新发突变的标签标注方法、装置、存储介质及服务器
文献发布时间:2023-06-19 18:46:07
技术领域
本申请涉及新发突变检测领域,具体而言,涉及一种新发突变的标签标注方法、装置、存储介质及服务器。
背景技术
在人类遗传学领域,之前主要关注遗传性疾病,这是因为传统的疾病识别方法主要依赖于在具有多个受影响的家庭成员的家系中,定位相关的基因位置,然后再利用Sanger测序来识别候选基因中的致病突变。随着测序技术的不断进步,大量的研究都利用WES(Who l e Exome Sequenc i ng)或WGS(Who l e Genome Sequenc i ng)来鉴定相关疾病突变,因为此技术可以检测绝大多数的遗传变异。虽然Sanger测序仍然是鉴定新发突变的金标准,但是随着测序数据的不断增大,例如在一项涉及9000位人员的WGS研究中,想利用Sanger测序鉴定所有的新发突变并研究其功能显然是不太现实的,这就要求研究人员开发出一款可以在高通量测序数据中相对准确地检测新发突变的工具来进行下游的分析,如此一来,许多的新发突变检测工具由此诞生。
Kobo l dt等开发了VarScan,用于在大规模并行测序中检测SNP和I nde l,并且评估它们的突变频率,同时VarScan还可以与多个比对器兼容(BLAT, Newb l er,cross_match,Bowt i e and Novoa l i gn)。对于单个样品,它可以基于读段的个数,碱基质量和等位基因频率实现对种系突变的鉴定和过滤。还可以通过比较两者的读段个数,通过与正常和肿瘤测序数据比对确定每种突变的体细胞状态。随后更新的VarScan2完善了更多功能,能够检测肿瘤外显子测序中的体细胞突变以及拷贝数变异。该软件基于Java平台编写,适用于各种操作系统。Bi ngshan等使用基于似然的框架来调用单核苷酸变异并检测单核苷酸突变,工具叫作Po l ymutt。该方式基于E l ston-Stewart剥离算法来评估特定的遗传突变、个体基因型以及新发突变。随后一种有着更好的算法,基于贝叶斯模型的升级版Tri odenovo问世。该方法通过将先验突变率与数据分割开来,通过对仿真以及真实数据进行应用,证明了此方法比别的方法具有更高的灵敏度和特异性。forestDNM则是用R语言编写的,利用随机森林算法在全基因组测序数据中检测单核苷酸突变工具。DenovoGear则是利用了基于似然错误的模型进行新发突变的检测。novoCa l l er工具是在家系和人群的测序数据中,利用贝叶斯网络来检测位于编码区的新发突变。人们通常也会直接利用GATK的各种参数来对原始的突变进行过滤,最终得到新发突变。
但是无论哪种工具,并不能有效过滤掉预测新发突变结果中所有的假阳性,并且工具所能适应的变异识别平台有限,且准确率不高;而且现实中获得的经 Sanger测序验证过的真新发突变样本量很小,并不足以支撑训练出一个高精度的分类器。
针对相关技术中预测新发突变出错率很高,且现实中获得的经Sanger测序验证过的真新发突变的样本量很小造成的不足以支撑训练出一个高精度的分类器的问题,目前尚未提出有效的解决方案。
发明内容
本申请的主要目的在于提供一种新发突变的标签标注方法、装置、存储介质及服务器,以解决现在市面上预测新发突变软件出错率很高,且获得的经 Sanger测序验证过的真新发突变的样本量很小造成的不足以支撑训练出一个高精度的分类器的问题。
为了实现上述目的,根据本申请的一个方面,提供了一种新发突变的标签标注方法。
根据本申请的新发突变的标签标注方法包括:接收来自第一数据库的第一测序数据;根据所述第一测序数据确定每个个体对应的可疑新发突变;依据所述可疑新发突变确定假新发突变,并通过给所述假新发突变标注上第一标签,形成阴性训练样本;参照预设模拟规则处理所述可遗传且只在亲代与子代间传递了一次的突变,然后通过不同家系亲代间的两两替换得到模拟新发突变,并通过给所述真新发突变和所述模拟新发突变标注上第二标签,形成阳性训练样本。
