一种裂殖壶菌CRISPR/Cas9基因编辑系统及其应用
文献发布时间:2023-06-19 09:35:27
技术领域
本发明涉及基因工程领域,尤其是一种涉及裂殖壶菌(
背景技术
裂殖壶菌是一种高产DHA的海洋真菌,因其生长速率快,发酵产生的油脂中不饱和脂肪酸成分简单,DHA含量高而成为研究的热点。裂殖壶菌主要通过PKS和FAS两种途径来分别合成饱和脂肪酸和不饱和脂肪酸,目前通过菌种选育、培养基优化和发酵调控来提高裂殖壶菌中不饱和脂肪酸的含量已经陷入瓶颈,需要对裂殖壶菌胞内脂肪酸合成途径的关键酶及调控因子进行深入研究,而裂殖壶菌遗传转化体系是研究代谢机制的重要手段。因此,亟需一个高效且可以实现多重编辑的工具,来实现裂殖壶菌体内多重基因编辑。CRISPR/Cas9系统是一种新兴基因编辑工具,具有脱靶率低、操作简便、可实现多重编辑等优点而被广泛应用。
目前,针对裂殖壶菌的基因改造,国内外学者主要采用同源重组的方法进行基因的过表达或者敲除,比如专利201710327363.X基于同源重组的方法,将用来自希瓦氏菌PKS酶中的酰基转移酶功能域替换裂殖壶菌PKS酶中的酰基转移酶功能域,提高了菌种中的EPA含量;专利201710747980.5和专利201710078025.7同样采用同源重组技术分别在裂殖壶菌中过表达丙二酸单酰转移酶基因和敲除酮基合成酶,最终调控了菌种的油脂积累和脂肪酸合成,但是同源重组的方法,效率不高。近年来,CRISPR/Cas技术在基因编辑方面的成就十分显著,被广泛应用于基因编辑领域。CRISPR/Cas系统是存在于细菌和古菌中的防御系统,用以免疫噬菌体以及外源DNA的入侵。CRISPR/Cas系统由重复的间隔序列(clusteredregularly interspaced short palindromic repeats)和CRISPR相关基因(cas)组成。根据菌种的不同,重复的间隔序列由多个21~48 bp回文重复序列和 26~72 bp重复序列间非重复间隔序列组成。当外源 DNA 第一次入侵细菌时,Cas核酸酶可在sgRNA的引导下与外源序列结合并切割DNA双链,产生新的间隔序列并插入至已有的间隔序列中。若相同DNA再次入侵,CASCADE 复合体识别,结合和剪切之,特异性降解外源DNA。但是目前,Crispr/Cas9的基因编辑方法在裂殖壶菌中未广泛应用,为提高裂殖壶菌的基因编辑效率,本发明构建了裂殖壶菌的CRISPR/Cas9基因编辑系统,并成功敲除了裂殖壶菌尿嘧啶合成途径的酶,得到一株尿嘧啶缺陷型的菌株,为后续的裂殖壶菌在合成生物学中的应用提供了技术指导。
发明内容
本发明的目的在于提供一种基于CRISPR/Cas9的应用于裂殖壶菌(
为实现上述技术目的,本发明采用如下技术方案:
一种应用于裂殖壶菌的CRISPR/Cas9基因编辑系统,在pBS-Zeo质粒中引入调控元件得到,所述调控元件包括裂殖壶菌P
所述的P
所述的Cas9蛋白的核苷酸序列如SEQ ID NO:3所示,所述的裂殖壶菌内源性核定位信号的核苷酸系列如SEQ ID NO:4所述。
所述sgRNA转录盒包括P
进一步的,所述P
进一步的,所述系统还包括SV40核定位信号(PKKKRKV),所述SV40核定位信号与裂殖壶菌内源性核定位信号分别连接Cas9蛋白的两端,可提高效率。
本发明还提供了上述CRISPR/Cas9基因编辑系统的构建方法,步骤如下:
(1)将P
(2)将步骤(1)构建好的重组载体pBS-Cas9单酶切后与裂殖壶菌P
(3)将步骤(2)构建好的CRISPR/Cas9重组载体转至
所述步骤(3)中,将构建好的CRISPR/Cas9重组载体通过热激法转化至大肠杆菌DH5α感受态细胞中。
所述培养方式如下:
单菌落挑取于50mL LB液体培养基中,200rpm、37℃振荡培养,过夜培养12小时,利用AXYGENE质粒小提试剂盒提取后得到重组载体质粒DNA。
本发明还提供了CRISPR/Cas9基因编辑系统在裂殖壶菌基因编辑中的应用,将构建好的质粒转化入裂殖壶菌感受态细胞中,取孵育液涂布于抗性筛选平板倒置培养,挑取转化子于单菌落于裂殖壶菌种子培养基中进行富集,富集后的阳性克隆菌株进行提取基因组DNA,PCR验证获得基因敲除的重组菌株。
本发明的基因编辑系统在初次构建完成后,如需改变敲除的目的基因,只需通过更换系统中的sgRNA识别的靶序列即可实现。
本发明具有如下有益效果:
(1)将敲除载体涉及的所有调控元件(Cas9表达启动子P
(2)采用裂殖壶菌内源性的启动子来控制Cas9蛋白和sgRNA的表达,可提高表达效果;
(3)设计采用内源性的核定位信号引入到载体中,更加有效地将Cas9蛋白引入到细胞核进行切割。此外还可增加通用型的SV40核定位信号,辅助定位,提高效率。
(4)筛选的Cas9表达启动子P
(5)本发明基于Crispr/Cas9系统获得了尿嘧啶缺陷性的裂殖壶菌菌株,为后续该菌株的基因改造提供了优良的实验材料。
附图说明
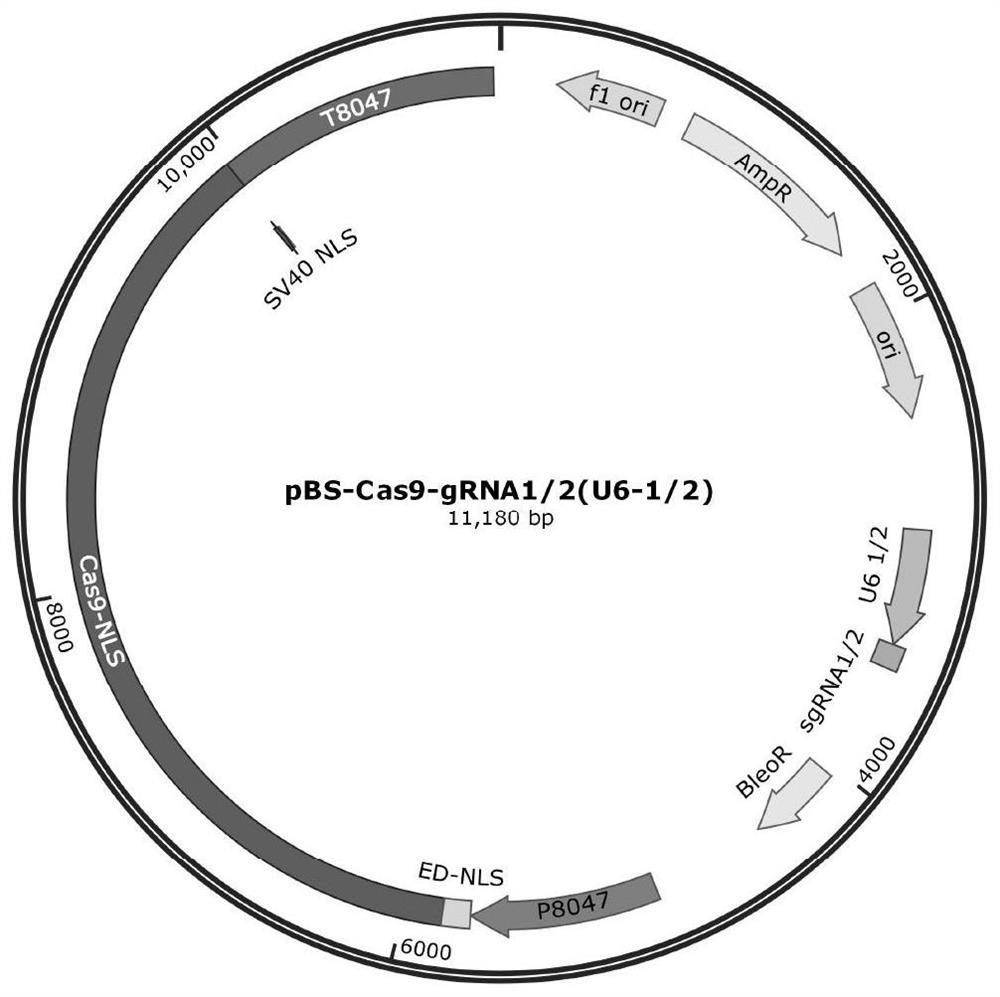
图1为本专利构建的裂殖壶菌Crispr基因敲除质粒骨架图。
图2为原始菌和敲除菌在5-FOA和尿嘧啶缺陷平板上的生长情况。
图3为原始菌和敲除菌的形态图。
具体实施方式
为了使本专利的目的、技术方案及优点更加清楚明白,以下结合具体实施例,对本专利进行进一步详细说明。此处所描述的具体实施例仅用以解释本专利、并不用于限定本发明。
以下实施例以敲除裂殖壶菌OPRT酶编码基因pyrF基因为例,构建基因敲除系统及基因敲除重组菌。
本发明中的生物材料来源如下:
裂殖壶菌(
质粒pBS-Zeo,已公开于本实验室在先申请的专利CN104974944B中;
