-2(序列号26被融合至序列号1上而得的)之外,还得到了被分类为Vk5-2的Vk5-2变体1(序列号2)和Vk5-2变体2(序列号3)。针对这些变体也进行了钙结合评价。Vk5-2、Vk5-2变体1和Vk5-2变体2的DNA片断分别被并入动物细胞用表达载体。通过本领域技术人员公知的方法确定得到的表达载体的碱基序列。以实施例6的(6-3)记载的方法,将分别并入了Vk5-2、Vk5-2变体1和Vk5-2变体2的DNA片断的动物细胞用表达载体、与使得CIM_H(序列号4)能作为重链表达的方式被并入的动物表达用载体共同导入动物细胞中,抗体被纯化。对经纯化的抗体的钙离子结合活性进行了评价。经纯化的抗体被供给至以20mM Tris-HCl、150mM NaCl、2mM CaCl
表9
结果,包含Vk5-2、Vk5-2变体1和Vk5-2变体2的序列的抗体的Fab结构域的Tm值基于包含该Fab结构域的抗体溶液中的钙离子的浓度而变动,这表明具有分类为Vk5-2的序列的抗体与钙离子结合。
实施例7对人Vk5(hVk5)序列的评价
(7-1)hVk5序列
Kabat数据库中,作为hVk5序列,仅hVk5-2序列被登记。下文中,将hVk5和hVk5-2视为同义。WO2010136598中,hVk5-2序列在生殖细胞系序列中的存在比例被记载为0.4%。其它报道中也提到hVk5-2序列在生殖细胞系序列中的存在比例为0~0.06%(J.Mol.Biol.(2000)296,57-86、Proc.Natl.Acad.Sci.(2009)106,48,20216-20221)。如上文所述,由于hVk5-2序列为生殖细胞系序列中出现频率较低的序列,所以认为通过对表达以人生殖细胞系序列构成的抗体文库或人抗体的小鼠进行免疫获得B细胞、从所述B细胞获得与钙结合的抗体效率不高。因此,虽然认为存在设计包含人hVk5-2序列的Ca文库的可能性,但报道过的合成抗体文库(WO2010105256、WO2010136598)中不含hVk5序列。进而,没有报道过关于hVk5-2序列的物性,其实现可能性此前是未知的。
(7-2)未添加糖链的hVk5-2序列的构建、表达和纯化
hVk5-2序列具有在第20位(Kabat编号)的氨基酸上添加了N型糖链的序列。向蛋白质上添加的糖链中存在异质性,因此,从物质的均一性的观点来看,优选不添加糖链。因此,制作了第20位(Kabat编号)的Asn(N)残基被取代为Thr(T)残基的修饰体hVk5-2L65(序列号5)。氨基酸的取代通过使用QuikChange Site-Directed Mutagenesis Kit(Stratagene)的本领域技术人员公知的方法来进行。编码修饰体hVk5-2_L65的DNA被并入动物表达用载体。以实施例6中记载的方法,将并入了制作的修饰体hVk5-2_L65的DNA的动物表达用载体与以CIM_H(序列号4)作为重链进行表达的方式而并入的动物表达用载体一起导入动物细胞中。以实施例6记载的方法纯化了在导入的动物细胞中表达的包含hVk5-2_L65和CIM_H的抗体。
(7-3)对包含未添加糖链的hVk5-2序列的抗体的物性评价
通过使用离子交换色谱,对获得的包含修饰序列hVk5-2_L65的抗体与修饰前的原始的包含hVk5-2序列的抗体相比异质性是否减少进行了分析。离子交换色谱的方法示于表10中。分析的结果显示,如图5所示那样对糖链添加位点进行了修饰的hVk5-2_L65较之原始的hVk5-2序列而言异质性减少。
表10
接着,使用实施例6记载的方法,对异质性减少的包含hVk5-2_L65序列的抗体是否与钙离子结合进行了评价。其结果,如表11所示,包含糖链添加位点被修饰的hVk5-2_L65的、抗体的Fab结构域的Tm值,也根据抗体溶液中钙离子的浓度的变化而变动。即,表明钙离子结合至包含糖链添加位点被修饰的hVk5-2_L65的抗体的Fab结构域上。
表11
实施例8钙离子针对包含hVk5-2序列的CDR序列的抗体分子的结合活性的评价
(8-1)包含hVk5-2序列的CDR序列的经修饰抗体的制作、表达和纯化
hVk5-2_L65序列为人Vk5-2序列的框架中存在的糖链添加位点的氨基酸经修饰的序列。虽然实施例7中表明即使修饰糖链添加位点钙离子也能结合,但从免疫原性的观点来看,一般优选框架序列为生殖细胞系的序列。因此,对于是否可能在维持钙离子对抗体的的结合活性的同时、将该抗体的框架序列取代为没有添加糖链的生殖细胞系序列的框架序列进行了研究。
通过PCR法,将编码其中化学合成的hVk5-2序列的框架序列被修饰为hVk1、hVk2、hVk3和hVk4序列而得的序列(分别为CaVk1(序列号31)、CaVk2(序列号32)、CaVk3(序列号33)、CaVk4(序列号34)的多核苷酸与编码天然型Kappa链的恒定区(序列号26)的多核苷酸连接,将连接而得的DNA片断并入动物细胞表达用载体。通过本领域技术人员公知的方法确认了制作得到的修饰体的序列。按照实施例6记载的方法,将如上文所述制作的各质粒与并入了编码CIM_H(序列号4)的多核苷酸的质粒一起导入动物细胞。从如上文所述已导入的动物细胞的培养液中纯化所表达的期望的抗体分子。
(8-2)包含hVk5-2序列的CDR序列的经修饰抗体的钙离子结合活性的评价
通过实施例6记载的方法,对包含hVk5-2序列以外的生殖细胞系序列(hVk1、hVk2、hVk3、hVk4)的框架序列和hVK5-2序列的CDR序列的经修饰抗体上是否结合钙离子进行了评价。评价结果示于表12。其显示各经修饰抗体的Fab结构域的Tm值根据抗体溶液中的钙离子浓度的变化而变动。因此表明,包含hVk5-2序列的框架序列以外的框架序列的抗体也结合钙离子。
表12
进而,热变性温度(Tm值)是以包含hVk5-2序列以外的生殖细胞系序列(hVk1、hVk2、hVk3、hVk4)的框架序列和hVK5-2序列的CDR序列的方式修饰的、各抗体的Fab结构域的热稳定性的指标,明确发现,与包含修饰前的原始的hVk5-2序列的抗体的Fab结构域的Tm值相比,有所增加。由该结果发现,包含hVk1、hVk2、hVk3、hVk4的框架序列和hVk5-2序列的CDR序列的抗体具有与钙离子结合的性质,从热稳定性的观点来看也是优秀的分子。
实施例9人生殖细胞系hVk5-2序列中存在的钙离子结合位点的鉴定
(9-1)对hVk5-2序列的CDR序列中的突变位点的设计
如实施例8中记载的那样,显示包含下述轻链的抗体也与钙离子结合,所述轻链为hVk5-2序列的CDR部分被导入其它生殖细胞系的框架序列而得的。该结果表明了存在于hVk5-2中钙离子结合位点存在于CDR中。作为与钙离子结合、即与钙离子螯合的氨基酸,可举出负电荷的氨基酸或可成为氢结合的受体的氨基酸。因此,针对包含突变hVk5-2序列(hVk5-2序列的CDR序列中存在的Asp(D)残基或Glu(E)残基被取代为Ala(A)残基而得的)的抗体是否与钙离子结合进行了评价。
(9-2)hVk5-2序列的Ala取代体的制作以及抗体的表达和纯化
制作了包含下述轻链的抗体分子,所述轻链中,hVk5-2序列的CDR序列中存在的Asp和/或Glu残基被修饰为Ala残基。如实施例7中记载的那样,没有添加糖链的修饰体hVk5-2_L65维持了钙离子结合,因此从钙离子结合性的观点来看,认为与hVk5-2序列等同。本实施例中,将hVk5-2_L65作为模板序列进行了氨基酸取代。制作的修饰体示于表13中。氨基酸的取代按照QuikChange Site-Directed Mutagenesis Kit(Stratagene)、PCR或Infusion Advantage PCR cloning kit(TAKARA)等本领域技术人员公知的方法来进行,构建了氨基酸被取代的修饰轻链的表达载体。
表13
按照本领域技术人员公知的方法来确定获得的表达载体的碱基序列。通过将制作的修饰轻链的表达载体与重链CIM_H(序列号4)的表达载体一起暂时导入来自人胎儿肾癌细胞的HEK293H株(Invitrogen)或FreeStyle293细胞(Invitrogen),使抗体表达。使用rProtein A SepharoseTM Fast Flow(GE Healthcare),按照本领域技术人员公知的方法从得到的培养上清液纯化了抗体。使用分光光度计,测定了经纯化的抗体溶液在280nm的吸光度。通过使用利用PACE法算出的吸光系数,从得到的测定值计算出抗体浓度(ProteinScience(1995)4,2411-2423)。
(9-3)包含hVk5-2序列的Ala取代体的抗体的钙离子结合活性评价
按照实施例6记载的方法,对得到的纯化抗体是否与钙离子结合进行了判定。其结果示于表14中。存在下述抗体:通过将hVk5-2序列的CDR序列中存在的Asp或Glu残基取代为与钙离子的结合或螯合无关的Ala残基,其Fab结构域的Tm值不根据抗体溶液的钙离子浓度的变化而变动。其表明:通过Ala取代Tm值不变动的取代位点(32位和92位(Kabat编号))对于钙离子与抗体的结合来说特别重要。
表14
实施例10包含具有钙离子结合基序的hVk1序列的抗体的评价
(10-1)具有钙离子结合基序的hVk1序列的制作以及抗体的表达和纯化
由实施例9中记载的Ala取代体的钙结合活性的结果表明,hVk5-2序列的CDR序列中,Asp、Glu残基对于钙结合来说是重要的。因此,对即使仅将第30位、31位、32位、50位和92位(Kabat编号)的残基导入其它生殖细胞系的可变区序列中是否能与钙离子结合进行了评价。具体而言,制作了下述修饰体LfVk1_Ca(序列号43),其中作为人生殖细胞系序列的hVk1序列的第30位、31位、32位、50位和92位(Kabat编号)的残基被取代为hVk5-2序列的第30位、31位、32位、50位和92位(Kabat编号)的残基。即,对下述抗体是否能与钙结合进行了判定,所述抗体包含向hVk5-2序列中仅导入了上述5个残基而得的hVk1序列。修饰体的制作与实施例9同样地进行。使得得到的轻链修饰体LfVk1_Ca和包含轻链hVk1序列的LfVk1(序列号44)与重链CIM_H(序列号4)一起表达。抗体的表达和纯化按照与实施例9相同的方法实施。
(10-2)包含具有钙离子结合基序的人hVk1序列的抗体的钙离子结合活性的评价
按照实施例6中记载的方法,对按上文所述获得的纯化抗体是否结合钙离子进行了判定。其结果示于表15中。包含具有hVk1序列的LfVk1的抗体的Fab结构域的Tm值不根据抗体溶液中的钙浓度的变化而变动,但另一方面,包含LfVk1_Ca的抗体序列的Tm值则根据抗体溶液中的钙浓度的变化而变化了1℃以上,由此表明包含LfVk1_Ca的抗体与钙结合。由上述结果表明,对钙离子的结合而言,hVk5-2的CDR序列并非全部必要,仅构建LfVk1_Ca序列时导入的残基就足够了。
表15
(10-3)分解抑制型LfVk1_Ca序列的构建、表达和纯化
