一种基于深度学习重建的水下视频对象编码方法
文献发布时间:2023-06-19 12:00:51
技术领域
本发明涉及一种水下视频对象信号处理技术,尤其是涉及一种基于深度学习重建的水下视频对象编码方法。
背景技术
水下视频技术正在越来越多的领域中使用,例如自动水下航行器、油气勘探、水下管道检查和环境监控等。在水下视频传输过程中,通过有线传输的方式存在成本高、维护更新不容易的问题;通过电磁波传输的方式存在迅速衰减的问题。相比之下,声波传输是适合水下视频的无线通信方法,但是,水下声波路径的数据传输速率比无线电路径的数据传输速率低得多,水下声波路径的数据传输速率的数量级一般为kbps,数值通常小于100,而IEEE 802.11ac无线电路径的数据传输速率的数量级一般为Mbps,数值通常为100+,由此可见水下声波路径的数据传输速率低。现有的视频编码标准,例如高效视频编码(HighEfficiency Video Coding,HEVC)标准,在高比特的数据传输速率下其视频压缩效果会更佳。相关实验结果表明,即使在带宽达到100kbps的传输通道上,以30fps传输320×240的彩色图像需要约500:1的压缩率。当水下视频的分辨率增大或者水下声波路径的数据传输速率更低时,这将严重影响水下视频的压缩质量。因此,用现有的视频编码标准直接压缩水下视频并不是最合适的,如何在数据传输速率不高的水下传输通道上实现具有庞大数据量的水下视频高效编码已成为重要问题。
在水下实际监测、勘探过程中,用户往往需要观察、检测水下视频的某一特定对象,其它信息非用户所感兴趣。在水下声波路径的数据传输速率不高的前提下,这些非感兴趣信息在压缩与传输过程中占用了不必要的资源。通过结合用户端需求只编码水下视频对象来减少水下视频源传输的数据量,是实现水下视频在低码率条件下高效编码的有效方式之一。而且,现有的视频编码标准,如HEVC可以兼容对象的编码,但是这些视频编码标准是基于编码块进行压缩,并非专门针对低码率条件下的对象编码。基于上述原因,针对水下视频感兴趣对象设计一种有效的编码方法十分有必要。
发明内容
本发明所要解决的技术问题是提供一种基于深度学习重建的水下视频对象编码方法,其能够在低码率条件下实现水下视频对象的高效编码。
本发明解决上述技术问题所采用的技术方案为:一种基于深度学习重建的水下视频对象编码方法,其特征在于包括以下步骤:
步骤一:在编码端,对待处理的原始的水下视频进行处理,去除背景而保留对象信息,得到仅包含对象信息的水下视频;然后将仅包含对象信息的水下视频中当前待编码的第t帧定义为当前帧;其中,t为正整数,t的初始值为1,1≤t≤Frame,Frame表示待处理的原始的水下视频中包含的帧的总帧数或仅包含对象信息的水下视频中包含的帧的总帧数,Frame>1,当前帧的宽和高对应为W
步骤二:将当前帧记为F
步骤三:对F
步骤四:将Ω
步骤五:判断t是否等于(k-1)×N+1,如果t等于(k-1)×N+1,则将F
步骤六:令t=t+1,将仅包含对象信息的水下视频中下一帧待编码的帧作为当前帧;然后返回步骤二继续执行,直到仅包含对象信息的水下视频中的所有帧处理完毕,得到所有对象掩膜码流和所有角点信息码流,及所有关键帧码流;再将所有对象掩膜码流和所有角点信息码流及所有关键帧码流发送给解码端;其中,t=t+1中的“=”为赋值符号;
步骤七:在解码端,对接收到的所有对象掩膜码流和所有角点信息码流及所有关键帧码流进行解码,得到解码后的水下视频,该解码后的水下视频包括每帧的对象掩膜和每帧中的每个角点的横坐标、纵坐标、R通道颜色值、G通道颜色值、B通道颜色值,及所有关键帧;
