一种室内空间温度和湿度调控方法及系统
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及电子设备控制技术领域,尤其涉及一种室内空间温度和湿度调控方法及系统。
背景技术
室内温湿度的状态对室内的居住人员的舒适度有极大的影响,在一些特定环境中,如博物馆、高端数控机床等对室内的温湿度的要求更为严格,精准均匀的温湿度分布更利于文物的保存与精密零部件的加工生产。因此,对室内温湿度控制进行研究具有很大意义。基于传统的控制方法监测范围有限,易造成室内温湿度分布不均匀的问题。目前,大多数的室内温湿度的方法没有将室内温湿度的精准度以及均匀度结合进行考虑,而主要针对于室内整体的舒适效果,忽略了环境内局部的分布情况。基于AI的室内温湿度技术也在不断被研究,如基于预测的控制,基于深度强化学习控制等。然而当应用场景发生变化时,已训练的控制模型不仅不一定适用于新的应用场景,甚至可能出现控制效果更差的情况。而在新的场景中训练新的控制模型需要耗费大量的时间和计算资源。
现在随着科技发展,各行业对温湿度的环境要求不断提高,研究人员也提出了一系列调控方法。如采用气液分离的冷冻除湿机系统和保障建筑空间的空气正压的溶液除湿新风机来实现室内环境的温湿度控制。然而传统的温湿度控制过度依赖人力,在低效率的同时控制精度不高。基于机器学习的室内温湿度自动控制系统具有较高的智能性和实用性,能够在无人值守的情况下完成对于温湿度的自动控制。然而现有方法对于房间的具体环境依赖性较大,需要针对每个房间进行单独训练与控制,算法对房间的传感和风口设施要求较高,难以做到快速大量地部署实践应用。
发明内容
鉴于此,本发明实施例提供了一种室内空间温度和湿度调控方法及系统,以消除或改善现有技术中存在的一个或更多个缺陷,解决人工智能模型受环境影响,无法快速高效部署在新环境中进行室内温湿度控制的问题。
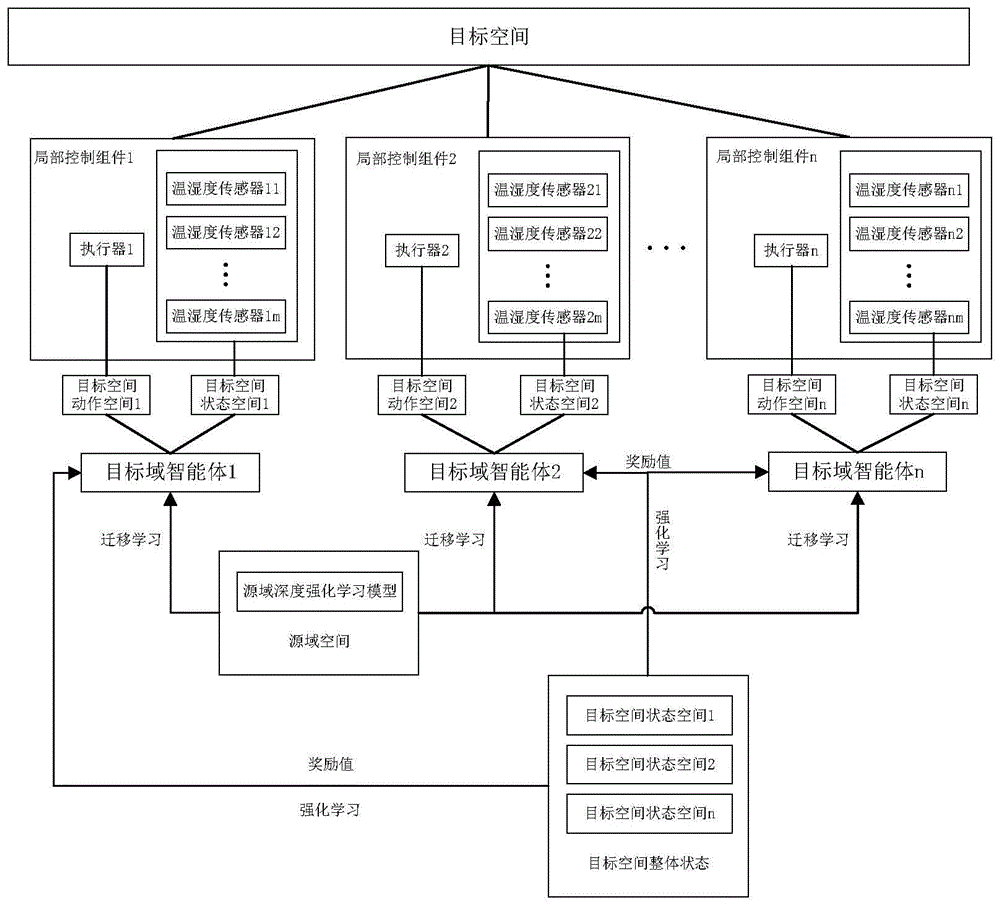
一个方面,本发明提供一种室内空间温度和湿度调控方法,所述方法用于在目标空间的中心控制器上运行,所述中心控制器连接云端服务器,所述中心控制器通过物联网连接所述目标空间内的多个温湿度传感器和多个执行器,所述执行器为恒温恒湿机的出风口,每个执行器与其周边设定范围内的温湿度传感器构成局部控制组件,所述中心控制器上运行多个目标域智能体,每个目标域智能体用于控制目标空间内一个局部控制组件,该方法包括以下步骤:
从所述云端服务器上获取基于源空间预训练得到的源域深度强化学习模型,所述源域深度强化学习模型以源空间内多个温湿度传感器按照指定间隔时间采集的温度值和湿度值作为状态参数构成源空间状态空间,源空间内以源空间设定湿度和源空间设定温度运行的各执行器的风速档位作为动作参数构成源空间动作空间;根据所述状态参数计算源空间观测奖励值;所述源域深度强化学习模型以最大化未来多步源空间观测奖励值之和为优化目标对所述初始强化学习模型进行训练和参数更新直至收敛得到。
将所述源域深度强化学习模型迁移分发至目标空间内的各目标域智能体,在深度强化学习过程中,每个目标域智能体以其控制的局部控制组件中多个温湿度传感器按照指定间隔时间采集的温度值和湿度值作为状态参数构成目标域局部状态空间,以目标空间设定湿度和目标空间设定温度运行的各执行器的风速档位作为动作参数构成目标域局部动作空间;计算目标空间内所有温湿度传感器的实际湿度值与所述目标空间设定湿度的第一湿度精度偏差,以及各实际湿度值之间的第一湿度均匀度偏差;计算目标空间内所有温湿度传感器的实际温度值与所述目标空间设定温度的第一温度精度偏差,以及各实际温度值之间的第一温度均匀度偏差;根据每个时间步对应的所述第一湿度精度偏差、所述第一湿度均匀度偏差、所述第一温度精度偏差和所述第一温度均匀度偏差计算目标空间观测奖励值;每个目标域智能体以最大化未来多步目标空间观测奖励值之和优化目标对所述源域深度强化学习模型进行训练和参数更新直至收敛。
在一些实施例中,所述源域深度强化学习模型的训练步骤包括:
获取源空间内多个温湿度传感器按照指定间隔时间采集的温度值和湿度值作为状态参数,以源空间作为整体构成整体状态空间;
获取源空间内以所述源空间设定湿度和所述源空间设定温度运行的各执行器的风速档位作为动作参数,构建整体动作空间;
计算源空间内所有湿度传感器的实际湿度值与所述源空间设定湿度的第二湿度精度偏差,以及各实际湿度值之间的第二湿度均匀度偏差;计算源空间内所有温度传感器的实际温度值与所述源空间设定温度的第二温度精度偏差,以及各实际温度值之间的第二温度均匀度偏差;
根据每个时间步对应的所述第二湿度精度偏差、所述第二湿度均匀度偏差、所述第二温度精度偏差和所述第二温度均匀度偏差计算源空间观测奖励值;
以最大化未来多步源空间观测奖励值之和为优化目标对所述初始强化学习模型进行训练和参数更新直至收敛,得到所述源域深度强化学习模型。
在一些实施例中,所述源域深度强化学习模型的训练步骤包括:
将所述源域深度强化学习模型分别发送至多个源域智能体,每个源域智能体用于控制一个执行器及其周边设定范围内的温湿度传感器;每个源域智能体以其控制的多个温湿度传感器按照指定间隔时间采集的温度值和湿度值作为状态参数构成源域局部状态空间;
每个源域智能体以其控制的执行器的风速档位作为动作参数构成源域局部动作空间;
计算源空间内所有温湿度传感器的实际湿度值与所述源空间设定湿度的第三湿度精度偏差,以及各实际湿度值之间的第三湿度均匀度偏差;计算源空间内所有温湿度传感器的实际温度值与所述源空间设定温度的第三温度精度偏差,以及各实际温度值之间的第三温度均匀度偏差;
根据每个时间步对应的所述第三湿度精度偏差、所述第三湿度均匀度偏差、所述第三温度精度偏差和所述第三温度均匀度偏差计算源空间观测奖励值;
每个源域智能体端到端地获取整个源空间的源空间观测奖励值,以最大化未来多步源空间观测奖励值之和为优化目标对每个源域智能体的初始强化学习模型进行训练和参数更新直至收敛,并将各源域智能体更新后的模型参数进行聚合,得到所述源域深度强化学习模型。
