抗PD-L1/抗4-1BB双特异性抗体及其用途
文献发布时间:2023-06-19 12:16:29
背景技术
也被称为分化簇274(CD274)或B7同源体1(B7-H1)的程序性死亡配体1(PD-L1)是一种40kDa的1型跨膜蛋白,在特定事件(诸如怀孕、组织同种异体移植、自身免疫性疾病和诸如肝炎的其它疾病状态)期间,程序性死亡配体1(PD-L1)被认为在抑制免疫系统中发挥主要作用。PD-L1与PD-1或B7.1的结合传递减少CD8+T细胞在淋巴结处增殖的抑制信号,并且对所述PD-1的补充也能通过进一步由基因Bcl-2的下调介导的细胞凋亡来控制外源抗原特异性T细胞在淋巴结中的积聚。
已经表明的是,PD-L1的上调可以使恶性肿瘤逃脱宿主免疫系统。对来自肾细胞癌患者的肿瘤标本的分析发现,PD-L1的高肿瘤表达与增加的肿瘤侵袭性和增加的死亡风险相关。许多PD-L1抑制剂作为肿瘤免疫疗法正在开发中,并且在临床试验中正在表现出良好的效果。
4-1BB是TNF受体超家族(TNFRSF)的成员,并且是在免疫细胞(先天性免疫细胞和适应性免疫细胞两者)的激活后表达的共刺激分子。4-1BB在调节各种免疫细胞的活性中起重要作用。4-1BB激动剂增强免疫细胞增殖、存活、细胞因子的分泌和细胞溶解活性CD8 T细胞。许多其它研究表明,4-1BB的激活增强免疫应答以消除小鼠中的肿瘤。因此,这表明4-1BB是癌症免疫学中有希望的靶点分子。虽然它们具有抗肿瘤功效,但是抗4-1BB抗体在临床应用中诱导严重的肝毒性。
发明内容
本公开提供了一种能够有效地阻断PD-L1与其受体PD-1之间以及4-1BB与其配体之间的相互作用的抗PD-L1/抗4-1BB双特异性抗体。该双特异性抗体可以对PD-L1蛋白(例如,人PD-L1蛋白)和4-1BB蛋白(例如,人4-1BB蛋白)两者具有高结合亲和力。
抗PD-L1/抗4-1BB双特异性抗体可以包括:抗PD-L1抗体或其抗原结合片段作为PD-L1靶向部分,能够特异性地识别和/或结合到PD-L1蛋白;以及抗4-1BB抗体或其抗原结合片段作为4-1BB靶向部分,能够特异性地识别和/或结合到4-1BB蛋白。
抗PD-L1/抗4-1BB双特异性抗体可以包括抗PD-L1抗体或其抗原结合片段作为PD-L1靶向部分。
在实施例中,包括在双特异性抗体中的抗PD-L1抗体或其片段可以特异性地结合到PD-L1(例如,人PD-L1)蛋白的免疫球蛋白C(IgC)结构域。在一些实施例中,IgC结构域由人PD-L1蛋白的氨基酸残基133-225组成。在一些实施例中,抗PD-L1抗体或其片段可以结合到人PD-L1蛋白的氨基酸残基Y134、K162和N183中的至少一个。在一些实施例中,抗PD-L1抗体或其片段不结合到PD-L1蛋白的免疫球蛋白V(IgV)结构域,例如,IgV结构域由人PD-L1蛋白的氨基酸残基19-127组成。例如,人PD-L1蛋白可以选自于由由基因库(GenBank)登录号NP_001254635.1、NP_001300958.1、NP_054862.1等表示的蛋白质组成的组,但是可以不限于此。这些抗PD-L1抗体可以用于诸如治疗各种类型的癌症等的治疗目的,并且也可以用于诊断和预后目的。在实施例中,抗PD-L1抗体或其片段能够对人PD-L1蛋白具有特异性。
抗PD-L1/抗4-1BB双特异性抗体包括抗PD-L1抗体或其抗原结合片段以及抗4-1BB抗体或其抗原结合片段,其中,
抗PD-L1抗体或其抗原结合片段能够特异性地结合到人程序性死亡配体1(PD-L1)蛋白的免疫球蛋白C(IgC)结构域,其中,IgC结构域由氨基酸残基133-225组成;
抗PD-L1抗体或其抗原结合片段包括:VH CDR1,具有SEQ ID NO:1的氨基酸序列;VH CDR2,具有选自于由SEQ ID NO:2和SEQ ID NO:3组成的组的氨基酸序列;VH CDR3,具有选自于由SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:262、SEQ ID NO:263、SEQ ID NO:264、SEQID NO:265、SEQ ID NO:266和SEQ ID NO:267组成的组的氨基酸序列;VL CDR1,具有SEQ IDNO:6、SEQ ID NO:268和SEQ ID NO:269的氨基酸序列;VL CDR2,具有SEQ ID NO:7的氨基酸序列;以及VL CDR3,具有SEQ ID NO:8、SEQ ID NO:270、SEQ ID NO:271和SEQ ID NO:272的氨基酸序列;并且
抗4-1BB抗体或其抗原结合片段包括:VH CDR1,具有选自于由SEQ ID NO:10和SEQID NO:11组成的组的氨基酸序列;VH CDR2,具有选自于由SEQ ID NO:12和SEQ ID NO:13组成的组的氨基酸序列;VH CDR3,具有选自于由SEQ ID NO:14、SEQ ID NO:15、SEQ ID NO:16和SEQ ID NO:17组成的组的氨基酸序列;VL CDR1,具有SEQ ID NO:18的氨基酸序列;VLCDR2,具有SEQ ID NO:19的氨基酸序列;以及VL CDR3,具有SEQ ID NO:20的氨基酸序列。
在实施例中,抗PD-L1抗体或其抗原结合片段包括:VH CDR1,具有SEQ ID NO:1的氨基酸序列;VH CDR2,具有选自于由SEQ ID NO:2和SEQ ID NO:3组成的组的氨基酸序列;VH CDR3,具有选自于由SEQ ID NO:4和SEQ ID NO:5组成的组的氨基酸序列;VL CDR1,具有SEQ ID NO:6的氨基酸序列;VLCDR2,具有SEQ ID NO:7的氨基酸序列;以及VL CDR3,具有SEQ ID NO:8的氨基酸序列。
在实施例中,抗PD-L1抗体或其抗原结合片段能够结合到PD-L1蛋白的氨基酸残基Y134、K162和N183中的至少一个。
在实施例中,抗PD-L1抗体或其抗原结合片段能够结合到PD-L1蛋白的氨基酸残基Y134、K162和N183。
在实施例中,抗PD-L1抗体或其抗原结合片段不结合到PD-L1蛋白的免疫球蛋白V(IgV)结构域,其中,IgV结构域由氨基酸残基19-127组成。
在实施例中,抗PD-L1/抗4-1BB双特异性抗体根据细胞表面上表达的PD-L1激活4-1BB信号或免疫应答。
在实施例中,抗PD-L1抗体或其抗原结合片段以及抗4-1BB抗体或其抗原结合片段中的每个独立地是嵌合抗体、人源化抗体或完全人抗体。
抗PD-L1/抗4-1BB双特异性抗体包括抗PD-L1抗体或其抗原结合片段以及抗4-1BB抗体或其抗原结合片段,其中,
抗PD-L1抗体或其抗原结合片段包括:
(1)VH CDR1,具有SEQ ID NO:1的氨基酸序列;
(2)VH CDR2,具有选自于由SEQ ID NO:2和SEQ ID NO:3组成的组的氨基酸序列;
(3)VH CDR3,具有选自于由SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:262、SEQ IDNO:263、SEQ ID NO:264、SEQ ID NO:265、SEQ ID NO:266和SEQ ID NO:267组成的组的氨基酸序列;
(4)VL CDR1,具有SEQ ID NO:6、SEQ ID NO:268和SEQ ID NO:269的氨基酸序列;
(5)VL CDR2,具有SEQ ID NO:7的氨基酸序列;以及
(6)VL CDR3,具有SEQ ID NO:8、SEQ ID NO:270、SEQ ID NO:271和SEQ ID NO:272的氨基酸序列,并且
抗4-1BB抗体或其抗原结合片段包括:
(i)VH CDR1,具有选自于由SEQ ID NO:10和SEQ ID NO:11组成的组的氨基酸序列;
(ii)VH CDR2,具有选自于由SEQ ID NO:12和SEQ ID NO:13组成的组的氨基酸序列;
(iii)VH CDR3,具有选自于由SEQ ID NO:14、SEQ ID NO:15、SEQ ID NO:16和SEQID NO:17组成的组的氨基酸序列;
(iv)VL CDR1,具有SEQ ID NO:18的氨基酸序列;
(v)VL CDR2,具有SEQ ID NO:19的氨基酸序列;以及
(vi)VL CDR3,具有SEQ ID NO:20的氨基酸序列。
抗PD-L1抗体或其片段可以包括:(1)VH CDR1,具有SEQ ID NO:1的氨基酸序列;(2)VH CDR2,具有选自于由SEQ ID NO:2和SEQ ID NO:3组成的组的氨基酸序列;(3)VHCDR3,具有选自于由SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:262、SEQ ID NO:263、SEQ IDNO:264、SEQ ID NO:265、SEQ ID NO:266和SEQ ID NO:267组成的组的氨基酸序列;(4)VLCDR1,具有SEQ ID NO:6、SEQ ID NO:268和SEQ ID NO:269的氨基酸序列;(5)VL CDR2,具有SEQ ID NO:7的氨基酸序列;以及(6)VL CDR3,具有SEQ ID NO:8、SEQ ID NO:270、SEQ IDNO:271和SEQ ID NO:272的氨基酸序列。例如,抗PD-L1抗体或其片段可以包括:VH CDR1,具有SEQ ID NO:1的氨基酸序列;VH CDR2,具有SEQ ID NO:2或SEQ ID NO:3的氨基酸序列;(3)VH CDR3,具有SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:262、SEQ ID NO:263、SEQ ID NO:264、SEQ ID NO:265、SEQ ID NO:266或SEQ ID NO:267的氨基酸序列;VL CDR1,具有SEQ IDNO:6、SEQ ID NO:268或SEQ ID NO:269的氨基酸序列;VL CDR2,具有SEQ ID NO:7的氨基酸序列;以及VL CDR3,具有SEQ ID NO:8、SEQ ID NO:270、SEQ ID NO:271或SEQ ID NO:272的氨基酸序列。
在实施例中,抗PD-L1抗体或其抗原结合片段包括:VH CDR1,具有SEQ ID NO:1的氨基酸序列;VH CDR2,具有选自于由SEQ ID NO:2和SEQ ID NO:3组成的组的氨基酸序列;VH CDR3,具有选自于由SEQ ID NO:4和SEQ ID NO:5组成的组的氨基酸序列;VL CDR1,具有SEQ ID NO:6的氨基酸序列;VL CDR2,具有SEQ ID NO:7的氨基酸序列;以及VL CDR3,具有SEQ ID NO:8的氨基酸序列。
抗PD-L1/抗4-1BB双特异性抗体可以包括抗4-1BB抗体或其抗原结合片段作为4-1BB靶向部分。在实施例中,抗4-1BB抗体或其片段可以特异性地结合到4-1BB(例如,人4-1BB)蛋白。
抗4-1BB抗体或其抗原结合片段能够在哺乳动物中增强免疫应答和/或治疗肿瘤(癌症)。抗4-1BB抗体或其抗原结合片段的特征在于与先前存在的抗4-1BB抗体相比,仅在肿瘤微环境(TME)中定位和/或激活并且/或者显著地降低肝毒性,并且保持增强的免疫应答增强和/或肿瘤治疗的功效。
例如,人4-1BB蛋白可以选自于由由NCBI登录号NP_001552等表示的蛋白质组成的组,但是可以不限于此。这些抗4-1BB抗体可以用于诸如治疗各种类型的癌症等的治疗目的,并且也可以用于诊断和预后目的。
在实施例中,抗4-1BB抗体或其片段能够对人4-1BB蛋白具有特异性。抗4-1BB抗体或其片段可以包括:(i)VH CDR1,具有选自于由SEQ ID NO:10和SEQ ID NO:11组成的组的氨基酸序列;(ii)VH CDR2,具有选自于由SEQ ID NO:12和SEQ ID NO:13组成的组的氨基酸序列;(iii)VH CDR3,具有选自于由SEQ ID NO:14、SEQ ID NO:15、SEQ ID NO:16和SEQ IDNO:17组成的组的氨基酸序列;(iv)VL CDR1,具有SEQ ID NO:18的氨基酸序列;(v)VLCDR2,具有SEQ ID NO:19的氨基酸序列;以及(vi)VL CDR3,具有SEQ ID NO:20的氨基酸序列。例如,抗4-1BB抗体或其片段可以包括:VH CDR1,具有SEQ ID NO:10或SEQ ID NO:11的氨基酸序列;VH CDR2,具有SEQ ID NO:12或SEQ ID NO:13的氨基酸序列;VH CDR3,具有SEQID NO:14、SEQ ID NO:15、SEQ ID NO:16或SEQ ID NO:17的氨基酸序列;VL CDR1,具有SEQID NO:18的氨基酸序列;VL CDR2,具有SEQ ID NO:19的氨基酸序列;以及VL CDR3,具有SEQID NO:20的氨基酸序列。
在实施例中,抗PD-L1抗体或其抗原结合片段以及抗4-1BB抗体或其抗原结合片段中的每个独立地是嵌合抗体、人源化抗体或完全人抗体。
在实施例中,其中,抗PD-L1抗体或其抗原结合片段以及抗4-1BB抗体或其抗原结合片段是人源化抗体。
在实施例中,抗PD-L1抗体或其抗原结合片段包括:重链可变区,包括选自于由SEQID NO:103和SEQ ID NO:104组成的组的氨基酸序列;或者多肽,与选自于由SEQ ID NO:103和SEQ ID NO:104组成的组的氨基酸序列具有至少90%序列同一性。
在实施例中,抗PD-L1抗体或其抗原结合片段包括:轻链可变区,包括选自于由SEQID NO:105和SEQ ID NO:106组成的组的氨基酸序列;或者肽,与选自于由SEQ ID NO:105和SEQ ID NO:106组成的组的氨基酸序列具有至少90%序列同一性。
在实施例中,抗4-1BB抗体或其抗原结合片段包括:重链可变区,包括选自于由SEQID NO:21、SEQ ID NO:22、SEQ ID NO:23和SEQ ID NO:24组成的组的氨基酸序列;或者多肽,与选自于由SEQ ID NO:21、SEQ ID NO:22、SEQ ID NO:23和SEQ ID NO:24组成的组的氨基酸序列具有至少90%序列同一性。
在实施例中,抗4-1BB抗体或其抗原结合片段包括:轻链可变区,包括选自于由SEQID NO:25和SEQ ID NO:26组成的组的氨基酸序列;或者肽,与选自于由SEQ ID NO:25和SEQID NO:26组成的组的氨基酸序列具有至少90%序列同一性。
在实施例中,抗PD-L1/抗4-1BB双特异性抗体根据细胞表面上表达的PD-L1激活4-1BB信号。
在实施例中,抗PD-L1/抗4-1BB双特异性抗体呈IgG-scFv形式的形式。
抗PD-L1/抗4-1BB双特异性抗体可以包括:重组分,包括选自于由SEQ ID NO:27、SEQ ID NO:29、SEQ ID NO:31、SEQ ID NO:33、SEQ ID NO:35、SEQ ID NO:37、SEQ ID NO:39、SEQ ID NO:41和SEQ ID NO:43组成的组的氨基酸序列;以及轻组分,包括选自于由SEQID NO:28、SEQ ID NO:30、SEQ ID NO:32、SEQ ID NO:34、SEQ ID NO:36、SEQ ID NO:38、SEQID NO:40、SEQ ID NO:42和SEQ ID NO:44组成的组的氨基酸序列。
另一实施例提供了一种包括如上所述的双特异性抗体的药物组合物。药物组合物还可以包括药学上可接受的载体。药物组合物可以用于治疗和/或预防癌症。
另一实施例提供了一种治疗和/或预防有需要的受试者的癌症的方法,所述方法包括向受试者施用药学有效量的双特异性抗体或药物组合物。所述方法还可以包括在施用步骤之前鉴定需要治疗和/或预防癌症的受试者的步骤。
另一实施例提供了一种双特异性抗体或药物组合物在治疗和/或预防癌症中的用途。另一实施例提供了一种双特异性抗体在制备用于治疗和/或预防癌症的药物组合物中的用途。
在这里提供的药物组合物、方法和/或用途中,癌症可以是实体癌症或血癌,优选地实体癌症。
另一实施例提供了一种用于在生物样品中检测PD-L1、4-1BB或同时地检测其两者的组合物,所述组合物包括双特异性抗体。另一实施例提供了一种在生物样品中检测PD-L1、4-1BB或同时地检测其两者的方法,所述方法包括使生物样品与双特异性抗体接触;以及检测(测量)双特异性抗体与PD-L1、4-1BB或其两者之间的抗原-抗体反应(结合)。
检测的方法还可以包括以下步骤:在检测步骤之后,当检测到抗原-抗体反应时,确定PD-L1、4-1BB或其两者存在于生物样品中;以及/或者当未检测到抗原-抗体反应时,确定生物样品中没有PD-L1、4-1BB或其两者(PD-L1、4-1BB或其两者不存在于生物样品中)。
另一实施例提供了一种用于诊断与PD-L1、4-1BB或其两者相关的疾病的药物组合物,所述组合物包括双特异性抗体。在另一实施例中,提供了一种双特异性抗体用于诊断与PD-L1、4-1BB或其两者相关的疾病的用途。
另一实施例提供了一种诊断与PD-L1、4-1BB或其两者相关的疾病的方法,所述方法包括以下步骤:使从患者获得的生物样品与双特异性抗体接触;以及检测生物样品中的抗原-抗体反应或测量生物样品中的抗原-抗体反应的水平。在一些实施例中,所述方法还可以包括以下步骤:使正常样品与双特异性抗体接触;以及测量正常样品中的抗原-抗体反应的水平。另外,所述方法还可以包括在测量步骤之后比较生物样品中和正常样品中的抗原-抗体反应的水平。另外,在检测步骤或比较步骤之后,所述方法还可以包括当在生物样品中检测到抗原-抗体反应时或者当生物样品中的抗原-抗体反应的水平比正常样品中的抗原-抗体反应的水平高时,将患者确定为患有与PD-L1、4-1BB或其两者相关的疾病的患者。
与PD-L1、4-1BB或其两者相关的疾病可以是与PD-L1、4-1BB或其两者的激活(例如,异常激活或过度激活)和/或过度产生(过表达)相关的疾病。例如,疾病可以是如上所述的癌症。
实施例提供了一种编码双特异性抗体的多核苷酸。具体地,实施例提供了一种编码呈IgG-scFv形式的双特异性抗体的重链的多核苷酸,IgG-scFv形式包括全长IgG和连接到全长IgG的C-末端和/或N-末端的scFv。其它实施例提供了一种编码呈IgG-scFv形式的双特异性抗体的轻链的多核苷酸。另一实施例提供了一种重组载体,重组载体包括编码双特异性抗体的重链的多核苷酸、编码双特异性抗体的轻链的多核苷酸或其两者。另一实施例提供了一种用重组载体转染的重组细胞。
另一实施例提供了一种制备双特异性抗体的方法,所述方法包括在细胞中表达编码双特异性抗体的重链的多核苷酸和编码双特异性抗体的轻链的多核苷酸。表达多核苷酸的步骤可以通过在允许多核苷酸的表达的条件下培养包括多核苷酸(例如,在重组载体中)的细胞来进行。所述方法还可以包括在表达或培养步骤之后从细胞培养物中分离和/或纯化双特异性抗体。
附图说明
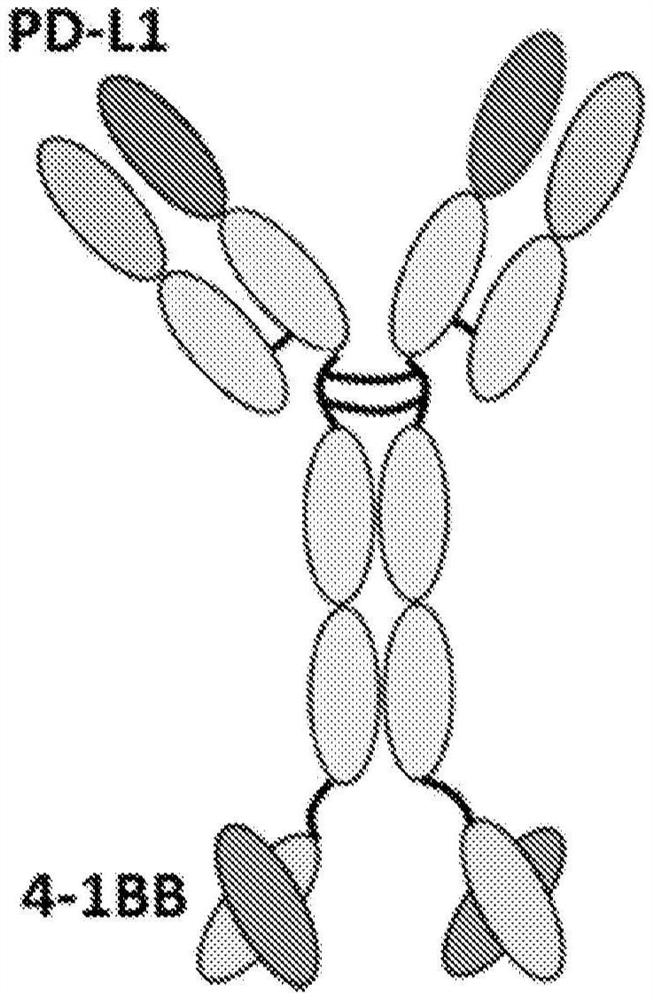
图1A和图1B示意性地示出了根据实施例的抗PD-L1/抗4-1BB双特异性抗体。
图2示意性地示出了根据实施例的抗PD-L1/抗4-1BB双特异性抗体的作用机制。
图3图示了关于PD-L1变体的验证的选择标准,以鉴定Hu1210-41结合所需的残基。
图4示出了根据实施例的参与同抗PD-L1抗体的结合的Y134残基(球体)、K162残基(球体)和N183残基(球体)的位置。
图5示出了根据实施例的抗4-1BB抗体可以以高亲和力结合到人4-1BB。
图6示出了根据实施例的抗4-1BB抗体可以有效地结合到哺乳动物细胞上表达的4-1BB。
图7A-图7B示出了示出通过DACE(双重抗原捕获ELISA)测量的根据实施例的抗PD-L1/抗4-1BB双特异性抗体与人PD-L1和人4-1BB的结合的曲线图。
图8示出了根据实施例的抗PD-L1/抗4-1BB双特异性抗体在人血清中是稳定的。
图9A-图9F示出了根据实施例的双特异性抗体PD-L1x4-1BB依据靶细胞上的PD-L1表达来激活4-1BB信号。
图10A和图10B示出了根据实施例的抗PD-L1/抗4-1BB双特异性抗体的PBMC测定结果。它也示出了示出根据实施例的抗PD-L1/抗4-1BB双特异性抗体的T细胞促进激活的曲线图。
图11示出了示出根据实施例的抗PD-L1/抗4-1BB双特异性抗体的肿瘤生长抑制作用的曲线图。
具体实施方式
定义
将注意的是,术语“一”或“一个(种)”实体指一个(种)或更多个(种)所述实体,例如,“抗体”被理解为表示一个(种)或更多个(种)抗体。如此,术语“一(或一个(种))”、“一个(种)或更多个(种)”和“至少一个(种/者)”可以在此互换地使用。
如在此使用的,术语“多肽”旨在涵盖单数的“多肽”以及复数的“多肽”,并且指由通过酰胺键(也称为肽键)线性地连接的单体(氨基酸)组成的分子。术语“多肽”指两个或更多个氨基酸的任何一条链或多条链,并且不指产物的具体长度。因此,肽、二肽、三肽、寡肽、“蛋白质”、“氨基酸链”或者用于指两个或更多个氨基酸的一条链或多条链的任何其它术语包括在“多肽”的定义中,术语“多肽”可以用于代替这些术语中的任何一个,或者与这些术语中的任何一个互换地使用。术语“多肽”还旨在指多肽的表达后修饰的产物,所述表达后修饰包括而不限于糖基化、乙酰化、磷酸化、酰胺化、通过已知的保护/阻断基团的衍生化、蛋白水解裂解或通过非天然地存在的氨基酸的修饰。多肽可以来源于天然生物来源或通过重组技术产生,但是不必从指定的核苷酸序列翻译。它可以以包括通过化学合成的任何方式产生。
如在此使用的关于细胞、核酸(诸如DNA或RNA)的术语“分离的”指分别与存在于大分子的天然来源中的其它DNA或RNA分离的分子。如在此使用的术语“分离的”也指当通过重组DNA技术生产时基本上不含细胞材料、病毒材料或培养基的核酸或肽或者当化学地合成时基本上不含化学前驱体或其它化学品的核酸或肽。此外,“分离的核酸”意在包括不以片段自然存在且不会以自然状态被发现的核酸片段。术语“分离的”在此也用于指与其它细胞蛋白质或组织分离的细胞或多肽。分离的多肽意在涵盖纯化的多肽和重组的多肽两者。
如在此使用的,术语“重组”在其涉及多肽或多核苷酸时意指非天然存在的多肽或多核苷酸的形式,其非限制性示例可以通过组合正常不会存在于一起的多核苷酸或多肽来产生。
“同源性”或“同一性”或“相似度(相似性)”指两个肽之间或两个核酸分子之间的序列相似度。可以通过比较在每个序列中可以用于比较目的比对的位置来确定同源性。当比较序列中的位置被相同的碱基或氨基酸占据时,那么分子在所述位置处是同源的。序列之间的同源性的程度是序列共有的匹配或同源位置的数目的函数。“不相关的”或“非同源的”序列与本公开的序列中的一个具有小于40%的同一性,但优选小于25%的同一性。
多核苷酸或多核苷酸区域(或者多肽或多肽区域)与另一序列具有一定百分比(例如,60%、65%、70%、75%、80%、85%、90%、95%、98%或99%)的“序列同一性”是指当比对时,比较两个序列中的所述百分比的碱基(或氨基酸)是相同的。所述比对和百分比同源性或序列同一性可以使用本领域已知的软件程序(例如,Ausubel等人编(2007)CurrentProtocols in Molecular Biology中描述的软件程序)来确定。优选地,使用默认参数进行比对。一种比对程序是使用默认参数的BLAST。具体地,程序是BLASTN和BLASTP,使用以下默认参数:Genetic code=standard;filter=none;strand=both;cutoff=60;expect=10;Matrix=BLOSUM62;Descriptions=50sequences;sort by=HIGH SCORE;Databases=non-redundant,GenBank+EMBL+DDBJ+PDB+GenBank CDS translations+Swiss Protein+SPupdate+PIR。生物学上等同的多核苷酸是具有上述特定百分比同源性且编码具有相同或相似的生物活性的多肽的多核苷酸。
术语“等同核酸或多核苷酸(等价核酸或多核苷酸)”指具有与核酸或其互补体的核苷酸序列具有一定程度的同源性或序列同一性的核苷酸序列的核酸。双链核酸的同源物旨在包括具有核苷酸序列的核酸,所述核苷酸序列与双链核酸或其互补体具有一定程度的同源性。在一方面,核酸的同源物能够与核酸或其互补体杂交。同样地,“等同多肽(等价多肽)”指与参考多肽的氨基酸序列具有一定程度的同源性或序列同一性的多肽。在一些方面,序列同一性是至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少98%或至少99%。在一些方面,等同多肽或多核苷酸具有与参考多肽或多核苷酸相比的一个、两个、三个、四个或五个添加、缺失、取代及其组合。在一些方面,等同序列保留参考序列的活性(例如,表位结合)或结构(例如,盐桥)。
杂交反应可以在不同的“严谨性”条件下进行。通常,低严谨性杂交反应在约40℃下在约10xSSC或等效离子强度/温度的溶液中进行。中严谨性杂交通常在约50℃下在约6xSSC中进行,高严谨性杂交反应通常在约60℃下在约1xSSC中进行。杂交反应也可以在本领域技术人员已知的“生理条件”下进行。生理条件的非限制性示例是通常在细胞中发现的温度、离子强度、pH和Mg