进一步的,接收来自第一数据库的第一测序数据之前还包括:接收用户在终端配置的平台信息;根据所述平台信息调用对应的平台接口,通过平台接口接入对应的变异识别平台,并从中调用所述第一测序数据。
进一步的,所述变异识别平台包括但不限于GATK、Deep var i ant、We ca l l、PBSV、Sn i ff l es或、cuteSV等各种变异识别平台。。
进一步的,参照预设模拟规则处理所述可遗传且只在亲代与子代间传递了一次的突变,然后通过不同家系亲代间的两两替换得到模拟新发突变,并通过给所述模拟新发突变标注上第二标签,形成阳性训练样本之后还包括:采用随机森林算法,先将阴性训练样本和阳性训练样本输入分类器进行训练,再将来自第二数据库的第二测序数据作为独立验证集进行参数调整与验证,最后利用经过Sanger 测序验证的新发突变数据作为测试集进行分类器性能的评估,生成新发突变预测模型;将待识别数据输入新发突变预测模型,判断出所述待识别数据是否为新发突变。
进一步的,所述第一测试数据为高通量测序的变异数据或三代测序的结构变异数据。
进一步的,参照预设模拟规则处理得到模拟新发突变包括:利用p l i nk软件计算每个突变等位基因的传递次数,找出只在亲代中传递过一次给子代的可遗传变异,并将家系的父母进行随机替换,得到模拟新发突变。
进一步的,依据所述可疑新发突变确定假新发突变,并通过给所述假新发突变标注上第一标签,形成阴性训练样本包括:
对于二代测序数据,根据后代及其父母基因型,找出所有在后代中基因型为 0/1且在亲代中基因型为0/0的突变作为假新发突变;对于三代测序数据,先利用 Jasmi ne软件对所有突变执行合并操作;再利用genSV软件将合并后的突变进行分型,然后根据每个变异的分型结果,找出所有在后代中基因型为0/1且在亲代中基因型为0/0的突变作为假新发突变;最后通过给所述假新发突变标注上第一标签,形成阴性训练样本。
为了实现上述目的,根据本申请的另一方面,提供了一种新发突变的标签标注装置。
根据本申请的新发突变的标签标注装置包括:接收模块,用于接收来自第一数据库的第一测序数据;确定模块,用于根据所述第一测序数据确定每个个体对应的可疑新发突变;阴性标注模块,用于依据所述可疑新发突变确定假新发突变,并通过给所述假新发突变标注上第一标签,形成阴性训练样本;阳性标注模块,用于参照预设模拟规则处理所述可遗传且只在亲代与子代间传递了一次的突变,然后通过不同家系亲代间的两两替换得到模拟新发突变,并通过给所述模拟新发突变标注上第二标签,形成阳性训练样本。
为了实现上述目的,根据本申请的另一方面,提供了一种计算机可读存储介质。
根据本申请的计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行所述的新发突变的标签标注方法。
为了实现上述目的,根据本申请的另一方面,提供了一种服务器。
根据本申请的服务器,包括:存储器和处理器,所述存储器中存储有计算机程序,其中,所述处理器被设置为运行所述计算机程序以执行所述的新发突变的标签标注方法。
在本申请实施例中,采用基于对新发突变模拟、扩充并标注上标签的方式,通过接收来自第一数据库的第一测序数据;根据所述第一测序数据确定每个个体对应的可疑新发突变;依据所述可疑新发突变确定假新发突变,并通过给所述假新发突变标注上第一标签,形成阴性训练样本;参照预设模拟规则处理得到模拟新发突变,并通过给所述模拟新发突变标注上第二标签,形成阳性训练样本;达到了有效过滤掉新发突变中较多的假阳性,以大幅降低现存新发突变预测软件的预测错误概率,且通过模拟对可信度较高的新发突变进行有效扩充的目的,从而实现了足以支撑训练出一个高精度的分类器的技术效果,进而解决了市面上新发突变预测工具准确率较低以及操作相对复杂的问题以及现实中获得的经Sanger测序验证过的真新发突变的样本量很小造成的不足以支撑训练出一个高精度的分类器的技术问题。
附图说明
构成本申请的一部分的附图用来提供对本申请的进一步理解,使得本申请的其它特征、目的和优点变得更明显。本申请的示意性实施例附图及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1是根据本申请实施例的新发突变的标签标注方法的流程示意图;