在一些实施例中,将各源域智能体更新后的模型参数进行聚合,包括:将各源域智能体更新后的参数按照设定权重融合,得到源域深度强化学习模型的参数。
在一些实施例中,计算目标空间内所有温湿度传感器的实际湿度值与所述目标空间设定湿度的第一湿度精度偏差,以及各实际湿度值之间的第一湿度均匀度偏差,其中,所述第一湿度精度偏差的计算式为:
H
所述第一湿度均匀度偏差的计算式为:
H
计算目标空间内所有温湿度传感器的实际温度值与所述目标空间设定温度的第一温度精度偏差,以及各实际温度值之间的第一温度均匀度偏差,其中,所述第一温度精度偏差的计算式为:
T
所述第一温度均匀度偏差的计算式为:
T
在一些实施例中,根据每个时间步对应的所述第一湿度精度偏差、所述第一湿度均匀度偏差、所述第一温度精度偏差和所述第一温度均匀度偏差计算目标空间观测奖励值,计算式为:
R
其中,R
在一些实施例中,每个目标域智能体以最大化未来多步目标空间观测奖励值之和优化目标对所述源域深度强化学习模型进行训练和参数更新直至收敛,包括:
构建优化目标函数,表达式为:
其中,γ表示折扣因素且γ<1,R
在一些实施例中,所述源域深度强化学习模型通过构建多层全连接层组成的神经网络以预测每个动作对应的Q值,该神经网络设置两个分支,第一个分支用于预测状态价值,第二个分支用于预测每个动作的优势,结合所述预测状态价值和每个动作的优势计算每个动作对应的Q值。
另一方面,本发明还提供一种室内空间温度和湿度调控系统,所述系统包括:
多个温湿度传感器,所述温湿度传感器包括湿度传感器和温度传感器,所述温湿度传感器设置在目标空间内;
恒温恒湿机,所述恒温恒湿机设有多个出风口,每个出风口设有多个风速档位,各出风口的风速档位单独设置不同,各出风口设置在所述目标空间内;每个出风口与其周边设定范围内的温湿度传感器构成局部控制组件;
中心控制器,所述中心控制器连接云端服务器,所述中心控制器通过物联网连接所述目标空间内的各温湿度传感器和所述恒温恒湿机的各出风口;所述中心控制器上运行多个目标域智能体,每个目标域智能体用于控制目标空间内一个局部控制组件;
所述中心控制器执行上述室内空间温度和湿度调控方法控制所述目标空间内的温度和湿度。
另一方面,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述方法的步骤。
本发明的有益效果至少是:
本发明所述室内空间温度和湿度调控方法及系统,以温湿度状态参数作为状态空间,以恒温恒湿机出风口风速档位作为动作空间,通过在源空间训练预训练得到源域深度强化学习模型;在目标空间中,每个执行器与其周边设定范围内的温湿度传感器构成局部控制组件,每个局部控制组件由独立的目标域智能体控制,每个目标智能体分别迁移学习源域深度强化学习模型进行参数微调和控制,以目标空间所有温湿度传感器采集的温度值和湿度值共同计算目标空间观测奖励值,以最大化未来多步目标空间观测奖励值为目标分别对各目标域智能体的源域深度强化学习模型进行训练,以快速适应对目标空间环境对温湿度的实现精准控制。
本发明的附加优点、目的,以及特征将在下面的描述中将部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本发明的实践而获知。本发明的目的和其它优点可以通过在说明书以及附图中具体指出的结构实现到并获得。
本领域技术人员将会理解的是,能够用本发明实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本发明能够实现的上述和其他目的。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,并不构成对本发明的限定。在附图中:
图1为本发明一实施例所述室内空间温度和湿度调控方法的逻辑示意图。
图2为本发明一实施例所述室内空间温度和湿度调控方法中源域深度强化学习模型训练逻辑示意图。
图3为本发明另一实施例所述室内空间温度和湿度调控方法中源域深度强化学习模型训练逻辑示意图。
图4为部署有恒温恒湿空调系统的A房间模型示意图。
图5为部署有恒温恒湿空调系统的B房间模型示意图。
图6为部署有恒温恒湿空调系统的C房间模型示意图。
图7为部署有恒温恒湿空调系统的D房间模型示意图。
图8为部署有恒温恒湿空调系统的E房间模型示意图。
图9为部署有恒温恒湿空调系统的F房间模型示意图。
图10为将C作为源域以多种形式迁移至D收敛后奖励值对比图。
图11为将E作为源域以多种形式迁移至D收敛后奖励值对比图。
图12为采用前端迁移情况下,单独训练、整体迁移与多智能体随机选用其一两种形式收敛后奖励值对比图。
图13为不同源域模型采用前端迁移以及多智能体随机选用其一的形式收敛后奖励值对比图。
图14为干扰条件下迁移强化与直接训练的温湿度精确度和均匀度比较图。
图15为干扰条件下C模型策略迁移学习至D与D模型直接训练情况下温湿度精确度与均匀性比较图。
图16为智能体数量不同情况下策略迁移学习的性能对比图。
图17为干扰条件下智能体数量不同情况下策略迁移学习的温湿度精确度与均匀性对比图。
图18为干扰条件下E模型策略迁移学习至F与F模型直接训练情况下温湿度精确度与均匀性比较图。
图19为F模型中每个智能体只监测2个温湿度传感器时,迁移学习和直接训练性能对比图。
图20为F模型中每个智能体只监测2个温湿度传感器时,干扰条件下迁移学习和直接训练精确度和均匀性对比图。
图21为F模型中每个智能体监测温湿度传感器数量不同时,迁移学习和直接训练性能对比图。
图22为F模型中每个智能体监测温湿度传感器数量不同时,干扰条件下迁移学习和直接训练精确度和均匀性对比图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施方式和附图,对本发明做进一步详细说明。在此,本发明的示意性实施方式及其说明用于解释本发明,但并不作为对本发明的限定。