多核苷酸由四个核苷酸碱基的特定序列组成:腺嘌呤(A);胞嘧啶(C);鸟嘌呤(G);胸腺嘧啶(T);以及当多核苷酸是RNA时尿嘧啶(U)替代胸腺嘧啶。因此,术语“多核苷酸序列”是多核苷酸分子的字母表示。所述字母表示可以输入到具有中央处理单元的计算机中的数据库中,并且用于诸如功能基因组学和同源性搜索的生物信息学应用。术语“多态性”指多于一种形式的基因或其部分的共存。存在至少两种不同的形式(即,两种不同的核苷酸序列)的基因的一部分被称为“基因的多态性区域”。多态性区域可以是单个核苷酸,其在不同的等位基因中具有不同的同一性。
术语“多核苷酸”和“寡核苷酸”可互换地使用,并且指任何长度的核苷酸(脱氧核糖核苷酸或核糖核苷酸或其类似物)的聚合形式。多核苷酸可以具有任何三维结构,并且可以执行已知或未知的任何功能。以下是多核苷酸的非限制性示例:基因或基因片段(例如,探针、引物、EST或SAGE标签)、外显子、内含子、信使RNA(mRNA)、转运RNA、核糖体RNA、核酶、cDNA、dsRNA、siRNA、miRNA、重组多核苷酸、分支多核苷酸、质粒、载体、任何序列的分离的DNA、任何序列的分离的RNA、核酸探针和引物。多核苷酸可以包括诸如甲基化的核苷酸和核苷酸类似物的修饰的核苷酸。如果存在,可以在多核苷酸组装之前或之后对核苷酸结构进行修饰。核苷酸的序列可以被非核苷酸组分中断。可以在聚合后进一步修饰多核苷酸,诸如通过与标记组分缀合。所述术语还指双链和单链分子两者。除非另外说明或要求,否则本公开的作为多核苷酸的任何实施例涵盖双链形式以及已知或预测构成双链形式的两种互补单链形式中的每个两者。
术语“编码”当其应用于多核苷酸时,指被称为“编码”多肽的多核苷酸如果处于其天然状态或当通过本领域技术人员已知的方法被操作时,多核苷酸可以被转录和/或翻译以产生针对多肽和/或其片段的mRNA。反义链是这种核酸的互补体,从反义链可以推断出编码序列。
如在此使用的,“抗体”或“抗原结合多肽”指特异性地识别且结合到抗原的多肽或多肽复合物。抗体可以是完整抗体以及其任何抗原结合片段或单链。因此,术语“抗体”包括包含分子的任何蛋白质或肽,所述分子包括免疫球蛋白分子的具有结合到抗原的生物活性的至少一部分。这样的示例包括但不限于重链或轻链的互补决定区(CDR)或者其配体结合部分、重链可变区或轻链可变区、重链恒定区或轻链恒定区、框架(FR)区或者其任何部分或者结合蛋白的至少一部分。
如在此使用的,术语“抗体片段”或“抗原结合片段”是诸如F(ab')
“单链可变片段”或“scFv”指免疫球蛋白的重链(V
术语“抗体”涵盖可以在生物化学上区分的各种广泛种类的多肽。本领域技术人员将理解的是,重链被分类为gamma、mu、alpha、delta或epsilon(γ、μ、α、δ、ε)以及它们之中的一些亚类(例如,γl-γ4)。所述链的性质分别将抗体的“种类”确定为IgG、IgM、IgA、IgG或IgE。免疫球蛋白亚类(同种型)(例如,IgG1、IgG2、IgG3、IgG4、IgG5等)被充分表征且已知被赋予功能特异性。鉴于本公开,这些种类和同种型中的每种的修饰形式对于技术人员来说是容易辨别的,因此,它们在本公开的范围内。所有免疫球蛋白种类明确地在本公开的范围内,以下讨论通常将针对免疫球蛋白分子的IgG种类。关于IgG,标准免疫球蛋白分子包括分子量是近似23,000道尔顿的两个相同的轻链多肽和分子量是53,000至70,000的两个相同的重链多肽。四条链通常以“Y”构型通过二硫键连接,其中,轻链从“Y”的口处开始且延续通过可变区而包围重链。
公开的抗体、抗原结合多肽、其变体或衍生物包括但不限于多克隆、单克隆、多特异性、人、人源化、灵长类化或嵌合抗体、单链抗体、表位结合片段、例如Fab、Fab'和F(ab')
轻链被分类为kappa或lambda(κ、λ)。每种重链种类可以与kappa或lambda轻链结合。通常,当免疫球蛋白由杂交瘤、B细胞或基因工程化宿主细胞产生时,轻链和重链彼此共价结合,并且两条重链的“尾”部分通过共价二硫连接或非共价连接彼此结合。在重链中,氨基酸序列从Y构型的分叉末端处的N-末端延伸至每条链的底部处的C-末端。
轻链和重链两者被分为结构和功能同源性的区域。术语“恒定”和“可变”在功能上使用。在这方面,将理解的是,轻(VL)链部分与重(VH)链部分两者的可变结构域决定抗原识别和特异性。相反地,轻链(CK)和重链(CH1、CH2或CH3)的恒定结构域赋予重要生物性质(诸如分泌、经胎盘移动性(transplacental mobility)、Fc受体结合、补体结合等)。按照惯例,恒定区结构域的编号随着它们变得更远离抗体的抗原结合位点或氨基末端而增加。N-末端部分是可变区,并且C-末端部分是恒定区;CH3和CK结构域实际上分别包括重链和轻链的羧基-末端。
如上所指示的,可变区允许抗体选择性地识别且特异性地结合抗原上的表位。即,抗体的VL结构域和VH结构域或者互补决定区(CDR)的子集组合以形成限定三维抗原结合位点的可变区。所述四级抗体结构形成存在于Y每个臂的端部处的抗原结合位点。更具体地,抗原结合位点由在VH链和VL链中的每个上的三个CDR(即,CDR-H1、CDR-H2、CDR-H3、CDR-L1、CDR-L2和CDR-L3)限定。在一些情况下,完整的免疫球蛋白分子可以仅由重链组成,而没有轻链,例如,来源于骆驼科物种或基于骆驼科的免疫球蛋白改造的某些免疫球蛋白分子。见例如Hamers-Casterman等人,Nature 363:446-448(1993)。
在天然存在的抗体中,当抗体在含水环境中呈现其三维构型时,存在于每个抗原结合结构域中的六个“互补决定区”或“CDR”是短的、非连续的氨基酸序列,所述氨基酸被特异性地定位以形成抗原结合结构域。被称为“框架”区的抗原结合结构域中的其余氨基酸显示出小的分子间可变性。框架区主要采用β-折叠构象,CDR形成环,所述环连接β-折叠结构且在一些情况下形成β-折叠结构的一部分。因此,框架区用于形成支架,所述支架提供通过链间、非共价相互作用将CDR以正确取向定位。由所定位的CDR形成的抗原结合结构域限定与免疫反应性抗原上的表位互补的表面。所述互补表面促进抗体与其同源表位的非共价结合。由于分别包括CDR和框架区的氨基酸已经被精确地定义(见www.bioinf.org.uk:Dr.Andrew C.R.Martin团队;“有免疫学意义的蛋白质的序列(Sequences ofProteins ofImmunological Interest),”Kabat,E.等人,美国卫生与公共事业部(U.S.Department ofHealth and Human Services),(1983);以及Chothia和Lesk,分子生物学杂志(J.MoI.Biol.),196:901-917(1987)),因此分别包括CDR和框架区的氨基酸可以由本领域普通技术人员针对任何给定的重链可变区或轻链可变区容易地鉴别。
在本领域内使用和/或接受的术语存在两个或更多个定义的情况下,除非明确地相反说明,否则如在此使用的术语的定义旨在包括所有这些含义。具体示例是使用术语“互补决定区”(“CDR”)来描述在重链多肽与轻链多肽两者的可变区内所发现的非连续抗原结合位点。该特定区域已经被其全部内容通过引用包含于此的Kabat等人,美国卫生与公共事业部(U.S.Dept.ofHealth and Human Services),“具有免疫学意义的蛋白质的序列(Sequences of Proteins ofImmunological Interest)”(1983)以及Chothia等人,分子生物学杂志(J.MoI.Biol.),196:901-917(1987)所描述。根据Kabat和Chothia的CDR定义包括当彼此比较时氨基酸残基的重叠或子集。然而,应用任一定义来指抗体或其变体的CDR都旨在处于如在此所定义且使用的术语的范围内。涵盖由以上引用的参考文献中的每个所定义的CDR的适当氨基酸残基阐述在下表中作为比较。涵盖特定CDR的确切残基数将根据CDR的序列和大小而变化。在给定抗体的可变区氨基酸序列的情况下,本领域技术人员可以常规地确定哪些残基包括特定CDR。
[表1]
Kabat等人还定义了适用于任何抗体的可变结构域序列的编号系统。本领域普通技术人员可以在不依赖于序列本身之外的任何实验数据的情况下毫无疑义地将此“Kabat编号”系统分配到任何可变结构域序列。如在此使用的,“Kabat编号”指由Kabat等人,美国卫生与公共事业部(U.S.Dept.ofHealth and Human Services),“具有免疫学意义的蛋白质的序列(Sequence ofProteins of Immunological Interest)”(1983)所阐述的编号系统。
除了上表之外,Kabat编号系统描述了如下的CDR区:CDR-H1在近似氨基酸31处(即,在第一个半胱氨酸残基后大约9个残基处)开始,包括大约5个至7个氨基酸,并且在下一个色氨酸残基处结束。CDR-H2在CDR-H1结束后的第15个残基处开始,包括大约16个至19个氨基酸,并且在下一个精氨酸或赖氨酸残基处结束。CDR-H3在CDR-H2结束后大约三十三个氨基酸残基处开始;包括3个至25个氨基酸;并且以序列W-G-X-G结束,其中,X是任何氨基酸。CDR-L1在大约残基24处(即,在半胱氨酸残基后)开始;包括大约10个至17个残基;并且在下一个色氨酸残基处结束。CDR-L2在CDR-L1结束后大约十六个残基处开始,并且包括大约7个残基。CDR-L3在CDR-L2结束后大约第三十三个残基处(即,在半胱氨酸残基后)开始;包括大约7个至11个残基,并且以序列F或W-G-X-G结束,其中,X是任何氨基酸。
在此公开的抗体可以来自包括鸟类和哺乳动物的任何动物来源。优选地,抗体是人、鼠类、驴、兔、山羊、豚鼠、骆驼、美洲驼、马或鸡抗体。在另一实施例中,可变区可以来源于软骨鱼纲(例如,来自鲨鱼)。
如在此使用的,术语“重链恒定区”包括来源于免疫球蛋白重链的氨基酸序列。包括重链恒定区的多肽包括以下中的至少一个:CH1结构域、铰链(例如,上铰链区、中铰链区和/或下铰链区)结构域、CH2结构域、CH3结构域或者其变体或片段。例如,用于公开中使用的抗原结合多肽可以包括:多肽链,包括CH1结构域;多肽链,包括铰链结构域的至少一部分、CH1结构域和CH2结构域;多肽链,包括CH1结构域和CH3结构域;多肽链,包括铰链结构域的至少一部分、CH1结构域和CH3结构域;或者多肽链,包括铰链结构域的至少一部分、CH1结构域、CH2结构域和CH3结构域。在另一实施例中,公开的多肽包括包含CH3结构域的多肽链。此外,用于在公开中使用的抗体可以缺少CH2结构域的至少一部分(例如,CH2结构域的全部或部分)。如上所述,本领域普通技术人员将理解的是,重链恒定区可以被修饰为使得它们在氨基酸序列方面与天然地存在的免疫球蛋白分子不同。
在此公开的抗体的重链恒定区可以来源于不同的免疫球蛋白分子。例如,多肽的重链恒定区可以包括源自IgG1分子的CH1结构域和源自IgG3分子的铰链区。在另一示例中,重链恒定区可以包括部分源自IgG1分子且部分源自IgG3分子的铰链区。在另一示例中,重链部分可以包括部分源自IgG1分子且部分源自IgG4分子的嵌合铰链。
如在此使用的,术语“轻链恒定区”包括源自抗体轻链的氨基酸序列。优选地,轻链恒定区包括恒定kappa结构域和恒定lambda结构域中的至少一种。
“轻链-重链对”指可以通过二硫键在轻链的CL结构域与重链的CH1结构域之间形成二聚体的轻链和重链的集合。
如前所述,各种免疫球蛋白种类的恒定区的亚结构和三维构型是已知的。如在此使用的,术语“VH结构域”包括免疫球蛋白重链的氨基末端可变结构域,术语“CH1结构域”包括免疫球蛋白重链的第一(大部分氨基末端)恒定区结构域。CH1结构域与VH结构域相邻,并且在免疫球蛋白重链分子的铰链区的氨基末端。
如在此使用的,术语“CH2结构域”包括例如使用常规编号方案从抗体的约残基244至残基360延伸的重链分子的一部分(残基244至360,Kabat编号系统;以及残基231-340,EU编号系统;见Kabat等人,美国健康与公共事业部(U.S.Dept.of Health and HumanServices),“具有免疫学意义的蛋白质的序列(Sequences of Proteins ofImmunological Interest)”(1983))。因为CH2结构域不与另一结构域紧密配对,所以CH2结构域是独特的。而是将两个N-连接的分支碳水化合物链插置在完整天然IgG分子的两个CH2结构域之间。还充分证明CH3结构域从CH2结构域延伸到IgG分子的C-末端且包括大约108个残基。
如在此使用的,术语“铰链区”包括将CH1结构域连接到CH2结构域的重链分子的部分。所述铰链区包括大约25个残基且是柔性的,因此允许两个N-末端抗原结合区独立地移动。铰链区可以细分为三个不同的结构域:上铰链结构域、中铰链结构域和下铰链结构域(Roux等人,免疫学杂志(J.Immunol)161:4083(1998))。
如在此使用的,术语“二硫键”包括在两个硫原子之间形成的共价键。氨基酸半胱氨酸包括可以与第二个硫醇基形成二硫键或桥的硫醇基。在大多数天然地存在的IgG分子中,CH1区和CK区通过二硫键连接,并且两条重链通过在与使用Kabat编号系统的239和242(位置226或229,EU编号系统)对应的位置处的两个二硫键连接。
如在此使用的,术语“嵌合抗体”将被认为意指其中免疫反应性区域或位点获得自或源自第一物种且恒定区(其可以是完整的、部分的或根据本公开修饰的)获得自第二物种的任何抗体。在某些实施例中,靶结合区或位点将来自非人源(例如,小鼠或灵长类动物),并且恒定区是人的。
如在此使用的,“人源化百分比”是通过确定人源化结构域与种系结构域之间的框架氨基酸差异(即,非CDR差异)的数量、从氨基酸总数减去该数量、然后除以氨基酸总数并乘以100来计算的。
通过“特异性地结合”或“对……具有特异性”,它通常意指抗体经由其抗原结合结构域结合到表位,并且该结合需要抗原结合结构域与表位之间的一定的互补性。根据所述定义,当与抗体将结合到随机、不相关的表位相比,该抗体更容易地经由其抗原结合结构域结合到表位时,抗体被称为“特异性地结合”到表位。术语“特异性”在此用于限定某个抗体结合到某个表位的相对亲和力。例如,抗体“A”可以被认为对于给定的表位具有比抗体“B”高的特异性;或者抗体“A”可以被称为以比对于相关表位“D”高的特异性结合到表位“C”。优选地,抗体以“高亲和力”结合到抗原(或表位),即,K
如在此使用的,术语“治疗”(“treat”或“treatment”)可以指治疗性治疗以及预防性或防治性措施,其中,目的是预防或减缓(减轻)不期望的生理变化或紊乱(诸如癌症的进程)。有益或期望的临床结果包括但不限于无论可检测的或不可检测的症状的减轻、疾病的程度的减小、疾病状态的稳定(即,不恶化)、疾病进展的延迟或减缓、疾病状态的改善或缓和以及缓解(无论部分或全部)。“治疗”还可以意指与如果不接受治疗预期的存活相比延长存活。需要治疗的患者包括已经患有病症或紊乱的患者以及易于患有病症或紊乱的患者或者其中要预防病症或紊乱的患者。
通过“受试者”或“个体”或“动物”或“患者”或“哺乳动物”,可以指任何期望诊断、预后或治疗的受试者(特别是哺乳动物受试者)。哺乳动物受试者包括人、家畜、农场动物以及动物园、运动或宠物动物(诸如狗、猫、豚鼠、兔、大鼠、小鼠、马、牛、奶牛等)。
如在此使用的,诸如“向需要治疗的患者”或“需要治疗的受试者”的短语包括将从施用本公开的抗体或组合物例如用于检测、用于诊断过程和/或用于治疗中受益的受试者(诸如哺乳动物受试者)。
本公开提供了一种能够有效地阻断PD-L1与其受体PD-1之间以及4-1BB与其配体之间的相互作用的抗PD-L1/抗4-1BB双特异性抗体。双特异性抗体可以对PD-L1蛋白(例如,人PD-L1蛋白)和4-1BB蛋白(例如,人4-1BB蛋白)两者具有高结合亲和力。
抗PD-L1/抗4-1BB双特异性抗体可以包括能够特异性地识别和/或结合到PD-L1蛋白的抗PD-L1抗体或其抗原结合片段作为PD-L1靶向部分以及能够特异性地识别和/或结合到4-1BB蛋白的抗4-1BB抗体或其抗原结合片段作为4-1BB靶向部分。
抗PD-L1/抗4-1BB双特异性抗体可以包括抗PD-L1抗体或其抗原结合片段作为PD-L1靶向部分。抗PD-L1抗体或其抗原结合片段可以表现出对PD-L1的有效结合和抑制活性,并且用于治疗和诊断用途。
PD-L1蛋白是40kDa的1型跨膜蛋白。PD-L1蛋白可以是人PD-L1蛋白,人PD-L1蛋白可以选自于由由GenBank登录号NP_001254635.1、NP_001300958.1、NP_054862.1等表示的蛋白质组成的组,但是可以不限于此。人PD-L1蛋白包括细胞外部分,细胞外部分包括N-末端免疫球蛋白V(IgV)结构域(氨基酸19-127)和C-末端免疫球蛋白C(IgC)结构域(氨基酸133-225)。与先前存在的结合到PD-L1的IgV结构域从而破坏PD-1与PD-L1之间的结合的抗PD-L1抗体不同,包括在双特异性抗体中的抗PD-L1抗体或其片段可以不结合到PD-L1蛋白的免疫球蛋白V(IgV)结构域,而是结合到PD-L1的IgC结构域,以有效地抑制PD-L1,从而改善治疗效果。
具体地,包括在双特异性抗体中的抗PD-L1抗体或其片段可以特异性地结合到PD-L1蛋白的免疫球蛋白C(IgC)结构域。在人PD-L1蛋白的情况下,IgC结构域包括全长人PD-L1蛋白的氨基酸残基133-225,或者本质上由全长人PD-L1蛋白的氨基酸残基133-225组成。更具体地,抗PD-L1抗体或其片段可以结合到选自于人PD-L1蛋白的氨基酸残基Y134、K162和N183中的至少一个。在一些实施例中,抗PD-L1抗体或其片段可以结合到选自于人PD-L1蛋白的氨基酸残基Y134、K162和N183中的至少两个。在一些实施例中,抗PD-L1抗体或其片段不结合到PD-L1蛋白的免疫球蛋白V(IgV)结构域,其中,IgV结构域由人PD-L1蛋白的氨基酸残基19-127组成。
在实施例中,抗PD-L1抗体或其片段能够对人PD-L1蛋白具有特异性。
抗PD-L1抗体或其片段可以包括:(1)VH CDR1,具有SEQ ID NO:1的氨基酸序列;(2)VH CDR2,具有选自于由SEQ ID NO:2和SEQ ID NO:3组成的组的氨基酸序列;(3)VHCDR3,具有选自于由SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:262、SEQ ID NO:263、SEQ IDNO:264、SEQ ID NO:265、SEQ ID NO:266和SEQ ID NO:267组成的组的氨基酸序列;(4)VLCDR1,具有SEQ ID NO:6、SEQ ID NO:268和SEQ ID NO:269的氨基酸序列;(5)VL CDR2,具有SEQ ID NO:7的氨基酸序列;以及(6)VL CDR3,具有SEQ ID NO:8、SEQ ID NO:270、SEQ IDNO:271和SEQ ID NO:272的氨基酸序列。
[表2]抗PD-L1抗体的CDR
在一些实施例中,抗体或其片段包括以上取代中的不超过一个、不超过两个或不超过三个。在一些实施例中,抗体或其片段包括SEQ ID NO:1的VH CDR1;SEQ ID NO:2或SEQID NO:3的VH CDR2;SEQ ID NO:4、SEQ ID NO:5、SEQ ID NO:262、SEQ ID NO:263、SEQ IDNO:264、SEQ ID NO:265、SEQ ID NO:266或SEQ ID NO:267的VH CDR3;SEQ ID NO:6、SEQ IDNO:268或SEQ ID NO:269的VL CDR1;SEQ ID NO:7的VL CDR2;以及SEQ ID NO:8、SEQ IDNO:270、SEQ ID NO:271或SEQ ID NO:272的VL CDR3。
例如,抗PD-L1抗体或其片段可以包括:VH CDR1,具有SEQ ID NO:1的氨基酸序列;VH CDR2,具有SEQ ID NO:2或SEQ ID NO:3的氨基酸序列;VH CDR3,具有SEQ ID NO:4或SEQID NO:5的氨基酸序列;VL CDR1,具有SEQ ID NO:6的氨基酸序列;VL CDR2,具有SEQ IDNO:7的氨基酸序列;以及VL CDR3,具有SEQ ID NO:8的氨基酸序列。
回复突变可以用于保留抗PD-L1抗体的某些特性。在一些实施例中,本公开的抗PD-L1抗体(具体地,人抗体或人源化抗体)可以包括一个或更多个回复突变。在一些实施例中,重链可变区(VH)中的回复突变(即,在指定位置处包括的氨基酸)是选自于以下中的一种或更多种:根据Kabat编号,重链可变区的(a)位置44处的Ser、(b)位置49处的Ala、(c)位置53处的Ala、(d)位置91处的Ile、(e)位置1处的Glu、(f)位置37处的Val、(g)位置40处的Thr、(h)位置53处的Val、(i)位置54处的Glu、(j)位置77处的Asn、(k)位置94处的Arg以及(l)位置108处的Thr以及它们的组合。在一些实施例中,VH回复突变选自于:根据Kabat编号的重链可变区的(a)位置44处的Ser、(b)位置49处的Ala、(c)位置53处的Ala和/或(d)位置91处的Ile以及它们的组合。
在一些实施例中,轻链可变区(VL)中的回复突变是选自于以下中的一种或更多种:根据Kabat编号,轻链可变区的(a)位置22处的Ser、(b)位置42处的Gln、(c)位置43处的Ser、(d)位置60处的Asp和(e)位置63处的Thr以及它们的组合。
在一些实施例中,抗PD-L1抗体或其片段还包括重链恒定区、轻链恒定区、Fc区或它们的组合。在一些实施例中,轻链恒定区可以是kappa或lambda链恒定区。在一些实施例中,抗体是IgG、IgM、IgA、IgE或IgD(例如,人IgG、人IgM、人IgA、人IgE或人IgD)的同种型。在一些实施例中,同种型可以是诸如IgG1、IgG2、IgG3或IgG4的IgG(例如,人IgG)。在一些实施例中,片段(抗PD-L1抗体的抗原结合片段)可以是包括抗体的重链CDR和/或轻链CDR的任何片段,例如,它可以选自于由Fab、Fab'、F(ab')
在不受限制的情况下,抗PD-L1抗体或其片段是嵌合抗体、人源化抗体或完全人抗体。在一方面,抗体或其片段不是天然地存在的,或者是化学地或重组地合成的。
可以使用本领域充分建立的一种或更多种技术来评估公开的抗体与PD-L1的结合。例如,在优选的实施例中,可以通过流式细胞术测定来测试抗体,其中,抗体与表达人PD-L1的细胞系(诸如已经转染以在其细胞表面上表达PD-L1(例如,人PD-L1或猴(例如,恒河猴或食蟹猴)PD-L1或小鼠PD-L1)的CHO细胞)反应。用于在流式细胞术测定中使用的其它合适的细胞包括表达天然PD-L1的抗CD3刺激的CD4
鉴于这些抗体中的每个可以结合到诸如人PD-L1的PD-L1,CDR序列或者V
抗PD-L1/抗4-1BB双特异性抗体可以包括抗4-1BB抗体或其抗原结合片段作为4-1BB靶向部分。
在实施例中,抗4-1BB抗体或其片段可以特异性地结合到4-1BB(例如,人4-1BB)蛋白。
例如,人4-1BB蛋白可以选自于由由NCBI登录号NP_001552等表示的蛋白质组成的组,但是可以不限于此。这些抗4-1BB抗体或其抗原结合片段能够在哺乳动物中增强免疫应答和/或治疗肿瘤(癌症)。抗4-1BB抗体或其抗原结合片段的特征在于与先前存在的抗4-1BB抗体相比,仅在肿瘤微环境(TME)中定位和/或激活并且/或者显著地降低肝毒性,并且保持提高免疫应答增强和/或肿瘤治疗的功效。
术语“4-1BB”指CD137或TNFRSF9(TNF受体25超家族成员9),是TNF受体超家族(TNFRSF)的成员,并且是在免疫细胞(先天性免疫细胞和适应性免疫细胞两者)激活后表达的共刺激分子。如在此使用的,4-1BB可以源自于例如智人(人)(NCBI登录号NP_001552)的哺乳动物。例如,人4-1BB蛋白(NP_001552)可以由如下的氨基酸序列(SEQ ID NO:9)表示:
1 mgnscyniva tlllvlnfer trslqdpcsn cpagtfcdnn rnqicspcpp nsfssaggqr
61 tcdicrqckg vfrtrkecss tsnaecdctp gfhclgagcs mceqdckqgq eltkkgckdc
121 cfgtfndqkr gicrpwtncs ldgksvlvng tkerdvvcgp spadlspgas svtppapare
181 pghspqiisf flaltstall fllffltlrf svvkrgrkkl lyifkqpfmr pvqttqeedg
241 cscrfpeeee ggcel
如在此描述的,术语“4-1BB”包括变体、亚型、同源物、直系同源物和旁系同源物。例如,在某些情况下,对人4-1BB蛋白具有特异性的抗体可以与来自除了人之外的物种的4-1BB蛋白交叉反应。在其它实施例中,对人4-1BB蛋白具有特异性的抗体可以对人4-1BB蛋白具有完全特异性,并且可以表现出物种或其它类型的交叉反应,或者可以与来自某些其它物种但并非所有其它物种的4-1BB交叉反应(例如,与猴4-1BB但不与小鼠4-1BB交叉反应)。术语“人4-1BB”指诸如具有NCBI登录号NP_001552的人4-1BB的完整氨基酸序列的人序列4-1BB。术语“小鼠4-1BB”指诸如具有NCBI登录号NP_033430.1的小鼠4-1BB的完整氨基酸序列的小鼠序列4-1BB。4-1BB在本领域中也可以被称为例如CD137。公开中的人4-1BB序列与NCBI登录号NP_001552的人4-1BB的不同之处可以在于具有例如保守突变或非保守区域中的突变,公开中的4-1BB具有与NCBI登录号NP_001552的人4-1BB基本上相同的生物学功能。