实施例10的(10-1)中,制作了修饰体LfVk1_Ca(序列号43)(其中作为人生殖细胞系序列的hVk1序列的第30位、31位、32位、50位和92位(Kabat编号)的残基被取代为hVk5-2序列的第30位、31位、32位、50位和92位(Kabat编号)的残基),显示其结合钙离子。因此,认为有设计包含LfVk1_Ca序列的Ca文库的可能性,但是由于没有对LfVk1_Ca序列的物性的报道,其实现可能性此前是未知的。关于LfVk1_Ca序列,第30位、31位和32位(Kabat编号)存在Asp,在CDR1序列中存在Asp-Asp序列(被报道为在酸性条件下分解)(J.Pharm.Biomed.Anal.(2008)47(1),23-30)。从保存稳定性的观点来看,希望避免在酸性条件下的分解。因此,制作了将存在分解可能性的Asp(D)残基取代为Ala(A)残基的修饰体LfVk1_Ca1(序列号45)、LfVk1_Ca2(序列号46)和LfVk1_Ca3(序列号47)。氨基酸的取代按照使用了QuikChange Site-Directed Mutagenesis Kit(Stratagene)的本领域技术人员公知的方法来进行。将编码修饰体的DNA并入动物表达用载体中,按照实施例6记载的方法,将并入了制作的修饰体的DNA的动物表达用载体和将GC_H(序列号48)以能作为重链表达的方式并入的动物表达用载体一起导入动物细胞中。按照实施例6记载的方法,对在导入的动物细胞中表达的抗体进行纯化。
(10-4)包含分解抑制型LfVk1_Ca序列的抗体的稳定性评价
通过比较热加速后的各抗体的异质性,对实施例10的(10-3)中获得的抗体与包含修饰前的初始LfVk1_Ca序列的抗体相比在pH6.0溶液中的分解是否受到抑制进行了评价。将各抗体于20mM组氨酸-HCl、150mM NaCl、pH6.0的溶液中于4℃的条件下透析一夜。将经透析的抗体制备为0.5mg/mL,在5℃或50℃下保存3天。以实施例7记载的方法对保存后的各抗体进行了离子交换色谱分析。分析的结果如图6所示,分解位点被修饰的LfVk1_Ca1比初始的LfVk1_Ca序列异质性少,其表明显著抑制了热加速导致的分解。即表明,通过氨基酸修饰可避免LfVk1_Ca序列中的第30位上存在的Asp(D)残基的分解。
(10-5)轻链第30位Asp残基分解抑制型LVk1_Ca序列的制作以及抗体的表达和纯化
从实施例10的(10-4)中记载的Ala取代体的分解抑制的结果可见,LfVk1_Ca序列的CDR序列中第30位(Kabat编号)的Asp(D)残基在酸性条件下分解,通过将第30位(Kabat编号)取代为其它氨基酸((10-4)中取代为Ala(A)残基),则可抑制分解。因此,针对将第30位(Kabat编号)的残基取代为Ser(S)残基(为能与钙离子螯合的残基的代表)而得的序列(称为LfVk1_Ca6。序列号49)是否能抑制分解进行了评价。修饰体的制作与实施例10同样地进行。使所得的轻链修饰体LfVk1_Ca6和轻链LfVk1_Ca序列与重链GC_H(序列号48)一起表达。抗体的表达和纯化按照与实施例10相同的方法实施。
(10-5)轻链第30位Asp残基分解抑制型LVk1_Ca序列的评价
按照实施例10的(10-4)记载的方法,对按照上文所述得到的纯化抗体在酸性条件下的保存稳定性进行了判定。结果显示,如图7所示,较之包含初始的LfVk1_Ca序列的抗体而言,包含LfVk1_Ca6序列的抗体的分解受到抑制。
进而,按照实施例6记载的方法,对包含LfVk1_Ca序列的抗体和包含LfVk1_Ca6序列的抗体是否与钙离子结合进行了判定。其结果示于表16。包含LfVk1_Ca序列的抗体和包含作为分解抑制型的LfVk1_Ca6序列的抗体的Fab结构域的Tm值分别根据抗体溶液中的钙浓度的变化而变化了1℃以上。
表16
实施例11设计将钙离子结合基序导入可变区的抗体分子的群体(Ca文库),以能更加高效地获得Ca浓度依赖性地与抗原结合的结合抗体
作为钙结合基序,可优选举出例如hVk5-2序列或其CDR序列,进而缩窄至残基第30位、31位、32位、50位、92位(Kabat编号)。此外,与钙结合的蛋白质具有的EF-HAND基序(钙调蛋白等)、C型凝集素(ASGPR等)也是钙结合基序。
Ca文库由重链可变区和轻链可变区构成。重链可变区使用人抗体序列,向轻链可变区中导入钙结合基序。作为将导入钙结合基序的轻链可变区的模板序列,选择了hVk1序列。包含LfVk1_Ca序列(将作为钙结合基序之一的hVk5-2的CDR序列向hVk1序列中导入而得的)的抗体如实施例10所示,显示出与钙离子结合。使得模板序列中出现多个氨基酸,以扩展构成文库的抗原结合分子的多样性。关于使多个氨基酸出现的位置,选择了与抗原的相互作用可能性高的、暴露于可变区的表面的位置。具体而言,第30位、31位、32位、34位、50位、53位、91位、92位、93位、94位和96位(Kabat编号)作为这些灵活残基而被选择。
接着,设定使得其出现的氨基酸残基的种类和出现频率。对Kabat数据库(KABAT,E.A.ET AL.:′Sequences of proteins of immunological interest′,Vol.91,1991,NIHPUBLICATION)中登记的hVk1和hVk3的序列中的灵活残基处的氨基酸的出现频率进行了分析。基于分析结果,从在各位置出现频率高的氨基酸中选择在Ca文库中出现的氨基酸的种类。此时,分析结果中被判定为出现频率低的氨基酸也被选择,以避免氨基酸的性质出现偏差。此外,关于选择的氨基酸的出现频率,参考Kabat数据库的分析结果而设定。
通过考虑如上文所述设定的氨基酸以及出现频率,作为Ca文库,设计了下述重视序列多样性的Ca文库,其包含钙结合基序、在该基序以外的各残基处包含多种氨基酸。Ca文库的详细设计示于表17和表18中(各表中的位置表示Kabat编号)。此外,关于表17和表18中记载的氨基酸的出现频率,以Kabat编号法表示的第92位为Asn(N)时,第94位可以不为Ser(S)而为Leu(L)。
表17
表18
实施例12 Ca文库的制作
以从人PBMC制作的多聚A RNA或市售的人多聚A RNA等作为模板,通过PCR法扩增了抗体重链可变区的基因文库。关于抗体轻链可变区部分,按照实施例11所记载的那样设计了提高了下述抗体出现频率的抗体可变区轻链部分,所述抗体维持钙结合基序、并能钙浓度依赖性地与抗原结合。此外,作为灵活残基中、导入钙结合基序的残基以外的氨基酸残基,参考天然人抗体中的氨基酸出现频率的信息((KABAT,E.A.ET AL.:′Sequences ofproteins of immunological interest′,vol.91,1991,NIH PUBLICATION),设计了使得在天然人抗体的序列中出现频率高的氨基酸均等分布的抗体轻链可变区的文库。将这样制作的抗体重链可变区的基因文库和抗体轻链可变区的基因文库的组合插入噬粒载体,构建了呈示包含人抗体序列的Fab结构域的人抗体噬菌体展示文库(Methods Mol Biol.(2002)178,87-100)。
按照实施例2记载的方法,针对从导入了抗体基因文库的大肠杆菌分离的抗体基因部分的序列进行了确认。得到的290种克隆的序列的氨基酸分布与设计的氨基酸分布示于图8。
实施例13 Ca文库中包含的分子的钙离子结合活性的评价
(13-1)Ca文库中包含的分子的钙离子结合活性
如实施例7所示,显示与钙离子结合的hVk5-2序列为在生殖细胞系序列中出现频率低的序列,因此认为,从由人生殖细胞系序列构成的抗体文库中、或从通过对表达人抗体的小鼠进行免疫而获得的B细胞中得到与钙结合的抗体是没有效率的。因此,在实施例12中构建了Ca文库。对构建的Ca文库中是否存在显示钙结合的克隆进行了评价。
(13-2)抗体的表达和纯化
将Ca文库中包含的克隆导入动物细胞表达用质粒。使用以下的方法进行抗体的表达。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle293Expression Medium培养基(Invitrogen)中,以1.33x10
(13-3)获得的抗体的钙离子结合性的评价
按照实施例6记载的方法,对按上文所述获得的纯化抗体是否与钙离子结合进行了判定。其结果示于表19。Ca文库中包含的多种抗体的Fab结构域的Tm根据钙离子浓度而变动,显示包含有与钙离子结合的分子。
表19
实施例14获得Ca依赖性地与IL-6受体结合的抗体
(14-1)通过珠粒淘选从文库获得Ca依赖性地结合至抗原的抗体片断
从构建的Ca文库中的最初的选拔,通过仅富集具有与抗原(IL-6受体)的结合能力的抗体片断来实施。
由保持了构建的噬菌体展示用噬粒的大肠杆菌进行噬菌体的产生。通过向进行了噬菌体产生的大肠杆菌的培养液中添加2.5M NaCl/10%PEG而沉淀的噬菌体的群体被稀释于TBS中,由此获得噬菌体文库液。接着,通过向噬菌体文库液中添加BSA和CaCl
具体而言,通过向制备的噬菌体文库液中添加250pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。用1mL的1.2mM CaCl
第2次的淘选中,以抗原结合能力或Ca依赖性的结合能力为指标进行噬菌体的富集。
具体而言,在以抗原结合能力为指标进行富集时,通过向制备的噬菌体文库液中添加40pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。用1mL的1.2mM CaCl
在以Ca依赖性的结合能力为指标进行富集时,通过向制备的噬菌体文库液中添加40pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。以1mL的1.2mMCaCl
(14-2)通过噬菌体ELISA进行的评价
按照常规方法(Methods Mol.Biol.(2002)178,133-145)从按上述方法获得的大肠杆菌的单菌落中回收了含有噬菌体的培养上清液。
将添加了BSA和CaCl
针对实施了上述噬菌体ELISA的克隆,对使用特异性引物扩增得到的基因的碱基序列进行了分析。噬菌体ELISA和序列分析的结果示于下表20中。
表20
(14-3)抗体的表达和纯化
将在噬菌体ELISA的结果中被判断为具有Ca依赖性地与抗原结合的能力的克隆导入动物细胞表达用质粒。使用以下的方法进行抗体的表达。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293Expression Medium培养基(Invitrogen)中,以1.33x10
(14-4)获得的抗体与人IL-6受体的Ca依赖性的结合能力的评价
为了判断实施例14中获得的抗体6RC1IgG_010(重链序列号72、轻链序列号73)、和6RC1IgG_012(重链序列号74、轻链序列号75)、和6RC1IgG_019(重链序列号76、轻链序列号77)针对人IL-6受体的结合活性是否为Ca依赖性的,使用Biacore T100(GE Healthcare)分析了这些抗体与人IL-6受体的相互作用。作为对人IL-6受体没有Ca依赖性的结合活性的对照抗体,使用了托珠单抗(重链序列号24、轻链序列号25)。作为高钙离子浓度和低钙离子浓度的条件,分别在1.2mM和3μM的钙离子浓度的溶液中对相互作用进行了分析。在通过胺偶联法固定化了适当的量的蛋白质A/G(Invitrogen)的传感器芯片CM5(GE Healthcare)上,捕获了目标抗体。关于运行缓冲液,使用20mM ACES、150mM NaCl、0.05%(w/v)Tween20、1.2mMCaCl