质粒pUC-Cas9,将密码子优化后的Cas9序列连接至pUC57质粒构建而成,具体构建方式可参照《分子克隆实验指南》;其中Cas9序列为委托基因公司合成的含密码子优化的Cas9序列,其核苷酸序列如SEQ ID NO:3所示;
质粒pUC-fFuCas9-HTB
实施例1 一种CRISPR/Cas9基因编辑系统及其构建方法
根据如图1质粒图构建Cas表达载体,以裂殖壶菌内源性启动子P4(即P
(1)将Cas9表达启动子P
以裂殖壶菌基因组DNA为模板,采用引物pbs-lb-uc pro F/pro-cas9 R,egfp-ter F/egfp-ter-RB-pbs R,cas9-nls F/e-nls R分别扩增启动子P
(2)sgRNA转录盒启动子P
以裂殖壶菌基因组DNA为模板,采用引物U6-2 F/U6-2R扩增启动子P
步骤(1)(2)连接体系和条件为:来自南京诺唯赞有限公司的One Step CloningKit 试剂盒,酶切后的载体n bp*0.02 ng、片段n bp*0.02 ng,ExnaseMultiS 2uL、5 × CEMultiS Buffer 4 uL、ddH2O up to 20uL,37℃,反应30 min。
此系统在初次构建后,如需改变敲除的目的基因,只需要通过更换系统中的N20序列即可,具体操作方法如下:
更换N20序列是,以设计好的目标位点的基因序列为模板,合成1条引物,利用合成引物与引物U6-2 gRNA R直接以pBS-Cas9- gRNA1(U6-2)质粒为模板进行扩增,扩增完成引物直接重组连入pBS-Cas9质粒,进而引导Cas9蛋白对基因组中的新的目的基因的特异性切割。
如需改变引导Cas9蛋白表达的启动子,直接更换Cas9前方序列重新整合至载体即可;
如需改变引导gRNA表达的启动子,直接更换gRNA前方序列重新整合至载体即可;
如需比较不同核定位信号,只需更换Cas9序列的N和C端处核定位信号序列即可。
本发明所使用的引物见下表:
表1主要引物及核苷酸序列
实施例2 不同核定位信号对敲除效率的影响
按照实施例1的方法更换不同的内源性核定位信号序列,考察不同核定位信号组合对敲除效果的影响,基因组编辑效果根据阳性克隆数获得。结果如表2所示。(实施例中内源性定位信号连接Cas9蛋白N端,SV40连接C端)
表2 不同核定位信号的基因组编辑效果
可见,利用裂殖壶菌内源性核定位信号序列的编辑效率高于传统的SV40序列,且将两种核定位信号共同使用可大幅度增加编辑效率。
实施例3 不同启动子控制Cas9蛋白和sgRNA表达对敲除效率的影响
按照实施例1的方法,以表1中的引物序列获得P1-P4四种启动子(SEQ ID NO:33-36),以启动Cas9蛋白的表达,考察其对敲除效果的影响,表达量通过RNA测序或RT-PCR方法获得,基因组编辑效果根据阳性克隆数获得。结果如表3所示。
表3 不同启动子基因组编辑效果
可见,利用中等强度启动子P4(即P
实施例4 基于CRISPR/Cas9的裂殖壶菌pyrF基因敲除
将实施例1构建成功的pyrF基因敲除载体转化入裂殖壶菌HX-308感受态细胞中(吸取感受态细胞与载体DNA混合物至2min预冷的电转杯中,冰浴静置10min,电压1.65kv进行电击,迅速加入1mL裂殖壶菌种子培养基中混匀,孵育,30℃、170rpm、复苏4h);取适量孵育液涂布于1.0g/L 浓度的5-FOA抗性筛选平板,28℃倒置培养,48h后挑取转化子于单菌落与裂殖壶菌种子培养基(50mL)中进行富集,富集后的阳性克隆菌株进行提取基因组DNA,以OPTR-F/OPRT R引物进行PCR验证,获得pyrF基因敲除的重组菌株MT10-1,MT 9-2。该菌株呈现出尿嘧啶缺陷性状,证明重组菌中尿嘧啶基因被破坏(如图2,3)。
以上所述实施例仅表达了本发明的一种实施方式,其描述较为具体和详细上述实施方式还可以做出若干变形、组合和改进,这些都属于本专利保护范围。因此,本专利的保护范围应以权利要求为准。
序列表
<110> 南京工业大学
<120> 一种裂殖壶菌CRISPR/Cas9基因编辑系统及其应用
<130> xb20102901
<160> 36
<170> SIPOSequenceListing 1.0
<210> 1
<211> 800
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 1
tttgtttctt acatcaattc attcgttcgc tcacgcactc cttctttatt actattagaa 60
ggcgcgcaca cccgcacacc cacactctct ccccacaccc gccccagcgc gcgcgcaaag 120
agctagagtg aagaagggag agggggggca gagagagaga aagaaaccaa agaaaaagaa 180
ggaaagaaag aaagaaagaa agaaagaaag aaagaaagaa aacaaaacaa aggatggtaa 240
aagaagtccc ctccactcta ctccactcca ctcctctcca ctccactcca ctccactcct 300
ctccactcct cgccactcag ctgctctcca gtccgctcga cgctgcgctc tctccagtct 360
cgggtctcgc cgtgtccgca ggcgcacgcg gcgcagcacg cggctctgtg cgcggccccg 420
tcttctctgg cgccgcccgc agggaggctc cctctgctcc gcaggaaggg aggaaggtgc 480
