一种基于边界拟合的多尺度特征融合场景文本检测方法
文献发布时间:2024-01-17 01:28:27
技术领域
本发明属于计算机视觉技术领域,特别涉及基于深度学习的场景文本检测方法。
背景技术
作为实际应用领域中的重要研究课题之一,场景文本检测技术在过去一段时间内取得了极大的进展,并且涌现出了许多优秀的方法模型。因为场景文本的复杂性与多变性,场景文本检测方法综合多方面因素,不断设计各式各样的功能模块,辅助网络对任意形状、大小分布不均、视觉角度扭曲的文本进行定位检测。
受到目标检测方法的启发,一些研究在文本实例为规则形状的文本图像上取得了理想的效果,它们主要由堆叠的卷积组成,将输入图像编码为特征映射,然后将特征图输入分类器,预测每个空间位置的文本实例的存在和定位。受一阶段检测模型的启发,Liao等人提出的Textboxes网络通过将默认框定义为具有不同高宽比的四边形来适应SSD网络,以有效地检测定位自然图像中的文本。并且为了更好的覆盖某些区域可能密集的文本,使用垂直偏移来调整默认框。Zhou提出的East网络采用U型设计网络,集成不同层次的特征,每个空间位置的特征用于回归底层文本实例的矩形或四边形边界框,同时预测检测框的角度以检测方向多向的文本,在文本检测领域中发挥了重要作用,既高度简化了管道,又能够进行高效的实时推理。基于相同的思路,在Ma等人提出的方法中,网络用于生成旋转候选区域而不是轴对齐矩形区域,以适应任意方向的文本。尽管上述方法对于检测水平多向性、规则形状文本具有较佳的效果,受到多变的文本形状、纹理尺度以及光照等干扰因素的影响,场景文本的研究仍具有巨大的挑战性,尤其是自然场景中的不规则形状文本图像的检测问题。
与上述方法不同的是,本发明的方法并没有采用基于检测框回归的方法,而是通过像素分类,基于分割确定预测检测框。
基于分割的方法通过像素级别预测来定位文本区域以增强文本形状、角度变化的鲁棒性。Liao等人提出的DBNet网络将二值化模块插入到分割网络中进行联合优化,这样网络可以自适应地预测图像中的每一个像素点的阈值和概率,从而完全区分前景和背景的像素。二值化阈值又从网络中学习得到,彻底将二值化步骤加入到网络中一起训练,这样最终输出对于阈值和概率就会具有非常敏感且可以进行自适应调整,在简化了后处理的同时提高了文本检测的效果。然而单一依赖于分割检测文本,很难区分相邻文本区域,Wang等人提出的方法以不同尺度收缩文本区域,并逐渐放大检测到的文本区域,直到与其他实例发生碰撞,该方法能够有效提取并区分图像中相邻的文本实例。
还有一些工作尝试使用不同方法来区分并提取相邻文本实例。例如,TextSnake网络认为文本可以表示为一系列沿文本中心线滑动的圆盘,类似蛇形,这符合文本实例的运行方向。通过这种新颖的方法,该模型学习并预测局部属性,包括中心线、文本区域/非文本区域、圆盘半径与方向,然后使用局部几何圆形以有序点列表的形式提取中心线,利用其重建文本行,在几个弯曲数据集中实现了较先进的性能。除了基于文本核心区域扩大的检测方法,近来还有一些工作尝试对特征提取部分以及损失函数进行调整。例如Kim等人提出的方法着重于设计网络架构来反映损失函数,从而得到最大化条件对数似然,并且该模块独立于输出特征的后处理。PAN方法提取特征部分由特征金字塔和特征融合模块组成,特征金字塔是一个可级联的U形模块,可以引入多层次信息指导更好的分割,经过该模块获得的特征再进行收缩后与分割图像共同作用,生成最终的检测框。
因此,场景文本检测方法总结如下:(1)基于回归的方法预测多个候选框,通过后处理方式选择表现最优秀的检测框。(2)基于分割的方法利用文本分类信息获得分割图,从而得到预测检测框。但是,这两种方法都存在缺陷与不足。基于回归的方法多采用四边形检测框,对自然场景中的弯曲文本检测效果不佳;基于分割的方法虽然能够更好检测任意形状场景文本,但过于依赖预测检测框精确度,出现边缘检测不完整或包含较多背景噪声等问题。