在分析使用了对照抗体即托珠单抗、6RC1IgG_010抗体和6RC1IgG_012抗体和6RClIgG_019抗体的抗原抗体反应的相互作用时,通过以流速5μL/min、以3分钟注射IL-6受体的稀释液和作为空白的运行缓冲液,使得IL-6受体与被捕获于传感器芯片上的托珠单抗、6RC1IgG_010抗体和6RC1IgG_012抗体和6RC1IgG_019抗体相互作用。之后,通过以流速30μL/min、以30秒注射10mM Glycine-HCl(pH1.5),传感器芯片被再生。
通过前述方法测定的高钙离子浓度下的传感图示于图9。
以相同的方法获得了关于低钙离子浓度的条件下的托珠单抗、6RC1IgG_010抗体、6RC1IgG_012抗体及6RC1IgG_019抗体的传感图。低钙离子浓度下的传感图示于图10中。
从前述结果观察到:通过将缓冲液中的钙离子浓度从1.2mM变为3μM,6RC1IgG_010抗体、6RC1IgG_012抗体和6RC1IgG_019抗体针对IL6受体的结合能力大幅降低。
实施例15从使用了噬菌体展示技术的人抗体文库获得Ca依赖性地与IL-6受体结合的抗体
(15-1)天然人抗体噬菌体展示文库的制作
以从人PBMC制作的多聚A RNA或市售的人多聚A RNA等作为模板,通过本领域技术人员公知的方法,构建了由多个噬菌体构成的人抗体噬菌体展示文库,所述噬菌体呈示互相之间不同的人抗体序列的Fab结构域。
(15-2)通过珠粒淘选从文库获得Ca依赖性地与抗原结合的抗体片断
从构建的天然人抗体噬菌体展示文库中的最初的选拔,通过仅富集具有与抗原(IL-6受体)的结合能力的抗体片断、或者通过以Ca浓度依赖性的与抗原(IL-6受体)结合的能力作为指标富集抗体片断来实施。以Ca浓度依赖性的与抗原(IL-6受体)结合的能力作为指标对抗体片断的富集通过下述方法实施:使用螯合Ca离子的EDTA,从在Ca离子存在下与IL-6受体结合的噬菌体文库洗脱出噬菌体。作为抗原,使用了经生物素标记的IL-6受体。
由保持了构建的噬菌体展示用噬粒的大肠杆菌进行噬菌体的产生。通过向进行了噬菌体产生的大肠杆菌的培养液中添加2.5M NaCl/10%PEG而沉淀的噬菌体的群体被稀释于TBS中,由此获得噬菌体文库液。接着,向噬菌体文库液中添加BSA和CaCl
具体而言,通过向制备的噬菌体文库液中添加250pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。用1mL的1.2mM CaCl
第2次以后的淘选中,以Ca依赖性的结合能力为指标进行噬菌体的富集。具体而言,通过向制备的噬菌体文库液中添加40pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。以1mL的1.2mM CaCl
(15-3)通过噬菌体ELISA进行的评价
按照常规方法(Methods Mol.Biol.(2002)178,133-145)从按上述方法获得的大肠杆菌的单菌落中回收了含有噬菌体的培养上清液。
将添加了BSA和CaCl
对将在噬菌体ELISA的结果中被判断为具有Ca依赖性的与抗原结合的能力的抗体片断作为模板、利用特异性引物进行扩增而得的基因的碱基序列进行了分析。
(15-4)抗体的表达和纯化
将在噬菌体ELISA的结果中被判断为具有Ca依赖性的与抗原结合的能力的克隆导入动物细胞表达用质粒。使用以下的方法进行抗体的表达。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293 Expression Medium培养基(Invitrogen)中,以1.33x10
实施例16获得的抗体与人IL-6受体的Ca依赖性的结合能力的评价
为了判断实施例15中获得的抗体6RL#9-IgG1(重链(序列号78、在序列号10上连接了来自IgG1的恒定区而得的序列)、轻链序列号79)、和FH4-IgG1(重链序列号80、轻链序列号81)与人IL-6受体的结合活性是否为Ca依赖性的,使用Biacore T100(GE Healthcare)对这些抗体与人IL-6受体的抗原抗体反应进行了速度理论分析。作为对人IL-6受体没有Ca依赖性的结合活性的对照抗体,使用了WO2009125825中记载的H54/L28-IgG1(重链序列号82、轻链序列号83)。作为高钙离子浓度和低钙离子浓度的条件,分别在2mM和3μM的钙离子浓度的溶液中对抗原抗体反应进行了速度理论分析。目标抗体被捕获于通过胺偶联法固定化了适当的量的蛋白质A(Invitrogen)的传感器芯片CM4(GE Healthcare)上。关于运行缓冲液,使用10mM ACES、150mMNaCl、0.05%(w/v)Tween20、2mM CaCl
在对使用了H54/L28-IgG1抗体的抗原抗体反应进行速度理论分析之际,通过以流速20μL/min、以3分钟注射IL-6受体的稀释液与作为空白的运行缓冲液,使得IL-6受体与被捕获于传感器芯片上的H54/L28-IgG1抗体相互作用。之后,以流速20μL/min将运行缓冲液流动10分钟,观察到IL-6受体的解离之后,通过以流速30μL/min、以30秒注射10mMGlycine-HCl(pH1.5),传感器芯片得以再生。从测定得到的传感图计算出作为动力学参数的结合速度常数ka(1/Ms)和解离速度常数kd(1/s)。使用这些值计算出H54/L28-IgG1抗体针对人IL-6受体的解离常数KD(M)。各参数的计算中,使用Biacore T100 EvaluationSoftware(GE Healthcare)。
在对使用了FH4-IgG1抗体和6RL#9-IgG1抗体的抗原抗体反应进行速度理论分析之际,通过以流速5μL/min、以15分钟注射IL-6受体的稀释液与作为空白的运行缓冲液,使得IL-6受体与被捕获于传感器芯片上的FH4-IgG1抗体或6RL#9-IgG1抗体相互作用。之后,通过以流速30μL/min、以30秒注射10mM Glycine-HCl(pH1.5),传感器芯片得以再生。根据测定得到的传感图、使用稳态亲和模式(steady state affinity model)计算出解离常数KD(M)。各参数的计算中,使用Biacore T100 Evaluation Software(GE Healthcare)。
通过该方法确定的2mM CaCl
表21
Ca浓度为3μM的条件下时的H54/L28-IgGl抗体的KD可以以与2mM Ca浓度存在下相同的方法计算出。Ca浓度为3μM的条件下时,因为基本观察不到FH4-IgG1抗体和6RL#9-IgG1抗体与IL-6受体的结合,因此难于通过上述方法计算出KD。但是,可以通过使用下式1(Biacore T100 Software Handbook,BR-1006-48,AE 01/2007),预测Ca浓度为3μM的条件下时这些抗体的KD。
式1
Req=C x Rmax/(KD+C)+RI
上式1中的各项目的意义如下:
Req(RU):稳态结合水平(Steady state binding levels)
Rmax(RU):待分析物的表面结合能力(Analyte binding capacity of thesurface)
RI(RU):试样中的批量折射率贡献(Bulk refractive index contribution inthe sample)
C(M):待分析物浓度(Analyte concentration)
KD(M):平衡解离常数(Equilibrium dissociation constant)
表22示出了使用上式1、对Ca浓度为3μmol/L的情况下各抗体与IL-6受体的解离常数KD的预测估算结果。表22中的Req、Rmax、RI、C为基于测定结果假定的值。
表22
从上述结果预测:FH4-IgG1抗体和6RL#9-IgG1抗体随着将缓冲液中的CaCl
表23总结了H54/L28-IgG1、FH4-IgG1、6RL#9-IgG1这3种抗体在2mM CaCl
表23
没有观察到由Ca浓度不同导致的H54/L28-IgG1抗体对IL-6受体的结合的不同。另一方面,低浓度的Ca条件下,观察到FH4-IgG1抗体和6RL#9-IgG1抗体对IL-6受体的结合显著减弱(表23)。
实施例17获得的抗体的钙离子结合评价
接着,作为钙离子向抗体的结合的评价的指标,通过示差扫描热量测定法(DSC)测定了热变性中值温度(Tm值)(MicroCal VP-Capillary DSC、MicroCal)。热变性中值温度(Tm值)为稳定性的指标,蛋白质通过钙离子的结合而稳定化的话,热变性中值温度(Tm值)将变得比未结合钙离子的情况高(J.Biol.Chem.(2008)283,37,25140-25149)。通过评价与抗体溶液中的钙离子浓度的变化相应的抗体Tm值的变化,评价了钙离子向抗体的结合活性。经纯化的抗体被供给至以20mM Tris-HCl、150mM NaCl、2mM CaCl
表24
表24的结果表明,显示出钙依赖性的结合能力的FH4-IgG1抗体和6RL#9-IgG1抗体的Fab的Tm值根据钙离子的浓度的变化而变动,不显示钙依赖性的结合能力的H54/L28-IgG1抗体的Fab的Tm值不根据钙离子的浓度的变化而变动。FH4-IgG1抗体和6RL#9-IgG1抗体的Fab的Tm值的变动显示钙离子与这些抗体结合、Fab部分稳定化了。上述结果表明,FH4-IgG1抗体和6RL#9-IgG1抗体上结合钙离子,而H54/L28-IgG1抗体上不结合钙离子。
实施例18 6RL#9抗体的钙离子结合位点通过X射线晶体结构分析进行的鉴定
(18-1)X射线晶体结构分析
如实施例17所示,关于6RL#9抗体,从热变性温度Tm值的测定表明了其与钙离子结合。但是,因为无法预测到6RL#9抗体的哪个位点与钙离子结合,所以通过使用X射线晶体结构分析的手段,鉴定出了与钙离子相互作用的6RL#9抗体的序列中的残基。
(18-2)6RL#9抗体的表达和纯化
对用于X射线结晶结构分析而表达的6RL#9抗体进行了纯化。具体而言,将动物表达用质粒(以使6RL#9抗体的重链(序列号78)和轻链(序列号79)分别表达的方式进行制备)暂时导入动物细胞。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293Expression Medium培养基(Invitrogen)中,以使最终细胞密度为1x10
(18-3)来自6RL#9抗体的Fab片段的纯化