tcgcgcggcc cgcgctctct cctctctcct ttcctctctg tgtctgctgc tcgcttgggt 540
gaactttttt ttaaactttg ttacctttgc acccatttcc cgctcgcctc ggctgtttct 600
cgcctccggg gccagagaga gaggcggcct ctgcacgcag caaacaccat tcgagggcca 660
gcaggcagtc ccgtgcagaa cgagaccggc cgtgctttcg ccttgctttg cgttgccagg 720
aacagcagca gcagcagcaa gagcaagagc aagagcaacg gcagcaggtt taccttcgga 780
ggaccagaac cagagaaacc 800
<210> 2
<211> 1189
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 2
atggtctcca agggcgagga gctctttacc ggcgtcgtcc ctattctcgt cgagctcgac 60
ggcgacgtca acggccacaa gttttccgtc tccggcgagg gcgagggcga cgccacctac 120
ggcaagctca ccctcaagtt tatttgcacc accggcaagc tccccgtccc ttggcctacc 180
ctcgtcacca ccctcaccta cggcgtccag tgcttttccc gctaccccga ccacatgaag 240
cagcacgact tcttcaagtc cgccatgccc gagggctacg tccaggagcg caccattttc 300
ttcaaggacg acggcaacta caagacccgc gccgaggtca agtttgaggg cgacaccctc 360
gtcaaccgca ttgagctcaa gggcatcgac tttaaggagg acggcaacat tctcggccac 420
aagctcgagt acaactacaa ctcccacaac gtctacatca tggccgacaa gcagaagaac 480
ggcatcaagg tcaacttcaa gatccgccac aacattgagg acggctccgt ccagctcgcc 540
gaccactacc agcagaacac ccctattggc gacggccctg tcctcctccc cgacaaccac 600
tacctctcca cccagtccgc cctctccaag gaccctaacg agaagcgcga ccacatggtc 660
ctcctcgagt ttgtcaccgc cgccggcatt accctcggca tggacgagct ctacaagtaa 720
atggtaaacc cggtttttgt acttttctga ctttttcact cctctctctt gctccttttg 780
tctttttgct gattgtttga gcctgaggcg agttattggt gactggacct tgtgtgcctt 840
gttttgcccc cttcttgttt tcaagggtga tcaagccgaa gcagagctga tttttgcttg 900
ggtccacaac caagatcgag gatggaggat ggcgcgccct cggaggacgt cttgcgcgag 960
agcggcggca gcgcaggggg cctcgtgacc gtggtgctgg atatgaacga agctctttgg 1020
gcgcaagtgt cggccaaggg cggcgaggac aacgtgacgc tcgcgagcgc cctcagcagc 1080
gtggtggtct ttctcaacgc cgtgcagctc atggaccgtg aaagcgaggt ctgtgtcgtg 1140
gcagagtgcc ccgacggcac tgcgcgcgta cttgctcgtg gtgtttccg 1189
<210> 3
<211> 4131
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 3
atggacaaga agtactcgat tggcctcgat atcggcacca acagcgtcgg ttgggcggtg 60
atcacggacg agtacaaggt ccccagcaag aagttcaagg tcctcggcaa tacggatcgc 120
cattcgatta agaaaaacct tatcggcgcc ctcctctttg atagcggcga gacggccgag 180
gcgacccgcc tcaaacgcac cgcccgccgt cgctacaccc gtcgtaagaa ccgcatctgc 240
tacctccaag agatcttttc gaatgagatg gccaaggtgg acgactcgtt tttccaccgc 300
cttgaggagt cgttcctcgt cgaggaggat aagaagcacg agcgccatcc gattttcggt 360
aatatcgtcg acgaggtggc gtaccacgag aaatatccca ccatctacca cctccgcaag 420