如实验示例中所证明的,在此公开的抗4-1BB抗体显示出4-1BB结合能力、对在细胞表面上表达的4-1BB的结合能力和高4-1BB结合亲和力。另外,如实验示例中所证明的,在此公开的抗4-1BB抗体(具体地,当与在此公开的抗PD-L1抗体组合时)能够激活T细胞。此外,如实验示例中所证明的,在此公开的抗4-1BB抗体具有增加的体内抗肿瘤作用。
这些抗4-1BB抗体可以用于诸如治疗各种类型的癌症等的治疗目的,并且还可以用于诊断和预后目的。
在实施例中,抗4-1BB抗体或其片段对人4-1BB蛋白能够具有特异性。抗4-1BB抗体或其片段可以包括:(i)VH CDR1,具有选自于由SEQ ID NO:10和SEQ ID NO:11组成的组的氨基酸序列;(ii)VH CDR2,具有选自于由SEQ ID NO:12和SEQ ID NO:13组成的组的氨基酸序列;(iii)VH CDR3,具有选自于由SEQ ID NO:14、SEQ ID NO:15、SEQ ID NO:16和SEQ IDNO:17组成的组的氨基酸序列;(iv)VL CDR1,具有SEQ ID NO:18的氨基酸序列;(v)VLCDR2,具有SEQ ID NO:19的氨基酸序列;以及(vi)VL CDR3,具有SEQ ID NO:20的氨基酸序列。例如,抗4-1BB抗体或其片段可以包括:VH CDR1,具有SEQ ID NO:10或SEQ ID NO:11的氨基酸序列;VH CDR2,具有SEQ ID NO:12或SEQ ID NO:13的氨基酸序列;VH CDR3,具有SEQID NO:14、SEQ ID NO:15、SEQ ID NO:16或SEQ ID NO:17的氨基酸序列;VL CDR1,具有SEQID NO:18的氨基酸序列;VL CDR2,具有SEQ ID NO:19的氨基酸序列;以及VL CDR3,具有SEQID NO:20的氨基酸序列。
[表3]抗4-1BB抗体的CDR
在抗4-1BB抗体或其片段的非限制性示例中,
(1)重链可变区可以包括具有选自于由SEQ ID NO:21、SEQ ID NO:22、SEQ ID NO:23和SEQ ID NO:24组成的组的氨基酸序列的多肽或者与上述氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%的序列同一性的多肽,或者本质上由具有选自于由SEQ ID NO:21、SEQ ID NO:22、SEQ ID NO:23和SEQ ID NO:24组成的组的氨基酸序列的多肽或者与上述氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%的序列同一性的多肽组成;并且/或者
(2)轻链可变区可以包括具有选自于由SEQ ID NO:25和SEQ ID NO:26组成的组的氨基酸序列的多肽或者与上述氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%的序列同一性的多肽,或者本质上由具有选自于由SEQ ID NO:25和SEQ ID NO:26组成的组的氨基酸序列的多肽或者与上述氨基酸序列具有至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%的序列同一性的多肽组成。
抗4-1BB抗体或其片段的非限制性示例可以包括重链可变区,重链可变区包括SEQID NO:21、SEQ ID NO:22、SEQ ID NO:23或SEQ ID NO:24的氨基酸序列或者本质上由SEQID NO:21、SEQ ID NO:22、SEQ ID NO:23或SEQ ID NO:24的氨基酸序列组成。
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDGQRNSMREFDYWGQGTLVTVSS(SEQ ID NO:21)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSGYDMSWVRQAPGKCLEWVSVIYPDDGNTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDAAVYYCAKHGGQKPTTKSSSAYGMDGWGQGTLVTVSS(SEQ ID NO:22)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRNSMREFDYWGQGTLVTVSS(SEQ ID NO:23)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRQSMREFDYWGQGTLVTVSS(SEQ ID NO:24)
抗4-1BB抗体或其片段的非限制性示例可以包括轻链可变区,轻链可变区包括SEQID NO:25或SEQ ID NO:26的氨基酸序列或者本质上由SEQ ID NO:25或SEQ ID NO:26的氨基酸序列组成。
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL(SEQ ID NO:25)
QSVLTQPPSASGTPGQRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL(SEQ ID NO:26)
公开的抗体的特征在于抗体的特定功能特征或性质。例如,抗体特异性地结合到人4-1BB且可以结合到来自某些其它物种的4-1BB(例如,猴(例如,食蟹猴、恒河猴)4-1BB),但是可以基本上不结合到来自某些其它物种的4-1BB(例如,小鼠4-1BB)。优选地,公开的抗体以高亲和力结合到人4-1BB。
此外,公开的抗体(具体地,作为包括在此公开的抗PD-L1抗体的双特异性抗体)具有增强免疫细胞增殖、存活、细胞因子的分泌和细胞溶解活性CD8 T细胞的能力。在某些实施例中,公开的抗体(具体地,作为包括抗PD-L1抗体的双特异性抗体)结合到人4-1BB且表现出激活T细胞的能力。
通过其评价抗体刺激免疫应答的能力的其它方法包括诸如在体内肿瘤移植模型中抗体抑制肿瘤生长的能力。
可以使用本领域充分建立的一种或更多种技术评估公开的抗体与4-1BB的结合。例如,在优选的实施例中,可以通过流式细胞术测定来测试抗体,其中,抗体与表达人4-1BB的细胞系(诸如已经转染以在其细胞表面上表达4-1BB(例如,人4-1BB或猴(例如,恒河猴或食蟹猴)4-1BB或小鼠4-1BB)的CHO细胞)反应。用于在流式细胞术测定中使用的其它合适的细胞包括表达天然4-1BB的抗CD3刺激的CD4
在一些实施例中,抗4-1BB抗体或其片段还包括重链恒定区、轻链恒定区、Fc区或它们的组合。在一些实施例中,轻链恒定区可以是kappa或lambda链恒定区。在一些实施例中,抗体具有IgG、IgM、IgA、IgE或IgD(例如,人IgG、人IgM、人IgA、人IgE或人IgD)的同种型。在一些实施例中,同种型可以是诸如IgG1、IgG2、IgG3或IgG4的IgG(例如,人IgG)。在一些实施例中,片段(抗4-1BB抗体的抗原结合片段)可以是包括抗体的重链CDR和/或轻链CDR的任何片段,例如,它可以选自于由Fab、Fab'、F(ab')
在不受限制的情况下,抗4-1BB抗体或其片段是嵌合抗体、人源化抗体或完全人抗体。在一方面,抗体或其片段不是天然地存在的,或者是化学地或重组地合成的。
鉴于这些抗体中的每个可以结合到诸如人4-1BB的4-1BB,CDR序列或者V
在包括PD-L1靶向部分和4-1BB靶向部分的双特异性抗体中,PD-L1靶向部分和4-1BB靶向部分中的一个可以是全长抗体,另一个可以是包括重链CDR、轻链CDR或它们的组合的抗原结合片段(例如,scFv)。靶向PD-L1和4-1BB蛋白中的一个的全长抗体和靶向另一蛋白的抗原结合片段可以直接或经由肽接头化学地连接(例如,共价地连接)。抗原结合片段(例如,scFv)可以直接或经由肽接头连接到全长抗体的N-末端(例如,全长抗体的轻链或重链的N-末端)、全长抗体的C-末端(例如,全长抗体的重链(或者Fc或CH3结构域)的C-末端)或其两者(见图1A和图1B)。
在实施例中,双特异性抗体可以包括全长抗PD-L1抗体、抗4-1BB抗体的抗原结合片段(例如,scFv)和它们之间的肽接头。在其它实施例中,双特异性抗体可以包括全长抗4-1BB抗体、抗PD-L1抗体的抗原结合片段(例如,scFv)和它们之间的肽接头。
在实施例中,包含在双特异性抗体中的scFv可以以任何顺序包括重链可变区和轻链可变区。例如,包含在双特异性抗体中的scFv可以在从N-末端到C-末端的方向上包括重链可变区和轻链可变区以及任选的在它们之间的肽接头,或者可选地,包含在双特异性抗体中的scFv可以在从N-末端到C-末端的方向上包括轻链可变区和重链可变区以及任选的在它们之间的肽接头。
在实施例中,抗PD-L1/抗4-1BB双特异性抗体根据细胞表面上表达的PD-L1激活4-1BB信号,并且因此激活免疫应答。
将肽接头用于双特异性抗体可以导致抗体的高纯度。
如在此使用的,术语“肽接头”可以是包括1个至100个(具体地,2个至50个)任何氨基酸的肽接头,并且可以包括任何种类的氨基酸而没有任何限制。肽接头可以包括例如Gly残基、Asn残基和/或Ser残基,并且还包括诸如Thr和/或Ala的中性氨基酸。适用于肽接头的氨基酸序列可以是相关领域中知晓的氨基酸序列。同时,可以在使得融合蛋白功能将不受影响的限度内不同地确定肽接头的长度。例如,肽接头可以通过包括总共约1个至约100个、约2个至约50个或约5个至约25个选自于由Gly、Asn、Ser、Thr和Ala组成的组中的一种或更多种来形成。在一个实施例中,肽接头可以表示为(G
在另一实施例中,PD-L1靶向部分和4-1BB靶向部分两者可以是全长抗体或者包括重链CDR、轻链CDR或它们的组合的抗原结合片段。
在另一实施例中,双特异性抗体可以是包括第一臂和第二臂的异二聚体形式,第一臂包括靶向PD-L1和4-1BB中的一个的一对第一重链和第一轻链,第二臂包括靶向PD-L1和4-1BB中的另一个的一对第二重链和第二轻链。
在实施例中,全长抗体可以呈全长免疫球蛋白形式(例如,IgG、IgM、IgA、IgE或IgD,诸如人IgG、人IgM、人IgA、人IgE或人IgD),抗原结合片段可以选自于由如上所述的Fab、Fab'、F(ab')
例如,在此描述的抗体可以包括柔性接头序列,或者可以被修饰以添加功能部分(例如,PEG、药物、毒素或标记)。
在此描述的抗体或变体可以包括衍生物,衍生物例如通过使任何类型的分子与抗体的共价附接来修饰,使得共价附接不妨碍抗体与抗原(例如,表位)结合。例如,但无限制性,抗体可以例如通过选自于由糖基化、乙酰化、聚乙二醇化、磷酸化、酰胺化、通过已知的保护/阻断基团衍生化、蛋白水解裂解、与细胞配体和其它蛋白质连接等组成的组中的至少一种被修饰。任何许多化学修饰可以通过包括但不限于特定的化学裂解、乙酰化、甲酰化、衣霉素的代谢合成等的已知技术进行。另外地,抗体可以包含一种或更多种非经典氨基酸。
可以通过用选自于化学发光化合物、荧光化合物(例如,荧光发射金属)、放射性同位素、染料等的常规标记材料加标签(偶联)来可检测地标记抗体或其片段。加标签的抗体或其片段的存在可以通过测量在抗体(或其片段)与标记材料之间的化学反应期间产生的信号来检测。特别有用的标记材料的示例可以是选自于由鲁米诺、异鲁米诺、热稳定的吖啶酯、咪唑、吖啶盐、草酸酯、荧光发射金属等组成的组中的至少一种。例如,荧光发射金属可以是
在某些实施例中,制备的双特异性抗体将不在要治疗的动物中(例如,人中)引发有害的免疫应答。在一个实施例中,可以使用任何常规技术修饰双特异性抗体以降低其免疫原性。例如,双特异性抗体可以是人源化的、灵长类化的、去免疫的或嵌合的抗体。这些类型的抗体源自保留或基本上保留亲本抗体的抗原结合性质但在人体中具有低的免疫原性的非人抗体(通常是鼠类或灵长类动物抗体)。这可以通过各种方法实现,所述方法包括:(a)将整个非人可变结构域移植到人恒定区上以产生嵌合抗体;(b)将一个或更多个非人互补决定区(CDR)的至少一部分移植到人框架和恒定区中,并且保留或不保留关键框架残基;或者(c)移植整个非人可变结构域,但是通过替换表面残基将它们用人样部分“隐身”。
去免疫也可以用于降低抗体的免疫原性。如在此使用的,术语“去免疫”可以包括改变抗体以修饰T细胞表位(见例如国际申请公开号:WO/9852976A1和WO/0034317A2)。例如,分析来自起始抗体的可变重链序列和可变轻链序列,并且产生来自每个V(可变)区的人T细胞表位“图谱”,所述图谱示出与互补决定区(CDR)相关的表位的位置以及序列内的其它关键残基。分析来自T细胞表位图谱的单独T细胞表位以鉴定具有改变最终抗体活性的低风险的备选氨基酸取代。设计一系列包括氨基酸取代的组合的备选的可变重链序列和可变轻链序列,随后将这些序列掺入到一系列结合多肽中。通常,产生12个与24个之间的变体抗体,并且测试结合和/或功能。然后将包括修饰的可变区和人恒定区的完整重链和轻链基因克隆到表达载体中,并且将随后的质粒导入到细胞系中以产生完整抗体。然后在适当的生物化学和生物学测定中比较抗体,并且鉴定最佳变体。
双特异性抗体对每种靶蛋白的结合特异性和/或亲和力可以通过任何常规测定(例如,诸如免疫沉淀、放射免疫测定(RIA)或酶联免疫吸附测定(ELISA)的体外测定)来确定,但不限于此。
可选地,可以调整描述为用于产生单链单元的技术(美国专利号4,694,778等)以产生本公开的单链单元。通过经由氨基酸桥(肽接头)连接Fv区的重链片段和轻链片段以产生单链融合肽(scFv)来形成单链单元。还可以使用用于在大肠杆菌中组装功能性Fv片段的技术。
可以用于产生单链Fv(scFv)和抗体的技术的示例包括在美国专利号4,946,778、美国专利号5,258,498等中描述的技术。对于包括在人的体内使用抗体和体外检测测定的一些用途,可以优选使用嵌合、人源化或人抗体。嵌合抗体是其中抗体的不同部分源自不同的动物物种的分子,诸如具有源自鼠类单克隆抗体的可变区和人免疫球蛋白恒定区的抗体。用于产生嵌合抗体的方法在本领域中是已知的。见例如其全部内容通过引用包含于此的美国专利号5,807,715、美国专利号4,816,567和美国专利号4,816,397。
人源化抗体是结合具有来自非人物种的一个或更多个互补决定区(CDR)和来自人免疫球蛋白分子的框架区的所需抗原的源自非人物种抗体的抗体分子。人框架区中的框架残基将经常被来自CDR供体抗体的对应的残基取代,以改变、优选地改善抗原结合。这些框架取代是通过本领域已知的方法来鉴定的,例如,通过对CDR和框架残基的相互作用建模以鉴定对抗原结合和序列比较而言重要的框架残基,以鉴定特定位置处的异常框架残基(见例如其全部内容通过引用包含于此的Queen等人,美国专利号5,585,089)。可以使用本领域已知的多种技术将抗体人源化,所述技术包括例如CDR-移植(其全部内容通过引用均被包含的美国专利号5,225,539、美国专利号5,530,101、美国专利号5,585,089等)、饰面或表面重修(其全部内容通过引用均被包含的EP 592,106;EP 519,596)和链改组(其全部内容通过引用被包含的美国专利号5,565,332)。
完全人抗体对于人患者的治疗性治疗是特别令人期望的。人抗体可以通过在本领域中已知的多种方法来制造,所述方法包括使用源自人免疫球蛋白序列的抗体文库的噬菌体展示方法。还见其全部内容通过引用均包含于此的美国专利号4,444,887、美国专利号4,716,111等。
人抗体还可以使用转基因小鼠来产生,所述转基因小鼠不能表达功能内源性免疫球蛋白,但是可以表达人免疫球蛋白基因。例如,可以随机地或通过同源重组将人重链和轻链免疫球蛋白基因复合物引入到小鼠胚胎干细胞中。可选地,除了人重链和轻链基因之外,人可变区、恒定区和多样区(diversity region)可以引入到小鼠胚胎干细胞中。可以单独地或者在引入人免疫球蛋白基因座的情况下同时地通过同源重组使小鼠重链和轻链免疫球蛋白基因无功能。具体地,JH区的纯合子缺失防止内源性抗体产生。将修饰的胚胎干细胞扩增且微注射到胚囊中以产生嵌合小鼠。然后使嵌合小鼠繁殖以产生表达人抗体的纯合子代。用选择的抗原(例如,所需的靶多肽的全部或部分)以正常方式对转基因小鼠免疫。针对抗原的单克隆抗体可以使用常规的杂交瘤技术从经免疫的转基因小鼠获得。转基因小鼠所具有的人免疫球蛋白转基因在B细胞分化期间重排,并且随后进行类别转换和体细胞突变。因此,使用这种技术,可以产生治疗有用的IgG、IgA、IgM和IgE抗体。
还可以使用被称为“引导选择”的技术来产生识别所选表位的完全人抗体。在所述方法中,使用选择的非人单克隆抗体(例如,小鼠抗体)以指导选择识别相同表位的完全人抗体。
在另一实施例中,编码所需单克隆抗体的DNA可以使用常规的程序(例如,通过使用能够与编码鼠类抗体的重链和轻链的基因特异性地结合的寡核苷酸探针)容易地进行分离和测序。分离的和亚克隆的杂交瘤细胞用作这种DNA的优选来源。一旦分离,可以将DNA放置在表达载体中,然后将其转染到不另外产生免疫球蛋白的原核或真核宿主细胞(诸如大肠杆菌细胞、猿猴COS细胞、中国仓鼠卵巢(CHO)细胞或骨髓瘤细胞)中。更具体地,分离的DNA(其可以是如在此所述合成的)可以用于克隆恒定区和可变区序列以制造抗体,如通过引用包含于此的Newman等人的美国专利号5,658,570中所述的。本质上,这需要从选择的细胞提取RNA,转化为cDNA,并且使用Ig特异性引物通过PCR扩增。用于此目的的合适引物也被描述在美国专利号5,658,570中。如下面将更详细讨论的,表达所需抗体的转化细胞可以以相对大的量增长,以提供免疫球蛋白的临床和商业供应。
另外地,使用常规重组DNA技术,可以将双特异性抗体的一个或更多个CDR插入框架区内(例如,插入到人框架区内),以使非人抗体人源化。框架区可以是天然地存在的或共有框架区,并且优选地人框架区(人框架区的列表见例如Chothia等人,分子生物学杂志(J.Mol.Biol.),278:457-479(1998))。例如,由框架区和CDR的组合产生的多核苷酸编码特异性地结合到所需多肽(例如,LIGHT)的至少一个表位的抗体。优选地,可以在框架区内进行一个或更多个氨基酸取代,优选地,氨基酸取代改善抗体与其抗原(或表位)的结合。另外地,此类方法可以用于制造参与链内二硫键的一个或更多个可变区半胱氨酸残基的氨基酸取代或缺失,以产生缺少一个或更多个链内二硫键的抗体分子。对多核苷酸的其它改变被本公开涵盖,并且在本领域的技术范围内。
另外,可以使用被开发用于通过将来自具有适当抗原特异性的小鼠抗体分子的基因与来自具有适当生物活性的人抗体分子的基因剪接在一起来产生“嵌合抗体”的技术。如在此使用的,嵌合抗体是其中不同部分源自不同的动物物种的分子,诸如具有源自鼠类单克隆抗体的可变区和人免疫球蛋白恒定区的抗体。
可选地,可以使用熟练技术人员已知的技术选择和培养产生抗体的细胞系。在各种实验室手册和主要出版物中描述了此类技术。
另外地,本领域技术人员知晓的标准技术可以用于在编码本公开抗体的核苷酸序列中引入突变,所述标准技术包括但不限于产生氨基酸取代的定点诱变和PCR介导的诱变。优选地,相对于参考可变重链区、CDR-H1、CDR-H2、CDR-H3、可变轻链区、CDR-L1、CDR-L2或CDR-L3,变体(包括衍生物)编码少于50个氨基酸取代,少于40个氨基酸取代、少于30个氨基酸取代、少于25个氨基酸取代、少于20个氨基酸取代、少于15个氨基酸取代、少于10个氨基酸取代、少于5个氨基酸取代、少于4个氨基酸取代、少于3个氨基酸取代或者少于2个氨基酸取代。可选地,可以诸如通过饱和诱变沿着编码序列的全部或部分随机地引入突变,并且可以针对生物活性筛选所得突变体以鉴定保留活性的突变体。
抗PD-L1/抗4-1BB双特异性抗体的非限制性示例提供在下表4中。
如在此使用的,“重组分”意指本公开的包括(1)抗PD-L1抗体的重链以及(2)抗4-1BB抗体的重链和轻链的抗PD-L1/抗4-1BB双特异性抗体的组分。
如在此使用的,“轻组分”意指本公开的包括抗PD-L1抗体的轻链的抗PD-L1/抗4-1BB双特异性抗体的组分。
[表4]抗PD-L1/抗4-1BB双特异性抗体的示例
在此提供的双特异性抗体能够同时地阻断PD-L1和4-1BB的活性,从而例如通过激活免疫应答(见图2)在免疫疗法和/或癌症治疗中表现出改善的效果。鉴于公开的双特异性抗体抑制PD-L1与PD-1分子的结合且刺激抗原特异性T细胞应答的能力,公开还提供了一种组合物或使用公开的抗体刺激、增强或上调抗原特异性T细胞应答的体外和体内方法。
实施例提供了一种包括如上所述的双特异性抗体的药物组合物。药物组合物还可以包括药学上可接受的载体。药物组合物可以用于刺激免疫应答(例如,抗原特异性T细胞应答)并且/或者治疗和/或预防与PD-L1、4-1BB或其两者相关的疾病。
另一实施例提供了一种在有需要的受试者中刺激免疫应答(例如,抗原特异性T细胞应答)并且/或者治疗和/或预防与PD-L1、4-1BB或其两者相关的疾病的方法,所述方法包括向受试者施用药学有效量的双特异性抗体或药物组合物。所述方法还可以包括在施用步骤之前鉴定需要治疗和/或预防与PD-L1、4-1BB或其两者相关的疾病的受试者的步骤。
与PD-L1、4-1BB或其两者相关的疾病可以选自于癌症(或肿瘤)、感染性疾病、自身免疫反应、神经系统障碍等。
在实施例中,受试者可以选自于包括人的哺乳动物,例如患有癌症哺乳动物细胞的哺乳动物(例如,人)。在其它实施例中,受试者可以是从哺乳动物(患有选自于癌症、感染性疾病、自身免疫反应、神经系统障碍等的疾病的哺乳动物)分离(隔离)的细胞(例如,癌细胞或者从哺乳动物中的感染区域分离(隔离)的细胞,或者诸如肿瘤浸润性T淋巴细胞、CD4+T细胞、CD8+T细胞或它们的组合的T细胞)。
另一实施例提供了一种双特异性抗体或药物组合物在治疗和/或预防癌症中的用途。另一实施例提供了一种双特异性抗体在制备用于治疗和/或预防癌症的药物组合物中的用途。
在此处提供的药物组合物、方法和/或用途中,与PD-L1、4-1BB或其两者相关的疾病可以是与PD-L1、4-1BB或其两者的激活(例如,异常激活或过度激活)和/或过度产生(过表达)相关的疾病。例如,疾病可以是癌症。
癌症可以是实体癌症或血癌,优选地实体癌症。
双特异性抗体的施用可以通过本领域充分建立的一种或更多种技术进行。
公开的抗体的“治疗有效剂量”优选地导致疾病症状的严重程度降低,疾病无症状期的频率和持续时间增加,或者预防由于疾病痛苦引起的损伤或失能。例如,对于荷瘤受试者的治疗,相对于未治疗的受试者,“治疗有效剂量”优选地抑制肿瘤生长至少约20%,更优选地至少约40%,甚至更优选地至少约60%,并且还更优选地至少约80%。治疗化合物的治疗有效量可以减小肿瘤大小,或者另外改善受试者的症状,受试者通常是人或可以是另一哺乳动物。
药物组合物可以包括有效量的双特异性抗体和可接受的载体。在一些实施例中,组合物还包括第二抗癌剂(例如,免疫检查点抑制剂)。
在具体实施例中,术语“药学上可接受的”可以指由联邦政府或州政府的监管机构批准的或者在美国药典或其它普遍认可的药典中列出的,用于动物中,更具体地用于人体中。此外,“药学上可接受的载体”将通常是无毒的固体、半固体或液体填料、稀释剂、封装材料或任何类型的配制助剂。
本公开的包括抗体或其抗原结合片段的组合物还可以包括药学上可接受的载体。药学上可接受的载体是常规用于制备制剂中的载体。
在来自患有某种癌症(例如,肿瘤细胞)的患者的生物样品(例如细胞、组织、血液、血清等)中观察到PD-L1和/或4-1BB的过表达和/或过度激活,并且/或者具有PD-L1和/或4-1BB过表达细胞的患者可能对用双特异性抗体的治疗有反应。因此,本公开的双特异性抗体也可以用于诊断和预后目的。
实施例提供了一种用于诊断与PD-L1、4-1BB或其两者相关的疾病的药物组合物,该组合物包括双特异性抗体。在另一实施例中,提供了一种双特异性抗体用于诊断与PD-L1、4-1BB或其两者相关的疾病的用途。
另一实施例提供了一种诊断与PD-L1、4-1BB或其两者相关的疾病的方法,所述方法包括以下步骤:使从患者获得的生物样品与双特异性抗体接触;以及检测生物样品中的抗原-抗体反应或测量生物样品中的抗原-抗体反应的水平。在所述方法中,当在生物样品中检测到抗原-抗体反应或生物样品中的抗原-抗体反应的水平比正常样品中的抗原-抗体反应的水平高时,可以将从其获得生物样品的患者确定为患有与PD-L1、4-1BB或其两者相关的疾病的患者。因此,在一些实施例中,所述方法还可以包括以下步骤:使正常样品与双特异性抗体接触;以及测量正常样品中抗原-抗体反应的水平。另外,所述方法还可以包括在测量步骤之后比较生物样品中和正常样品中的抗原-抗体反应的水平。另外,在检测步骤或比较步骤之后,所述方法还可以包括当在生物样品中检测到抗原-抗体反应或生物样品中的抗原-抗体反应的水平比正常样品中的抗原-抗体反应的水平高时,将患者确定为患有与PD-L1、4-1BB或其两者相关的疾病的患者。
与PD-L1、4-1BB或其两者相关的疾病可以是与PD-L1、4-1BB或其两者的激活(例如,异常激活或过度激活)和/或过度产生(过表达)相关的疾病。例如,疾病可以是如上所述的癌症。