使用分子量分离点10000MWCO的超滤膜,将6RL#9抗体富集为21mg/mL。使用4mM L-半胱氨酸、5mM EDTA、20mM磷酸钠缓冲液(pH 6.5),制备了稀释至5mg/mL的2.5mL的该抗体的试样。将添加了0.125mg木瓜蛋白酶(RocheApplied Science)并搅拌的该试样在35℃静置2小时。静置后,再将溶解有1片不含EDTA的蛋白酶抑制剂微混合物(Protease InhibitorCocktail Mini)(Roche Applied Science)的10mL的25mM MES缓冲液(pH6)加入到试样中,通过在冰中静置,使通过木瓜蛋白酶进行的蛋白酶反应停止。接着,将该试样加入到1mL大小的阳离子交换柱HiTrap SP HP(GE Healthcare)上,该交换柱经25mM MES缓冲液pH6平衡化过,并与下游1mL大小的ProteinA载体柱HiTrap MabSelect Sure(GE Healthcare)串联连接。通过将该缓冲液中NaCl浓度直线上升至300mM进行洗脱,得到了6RL#9抗体的Fab片段的纯化级分。接着,将得到的纯化级分经5000MWCO的超滤膜富集至0.8mL左右。将富集液添加至用包含50mM NaCl的100mM HEPES缓冲液(pH 8)平衡化过的凝胶过滤柱Superdex20010/300GL(GE Healthcare)上。使用相同缓冲液,将用于结晶化的纯化6RL#9抗体的Fab片段从柱洗脱出来。需要说明的是,上述全部的柱操作均在6~7.5℃的低温下实施。
(18-4)6RL#9抗体的Fab片段在Ca存在下的结晶化
预先在一般条件设定下获得6RL#9Fab片段的晶种。接着,添加CaCl
(18-5)6RL#9抗体的Fab片段在Ca不存在时的结晶化
使用5000MWCO的超滤膜将纯化的6RL#9抗体的Fab片段富集为15mg/mL。接着,通过悬滴蒸汽扩散法,对经前述富集的试样进行结晶化。作为贮液,使用包含18-25%的PEG4000的100mM HEPES缓冲液(pH7.5)。盖玻片上,通过对0.8μl的贮液和0.8μl的前述富集试样的混合液添加0.2μl下述溶液,制备结晶化液滴,所述溶液为在包含25%PEG4000的100mMHEPES缓冲液(pH7.5)中、将经破碎的在Ca存在下获得的6RL#9抗体的Fab片段的结晶稀释了100-10000倍而得的稀释系列溶液。通过将该结晶化液滴于20℃静置2天至3天获得薄板状结晶,测定了该结晶的X射线衍射数据。
(18-6)6RL#9抗体的Fab片段在Ca存在下的结晶的X射线衍射数据测定
将6RL#9抗体的Fab片段在Ca存在下获得的单结晶之一(浸于包含35%PEG4000和5mM CaCl
(18-7)6RL#9抗体的Fab片段在不存在Ca时的结晶的X射线衍射数据测定
将6RL#9抗体的Fab片段在不存在Ca时获得的单结晶之一(其浸于包含35%PEG4000和5mM CaCl
(18-8)6RL#9抗体的Fab片段在Ca存在下的结晶的结构分析
通过使用了程序Phaser(CCP4 Software Suite)的分子取代法,确定了6RL#9抗体的Fab片段在Ca存在下的结晶的结构。基于得到的结晶晶格的大小和6RL#9抗体的Fab片段的分子量,预测非对称单元中的分子数为1个。基于一级序列上的同源性,从PDB编号:1ZA6的结构坐标获得的A链112-220号和B链116-218号的氨基酸残基部分被用作为CL和CH1区的探测用模型分子。接着,从PDB编号:1ZA6的结构坐标获得的B链1-115号的氨基酸残基部分被用作为VH区的探测用模型分子。最后,从PDB编号2A9M的结构坐标获得的轻链3-147号的氨基酸残基被用作为VL区的探测用模型分子。按照该顺序,通过从旋转函数和转换函数(translation function)确定各探测用模型分子的结晶晶格内方向和位置,获得6RL#9抗体的Fab片段的初始结构模型。针对该初始结构模型,通过对VH、VL、CH1、CL的各结构域进行刚体移动精细化(rigid body refinement moving),针对
(18-9)对6RL#9抗体的Fab片段在不存在Ca时的结晶的结构分析
6RL#9抗体的Fab片段在不存在Ca时的结晶的结构,使用其同型在Ca存在下的结晶结构来确定。从6RL#9抗体的Fab片段在Ca存在下的结晶的结构坐标中排除掉水分子和Ca离子分子,移动VH、VL、CH1、CL的各结构域进行刚体移动精细化。针对
(18-10)6RL#9抗体的Fab片段在Ca存在和不存在时的结晶的X射线衍射数据的比较
对6RL#9抗体的Fab片段在Ca存在下的结晶和不存在Ca时的结晶的结构进行比较,在重链CDR3中发现了大的变化。通过X射线结晶结构分析确定的6RL#9抗体的Fab片段的重链CDR3的结构如图11所示。具体而言,Ca存在下的6RL#9抗体的Fab片段的结晶中,在重链CDR3的环部分的中心部分存在钙离子。认为钙离子与重链CDR3的第95位、96位和100a位(Kabat编号)相互作用。认为:Ca存在下时,对于与抗原的结合来说重要的重链CDR3环通过与钙结合从而稳定化,成为最适合于与抗原结合的结构。钙结合至抗体的重链CDR3上的例子迄今为止没有被报道过,钙结合至抗体的重链CDR3的结构是新的结构。
基于6RL#9抗体的Fab片段的结构已经明确的、在重链CDR3中存在的钙结合基序,也可成为实施例11所示的Ca文库的设计的新要素。即,虽然实施例11中向轻链可变区中导入钙结合基序,但也可考虑例如包含6RL#9抗体的重链CDR3、并在包括轻链在内的其它CDR中包含灵活残基的文库。
实施例19从使用了噬菌体展示技术而得的人抗体文库中获得Ca依赖性地与IL-6结合的抗体
(19-1)天然人抗体噬菌体展示文库的制作
以从人PBMC制作的多聚A RNA或市售的人多聚A RNA等作为模板,通过本领域技术人员公知的方法,构建了由多个噬菌体构成的人抗体噬菌体展示文库,所述噬菌体呈示互相之间不同的人抗体序列的Fab结构域。
(19-2)通过珠粒淘选从文库获得Ca依赖性地与抗原结合的抗体片断
从构建的天然人抗体噬菌体展示文库中的最初的选拔,通过仅富集具有与抗原(IL-6受体)的结合能力的抗体片断来实施。作为抗原,使用了经生物素标记的IL-6受体。
由保持了构建的噬菌体展示用噬粒的大肠杆菌进行噬菌体的产生。通过向进行了噬菌体产生的大肠杆菌的培养液中添加2.5M NaCl/10%PEG而沉淀的噬菌体的群体被稀释于TBS中,由此获得噬菌体文库液。接着,向噬菌体文库液中添加BSA和CaCl
具体而言,通过向制备的噬菌体文库液中添加250pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。用1.2mM CaCl
第2次以后的淘选中,以Ca依赖性的结合能力为指标进行噬菌体的富集。具体而言,通过向制备的噬菌体文库液中添加40pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。以1mL的1.2mM CaCl
(19-3)通过噬菌体ELISA进行的评价
按照常规方法(Methods Mol.Biol.(2002)178,133-145)从按上述方法获得的大肠杆菌的单菌落中回收了含有噬菌体的培养上清液。
将添加了BSA和CaCl
通过使用分离的96个克隆进行噬菌体ELISA,得到了具有针对IL-6的Ca依赖性结合能力的6KC4-1#85抗体。对将在前述噬菌体ELISA的结果中被判断为具有Ca依赖性地与抗原结合的能力的抗体片断作为模板、通过特异性引物扩增获得的基因的碱基序列进行了分析。6KC4-1#85抗体的重链可变区的序列记载为序列号11,以及,轻链可变区的序列记载为序列号84。通过PCR法,将编码6KC4-1#85抗体的重链可变区(序列号11)的多核苷酸与编码来自IgG1的序列的多核苷酸连接起来,将得到的DNA片断并入动物细胞表达用载体,构建了表达以序列号85表示的重链的载体。通过PCR法将编码6KC4-1#85抗体的轻链可变区(序列号84)的多核苷酸与编码天然型Kappa链的恒定区(序列号26)的多核苷酸连接,将得到的DNA片断并入动物细胞表达用载体。通过本领域技术人员公知的方法确认了制作的修饰体的序列。通过本领域技术人员公知的方法确认了制作的修饰体的序列。
(19-4)抗体的表达和纯化
将在噬菌体ELISA的结果中被判断为具有Ca依赖性地与抗原结合的能力的克隆6KC4-1#85导入动物细胞表达用质粒。使用以下方法进行抗体表达。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293 Expression Medium培养基(Invitrogen)中,以1.33x10
实施例20 6KC4-1#85抗体的钙离子结合评价
对从人抗体文库获得的钙依赖性的抗原结合抗体6KC4-1#85抗体是否与钙离子结合进行了判定。按照实施例6记载的方法,对离子化钙浓度不同的条件下测定的Tm值是否变动进行了评价。
6KC4-1#85抗体的Fab结构域的Tm值示于表25。如表25所示,6KC4-1#85抗体的Fab结构域的Tm值根据钙离子的浓度而变动,因此确认了6KC4-1#85抗体与钙结合。
表25
实施例21 6KC4-1#85抗体的钙离子结合位点的鉴定
如实施例20所示,虽然显示6KC4-1#85抗体与钙离子结合,但6KC4-1#85并不具有基于对hVk5-2序列的研究所明确的钙结合基序。因此,为了确认钙离子是结合至6KC4-1#85抗体的重链、还是结合至轻链、或者是与两者都结合,针对钙离子对下述修饰抗体的结合进行了评价,所述修饰抗体中与不结合钙离子的抗磷脂酰肌醇蛋白聚糖(Glypican)3抗体(重链序列GC_H(序列号48)、轻链序列GC_L(序列号86))的重链和轻链分别进行了交换。按照实施例6所示的方法测定的修饰抗体的Tm值示于表26。结果,因为具有6KC4-1#85抗体的重链的修饰抗体的Tm值根据钙离子的浓度而变化,因此认为钙在6KC4-1#85抗体的重链中结合。
表26
因此,进而为了鉴定6KC4-1#85抗体的重链中何种残基与钙离子结合,制作了修饰重链(6_H1-11(序列号87)、6_H1-12(序列号88)、6_H1-13(序列号89)、6_H1-14(序列号90)、6_H1-15(序列号91))或修饰轻链(6_L1-5(序列号92)和6_L1-6(序列号93)),其中将6KC4-1#85抗体的CDR中存在的Asp(D)残基取代为与钙离子的结合或螯合不相关的Ala(A)。从导入了包含修饰抗体基因的表达载体的动物细胞的培养液,按照实施例19记载的方法纯化了修饰抗体。按照实施例6记载的方法,测定了经纯化的修饰抗体的钙结合。测定结果示于表27。如表27所示,通过将6KC4-1#85抗体的重链CDR3的第95位或101位(Kabat编号)取代为Ala残基,6KC4-1#85抗体的钙结合能力丧失,因此认为该残基对于与钙的结合来说是重要的。从6KC4-1#85抗体的修饰抗体的钙结合性揭示的、在6KC4-1#85抗体的重链CDR3的环的基底附近存在的钙结合基序也可成为实施例11记载的Ca文库的设计的新要素。即,虽然实施例11中向轻链可变区中导入钙结合基序,还可考虑如下文库,该文库例如包含6KC4-1#85抗体的重链CDR3、并在包括轻链在内的其它CDR中包含灵活残基。
表27
实施例22 Ca依赖性地与人IgA结合的抗体的获得
(22-1)添加了MRA-hIgA、GC-hIgA和生物素的人IgA-Fc的制备