图2是根据本申请实施例的新发突变的标签标注装置的结构示意图;
图3是根据本申请优选实施例的新发突变的标注示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
在本申请中,术语“上”、“下”、“左”、“右”、“前”、“后”、“顶”、“底”、“内”、“外”、“中”、“竖直”、“水平”、“横向”、“纵向”等指示的方位或位置关系为基于附图所示的方位或位置关系。这些术语主要是为了更好地描述本发明及其实施例,并非用于限定所指示的装置、元件或组成部分必须具有特定方位,或以特定方位进行构造和操作。
并且,上述部分术语除了可以用于表示方位或位置关系以外,还可能用于表示其他含义,例如术语“上”在某些情况下也可能用于表示某种依附关系或连接关系。对于本领域普通技术人员而言,可以根据具体情况理解这些术语在本发明中的具体含义。
此外,术语“安装”、“设置”、“设有”、“连接”、“相连”、“套接”应做广义理解。例如,可以是固定连接,可拆卸连接,或整体式构造;可以是机械连接,或电连接;可以是直接相连,或者是通过中间媒介间接相连,又或者是两个装置、元件或组成部分之间内部的连通。对于本领域普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
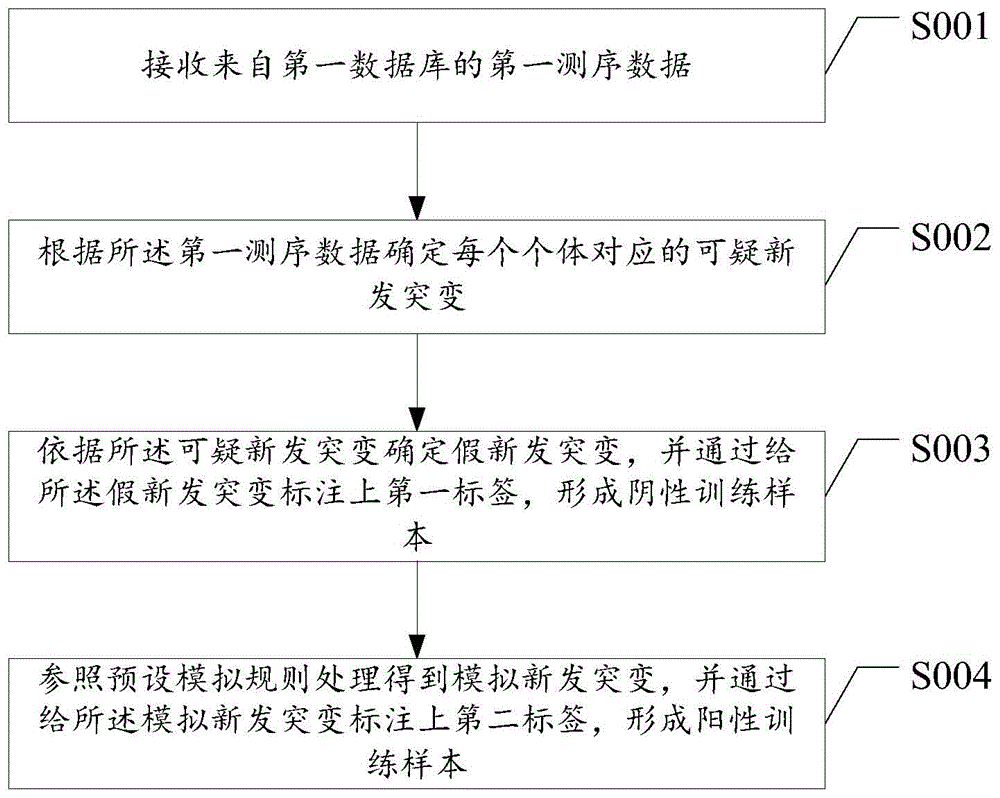
根据本发明实施例,提供了一种新发突变的标签标注方法,如图1所示,该方法包括如下的步骤S001至步骤S004:
步骤S001、接收来自第一数据库的第一测序数据;
本实施例中,所述第一测试数据为高通量测序的变异数据或三代测序的结构变异数据。第一测试数据可以来自包括但不限于GATK、Deep var i ant、We ca l l、 PBSV、Sn iff l es或、cuteSV等各种变异识别平台的不同数据库,比如:高通量测序的变异数据可以来自GATK平台的SSC数据库中。第一测序数据可以根据突变基因型,找到所有的推测的新发突变。
根据本发明实施例,优选的,接收来自第一数据库的第一测序数据之前还包括:
接收用户在终端配置的平台信息;
根据所述平台信息调用对应的平台接口,通过平台接口接入对应的变异识别平台,并从中调用所述第一测序数据。
预先在手机、电脑、平板的终端上安装了应用处理软件,或者建立URL与网站的调用关系,在人员打开软件或者输入网址时,可以调出操作界面,人员在操作界面选择相应的平台信息并反馈给服务器,服务器根据平台信息能够调用对应的平台接口,与对应的变异识别平台对接,从中调取第一测序数据到服务器上,供服务器进行进一步的处理。
本实施例中,所述变异识别平台为GATK、Deep var i ant或者We ca l l平台,这些平台能够提供高通量测序的变异数据。界面中提供了三种变异识别平台供人员选择,从而可以适配不同的平台,基于不同平台数据生成新的训练集。此处仅为列举的变异识别平台,还可以是Sn i ff l es、cuteSV、PBSV等平台,这些能够提供三代测序的结构变异数据,因此不应当理解为对保护范围的限制。
步骤S002、根据所述第一测序数据确定每个个体对应的可疑新发突变;
服务器接收到第一测序数据后,基于该数据可以确定每个个体对应的可疑新发突变;即将平台经过检测获取的新发突变均确定为可疑新发突变。为后续的进一步判断、过滤提供原始数据支持。
步骤S003、依据所述可疑新发突变确定假新发突变,并通过给所述假新发突变标注上第一标签,形成阴性训练样本;
由于未过滤的原始测序数据中可信度不高,绝大部分的都不是真的新发突变,所以我们将所有在原始测序数据中根据基因型判断新发突变,由于其可信度不高,为此,在一种具体实施方式中,针对于高通量测序的变异数据,将基于高通量测序的变异数据确定的可疑新发突变均作为假新发突变。给假新发突变全标注上“0”的第一标签(呈阴性)。