步骤八:构造一个卷积神经网络以进行基于深度学习的对象精细化重建;然后将解码后的水下视频中当前待处理的第t帧定义为当前帧;其中,1≤t≤Frame;
步骤九:将当前帧记为F'
步骤十:根据Matrix'
步骤十一:判断t是否等于(k'-1)×N+1,如果t等于(k'-1)×N+1,则令C
步骤十二:令t=t+1,将解码后的水下视频中下一帧待处理的帧作为当前帧;然后返回步骤九继续执行,直到t等于k'×N+1时执行步骤十三;其中,t=t+1中的“=”为赋值符号;
步骤十三:令k'=k'+1,然后返回步骤九继续执行,直到k'等于
所述的步骤二中,Matrix
所述的步骤二中,对Matrix
所述的步骤八中,卷积神经网络由输入卷积模块、中间残差模块以及输出卷积模块组成;输入卷积模块包括依次连接的第一卷积层、第二卷积层、第三卷积层、第四卷积层,第一卷积层的输入端接收一幅输入图像的R通道、G通道和B通道,第二卷积层的输入端接收第一卷积层的输出端输出的所有特征图,第三卷积层的输入端接收第二卷积层的输出端输出的所有特征图,第四卷积层的输入端接收第三卷积层的输出端输出的所有特征图,第四卷积层的输出端输出的所有特征图传输给中间残差模块;中间残差模块包括依次连接的第一残差层、第二残差层、第三残差层、第四残差层,第一残差层、第二残差层、第三残差层、第四残差层的结构相同,其由第1个卷积层和第2个卷积层组成,第1个卷积层的输入端作为其所在的残差层的输入端,第2个卷积层的输入端接收第1个卷积层的输出端输出的所有特征图,对输入到第1个卷积层的输入端的所有特征图与第2个卷积层的输出端输出的所有特征图进行对应元素相加操作,相加操作后得到的所有特征图由“LeakyReLU”激活后作为所在的残差层的输出端输出的所有特征图,第一残差层的输入端接收第四卷积层的输出端输出的所有特征图,第二残差层的输入端接收第一残差层的输出端输出的所有特征图,第三残差层的输入端接收第二残差层的输出端输出的所有特征图,第四残差层的输入端接收第三残差层的输出端输出的所有特征图,第四残差层的输出端输出的所有特征图传输给输出卷积模块;输出卷积模块包括依次连接的第五卷积层、第六卷积层、第七卷积层、第八卷积层,第五卷积层的输入端接收第四残差层的输出端输出的所有特征图,第六卷积层的输入端接收第五卷积层的输出端输出的所有特征图,第七卷积层的输入端接收第六卷积层的输出端输出的所有特征图,第八卷积层的输入端接收第七卷积层的输出端输出的所有特征图,第八卷积层的输出端输出结果;其中,第一卷积层、第二卷积层、第三卷积层、第四卷积层的卷积核尺寸均为3×3、卷积步长均为1、采用的激活函数均为“LeakyReLU”,第一卷积层的输入通道数为3、输出通道数为32,第二卷积层的输入通道数为32、输出通道数为32,第三卷积层的输入通道数为32、输出通道数为64,第四卷积层的输入通道数为64、输出通道数为128,第一残差层、第二残差层、第三残差层、第四残差层中的第1个卷积层的卷积核尺寸均为3×3、卷积步长均为1、输入通道数均为128、输出通道数均为128、采用的激活函数均为“LeakyReLU”,第一残差层、第二残差层、第三残差层、第四残差层中的第2个卷积层的卷积核尺寸均为3×3、卷积步长均为1、输入通道数均为128、输出通道数均为128、未激活函数,第五卷积层、第六卷积层、第七卷积层的卷积核尺寸均为3×3、卷积步长均为1、采用的激活函数均为“LeakyReLU”,第五卷积层的输入通道数为128、输出通道数为64,第六卷积层的输入通道数为64、输出通道数为32,第七卷积层的输入通道数为32、输出通道数为32,第八卷积层的卷积核尺寸为3×3、卷积步长为1、采用的激活函数均为“Sigmoid”,第八卷积层的输入通道数为32、输出通道数为3。