作为人IgA,按照下文所述制备了MRA-hIgA(重链序列号97、轻链序列号25)GC-hIgA(重链序列号98、轻链序列号99)和添加了生物素的人IgA-Fc(也称为生物素标记hIgA-Fc,hIgA_CH2-CH3-Avitag:序列号100)。
按下文所述制备了人IgA的重组体即MRA-hIgA(以下MRA-hIgA)。通过本领域技术人员公知的方法,使用离子交换色谱和凝胶过滤色谱,纯化了包含表达的H(WT)-IgA1(序列号97)和L(WT)(序列号25)的hIgA。
人IgA的重组体即GC-hIgA按下文所述制备。将编码GC-hIgA(重链序列号98、轻链序列号99)的基因片断并入动物细胞表达用载体。使用293Fectin(Invitrogen)将构建的质粒载体与表达EBNA1的基因一起导入FreeStyle293(Invitrogen)中。之后,将导入了基因的细胞在37℃、CO
用0.22μm的瓶顶过滤器过滤包含GC-hIgA的细胞培养液,获得培养上清液。将用相同溶液稀释的培养上清液上样到经20mM Tris-HCl,pH8.0平衡化过的HiTrap Q HP(GEhealthcare)上,通过NaCl浓度梯度洗脱GC-hIgA。之后,通过利用Superdex200的凝胶过滤色谱,除去结合体,并替换为20mM His-HCl、150mM NaCl,pH6.0,得到了纯化GC-hIgA。
为了向目标蛋白质(人IgA-Fc)的C末端添加生物素,在编码人IgA-Fc区的基因片断的下游连接编码特异性序列(Avitag序列的)的基因片断,所述特异性序列是通过生物素连接酶添加了生物素而得的。将编码连接了人IgA和Avitag序列的蛋白质(hIgA_CH2-CH3-Avitag(序列号100))的基因片断并入动物细胞表达用载体。使用293Fectin(Invitrogen),将构建的质粒载体进行基因导入至FreeStyle293(Invitrogen)。此时,表达EBNA1的基因和表达生物素连接酶(BirA)的基因被同时导入,通过添加生物素而进行了生物素标记。将按照前述流程导入了基因的细胞在37℃、CO2 8%下培养6天,使目标蛋白质分泌在培养上清液中。
用0.22μm的瓶顶过滤器过滤包含作为目标的人IgA-Fc的细胞培养液,获得培养上清液。将用相同溶液稀释的培养上清液上样到经20mM Tris-HCl,pH7.4平衡化过的HiTrapQ HP(GE healthcare)上,通过NaCl浓度梯度洗脱目标人IgA-Fc。将经50mM Tris-HCl,pH8.0稀释的HiTrap Q HP洗脱液上样到使用相同溶液平衡化过的SoftLink Avidin柱上,用5mM生物素、150mM NaC1、50mM Tris-HCl,pH8.0进行洗脱。之后,通过利用Superdex200的凝胶过滤色谱,除去结合体,并替换为20mM His-HCl、150mM NaCl,pH6.0,得到了纯化的人IgA-Fc。
(22-2)通过珠粒淘选从Ca文库获得Ca依赖性地与抗原结合的抗体片断
从构建的Ca依赖性地与抗原结合的抗体文库(Ca文库)中的最初的选拔,通过以与抗原(人IgA-Fc)的结合能力为指标来实施。
由保持了构建的噬菌体展示用噬粒的大肠杆菌进行噬菌体的产生。通过向进行了噬菌体产生的大肠杆菌的培养液中添加2.5M NaCl/10%PEG而沉淀的噬菌体的群体被稀释于TBS中,由此获得噬菌体文库液。接着,通过向噬菌体文库液中添加BSA或脱脂奶、和CaCl
具体而言,通过向制备的噬菌体文库液中添加250pmol的经生物素标记抗原(生物素标记IgA-Fc),将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA或脱脂奶封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。用1mL的1.2mMCaCl
第2次、第3次的淘选中,以Ca离子浓度依赖性的抗原结合能力为指标进行噬菌体的富集。具体而言,通过向噬菌体文库液(与第1次淘选相同地进行封闭而制备的)中添加40pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。以1mL的1.2mMCaCl
(22-3)利用Biacore对人IgA结合抗体的筛选
从第2次淘选结束后获得的大肠杆菌获得噬粒,将从该噬粒提取的抗体片断基因插入动物细胞表达用载体中。使用以下方法进行抗体的表达。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293 Expression Medium培养基(Invitrogen)中,以2.63x10
使用通过上述方法获得的培养上清液,使用BiacoreA100分析了对GC-hIgA的结合能力。使培养上清液中的抗体相对传感器芯片CM5(GE Healthcare)被固定化,该芯片上通过胺偶联法固定化了适当的量的蛋白质A(Invitrogen)。关于运行缓冲液,使用20mM ACES、150mM NaCl、0.05%(w/v)Tween20、1.2mM CaCl
针对在前述通过Biacore对IgG的结合能力分析的结果中判断为对GC-hIgA存在结合能力的抗体,使用特异性引物从用于表达的动物细胞表达用载体扩增了抗体基因,对该基因的碱基序列进行了分析。
(22-4)利用Phage ELISA进行的hIgA结合抗体的筛选
按照常规方法(Methods Mol.Biol.(2002)178,133-145)从按(22-2)实施的第3次淘选后获得的大肠杆菌的单菌落进行了噬菌体的培养,回收了含有噬菌体的培养上清液。将添加了BSA和CaCl
针对在上述的噬菌体ELISA的结果中被判断为对IgA-Fc的结合能力根据Ca离子浓度而变化的克隆,进行抗体片断基因的碱基序列分析。
(22-5)通过固层淘选法从Ca文库获得Ca依赖性地与抗原结合的抗体片断
从构建的Ca依赖性地结合至抗原的抗体文库(Ca文库)中的最初的选拔,通过以与抗原(人IgA-Fc)的结合能力为指标来实施。
从保持了构建的噬菌体展示用噬粒的大肠杆菌进行噬菌体的产生。通过向进行了噬菌体产生的大肠杆菌的培养液中添加2.5M NaCl/10%PEG而沉淀的噬菌体的群体被稀释于TBS中,由此获得噬菌体文库液。接着,通过向噬菌体文库液中添加BSA或脱脂奶、和CaCl
具体而言,通过向制备的噬菌体文库液中添加250pmol的经生物素标记抗原(生物素标记IgA-Fc),将该噬菌体文库液在室温下与抗原接触60分钟。加入经脱脂奶封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。用1mL的1.2mM CaCl
第2次的淘选中,使用在板上固层化的抗原进行了淘选。具体而言,将涂布了链亲和素的10孔的板(Streptawell,Roche)的各孔中每孔加入5pmol的生物素标记抗原,在室温下接触抗原60分钟后,制作了经TBST(包含0.1%Tween20的TBS)清洗3次的抗原固相化板。此时,添加包含1.2mM Ca的经脱脂奶封闭的噬菌体文库,室温下与抗原接触60分钟。通过1.2mM CaCl
(22-6)通过Phage ELISA进行的hIgA结合抗体的筛选
按照常规方法(Methods Mol.Biol.(2002)178,133-145)从前述淘选后获得的大肠杆菌的单菌落进行噬菌体的培养,回收了含有噬菌体的培养上清液。针对通过(22-4)记载的方法、实施PhageELISA、判断为具有Ca依赖性的抗原结合能力的克隆,进行碱基序列分析,将其插入动物细胞表达用载体,作为抗体被表达、纯化。
实施例23获得的抗体对人IgA的Ca依赖性的结合能力的评价
(23-1)获得的抗人IgA抗体的表达和纯化
作为在实施例22中被判断为存在对人IgA的结合能力的抗体而获得的抗体中,使用以下方法表达了GA1-IgG1((22-3)中获得的,重链序列号101、轻链序列号102)、GA2-IgG1((22-4)中获得的,重链序列号103、轻链序列号104)、GA3-IgG1((22-6)中获得的,重链序列号105、轻链序列号106)、GA4-IgG1((22-3)中获得的,重链序列号107、轻链序列号108),进行了对所述抗体的纯化。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293Expression Medium培养基(Invitrogen)中,以1.33x10
(23-2)获得的抗体针对人IgA的Ca依赖性的结合能力的评价
使用Biacore T200(GE Healthcare),评价了(23-1)中获得的抗体(GAl-IgG1、GA2-IgG1、GA3-IgG1和GA4-IgG1)对人IgA的结合活性(解离常数K
将抗体结合至传感器芯片CM5(GE Healthcare)上,该芯片上通过胺偶联法固定化有适当的量的重组型蛋白质A/G(Thermo Scientific)。作为待分析物,注射适当浓度的MRA-hIgA(记载于(22-1)),使其与传感器芯片上的抗体相互作用。之后,注射10mmol/LGlycine-HCl,pH1.5,传感器芯片得以再生。测定在37℃进行。使用Biacore T200评估软件(GE Healthcare),通过对测定结果的曲线拟合进行的分析以及通过平衡值分析,计算出了解离常数KD(M)。其结果示于表28。此外,获得的传感图示于图12。其明确显示,GA2-IgG1、GA3-IgG1、GA4-IgG1在Ca
表28
虽然在实施例14中从Ca文库获得了针对IL6受体、与抗原(IL6受体)的相互作用Ca离子浓度依赖性地变化的抗体,但明确显示,Ca离子浓度依赖性地与抗原结合的抗体并不仅限于使用IL6受体,还可使用人IgA获得。
实施例24Ca依赖性地与人磷脂酰肌醇蛋白聚糖3(GPC3)结合的抗体的获取
(24-1)人磷脂酰肌醇蛋白聚糖3的制备
按照下文所述,制备了作为抗原使用的重组人磷脂酰肌醇蛋白聚糖3(以下GPC3)。将表达下述序列(序列号109)的质粒恒定地导入CHO细胞,回收该细胞的培养上清液,所述序列在不含人磷脂酰肌醇蛋白聚糖3的跨膜区的氨基酸序列中连接6个残基的组氨酸。对得到的培养上清液进行离子交换色谱纯化,之后对其进行使用His标签的亲和纯化和凝胶过滤色谱纯化,获得了GPC3。使用EZ-Link NHS-PEG4-生物素(Thermo SCIENTIFIC),针对该GPc3制备了经生物素标记的生物素标记GPC3。
(24-2)通过珠粒淘选从文库获得Ca依赖性地与抗原结合的抗体片断
从构建的Ca依赖性地与GPC3结合的抗体文库中的最初的选拔,通过以与抗原(GPC3)的结合能力为指标来实施。
从保持了构建的噬菌体展示用噬粒的大肠杆菌进行噬菌体的产生。通过向进行了噬菌体产生的大肠杆菌的培养液中添加2.5M NaCl/10%PEG而沉淀的噬菌体的群体被稀释于TBS中,由此获得噬菌体文库液。接着,通过向噬菌体文库液中添加BSA或脱脂奶、和CaCl
具体而言,通过向制备的噬菌体文库液中添加250pmol的经生物素标记抗原(生物素标记GPC3),将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA或脱脂奶封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。用1mL的1.2mMCaCl