在另一种具体实施方式中,依据所述可疑新发突变确定假新发突变,并通过给所述假新发突变标注上第一标签,形成阴性训练样本包括:
对于二代测序数据,根据后代及其父母基因型,找出所有在后代中基因型为 0/1且在亲代中基因型为0/0的突变作为假新发突变;
对于三代测序数据,由于三代测序在结构变异的推断以及变体调用方式上存在缺陷,在标注之前,先利用Jasmi ne软件对所有突变执行合并操作,通过其 KD-tree的算法减少孟德尔不一致变体的数量;再利用genSV软件将合并后的突变进行分型,然后根据每个变异的分型结果,找出所有在后代中基因型为0/1且在亲代中基因型为0/0的突变作为假新发突变;最后通过给所述假新发突变标注上第一标签,形成阴性训练样本。实现了三代测序的结构变异数据中新发突变的分型,得到了更加精确的基因型。
步骤S004、参照预设模拟规则处理所述可遗传且只在亲代与子代间传递了一次的突变,然后通过不同家系亲代间的两两替换得到模拟新发突变,并通过给所述模拟新发突变标注上第二标签,形成阳性训练样本。
经Sanger测序验证过的新发突变往往样本量极小,不利于训练出高精度分类器。针对于此,预先在服务器上配置了模拟规则,参照该模拟规则可以基于可遗传突变在计算等位基因频率后,模拟并扩充出更多的新发突变,即模拟新发突变。这些模拟的新发突变统一标注上“1”第二标签(呈阳性)。
在一种具体的实施方式中,参照预设模拟规则处理所述得到模拟新发突变包括:
利用p l i nk软件计算每个突变等位基因的传递次数,找出亲代中传递过一个给子代的可遗传变异,并将家系的父母进行随机替换,得到模拟新发突变。
具体而言,利用p l i nk软件计算每个突变等位基因的传递次数,找出那些在亲代中只传递过一个给子代的可遗传变异,我们称之为(Pr ivate I nher ited Variants)。将其作为模拟并扩充新发突变的基础。由于只传递过一次,如果将家系的父母进行随机替换,那么这些突变就都变成为了模拟真新发突变。实现了高通量测序的变异数据中真新发突变的模拟,生成高质量带标签的训练集,给用户个性化的在自己的变异识别平台数据上训练自己的新发突变分类器,以适应不同的变异识别平台数据。
本实施例中,可以是人员通过操作调用p l i nk软件进行可遗传突变的传递次数计算;也可以是机器(服务器)在对接到第一测序数据后,自动调用p l i nk软件进行计算。实现人机交互或自动进行可遗传突变的传递次数计算。
在一种具体的实施方式中,如图3所示,对于性染色体上的新发突变,由于性别的原因以及性染色体上存在拟常染色体区域(Pseudoautosoma l region),我们需要对男女进行分别讨论。
拟常染色体区是高等动物性染色体上的一段同源序列,分为PAR1和PAR2两个部分,目前为止,在该区域上发现了至少29个基因,该区域是X染色体与Y染色体唯一能够发生互换的位置。在GRCh38参考基因组,拟常染色体的位置分别位于X染色体的GRCh38:chrX:10001-2781479和GRCh38:chrX:155701383 -156030895,Y染色体的GRCh38:chrY:10001-2781479和GRCh38:chrY: 56887903-57217415。而在GRCh37参考基因组,位置分别位于X染色体的 GRCh37:chrX:60001-2699520和GRCh37:chrX:154931044-155260560,Y染色体的GRCh37:chrY:10001-2649520和GRCh37:chrY:59034050-59363566。