发明内容
本发明的目的在于提出一种基于边界拟合的多尺度特征融合场景文本检测方法,通过引入距离和方法先验知识,从而更加有利于相邻密集文本的分离与区分;并且设计一种基于边界拟合的文本检测框架,包含边界拟合模块和多尺度融合模块,通过使边界自适应学习变形和增加感受野,提升模型的检测精确度。为了公平客观的比较结果,本发明的方法采用使用广泛的场景文本数据集Total-Text和CTW1500进行训练,数据集中都标定了多边形检测框的位置。训练完成后,在这两个数据集中的测试集进行测试,通过对比发现,本发明的方法提升了场景文本检测的精度。
为了达到以上目的,本发明技术方案为:一种基于边界拟合的多尺度特征融合场景文本检测方法,该方法为:
输入图像依次经过残差网络ResNet、多尺度特征融合模块,然后分为两路一路经过一个卷积模块conv1,卷积模块conv1的输出与另一路一起输入通道融合模块C,通道融合模块C的输出经过边界拟合模块和预测输出模块;
所述先验特征提取模块的损失函数L
其中,L
p∈T表示属于文本区域T的所有像素点p,D
L
其中,norm_loss表示距离损失,angle_loss表示角度损失,V
进一步的,所述所述残差网络ResNet为提取输入图像的多尺度特征,尺度包括;1/16、1/8、1/4;
多尺度特征融合模块的融合方法为:
步骤1:将1/4大小的特征图进行上采样与卷:操作,生成32通道的尺度为原来两倍的图像,尺度为1/2;
步骤2:依次将1/16、1/8、1/4和生成的1/2尺度的特征图进行上采样,再通过1×1卷积将通道数均调整为32;
步骤3:将步骤2得到的各尺度特征图在通道维度上对应融合生成多尺度融合特征,再利用1×1卷积将融合后的特征图通道数调整至原输入图像的大小,得到共享特征。
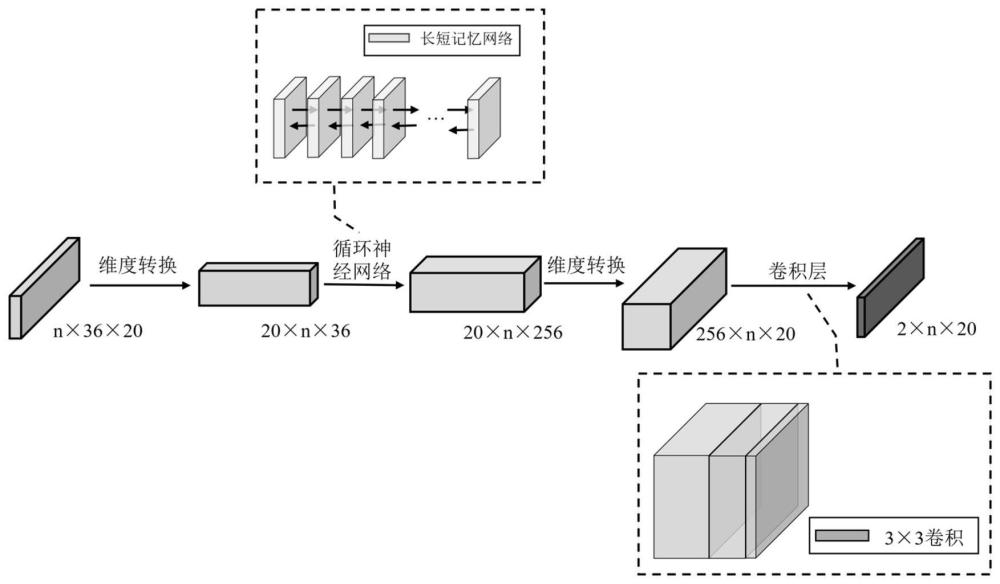
进一步的,所述边界拟合模块的输入数据首先经过维度转换,送入循环神经网络,然后再次经过维度转换后送入卷积层,最后输出;
所述边界拟合模块的损失函数L
其中,T表示图像中所有的文本实例的控制点集,n表示设定的控制点的数量,(k+i)%n表示损失计算中控制点是顺序计算的,||·||
本发明提出引入先验知识,并通过边界变形,融合多尺度特征来实现检测精度提升。具体来说,本发明为了缓解紧密文本识别不佳的问题,在网络模型中增加方向知识辅助像素分类;通过方向信息与距离信息,结合文本像素点方向与距离能够有效分离紧密文本内容,并帮助预测文本边界;针对基于分割的检测方法依赖于轮廓边界的问题,本发明提出边界拟合模块,利用序列关系进行学习让控制点发生偏移以使边界变形,获得最终的检测外轮廓。以保证轮廓尽量包含完整的文本区域,使检测外轮廓更加拟合不规则形状的文本;针对自然场景中存在较多面积较大的文本,其中包含的文本形态各异并且大小分布不均匀,本发明在特征提取部分增加多尺度特征融合模块,获取不同大小感受野的特征信息,改善自然场景中的文本检测不完整的问题。
附图说明
图1是基于边界拟合的多尺度特征融合场景文本检测网络结构图。
图2是边界拟合模块网络结构图。
图3是多尺度特征融合模块结构图。
图4是在Total-Text数据集中的实验结构图。
具体实施方式
本发明的主要特点在于:本发明提出了一种基于边界拟合的场景文本检测方法,用于提升文本定位准确性。(1)为分离紧密文本,本文引入方向和距离信息作为先验知识。(2)同时本文对检测区域不能包含完整文本内容或包含过多背景噪声的问题进行深入分析,设计了两个有效的模块。一是边界拟合模块,通过控制点偏移使检测框更加拟合文本形状。二是多尺度融合模块,融合多尺度特征图信息以增加网络感受野;(3)在Total-Text和CTW1500数据集中的大量实验证明,本发明所提出的模块能有效提升场景文本检测网络性能,在Total-Text数据集上获得了最佳性能,在CTW1500数据集中取得了较具竞争力的性能。