所述的步骤十中,C'
所述的步骤五中,采用HEVC标准的编码技术对F
与现有技术相比,本发明的优点在于:
1)本发明方法结合水下视频的实际应用特点,即水下视频在实际观察、监测等应用中存在明显的前景信息与背景信息,前景信息一般是用户关注度更高的感兴趣对象,背景信息则一般不为用户所感兴趣,因此针对水下视频对象进行编码,减小了水下视频编码所需要编码的数据总量。
2)本发明方法针对水下视频对象编码过程中,给出了满足低码率条件的视频对象编码方法,通过角点信息编码、对象掩膜编码以及少量关键帧编码,以此代替现有编码标准编码全部像素点颜色信息,进一步减小了所需要的编码数据总量,达到了低码率编码的目的。
3)本发明方法在解码端构建了一个卷积神经网络,用于在本发明方法对应的编码方法下进行基于深度学习的最终重建,从而在低码率编码条件下提升本发明方法解码端的重建结果质量。
附图说明
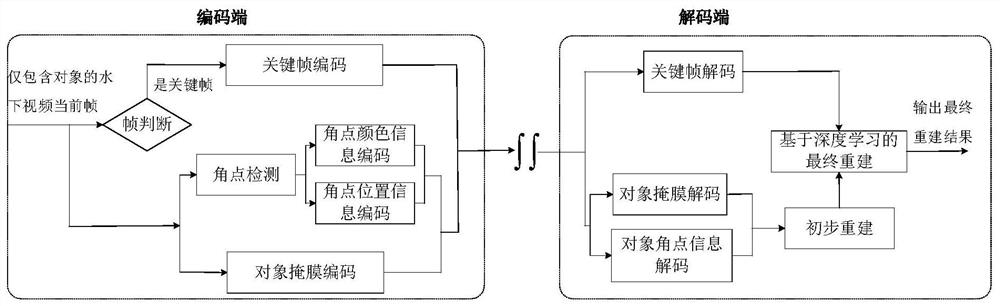
图1为本发明方法的总体实现框图;
图2a为一帧仅包含对象信息的水下视频帧;
图2b为对图2a所示的水下视频帧进行Harris角点检测后得到的所有角点的示意图;
图3a为Dolphin测试序列的第二帧原始图像;
图3b为Grayfish测试序列的第二帧原始图像;
图4a为图3a对应的仅包含对象信息的图像;
图4b为图3b对应的仅包含对象信息的图像;
图5a为图3a对应的最终重建结果;
图5b为图3b对应的最终重建结果。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种基于深度学习重建的水下视频对象编码方法,其总体实现框图如图1所示,其包括以下步骤:
步骤一:在编码端,对待处理的原始的水下视频进行处理,去除背景而保留对象信息,得到仅包含对象信息的水下视频;然后将仅包含对象信息的水下视频中当前待编码的第t帧定义为当前帧;其中,t为正整数,t的初始值为1,1≤t≤Frame,Frame表示待处理的原始的水下视频中包含的帧的总帧数或仅包含对象信息的水下视频中包含的帧的总帧数,Frame>1,在本实施例中Frame为200,当前帧的宽和高对应为W
在此,对原始的水下视频进行处理,去掉背景而保留对象信息,得到仅包含对象信息的水下视频,所采用的技术为常规技术,如选用参考文献Qin X,Zhang Z,Huang C,etal.BASNet:Boundary-Aware Salient Object Detection[C]//2019IEEE/CVF Conferenceon Computer Vision and Pattern Recognition(CVPR).IEEE,2019,7471-7481.(边界感知显著目标检测)中记载的方法。
步骤二:将当前帧记为F
在本实施例中,所述的步骤二中,Matrix
在本实施例中,所述的步骤二中,对Matrix
步骤三:对F
图2a给出了一帧仅包含对象信息的水下视频帧,图2b给出了对图2a所示的水下视频帧进行Harris角点检测后得到的所有角点的示意图。
步骤四:将Ω
步骤五:判断t是否等于(k-1)×N+1,如果t等于(k-1)×N+1,则将F
在本实施例中,所述的步骤五中,采用HEVC标准的编码技术对F