在构建训练集时,由于女性后代的染色体为XX,在两个X染色体各有一个复本,可以进行交换,依然同常染色体一样,在随机替换完父母后,在pr ivate i nher ited突变中选择父母双方基因型为0/0,而女性后代基因型为0/1的突变标记为真新发突变。而对于男性后代,染色体为XY,男性只有在唯一的X染色体上有基因,Y染色体的对应区域则没有,所以我们要根据突变位置是否在拟常染色体区域内进行区别对待。对于男性后代在拟常染色体中的突变,由于会发生染色体互换,依然同常染色体一样,在随机替换完父母后,在private i nher ited突变中选择父母双方基因型为0/0,而女性后代基因型为0/1的突变标记为真新发突变。而对于不在男性后代拟常染色体区域的突变,由于不能发生交换,我们在进行随机替换父母步骤之前,对于X染色体上的突变,在pr i vate i nher ited突变中选择男性后代基因型为1/1,母亲基因型为0/1,由于X染色体只能从母亲那继承,所以对父亲基因型没有要求,这样一来,在替换父母后,男性后代X染色体上的基因型为1/1,母亲为0/0,于是我们将这种突变标记为真新发突变。对于Y染色体上的突变,在pr i vate i nherited突变中选择男性后代基因型为1/1,父亲基因型为0/1,由于Y染色体只能从父亲那继承,所以对母亲的基因型没有要求,这样一来,在替换父母后,男性后代Y染色体上的基因型为1/1,父亲为0/0,于是将这种突变标记为真新发突变。
如此,可以根据以上的模拟规则,以可遗传突变为基础模拟出足够多的模拟新发突变,也就可以得到足够多的阳性训练样本,实现训练集的有效扩充,基于训练集足以支撑训练出一个高精度的分类器。
从以上的描述中,可以看出,本发明实现了如下技术效果:
在本申请实施例中,采用基于对新发突变模拟、扩充并标注上标签的方式,通过接收来自第一数据库的第一测序数据;根据所述第一测序数据确定每个个体对应的可疑新发突变;利用预设筛选软件将所述可疑新发突变分为假新发突变,并通过给所述假新发突变标注上第一标签,形成阴性训练样本;参照预设模拟规则处理所述可遗传突变以得到模拟新发突变,并通过给所述模拟新发突变标注上第二标签,形成阳性训练样本;达到了有效过滤掉新发突变中较多的假阳性,以大幅降低现存新发突变预测软件存在出错率较高的缺点,且通过模拟对可信度较高的新发突变进行有效扩充的目的,从而实现了足以支撑训练出一个高精度的分类器的技术效果,进而解决了市面上新发突变预测工具准确率较低、操作相对复杂的问题以及现实中获得的经Sanger测序验证过的真新发突变的样本量很小造成的不足以支撑训练出一个高精度的分类器的技术问题。
根据本发明实施例,优选的,参照预设模拟规则处理所述可遗传突变以得到模拟新发突变,并通过给所述模拟新发突变标注上第二标签,形成阳性训练样本之后还包括:
采用随机森林算法,先将阴性训练样本和阳性训练样本输入分类器进行训练,再将来自第二数据库的第二测序数据作为独立验证集进行参数调整与验证,最后利用经过Sanger测序验证的新发突变数据作为测试集进行分类器性能的评估,生成新发突变预测模型;
将待识别数据输入新发突变预测模型,判断出所述待识别数据是否为新发突变。
作为一种具体的实施方式,该分类器在部分孤独症SSC数据上进行训练,并且在另外的一个孤独症数据库REACH中进行独立验证调参,最终在经过Sanger验证的部分SSC/SPARK数据上进行测试,判断其性能。结果表明,该分类器性能优秀,准确性较高,不仅运行只需要VCF文件以及含有家庭成员关系的Fam文件作为输入文件,而且输出文件容量较小也易于理解,其结果也方便直接进行 Roc_curve图的绘制,同时,针对目前流行的Joi nt-cal l ed genotyp i ng VCF文件也能胜任。另外,能够在除GATK外的Deep var i ant或Weca l l平台中自动化生成高质量带标签的训练集,然后利用训练好的分类器对其进行新发突变的识别。如此一来,面对不同平台的测序样本,有能力重新生成一个高质量的训练集用来训练一个新的分类器,利用此分类器可以在多种测序数据中快速精准地鉴定出新发突变来供研究人员进行下游分析且预测新发突变的准确率得到了提高。