在此,还需要说明的是,为了避免因不必要的细节而模糊了本发明,在附图中仅仅示出了与根据本发明的方案密切相关的结构和/或处理步骤,而省略了与本发明关系不大的其他细节。
应该强调,术语“包括/包含”在本文使用时指特征、要素、步骤或组件的存在,但并不排除一个或更多个其它特征、要素、步骤或组件的存在或附加。
在此,还需要说明的是,如果没有特殊说明,术语“连接”在本文不仅可以指直接连接,也可以表示存在中间物的间接连接。
在下文中,将参考附图描述本发明的实施例。在附图中,相同的附图标记代表相同或类似的部件,或者相同或类似的步骤。
强化学习方法可以通过与环境互动而学习到最佳策略,且无模型的方法可以忽略对不同环境进行建模与计算的复杂度与难度。所以利用强化学方法进行室内空间温湿度调节符合客观条件的需求,能够实现房间内温湿度的高精准度和高均匀度控制,尽可能减少对室内保存的特殊物品的损伤,使物品不易产生过高温和过低温导滞的物理性破坏,也不易因温湿度波动幅度剧烈早场永久性破坏。
但是由于不同空间环境差异较大,每一个控制模型在特定空间内都需要重新进行训练和适应,对于一些复杂空间温湿度控制模型的训练算力需求较高,又由于不同的应用环境下可能缺少足够的算力条件,所以通过强化学习进行室内温湿度控制难以大范围推广。
强化学习迁移算法对于大量对于环境相似的室内能够,能够实现温湿度控制强化模型的快速部署。例如,对保存特殊物品的不同库房而言,能够将高效率高性能的强化学习算法在适配每一间库房的同时批量推广,对于减少设备的计算资源计算时间都有着重要意义。且在这各过程中,一个智能体控制多个风口,难以达到均匀的效果,算法的稳定性较差。因此,需要一种方法能够满足室内温湿度精准均匀的要求,且具有更高的抗干扰能力,还能够迅速迁移至新的室内环境进行应用。
具体的,本申请提供一种室内空间温度和湿度调控方法,所述方法用于在目标空间的中心控制器上运行,中心控制器连接云端服务器,中心控制器通过物联网连接所述目标空间内的多个温湿度传感器和多个执行器,执行器为恒温恒湿机的出风口,每个执行器与其周边设定范围内的温湿度传感器构成局部控制组件,中心控制器上运行多个目标域智能体,每个目标域智能体用于控制目标空间内一个局部控制组件。
本申请中,为更好地利用已训练的模型,避免由于不同场景下,空间布局不同,传感器因素影响导致智能体输入输出维度不同的问题,引入基于多智能体的迁移强化学习,多个智能体通过合作,联合控制室内温湿度。将目标空间内的温湿度传感器和执行器划分为多个局部控制组件,为每个局部控制组件配置目标域智能体以对相应局部空间进行温湿度调节。这样,每个目标域智能体内环境参数和控制参数变小,使强化学习模型能够快速收敛。同时,可以通过迁移学习的方式,将预训练的强化学习模型迁移至目标空间每个局部控制组件的目标域智能体上,以快速适应目标空间环境温湿度调节需求。
具体的,如图1所示,所述方法包括以下步骤S101~S102:
步骤S101:从云端服务器上获取基于源空间预训练得到的源域深度强化学习模型,源域深度强化学习模型以源空间内多个温湿度传感器按照指定间隔时间采集的温度值和湿度值作为状态参数构成源空间状态空间,源空间内以源空间设定湿度和源空间设定温度运行的各执行器的风速档位作为动作参数构成源空间动作空间;根据状态参数计算源空间观测奖励值;源域深度强化学习模型以最大化未来多步源空间观测奖励值之和为优化目标对初始强化学习模型进行训练和参数更新直至收敛得到。
步骤S102:将源域深度强化学习模型迁移分发至目标空间内的各目标域智能体,在深度强化学习过程中,每个目标域智能体以其控制的局部控制组件中多个温湿度传感器按照指定间隔时间采集的温度值和湿度值作为状态参数构成目标域局部状态空间,以目标空间设定湿度和目标空间设定温度运行的各执行器的风速档位作为动作参数构成目标域局部动作空间;计算目标空间内所有温湿度传感器的实际湿度值与目标空间设定湿度的第一湿度精度偏差,以及各实际湿度值之间的第一湿度均匀度偏差;计算目标空间内所有温湿度传感器的实际温度值与目标空间设定温度的第一温度精度偏差,以及各实际温度值之间的第一温度均匀度偏差;根据每个时间步对应的第一湿度精度偏差、第一湿度均匀度偏差、第一温度精度偏差和第一温度均匀度偏差计算目标空间观测奖励值;每个目标域智能体以最大化未来多步目标空间观测奖励值之和优化目标对源域深度强化学习模型进行训练和参数更新直至收敛。
在步骤S101中,由中心控制器从云端服务器直接获取预训练的源域深度强化学习模型,源域深度强化学习模型能够实现通过控制恒温恒湿机出风口风速档位调节室内空间温湿度,是基于源空间的环境状态参数和控制参数训练得到的。源域进行预训练的形式可以包括两种,第一是利用源空间整体状态参数和控制参数进行预训练;第二是将源空间划分为多个局部控制区,在每一个局部控制区内单独预训练一个强化学习神经网络,并进行融合,各局部控制区中强化学习神经网络强化学习的过程采用源空间整体的观测奖励值进行优化。
对于第一种源域深度强化学习模型的预训练形式,如图2所示,所述源域深度强化学习模型的训练步骤包括步骤S201~S205:
步骤S201:获取源空间内多个温湿度传感器按照指定间隔时间采集的温度值和湿度值作为状态参数,以源空间作为整体构成整体状态空间。
步骤S202:获取源空间内以源空间设定湿度和源空间设定温度运行的各执行器的风速档位作为动作参数,构建整体动作空间。
步骤S203:计算源空间内所有湿度传感器的实际湿度值与源空间设定湿度的第二湿度精度偏差,以及各实际湿度值之间的第二湿度均匀度偏差;计算源空间内所有温度传感器的实际温度值与源空间设定温度的第二温度精度偏差,以及各实际温度值之间的第二温度均匀度偏差。
步骤S204:根据每个时间步对应的第二湿度精度偏差、第二湿度均匀度偏差、第二温度精度偏差和第二温度均匀度偏差计算源空间观测奖励值。
步骤S205:以最大化未来多步源空间观测奖励值之和为优化目标对初始强化学习模型进行训练和参数更新直至收敛,得到源域深度强化学习模型。
步骤S201~S205中,以源空间所有的温湿度传感器和出风口的状态构建状态空间和动作空间,通过强化学习的方式进行温湿度控制,实现单个模型对全局空间范围的整体调控。