aaactcgtgg actcgacgga caaggcggac ctccgcctca tctacctcgc gctcgcccac 480
atgattaaat tccgcggcca tttcctcatc gagggcgatc ttaaccccga caacagcgac 540
gtggacaagc tcttcatcca gctcgtccag acgtacaacc aactctttga ggagaacccc 600
attaatgcct cgggcgtgga tgcgaaggcc atcctttcgg cgcgtctcag caagagccgc 660
cgcctcgaaa atcttatcgc ccagctcccc ggtgagaaaa agaacggtct cttcggcaac 720
cttattgcgc tttcgcttgg cctcaccccc aacttcaaat cgaatttcga cctcgcggag 780
gacgccaagc tccagctctc gaaggacacg tacgatgatg acctcgacaa ccttctcgcc 840
cagatcggtg accagtacgc cgacctcttc ctcgcggcca aaaaccttag cgacgccatc 900
ctcctttcgg acattctccg cgtcaacacc gaaattacga aggccccgct ctcggccagc 960
atgatcaaac gctacgacga gcatcaccaa gatcttacgc ttctcaaagc cctcgtccgt 1020
caacagctcc cggagaagta caaggagatc ttcttcgacc aatcgaagaa cggttacgcc 1080
ggctatatcg atggcggcgc ctcgcaagaa gagttctaca agttcatcaa gcccatcctc 1140
gaaaagatgg acggtacgga ggagctcctc gtcaagctca accgcgaaga ccttctccgt 1200
aagcaacgca cgtttgataa cggcagcatc ccgcaccaga tccaccttgg cgagcttcat 1260
gccattcttc gtcgtcaaga agacttttat ccctttctca aggacaaccg cgagaagatt 1320
gagaagattc tcaccttccg catcccctac tacgtgggtc cccttgcccg cggcaattcg 1380
cgcttcgcgt ggatgacccg caagagcgag gagaccatca cgccttggaa ctttgaggaa 1440
gtcgtggaca agggcgcgtc ggcccagagc ttcattgagc gtatgacgaa cttcgacaag 1500
aacctcccca atgagaaggt cctccccaag cattcgctcc tctacgagta tttcacggtc 1560
tacaatgaac tcaccaaggt caaatacgtc accgagggca tgcgtaagcc cgcctttctt 1620
tcgggcgaac agaaaaaggc catcgtcgac ctccttttca agacgaaccg taaggtcacg 1680
gtcaagcaac tcaaagagga ttatttcaag aagatcgagt gcttcgactc ggtcgagatt 1740
tcgggcgtgg aagaccgttt taacgcctcg cttggtacct atcacgacct tctcaagatc 1800
attaaggata aggacttcct cgacaacgag gagaatgagg acatccttga ggacatcgtc 1860
cttacgctta cccttttcga agaccgtgag atgattgagg agcgcctcaa aacctacgcc 1920
cacctcttcg acgataaggt catgaaacaa ttaaaacgtc gccgttatac gggttggggc 1980
cgcctctcgc gcaagctcat caacggcatc cgtgacaagc aaagcggcaa gaccattctc 2040
gacttcctca agtcggacgg ctttgccaat cgtaacttca tgcagctcat ccacgacgat 2100
tcgctcacgt tcaaggagga tattcagaaa gcccaagtct cgggccaagg tgatagcctt 2160
cacgagcata ttgccaacct cgcgggttcg cccgccatta agaagggtat ccttcagacg 2220
gtcaaggtgg tggacgagct cgtcaaggtc atgggtcgtc acaagcccga gaacatcgtc 2280
atcgaaatgg cgcgtgagaa tcagaccacc cagaagggcc aaaaaaattc gcgtgagcgt 2340
atgaaacgca ttgaggaggg tatcaaggag ctcggctcgc agatcctcaa ggaacacccg 2400
gtggagaaca cgcaactcca gaatgagaag ctctaccttt actacctcca gaatggccgt 2460