经过对随机森林算法中内置的参数进行多达6912种的组合与调整,使得分类器在验证集中的真阳性率高达97.1%。(2)分类器在测试集中的真阳性率高达 95.4%。此外,与主流的新发突变检测工具Tr i oDeNovo以及DenovoGear在同一测试集上进行性能测试后,我们的分类器ROC曲线下面积(the area under the ROC curve,AUC)为0.998高于其它两者的0.971和0.978,这表明我们的分类器性能更加优秀,能够更有效地区分阳性与阴性样本。(3)我们利用经过Sanger测序验证的SPARK数据库的测序数据进行不同变异识别平台中分类器的准确性验证,结果显示在各平台中,分类器的召回率都在92%以上。这说明自动化构建训练集的系统鲁棒性较强,能够让在不同变异识别平台的测序数据中训练的分类器所预测的结果较为一致。
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
根据本发明实施例,还提供了一种用于实施上述新发突变的标签标注方法的装置,如图2所示,该装置包括:
接收模块10,用于接收来自第一数据库的第一测序数据;
本实施例中,所述第一测试数据为高通量测序的变异数据或三代测序的结构变异数据。第一测试数据可以来自包括但不限于GATK、Deep var i ant、We ca l l、 PBSV、Sn iff l es或、cuteSV等各种变异识别平台的不同数据库,比如:高通量测序的变异数据可以来自GATK平台的SSC数据库中。第一测序数据可以根据突变基因型,找到所有的推测的新发突变。
根据本发明实施例,优选的,接收来自第一数据库的第一测序数据之前还包括:
接收用户在终端配置的平台信息;
根据所述平台信息调用对应的平台接口,通过平台接口接入对应的变异识别平台,并从中调用所述第一测序数据。
预先在手机、电脑、平板的终端上安装了应用处理软件,或者建立URL与网站的调用关系,在人员打开软件或者输入网址时,可以调出操作界面,人员在操作界面选择相应的平台信息并反馈给服务器,服务器根据平台信息能够调用对应的平台接口,与对应的变异识别平台对接,从中调取第一测序数据到服务器上,供服务器进行进一步的处理。
本实施例中,所述变异识别平台为GATK、Deep var i ant或者We ca l l平台,这些平台能够提供高通量测序的变异数据。界面中提供了三种变异识别平台供人员选择,从而可以适配不同的平台,基于不同平台数据生成新的训练集。此处仅为列举的变异识别平台,还可以是Sn i ff l es、cuteSV、PBSV等平台,这些能够提供三代测序的结构变异数据,因此不应当理解为对保护范围的限制。
确定模块20,用于根据所述第一测序数据确定每个个体对应的可疑新发突变;
服务器接收到第一测序数据后,基于该数据可以确定每个个体对应的可疑新发突变;即将平台经过检测获取的新发突变均确定为可疑新发突变。为后续的进一步判断、过滤提供原始数据支持。
阴性标注模块30,用于依据所述可疑新发突变确定假新发突变,并通过给所述假新发突变标注上第一标签,形成阴性训练样本;
由于未过滤的原始测序数据中根据基因型判断新发突变的可信度不高,绝大部分的都不是真的新发突变,原始数据中直接通过基因型找出的新发突变全都当作是假的新发突变,为此,在一种具体实施方式中,针对于高通量测序的变异数据,将基于基因型所得到的可疑新发突变均作为假新发突变。给假新发突变全标注上“0”的第一标签(呈阴性)。有效降低了标注出来的训练用新发突变的出错率,也就能够提高训练出来的分类器的预测精度。
本实施例中,可以是人员通过操作,对假新发突变进行标注,也可以是在基因分型得到假新发突变后,机器自动对假新发突变进行标注。实现人机交互或自动标注。
在另一种具体实施方式中,依据所述可疑新发突变确定假新发突变,并通过给所述假新发突变标注上第一标签,形成阴性训练样本包括:
对于二代测序数据,根据后代及其父母基因型,找出所有在后代中基因型为 0/1且在亲代中基因型为0/0的突变作为假新发突变;
对于三代测序数据,由于三代测序在结构变异的推断以及变体调用方式上存在缺陷,在标注之前,先利用Jasmi ne软件对所有突变执行合并操作,通过其 KD-tree的算法减少孟德尔不一致变体的数量;再利用genSV软件将合并后的突变进行分型,然后根据每个变异的分型结果,找出所有在后代中基因型为0/1且在亲代中基因型为0/0的突变作为假新发突变;最后通过给所述假新发突变标注上第一标签,形成阴性训练样本。实现了三代测序的结构变异数据中新发突变的分型,得到了更加精确的基因型。