在一些实施例中,为了保持源域深度强化学习模型形成过程与目标空间强化学习的运行过程相同,提升模型泛化能力,如图3所示,可以设置源域深度强化学习模型的训练步骤包括步骤S301~S305:
步骤S301:将源域深度强化学习模型分别发送至多个源域智能体,每个源域智能体用于控制一个执行器及其周边设定范围内的温湿度传感器;每个源域智能体以其控制的多个温湿度传感器按照指定间隔时间采集的温度值和湿度值作为状态参数构成源域局部状态空间。
步骤S302:每个源域智能体以其控制的执行器的风速档位作为动作参数构成源域局部动作空间。
步骤S303:计算源空间内所有温湿度传感器的实际湿度值与源空间设定湿度的第三湿度精度偏差,以及各实际湿度值之间的第三湿度均匀度偏差;计算源空间内所有温湿度传感器的实际温度值与源空间设定温度的第三温度精度偏差,以及各实际温度值之间的第三温度均匀度偏差。
步骤S304:根据每个时间步对应的第三湿度精度偏差、第三湿度均匀度偏差、第三温度精度偏差和第三温度均匀度偏差计算源空间观测奖励值。
步骤S305:每个源域智能体端到端地获取整个源空间的源空间观测奖励值,以最大化未来多步源空间观测奖励值之和为优化目标对每个源域智能体的初始强化学习模型进行训练和参数更新直至收敛,并将各源域智能体更新后的模型参数进行聚合,得到所述源域深度强化学习模型。
步骤S301~S305中,源域深度强化学习模型在源空间内的预训练形式与本申请目标空间的形式相同,都是通过划分局部空间,并为每个局部空间分别配置智能体,在局部空间内单独实施强化学习训练模型,利用整个源空间环境的观测奖励值进行优化调参,最终将各智能体训练得到的模型参数进行聚合得到最终的源域深度强化学习模型,这种形式更贴合最终的运行环境。
在一些实施例中,步骤S102中,计算目标空间内所有温湿度传感器的实际湿度值与目标空间设定湿度的第一湿度精度偏差,以及各实际湿度值之间的第一湿度均匀度偏差,其中,第一湿度精度偏差的计算式为:
H
第一湿度均匀度偏差的计算式为:
H
计算目标空间内所有温湿度传感器的实际温度值与目标空间设定温度的第一温度精度偏差,以及各实际温度值之间的第一温度均匀度偏差,其中,第一温度精度偏差的计算式为:
T
第一温度均匀度偏差的计算式为:
T
同理,本申请中计算第二湿度精度偏差、第二湿度均匀度偏差、第二温度精度偏差、第二温度均匀度偏差、第三湿度精度偏差、第三湿度均匀度偏差、第三温度精度偏差以及第三温度均匀度偏差的计算式均可以参照计算式1~6。
在一些实施例中,根据每个时间步对应的第一湿度精度偏差、第一湿度均匀度偏差、第一温度精度偏差和第一温度均匀度偏差计算目标空间观测奖励值,计算式为:
R
其中,R
在一些实施例中,每个目标域智能体以最大化未来多步目标空间观测奖励值之和优化目标对所述源域深度强化学习模型进行训练和参数更新直至收敛,包括:
构建优化目标函数,表达式为:
其中,γ表示折扣因素且γ<1,R
同理,步骤S201~S205、S301~S305中,源域深度强化学习模型的训练和参数更新约束方式也可以参照上式7和8。
在一些实施例中,源域深度强化学习模型通过构建多层全连接层组成的神经网络以预测每个动作对应的Q值,该神经网络设置两个分支,第一个分支用于预测状态价值,第二个分支用于预测每个动作的优势,结合所述预测状态价值和每个动作的优势计算每个动作对应的Q值。
本发明所采用一种源域深度强化学习模型,标记为nMAD3QN-PER(n-step Multi-Agent Double Dueling DQN with Prioritized Experience Replay)算法。
nMAD3QN-PER同时引入Double DQN结构和Dueling DQN结构,相较于传统的QLearning网络,DQN利用深度卷积网络逼近值函数,独立设置了目标网络来单独处理时间查分算法中的TD偏差,利用经验回放对强化学习过程进行训练。Dueling DQN网络在Value函数V以外,还增加了Advantage function优势函数A,使Dueling DQN在只收集一个离散动作的数据后,能够更准确地去估算Q值,选择最合适的动作。Double DQN网络选择Q网络中拥有最大输出值的动作,然后再选择动作对应的目标Q网络,从而避免Q值被高估的问题。本申请采用的nMAD3QN-PER网络则结合了Dueling DQN和Double DQN网络的优点。
进一步的,nMAD3QN-PER还引入优先经验值回放(Prioritized ExperienceReplay),通过增加优先经验值回放更多地采样高期望值的经验,以TD error的绝对值为衡量标准,可依有效减少学习所需的经验数量,提高了学习效率。
进一步的,nMAD3QN-PER引入n-step法,观察未来多个步骤的奖励进行更新,进一步提高了学习效率。
进一步的,nMAD3QN-PER引入多智能体组合集成(Multi-Agent),包括:第一、奖励值共享:多智能体的奖励值为同一个,均为所有智能体监测到的环境状态的奖励值。每个智能体根据其周边的传感器监测到的温湿度状态,控制风口档位动作,通过包括但不限于以中心控制器或智能体之间端到端通信进行全局奖励值共享。由于奖励目标一致,多智能体之间为完全合作关系,避免了因为相互竞争所导致的算法冗余。第二,独立策略及控制:且由于nMAD3QN-PER网络会监测到当前的状态值以及该状态下的行为优势,可以较快地学习智能体有效率的动作选择。虽然智能体迁移到的算法网络一致,但是在环境中训练Fine-Tune后,每个智能体可以根据各自所收集到的状态信息,采取对于各自而言最优的策略,采用最优的控制动作,使得调控更加高效精准。第三,便于迁移学习:多智能体策略中每个智能体仅负责一个行为的选择,且采用独立的算法策略,不需要参考其他智能体所收集到的环境状态信息及他们的控制行为。除需要与外部通信全局奖励值外,每个智能体可以独立完成环境状态的监测、行为的选择及执行,在迁移后可以较快地独立应用于智能体数量不等同的迁移场景中。多个智能体同时参与训练与控制,每个智能体可以直接在边缘节点上进行低时延本地化分布式的精细化训练,节省了由中心控制器直接控制全局所带来的高频通信开销,也避免了多信道同时传输带来的信道堵塞。
