一种基于深度压缩感知的语音去噪方法及设备
文献发布时间:2023-06-19 18:46:07
技术领域
本发明属于语音去噪技术领域,特别涉及一种基于深度压缩感知的语音去噪方法。
背景技术
语音是人类特有的功能,也是人类获取外界信息的重要工具,也是人与人交流必不可少的重要手段。语音去噪又被称为语音增强,主要是针对于有人声的音频进行处理,目的是去除那些背景噪声,增强音频中人声的可懂性。传统的语音去噪方法主要为谱减法和维纳滤波法,能够去除一些简单的噪声,但是对非线性噪声处理效果不好,所以引入深度学习来进行语音去噪,经过深度学习能够很好的解决非线性问题,
发明内容
本发明的目的在于提供一种基于深度压缩感知的语音去噪方法及设备,能够利用压缩感知和深度学习去除非线性噪声,并且可以通过压缩感知将信号进行降维,加快去噪速度;
为达到上述目的,本发明采用的技术方案是:
一种基于深度压缩感知的语音去噪方法,包括以下步骤:
信号预处理:对纯净语音信号X加入高斯白噪声,得到带噪语音信号,对纯净语音信号X和带噪语音信号进行时长规整和分帧处理,之后对纯净语音信号X进行端点检测处理;
信号压缩:采用压缩感知方法,对预处理后的纯净语音信号X和带噪语音信号进行感知特征提取,得到纯净语音的感知特征Y
模型训练:采用深度学习模型的生成对抗网络作为去噪模型,将带噪语音的感知特征Y
信号重构:采用压缩感知的OMP重构算法,对生成纯净语音的感知特征Y′进行信号重构,得到生成纯净语音信号X′,
其中,所述信号重构过程中,先将生成纯净语音的感知特征Y′进行分帧处理,按每帧进行重构信号,然后对重构的每帧信号进行拼接,得到生成纯净语音信号X′。
优选的,所述语音时长规整包括以下步骤:
将纯净语音信号X和带噪语音信号的长度设置为信号帧长的整数倍。
优选的,所述端点检测包括以下步骤:
采用短时能量和过零率的双门限两级判别方法对纯净语音信号X进行端点检测,对纯净语音信号X的有语音段和无语音段进行区分。
优选的,所述感知特征提取包括以下步骤:
将N×1维的纯净语音信号X在M×N维的随机高斯矩阵Φ上进行感知测量,使Y
带噪语音信号感知特征提取选用高斯随机矩阵与纯净语音信号X感知特征提取所用高斯矩阵Φ相同,且带噪语音信号的维数与纯净语音信号X的维数N相同,带噪语音信号通过感知特征提取,得到带噪语音的感知特征Y
优选的,所述感知特征提取还包括以下步骤:
先对纯净语音信号X和带噪语音信号的每帧信号进行感知特征提取,再将每帧感知特征进行拼接,最终得到纯净语音信号的感知特征Y
优选的,所述生成对抗网络包括生成网络G和鉴别网络D,生成网络G用于对带噪语音的感知特征Y
优选的,所述训练生成对抗网络包括以下步骤:
将带噪语音的感知特征Y
优选的,所述信号重构包括以下步骤:
选用DCT矩阵Ψ为稀疏表示矩阵,得到传感矩阵A=ΦΨ,根据Y′=A×theta和Y′=Ψ×theta,利用最小二乘法解出theta,然后重构出生成纯净语音信号X′。
根据本发明的另一方面,还提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时执行一种基于深度压缩感知的语音去噪方法中的步骤。
根据本发明的另一方面,还提供一种基于深度压缩感知的语音去噪设备包括:
存储器,用于存储软件应用程序,
处理器,用于执行所述软件应用程序,所述软件应用程序的各程序相对应地执行一种基于深度压缩感知的语音去噪方法中的步骤。
本发明的有益效果:
1、本发明采用的深度压缩感知方法,更适用于非线性噪声分析与处理,通过该方法,提高了生成纯净语音信号X′的去噪效果。
2、本发明采用的端点检测方法将无声段和有声段区分,结合深度学习无声段去噪过程,将其利用到有声段,达到有声段语音去噪,且在生成对抗网络中鉴别网络只需鉴别无声段去噪效果即可。
3、本发明采用压缩感知的方法,通过将信号压缩再进行去噪,可降低数据维数,也就是N×1维大小的数据压缩为M×1维的数据,其中N>>M,提高算法运行效率。
附图说明
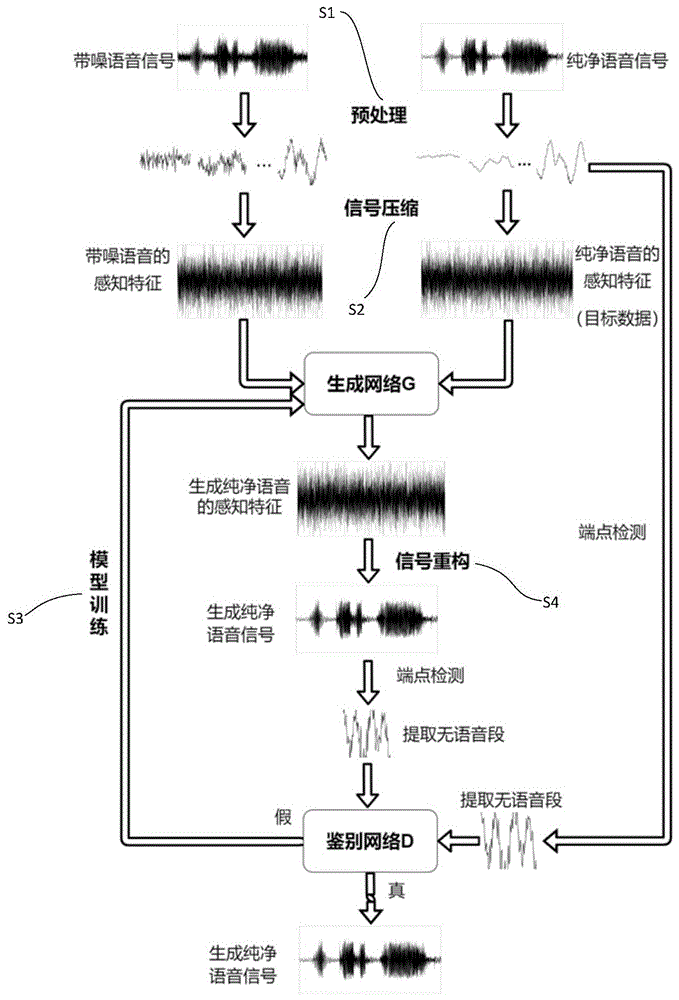
图1为本发明流程结构示意图。