在诊断组合物和方法中,生物样品可以是从要诊断的患者获得(分离)的选自于由细胞、组织、体液(例如,血液、血清、淋巴等)等组成的组中的至少一种。正常样品可以是从未患有与PD-L1、4-1BB或其两者相关的疾病的患者获得(分离)的选自于由细胞、组织、体液(例如,血液、血清、淋巴、尿液等)等组成的组中的至少一种。患者可以选自于诸如人的哺乳动物。在样品的可选的预处理后,可以在允许抗体与样品中可能存在的PD-L1和/或4-1BB蛋白相互作用的条件下,将样品与本公开的双特异性抗体孵育。
样品中的PD-L1和/或4-1BB蛋白的存在和/或水平(浓度)可以用于鉴定适合于用双特异性抗体治疗的患者或者对用双特异性抗体治疗有反应或易感的患者。
实施例提供了一种药物组合物,所述药物组合物鉴定适合于用双特异性抗体治疗的患者或者对用双特异性抗体治疗有反应或易感的患者,该组合物包括双特异性抗体。在另一实施例中,提供了一种双特异性抗体用于鉴定适合于用双特异性抗体治疗的患者或者对用双特异性抗体治疗有反应或易感的患者的用途。另一实施例提供了一种鉴定适合于用双特异性抗体治疗的患者或者对用双特异性抗体治疗有反应或易感的患者的方法,所述方法包括以下步骤:使从患者获得的生物样品与双特异性抗体接触;以及检测生物样品中的抗原-抗体反应或测量生物样品中的抗原-抗体反应的水平。
实施例提供了一种用于检测生物样品中的PD-L1、4-1BB或同时检测其两者的组合物,该组合物包括双特异性抗体。另一实施例提供了一种检测生物样品中的PD-L1、4-1BB或同时检测其两者的方法,所述方法包括以下步骤:使生物样品与双特异性抗体接触;以及检测(测量)双特异性抗体与PD-L1、4-1BB或其两者之间的抗原-抗体反应(结合)。
在检测组合物和检测方法中,术语“检测PD-L1、4-1BB或其两者”可以指但不限于检测生物样品中的PD-L1、4-1BB或其两者的存在(和/或不存在)和/或水平。
在检测方法中,当检测到抗原-抗体反应时,可以确定PD-L1、4-1BB或其两者存在于生物样品中,当未检测到抗原-抗体反应时,可以确定生物样品中没有PD-L1、4-1BB或其两者(PD-L1、4-1BB或其两者不存在于生物样品中)。因此,检测方法还可以包括:在检测步骤之后,当检测到抗原-抗体反应时,确定PD-L1、4-1BB或其两者存在于生物样品中;以及/或者当未检测到抗原-抗体反应时,确定生物样品中没有PD-L1、4-1BB或其两者(PD-L1、4-1BB或其两者不存在于生物样品中)。
在检测方法中,PD-L1、4-1BB或其两者的水平可以根据抗原-抗体反应的程度(例如,可以通过任何常规手段测量的通过抗原-抗体反应形成的抗原-抗体复合物的量、通过抗原-抗体反应获得的任何信号的强度等)来确定。
生物样品可以包括从诸如人的哺乳动物获得或分离的选自于由细胞(例如,肿瘤细胞)、组织(例如,肿瘤组织)、体液(例如,血液、血清等)等组成的组中的至少一种。检测方法的步骤可以在体外进行。
在诊断方法和/或检测方法中,检测抗原-抗体反应或测量抗原-抗体反应的水平的步骤可以通过诸如一般酶促反应、荧光反应、发光反应和/或辐射的检测的相关领域已知的任何一般方法执行。例如,所述步骤可以通过选自于但不限于下面的组的方法执行,所述组由免疫色谱、免疫组织化学(IHC)、酶联免疫吸附测定(ELISA)、放射免疫测定(RIA)、酶免疫测定(EIA)、荧光免疫测定(FIA)、发光免疫测定(LIA)、蛋白质印迹、微阵列、流式细胞术、表面等离子体共振(SPR)等组成,但不限于此。
实施例提供了一种编码双特异性抗体的多核苷酸。具体地,实施例提供了一种编码呈IgG-scFv形式的双特异性抗体的重链的多核苷酸。其它实施例提供了一种编码呈IgG-scFv形式的双特异性抗体的轻链的多核苷酸。IgG-scFv形式可以指一种双特异性抗体,所述双特异性抗体包括靶向(结合到)PD-L1和4-1BB蛋白中的一个的全长IgG抗体以及靶向(结合到)PD-L1和4-1BB蛋白中的另一个的scFv片段,其中,scFv直接(不用肽接头)或经由肽接头连接到全长IgG抗体的C-末端和/或N-末端。
在实施例中,当呈IgG-scFv形式的双特异性抗体包括针对PD-L1的全长IgG抗体和针对4-1BB的scFv片段时,编码双特异性抗体的重链的多核苷酸可以编码针对PD-L1的全长IgG抗体以及针对4-1BB的scFv片段的重链,所述针对4-1BB的scFv片段直接或经由肽接头连接到全长IgG抗体的C-末端和/或N-末端;并且编码双特异性抗体的轻链的多核苷酸可以编码针对PD-L1的全长IgG抗体的轻链。
在另一实施例中,当呈IgG-scFv形式的双特异性抗体包括针对4-1BB的全长IgG抗体和针对PD-L1的scFv片段时,编码双特异性抗体的重链的多核苷酸可以编码针对4-1BB的全长IgG抗体以及针对PD-L1的scFv片段的重链,所述针对PD-L1的scFv片段直接或经由肽接头连接到全长IgG抗体的C-末端和/或N-末端;并且编码双特异性抗体的轻链的多核苷酸可以编码针对4-1BB的全长IgG抗体的轻链。
另一实施例提供了一种重组载体,所述重组载体包括编码双特异性抗体的重链的多核苷酸、编码双特异性抗体的轻链的多核苷酸或其两者。另一实施例提供了一种用重组载体转染的重组细胞。
另一实施例提供了一种制备双特异性抗体的方法,所述方法包括在细胞中表达编码双特异性抗体的重链的多核苷酸以及编码双特异性抗体的轻链的多核苷酸。表达多核苷酸的步骤可以通过在允许多核苷酸表达的条件下培养包括多核苷酸(例如,在重组载体中)的细胞来进行。所述方法还可以包括在表达或培养步骤之后从细胞培养物中分离和/或纯化双特异性抗体。
[示例]
在下文中,将通过示例详细描述本发明。
以下示例仅旨在说明发明,而不解释为限制发明。
示例1:抗PD-L1单克隆抗体的制备
1.1、抗人PD-L1小鼠单克隆抗体的制备及其分析
如国际申请公开WO2017-215590中公开的,使用杂交瘤技术产生抗人PD-L1小鼠单克隆抗体。
命名为杂交瘤HL1210-3的杂交瘤上清液的可变区的氨基酸和多核苷酸序列提供在下表5中。
[表5]HL1210-3可变序列
1.2、HL1210-3小鼠mAb的人源化
根据本领域中常用的方法和如国际申请公开WO2017-215590中公开的方法,采用mAb HL1210-3可变区基因来产生人源化Mab。
所得的人源化抗体中的一些的氨基酸和核苷酸序列列出在下表6中。
[表6]人源化抗体序列(粗体表示CDR)
合成地产生人源化VH和VK基因,然后分别克隆到包含人gamma1和人kappa恒定结构域的载体中。人VH和人VK的配对产生40种人源化抗体(见表7)。
[表7]具有其VH区和VL区的人源化抗体
1.3、PD-L1表位的鉴定
进行该研究以鉴定参与PD-L1与本公开的抗体的结合的氨基酸残基。
构建PD-L1的丙氨酸扫描文库。简言之,在Integral Molecular的蛋白质工程平台上产生217个PD-L1突变体克隆。通过高通量流式细胞术一式两份地确定Hu1210-41 Fab与PD-L1突变文库中的每个变体的结合。每个原始数据点减去背景荧光,并且针对与PD-L1野生型(WT)的反应性归一化。对于每个PD-L1变体,绘出平均结合值随表达的函数。为了鉴定初步关键克隆(具有叉号的圆圈),应用>70%WT与对照MAb(MIH1 Mab,内部制备)的结合和<30%WT对Hu1210-41 Fab的反应性的阈值(虚线)(图3)。PDL1的Y134、K162和N183被鉴定为Hu1210-41结合的必需残基。N183A克隆与Hu1210-41 Fab的低反应性表明它是Hu1210-41结合的主要有力贡献者,并且Y134和K162的贡献较小。
如图4中所示,在3D PD-L1结构上鉴定关键残基(球体)。因此,这些残基Y134、K162和N183构成负责结合到本公开的各种实施例的抗体的PD-L1的表位。
值得注意的是,Y134、K162和N183都位于PD-L1蛋白的IgC结构域内。PD-1和PD-L1两者的细胞外部分具有IgV结构域和IgC结构域。公知的是,PD-L1与PD-1通过它们IgV结构域之间的结合而结合。然而,与此类常规抗体不同,Hu1210-41结合到IgC结构域,已经预期Hu1210-41在抑制PD-1/PD-L1结合方面无效。出人意料地,Hu1210-41的这种不同表位可能有助于Hu1210-41的优异活性。
1.4、抗PD-L1抗体的抗体工程
示例1.4试图鉴定基于Hu1210-41使用诱变的进一步改善的抗体。
使用以下策略中的任何一种构建四个亚文库用于抗PD-L1单克隆抗体的抗体工程。在策略1中,通过高度随机突变执行重链可变结构域VH CDR3或VL-CDR3的诱变。在策略2中,通过具有受控突变率的CDR步移产生由(VH-CDR3、VL-CDR3和VL-CDR1)或(VH-CDR1、VH-CDR2和VL-CDR2)构成的两个CDR组合文库。
生物淘选:通过缩短在苛刻洗涤条件前的孵育/结合时间来调整噬菌体淘选方法。简言之,在室温下用1mL MPBS封闭100μL磁性链霉亲和素珠(Invitrogen,美国)1小时。在另一试管中,将文库噬菌体与1mL MPBS中的100μL磁性链霉亲和素珠(每轮5×10^11-12)预孵育以除去不需要的结合物。使用磁颗粒浓缩器以分离噬菌体和珠粒。将生物素化的PD-L1蛋白添加到噬菌体且在室温下孵育2h,并且使用顶置摇床轻轻地混合。在磁颗粒浓缩器中将携带噬菌体的珠粒从溶液分离,并且弃去上清液。将珠粒用新鲜的洗涤缓冲液洗涤,用PBST洗涤10次,用PBS(pH 7.4)洗涤10次。添加0.8mL的0.25%胰蛋白酶于PBS中(Sigma,美国),并且在37℃下温育20分钟以洗脱噬菌体。将输出噬菌体滴定并挽救以用于下一轮淘选,逐轮降低抗原浓度。
ELISA筛选和On/off率排序
从所需的淘选输出挑取并诱导克隆;进行噬菌体ELISA以便初步筛选;通过测序来分析阳性克隆;发现独特热点。
表8示出了鉴定的突变。如下所示,热点突变残基和/或其取代物加下划线。
[表8]CDR中的突变
这些抗体的可变区的氨基酸序列示出在下表9中。
[表9]抗体序列
[表10]H12和B6克隆的重链可变区
[表11]H12和B6克隆的轻链可变区
1.5、
为了探索人源化抗体的结合动力学,本示例通过使用Biacore执行亲和力排序。如下表12中所示,H12和B6。
[表12]
如表12中所示,测试的抗PD-L1抗体显示出高PD-L1结合亲和力。
示例2、抗4-1BB单克隆抗体的制备
2.1、针对4-1BB的全人单克隆抗体的筛选
针对4-1BB的噬菌体文库免疫管淘选
为了淘选针对靶分子的文库,使用4-1BB包被的免疫管总共进行四轮淘选。
将来自3轮淘选输出的细菌菌落在96深孔板中的SB-羧苄青霉素中生长直至浑浊,此时向每个孔添加1011pfu的VCSM13辅助噬菌体。在37℃下轻轻振荡(80rpm)感染1小时之后,添加70μg/mL卡那霉素,并且将细胞在30℃下以200rpm振荡培养过夜。
第二天,将板离心,并且将包含噬菌体的上清液添加到用PBST中的3%BSA封闭的4-1BB抗原包被的ELISA板。在室温下孵育1小时之后,将板用PBST洗涤三次,并且添加抗M13抗体。将板温育1小时,用PBST洗涤三次,并且使用四甲基联苯胺(TMB)测量结合活性。
扩增4-1BB特异性结合物用于质粒DNA测序。分析Ig轻链V基因(VL)和VH序列以鉴定独特序列且确定序列多样性。
[表13]重链可变区
[表14]重链CDR
[表15]轻链可变区
[表16]轻链CDR
2.2、抗4-1BB抗体与人4-1BB的抗原结合能力
为了评价抗原结合活性,对抗体候选物进行ELISA测试。简言之,在4℃下,用在PBS中的0.1μg/mL的人4-1BB Fc蛋白以100μL/孔包被微量滴定板过夜,然后用100μL/孔的5%BSA封闭。将从10μg/mL开始的人源化抗体{41B01和41B02}的五倍稀释物添加至每个孔,并且在室温下孵育1小时-2小时。将板用PBS/Tween洗涤,然后与缀合有辣根过氧化物酶(HRP)的山羊抗人IgG抗体在室温下孵育1小时。在洗涤之后,将板用TMB底物显色,并且通过分光光度计在OD 450nm-630nm处分析。如图5中所示,测试的抗4-1BB抗体显示出4-1BB结合能力。
为了评价抗原结合性质,通过FACS分析抗体候选物与哺乳动物表达的4-1BB的结合。简言之,将4-1BB-Jurkat细胞与抗体(41B01和41B02)孵育。在通过FACS缓冲液(在PBS中的1%BSA)洗涤之后,将FITC-抗人IgG抗体添加到每个孔中,并且在4℃下孵育1小时。通过FACS Caliber评价FITC的MFI。如图6中所示,所测试的抗4-1BB抗体显示出与在细胞表面上表达的4-1BB的结合能力,并且可以有效地结合到在哺乳动物细胞上表达的4-1BB。
为了探索人源化抗体的结合动力学,本示例通过使用Octet Red 96执行亲和力排序。如下表17中所示,41B01和41B02。
[表17]
如表17中所示,测试的抗4-1BB抗体显示出高4-1BB结合亲和力。
示例3、抗PD-L1/抗4-1BB双特异性抗体的制备
示例性地选择示例1中制备的抗PD-L1克隆之中的Hu1210-41(Hu1210VH.4dxHu1210 VK.1,见表6;在下文中,“H12”)和B6(见表12)克隆以及示例2中制备的抗4-1BB克隆之中的41B01、41B01.01、41B01.02、41B01.03、41B01.04和41B02克隆,以制备呈全长IgG X scFv形式的抗PD-L1/抗4-1BB双特异性抗体。当将PD-L1放置在全IgG部分中时,使用具有减少ADCC的突变骨架的IgG1(N297A突变;美国专利号7332581、美国专利号8219149等),并且当将4-1BB放置在全IgG部分中时,使用IgG4。
将具有编码抗PD-L1/抗4-1BB双特异性抗体的IgG抗体的重链的核苷酸序列的DNA区段1插入到pcDNA3.4(Invitrogen,A14697;质粒1)中,并且将具有编码抗PD-L1/抗4-1BB双特异性抗体的IgG抗体的轻链的核苷酸序列的DNA区段2插入到pcDNA3.4(Invitrogen,A14697;质粒2)中。此后,使用编码具有10个氨基酸长度(其由(GGGGS)2组成)的接头肽的DNA区段4,将编码scFv的DNA区段3融合在与插入到质粒1中的IgG抗体的Fc区的C-末端对应的DNA区段1的一部分处,以构建用于表达双特异性抗体的载体。此外,为了稳定scFv,应用另外的修饰以产生将VL103-VH44分别融合到轻链的C-末端和重链的C-末端的二硫桥。
重链、轻链、scFv和DNA区段的序列总结在表18中:
[表18]包括呈IgG形式的抗PD-L1克隆和呈scFv形式的抗4-1BB克隆的双特异性抗体(PD-L1x4-1BB)
使用(ExpiFectamine
通过重组蛋白A亲和色谱(Hitrap Mabselect Sure,GE Healthcare,28-4082-55)和用HiLoad 26/200Superdex200制备级柱(GE Healthcare,28-9893-36)的凝胶过滤色谱,从细胞培养物上清液纯化每种BsAb。执行SDS-PAGE(NuPage 4-12%Bis-Tris凝胶,NP0321)和用SE-HPLC柱(SWXL SE-HPLC柱,TOSOH,G3000SWXL)的尺寸排阻HPLC(Agilent,1200系列)分析,以检测且确认每种BsAb的尺寸和纯度。使用Amicon Ultra15 30K装置(Merck,UFC903096),通过超滤将纯化的蛋白质在PBS中浓缩,并且使用nanodrop(Thermo,NanodropOne)评价蛋白质浓度。当应用双载体系统时,轻链与重链之间的比可以是按重量计的1:1至1:3。可选地,也可以使用在一个单一载体中包含两条链的单载体系统。
制备的抗PD-L1/抗4-1BB双特异性抗体分别被命名为H12x41B01(ABLPNB.01)、H12x41B01.03(ABLPNB.02)、H12x41B02(ABLPNB.03)、B6x41B01(ABLPNB.04)、B6x41B01.01(ABLPNB.05)、B6x41B01.01(ABLPNB.06)、B6x41B01.03(ABLPNB.07)、B6x41B01.04(ABLPNB.08)和B6x41B02(ABLPNB.09),其中,前者指呈IgG形式的克隆,后者指呈scFv形式的克隆。
示例4、双特异性抗体PD-L1x4-1BB的表征
4.1、双特异性抗体的结合
为了评价示例3中制备的双特异性抗体与PD-L1和4-1BB的结合活性,对BsAb(ABLPNB.01、ABLPNB.03、ABLPNB.04和ABLPNB.07)进行DACE(双抗原捕获ELISA)测试。简言之,在4℃下,用PBS中的人PD-L1-Fc蛋白(Sinobio,10084-H02H)以100ng/孔包被微量滴定板过夜,然后在37℃下用100μL/孔的1%BSA封闭2小时。将从100nM开始的BsAb中的每个的三倍稀释液添加到每个孔中,并且在37℃下孵育2小时。将板用PBS/Tween洗涤,然后在37℃下与1%BSA中的50ng/孔的人4-1BB-His蛋白(Sinobio,16498-H08H)孵育1小时。将板用PBS/Tween洗涤,然后在37℃下与抗His HRP(Roche,Cat:11965085001)孵育1小时。在洗涤之后,将板用TMB底物显色,并且通过分光光度计在OD 450nm至650nm处分析。结果显示在图7A和图7B中。如图7A和图7B中所示,所有测试的BsAb可以以高活性结合到人PD-L1和人4-1BB蛋白两者。
4.2双特异性抗体的血清稳定性
为了评价BsAb(ABLPNB.05、ABLPNB.06、ABLPNB.07和ABLPNB.08)对PD-L1和4-1BB的血清稳定性,在37℃下将BsAb在人血清中孵育3天、7天、14天。通过DACE(双抗原捕获ELISA)测试分析结合活性。简言之,在4℃下,用PBS中的人PD-L1-Fc蛋白(Sinobio,10084-H02H)以100ng/孔包被微量滴定板过夜,然后在37℃下用100μL/孔的1%BSA封闭2小时。将从100nM开始的BsAb中的每个的三倍稀释液添加到每个孔,并且在37℃下孵育2小时。将板用PBS/Tween洗涤,然后在37℃下与1%BSA中的50ng/孔的人4-1BB-His蛋白(Sinobio,16498-H08H)孵育1小时。将板用PBS/Tween洗涤,然后在37℃下与抗His HRP(Roche,Cat:11965085001)孵育1小时。在洗涤之后,将板用TMB底物显色,并且通过分光光度计在OD450nm至650nm处分析。BsAb(ABLPNB.05至ABLPNB.08)中的每个对两种抗原的结合活性与每个样品相当。这意味着BsAb在37℃下在人血清中稳定2周。代表性日期如图8中所示。
4.3、双特异性抗体的可开发性
评估关于对BsAb(ABLPNB.02和ABLPNB.07)的PD-L1和4-1BB的物理化学性质的可开发性。通过几种分析方法评价BsAb的质量属性。简言之,通过尺寸排阻-高效液相色谱(SE-HPCL)测量纯度,并且BsAb两者显示出超过99%的高纯度。通过蛋白质热移位(PTS)与荧光标记的实时聚合酶链反应(RT-PCR)分析热稳定性。在超过67℃时观察到它们的熔解温度,这指示测试制品具有稳定的结构完整性。为了评价分子的溶解度,使用超滤(AmiconUltra-15旋转浓缩器)将蛋白质浓缩至20mg/mL。结果,通过视觉检查未观察到可见颗粒,并且通过SE-HPLC确认没有聚集体的增加。通过毛细管等电聚焦(cIEF)测量的ABLPNB.02和ABLPNB.07的等电点(pI)分别是8.26和8.35。所述pI范围适合于进行下游工艺和配方开发。总体而言,如表19中所示。这表明测试的BsAb(ABLPNB.02和ABLPNB.07)具有适当的用于成功开发的物理化学性质。
[表19]
4.4、双特异性抗体促进4-1BB信号的活性
为了测试双特异性抗体(ABLPNB.01、ABLPNB.03、ABLPNB.07和ABLPNB.08)促进4-1BB信号的能力,使用细胞类4-1BB测定。在该测定中,Glo Response
4.5、双特异性抗体促进人T细胞免疫应答的活性
为了测试双特异性抗体刺激人PBMC应答的能力,使用细胞因子产生测定。用人抗CD3抗体刺激的人PBMC用作效应细胞。表达PD-L1的HCC1954细胞用作靶细胞。在该体系中,在人抗CD3抗体的存在下,PBMC(3×10
4.6、双特异性抗体的肿瘤生长抑制(体内测定)
使用表达人4-1BB的细胞外结构域的人源化小鼠。将小鼠结肠癌细胞(MC38)工程化以表达人PD-L1。对人源化小鼠(h4-1BB)皮下植入MC38-hPD-L1细胞。对小鼠以Q3D腹膜施用5次下述抗体(每三天注射五次抗体):同种型对照(10mg/kg)、抗PD-L1抗体(H12,10mg/kg)、抗4-1BB抗体(41B01,10mg/kg)、抗PD-L1(H12,10mg/kg)和抗4-1BB(41B01,10mg/kg)的组合以及PD-L1x4-1BB双特异性抗体(BsAb){ABLPNB.01,13.3mg/kg}。在实验期间,通过卡尺每周两次测量监测肿瘤体积。由ABLPNB.01诱导的肿瘤生长抑制显著大于用每种靶向单克隆抗体的组合观察到的肿瘤生长抑制(见图11)。
本公开不受具体实施例描述的范围的限制,所述实施例仅旨在说明公开的各个方面,并且任何功能上相同的组合物或方法在本公开的范围内。对于本领域技术人员而言将明显的是,在不脱离公开的精神或范围的情况下,可以在本公开的方法和组合物中做出各种修改和变化。因此,预期的是,本公开覆盖本公开的修改和变化,只要它们在所附权利要求及其等同物的范围内即可。
本说明书中提及的所有出版物和专利申请通过引用包含于此,引用的程度如同每个单独的出版物或专利申请被具体且单独地指出通过引用而包含。
SEQ ID NO: 1
蛋白质
人工序列(Arificial Sequence)
抗PD-L1抗体的VH CDR1
SYDMS
SEQ ID NO: 2
蛋白质
人工序列(Arificial Sequence)
抗PD-L1抗体的VH CDR2
TISDAGGYIYYSDSVKG
SEQ ID NO: 3
蛋白质
人工序列(Arificial Sequence)
抗PD-L1抗体的VH CDR2
TISDAGGYIYYRDSVKG
SEQ ID NO: 4
蛋白质
人工序列(Arificial Sequence)
抗PD-L1抗体的VH CDR3
EFGKRYALDY
SEQ ID NO: 5
蛋白质
人工序列(Arificial Sequence)
抗PD-L1抗体的VH CDR3
ELPWRYALDY
SEQ ID NO: 6
蛋白质
人工序列(Arificial Sequence)
抗PD-L1抗体的VL CDR1
KASQDVTPAVA
SEQ ID NO: 7
蛋白质
人工序列(Arificial Sequence)
抗PD-L1抗体的VL CDR2
STSSRYT
SEQ ID NO: 8
蛋白质
人工序列(Arificial Sequence)
抗PD-L1抗体的VL CDR3
QQHYTTPLT
SEQ ID NO: 9
蛋白质
智人
人4-1BB 蛋白质
mgnscynivatlllvlnfertrslqdpcsncpagtfcdnnrnqicspcppnsfssaggqrtcdicrqckgvfrtrkecsstsnaecdctpgfhclgagcsmceqdckqgqeltkkgckdccfgtfndqkrgicrpwtncsldgksvlvngtkerdvvcgpspadlspgassvtppaparepghspqiisfflaltstallfllffltlrfsvvkrgrkkllyifkqpfmrpvqttqeedgcscrfpeeeeggcel
SEQ ID NO: 10
蛋白质
人工序列(Arificial Sequence)
抗4-1BB抗体的VH CDR1
SYDMS
SEQ ID NO: 11
蛋白质
人工序列(Arificial Sequence)
抗4-1BB抗体的VH CDR1
GYDMS
SEQ ID NO: 12
蛋白质
人工序列(Arificial Sequence)
抗4-1BB抗体的VH CDR2
WISYSGGSIYYADSVKG
SEQ ID NO: 13
蛋白质
人工序列(Arificial Sequence)
抗4-1BB抗体的VH CDR2
VIYPDDGNTYYADSVKG
SEQ ID NO: 14
蛋白质
人工序列(Arificial Sequence)
抗4-1BB抗体的VH CDR3
DGQRNSMREFDY
SEQ ID NO: 15
蛋白质
人工序列(Arificial Sequence)
抗4-1BB抗体的VH CDR3
HGGQKPTTKSSSAYGMDG
SEQ ID NO: 16
蛋白质
人工序列(Arificial Sequence)
抗4-1BB抗体的VH CDR3
DAQRNSMREFDY
SEQ ID NO: 17
蛋白质
人工序列(Arificial Sequence)
抗4-1BB抗体的VH CDR3
DAQRQSMREFDY
SEQ ID NO: 18
蛋白质
人工序列(Arificial Sequence)
抗4-1BB抗体的VL CDR1
SGSSSNIGNNYVT
SEQ ID NO: 19
蛋白质
人工序列(Arificial Sequence)
抗4-1BB抗体的VL CDR2
ADSHRPS
SEQ ID NO: 20
蛋白质
人工序列(Arificial Sequence)
抗4-1BB抗体的VL CDR3
ATWDYSLSGYV
SEQ ID NO: 21