最终得到了基于nMAD3QN-PER(n-step Multi-Agent Dueling Double DQN withPrioritized Experience Replay)的室内温度和湿度控制方法。
另一方面,本发明还提供一种室内空间温度和湿度调控系统,所述系统包括:
多个温湿度传感器,所述温湿度传感器包括湿度传感器和温度传感器,所述温湿度传感器设置在目标空间内;
恒温恒湿机,所述恒温恒湿机设有多个出风口,每个出风口设有多个风速档位,各出风口的风速档位单独设置不同,各出风口设置在所述目标空间内;每个出风口与其周边设定范围内的温湿度传感器构成局部控制组件;
中心控制器,所述中心控制器连接云端服务器,所述中心控制器通过物联网连接所述目标空间内的各温湿度传感器和所述恒温恒湿机的各出风口;所述中心控制器上运行多个目标域智能体,每个目标域智能体用于控制目标空间内一个局部控制组件;
所述中心控制器执行上述室内空间温度和湿度调控方法控制所述目标空间内的温度和湿度。
另一方面,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述方法的步骤。
下面结合一具体实施例对本发明进行说明:
本实施例提供一种用于室内温湿度精准均匀调控的多智能体迁移强化学习方法。利用多智能体迁移强化学习算法,控制室内温湿度,达到精准均匀状态,包括如下内容:
1)将室内空间划分为多个局部区域,设计多智能体强化学习算法,通过多个智能体分别对各局部区域进行操作,合作控制室内恒温恒湿机。
2)根据仿真场景设计控制系统要素,由于使用基于强化学习的控制算法,需根据当前场景设计强化学习算法三大要素:状态、控制动作以及奖励。
3)在CFD仿真软件中模拟实际库房场景,初始化仿真场景,并将当前的环境状态(温湿度情况)传送给强化学习算法控制智能体。
4)智能体根据传入的环境状态,计算当前环境状态的奖励值,经过强化学习神经网络训练选择当前状态下的最优动作,并将动作通信给执行器,即恒温恒湿机的出风口。
5)恒温恒湿机执行动作完毕,再将下一状态发送至智能体,进行下一步的学习。由此循环交替,形成智能体于环境的互动过程。
6)经过训练学习,智能体能根据当前状态,选择最优动作,实现室内温湿度达到精准均匀的效果,得到源域空间的强化学习模型。
7)当有新的库房需要实现室内温湿度精准均匀调控时,将预训练的智能体策略迁移学习至新的库房的智能体。
8)智能体的算法网络经过微调,训练生成对当前房间最优的决策策略,在发生外界干扰的情况下,所需应对时间缩短,维持温湿度在最佳状态。
具体的,配置系统环境以及结构:
环境:在库房中,配置有恒温恒湿系统,该系统通过多个入风口的多个传感器对室内环境进行温湿度调控。由于不同材质的物品需要存放在特定的温湿度环境中,因此必须严格控制库房内的空气温度和湿度。
传感器:温湿度传感器,可定时检测环境状况,并通过物联网(Internet ofThing,IoT)将收集的数据上传至中心控制器。大面积房间往往存在室内温度和湿度不均匀的问题。因此,部署分布式温度和湿度传感器来探测室内环境中不同位置的湿度数据。
中心控制器:中心控制器采用经过迁移学习的基于多智能体深度强化学习MADRL(Multi-Agent Deep Reinforcement Learning)的算法。中心控制器的目标是将温度和湿度保持在期望范围内且均匀。中心控制器由多个智能体组成,多个传感器上传的环境信息奖励反馈会各自上传至多个智能体,每个智能体调整各自对应的风口的风速档位,协同来做出控制决策。
执行器:恒温湿度空调系统将根据中心控制器的决策调整出风口的风速档位,不同风口的风速可调节至不同档位。
策略迁移:将源房间的源智能体策略部分迁移至目标房间的目标智能体上,通过Fine-Tune方法根据目标房间的环境进行训练。
在控制过程中,每个出风口处由一个智能体进行风速档位控制,房间内包含多个出风口时则会有相同数量的智能体控制。每个智能体控制一个出风口和多个传感器,每个传感器将检测到房间各点处的温度与湿度的环境状态上传对应的智能体中。将传感器上传的信息作为输入信息,通过深度神经网络nMAD3QN-PER,进行训练,得到相应的决策,并将动作决策输出到执行器当中。在本实施例中,执行器指恒温恒湿系统(Constant Temperatureand Humidity,CTHA)的出风口,在一定的时隙后,传感器将新采集得到的数据,再次上传至智能体。房间内所有的智能体根据当前的温湿度状态计算得到在上一个时隙内执行动作的奖励值,这里需要强调的是,所有智能体的奖励值全部为目标房间的全局奖励值,确保了所有智能体的控制目标一致。基于该奖励值,进行智能体的多智能体强化学习训练。
所以,只要标房间的热力学环境与已训练好的源房间相似,则可以使用迁移学习的方式,将源房间的智能体前端子网络进行迁移至目标房间的每个智能体,每个智能体根据其所监测的多个传感器的温湿度数据,动作为控制1个风口的风速档位,以整个房间的温湿度精确度和均匀度为奖励值。房间内的多个智能体协作,对Dueling网络的V+A层进行微调(Fine-tune),来训练适应当前房间的热力学环境,得到最优的温湿度精准度与均匀度调控策略。
下面建立系统模型并定义问题:
在部署有恒温恒湿机温湿度控制系统的室内环境中,控制目标为使室内的温湿度达到精准均匀的状态。将目标的温湿度值分别定义为T
对于每一个恒温恒湿机出风口I
由于当前室内的温湿度仅取决于前一时刻的室内状态以及恒温恒湿机的控制动作,而与之前室内状态无关。因此,本实施例将深度强化学习控制过程定义为马尔可夫决策过程。因为下一个时隙的室内空气温度和湿度由当前室内状态、CTHA系统的动作决定,与之前的状态无关。因此控制优化可以定义为一个强化学习问题。