第2次以后的淘选中,以Ca依赖性的抗原结合能力为指标进行噬菌体的富集。具体而言,通过向噬菌体文库液(与第1次淘选相同地进行封闭而制备的)中添加40pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA或脱脂奶封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。以1mL的1.2mMCaCl
(24-3)利用Phage ELISA进行的GPC3结合抗体的筛选
按照常规方法(Methods Mol.Biol.(2002)178,133-145)从按上述方法实施的第2次和第3次淘选后获得的大肠杆菌的单菌落进行了噬菌体的培养,回收了含有噬菌体的培养上清液。
将添加了BSA和CaCl
将在噬菌体ELISA的结果中被判断为存在Ca依赖性地与抗原结合的能力的抗体片断作为模板,利用特异性引物进行了扩增,对扩增得到的基因的碱基序列进行了分析。
(24-4)与人GPC3结合的抗体的表达和纯化
在噬菌体ELISA的结果中被判断为存在Ca依赖性的与抗原结合能力的4种抗体、CSCM-01_005(重链序列110、轻链序列111)、CSCM-01_009(重链序列112、轻链序列113)、CSCM-01_015(重链序列114、轻链序列115)和CSCM-01_023(重链序列116、轻链序列117)以及作为对照的抗人GPC3抗体GC-IgG1(重链序列118、轻链序列119)被分别插入动物细胞表达用质粒中。使用以下方法使抗体表达。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293 Expression Medium培养基(Invitrogen)中,以1.33x10
(24-5)获得的抗体对人GPC3的Ca依赖性结合能力的评价
将获得的抗体以下述流程供给至ELISA。使用包含生物素标记抗原的100μL PBS对StreptaWell 96微滴定板(Roche)涂布1夜。通过用ACES缓冲液(10mM ACES,150mM NaCl,100mM CaCl
测定结果如图13所示。GC-IgG1的情况下吸光度相同,与钙离子的浓度无关,与之相对,CSCM-01_005、CSCM-01_009、CSCM-01_015和CSCM-01_023的情况下,与1.2mM钙离子浓度(高钙离子浓度)处吸光度进行比较,结果3μM钙离子浓度(低钙离子浓度)处的吸光度显著更低。该结果表明,CSCM-01_005、CSCM-01_009、CSCM-01_015和CSCM-01_023具有与抗原的结合根据钙离子的浓度而变化的性质,还表明针对人磷脂酰肌醇蛋白聚糖3也可获得钙依赖性的抗体。
实施例25pH依赖性地与小鼠IgA结合的抗体的获取
(25-1)GC-mIgA和添加有生物素的小鼠IgA-Fc的制备
作为小鼠IgA,GC-mIgA(重链序列号120、轻链序列号121)和添加有生物素的小鼠IgA-Fc(也称为生物素标记mIgA-Fc,mIgA_CH2-CH3-Avitag:序列号122)按下文所述来制备。
(25-1-1)GC-mIgA的制备
小鼠IgA的重组体即GC-mIgA按下文所述来制备。将编码GC-mIgA(重链序列号120、轻链序列号121)的基因片断并入动物细胞表达用载体。使用293Fectin(Invitrogen),将构建的质粒载体与表达EBNA1的基因一起导入FreeStyle293(Invitrogen)。之后,将导入了基因的细胞在37℃、CO
用0.22μm的瓶顶过滤器过滤包含GC-mIgA的细胞培养液,获得培养上清液。将用相同溶液稀释的培养上清液上样到经20mM Tris-HCl,pH8.0平衡化过的HiTrap Q HP(GEhealthcare)上,通过NaCl浓度梯度洗脱GC-mIgA。之后,将通过利用SuperdeX200的凝胶过滤色谱除去了结合体的包含GC-mIgA的缓冲液替换为20mM His-HCl、150mM NaCl,pH6.0,得到了纯化GC-mIgA。
为了向目标蛋白质(小鼠IgA-Fc)的C末端添加生物素,在编码小鼠IgA-Fc区的基因片断的下游连接编码特异性序列(Avitag序列的)基因片断,所述特异性序列是通过生物素连接酶添加了生物素而得的。将编码连接了小鼠IgA和Avitag序列的蛋白质(mIgA_CH2-CH3-Avitag(序列号122))的基因片断并入动物细胞表达用载体。使用293Fectin(Invitrogen),将构建的质粒载体导入FreeStyle293(Invitrogen)。此时,表达EBNA1的基因和表达生物素连接酶(BirA)的基因被同时导入,通过添加生物素而进行了生物素标记。将按照前述流程导入的细胞在37℃、CO
用0.22μm的瓶顶过滤器过滤包含作为目标的人IgA-Fc的细胞培养液,获得培养上清液。将用相同溶液稀释的培养上清液上样到经20mM Tris-HCl,pH7.4平衡化过的HiTrapQ HP(GE healthcare)上,通过NaCl浓度梯度洗脱小鼠IgA-Fc。接着,从用50mM Tris-HCl,pH8.0平衡化后、上样了用相同溶液稀释的上述HiTrap Q HP洗脱液的SoftLink Avidin柱上,用5mM生物素、150mM NaCl、50mM Tris-HCl,pH8.0洗脱作为目标的小鼠IgA-Fc。之后,将通过利用Superdex200的凝胶过滤色谱除去了结合体的、包含小鼠IgA-Fc的缓冲液替换为20mM His-HCl、150mM NaCl,pH6.0,得到了纯化小鼠IgA-Fc。
(25-2)通过珠粒淘选从His文库获得pH依赖性地与抗原结合的抗体片断
从构建的pH依赖性地与抗原结合的抗体文库(His文库1)中的最初的选拔,通过以与抗原(小鼠IgA-Fc)的结合能力为指标来实施。
从保持了构建的噬菌体展示用噬粒的大肠杆菌进行噬菌体的产生。通过向进行了噬菌体产生的大肠杆菌的培养液中添加2.5M NaCl/10%PEG而沉淀的噬菌体的群体被稀释于TBS中,由此获得噬菌体文库液。接着,通过向噬菌体文库液中添加脱脂奶以使终浓度为3%脱脂奶,制备了经封闭的噬菌体文库液。作为淘选方法,参照作为一般性方法的使用了固定化至磁性珠粒的抗原的淘选方法(J.Immunol.Methods.(2008)332(1-2),2-9、J.Immunol.Methods.(2001)247(1-2),191-203、Biotechnol.Prog.(2002)18(2)212-20、Mol.Cell Proteomics(2003)2(2),61-9)。作为磁性珠粒,使用涂布有NeutrAvidin的珠粒(Sera-Mag SpeedBeads NeutrAvidin-coated)或涂布有链亲和素的珠粒(Dynabeads M-280 Streptavidin)。
具体而言,通过向制备的噬菌体文库液中添加经生物素标记抗原(生物素标记mIgA-Fc),将该噬菌体文库液在室温下与抗原接触60分钟。在第1次淘选中使用250pmol的生物素标记抗原,在第2次的淘选中使用40pmol的生物素标记抗原,在第3次淘选中使用10pmol的生物素标记抗原。加入经脱脂奶封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。用1mL的1.2mM CaCl
(25-3)通过Biacore对小鼠IgA结合抗体的结合能力的评价
从第3次淘选结束后获得的大肠杆菌获得噬粒,将从该噬粒提取的抗体片断基因插入动物细胞表达用载体中。使用以下方法进行抗体表达。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293 Expression Medium培养基(Invitrogen)中,以2.63x10
使用通过上述方法获得的培养上清液,使用BiacoreA100分析了对GC-mIgA的结合能力。使得培养上清液中的抗体被捕获至传感器芯片CM5(GE Healthcare)上,该芯片通过胺偶联法固定化有适当的量的蛋白质A/G(PIERCE)。关于运行缓冲液,使用20mM ACES、150mM NaCl、0.05%(w/v)Tween20、1.2mM CaCl
作为前述利用Biacore进行的结合评价的结果中被判断为针对GC-mIgA具有pH依赖性的结合能力的抗体,获得了mIAP1B3-3_#024(重链序列号123、轻链序列号124)、mIAP1B3-3_#130(重链序列号125、轻链序列号126)、mIAP1B3-3_#230(重链序列号127、轻链序列号128)。这些抗体的pH7.4和pH5.8时的传感图示于图14。通过使缓冲液中的pH从pH7.4变为pH5.8,观察到针对小鼠IgA的结合能力降低。
针对这些抗体,从用于表达的动物细胞表达用载体分析了抗体基因的碱基序列。
虽然在实施例3中从His文库1获得了针对IL-6R、与抗原(IL-6R)的相互作用pH依赖性地变化的抗体,但明确显示,pH依赖性地与抗原结合的抗体并不仅限于使用IL6受体,还可使用小鼠IgA获得。
实施例26 pH依赖性地与人HMGB1结合的抗体的获取
(26-1)人HMGB1和添加有生物素的人HMGB1的制备
按下文所述制备了人HMGB1(序列号129)和添加有生物素的人HMGB1-Avi(也称为生物素标记hHMGB1,hHMGB1-Avitag:序列号130)。
(26-1-1)人HMGB1的制备
人HMGB1的重组体即hHMGB1按下文所述来制备。将编码hHMGB1(序列号129)的基因片断并入动物细胞表达用载体。使用293Fectin(Invitrogen),将构建的质粒载体与表达EBNA1的基因一起导入FreeStyle293(Invitrogen)。之后,将导入了基因的细胞在37℃、CO
(26-1-2)生物素标记人HMGB1的制备
为了向目标蛋白质(人HMGB1)的C末端添加生物素,在编码人HMGB1区的基因片断的下游连接编码特异性序列(Avitag序列的)基因片断,所述特异性序列是通过生物素连接酶添加了生物素而得的。将编码连接了人HMGB1和Avitag序列的蛋白质(hHMGB1-Avitag(序列号130))的基因片断并入动物细胞表达用载体。使用293Fectin(Invitrogen),将构建的质粒载体导入FreeStyle293(Invitrogen)。此时,表达EBNA1的基因和表达生物素连接酶(BirA)的基因被同时导入,通过添加生物素而进行了生物素标记。将按照前述流程导入的细胞在37℃、CO
将在经PBS平衡化之后、上样了培养上清液的HiTrap SP Sepharose HP(GEHealthcare社)用PBS清洗,之后,通过氯化钠的线性浓度梯度洗脱吸附到柱上的蛋白质。向经TBS平衡化的SoftLink Soft Release Avidin Resin柱(Promega社)上上样经100mMTris-HCl,pH7.4稀释至2倍的包含HMGB1-Avi的级分。使用包含5mM生物素的TBS(pH 8.0)从用TBS清洗过的柱洗脱吸附到柱上的蛋白质。将经超滤膜富集的包含HMGB1-Avi的级分上样到经300mM NaCl,20mM组氨酸,pH6.0平衡化过的Superdex200柱(GE Healthcare社)上。通过用相同缓冲液分离,得到生物素化的hHMGB1纯化级分。