具体实施方式
以下结合附图和具体实施例,对本发明做进一步说明。
如图1所示,本发明一种基于深度压缩感知的语音去噪方法,包括以下步骤:
S1、信号预处理:对纯净语音信号X加入高斯白噪声,得到带噪语音信号,对纯净语音信号X和带噪语音信号进行时长规整、分帧处理,之后对纯净语音信号X进行端点检测处理;
其中,对纯净语音信号X和带噪语音信号进行分帧,帧长可以设置为128,同时将语音信号的时长规整为帧长128的整数倍,
S2、信号压缩:采用压缩感知方法,对预处理后的纯净语音信号X和带噪语音信号进行感知特征提取,得到纯净语音的感知特征Y
S3、模型训练:采用深度学习模型的生成对抗网络作为去噪模型,将带噪语音的感知特征Y
S4、信号重构:采用压缩感知的OMP重构算法,对生成纯净语音的感知特征Y′进行信号重构,得到生成纯净语音信号X′,
其中,所述信号重构过程中,先将生成纯净语音的感知特征Y′进行分帧处理,按每帧进行重构信号,然后对重构的每帧信号进行拼接,得到生成纯净语音信号X′;
具体的,步骤S1中,所述端点检测包括以下步骤:
S11、采用短时能量和过零率的双门限两级判别方法对纯净语音信号X进行端点检测,对纯净语音信号X的有语音段和无语音段进行区分,
其中,短时能量判别方法是通过设置一个较高的平均能量门限值T
具体的,步骤S2中,所述感知特征提取包括以下步骤:
S21、将N×1维的纯净语音信号X在M×N维的随机高斯矩阵Φ上进行感知测量,使Y
带噪语音信号感知特征提取选用高斯随机矩阵与纯净语音信号X感知特征提取所用高斯矩阵Φ相同,且带噪语音信号的维数与纯净语音信号X的维数相同,带噪语音信号通过感知特征提取,得到带噪语音的感知特征Y
其中,感知特征提取是根据压缩感知理论的压缩采样原理;
纯净语音的感知特征Y
其中,将信号帧长设置为128,将128×1维的信号在M×128维的高斯随机矩阵上进行感知特征提取,得到M×1维的感知特征,其中128×1维的信号为纯净语音信号X或带噪语音信号,由于M<<128,即将128×1维的信号压缩为M×1维的的感知特征,
具体的,步骤S2中,所述感知特征提取还包括以下步骤:
S22、先对纯净语音信号X和带噪语音信号的每帧信号进行感知特征提取,再将每帧感知特征进行拼接,最终得到纯净语音信号的感知特征Y
其中,对纯净语音信号X和带噪语音信号感知特征提取,是对纯净语音信号X和带噪语音信号分帧后的每一帧进观测,将得到的若干感知特征进行拼接,最终得到纯净语音信号的感知特征Y
具体的,步骤S3中,所述生成对抗网络包括生成网络G和鉴别网络D,生成网络G用于对带噪语音的感知特征Y
其中,生成对抗网络的训练过程具体为生成对抗网络中的两个网络交替训练,能力同步提高,直到生成网络生成的数据能够以假乱真,并且鉴别网络D的能力达到纳什均衡。
具体的,步骤S3中,所述训练生成对抗网络包括以下步骤:
S31、将带噪语音的感知特征Y
其中,通过更改感知特征提取时所用高斯随机矩阵可得到多个不同高斯矩阵下生成对抗网络模型,即每次进行信号压缩使用不同的高斯随机矩阵都会对应一种相应的生成对抗网络模型,使用不同生成对抗网络模型便于得到不同的去噪效果,通过挑选得到最好去噪效果的生成对抗网络模型。
其中,OMP重构算法是以贪婪迭代的方式选择测量矩阵Φ的列,使得在每次迭代中所选择的列与当前的冗余向量最大程度地相关,从测量向量中减去相关部分并反复迭代,直到迭代次数达到稀疏度K,强制迭代停止。
具体的,步骤S4中,所述信号重构包括以下步骤:
S41、选用DCT矩阵Ψ为稀疏表示矩阵,得到传感矩阵A=ΦΨ,根据Y′=A×theta和Y′=Ψ×theta,利用最小二乘法解出theta,然后重构出生成纯净语音信号X′。
本发明的另一方面,还提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时本发明方法中的步骤。
本发明的另一方面,还提供一种基于深度压缩感知的语音去噪设备,包括:存储器,用于存储软件应用程序,处理器,用于执行所述软件应用程序,所述软件应用程序的各程序相对应地执行本发明的一种基于深度压缩感知的语音去噪方法中的步骤。