1)室内温湿度状态:基于MADRL的控制器基于当前室内多点的温度和湿度状态进行决策。因此,状态是一个重要因素。本实施例部署分布式传感器来检测室内环境信息,包括各点的温度和湿度。本实施例将传感器在时间t时刻检测到的温度和湿度为
2)温度和湿度设定点:本实施例将目标温度和湿度定义为T
3)风速:恒温恒湿系统以恒定的温度和湿度工作,基于MADRL的智能体主要通过控制CTHA的风速档位,维持室内的温湿度在均匀精准的状态。本实施例将风速档位定义为F,F={off,low,medium,high}。即关闭,低,中,高四个档位。
4)对于多智能体Agent={Ag
系统状态(State):控制决策(即每个风口的档位值)基于对当前室内温度和湿度的观测。每个时隙的系统状态由Ag
其中,
控制动作(Action):本实施例认为可控制的变量是CTHA系统多个风口的风速档位,单个智能体Ag
5)对于整个温湿度调节系统,将其的奖励定义如下,每个智能体Ag
R
式子7中的第一项计算了每个点之间与目标状态的温度和湿度偏差。本实施例定义了两个变量,温度精准度T
式子7中的第二项主要关注了室内温湿度的均匀性。智能体旨在减少房间内不均匀温湿度分布。因此,本实施例定义了温度均匀度偏差T
优化目标:智能体根据环境产生的结果来判断动作的好坏。它的目标在于学习可以使其实现目标的动作序列。目标函数表示如下:
γ表示折扣因素且γ<1。深度强化学习的目标是最大限度地提高折扣奖励的总和。对于单个智能体,其优化目标为最大化其奖励的总合。
进一步的,基于上述nMAD3QN-PER网络进行强化学习进行室内温湿度调控,具体采用迁移学习的形式进行强化学习。
由于深度强化学习算法是针对特定的马尔可夫决策过程进行的,在当前房间通过nD3QN-PER算法所制定的最优的温湿度调节策略模型,在其他的房间未必适用,且可能会导致控制效果更差。这是由于基于无模型方法的深度强化学习虽然省略了建模的复杂度,其可以通过不断与环境交互从而进行学习,但其最终学习到的是关于某一特定房间的动态热力学模型特征,而针对这些特定的特征进行进一步的决策控制。而在新的应用场景中,其环境可能会与之前的环境有很大的区别,因此,对于不同的直接使用已有模型并不可行。此时就必须针对新的热力学环境重新训练(Learning from scratch),这需要消耗大量的计算资源与计算时间,十分低效。
由于在源房间内的温湿度控制由多个智能体共同控制完成,对于每一个智能体,其主要监测与控制局部区域的温湿度,再通过计算全局的状态得到奖励,在目标房间中,为达到同样的目标,本实施例提出将源房间内的单个智能体的策略,迁移至目标房间的多个智能体,再经过训练,共同完成目标房间内合作控制。
将智能体的强化学习策略迁移,即将源房间的智能体策略模型作为预训练模型,再基于模型进行微调(Fine-tune)。相较于直接训练目标房间的智能体,通过迁移学习和模型微调,能够更快地训练到局部最优解,节省大量的计算资源和计算时间,提高了收敛效率,提升了房间的温湿度的精准度和均匀度。本实施例提出对比四种不同的迁移方式,迁移前端自网络,迁移后端子网络,迁移全局网络、均值融合迁移网络。
迁移强化学习是能够适应不同新任务并得到相应最优策略的学习算法。迁移强化学习的基本假设是用于迁移学习的源任务与目标任务服从同一任务分布
其中,
nD3QN-PER网络由多层全连接层组成,有两个分支,V(a)用于预测状态价值(StateValue),为标量;A(s,a;θ,α)用于预测每个动作的优势(Action Advantage Value),为一个矢量,矢量长度等于动作空间大小;θ指网络卷积层的参数,α和β分别是两个分支的全连接层的参数;最后将这两个分支的结果合并输出Q(s,a;θ,α,β)。值函数V反应的是当前状态s的好坏程度,动作值函数Q描述的是在当前这个状态下选择这个动作的好坏程度,优势函数A描述的是每个动作的重要程度。在DQN中,对每个状态state估计多个Q(s,a)会导致算法的不稳定,而将值函数V与优势函数A分开计算,会增强算法的鲁棒性。
Q(s,a;θ,α,β)=V(s;θ,β)+A(s,a;θ,α); (14)
迁移前端网络:将源房间的智能体前端子网络进行迁移至目标房间的每个智能体,每个智能体根据其所监测的β个传感器的温湿度数据,动作为控制1个风口的风速档位,以整个房间的温湿度精确度和均匀度为奖励值。房间内的多个智能体协作,对Dueling网络的V+A层进行微调(Fine-tune),来训练适应当前房间的热力学环境,得到最优的温湿度精准度与均匀度调控策略。
迁移后端网络:将后端子网络两个分支网络及V+A层迁移,至目标房间的每个智能体,每个智能体根据其所监测的β个传感器的温湿度数据,动作为控制1个风口的风速档位,以整个房间的温湿度精确度和均匀度为奖励值。房间内的多个智能体协作,对网络的前端进行微调(Fine-tune),来训练适应当前房间的热力学环境,得到最优的温湿度精准度与均匀度调控策略。
迁移全局网络:将源房间的智能体策略的算法网络直接应用到目标房间的智能体,每个智能体根据其所监测的β个传感器的温湿度数据,动作为控制1个风口的风速档位,以整个房间的温湿度精确度和均匀度为奖励值。房间内的多个智能体协作,得到最优的温湿度精准度与均匀度调控策略。
均值融合(Federate)迁移网络:将源房间的多个智能体的多层全连接网络以等权重的形式进行加权融合,再将融合后的全局网络迁移应用到目标房间的智能体,每个智能体根据其所监测的β个传感器的温湿度数据,动作为控制1个风口的风速档位,以整个房间的温湿度精确度和均匀度为奖励值。房间内的多个智能体协作,得到最优的温湿度精准度与均匀度调控策略。
具体的,温湿度控制仿真在CFD仿真软件中完成,算法部分使用了开源深度学习框架tensorflow2.0完成。