阳性标注模块40,用于参照预设模拟规则处理所述可遗传突变以得到模拟新发突变,并通过给所述模拟新发突变标注上第二标签,形成阳性训练样本。
经Sanger测序验证过的新发突变往往样本量极小,不利于训练出高精度分类器。针对于此,预先在服务器上配置了模拟规则,参照该模拟规则可以基于可遗传突变在计算等位基因频率后,模拟并扩充出更多的新发突变,即模拟新发突变。这些模拟的新发突变统一标注上“1”第二标签(呈阳性)。
在一种具体的实施方式中,参照预设模拟规则处理所述假新发突变以得到模拟新发突变包括:
利用p l i nk软件计算每个突变等位基因的传递次数,找出亲代中传递过一个给子代的可遗传变异,并将家系的父母进行随机替换,得到模拟新发突变。
具体而言,利用p l i nk软件计算每个突变等位基因的传递次数,找出那些在亲代中只传递过一个给子代的可遗传变异,我们称之为(Pr ivate I nher ited Variants)。将其作为模拟并扩充新发突变的基础。由于只传递过一次,如果将家系的父母进行随机替换,那么这些突变就都变成为了模拟新发突变。实现了高通量测序的变异数据中新发突变的模拟,生成高质量带标签的训练集,给用户个性化的在自己的变异识别平台数据上训练自己的新发突变分类器,以适应不同的变异识别平台数据。
本实施例中,可以是人员通过操作调用p l i nk软件进行可遗传突变的传递次数计算;也可以是机器(服务器)在对接到第一测序数据后,自动调用p l i nk软件进行计算。实现人机交互或自动进行可遗传突变的传递次数计算。
在一种具体的实施方式中,如图3所示,对于性染色体上的新发突变,由于性别的原因以及性染色体上存在拟常染色体区域(Pseudoautosoma l region),我们需要对男女进行分别讨论。
拟常染色体区是高等动物性染色体上的一段同源序列,分为PAR1和PAR2两个部分,目前为止,在该区域上发现了至少29个基因,该区域是X染色体与Y染色体唯一能够发生互换的位置。在GRCh38参考基因组,拟常染色体的位置分别位于X染色体的GRCh38:chrX:10001-2781479和GRCh38:chrX:155701383 -156030895,Y染色体的GRCh38:chrY:10001-2781479和GRCh38:chrY: 56887903-57217415。而在GRCh37参考基因组,位置分别位于X染色体的 GRCh37:chrX:60001-2699520和GRCh37:chrX:154931044-155260560,Y染色体的GRCh37:chrY:10001-2649520和GRCh37:chrY:59034050-59363566。
在构建训练集时,由于女性后代的染色体为XX,在两个X染色体各有一个复本,可以进行交换,依然同常染色体一样,在随机替换完父母后,在pr ivate i nher ited突变中选择父母双方基因型为0/0,而女性后代基因型为0/1的突变标记为真新发突变。而对于男性后代,染色体为XY,男性只有在唯一的X染色体上有基因,Y染色体的对应区域则没有,所以我们要根据突变位置是否在拟常染色体区域内进行区别对待。对于男性后代在拟常染色体中的突变,由于会发生染色体互换,依然同常染色体一样,在随机替换完父母后,在private i nher ited突变中选择父母双方基因型为0/0,而女性后代基因型为0/1的突变标记为真新发突变。而对于不在男性后代拟常染色体区域的突变,由于不能发生交换,我们在进行随机替换父母步骤之前,对于X染色体上的突变,在pr i vate i nher ited突变中选择男性后代基因型为1/1,母亲基因型为0/1,由于X染色体只能从母亲那继承,所以对父亲基因型没有要求,这样一来,在替换父母后,男性后代X染色体上的基因型为1/1,母亲为0/0,于是我们将这种突变标记为真新发突变。对于Y染色体上的突变,在pr i vate i nherited突变中选择男性后代基因型为1/1,父亲基因型为0/1,由于Y染色体只能从父亲那继承,所以对母亲的基因型没有要求,这样一来,在替换父母后,男性后代Y染色体上的基因型为1/1,父亲为0/0,于是将这种突变标记为真新发突变。