步骤六:令t=t+1,将仅包含对象信息的水下视频中下一帧待编码的帧作为当前帧;然后返回步骤二继续执行,直到仅包含对象信息的水下视频中的所有帧处理完毕,得到所有对象掩膜码流和所有角点信息码流,及所有关键帧码流;再将所有对象掩膜码流和所有角点信息码流及所有关键帧码流发送给解码端;其中,t=t+1中的“=”为赋值符号。
步骤七:在解码端,对接收到的所有对象掩膜码流和所有角点信息码流及所有关键帧码流进行解码,得到解码后的水下视频,该解码后的水下视频包括每帧的对象掩膜和每帧中的每个角点的横坐标、纵坐标、R通道颜色值、G通道颜色值、B通道颜色值,及所有关键帧。
步骤八:构造一个卷积神经网络以进行基于深度学习的对象精细化重建;然后将解码后的水下视频中当前待处理的第t帧定义为当前帧;其中,1≤t≤Frame。
在本实施例中,所述的步骤八中,卷积神经网络由输入卷积模块、中间残差模块以及输出卷积模块组成;输入卷积模块包括依次连接的第一卷积层、第二卷积层、第三卷积层、第四卷积层,第一卷积层的输入端接收一幅输入图像的R通道、G通道和B通道,第二卷积层的输入端接收第一卷积层的输出端输出的所有特征图,第三卷积层的输入端接收第二卷积层的输出端输出的所有特征图,第四卷积层的输入端接收第三卷积层的输出端输出的所有特征图,第四卷积层的输出端输出的所有特征图传输给中间残差模块;中间残差模块包括依次连接的第一残差层、第二残差层、第三残差层、第四残差层,第一残差层、第二残差层、第三残差层、第四残差层的结构相同,其由第1个卷积层和第2个卷积层组成,第1个卷积层的输入端作为其所在的残差层的输入端,第2个卷积层的输入端接收第1个卷积层的输出端输出的所有特征图,对输入到第1个卷积层的输入端的所有特征图与第2个卷积层的输出端输出的所有特征图进行对应元素相加操作,相加操作后得到的所有特征图由“LeakyReLU”激活后作为所在的残差层的输出端输出的所有特征图,第一残差层的输入端接收第四卷积层的输出端输出的所有特征图,第二残差层的输入端接收第一残差层的输出端输出的所有特征图,第三残差层的输入端接收第二残差层的输出端输出的所有特征图,第四残差层的输入端接收第三残差层的输出端输出的所有特征图,第四残差层的输出端输出的所有特征图传输给输出卷积模块;输出卷积模块包括依次连接的第五卷积层、第六卷积层、第七卷积层、第八卷积层,第五卷积层的输入端接收第四残差层的输出端输出的所有特征图,第六卷积层的输入端接收第五卷积层的输出端输出的所有特征图,第七卷积层的输入端接收第六卷积层的输出端输出的所有特征图,第八卷积层的输入端接收第七卷积层的输出端输出的所有特征图,第八卷积层的输出端输出结果;其中,第一卷积层、第二卷积层、第三卷积层、第四卷积层的卷积核尺寸均为3×3、卷积步长均为1、采用的激活函数均为“LeakyReLU”,第一卷积层的输入通道数为3、输出通道数为32,第二卷积层的输入通道数为32、输出通道数为32,第三卷积层的输入通道数为32、输出通道数为64,第四卷积层的输入通道数为64、输出通道数为128,第一残差层、第二残差层、第三残差层、第四残差层中的第1个卷积层的卷积核尺寸均为3×3、卷积步长均为1、输入通道数均为128、输出通道数均为128、采用的激活函数均为“LeakyReLU”,第一残差层、第二残差层、第三残差层、第四残差层中的第2个卷积层的卷积核尺寸均为3×3、卷积步长均为1、输入通道数均为128、输出通道数均为128、未激活函数,第五卷积层、第六卷积层、第七卷积层的卷积核尺寸均为3×3、卷积步长均为1、采用的激活函数均为“LeakyReLU”,第五卷积层的输入通道数为128、输出通道数为64,第六卷积层的输入通道数为64、输出通道数为32,第七卷积层的输入通道数为32、输出通道数为32,第八卷积层的卷积核尺寸为3×3、卷积步长为1、采用的激活函数均为“Sigmoid”,第八卷积层的输入通道数为32、输出通道数为3。