gatatgtacg tggatcaaga gctcgatatc aaccgcctca gcgactacga tgtggaccac 2520
atcgtcccgc agagctttct taaggatgat agcatcgaca acaaggtcct tacccgtagc 2580
gacaagaacc gtggtaagtc ggacaacgtc ccgtcggagg aggttgtgaa gaaaatgaag 2640
aactactggc gccagctcct taacgcgaaa cttatcaccc agcgcaagtt cgataacctt 2700
accaaggcgg agcgcggcgg tctctcggaa cttgacaagg cgggcttcat caaacgccag 2760
ctcgtcgaaa cgcgccagat cacgaagcac gtggcgcaaa tcctcgacag ccgcatgaac 2820
accaaatatg atgaaaacga caaacttatt cgcgaagtga aggtgatcac gctcaaatcg 2880
aagctcgtgt cggacttccg caaggacttc cagttctaca aggtgcgcga gatcaataac 2940
taccaccatg cgcacgacgc ctacctcaac gcggtcgtcg gtacggccct tattaagaag 3000
tacccgaaac tcgaatcgga gtttgtgtac ggtgactaca aggtgtacga tgtgcgcaag 3060
atgatcgcca agagcgagca agaaatcggc aaggcgacgg cgaagtactt cttttactcg 3120
aacatcatga acttcttcaa gacggaaatt acgcttgcga acggcgagat ccgcaaacgt 3180
ccccttattg agacgaacgg tgagacgggt gaaatcgtgt gggacaaagg tcgcgacttt 3240
gccaccgtgc gcaaggtcct ctcgatgccg caagttaaca tcgtgaaaaa aaccgaggtc 3300
caaaccggtg gtttcagcaa agagagcatc cttcccaagc gtaactcgga caaacttatc 3360
gcccgcaaga aggattggga tcccaagaag tacggcggct ttgatagccc gaccgtggcc 3420
tattcggtcc tcgtcgtggc caaggtcgaa aagggcaagt cgaagaaact taaaagcgtc 3480
aaggaactcc tcggcattac gatcatggag cgtagcagct tcgaaaaaaa ccccatcgac 3540
tttctcgagg cgaagggtta caaagaagtg aaaaaggatc tcattattaa gctcccgaag 3600
tacagcctct ttgagctcga gaacggccgt aagcgtatgc tcgccagcgc cggcgaactt 3660
cagaagggca acgagcttgc cctcccgtcg aaatacgtca acttcctcta cctcgccagc 3720
cactacgaaa agctcaaagg ttcgcccgag gataacgagc agaaacagct ctttgtcgag 3780
cagcataaac actacctcga tgagattatt gagcaaattt cggagttttc gaagcgcgtg 3840
atcctcgcgg acgcgaacct cgacaaagtc ctctcggcct acaataagca ccgcgataaa 3900
ccgattcgcg aacaagccga aaacatcatc catctcttca cgctcacgaa cctcggcgcc 3960
ccggccgcgt ttaaatactt tgataccacc attgaccgca agcgctatac gagcaccaag 4020
gaggtcctcg atgccacgct tatccaccag agcattacgg gcctttacga gacgcgcatc 4080
gatcttagcc aactcggtgg cgacggttcg ccgaagaaaa aacgtaaagt c 4131
<210> 4
<211> 120
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 4
atggccggcg gatccaaggg cgtgagcaag aaggcagcca aggccaccaa ggcctcgggc 60
gacaagtcga agaagcgctc gaagcgcacg gagacctact cctcgtacat ttacaaggtg 120
<210> 5
<211> 300
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 5
tgacgtcgat tttattggca gtcacaagac gatcacgctc agcacggggc cttacacgcc 60
ctttacgcac tggcaccaat gccgcatgct cctccccgag cccattgccg tgaacaaggg 120
