基于复空间角中心高斯混合聚类模型和双向长短时记忆网络的波束成形语音分离方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于阵列麦克风语音分离领域,尤其涉及基于复空间角中心高斯混合聚类模型和双向长短时记忆网络的波束成形语音分离方法。
背景技术
“鸡尾酒会问题”是一个具有数十年历史的经典问题,近年来基于学习的方法获得了远超传统方法的突出结果。根据语音数字信号的硬件采集设备的不同,语音分离分为单通道语音分离和多通道语音分离,前者主要依赖于单通道语音本身的时频域特征,而后者更多地考虑各通道语音的空间关系。
机器学习的方法在语音分离中一直受到广泛应用,包括自适应波束形成器的设计、聚类方法等。前者如波束形成器设计中的广义旁瓣抵消算法自适应更新干扰抵消器、自适应的广义特征值分解波束形成器等,后者如基于复高斯混合模型、复沃特森混合模型等混合模型,可使用期望最大化等迭代算法对掩蔽值进行无监督估计。
神经网络是一种近年来十分活跃且效果优异的统计学习方法。大量的神经网络结构,如卷积神经网络、循环神经网络、注意力网络等已经应用于语音分离领域。但语音分离这一研究领域依然需要开展大量、深入的研究工作,传统语音分离算法在高混响、低信噪比的环境下性能下降严重。
发明内容
本发明目的在于提供一种基于复空间角中心高斯混合聚类模型和双向长短时记忆网络的波束成形语音分离方法,针对在噪声、混响干扰环境,在波束形成器的基本框架下,结合麦克风阵列信号的时频域及空间信息,以解决多通道语音的说话人无关语音分离的技术问题。
为解决上述技术问题,本发明的具体技术方案如下:
一种基于复空间角中心高斯混合聚类模型和双向长短时记忆网络的波束成形语音分离方法,该方法包括以下步骤:
步骤1、包含噪声和混响的多通道训练语音信号,通过分帧、加窗、短时傅里叶变换、取对数运算和去混响预处理后,计算参考通道训练语音信号的对数功率谱、参考通道训练语音信号与其余通道训练语音信号之间相位差的正弦与余弦值;
步骤2、利用步骤1计算的参考通道训练语音信号的对数功率谱,基于期望最大化迭代算法,得到训练语音信号基于复空间角中心高斯混合聚类模型参数,估计各目标声源在参考通道训练语音信号中的掩蔽值;
步骤3、将步骤1计算的参考通道训练语音信号的对数功率谱、参考通道训练语音信号与其余通道训练语音信号之间相位差的正弦与余弦值,作为双向长短时记忆网络的输入特征,将步骤2中各目标声源在参考通道训练语音信号的掩蔽值作为双向长短时记忆网络的训练目标,基于均方误差损失函数训练双向长短时记忆网络;
步骤4、包含噪声和混响的多通道测试语音信号,通过分帧、加窗、短时傅里叶变换、取对数运算和去混响预处理后,计算参考通道测试语音信号的对数功率谱、参考通道测试语音信号与其余通道测试语音信号之间相位差的正弦与余弦值,同时短时傅里叶变换得到多通道测试语音信号的相位谱;
步骤5、将步骤4中参考通道测试语音信号的对数功率谱、参考通道测试语音信号与其余通道测试语音信号之间相位差的正弦与余弦值,作为步骤3训练得到的双向长短时记忆网络的输入特征,输出各目标声源在参考通道测试语音信号中的掩蔽值;
步骤6、根据步骤5中双向长短时记忆网络输出的掩蔽值,以及步骤4的多通道测试语音信号,计算多通道测试语音信号的协方差矩阵,基于给定目标声源在波束形成器输出处的预期信噪比增益最大化准则,得到各目标声源的波束成形器系数;波束成形器与多通道测试语音信号卷积后,结合步骤4中多通道测试语音数据的相位谱,得到分离后的目标语音信号频谱,经过短时傅里叶逆变换,得到目标语音信号的时域波形。