蛋白质
人工序列(Arificial Sequence)
双特异性抗体中的抗4-1BB抗体的重链可变区
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDGQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 22
蛋白质
人工序列(Arificial Sequence)
双特异性抗体中的抗4-1BB抗体的重链可变区
EVQLLESGGGLVQPGGSLRLSCAASGFTFSGYDMSWVRQAPGKCLEWVSVIYPDDGNTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDAAVYYCAKHGGQKPTTKSSSAYGMDGWGQGTLVTVSS
SEQ ID NO: 23
蛋白质
人工序列(Arificial Sequence)
双特异性抗体中的抗4-1BB抗体的重链可变区
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 24
蛋白质
人工序列(Arificial Sequence)
双特异性抗体中的抗4-1BB抗体的重链可变区
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRQSMREFDYWGQGTLVTVSS
SEQ ID NO: 25
蛋白质
人工序列(Arificial Sequence)
双特异性抗体中的抗4-1BB抗体的轻链可变区
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL
SEQ ID NO: 26
蛋白质
人工序列(Arificial Sequence)
双特异性抗体中的抗4-1BB抗体的轻链可变区
QSVLTQPPSASGTPGQRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL
SEQ ID NO: 27
蛋白质
人工序列(Arificial Sequence)
ABLPNB.01的重组分
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSGGGGSGGGGSQSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVLGGGGSGGGGSGGGGSGGGGSEVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDGQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 28
蛋白质
人工序列(Arificial Sequence)
ABLPNB.01的轻组分
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO: 29
蛋白质
人工序列(Arificial Sequence)
ABLPNB.02的重组分
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSGGGGSGGGGSQSVLTQPPSASGTPGQRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVLGGGGSGGGGSGGGGSGGGGSEVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 30
蛋白质
人工序列(Arificial Sequence)
ABLPNB.02的轻组分
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO: 31
蛋白质
人工序列(Arificial Sequence)
ABLPNB.03的重组分
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSGGGGSGGGGSQSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVLGGGGSGGGGSGGGGSGGGGSEVQLLESGGGLVQPGGSLRLSCAASGFTFSGYDMSWVRQAPGKCLEWVSVIYPDDGNTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDAAVYYCAKHGGQKPTTKSSSAYGMDGWGQGTLVTVSS
SEQ ID NO: 32
蛋白质
人工序列(Arificial Sequence)
ABLPNB.03的轻组分
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO: 33
蛋白质
人工序列(Arificial Sequence)
ABLPNB.04的重组分
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSGGGGSGGGGSQSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVLGGGGSGGGGSGGGGSGGGGSEVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDGQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 34
蛋白质
人工序列(Arificial Sequence)
ABLPNB.04的轻组分
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO: 35
蛋白质
人工序列(Arificial Sequence)
ABLPNB.05的重组分
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSGGGGSGGGGSQSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVLGGGGSGGGGSGGGGSGGGGSEVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 36
蛋白质
人工序列(Arificial Sequence)
ABLPNB.05的轻组分
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO: 37
蛋白质
人工序列(Arificial Sequence)
ABLPNB.06的重组分
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSGGGGSGGGGSQSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVLGGGGSGGGGSGGGGSGGGGSEVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRQSMREFDYWGQGTLVTVSS
SEQ ID NO: 38
蛋白质
人工序列(Arificial Sequence)
ABLPNB.06的轻组分
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO: 39
蛋白质
人工序列(Arificial Sequence)
ABLPNB.07的重组分
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSGGGGSGGGGSQSVLTQPPSASGTPGQRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVLGGGGSGGGGSGGGGSGGGGSEVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 40
蛋白质
人工序列(Arificial Sequence)
ABLPNB.07的轻组分
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO: 41
蛋白质
人工序列(Arificial Sequence)
ABLPNB.08的重组分
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSGGGGSGGGGSQSVLTQPPSASGTPGQRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVLGGGGSGGGGSGGGGSGGGGSEVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRQSMREFDYWGQGTLVTVSS
SEQ ID NO: 42
蛋白质
人工序列(Arificial Sequence)
ABLPNB.08的轻组分
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO: 43
蛋白质
人工序列(Arificial Sequence)
ABLPNB.09的重组分
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSGGGGSGGGGSQSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVLGGGGSGGGGSGGGGSGGGGSEVQLLESGGGLVQPGGSLRLSCAASGFTFSGYDMSWVRQAPGKCLEWVSVIYPDDGNTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDAAVYYCAKHGGQKPTTKSSSAYGMDGWGQGTLVTVSS
SEQ ID NO: 44
蛋白质
人工序列(Arificial Sequence)
ABLPNB.09的轻组分
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO: 45
DNA
人工序列(Arificial Sequence)
HL1210-3 VH
GAAGTGAAACTGGTGGAGTCTGGGGGAGACTTAGTGAAGCCTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATTCACTTTCAGTAGCTATGACATGTCTTGGGTTCGCCAGACTCCGGAGAAGAGTCTGGAGTGGGTCGCAACCATTAGTGATGGTGGTGGTTACATCTACTATTCAGACAGTGTGAAGGGGCGATTTACCATCTCCAGAGACAATGCCAAGAACAACCTGTACCTGCAAATGAGCAGTCTGAGGTCTGAGGACACGGCCTTGTATATTTGTGCAAGAGAATTTGGTAAGCGCTATGCTTTGGACTACTGGGGTCAAGGAACCTCAGTCACCGTCTCCTCA
SEQ ID NO: 46
蛋白质
人工序列(Arificial Sequence)
HL1210-3 VH
EVKLVESGGDLVKPGGSLKLSCAASGFTFSSYDMSWVRQTPEKSLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNNLYLQMSSLRSEDTALYICAREFGKRYALDYWGQGTSVT
SEQ ID NO: 47
DNA
人工序列(Arificial Sequence)
HL1210-3 VL
GACATTGTGATGACCCAGTCTCACAAATTCATGTCCACATCGGTAGGAGACAGGGTCAGCATCTCCTGCAAGGCCAGTCAGGATGTGACTCCTGCTGTCGCCTGGTATCAACAGAAGCCAGGACAATCTCCTAAACTACTGATTTACTCCACATCCTCCCGGTACACTGGAGTCCCTGATCGCTTCACTGGCAGTGGATCTGGGACGGATTTCACTTTCACCATCAGCAGTGTGCAGGCTGAAGACCTGGCAGTTTATTACTGTCAGCAACATTATACTACTCCGCTCACGTTCGGTGCTGGGACCAAGCTGGAGCTGAAA
SEQ ID NO: 48
蛋白质
人工序列(Arificial Sequence)
HL1210-3 VL
DIVMTQSHKFMSTSVGDRVSISCKASQDVTPAVAWYQQKPGQSPKLLIYSTSSRYTGVPDRFTGSGSGTDFTFTISSVQAEDLAVYYCQQHYTTPLTFGAGTKLELK
SEQ ID NO: 49
蛋白质
人工序列(Arificial Sequence)
HL1210-VH
EVKLVESGGDLVKPGGSLKLSCAASGFTFSSYDMSWVRQTPEKSLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNNLYLQMSSLRSEDTALYICAREFGKRYALDYWGQGTSVTVSS
SEQ ID NO: 50
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.1
EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVSTISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 51
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.1a
EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 52
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.1b
EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 53
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.2
EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWIRQAPGKGLEWVSTISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 54
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.2a
EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWIRQAPGKGLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 55
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.2b
EVQLVESGGGLVKPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 56
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.3
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVSTISDGGGYIYYSDSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 57
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.3a
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDGGGYIYYSDSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 58
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.4
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVSTISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYYCAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 59
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.4a
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYYCAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 60
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.4b
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 61
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.4c
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISEGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 62
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.4d(H12 VH)
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 63
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.4e
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDVGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 64
蛋白质
人工序列(Arificial Sequence)
Hu1210 VH.5
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCAREFGKRYALDYWGQGTLVTVSS
SEQ ID NO: 65
蛋白质
人工序列(Arificial Sequence)
HU1210 VH.5a
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYICAREFGKRYALDYWGQGTLVTVSS
SEQ ID NO: 66
蛋白质
人工序列(Arificial Sequence)
HU1210 VH.5b
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 67
蛋白质
人工序列(Arificial Sequence)
HU1210 VH.5C
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNNLYLQMNSLRAEDTAVYICAREFGKRYALDYWGQGTLVTVSS
SEQ ID NO: 68
蛋白质
人工序列(Arificial Sequence)
HU1210 VH.5d
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQTPEKSLEWVATISDGGGYIYYSDSVKGRFTISRDNAKNNLYLQMNSLRAEDTAVYICAREFGKRYALDYWGQGTLVTVSS
SEQ ID NO: 69
蛋白质
人工序列(Arificial Sequence)
HL1210-VK
DIVMTQSHKFMSTSVGDRVSISCKASQDVTPAVAWYQQKPGQSPKLLIYSTSSRYTGVPDRFTGSGSGTDFTFTISSVQAEDLAVYYCQQHYTTPLTFGAGTKLELK
SEQ ID NO: 70
蛋白质
人工序列(Arificial Sequence)
Hu1210 VK.1 (H12 VL)
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIK
SEQ ID NO: 71
蛋白质
人工序列(Arificial Sequence)
Hu1210 VK.1a
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKSPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIK
SEQ ID NO: 72
蛋白质
人工序列(Arificial Sequence)
Hu1210 VK.2
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQHYTTPLTFGQGTKLEIKR
SEQ ID NO: 73
蛋白质
人工序列(Arificial Sequence)
Hu1210 VK.2a
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPDRFTGSGSGTDFTLTISSLQPEDFATYYCQQHYTTPLTFGQGTKLEIKR
SEQ ID NO: 74
蛋白质
人工序列(Arificial Sequence)
Hu1210 VK.2b
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGQSPKLLIYSTSSRYTGVPDRFTGSGSGTDFTLTISSLQPEDFATYYCQQHYTTPLTFGQGTKLEIKR
SEQ ID NO: 75
蛋白质
人工序列(Arificial Sequence)
Hu1210 VK.2c
DIQMTQSPSSLSASVGDRVTISCKASQDVTPAVAWYQQKPGQSPKLLIYSTSSRYTGVPDRFTGSGSGTDFTLTISSLQPEDFATYYCQQHYTTPLTFGQGTKLEIKR
SEQ ID NO: 76
DNA
人工序列(Arificial Sequence)
HL1210 VH
GAGGTGAAGCTGGTGGAGAGCGGCGGAGATCTGGTGAAGCCTGGCGGCAGCCTGAAGCTGAGCTGTGCCGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGGCAGACCCCCGAGAAGAGCCTGGAGTGGGTGGCCACCATCAGCGATGGCGGCGGCTACATCTACTACAGCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAACCTGTACCTGCAGATGAGCAGCCTGAGGAGCGAGGACACCGCCCTGTACATCTGCGCCAGGGAGTTCGGCAAGAGGTACGCCCTGGACTACTGGGGACAGGGCACCAGCGTGACCGTGAGCAGC
SEQ ID NO: 77
DNA
人工序列(Arificial Sequence)
Hu1210 VH.1
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAGGCCTGGAGTGGGTGAGCACCATCTCCGATGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 78
DNA
人工序列(Arificial Sequence)
Hu1210 VH.1a
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAGGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 79
DNA
Hu1210 VH.1b
人工序列(Arificial Sequence)
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 80
DNA
人工序列(Arificial Sequence)
Hu1210 VH.2
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGATCAGACAGGCCCCTGGCAAAGGCCTGGAGTGGGTGAGCACCATCTCCGATGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 81
DNA
人工序列(Arificial Sequence)
Hu1210 VH.2a
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGATCAGACAGGCCCCTGGCAAAGGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 82