(26-2)通过珠粒淘选从His文库获得pH依赖性地与抗原结合的抗体片断
从构建的pH依赖性地与抗原结合的抗体文库(His文库1)中的最初的选拔,通过以与抗原(人HMGB1)的结合能力为指标来实施。
从保持了构建的噬菌体展示用噬粒的大肠杆菌进行噬菌体的产生。通过向进行了噬菌体产生的大肠杆菌的培养液中添加2.5M NaCl/10%PEG而沉淀的噬菌体的群体被稀释于TBS中,由此获得噬菌体文库液。接着,通过向噬菌体文库液中添加BSA和CaCl
具体而言,通过向制备的噬菌体文库液中添加250pmol经生物素标记抗原(生物素标记hHMGB1),将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。用1mL的1.2mM CaCl
第2次以后的淘选中,以抗原结合能力或pH依赖性的结合能力为指标进行噬菌体的富集。具体而言,通过向制备的噬菌体文库液中添加40pmol的经生物素标记抗原,将该噬菌体文库液在室温下与抗原接触60分钟。加入经BSA封闭的磁性珠粒,使抗原和噬菌体的复合体与磁性珠粒在室温下结合15分钟。以1mL的1.2mM CaCl
(26-3)通过Phage ELISA进行的人HMGB1结合抗体的筛选
按照常规方法(Methods Mol.Biol.(2002)178,133-145),从按(26-2)实施的第3次和第4次淘选后获得的大肠杆菌的单菌落进行噬菌体的培养,回收了含有噬菌体的培养上清液。将添加了BSA和CaCl
针对在上述噬菌体ELISA的结果中判断为对人HMGB1的结合能力根据pH而变化的克隆中所包含的抗体片断基因的碱基序列,进行了分析。
(26-4)与人HMGB1结合的抗体的表达和纯化
在噬菌体ELISA的结果中被判断为具有pH依赖性与抗原结合的能力的3种抗体、HM_3_2_R_017(重链序列号131、轻链序列号132)、HM_3_2_R_054(重链序列号33、轻链序列号134)、及HM_4_1_R_001(重链序列号135、轻链序列号136)被分别插入动物细胞表达用质粒中。使用以下方法使抗体表达。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)悬浮于FreeStyle 293 Expression Medium培养基(Invitrogen)中,以1.33x10
(26-5)获得的抗体对人HMGB1的pH依赖性结合能力的评价
为了判断(26-4)获得的抗体HM_3_2_R_017(重链序列号131、轻链序列号132)、HM_3_2_R_054(重链序列号33、轻链序列号134)、及HM_4_1_R_001(重链序列号135、轻链序列号136)针对hHMGB1的结合活性是否为pH依赖性的,使用Biacore T100(GE Healthcare)分析了这些抗体与hHMGB1的相互作用。作为中性区域pH和酸性区域pH的条件,分别在pH7.4和pH5.8的溶液中分析了抗原抗体反应的相互作用。在通过胺偶联法固定化了适当的量的蛋白质A/G(Invitrogen)的传感器芯片(Sensor chip)CM5(GE Healthcare)上,分别捕获了200RU左右的目标抗体。关于运行缓冲液,使用20mM ACES、150mM NaCl、0.05%(w/v)Tween20、1.2mM CaCl
在针对使用了HM_3_2_R_017抗体和HM_3_2_R_054抗体和HM_4_1_R_001抗体的抗原抗体反应的相互作用进行分析时,通过以流速10μL/min、以6分钟注射hHMGB1的稀释液和作为空白的运行缓冲液,使其被捕获于传感器芯片上。使hHMGB1与HM_3_2_R_017抗体和HM_3_2_R_054抗体和HM_4_1_R_001抗体相互作用。之后,通过以流速30μL/min、以30秒注射10mM Glycine-HCl(pH1.5),传感器芯片被再生。
通过前述方法测定的pH7.4、pH5.8下的传感图示于图15。
从前述结果观察到:通过将缓冲液中的pH从pH7.4变为pH5.8,HM_3_2_R_017抗体、HM_3_2_R_054抗体及HM_4_1_R_001抗体针对hHMGB1的结合能力降低,这表明针对人HMGB1也可获得pH依赖性的结合抗体。
参考实施例1使用正常小鼠评价Ca依赖性结合抗体对抗原的血浆中滞留性的影响
(1-1)使用正常小鼠的体内试验
向正常小鼠(C57BL/6J小鼠,Charles River Japan)单独给予hsIL-6R(可溶型人IL-6受体;按照参考实施例4制作),或者同时给予hsIL-6R和抗人IL-6受体抗体,之后对hsIL-6R和抗人IL-6受体抗体的体内动态进行了评价。将hsIL-6R溶液(5μg/mL)、或hsIL-6R和抗人IL-6受体抗体的混合溶液以10mg/kg单次给予尾静脉。作为抗人IL-6受体抗体,使用前述的H54/L28-IgG1、6RL#9-IgG1、FH4-IgG1。
虽然混合溶液中的hsIL-6R浓度均为5μg/mL,但抗人IL-6受体抗体浓度随抗体各异,H54/L28-IgG1为0.1mg/mL,6RL#9-IgG1和FH4-IgG1为10mg/mL,此时,对hsIL-6R而言抗人IL-6受体抗体以十分过量的量存在,因此认为hsIL-6R大部分都结合至抗体。在给予后15分钟、7小时、1日、2日、4日、7日、14日、21日、28日的时间点进行了采血。通过对采集的血液直接进行4℃、12,000rpm下的15分钟离心分离,得到血浆。在直到实施测定之前,将分离的血浆保存于设定为-20℃以下的冰箱中。
(1-2)通过ELISA法测定正常小鼠血浆中的抗人IL-6受体抗体浓度
通过ELISA法测定了小鼠血浆中的抗人IL-6受体抗体浓度。首先,将抗体的抗人IgG(γ-链特异性的)F(ab′)2片断(SIGMA)分注至Nunc-Immuno板,MaxiSoup(Nalge nuncIntemational)中,通过于4℃静置1夜,制作了抗人IgG固相化板。作为血浆中的浓度,将0.64、0.32、0.16、0.08、0.04、0.02、0.01μg/mL的标准曲线试样以及稀释了100倍以上的小鼠血浆测定试样分注至抗人IgG固相化板,将所述的板在25℃孵育1小时。之后,使生物素化的抗人IL-6R抗体(R&D)在25℃反应1小时后,使链亲和素-PolyHRP80(StereospecificDetection Technologies)在25℃反应0.5小时。将TMB One Component HRP MicrowellSubstrate(BioFX Laboratories)作为底物进行显色反应,通过1N硫酸(Showa Chemical)终止了显色反应,之后使用微滴定板读数仪测定了显色液在450nm处的吸光度。使用分析软件SOFTmax PRO(Molecular Devices),以标准曲线的吸光度为基准,计算出小鼠血浆中的浓度。通过该方法测定的、静脉内给予后的正常小鼠中的H54/L28-IgG1、6RL#9-IgG1、FH4-IgG1的血浆中抗体浓度的推移示于图16中。
(1-3)通过电化学发光法测定血浆中的hsIL-6R浓度
通过电化学发光法测定了小鼠的血浆中的hsIL-6R浓度。将调整为2000、1000、500、250、125、62.5、31.25pg/mL的hsIL-6R标准曲线试样和经50倍以上稀释的小鼠血浆测定试样与使用SULFO-TAG NHS Ester(Meso Scale Discovery)钌化的单克隆抗人IL-6R抗体(R&D)和生物素化的抗人IL-6R抗体(R&D)以及托珠单抗(重链序列号24、轻链序列号25)溶液的混合液在4℃反应1夜。为了使样品中的游离Ca浓度降低,样品中几乎全部的hsIL-6R从6RL#9-IgG1或FH4-IgG1解离、而成为与添加的托珠单抗结合的状态,此时的试验缓冲液中含有10mM EDTA。之后,将该反应液分注进MA 400PR链亲和素板(MesoScale Discovery)。进而,使板在25℃反应1小时,对板的各孔清洗之后,向各孔中分注Read缓冲液T(×4)(MesoScale Discovery)。之后立即使用SECTOR PR 400读数仪(Meso Scale Discovery)对反应液进行了测定。使用分析软件SOFTmax PRO(Molecular Devices)从标准曲线的应答计算出hSIL-6R浓度。通过前述方法测定的静脉内给予后的正常小鼠的血浆中的hsIL-6R浓度推移示于图17。
结果,单独hsIL-6R的情况下显示出非常早的消失,与之相对,在将hsIL-6R和没有Ca依赖性结合的通常的抗体H54/L28-IgG1同时给予的情况下,hsIL-6R的消失大幅延迟。与之相对,同时给予hsIL-6R和具有100倍以上的Ca依赖性的结合的6RL#9-IgG1或FH4-IgG1的情况下,hsIL-6R的消失被大幅加速。与同时给予H54/L28-IgG1的情况相比较,同时给予6RL#9-IgG1和FH4-IgG1的情况下,1日后的血浆中的hsIL-6R浓度分别降低39倍和2倍。由此确认到钙依赖性的结合抗体可加速抗原从血浆中消失。
参考实施例2对Ca依赖性的抗原结合抗体的抗原消失加速效果的提高的研究(抗体制作)
(2-1)关于IgG抗体对FcRn的结合
IgG抗体因为与FcRn结合,故而具有较长的血浆中滞留性。仅在酸性条件下(pH6.0)发现IgG与FcRn的结合,在中性条件下(pH 7.4)则基本没有发现该结合。IgG抗体虽然非特异性地被并入细胞,但在核内体内的酸性条件下通过与核内体内的FcRn结合而回到细胞表面,在血浆中的中性条件下则从FcRn解离。向IgG的Fc区中导入突变、使得在酸性条件下与FcRn的结合丧失时,则无法从核内体内再循环进血浆中,故而显著损害了抗体在血浆中的滞留性。
作为改善IgG抗体的血浆中滞留性的方法,报道了提高酸性条件下与FcRn的结合的方法。通过向IgG抗体的Fc区域中导入氨基酸取代、提高酸性条件下与FcRn的结合,从核内体内向血浆中的IgG抗体的循环效率上升。结果,IgG抗体在血浆中的滞留性改善。在导入氨基酸取代时被认为很重要的一点是,中性条件下与FcRn的结合不被提高。认为在中性条件下与FcRn结合的IgG抗体即使能通过在核内体内的酸性条件下与FcRn的结合而回到细胞表面上,由于在中性条件下的血浆中IgG抗体不从FcRn解离、不被循环进血浆中,所以反而会损害IgG抗体的血浆中滞留性。