整体检测网络框架如图1所示,引入先验知识,并包括边界拟合模块和多尺度特征融合模块;整体损失函数L为先验知识部分L
(1)引入距离、方向先验知识
方向场是一个单位二维向量,表示文本像素点到最近非文本像素点的方向,靠近文本边缘的文本像素指向文本中心方向。如果两个文本区域相邻,其二者边缘处的像素指向则不同,因此方向场能够根据预测向量和真实方向向量之间方向和距离的差异,有效区分紧密文本区域。同时借助方向场距离信息生成距离信息,表示文本像素在文本区域内的相对位置。通过方向信息与距离信息,结合文本像素点方向与距离能够有效分离紧密文本内容,并帮助预测文本边界。
其中,损失函数的设计为:在预测文本或非文本时,采用常用的交叉熵分类损失函数作为文本分类的损失函数,L
其中D
其中V
L
经过上述步骤即可以计算出预测候选边界所需的损失函数L
(2)设计边界拟合模块
通过在预测边界上等距离采样一定数量的控制点,利用序列关系进行学习让控制点发生偏移以使边界变形,获得最终的检测外轮廓,其网络结果如图2所示。以保证轮廓尽量包含完整的文本区域,同时减少检测结果中的非文本背景噪声,使检测外轮廓更加拟合不规则形状的文本。
在边界中选取控制点进行训练学习,使其接近ground truth中的控制点,本发明采用一种类似点匹配损失来计算控制点与真实点之间的偏差来调整模型以及自适应变化方向。在该网络中预测时选取的控制点和真实边界上选取的控制点数量是一致的,顺序也相似(逆时针顺序),将预测点集定义为P={p
其中n表示设定的控制点的数量,函数中用(k+i)%n来确保损失计算中控制点是顺序计算的,由此计算出的损失
因为一张输入图像中往往含有多个文本区域,所以将总的边界控制点损失定义为L
(3)设计多尺度融合模块
本发明将不同尺度特征进行上采样后进行融合。但不同于下采样再上采样以将每个尺度的特征进行融合的方法,本发明所设计的模块更为简单并且具有更小的计算损耗。首先将1/4大小的特征图进行上采样与卷积(conv)操作,生成32通道的尺度为原来两倍的图像,然后依次将1/16、1/8、1/4和生成的1/2尺度的特征图进行上采样后通过1×1卷积将通道数均调整为32,在通道维度上融合生成多尺度融合特征,再利用1×1卷积将融合后的特征图通道数调整至原输出大小,其结构如图3所示。该方法在依次特征融合后,直接在最终输出的特征图中融入深层次特征图信息,让输出图获得更多高层次特征信息,并且将原来网络中特征金字塔的输出放大4倍数,输出与原图像大小一致。多尺度特征融合模块在上采样过程中融合不同尺度的特征图信息,达到在不增加过多参数的基础上扩大感受野的效果。
以下是本发明的方法的实验结果。在介绍实验结果之前,先介绍实验设定。本发明采用Total-Text和CTW1500数据集进行实验,采用精确率P、召回率R和二者的调和平均数F作为评价指标。
表1为本发明的方法与现有先进方法的对比,通过表格中的实验数据对比,证明本发明所提出的检测网络在引入方向、距离信息,增加边界拟合模块,改善特征融合模块后能够在自然场景文本数据集中取得不错的效果。其中Backbone表示网络模型所选用的特征提取网络类型,External Dataset表示所使用的预训练数据集。
与现阶段方法对比,该模型能够取得较先进的结果,在前沿方法中具有一定竞争力。在Total-Text数据集中,达到了89.7%的精确度和83.7%的召回率;在CTW1500数据集中,获得了86.4%的精确度和83.7%的调和平均数结果。
同时,通过图4中可视结果的对比,本发明提出的方法能够较为完整的检测文本区域,生成的边界能够更好地拟合文本形状,且对于相邻的密集文本区域,能够实现有效分离。
表1与现有先进方法在Total-Text和CTW1500数据集上对比实验数据
- 一种基于多维信息特征融合的交通场景烟雾智能检测方法
- 一种基于多尺度特征金字塔的场景文本检测方法及系统
- 一种基于选择性特征融合金字塔的场景文本检测方法