进一步的,步骤1和步骤4中的去混响预处理采用了带权重预测误差去混响预处理;多通道数据通过分帧、加窗、短时傅里叶变换、取对数运算后,基于带权重预测误差去混响算法,得到纯净语音的最大似然估计,去除信号中的混响成分。
进一步的,步骤2中基于复空间角中心高斯混合聚类模型对训练语音信号进行建模,计算参考通道训练语音信号中各目标声源信号的掩蔽值;复空间角中心高斯混合模型的概率密度函数表示式为:
其中,
其中,det()为矩阵的行列式运算,M为通道数目,!表示阶乘运算,H表示转置运算。
进一步的,步骤3中将基于复空间角中心高斯混合聚类模型计算的掩蔽值和双向长短时记忆网络输出的掩蔽估计值之间的均方误差作为损失函数
其中,
进一步的,步骤6中基于给定目标声源在波束形成器输出处的预期信噪比增益最大化为准则,得到每个声源的波束成形系数具体包括以下步骤:
在计算某个目标声源i时,将其它声源视为噪声,对于每一个时频点,使用时域平均代替统计平均,得到目标声源i的协方差矩阵
其中,T
广义特征值分解波束形成器,使得给定目标声源在波束形成器输出处的预期信噪比增益最大化,进而得到目标声源i的波束成形器系数
根据第i个目标声源的波束成形器系数
其中,H表示转置运算。
本发明的基于复空间角中心高斯混合聚类模型和双向长短时记忆网络的波束成形语音分离方法,具有以下优点:
本发明将研究方向集中在波束形成上,并将掩蔽值、神经网络等已被证明具有优良效果的方法融入到波束形成算法中,从而一方面能够保证算法具有波束形成器普遍具有的短时不变、稳定迭代的特性,对语音有较为稳定的处理效果,避免神经网络的时变输出影响到语音的连续性;另一方面也使得波束形成器设计能利用神经网络等算法的优势,学习到大量数据中的信息,从而改进其参数估计及迭代策略,拥有更好的分离效果。在不同声学环境下的仿真测试表明,本发明算法性能优于传统波束成形算法,在语音分离中显著提高了尺度不变信噪比和短时语音可懂度。
附图说明
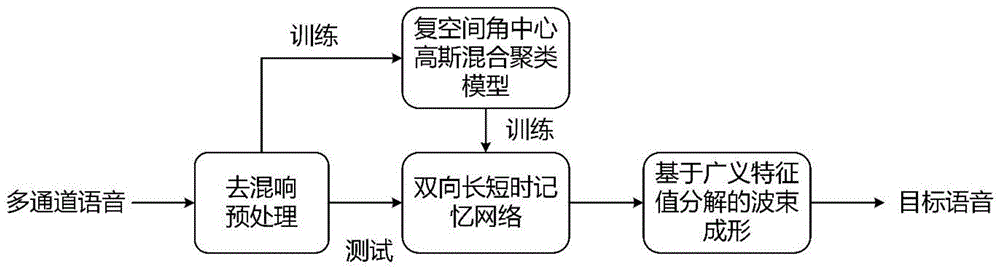
图1为本发明多通道分离系统整体算法流程图;
图2为本发明利用期望最大化迭代算法估计掩蔽值流程图。
具体实施方式
为了更好地了解本发明的目的、结构及功能,下面结合附图,对本发明一种基于复空间角中心高斯混合聚类模型和双向长短时记忆网络的波束成形语音分离方法做进一步详细的描述。
如图1所示,复空间角中心高斯混合聚类模型和双向长短时记忆网络语音分离方法包括以下步骤:
步骤一、本发明的声源信号是在TIMIT语音库中随机抽选语音信号,其中包括男声女声,包括各种不同的句子,针对每个声源位置对,随机选出5种不同的语音对,每对语音的功率差随机设置在0dB到3dB间,生成带有混响的混合语音,混响有0ms(无混响)、200ms、500ms这3种配置。本发明还从RIRS_NOISES噪声库中随机选取噪声以特定信噪比添加到混合语音中,包括街头、鸣笛等多种真实场景的噪声。
多通道训练语音信号通过分帧、加窗、短时傅里叶变换、取对数运算和去混响预处理后,计算参考通道训练语音信号的对数功率谱、参考通道训练语音信号与其余通道训练语音信号之间相位差的正弦与余弦值。
第m通道语音信号进行短时傅里叶变换得到第t帧、第f频点上的频谱
其中,x
设参考通道为第1个通道,该参考通道语音信号对数功率谱的计算如下:
其中,
计算参考通道语音信号与其余通道语音信号之间的相位差,并计算相位差的正弦和余弦值,参考通道和第j个通道语音信号相位差IPD
cosIPD
sinIPD
其中,