DNA
人工序列(Arificial Sequence)
Hu1210 VH.2b
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGAAGCCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 83
DNA
人工序列(Arificial Sequence)
Hu1210 VH.3
GAGGTGCAGCTGCTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAGGCCTGGAGTGGGTGAGCACCATCTCCGATGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACAGCAAGAACACCCTGTACCTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 84
DNA
人工序列(Arificial Sequence)
GAGGTGCAGCTGCTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACAGCAAGAACACCCTGTACCTGCAGATGAACAGCCTGAGGGCCGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 85
DNA
人工序列(Arificial Sequence)
Hu1210 VH.4
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAGGCCTGGAGTGGGTGAGCACCATCTCCGATGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 86
DNA
人工序列(Arificial Sequence)
Hu1210 VH.4a
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAGGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACTACTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 87
DNA
人工序列(Arificial Sequence)
Hu1210 VH.4b
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 88
DNA
人工序列(Arificial Sequence)
Hu1210 VH.4c
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGAAGGCGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 89
DNA
人工序列(Arificial Sequence)
Hu1210_VH.4d
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGCGGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 90
DNA
人工序列(Arificial Sequence)
Hu1210_VH.4e
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGTTGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGC
SEQ ID NO: 91
DNA
人工序列(Arificial Sequence)
Hu1210 VH.5
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGCCTGGTGCAACCTGGAGGCTCCCTGAGGCTGTCCTGTGCCGCTTCCGGCTTCACCTTCAGCTCCTACGATATGAGCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGGCCACCATCTCCGACGGAGGCGGCTACATCTACTACTCCGACTCCGTGAAGGGCAGGTTCACCATCTCCCGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCTCTCAGGGCTGAGGACACCGCCGTGTATTACTGCGCCAGGGAGTTTGGCAAGAGGTACGCCCTGGATTACTGGGGCCAGGGCACACTGGTGACAGTGAGCTCC
SEQ ID NO: 92
DNA
人工序列(Arificial Sequence)
Hu1210 VH.5a
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGCCTGGTGCAACCTGGAGGCTCCCTGAGGCTGTCCTGTGCCGCTTCCGGCTTCACCTTCAGCTCCTACGATATGAGCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGGCCACCATCTCCGACGGAGGCGGCTACATCTACTACTCCGACTCCGTGAAGGGCAGGTTCACCATCTCCCGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCTCTCAGGGCTGAGGACACCGCCGTGTATATCTGCGCCAGGGAGTTTGGCAAGAGGTACGCCCTGGATTACTGGGGCCAGGGCACACTGGTGACAGTGAGCTCC
SEQ ID NO: 93
DNA
人工序列(Arificial Sequence)
Hu1210 VH.5b
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGCCTGGTGCAACCTGGAGGCTCCCTGAGGCTGTCCTGTGCCGCTTCCGGCTTCACCTTCAGCTCCTACGATATGAGCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGGCCACCATCTCCGACGGAGGCGGCTACATCTACTACTCCGACTCCGTGAAGGGCAGGTTCACCATCTCCCGGGACAACGCCAAGAACAACCTGTACCTGCAGATGAACTCTCTCAGGGCTGAGGACACCGCCGTGTATATCTGCGCCAGGGAGTTTGGCAAGAGGTACGCCCTGGATTACTGGGGCCAGGGCACACTGGTGACAGTGAGCTCC
SEQ ID NO: 94
DNA
人工序列(Arificial Sequence)
Hu1210 VH.5c
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGCCTGGTGCAACCTGGAGGCTCCCTGAGGCTGTCCTGTGCCGCTTCCGGCTTCACCTTCAGCTCCTACGATATGAGCTGGGTGAGGCAGACCCCTGAGAAGAGCCTGGAGTGGGTGGCCACCATCTCCGACGGAGGCGGCTACATCTACTACTCCGACTCCGTGAAGGGCAGGTTCACCATCTCCCGGGACAACGCCAAGAACAACCTGTACCTGCAGATGAACTCTCTCAGGGCTGAGGACACCGCCGTGTATATCTGCGCCAGGGAGTTTGGCAAGAGGTACGCCCTGGATTACTGGGGCCAGGGCACACTGGTGACAGTGAGCTCC
SEQ ID NO: 95
DNA
人工序列(Arificial Sequence)
Hu1210_VH.5d
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGCCTGGTGCAACCTGGAGGCTCCCTGAGGCTGTCCTGTGCCGCTTCCGGCTTCACCTTCAGCTCCTACGATATGAGCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGGCCACCATCTCCGACGGAGGCGGCTACATCTACTACTCCGACTCCGTGAAGGGCAGGTTCACCATCTCCCGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCTCTCAGGGCTGAGGACACCGCCGTGTATATCTGCGCCAGGGAGTTTGGCAAGAGGTACGCCCTGGATTACTGGGGCCAGGGCACAACCGTGACAGTGAGCTCC
SEQ ID NO: 96
DNA
人工序列(Arificial Sequence)
HL1210 VK
GACATCGTGATGACCCAGAGCCACAAGTTCATGAGCACCAGCGTGGGCGATAGGGTGAGCATCAGCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCCAGAGCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCGACAGGTTCACAGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCGTGCAGGCCGAGGACCTGGCCGTGTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCGCCGGCACCAAGCTGGAGCTGAAG
SEQ ID NO: 97
DNA
人工序列(Arificial Sequence)
Hu1210 VK.1
GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGCAGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCCGAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAG
SEQ ID NO: 98
DNA
人工序列(Arificial Sequence)
Hu1210 VK.1a
GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCAAGTCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGCAGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCCGAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAG
SEQ ID NO: 99
DNA
人工序列(Arificial Sequence)
Hu1210 VK.2
GACATTCAGATGACCCAGTCCCCTAGCAGCCTGTCCGCTTCCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGACGTGACACCTGCTGTGGCCTGGTATCAACAGAAGCCTGGCAAGGCTCCTAAGCTCCTGATCTACAGCACATCCTCCCGGTACACCGGAGTGCCCTCCAGGTTTAGCGGCAGCGGCTCCGGCACCGATTTCACCCTGACCATTTCCTCCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCAGCAGCACTACACCACACCCCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGCGG
SEQ ID NO: 100
DNA
人工序列(Arificial Sequence)
Hu1210 VK.2a
GACATTCAGATGACCCAGTCCCCTAGCAGCCTGTCCGCTTCCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGACGTGACACCTGCTGTGGCCTGGTATCAACAGAAGCCTGGCAAGGCTCCTAAGCTCCTGATCTACAGCACATCCTCCCGGTACACCGGAGTGCCCGACAGGTTTACCGGCAGCGGCTCCGGCACCGATTTCACCCTGACCATTTCCTCCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCAGCAGCACTACACCACACCCCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGCGG
SEQ ID NO: 101
DNA
人工序列(Arificial Sequence)
Hu1210 VK.2b
GACATTCAGATGACCCAGTCCCCTAGCAGCCTGTCCGCTTCCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGACGTGACACCTGCTGTGGCCTGGTATCAACAGAAGCCTGGCCAGAGCCCTAAGCTCCTGATCTACAGCACATCCTCCCGGTACACCGGAGTGCCCGACAGGTTTACCGGCAGCGGCTCCGGCACCGATTTCACCCTGACCATTTCCTCCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCAGCAGCACTACACCACACCCCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGCGG
SEQ ID NO: 102
DNA
人工序列(Arificial Sequence)
Hu1210 VK.2c
GACATTCAGATGACCCAGTCCCCTAGCAGCCTGTCCGCTTCCGTGGGCGACAGGGTGACCATCAGCTGCAAGGCCAGCCAGGACGTGACACCTGCTGTGGCCTGGTATCAACAGAAGCCTGGCCAGAGCCCTAAGCTCCTGATCTACAGCACATCCTCCCGGTACACCGGAGTGCCCGACAGGTTTACCGGCAGCGGCTCCGGCACCGATTTCACCCTGACCATTTCCTCCCTGCAGCCCGAGGACTTCGCCACCTACTACTGCCAGCAGCACTACACCACACCCCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGCGG
SEQ ID NO: 103
蛋白质
人工序列(Arificial Sequence)
H12的重链可变区
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 104
蛋白质
人工序列(Arificial Sequence)
B6的重链可变区
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSS
SEQ ID NO: 105
蛋白质
人工序列(Arificial Sequence)
H12的轻链可变区
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIK
SEQ ID NO: 106
蛋白质
人工序列(Arificial Sequence)
B6的轻链可变区
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIK
SEQ ID NO: 107
蛋白质
人工序列(Arificial Sequence)
CDR-H1的WT
SYDMS
SEQ ID NO: 108
蛋白质
人工序列(Arificial Sequence)
CDR-H1的B3
SYDMS
SEQ ID NO: 109
蛋白质
人工序列(Arificial Sequence)
CDR-H1的C4
SYDMS
SEQ ID NO: 110
蛋白质
人工序列(Arificial Sequence)
CDR-H1的B1
SYDMS
SEQ ID NO: 111
蛋白质
人工序列(Arificial Sequence)
CDR-H1的B6
SYDMS
SEQ ID NO: 112
蛋白质
人工序列(Arificial Sequence)
CDR-H1的C3
SYDMS
SEQ ID NO: 113
蛋白质
人工序列(Arificial Sequence)
CDR-H1的C6
SYDMS
SEQ ID NO: 114
蛋白质
人工序列(Arificial Sequence)
CDR-H1的A1
SYDMS
SEQ ID NO: 115
蛋白质
人工序列(Arificial Sequence)
CDR-H1的A2
SYDMS
SEQ ID NO: 116
蛋白质
人工序列(Arificial Sequence)
CDR-H1的A3
SYDMS
SEQ ID NO: 117
蛋白质
人工序列(Arificial Sequence)
CDR-H2的WT
TISDAGGYIYYSDSVKG
SEQ ID NO: 118
蛋白质
人工序列(Arificial Sequence)
CDR-H2的B3
TISDAGGYIYYRDSVKG
SEQ ID NO: 119
蛋白质
人工序列(Arificial Sequence)
CDR-H2的C4
TISDAGGYIYYRDSVKG
SEQ ID NO: 120
蛋白质
人工序列(Arificial Sequence)
CDR-H2的B1
TISDAGGYIYYRDSVKG
SEQ ID NO: 121
蛋白质
人工序列(Arificial Sequence)
CDR-H2的B6
TISDAGGYIYYRDSVKG
SEQ ID NO: 122
蛋白质
人工序列(Arificial Sequence)
CDR-H2的C3
TISDAGGYIYYRDSVKG
SEQ ID NO: 123
蛋白质
人工序列(Arificial Sequence)
CDR-H2的C6
TISDAGGYIYYRDSVKG
SEQ ID NO: 124
蛋白质
人工序列(Arificial Sequence)
CDR-H2的A1
TISDAGGYIYYRDSVKG
SEQ ID NO: 125
蛋白质
人工序列(Arificial Sequence)
CDR-H2的A2
TISDAGGYIYYRDSVKG
SEQ ID NO: 126
蛋白质
人工序列(Arificial Sequence)
CDR-H2的A3
TISDAGGYIYYRDSVKG
SEQ ID NO: 127
蛋白质
人工序列(Arificial Sequence)
CDR-H3的WT
EFGKRYALDY
SEQ ID NO: 128
蛋白质
人工序列(Arificial Sequence)
CDR-H3的B3
EFGKRYALDY
SEQ ID NO: 129
蛋白质
人工序列(Arificial Sequence)
CDR-H3的C4
EFGKRYALDS
SEQ ID NO: 130
蛋白质
人工序列(Arificial Sequence)
CDR-H3的B1
EIFNRYALDY
SEQ ID NO: 131
蛋白质
人工序列(Arificial Sequence)
CDR-H3的B6
ELPWRYALDY
SEQ ID NO: 132
蛋白质
人工序列(Arificial Sequence)
CDR-H3的C3
ELHFRYALDY
SEQ ID NO: 133
蛋白质
人工序列(Arificial Sequence)
CDR-H3的C6
ELYFRYALDY
SEQ ID NO: 134
蛋白质
人工序列(Arificial Sequence)
CDR-H3的A1
ELLHRYALDY
SEQ ID NO: 135
蛋白质
人工序列(Arificial Sequence)
CDR-H3的A2
ELRGRYALDY
SEQ ID NO: 136
蛋白质
人工序列(Arificial Sequence)
CDR-H3的A3
EFGKRYALDY
SEQ ID NO: 137
蛋白质
人工序列(Arificial Sequence)
CDR-L1的WT
KASQDVTPAVA
SEQ ID NO: 138
蛋白质
人工序列(Arificial Sequence)
CDR-L1的B3
KAKQDVTPAVA
SEQ ID NO: 139
蛋白质
人工序列(Arificial Sequence)
CDR-L1的C4
KASQDVWPAVA
SEQ ID NO: 140
蛋白质
人工序列(Arificial Sequence)
CDR-L1的B1
KASQDVTPAVA
SEQ ID NO: 141
蛋白质
人工序列(Arificial Sequence)
CDR-L1的B6
KASQDVTPAVA
SEQ ID NO: 142
蛋白质
人工序列(Arificial Sequence)
CDR-L1的C3
KASQDVTPAVA
SEQ ID NO: 143
蛋白质
人工序列(Arificial Sequence)
CDR-L1的C6
KASQDVTPAVA
SEQ ID NO: 144
蛋白质
人工序列(Arificial Sequence)
CDR-L1的A1
KASQDVTPAVA
SEQ ID NO: 145
蛋白质
人工序列(Arificial Sequence)
CDR-L1的A2
KASQDVTPAVA
SEQ ID NO: 146
蛋白质
人工序列(Arificial Sequence)
CDR-L1的A3
KASQDVTPAVA
SEQ ID NO: 147
蛋白质
人工序列(Arificial Sequence)
CDR-L2的WT
STSSRYT
SEQ ID NO: 148
蛋白质
人工序列(Arificial Sequence)
CDR-L2的B3
STSSRYT
SEQ ID NO: 149
蛋白质
人工序列(Arificial Sequence)
CDR-L2的C4
STSSRYT
SEQ ID NO: 150
蛋白质
人工序列(Arificial Sequence)
CDR-L2的B1
STSSRYT
SEQ ID NO: 151
蛋白质
人工序列(Arificial Sequence)
CDR-L2的B6
STSSRYT
SEQ ID NO: 152
蛋白质
人工序列(Arificial Sequence)
CDR-L2的C3
STSSRYT
SEQ ID NO: 153
蛋白质
人工序列(Arificial Sequence)
CDR-L2的C6
STSSRYT
SEQ ID NO: 154
蛋白质
人工序列(Arificial Sequence)
CDR-L2的A1
STSSRYT
SEQ ID NO: 155
蛋白质
人工序列(Arificial Sequence)
CDR-L2的A2
STSSRYT
SEQ ID NO: 156
蛋白质
人工序列(Arificial Sequence)
CDR-L2的A3
STSSRYT
SEQ ID NO: 157
蛋白质
人工序列(Arificial Sequence)
CDR-L3的WT
QQHYTTPLT
SEQ ID NO: 158
蛋白质
人工序列(Arificial Sequence)
CDR-L3的B3
MQHYTTPLT
SEQ ID NO: 159
蛋白质
人工序列(Arificial Sequence)
CDR-L3的C4
QQHSTTPLT
SEQ ID NO: 160
蛋白质
人工序列(Arificial Sequence)
CDR-L3的B1
QQHYTTPLT
SEQ ID NO: 161
蛋白质
人工序列(Arificial Sequence)
CDR-L3的B6
QQHYTTPLT
SEQ ID NO: 162
蛋白质
人工序列(Arificial Sequence)
CDR-L3的C3
QQHYTTPLT
SEQ ID NO: 163
蛋白质
人工序列(Arificial Sequence)
CDR-L3的C6
QQHYTTPLT
SEQ ID NO: 164
蛋白质
人工序列(Arificial Sequence)
CDR-L3的A1
QQHYTTPLT
SEQ ID NO: 165
蛋白质
人工序列(Arificial Sequence)
CDR-L3的A2
QQHYTTPLT
SEQ ID NO: 166
蛋白质
人工序列(Arificial Sequence)
CDR-L3的A3
QQHSDAPLT
SEQ ID NO: 167
蛋白质
人工序列(Arificial Sequence)
WT-VH
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 168