tcagacagtg gagggaacga tccacatggt tgccaacgag aagttttcct acacgatcaa 180
tctcgaggtt gcactcaagg gcaccgacgt gaagtcgtcc aacgtcattc ttttgcagga 240
gcaattctac cactatcttc agggctcgcc gtctttctct gccgagtgaa cgcagctgga 300
<210> 6
<211> 80
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 6
gttttagagc tagaaatagc aagttaaaat aaggctagtc cgttatcaac ttgaaaaagt 60
ggcaccgagt cggtgctttt 80
<210> 7
<211> 51
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 7
ttttggtcat gcatgagatc agatctgttt acaccacaat atatcctgcc a 51
<210> 8
<211> 38
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 8
gtacttcttg tccatcttgg ccttgtcttg tttcctgc 38
<210> 9
<211> 37
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 9
agacaaggcc aagatggaca agaagtactc gattggc 37
<210> 10
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 10
caccttgtaa atgtacgagg agtag 25
<210> 11
<211> 32
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 11
acaaggtgat ggacaagaag tactcgattg gc 32
<210> 12
<211> 41
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 12
cccttggaga ccatgacttt acgttttttc ttcggcgaac c 41
<210> 13
<211> 33
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 13
aaaaacgtaa agtcatggtc tccaagggcg agg 33
<210> 14
<211> 51
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 14
ataagcttga tatcgaattc tgacaggata tattggcggg taaaccggaa a 51
<210> 15
<211> 45
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 15
agctccaccg cggtggcggc cgctgacgtc gattttattg gcagt 45
<210> 16
<211> 44
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 16
ctgcgtgggc gagagtgggt aactcttact tatatagtat aagc 44
<210> 17
<211> 32
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 17
ttacccactc tcgcccacgc agaccagcga gt 32
<210> 18
<211> 46
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 18
tccactagtt ctagagcggc cgcaaaaaaa gcaccgactc ggtgcc 46
<210> 19
<211> 45
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 19
agctccaccg cggtggcggc cgctgacgtc gattttattg gcagt 45
<210> 20
<211> 44
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 20
ctgcgtgggc gagagtgggt aactcttact tatatagtat aagc 44
<210> 21
<211> 32
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 21
ttacccactc tcgcccacgc agaccagcga gt 32
<210> 22
<211> 46
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 22
tccactagtt ctagagcggc cgcaaaaaaa gcaccgactc ggtgcc 46
<210> 23
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 23
atcctctgca gcggagtcga ga 22