在实验中,设计模拟6个不同的房间模型,如图4至9分别为房间ABCDEF的模型示意图,6个房间面积,布局各异,每个房间内均匀部署多个恒温恒湿机入风口,空调系统通过入风口调节室内的温湿度,以及多个分布式传感器。如图4,在A模型中部署有2个入风口,且每个入风口分别配备与其较为接近的3个传感器,智能体通过监测其三个传感器数据,从而进行调控。如图5至9,在BCDE模型当中,部署有3个入风口,F模型中,部署有4个入风口。
在本实施例的实验中,T
MADRL神经网络中有两个隐藏层,每个层都有512个神经元。采用了ReLU为激活函数。并使用Adam优化器,学习率设置为0.000005。折扣系数设置为0.9,mini-batch大小为32。本实施例使用ε-greedy策略进行开发和探索。ε初始是1,经过200回合它最终减少到0.001。在多智体的迁移实验中,选取不同的模型进行迁移,对比在相同以及不同智能体数量的场景中,不同的迁移方式的迁移效果。
不同算法迁移性能比较,评估四种不同迁移算法与直接训练算法的收敛情况,结果见图10和图11。
将D模型训练与由C模型、E模型进行不同方式迁移对比。在D模型以及C模型、E模型中,智能体的个数相同,采用了对应迁移的方式,即对于相应位置的智能体,如靠近出入口处,选取源模型中的对应智能体进行迁移。图中展示了对于不同迁移方式的迁移性能,可见当迁移全部网络(将C作为源模型全部迁移至D,记为D-TC-All;将E作为源模型全部迁移至D,记为D-TE-All)时,其收敛速度较源模型单独训练(D)快,但收敛值与单独训练相当。使用前端迁移(将C作为源模型前端迁移至D,记为D-TC-Front;将E作为源模型前端迁移至D,记为D-TE-Front)或后端迁移(将C作为源模型后端迁移至D,记为D-TC-Back;将E作为源模型后端迁移至D,记为D-TE-Back),收敛速度较快,且收敛值相对于单独训练更高,且在使用前端网络迁移时,其收敛值更高且更平稳。D-TC-FEDERARE表示将C作为源模型,采用均值权重迁移的方式进行全局网络模型迁移,具体是指把源模型的多个智能体的参数平均加权。
由上述图10和图11可见,当源模型与目标模型差异较大或类似的情况下,迁移前端网络都能减少所需要的训练时间以及提升其表现,这是由于对于MADRL的网络模型,前端网络的作用在于处理输入信息,捕捉到特定的环境状态数据,后端网络通过训练,可以根据前端输入信息,学习到相应的控制策略。因此,在迁移时,对于不同的模型,对主要用于生成控制策略的后端网络进行Fine-Tune,即针对不同的场景重新训练其特定适用于该目标场景的控制策略。同时,由于先前所积累的控制经验,在新的场景中进行再训练时,其有更大概率快速探索到更优的控制策略,因此其收敛值相对于原始训练方式更高。
智能体选取方式的算法对比:
在实际部署时,为更加方便,希望可以不区分每个智能体的位置而进行迁移部署,因此,本实施例验证了在源模型中任意选取一个智能体对目标模型中所有的智能体进行迁移的方式的效果。同样本实施例选取了目标模型为D模型,源模型为E,对比两种选取智能体的方式下的效果。如图12所示,类似地,对比了不同迁移方式下的性能,D表示单独训练D模型,D-TE-All表示将E作为源模型全部迁移至D,D-TE-Front表示将E作为源模型前端迁移至D,D-TE-Front-RANDOM表示将源模型E中多个智能体中的随机一个前端迁移至D,同样可见,对于不同的迁移方式,只需要更少的训练时间就可以达到目标模型单独训练的收敛值,且对比上述两图,在迁移前端网络时,无论是对于每个智能体对应迁移或是任意选取源模型中一个智能体对目标模型所有智能体进行迁移的方式,两种方式的收敛效果相当,收敛值也没有明显差异。因此,为了更利于实际的部署,在源模型中选取一个智能体的方式更加高效。
源空间不同智能体数量对比:
除此之外,对比了智能体数量不同的源房间进行迁移的效果对比。同样本实施例选取了目标模型为D模型,源模型为分别为ABC,即在ABC模型中任意选取一个智能体,并利用迁移前端网络的方式迁移至D模型中。如图13所示,D-TA-Front-RANDOM表示将源模型A中多个智能体中的随机一个前端迁移至D,D-TB-Front-RANDOM表示将源模型B中多个智能体中的随机一个前端迁移至D,D-TC-Front-RANDOM表示将源模型C中多个智能体中的随机一个前端迁移至D,D表示独立训练;其中,A模型中仅有2个智能体,可以看出,无论源模型的布局如何,或智能体的数量相等或更少,经过迁移学习,仍能以较快的收敛速度收敛至更高的值。
干扰下精准度与均匀度对比:
为了评估干扰下的精准度和均匀度,本实施例测试了60个回合。测试选用了D作为目标模型,ABCE为源模型。在每一回合中,本实施例假设随机温度和湿度的干扰(例如温度27℃,湿度45%;)在随机时刻进入,导致室内在某些位置温度和湿度偏离目标值(温度:25℃,湿度:50%)。其对比效果如柱状图14所示,D表示单独训练,D-TA表示将A模型迁移至D,D-TC表示将C模型迁移至D,D-TB表示将B模型迁移至D,D-TE表示将E模型迁移至D。可见迁移方式下的模型的控制效果更好,在温湿度的精准度,均匀度四个方面下,其值优于源模型的单独训练效果。
图15展示了D模型单独训练以及C模型作为源模型的迁移训练的50个回合下的控制效果对比,其中带圆形标记点的折线为迁移训练结果,带三角形标记点的折线为独立训练结果。在温湿度的精准度上有明显的提升,分别提升了14.42%,15.05%,在温湿度的均匀度上,分别提升了6.23%,3.38%。
房间含不同数量智能体的迁移算法对比:
在以上实验中,主要完成了源智能体与目标智能体为2-3或3-3数量对的策略迁移方式对比,为进一步验证所提出方法的有效性,进行了2-4以及3-4数量对的智能体策略迁移对比。选取了F模型作为目标模型,ABCE作为源模型。在目标模型中,任意选取所需要的迁移的智能体,迁移其前端网络至目标智能体,对其后端网络进行训练。如图16所示,F-TA-Front表示将A作为源模型前端迁移至F,F-TB-Front表示将B作为源模型前端迁移至F,F-TC-Front表示将C作为源模型前端迁移至F,F-TE-Front表示将E作为源模型前端迁移至F,F表示独立训练,使用ACE模型作为源模型时,其学习速度较于F模型训练更快,且所学习的效果更好,而B模型,训练效果较差,由于在B模型中,其布局较为简单,没有为更复杂的环境累计高效的控制经验。