蛋白质
人工序列(Arificial Sequence)
WT- VK
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIK
SEQ ID NO: 169
蛋白质
人工序列(Arificial Sequence)
B3-VH
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 170
蛋白质
人工序列(Arificial Sequence)
B3- VK
DIQMTQSPSSLSASVGDRVTITCKAKQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCMQHYTTPLTFGQGTKLEIK
SEQ ID NO: 171
蛋白质
人工序列(Arificial Sequence)
C4-VH
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDSWGQGTTVTVSS
SEQ ID NO: 172
蛋白质
人工序列(Arificial Sequence)
C4- VK
DIQMTQSPSSLSASVGDRVTITCKASQDVWPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHSTTPLTFGQGTKLEIK
SEQ ID NO: 173
蛋白质
人工序列(Arificial Sequence)
B1-VH
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREIFNRYALDYWGQGTTVTVSS
SEQ ID NO: 174
蛋白质
人工序列(Arificial Sequence)
B1- VK
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIK
SEQ ID NO: 175
蛋白质
人工序列(Arificial Sequence)
B6-VH
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSS
SEQ ID NO: 176
蛋白质
人工序列(Arificial Sequence)
B6- VK
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIK
SEQ ID NO: 177
蛋白质
人工序列(Arificial Sequence)
C3-VH
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELHFRYALDYWGQGTTVTVSS
SEQ ID NO: 178
蛋白质
人工序列(Arificial Sequence)
C3- VK
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIK
SEQ ID NO: 179
蛋白质
人工序列(Arificial Sequence)
C6-VH
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELYFRYALDYWGQGTTVTVSS
SEQ ID NO: 180
蛋白质
人工序列(Arificial Sequence)
C6- VK
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIK
SEQ ID NO: 181
蛋白质
人工序列(Arificial Sequence)
A1-VH
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELLHRYALDYWGQGTTVTVSS
SEQ ID NO: 182
蛋白质
人工序列(Arificial Sequence)
A1- VK
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIK
SEQ ID NO: 183
蛋白质
人工序列(Arificial Sequence)
A2-VH
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELRGRYALDYWGQGTTVTVSS
SEQ ID NO: 184
蛋白质
人工序列(Arificial Sequence)
A2- VK
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHYTTPLTFGQGTKLEIK
SEQ ID NO: 185
蛋白质
人工序列(Arificial Sequence)
A3-VH
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSS
SEQ ID NO: 186
蛋白质
人工序列(Arificial Sequence)
A3- VK
DIQMTQSPSSLSASVGDRVTITCKASQDVTPAVAWYQQKPGKAPKLLIYSTSSRYTGVPSRFSGSGSGTDFTFTISSLQPEDIATYYCQQHSDAPLTFGQGTKLEIK
SEQ ID NO: 187
蛋白质
人工序列(Arificial Sequence)
41B01的重链可变区
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDGQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 188
蛋白质
人工序列(Arificial Sequence)
41B01.01的重链可变区
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 189
蛋白质
人工序列(Arificial Sequence)
41B01.02的重链可变区
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRQSMREFDYWGQGTLVTVSS
SEQ ID NO: 190
蛋白质
人工序列(Arificial Sequence)
41B01.03的重链可变区
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 191
蛋白质
人工序列(Arificial Sequence)
41B01.04的重链可变区
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKGLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRQSMREFDYWGQGTLVTVSS
SEQ ID NO: 192
蛋白质
人工序列(Arificial Sequence)
41B02的重链可变区
EVQLLESGGGLVQPGGSLRLSCAASGFTFSGYDMSWVRQAPGKGLEWVSVIYPDDGNTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDAAVYYCAKHGGQKPTTKSSSAYGMDGWGQGTLVTVSS
SEQ ID NO: 193
蛋白质
人工序列(Arificial Sequence)
41B01的轻链可变区
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGGGTKLTVL
SEQ ID NO: 194
蛋白质
人工序列(Arificial Sequence)
41B01.01的轻链可变区
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGGGTKLTVL
SEQ ID NO: 195
蛋白质
人工序列(Arificial Sequence)
41B01.02的轻链可变区
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGGGTKLTVL
SEQ ID NO: 196
蛋白质
人工序列(Arificial Sequence)
41B01.03的轻链可变区
QSVLTQPPSASGTPGQRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGGGTKLTVL
SEQ ID NO: 197
蛋白质
人工序列(Arificial Sequence)
41B01.04的轻链可变区
QSVLTQPPSASGTPGQRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGGGTKLTVL
SEQ ID NO: 198
蛋白质
人工序列(Arificial Sequence)
41B02的轻链可变区
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGGGTKLTVL
SEQ ID NO: 199
蛋白质
人工序列(Arificial Sequence)
ABLPNB.01的重组分中的H12的重链
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 200
蛋白质
人工序列(Arificial Sequence)
ABLPNB.01的重组分的接头
GGGGSGGGGSGGGGS
SEQ ID NO: 201
蛋白质
人工序列(Arificial Sequence)
ABLPNB.01中的41B01的scFv的VL
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL
SEQ ID NO: 202
蛋白质
人工序列(Arificial Sequence)
ABLPNB.01中的41B01的scFv的接头
GGGGSGGGGSGGGGSGGGGS
SEQ ID NO: 203
蛋白质
人工序列(Arificial Sequence)
ABLPNB.01中的41B01的scFv的VH
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDGQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 204
DNA
人工序列(Arificial Sequence)
ABLPNB.01的重组分
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGCGGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGCgctAgcAccAAgGGCCCCTCTGTGTTCCCTCTGGCCCCTTCCTCTAAATCCACCTCTGGCGGAACCGCTGCTCTGGGCTGTCTGGTCAAGGACTACTTCCCTGAGCCCGTGACCGTGTCTTGGAATTCTGGCGCTCTGACCAGCGGAGTGCACACCTTTCCAGCTGTGCTGCAGTCCTCCGGCCTGTACTCTCTGTCCTCTGTCGTGACAGTGCCTTCCAGCTCTCTGGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCCTCCAACACCAAGGTGGACAAGAAGGTGGAACCCAAGTCCTGCGACAAGACCCACACCTGTCCTCCATGTCCTGCTCCAGAACTGCTGGGCGGACCCTCCGTGTTCCTGTTCCCTCCAAAGCCTAAGGACACCCTGATGATCTCCCGGACCCCTGAAGTGACCTGCGTGGTGGTGGATGTGTCCCACGAGGATCCCGAAGTGAAGTTCAATTGGTACGTGGACGGCGTGGAAGTGCACAACGCCAAGACCAAGCCTAGAGAGGAACAGTACgccTCCACCTACCGGGTGGTGTCCGTGCTGACCGTTCTGCACCAGGATTGGCTGAACGGCAAAGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAAAAGACCATCTCTAAGGCCAAGGGCCAGCCCCGGGAACCTCAAGTGTACACCTTGCCTCCCAGCCGGGAAGAGATGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTTAAGGGCTTCTACCCCTCCGATATCGCCGTGGAATGGGAGTCTAACGGCCAGCCCGAGAACAACTACAAGACCACCCCTCCTGTGCTGGACTCCGACGGCTCATTCTTCCTGTACTCCAAGCTGACCGTGGACAAGTCTCGGTGGCAGCAGGGCAACGTGTTCTCCTGCTCTGTGATGCACGAGGCCCTGCACAACCACTACACCCAGAAGTCCCTGTCCCTGTCTCCCGGCAAAGGTGGGGGGGGATCTGGTGGTGGTGGATCAGGGGGTGGGGGGTCTCAAAGCGTACTCACCCAACCTCCATCTGCATCCGGTACACCTGGTCGGCGAGTAACCATCTCCTGCTCTGGGAGCTCTTCTAATATTGGTAACAACTATGTCACCTGGTATCAGCAGTTGCCTGGGACAGCACCCAAACTTCTTATATATGCCGATAGCCATCGGCCTTCCGGCGTACCCGATCGCTTCTCCGGGTCAAAATCTGGAACATCTGCCTCACTCGCAATTAGTGGATTGCGATCTGAGGATGAAGCAGATTATTATTGCGCTACCTGGGATTATTCACTTTCTGGCTACGTCTTTGGTtgtggaACAAAACTTACCGTGTTGGGCGGCGGAGGAAGCGGAGGCGGCGGTTCTGGTGGTGGCGGTAGCGGAGGTGGTGGATCTGAAGTACAGCTTCTTGAGTCTGGCGGAGGATTGGTCCAGCCAGGCGGTTCCCTCCGCCTGTCATGTGCCGCATCCGGCTTTACTTTCTCTAGTTATGATATGAGCTGGGTTCGCCAAGCTCCTGGCAAAtgcCTGGAGTGGGTCTCCTGGATTTCATACTCAGGTGGCAGCATCTATTATGCTGACAGTGTGAAAGGTCGCTTTACAATCTCCCGAGATAACAGCAAAAACACCTTGTACCTGCAAATGAACAGCCTTCGCGCAGAGGACACAGCCGTATATTATTGCGCTCGCGATGGACAACGTAATTCTATGCGTGAGTTTGACTACTGGGGACAGGGGACATTGGTCACTGTATCTTCCtga
SEQ ID NO: 205
DNA
人工序列(Arificial Sequence)
ABLPNB.01的轻组分
GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGCAGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCCGAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGAGAACCGTGGCCGCTCCCTCCGTGTTCATCTTCCCACCATCTGACGAGCAGCTGAAGTCCGGCACCGCTTCTGTCGTGTGCCTGCTGAACAACTTCTACCCTCGGGAAGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGTCCGGCAACTCCCAAGAGTCTGTGACCGAGCAGGACTCCAAGGACAGCACCTACTCCCTGTCCTCTACCCTGACCCTGTCCAAGGCCGACTACGAGAAGCACAAGGTGTACGCCTGCGAAGTGACCCACCAGGGACTGTCTAGCCCCGTGACCAAGTCCTTCAACAGAGGCGAGTGCTGA
SEQ ID NO: 206
蛋白质
人工序列(Arificial Sequence)
ABLPNB.02的重组分中的H12的重链
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 207
蛋白质
人工序列(Arificial Sequence)
ABLPNB.02的重组分的接头
GGGGSGGGGSGGGGS
SEQ ID NO: 208
蛋白质
人工序列(Arificial Sequence)
ABLPNB.02中的41B01.03的scFv的VL
QSVLTQPPSASGTPGQRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL
SEQ ID NO: 209
蛋白质
人工序列(Arificial Sequence)
ABLPNB.02中的41B01.03的scFv的接头
GGGGSGGGGSGGGGSGGGGS
SEQ ID NO: 210
蛋白质
人工序列(Arificial Sequence)
ABLPNB.02中的41B01.03的scFv的VH
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 211
DNA
人工序列(Arificial Sequence)
ABLPNB.02的重组分
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGCGGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGCgctAgcAccAAgGGCCCCTCTGTGTTCCCTCTGGCCCCTTCCTCTAAATCCACCTCTGGCGGAACCGCTGCTCTGGGCTGTCTGGTCAAGGACTACTTCCCTGAGCCCGTGACCGTGTCTTGGAATTCTGGCGCTCTGACCAGCGGAGTGCACACCTTTCCAGCTGTGCTGCAGTCCTCCGGCCTGTACTCTCTGTCCTCTGTCGTGACAGTGCCTTCCAGCTCTCTGGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCCTCCAACACCAAGGTGGACAAGAAGGTGGAACCCAAGTCCTGCGACAAGACCCACACCTGTCCTCCATGTCCTGCTCCAGAACTGCTGGGCGGACCCTCCGTGTTCCTGTTCCCTCCAAAGCCTAAGGACACCCTGATGATCTCCCGGACCCCTGAAGTGACCTGCGTGGTGGTGGATGTGTCCCACGAGGATCCAGAAGTGAAGTTCAATTGGTACGTGGACGGCGTGGAAGTGCACAATGCCAAGACCAAGCCTAGAGAGGAACAGTACGCCTCCACCTACAGAGTGGTGTCCGTGCTGACTGTGCTGCACCAGGATTGGCTGAACGGCAAAGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCTGCTCCTATCGAAAAGACCATCAGCAAGGCCAAGGGCCAGCCTAGGGAACCCCAGGTTTACACCCTGCCTCCAAGCCGGGAAGAGATGACCAAGAACCAGGTGTCCCTGACCTGCCTCGTGAAGGGCTTCTACCCTTCCGATATCGCCGTGGAATGGGAGAGCAATGGCCAGCCTGAGAACAACTACAAGACAACCCCTCCTGTGCTGGACTCCGACGGCTCATTCTTCCTGTACTCCAAGCTGACCGTGGACAAGTCCAGATGGCAGCAGGGCAACGTGTTCTCCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGTCCCTGTCTCTGAGCCCTGGAAAAGGCGGCGGAGGATCTGGCGGAGGTGGTAGCGGAGGCGGTGGATCTCAGTCTGTTCTGACCCAGCCTCCTTCCGCTTCTGGCACCCCTGGAcAGAGAGTGACCATCTCTTGCTCCGGCTCCTCCTCCAACATCGGCAACAACTACGTGACCTGGTATCAGCAGCTGCCCGGCACAGCTCCCAAACTGCTGATCTACGCCGACTCTCACAGACCTTCCGGCGTGCCCGATAGATTCTCCGGCTCTAAGTCTGGCACCTCTGCCAGCCTGGCTATCAGCGGCCTGAGATCTGAGGACGAGGCCGACTACTACTGCGCCACCTGGGATTATTCCCTGTCCGGCTACGTGTTCGGCTGCGGCACAAAACTGACAGTGCTCGGAGGCGGAGGAAGTGGTGGCGGAGGTTCAGGTGGTGGTGGTAGTGGCGGAGGCGGATCAGAAGTTCAGCTGTTGGAGTCAGGTGGCGGCTTGGTGCAACCAGGTGGAAGTCTGAGACTCAGCTGTGCTGCCAGCGGCTTTACCTTCAGCTCCTACGACATGAGCTGGGTTCGACAAGCTCCCGGAAAGTGCTTGGAGTGGGTTTCCTGGATCTCCTACTCCGGCGGCAGCATCTATTACGCCGACAGCGTGAAAGGCCGGTTTACCATCTCTCGGGATAACAGCAAGAATACCCTCTACCTCCAAATGAACTCTCTGAGAGCCGAGGACACTGCTGTGTACTATTGCGCCAGAGATGccCAGCGGAACTCCATGAGAGAGTTCGACTACTGGGGACAAGGCACCCTGGTCACCGTGTCTAGTTGA
SEQ ID NO: 212
DNA
人工序列(Arificial Sequence)
ABLPNB.02的轻组分
GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGCAGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCCGAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGAGAACCGTGGCCGCTCCCTCCGTGTTCATCTTCCCACCATCTGACGAGCAGCTGAAGTCCGGCACCGCTTCTGTCGTGTGCCTGCTGAACAACTTCTACCCTCGGGAAGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGTCCGGCAACTCCCAAGAGTCTGTGACCGAGCAGGACTCCAAGGACAGCACCTACTCCCTGTCCTCTACCCTGACCCTGTCCAAGGCCGACTACGAGAAGCACAAGGTGTACGCCTGCGAAGTGACCCACCAGGGACTGTCTAGCCCCGTGACCAAGTCCTTCAACAGAGGCGAGTGCTGA
SEQ ID NO: 213
蛋白质
人工序列(Arificial Sequence)
ABLPNB.03的重组分中的H12的重链
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYSDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICAREFGKRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 214
蛋白质
人工序列(Arificial Sequence)
ABLPNB.03的重组分的接头
GGGGSGGGGSGGGGS
SEQ ID NO: 215
蛋白质
人工序列(Arificial Sequence)
ABLPNB.03中的41B02的scFv的VL
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL
SEQ ID NO: 216
蛋白质
人工序列(Arificial Sequence)
ABLPNB.03中的41B02的scFv的接头
GGGGSGGGGSGGGGSGGGGS
SEQ ID NO: 217
蛋白质
人工序列(Arificial Sequence)
ABLPNB.03中的41B02的scFv的VH
EVQLLESGGGLVQPGGSLRLSCAASGFTFSGYDMSWVRQAPGKCLEWVSVIYPDDGNTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDAAVYYCAKHGGQKPTTKSSSAYGMDGWGQGTLVTVSS
SEQ ID NO: 218
DNA
人工序列(Arificial Sequence)
ABLPNB.03的重组分