<210> 24
<211> 22
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 24
ttcggcttgt acgcggcggc ca 22
<210> 25
<211> 40
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 25
ttagtccgac ttggccttgg ttacttgtag agctcgtcca 40
<210> 26
<211> 35
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 26
ggtttgaatt ctcggtacca ccgcgtaata cgact 35
<210> 27
<211> 31
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 27
gctttagatc ttctcatctt ggtcatcttg c 31
<210> 28
<211> 40
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 28
tcctcgccct tggagaccat cttttcacga gctgttgtgg 40
<210> 29
<211> 34
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 29
gctttagatc tgctcgagac cgagctctcc tcct 34
<210> 30
<211> 34
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 30
gcccttggag accatcttcg gttcttctcg ctgc 34
<210> 31
<211> 34
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 31
ggtttagatc tatgtccagt ggaggcagag agcc 34
<210> 32
<211> 37
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 32
cccttggaga ccatcttggc cttgtcttgt ttcctgc 37
<210> 33
<211> 800
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 33
tttgtttctt acatcaattc attcgttcgc tcacgcactc cttctttatt actattagaa 60
ggcgcgcaca cccgcacacc cacactctct ccccacaccc gccccagcgc gcgcgcaaag 120
agctagagtg aagaagggag agggggggca gagagagaga aagaaaccaa agaaaaagaa 180
ggaaagaaag aaagaaagaa agaaagaaag aaagaaagaa aacaaaacaa aggatggtaa 240
aagaagtccc ctccactcta ctccactcca ctcctctcca ctccactcca ctccactcct 300
ctccactcct cgccactcag ctgctctcca gtccgctcga cgctgcgctc tctccagtct 360
cgggtctcgc cgtgtccgca ggcgcacgcg gcgcagcacg cggctctgtg cgcggccccg 420
tcttctctgg cgccgcccgc agggaggctc cctctgctcc gcaggaaggg aggaaggtgc 480
tcgcgcggcc cgcgctctct cctctctcct ttcctctctg tgtctgctgc tcgcttgggt 540
gaactttttt ttaaactttg ttacctttgc acccatttcc cgctcgcctc ggctgtttct 600
cgcctccggg gccagagaga gaggcggcct ctgcacgcag caaacaccat tcgagggcca 660
gcaggcagtc ccgtgcagaa cgagaccggc cgtgctttcg ccttgctttg cgttgccagg 720
aacagcagca gcagcagcaa gagcaagagc aagagcaacg gcagcaggtt taccttcgga 780
ggaccagaac cagagaaacc 800
<210> 34
<211> 800
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 34
tctcatcttg gtcatcttgc gcgtctcgtc tcatctcatc tcgtcccagc ccgtcgtggc 60
cgtcctgctc gccgcgtctc gctcgacgct ggccggcggg gcgcgagaaa cgcccggctg 120
cgcgtccgcc cgtgcgtccg tcggccgcgg tccgagccgg ggcggggtcg cacgcactcg 180
aggtgacgga gcagcggaga agagaggcag tcccggccaa gattccgcag cttgcaagcg 240
