基于门控循环单元网络的工业互联网设备故障预测方法
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及信息技术领域。
背景技术
设备的故障诊断与预测一直是学者们关注的研究热点,近几年来,随着机器学习方法的流行,越来越多的研究人员尝试将机器学习的方法应用到设备状态诊断与预测中来。
陈志平等人采用基于奇异值分解优化的局部均值分解法提取电梯轿厢振动时频域特征,然后采用聚类分析进行电梯故障分析,采用回归分析实现电梯故障的预测。范李平等人首先对变电设备故障影响因素进行相关性分析,选择影响因素,然后利用Logistic回归算法进行故障预测。王桂兰等人使用XGBoost算法在风机主轴承故障预测中取得了良好的效果.Leahy等人首先根据领域知识进行特征选择,然后通过随机网格搜索寻找超参数来训练支持向量机进行故障诊断。
然而,以上基于传统机器学习算法的研究仅适用于有限数据样本空间,在实际工业环境中,数据规模特别大,且数据之间具有高度的时间相关性,以上方法并不适用。
随着近几年深度学习的快速发展,基于深度学习的时间序列分析也成为目前设备故障诊断与预测的一个研究热点。国内的周剑飞等人也提出了一种基于LSTM神经网络模型和滑动窗口技术进行设备故障的在线检测,但此方法并没有解决实际工业环境中数据严重倾斜的问题。
现有技术说明
在实际问题中,异常数据往往只占正常数据的极小比例,而当前绝大多数机器学习算法都是基于正负样本比例相差不大的假设,因此严重倾斜的样本数据在某些情况下会导致算法准确性大大降低.例如:欺诈电话检测、信息检索和过滤以及机载直升机变速箱故障监测等问题。
欧式距离也称欧几里得距离,是最常见的距离度量,衡量的是多维空间中两个点之间的绝对距离。
在工业上直接通过设备传感器获得的数据往往具有非常高的相关性,并且由于内外部环境的影响,传感器产生的数据一般都会具有噪声.基于以上原因,直接对传感器数据进行处理会产生算法的运行效率低、准确率不高等问题。
sigmoid神经网络中的激活函数,其作用就是引入非线性。具体的非线性形式,则有多种选择。sigmoid的优点在于输出范围有限,所以数据在传递的过程中不容易发散。当然也有相应的缺点,就是饱和的时候梯度太小。sigmoid还有一个优点是输出范围为(0,1),所以可以用作输出层,输出表示概率。sigmoid求导容易。
发明内容
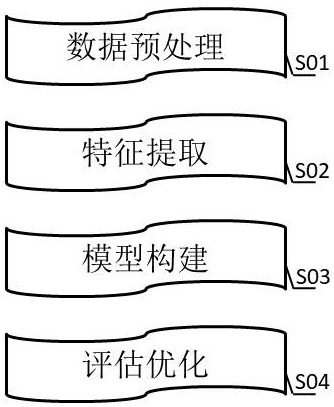
鉴于现有技术的不足,本发明提供的基于门控循环单元网络的工业互联网设备故障预测方法包括四个步骤,分别是数据预处理、特征提取、模型构建和评估优化;
1)数据预处理
⑴根据正常数据和异常数据比例,即数据倾斜程度确定一个采样比率N,当正常数 据大于异常数据时,采样比率为正常数据总数除以异常数据总数,少数类样本为异常数据 样本;当正常数据小于异常数据时,采样比率为异常数据总数除以正常数据总数,少数类样 本为正常数据样本;设少数类中样本数为T;对于少数类中的一个样本
⑵从这k个近邻样本中任取一个
⑶将步骤2重复N次,对于
⑷对于少数类中所有样本执行上述操作,为该少数类合成N×T个新样本,少数类样本与多数类样本总数达到一致,即正常数据样本与异常数据样本在总数上达到同样数目;
2)特征提取
⑴设原始数据样本包含m个n维特征向量
⑵计算样本数据的协方差矩阵:
⑶利用特征值分解方法求解协方差矩阵的特征值λ
⑷将特征值从小到大排序,选取其中最大的k个,然后将其对应的k个特征向量组成特征向量矩阵P;
⑸将原始样本数据投影到低维向量空间中:Y=P
3)模型构建
⑴在循环神经网络中添加遗忘门,遗忘门由一个sigmoid函数对输入数据进行选 择,淘汰数据则输出为0,选择数据则输出为
⑵在循环神经网络中添加输入门,输入门计算需要更新的信息
⑶输入门计算备选的用来更新的内容
tanh为激活函数,b
⑷输入门更新神经网络的细胞状态
⑸在循环神经网络中添加输出门,输出门确定作为输出的细胞状态
B
⑹输出门计算输出值
4)评估优化
将设备的工作状态问题转换为二分类问题:工作正常或工作异常,因此对工作状态的预测共有4种可能的结果:真正例TP、真负例TN、假正例FP、假负例FN;
查准率=真正例/(真正例+假正例);
召回率=真正例/(真正例+假负例);
调和平均值=2*查准率*召回率/(查准率+召回率)。
有益效果
本发明的方法与基于传统机器学习的状态预测相比,对特征工程质量的依赖更少,可以更灵活地分析和处理机器状态的特征;与基于深度学习的状态分析相比,不需要海量训练集,节省了大量的人力和物力成本。
附图说明
图1是本发明的步骤流程图。
具体实施方式
实施例一
参看图1,本发明提供的基于门控循环单元网络的工业互联网设备故障预测方法包括四个步骤,分别是数据预处理、特征提取、模型构建和评估优化;
S01数据预处理步骤
⑴根据正常数据和异常数据比例,即数据倾斜程度确定一个采样比率N,当正常数 据大于异常数据时,采样比率为正常数据总数除以异常数据总数,少数类样本为异常数据 样本;当正常数据小于异常数据时,采样比率为异常数据总数除以正常数据总数,少数类样 本为正常数据样本;设少数类中样本数为T;对于少数类中的一个样本
⑵从这k个近邻样本中任取一个
⑶将步骤2重复N次,对于
⑷对于少数类中所有样本执行上述操作,为该少数类合成N×T个新样本,少数类样本与多数类样本总数达到一致,即正常数据样本与异常数据样本在总数上达到同样数目;
S02特征提取步骤
⑴设原始数据样本包含m个n维特征向量
⑵计算样本数据的协方差矩阵:
⑶利用特征值分解方法求解协方差矩阵的特征值λ
⑷将特征值从小到大排序,选取其中最大的k个,然后将其对应的k个特征向量组成特征向量矩阵P;
⑸将原始样本数据投影到低维向量空间中:Y=P
S03模型构建步骤
⑴在循环神经网络中添加遗忘门,遗忘门由一个sigmoid函数对输入数据进行选 择,淘汰数据则输出为0,选择数据则输出为
⑵在循环神经网络中添加输入门,输入门计算需要更新的信息
⑶输入门计算备选的用来更新的内容
tanh为激活函数,b
⑷输入门更新神经网络的细胞状态
⑸在循环神经网络中添加输出门,输出门确定作为输出的细胞状态
B
⑹输出门计算输出值
S04评估优化步骤
将设备的工作状态问题转换为二分类问题:工作正常或工作异常,因此对工作状态的预测共有4种可能的结果:真正例TP、真负例TN、假正例FP、假负例FN;
查准率=真正例/(真正例+假正例);
召回率=真正例/(真正例+假负例);
调和平均值=2*查准率*召回率/(查准率+召回率)。
- 基于门控循环单元网络的工业互联网设备故障预测方法
- 基于门控循环单元网络集成的水质预测方法