柱状图17展示了在50个不同回合下,不同模型的控制效果对比,F表示单独训练,F-TA表示将A模型迁移至F,F-TC表示将C模型迁移至F,F-TB表示将B模型迁移至F,F-TE表示将E模型迁移至F。综合来看,其表现性能与训练效果一致。ACE模型在迁移时,应对不同干扰时对温湿度的精准度以及均匀度的控制明显优于目标模型原始训练的方式。可见当目标模型为4智能体,源模型为2或3智能体时,均能取的较好的控制效果。
同样,如图18所示,对比了在E作为迁移模型以及F模型单独训练下的效果对比,其中带圆形标记点的折线为迁移训练结果,带三角形标记点的折线为独立训练结果。同样,测试了50个回合中,温湿度精准度以及均匀度的变化情况,可见在不同的干扰情况下,迁移策略都明显优于原始策略,验证了所提出方法的有效性。在温度的精准度以及均匀度方面,所提出的迁移方法相较于原始训练提高16.53%、17.10%,湿度方面分别提高了16.20%、24.68%。
智能体监测传感器数量不同时的迁移算法对比
考虑到在实际部署时,在目标模型中,对于每一个智能体其所配备的传感器个数可能发生变化,如目标模型中,智能体的仅能配备2个传感器,即智能体通过监测两个传感器的数据进行动作决策。而由于源模型中,学习了3个传感器的数据信息,当在迁移时,传感器数量发生变化,导致输入维度发生变化。因此,本实施例提出映射方式,即将目标场景中2个传感器的温湿度4维数据信息映射为与源场景中输入维度一致的信息。同样选取了F模型作为目标场景,比较当ACE模型作为源模型时的训练效果对比,如图19所示,F表示单独训练,F-TA表示将A模型迁移至F,F-TC表示将C模型迁移至F,F-TE表示将E模型迁移至F。可见,相较于F模型原始训练,迁移学习的方式以较快的学习速度达到更优的学习效果。
在ACE模型中,智能体数量为分别为2,3,3,每个智能体配备的传感器数量为3,验证了当智能体数量增多至4,且传感器数量减少至2的情况下,所提出方法的有效性。对比在不同干扰下,当传感器数量减少的迁移学习效果对比。图20的柱状图结果显示,F表示单独训练,F-TA表示将A模型迁移至F,F-TC表示将C模型迁移至F,F-TE表示将E模型迁移至F,尽管传感器数量的减少,所提出的迁移方式仍能高效地对室内的温湿度进行控制,且达到更优的精准度以及均匀度。其中,当使用E模型作为源模型时,迁移效果最好,其在温湿度的精准度提升了10.43%、13.13%,均匀度上分别提升了13.69%、14.45%。
智能体含不同数量传感器时的迁移算法对比
在现实世界中,为了进一步减少开支,在个别场景中,可供的传感器数目也较少。因此,本实施例将验证当部分智能体所监测的传感器数量减少至1或2时,所提出方式的有效性。图中21显示的是当F模型中,2个智能体所检测的传感器数量为1,其余智能体所监测智能体数量为2的情况下,不同的源模型迁移学习的学习曲线,F表示单独训练,F-TA表示将A模型迁移至F,F-TC表示将C模型迁移至F,F-TE表示将E模型迁移至F。同样采用映射的方式,将输入数据维度扩充至与源模型一致,通过迁移前端网络。学习结果如图22所示,当传感器数量发生明显变化时,映射的迁移方式仍能发挥作用,且温湿度的精准度和均匀度上均有提升。
综上所述,本发明所述室内空间温度和湿度调控方法及系统,以温湿度状态参数作为状态空间,以恒温恒湿机出风口风速档位作为动作空间,通过在源空间训练预训练得到源域深度强化学习模型;在目标空间中,每个执行器与其周边设定范围内的温湿度传感器构成局部控制组件,每个局部控制组件由独立的目标域智能体控制,每个目标智能体分别迁移学习源域深度强化学习模型进行参数微调和控制,以目标空间所有温湿度传感器采集的温度值和湿度值共同计算目标空间观测奖励值,以最大化未来多步目标空间观测奖励值为目标分别对各目标域智能体的源域深度强化学习模型进行训练,以快速适应对目标空间环境对温湿度的实现精准控制。
本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时以实现前述边缘计算服务器部署方法的步骤。该计算机可读存储介质可以是有形存储介质,诸如随机存储器(RAM)、内存、只读存储器(ROM)、电可编程ROM、电可擦除可编程ROM、寄存器、软盘、硬盘、可移动存储盘、CD-ROM、或技术领域内所公知的任意其它形式的存储介质。
本领域普通技术人员应该可以明白,结合本文中所公开的实施方式描述的各示例性的组成部分、系统和方法,能够以硬件、软件或者二者的结合来实现。具体究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。当以硬件方式实现时,其可以例如是电子电路、专用集成电路(ASIC)、适当的固件、插件、功能卡等等。当以软件方式实现时,本发明的元素是被用于执行所需任务的程序或者代码段。程序或者代码段可以存储在机器可读介质中,或者通过载波中携带的数据信号在传输介质或者通信链路上传送。
需要明确的是,本发明并不局限于上文所描述并在图中示出的特定配置和处理。为了简明起见,这里省略了对已知方法的详细描述。在上述实施例中,描述和示出了若干具体的步骤作为示例。但是,本发明的方法过程并不限于所描述和示出的具体步骤,本领域的技术人员可以在领会本发明的精神后,作出各种改变、修改和添加,或者改变步骤之间的顺序。
本发明中,针对一个实施方式描述和/或例示的特征,可以在一个或更多个其它实施方式中以相同方式或以类似方式使用,和/或与其他实施方式的特征相结合或代替其他实施方式的特征。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域的技术人员来说,本发明实施例可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。