步骤二、基于步骤一计算得到的对数功率谱和期望最大化迭代算法,得到训练语音信号基于复空间角中心高斯混合聚类模型的参数,估计各目标声源在参考通道训练语音信号中的掩蔽值
第k个声源的复空间角中心高斯混合聚类模型参数
首先对模型参数
其中
L(Θ
其中,
第i个声源在参考通道训练语音信号第t帧、第f频点上的掩蔽估计值
其中,k表示所有声源序号,取值范围为[1,K],K为声源数目。
步骤三将步骤一计算的参考通道训练语音信号对数功率谱、参考通道训练语音信号与其余通道训练语音信号之间相位差的正弦和余弦值,作为双向长短时记忆网络的输入特征,本发明利用双向长短时记忆网络将上述特征映射为各目标声源的掩蔽值。将步骤二基于复空间角中心高斯混合聚类模型计算的掩蔽值和双向长短时记忆网络输出的掩蔽估计值之间的均方误差作为损失函数
其中,
步骤四多通道测试语音信号,分别通过分帧、加窗、短时傅里叶变换、取对数运算和去混响预处理后,计算参考通道测试语音信号的对数功率谱、参考通道测试语音与其余通道测试语音之间相位差的正弦与余弦值,同时短时傅里叶变换得到多通道测试语音信号相位谱;
步骤五将步骤四参考通道测试语音信号的对数功率谱、参考通道测试语音与其余通道测试语音之间相位差的正弦与余弦值,作为步骤三中训练得到的双向长短时记忆网络的输入特征,输出各目标声源在参考通道测试语音信号中的掩蔽估计值;
步骤六根据步骤五中双向长短时记忆网络输出的掩蔽估计值,以及步骤四的多通道测试语音信号,计算多通道测试语音信号的协方差矩阵。基于给定目标声源在波束形成器输出处的预期信噪比增益最大化为准则,得到每个声源的波束成形系数。
在计算某个目标声源i时,将其它声源视为噪声,对于每一个时频点,使用时域平均代替统计平均,得到目标声源i的协方差矩阵
其中,T
广义特征值分解波束形成器,使得给定目标声源在波束形成器输出处的预期信噪比增益最大化,进而得到目标声源i的波束成形器系数
根据第i个目标声源的波束成形器系数
其中,H表示转置运算。
性能评估:
使用尺度不变的信噪比SI-SNRi(Scale-Invariant Source-to-Noise Ratioimprovement)衡量语音分离质量,使用短时语音可懂度STOI(Short-Time ObjectiveIntelligibility)指标评价语音可懂度,STOI取值区间在[0,1],STOI越高,语音的可懂度越好。将本发明基于复空间角中心高斯混合聚类模型和双向长短时记忆网络的语音分离方法,与基于传统波束形成和双向长短时记忆网络的多通道语音分离算法MVDR-BLSTM、基于掩蔽值和长短时记忆网络的多通道语音分离算法BLSTM-IRM,进行性能比较,结果如下。
表一给出了是本发明的算法和BLSTM-IRM、MVDR-BLSTM两类对比算法的SI-SNRi比较结果,表格中SNR为信噪比,T
表一多环境下不同算法的SI-SNRi值比较
表二给出的是本发明的算法和BLSTM-IRM、MVDR-BLSTM两类对比算法的STOI比较结果在测试数据集上的具体评价指标的比较。
表二多环境下不同算法的STOI值比较
可以理解,本发明是通过一些实施例进行描述的,本领域技术人员知悉的,在不脱离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。另外,在本发明的教导下,可以对这些特征和实施例进行修改以适应具体的情况及材料而不会脱离本发明的精神和范围。因此,本发明不受此处所公开的具体实施例的限制,所有落入本申请的权利要求范围内的实施例都属于本发明所保护的范围内。