gctgcggagt cgaacgacgg caagcgggag gaagttcaag ttggacgggg aagaaaaagc 300
tcctaagctg acctgcgggc tgccaagacg gccgagcttg aagccttgat ggtctgggga 360
cggcgagcga gatccaggct gggccggcca aggacgaact cgacgccgtc ctggccttgt 420
tgctgctgct gatgatggat gaatgacgga tgatggatga tggatgatgc tgggcttgag 480
cgtcgcgttg aagaaggacg acttcaggaa tggtgctttt cgaggtcttg gccgcgagcg 540
tggcgggggg cacaagaaac gactcctggc gggacgagat gatctgcttt gcgtcctggc 600
aggctcacgg gacacggagt cggcgtatcg gatagtagac tgactggcag acaggtcgag 660
gaaggatcac aaagaaagat tccacacgca gatctggaga gcagaaccgc aacgctgagc 720
tgaaagatcg cgaccctacg aggcggaagc aggaccagca caagaggcga agaagcttta 780
ccacaacagc tcgtgaaaag 800
<210> 35
<211> 812
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 35
tcggtacccg ttagaacgcg taatacgact cactataggg agagtcgact gagcacaact 60
ctgctgcgag cgggcctcga gagcgtttgc ttcgagccgc ggagcaaggg ggatggatcg 120
ctcatgcggt cgtgcggccc tcggtcaccc ggtgggtcct gcactgacgc atctgttctg 180
atcagacaca cgaacgaaca aaccgaggag ccgcagcgcc tggtgcaccc gccgggcgtt 240
gttgtgtgct cttcttgcct ccgagagaga gagcggagcg gatgcatagg aaatcgggcc 300
acgcgggagg gccatgcgtt cgccccacac gccactttcc acgcccgctc tctctccggc 360
cggcaggcag cgcataactc tccgacgctg gcaggctggt agcaactggc agggacaact 420
cgcgcgcggg tcccggtcgt tcgatgtgcc aacccgagag aatccagcca gcagggcggt 480
tggcctcatc gcccacctgc tatggtgcag cgaaccaact cccgaagcgg ccggttctgc 540
gattccctct tctgaattct gaattctgaa ctgattccgg aggagaaccc tctggaagcg 600
cgggttgcct ctccagttct gccgaactag acaggggagt gagcagagag tgaccctgac 660
gcggagcgag ctggttgctg gaaaagtcgc gaacgctggg ctgtgtcacg cgtccacttc 720
gggcagaccc caaacgacaa gcagaacaag caacaccagc agcagcaagc gacctaagca 780
acactagcca acatgactga ggataagacg aa 812
<210> 36
<211> 500
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 36
gaagaggggg taagcgagtc tgaacaagga gaagcggaag ttgacattga ggtcggcgag 60
aaccagccta aacaagatgg ctcgaagggt gatcagccgc aggggactgt ccttgcatcg 120
acttcctccg gtactcaagc ttcttcatac aagggtgacg atctcggcat tgacagttcg 180
gtttgcgagg aagacgccgt atccacttca caaacttcgc acctctcgca aaagcgccga 240
gcatcgagtg gcagacttcg cccgatgcgc aactccatcg catcttcgta atttacacgg 300
ggcttgtgtg accctatttc ggacaaaaga ttgcttcaca cgcttccatc tctttttttc 360
cattcacatt tatactatga cccaataagt tactcgtttt gttttgttgg ctcgtctttc 420
tttatgcggc tgtttcgctt cggcagcaca attgcctttt gataccgccg caatcgtgtc 480
acatcagtct aatttctgat 500
- 一种裂殖壶菌CRISPR/Cas9基因编辑系统及其应用
- 一种应用于黑水虻的CRISPR/Cas9基因编辑系统的标记基因