如此,可以根据以上的模拟规则,以可疑新发突变为基础模拟出足够多的模拟新发突变,也就可以得到足够多的阳性训练样本,实现训练集的有效扩充,基于训练集足以支撑训练出一个高精度的分类器。
从以上的描述中,可以看出,本发明实现了如下技术效果:
在本申请实施例中,采用基于对新发突变模拟、扩充并标注上标签的方式,通过接收来自第一数据库的第一测序数据;根据所述第一测序数据确定每个个体对应的可疑新发突变;利用预设筛选软件将所述可疑新发突变分为假新发突变,并通过给所述假新发突变标注上第一标签,形成阴性训练样本;参照预设模拟规则处理所述可遗传突变以得到模拟新发突变,并通过给所述模拟新发突变标注上第二标签,形成阳性训练样本;达到了有效过滤掉新发突变中较多的假阳性,以大幅降低现存新发突变预测软件存在出错率较高的缺点,且通过模拟对可信度较高的新发突变进行有效扩充的目的,从而实现了足以支撑训练出一个高精度的分类器的技术效果,进而解决了市面上新发突变预测工具准确率较低、操作相对复杂的问题以及现实中获得的经Sanger测序验证过的真新发突变的样本量很小造成的不足以支撑训练出一个高精度的分类器的技术问题。根据本发明实施例,优选的,参照预设模拟规则处理所述可遗传突变以得到模拟新发突变,并通过给所述真新发突变和所述模拟新发突变标注上第二标签,形成阳性训练样本之后还包括:
采用随机森林算法,先将阴性训练样本和阳性训练样本输入分类器进行训练,再将来自第二数据库的第二测序数据作为独立验证集进行参数调整与验证,最后利用经过Sanger测序验证的新发突变数据作为测试集进行分类器性能的评估,生成新发突变预测模型;
将待识别数据输入新发突变预测模型,判断出所述待识别数据是否为新发突变。
作为一种具体的实施方式,该分类器在部分孤独症SSC数据上进行训练,并且在另外的一个孤独症数据库REACH中进行独立验证调参,最终在经过Sanger验证的部分SSC/SPARK数据上进行测试,判断其性能。结果表明,该分类器性能优秀,准确性较高,不仅运行只需要VCF文件以及含有家庭成员关系的Fam文件作为输入文件,而且输出文件容量较小也易于理解,其结果也方便直接进行 Roc_curve图的绘制,同时,针对目前流行的Joi nt-cal l ed genotypi ng VCF文件也能胜任。另外,能够在除GATK外的Deep var iant或We cal l平台中自动化生成高质量带标签的训练集,然后利用训练好的分类器对其进行新发突变的识别。如此一来,面对不同平台的测序样本,有能力重新生成一个高质量的训练集用来训练一个新的分类器,利用此分类器可以在多种测序数据中快速精准地鉴定出新发突变来供研究人员进行下游分析并且预测新发突变的准确率得到了提高。
经过对随机森林算法中内置的参数进行多达6912种的组合与调整,使得分类器在验证集中的真阳性率高达97.1%。(2)分类器在测试集中的真阳性率高达 95.4%。此外,与主流的新发突变检测工具Tr ioDeNovo以及DenovoGear在同一测试集上进行性能测试后,我们的分类器ROC曲线下面积(the area under the ROC curve,AUC)为0.998高于其它两者的0.971和0.978,这表明我们的分类器性能更加优秀,能够更有效地区分阳性与阴性样本。(3)我们利用经过Sanger测序验证的SPARK数据库的测序数据进行不同变异识别平台中分类器的准确性验证,结果显示在各平台中,分类器的召回率都在92%以上。这说明自动化构建训练集的系统鲁棒性较强,能够让在不同变异识别平台的测序数据中训练的分类器所预测的结果较为一致。
显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。