步骤九:将当前帧记为F'
步骤十:根据Matrix'
在本实施例中,所述的步骤十中,C'
步骤十一:判断t是否等于(k'-1)×N+1,如果t等于(k'-1)×N+1,则令C
步骤十二:令t=t+1,将解码后的水下视频中下一帧待处理的帧作为当前帧;然后返回步骤九继续执行,直到t等于k'×N+1时执行步骤十三;其中,t=t+1中的“=”为赋值符号。
步骤十三:令k'=k'+1,然后返回步骤九继续执行,直到k'等于
对本发明方法进行测试,以验证本发明方法的有效性和可行性。
本发明方法能够解决低码率下结合用户对水下视频实际应用需求的编码问题,具体为通过对水下视频对象进行编码来解决水下视频数据量庞大而水声数据传输速率有限的矛盾。为了验证本发明方法的性能,从视频网站https://www.oceannetworks.ca/中选择了Dolphin、Grayfish两个测试序列进行实验和分析,图3a给出了Dolphin测试序列的第二帧原始图像,图3b给出了Grayfish测试序列的第二帧原始图像。Dolphin、Grayfish两个测试序列的帧数为200帧,分辨率为1920×1080。图4a给出了图3a对应的仅包含对象信息的图像,图4b给出了图3b对应的仅包含对象信息的图像。在HEVC参考软件HM16.2上对本发明方法进行实验。实验电脑配置为联想90E8CTO1WW,RAM16GB,NVIDIA GTX750,Intel(R)core(TM)i5-6500CPU@3.20GHz。采用本发明方法对Dolphin、Grayfish测试序列进行处理,得到Dolphin、Grayfish测试序列各自的最终重建结果,图5a给出了图3a对应的最终重建结果,图5b给出了图3b对应的最终重建结果。
为进一步说明本发明方法的表现,采用HEVC标准作为对比方法,HEVC标准有随机接入(RA)、低时延P(LDP)和全帧内(AI)三种编码方式,由于配置不同分别可以得到不同的编码性能。出于本发明方法旨在解决水下视频对象在低码率下的编码问题,码率结果越低,越能满足条件。因此,将对比方法设置为最小码率,即当HEVC中的编码量化参数QP为51时。不同方法码率使用的比较结果如表1所示。
表1不同方法码率使用情况对比
由表1可以看出,与HEVC标准相比,无论采用何种编码方式,本发明方法都能大大节省码率,这意味着本发明方法更能满足水下低码率的要求。
出于量化最后重建结果质量的考虑,采用既考虑数据差异也考虑人眼主观感知的视频/图像质量评价方式视觉信息保真度VIF作为评价指标。使用BD-rate计算在相同VIF质量评价下本发明方法相对对比方法可以节省的码率。为了得到四个编码实验结果,将HEVC标准的编码量化参数QP分别设置为48、49、50、51,因为这样消耗的码率较小。本发明方法中的N分别设为200、100、50、25,来表示关键帧更新周期的大小改变,关键帧更新周期变化其最终重建结果与码率结果也会发生改变。采用本发明方法相对HEVC-LDP与HEVC-RA可以节省的码率如表2所示。
表2相同VIF质量评价下采用本发明方法相对对比方法可以节省的码率百分比
表2中的负值表示采用本发明方法相对对比方法在相同VIF质量评价下可以节省的码率百分比。从表2中可以看出,采用本发明方法相对对比方法在相同VIF质量评价下均可以节省码率,在低码率下具有更好的编码性能。
- 一种基于深度学习重建的水下视频对象编码方法
- 基于深度学习的水下扭曲图像重建方法