例如,如Dall’Acqua等人(J.Immunol.(2002)169(9),5171-5180)记载的那样,报道了向小鼠给予的、通过导入氨基酸取代而确认到在中性条件下(pH7.4)对小鼠FcRn的结合的IgG1抗体在血浆中的滞留性恶化。此外,如Yeung等人(J.Immunol.(2009)182(12),7663-7671)、Datta-Mannan等人(J.Biol.Chem.(2007)282(3),1709-1717)、Dall’Acqua等人(J.Immunol.(2002)169(9),5171-5180)记载的那样,确认到:通过导入氨基酸取代在酸性条件下(pH6.0)人FcRn结合提高的IgG1抗体修饰体,同时也在中性条件下(pH7.4)针对人FcRn结合。报道称给予食蟹猕猴的该抗体的血浆中滞留性没有改善,没有发现血浆中滞留性有变化。因此,在提高抗体的功能的抗体工程学技术中,关注于通过不增加中性条件下(pH7.4)对人FcRn的结合、并增加酸性条件下对人FcRn的结合来改善抗体的血浆中滞留性。即,此前从未报道过通过在其Fc区中导入氨基酸取代、在中性条件下(pH7.4)对人FcRn的结合增加了的IgG1抗体的优点。
Ca依赖性地与抗原结合的抗体可加速可溶型的抗原的消失,具有以一个抗体分子多次重复结合可溶型的抗原的效果,因此极为有用。作为进一步提高抗原消失加速效果的方法,验证了增强中性条件下(pH7.4)对FcRn的结合的方法。
(2-2)中性条件下具有对FcRn的结合活性的Ca依赖性的人IL-6受体结合抗体的制备
通过向具有钙依赖性的抗原结合能力的FH4-IgG1、6RL#9-IgG1及作为对照使用的不具有钙依赖性的抗原结合能力的H54/L28-IgG1的Fc区中导入氨基酸突变,制作了具有在中性条件下(pH7.4)对FcRn的结合的修饰体。使用利用PCR的本领域技术人员公知的方法,导入氨基酸突变。具体而言,制作了针对IgG1的重链恒定区将以EU编号表示的第434位氨基酸Asn取代为Trp的、FH4-N434W(重链序列号94、轻链序列号81)、6RL#9-N434W(重链序列号95、轻链序列号79)和H54/L28-N434W(重链序列号96、轻链序列号83)。使用QuikChange定点诱变试剂盒(Stratagene),使用其所附的说明书记载的方法,制作了动物细胞表达载体,其中插入有编码该氨基酸被取代的变体的多核苷酸。抗体的表达、纯化、浓度测定按照实施例15记载的方法来实施。
参考实施例3使用正常小鼠评价Ca依赖性结合抗体的消失加速效果
(3-1)使用正常小鼠的体内试验
向正常小鼠(C57BL/6J小鼠,Charles River Japan)单独给予hsIL-6R(可溶型人IL-6受体;按照参考实施例4制作),或者同时给予hsIL-6R和抗人IL-6受体抗体,之后对hsIL-6R和抗人IL-6受体抗体的体内动态进行了评价。将hsIL-6R溶液(5μg/mL)、或hsIL-6R和抗人IL-6受体抗体的混合溶液以10mg/kg单次给予尾静脉。作为抗人IL-6受体抗体,使用前述的H54/L28-N434W、6RL#9-N434W、FH4-N434W。
虽然混合溶液中的hsIL-6R浓度均为5μg/mL,但抗人IL-6受体抗体浓度随抗体各异,制备为H54/L28-N434W为0.042mg/mL、6RL#9-N434W为0.55mg/mL、FH4-N434W为1mg/mL。此时,对hsIL-6R而言抗人IL-6受体抗体以十分过量的量存在,因此认为hsIL-6R大部分都结合至抗体。在给予后15分钟、7小时、1日、2日、4日、7日、14日、21日、28日的时间点进行了采血。通过对采集的血液直接进行4℃、12,000rpm下的15分钟离心分离,得到血浆。在直到实施测定之前,将分离的血浆保存于设定为-20℃以下的冰箱中。
(3-2)通过ELISA法测定正常小鼠血浆中的抗人IL-6受体抗体浓度
按照与参考实施例1相同的ELISA法测定了小鼠血浆中的抗人IL-6受体抗体浓度。通过该方法测定的静脉内给予后的正常小鼠中的H54/L28-N434W、6RL#9-N434W、FH4-N434W抗体的血浆中的抗体浓度的推移示于图18。
(3-3)通过电化学发光法测定血浆中的hsIL-6R浓度
通过电化学发光法测定了小鼠的血浆中的hsIL-6R浓度。将制备为2000、1000、500、250、125、62.5、31.25pg/mL的hsIL-6R标准曲线试样和经50倍以上稀释的小鼠血浆测定试样与使用SULFO-TAG NHS Ester(Meso Scale Discovery)钌化的单克隆抗人IL-6R抗体(R&D)和生物素化的抗人IL-6R抗体(R&D)的混合液在4℃反应1夜。为了使样品中的游离Ca浓度降低、样品中几乎全部的hsIL-6R从6RL#9-N434W或FH4-N434W解离、成为作为游离体存在的状态,此时的试验缓冲液中含有10mM EDTA。之后,将该反应液分注进MA 400PR链亲和素板(Meso Scale Discovery)。进而,使板在25℃反应1小时,对板的各孔清洗之后,向各孔中分注Read缓冲液T(×4)(Meso Scale Discovery)。之后立即使用SECTOR PR 400读数仪(Meso Scale Discovery)对反应液进行了测定。使用分析软件SOFTmax PRO(MolecularDevices)从标准曲线的应答计算出hSIL-6R浓度。通过前述方法测定的静脉内给予后的正常小鼠的血浆中的hsIL-6R浓度推移示于图19。
结果,pH7.4时对FcRn具有结合活性、而对hsIL-6R不具有Ca依赖性结合活性的H54/L28-N434W抗体被同时给予的情况下,较之单独给予hsIL-6R的情况而言,hsIL-6R的消失大幅延迟。与之相对,在同时给予针对hsIL-6R具有100倍以上的Ca依赖性结合、在pH7.4时具有针对FcRn的结合的6RL#9-N434W抗体或FH4-N434W抗体的情况下,较之单独给予hsIL-6R的情况也加速了hsIL-6R的消失。较之单独给予hsIL-6R的情况,同时给予6RL#9-N434W抗体或FH4-N434W抗体的情况下,给予后1日时的血浆中的hsIL-6R浓度分别降低了3倍和8倍。结果确认到,针对钙依赖性地与抗原结合的抗体,通过赋予pH7.4时对FcRn的结合活性,能够进一步加速抗原从血浆中消失。
与针对hsIL-6R不具有Ca依赖性结合活性的H54/L28-IgG1抗体相比,确认到针对hsIL-6R有100倍以上的Ca依赖性结合活性的6RL#9-IgG1抗体或FH4-IgG1抗体具有增加hsIL-6R消失的效果。确认到针对hsIL-6R具有100倍以上的Ca依赖性结合、并且在pH7.4时具有对FcRn的结合的6RL#9-N434W抗体或FH4-N434W抗体较之单独给予hsIL-6R而言进一步加速了hsIL-6R的消失。这些数据表明,与pH依赖性地与抗原结合的抗体相同,Ca依赖性地与抗原结合的抗体在核内体内解离抗原。
参考实施例4可溶型人IL-6受体(hsIL-6R)的制备
按下文所述制备了作为抗原的人IL-6受体的重组人IL-6受体。用本领域技术人员公知的方法,构建了Mullberg等人(J.Immunol.(1994)152,4958-4968)报道的、由N末端侧第1位至第357位的氨基酸序列构成的可溶型人IL-6受体(以下称hsIL-6R)的CHO恒定表达株。通过培养该表达株,表达了hsIL-6R。通过Blue Sepharose 6FF柱色谱、凝胶过滤柱色谱,从得到的培养上清液纯化hsIL-6R。作为最终纯化品,使用在最后的步骤中作为主峰洗脱的级分。
参考实施例5通过NMR对包含具有钙离子结合基序的人hVk1序列的抗体的钙离子结合活性的评价
(5-1)抗体的表达和纯化
为了用于NMR测定,使得包含LfVk1_Ca的抗体和包含LfVk1的抗体表达,并对其进行了纯化。具体而言,关于包含LfVk1_Ca的抗体(也称为LfVk1_Ca抗体),将以使重链(序列号24)和轻链(序列号43)分别表达的方式制备的动物表达用质粒暂时导入动物细胞中。此外,关于包含LfVk1的抗体(也称为LfVk1抗体),将以使重链(序列号24)和轻链(序列号44)分别表达的方式制备的动物表达用质粒暂时导入动物细胞中。将源于人胎儿肾细胞的FreeStyle 293-F株(Invitrogen)以1x10
使用分子量分离点30,000MWCO的超滤膜,将各种抗体富集至8.2-11.8mg/mL。使用L-半胱氨酸1mM、EDTA 2mM、50mM乙酸/125mM Tris缓冲液(pH 6.8),制备了稀释为8mg/mL的所述抗体的试样。将针对各抗体添加1/240量的木瓜蛋白酶(Roche Applied Science)并搅拌而得的所述试样在37℃静置1小时。静置后,分别添加到下游处与1mL尺寸的ProteinA载体柱HiTrap MabSelect Sure(GE Healthcare)串联的、经50mM乙酸/125mM Tris缓冲液(pH6.8)平衡化的、结合了Gly-Gly-Tyr-Arg(Sigma)肽的1mL尺寸的HiTrap NHS-活化的HP(GEHealthcare)中。通过上游的Gly-Gly-Tyr-Arg肽除去活性化木瓜蛋白酶,并通过下游的蛋白质A载体柱除去Fc片段和未消化抗体,由此得到Fab片段的纯化级分。为防止Fab级分中含有的不活性木瓜蛋白酶活性化,向Fab级分中添加了10μM半胱氨酸蛋白酶抑制剂E64(Sigma)。需要说明的是,上述所有柱操作均在20~25℃的室温下实施。
使用MWCO 5000的超滤器Vivaspin(Sartorius)将抗体溶液富集至0.5mL。接着,在上述超滤器中设置渗滤杯(diafiltration cup),将缓冲液替换为NMR用缓冲液:5mM d-BisTris,20mM NaCl,0.001%(w/v)NaN
NMR测定中使用设置了TCI CryoProbe的NMR分光器DRX750(Bruker Biospin)。设定温度为307K(GasFlow 535L/h)。为观测酰胺基信号的NMR测定中使用
在此之前,托珠单抗(重链序列号24、轻链序列号25)的Fab片段的主链酰胺基的NMR信号中有80%已被归属(数据未公开)。LfVk1_Ca抗体的Fab片段的氨基酸序列除了轻链CDR1、CDR2、CDR3的一部分以及轻链第73、83位的氨基酸残基以外,与托珠单抗Fab片段的氨基酸序列相同。关于两抗体中氨基酸序列相同的部分,因为其NMR信号具有相同的化学位移,或者化学位移接近,因此转移托珠单抗的归属信息是可能的。关于Leu标记试样,轻链11、(33)、(46)、(47)、(54)、(78)、125、135、136、154、175、179、181、201、重链18、46、64、71、81、83、114、144、147、165、176、181、184、195的归属转移是可能的。上述中,没有括号的编号为化学位移与托珠单抗相同、可转移归属的残基编号,具有括号的编号为具有与托珠单抗接近的化学位移、并且除此之外没有接近的化学位移的信号、因此可进行归属的残基编号。另一方面,关于Asp、Glu、Asn、Gln标记试样,对LfVk1_Ca抗体和LfVk1抗体的谱进行比较,在LfVk1_Ca中新观测到了4个信号。其可被分类为:该两抗体间Asp、Glu、Asn、Gln残基内,来自于作为Ca
将LfVk1_Ca抗体的Fab片段的Ca
相对LfVk1_Ca抗体的Fab片段而言Ca
式2
f(x)=s×[1-0.5/a×{(a×x+a+Kd)-((a×x+a+Kd)
式2表示的函数中,s、t分别表示Ca