GAGGTGCAGCTGGTGGAGAGCGGAGGAGGACTGGTGCAACCCGGAGGCAGCCTGAGACTGAGCTGCGCTGCCAGCGGCTTCACCTTCAGCAGCTACGACATGAGCTGGGTGAGACAGGCCCCTGGCAAAAGCCTGGAGTGGGTGGCCACCATCTCCGATGCGGGCGGCTACATCTATTACTCCGACAGCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACAGCCTGTACCTGCAGATGAACAGCCTGAGGGATGAGGACACCGCCGTGTACATCTGCGCCAGGGAGTTCGGCAAAAGGTACGCCCTGGACTACTGGGGCCAGGGCACAACCGTGACCGTGAGCAGCgctAgcAccAAgGGCCCCTCTGTGTTCCCTCTGGCCCCTTCCTCTAAATCCACCTCTGGCGGAACCGCTGCTCTGGGCTGTCTGGTCAAGGACTACTTCCCTGAGCCCGTGACCGTGTCTTGGAATTCTGGCGCTCTGACCAGCGGAGTGCACACCTTTCCAGCTGTGCTGCAGTCCTCCGGCCTGTACTCTCTGTCCTCTGTCGTGACAGTGCCTTCCAGCTCTCTGGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCCTCCAACACCAAGGTGGACAAGAAGGTGGAACCCAAGTCCTGCGACAAGACCCACACCTGTCCTCCATGTCCTGCTCCAGAACTGCTGGGCGGACCCTCCGTGTTCCTGTTCCCTCCAAAGCCTAAGGACACCCTGATGATCTCCCGGACCCCTGAAGTGACCTGCGTGGTGGTGGATGTGTCCCACGAGGATCCCGAAGTGAAGTTCAATTGGTACGTGGACGGCGTGGAAGTGCACAACGCCAAGACCAAGCCTAGAGAGGAACAGTACgccTCCACCTACCGGGTGGTGTCCGTGCTGACCGTTCTGCACCAGGATTGGCTGAACGGCAAAGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAAAAGACCATCTCTAAGGCCAAGGGCCAGCCCCGGGAACCTCAAGTGTACACCTTGCCTCCCAGCCGGGAAGAGATGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTTAAGGGCTTCTACCCCTCCGATATCGCCGTGGAATGGGAGTCTAACGGCCAGCCCGAGAACAACTACAAGACCACCCCTCCTGTGCTGGACTCCGACGGCTCATTCTTCCTGTACTCCAAGCTGACCGTGGACAAGTCTCGGTGGCAGCAGGGCAACGTGTTCTCCTGCTCTGTGATGCACGAGGCCCTGCACAACCACTACACCCAGAAGTCCCTGTCCCTGTCTCCCGGCAAAGGTGGGGGGGGATCTGGTGGTGGTGGATCAGGGGGTGGGGGGTCTCAAAGCGTACTCACCCAACCTCCATCTGCATCCGGTACACCTGGTCGGCGAGTAACCATCTCCTGCTCTGGGAGCTCTTCTAATATTGGTAACAACTATGTCACCTGGTATCAGCAGTTGCCTGGGACAGCACCCAAACTTCTTATATATGCCGATAGCCATCGGCCTTCCGGCGTACCCGATCGCTTCTCCGGGTCAAAATCTGGAACATCTGCCTCACTCGCAATTAGTGGATTGCGATCTGAGGATGAAGCAGATTATTATTGCGCTACCTGGGATTATTCACTTTCTGGCTACGTCTTTGGTtgtGGAACAAAACTTACCGTGTTGGGCGGCGGAGGAAGCGGAGGCGGCGGTTCTGGTGGTGGCGGTAGCGGAGGTGGTGGATCTGAGGTTCAACTGTTGGAGTCAGGTGGCGGACTTGTCCAGCCTGGCGGGTCTCTGAGGCTGAGTTGCGCTGCTTCTGGGTTTACTTTTTCAGGATATGACATGAGTTGGGTACGTCAGGCTCCAGGTAAGtgcCTCGAATGGGTCTCCGTTATCTATCCCGATGATGGAAATACTTACTACGCTGACAGTGTGAAAGGCAGGTTCACAATCAGTAGGGACAATTCTAAAAATACACTCTACCTCCAGATGAACTCACTTCGAGCCGAGGACGCCGCCGTATATTACTGTGCCAAACACGGCGGGCAAAAACCCACTACTAAATCCAGTAGTGCTTACGGGATGGATGGCTGGGGACAGGGGACATTGGTCACTGTATCTTCCtga
SEQ ID NO: 219
DNA
人工序列(Arificial Sequence)
ABLPNB.03的轻组分
GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGCAGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCCGAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGAGAACCGTGGCCGCTCCCTCCGTGTTCATCTTCCCACCATCTGACGAGCAGCTGAAGTCCGGCACCGCTTCTGTCGTGTGCCTGCTGAACAACTTCTACCCTCGGGAAGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGTCCGGCAACTCCCAAGAGTCTGTGACCGAGCAGGACTCCAAGGACAGCACCTACTCCCTGTCCTCTACCCTGACCCTGTCCAAGGCCGACTACGAGAAGCACAAGGTGTACGCCTGCGAAGTGACCCACCAGGGACTGTCTAGCCCCGTGACCAAGTCCTTCAACAGAGGCGAGTGCTGA
SEQ ID NO: 220
蛋白质
人工序列(Arificial Sequence)
ABLPNB.04的重组分中的B6的重链
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 221
蛋白质
人工序列(Arificial Sequence)
ABLPNB.04的重组分的接头
GGGGSGGGGSGGGGS
SEQ ID NO: 222
蛋白质
人工序列(Arificial Sequence)
ABLPNB.04中的41B01的scFv的VL
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL
SEQ ID NO: 223
蛋白质
人工序列(Arificial Sequence)
ABLPNB.04中的41B01的scFv的接头
GGGGSGGGGSGGGGSGGGGS
SEQ ID NO: 224
蛋白质
人工序列(Arificial Sequence)
ABLPNB.04中的41B01的scFv的VH
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDGQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 225
DNA
人工序列(Arificial Sequence)
ABLPNB.04的重组分
GAAGTGCAGCTGGTTGAATCTGGCGGCGGATTGGTTCAGCCTGGCGGATCTCTGAGACTGTCTTGTGCCGCCTCCGGCTTCACCTTCTCCAGCTACGATATGTCCTGGGTCCGACAGGCCCCTGGCAAGTCTTTGGAATGGGTCGCCACCATCTCTGACGCTGGCGGCTACATCTACTACCGGGACTCTGTGAAGGGCAGATTCACCATCAGCCGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACAGCCTGCGCGACGAGGATACCGCCGTGTACATCTGTGCTAGAGAGCTGCCTTGGAGATACGCCCTGGATTATTGGGGCCAGGGCACCACAGTGACCGTGTCCTCTGCTTCTACCAAGGGACCCAGCGTGTTCCCTCTGGCTCCTTCCAGCAAGTCTACCTCTGGCGGAACAGCTGCTCTGGGCTGCCTGGTCAAGGACTACTTTCCTGAGCCTGTGACAGTGTCCTGGAACTCTGGCGCTCTGACATCTGGCGTGCACACCTTTCCAGCAGTGCTGCAGTCCTCCGGCCTGTACTCTCTGTCCTCTGTCGTGACCGTGCCTTCCAGCTCTCTGGGAACCCAGACCTACATCTGCAATGTGAACCACAAGCCTTCCAACACCAAGGTGGACAAGAAGGTGGAACCCAAGTCCTGCGACAAGACCCACACCTGTCCTCCATGTCCTGCTCCAGAACTGCTCGGCGGACCTTCCGTGTTCCTGTTTCCTCCAAAGCCTAAGGACACCCTGATGATCTCTCGGACCCCTGAAGTGACCTGCGTGGTGGTGGATGTGTCCCACGAGGATCCAGAAGTGAAGTTCAATTGGTACGTGGACGGCGTGGAAGTGCACAATGCCAAGACCAAGCCTAGAGAGGAACAGTACGCCTCCACCTACAGAGTGGTGTCCGTGCTGACTGTGCTGCACCAGGATTGGCTGAACGGCAAAGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCTGCTCCTATCGAAAAGACCATCAGCAAGGCCAAGGGCCAGCCTAGGGAACCCCAGGTTTACACCCTGCCTCCAAGCCGGGAAGAGATGACCAAGAACCAGGTGTCCCTGACCTGCCTCGTGAAGGGCTTCTACCCTTCCGATATCGCCGTGGAATGGGAGAGCAATGGCCAGCCTGAGAACAACTACAAGACAACCCCTCCTGTGCTGGACTCCGACGGCTCATTCTTCCTGTACTCCAAGCTGACCGTGGACAAGTCCAGATGGCAGCAGGGCAACGTGTTCTCCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGTCCCTGTCTCTGAGCCCTGGAAAAGGCGGCGGAGGATCTGGCGGAGGTGGTAGCGGAGGCGGTGGATCTCAGTCTGTTCTGACCCAGCCTCCTTCCGCTTCTGGCACCCCTGGAAGAAGAGTGACCATCTCTTGCTCCGGCTCCTCCTCCAACATCGGCAACAACTACGTGACCTGGTATCAGCAGCTGCCCGGCACAGCTCCCAAACTGCTGATCTACGCCGACTCTCACAGACCTTCCGGCGTGCCCGATAGATTCTCCGGCTCTAAGTCTGGCACCTCTGCCAGCCTGGCTATCAGCGGCCTGAGATCTGAGGACGAGGCCGACTACTACTGCGCCACCTGGGATTATTCCCTGTCCGGCTACGTGTTCGGCTGCGGCACAAAACTGACAGTGCTCGGAGGCGGAGGAAGTGGTGGCGGAGGTTCAGGTGGTGGTGGTAGTGGCGGAGGCGGATCAGAAGTTCAGCTGTTGGAGTCAGGTGGCGGCTTGGTGCAACCAGGTGGAAGTCTGAGACTCAGCTGTGCTGCCAGCGGCTTTACCTTCAGCTCCTACGACATGAGCTGGGTTCGACAAGCTCCCGGAAAGTGCTTGGAGTGGGTTTCCTGGATCTCCTACTCCGGCGGCAGCATCTATTACGCCGACAGCGTGAAAGGCCGGTTTACCATCTCTCGGGATAACAGCAAGAATACCCTCTACCTCCAAATGAACTCTCTGAGAGCCGAGGACACTGCTGTGTACTATTGCGCCAGAGATGGCCAGCGGAACTCCATGAGAGAGTTCGACTACTGGGGACAAGGCACCCTGGTCACCGTGTCTAGTTGA
SEQ ID NO: 226
DNA
人工序列(Arificial Sequence)
ABLPNB.04的轻组分
GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGCAGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCCGAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGAGAACCGTGGCCGCTCCCTCCGTGTTCATCTTCCCACCATCTGACGAGCAGCTGAAGTCCGGCACCGCTTCTGTCGTGTGCCTGCTGAACAACTTCTACCCTCGGGAAGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGTCCGGCAACTCCCAAGAGTCTGTGACCGAGCAGGACTCCAAGGACAGCACCTACTCCCTGTCCTCTACCCTGACCCTGTCCAAGGCCGACTACGAGAAGCACAAGGTGTACGCCTGCGAAGTGACCCACCAGGGACTGTCTAGCCCCGTGACCAAGTCCTTCAACAGAGGCGAGTGCTGA
SEQ ID NO: 227
蛋白质
人工序列(Arificial Sequence)
ABLPNB.05的重组分中的B6的重链
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 228
蛋白质
人工序列(Arificial Sequence)
ABLPNB.05的重组分的接头
GGGGSGGGGSGGGGS
SEQ ID NO: 229
蛋白质
人工序列(Arificial Sequence)
ABLPNB.05中的41B01.01的scFv的VL
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL
SEQ ID NO: 230
蛋白质
人工序列(Arificial Sequence)
ABLPNB.05中的41B01.01的scFv的接头
GGGGSGGGGSGGGGSGGGGS
SEQ ID NO: 231
蛋白质
人工序列(Arificial Sequence)
ABLPNB.05中的41B01.01的scFv的VH
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 232
DNA
人工序列(Arificial Sequence)
ABLPNB.05的重组分
GAAGTGCAGCTGGTTGAATCTGGCGGCGGATTGGTTCAGCCTGGCGGATCTCTGAGACTGTCTTGTGCCGCCTCCGGCTTCACCTTCTCCAGCTACGATATGTCCTGGGTCCGACAGGCCCCTGGCAAGTCTTTGGAATGGGTCGCCACCATCTCTGACGCTGGCGGCTACATCTACTACCGGGACTCTGTGAAGGGCAGATTCACCATCAGCCGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACAGCCTGCGCGACGAGGATACCGCCGTGTACATCTGTGCTAGAGAGCTGCCTTGGAGATACGCCCTGGATTATTGGGGCCAGGGCACCACAGTGACCGTGTCCTCTGCTTCTACCAAGGGACCCAGCGTGTTCCCTCTGGCTCCTTCCAGCAAGTCTACCTCTGGCGGAACAGCTGCTCTGGGCTGCCTGGTCAAGGACTACTTTCCTGAGCCTGTGACAGTGTCCTGGAACTCTGGCGCTCTGACATCTGGCGTGCACACCTTTCCAGCAGTGCTGCAGTCCTCCGGCCTGTACTCTCTGTCCTCTGTCGTGACCGTGCCTTCCAGCTCTCTGGGAACCCAGACCTACATCTGCAATGTGAACCACAAGCCTTCCAACACCAAGGTGGACAAGAAGGTGGAACCCAAGTCCTGCGACAAGACCCACACCTGTCCTCCATGTCCTGCTCCAGAACTGCTCGGCGGACCTTCCGTGTTCCTGTTTCCTCCAAAGCCTAAGGACACCCTGATGATCTCTCGGACCCCTGAAGTGACCTGCGTGGTGGTGGATGTGTCCCACGAGGATCCAGAAGTGAAGTTCAATTGGTACGTGGACGGCGTGGAAGTGCACAATGCCAAGACCAAGCCTAGAGAGGAACAGTACGCCTCCACCTACAGAGTGGTGTCCGTGCTGACTGTGCTGCACCAGGATTGGCTGAACGGCAAAGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCTGCTCCTATCGAAAAGACCATCAGCAAGGCCAAGGGCCAGCCTAGGGAACCCCAGGTTTACACCCTGCCTCCAAGCCGGGAAGAGATGACCAAGAACCAGGTGTCCCTGACCTGCCTCGTGAAGGGCTTCTACCCTTCCGATATCGCCGTGGAATGGGAGAGCAATGGCCAGCCTGAGAACAACTACAAGACAACCCCTCCTGTGCTGGACTCCGACGGCTCATTCTTCCTGTACTCCAAGCTGACCGTGGACAAGTCCAGATGGCAGCAGGGCAACGTGTTCTCCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGTCCCTGTCTCTGAGCCCTGGAAAAGGCGGCGGAGGATCTGGCGGAGGTGGTAGCGGAGGCGGTGGATCTCAGTCTGTTCTGACCCAGCCTCCTTCCGCTTCTGGCACCCCTGGAAGAAGAGTGACCATCTCTTGCTCCGGCTCCTCCTCCAACATCGGCAACAACTACGTGACCTGGTATCAGCAGCTGCCCGGCACAGCTCCCAAACTGCTGATCTACGCCGACTCTCACAGACCTTCCGGCGTGCCCGATAGATTCTCCGGCTCTAAGTCTGGCACCTCTGCCAGCCTGGCTATCAGCGGCCTGAGATCTGAGGACGAGGCCGACTACTACTGCGCCACCTGGGATTATTCCCTGTCCGGCTACGTGTTCGGCTGCGGCACAAAACTGACAGTGCTCGGAGGCGGAGGAAGTGGTGGCGGAGGTTCAGGTGGTGGTGGTAGTGGCGGAGGCGGATCAGAAGTTCAGCTGTTGGAGTCAGGTGGCGGCTTGGTGCAACCAGGTGGAAGTCTGAGACTCAGCTGTGCTGCCAGCGGCTTTACCTTCAGCTCCTACGACATGAGCTGGGTTCGACAAGCTCCCGGAAAGTGCTTGGAGTGGGTTTCCTGGATCTCCTACTCCGGCGGCAGCATCTATTACGCCGACAGCGTGAAAGGCCGGTTTACCATCTCTCGGGATAACAGCAAGAATACCCTCTACCTCCAAATGAACTCTCTGAGAGCCGAGGACACTGCTGTGTACTATTGCGCCAGAGATGccCAGCGGAACTCCATGAGAGAGTTCGACTACTGGGGACAAGGCACCCTGGTCACCGTGTCTAGTTGA
SEQ ID NO: 233
DNA
人工序列(Arificial Sequence)
ABLPNB.05的轻组分
GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGCAGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCCGAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGAGAACCGTGGCCGCTCCCTCCGTGTTCATCTTCCCACCATCTGACGAGCAGCTGAAGTCCGGCACCGCTTCTGTCGTGTGCCTGCTGAACAACTTCTACCCTCGGGAAGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGTCCGGCAACTCCCAAGAGTCTGTGACCGAGCAGGACTCCAAGGACAGCACCTACTCCCTGTCCTCTACCCTGACCCTGTCCAAGGCCGACTACGAGAAGCACAAGGTGTACGCCTGCGAAGTGACCCACCAGGGACTGTCTAGCCCCGTGACCAAGTCCTTCAACAGAGGCGAGTGCTGA
SEQ ID NO: 234
蛋白质
人工序列(Arificial Sequence)
ABLPNB.06的重组分中的B6的重链
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 235
蛋白质
人工序列(Arificial Sequence)
ABLPNB.06的重组分的接头
GGGGSGGGGSGGGGS
SEQ ID NO: 236
蛋白质
人工序列(Arificial Sequence)
ABLPNB.06中的41B01.02的scFv的VL
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL
SEQ ID NO: 237
蛋白质
人工序列(Arificial Sequence)
ABLPNB.06中的41B01.02的scFv的接头
GGGGSGGGGSGGGGSGGGGS
SEQ ID NO: 238
蛋白质
人工序列(Arificial Sequence)
ABLPNB.06中的41B01.02的scFv的VH
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRQSMREFDYWGQGTLVTVSS
SEQ ID NO: 239
DNA
人工序列(Arificial Sequence)
ABLPNB.06的重组分
GTGCAGCTGGTTGAATCTGGCGGCGGATTGGTTCAGCCTGGCGGATCTCTGAGACTGTCTTGTGCCGCCTCCGGCTTCACCTTCTCCAGCTACGATATGTCCTGGGTCCGACAGGCCCCTGGCAAGTCTTTGGAATGGGTCGCCACCATCTCTGACGCTGGCGGCTACATCTACTACCGGGACTCTGTGAAGGGCAGATTCACCATCAGCCGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACAGCCTGCGCGACGAGGATACCGCCGTGTACATCTGTGCTAGAGAGCTGCCTTGGAGATACGCCCTGGATTATTGGGGCCAGGGCACCACAGTGACCGTGTCCTCTGCTTCTACCAAGGGACCCAGCGTGTTCCCTCTGGCTCCTTCCAGCAAGTCTACCTCTGGCGGAACAGCTGCTCTGGGCTGCCTGGTCAAGGACTACTTTCCTGAGCCTGTGACAGTGTCCTGGAACTCTGGCGCTCTGACATCTGGCGTGCACACCTTTCCAGCAGTGCTGCAGTCCTCCGGCCTGTACTCTCTGTCCTCTGTCGTGACCGTGCCTTCCAGCTCTCTGGGAACCCAGACCTACATCTGCAATGTGAACCACAAGCCTTCCAACACCAAGGTGGACAAGAAGGTGGAACCCAAGTCCTGCGACAAGACCCACACCTGTCCTCCATGTCCTGCTCCAGAACTGCTCGGCGGACCTTCCGTGTTCCTGTTTCCTCCAAAGCCTAAGGACACCCTGATGATCTCTCGGACCCCTGAAGTGACCTGCGTGGTGGTGGATGTGTCCCACGAGGATCCAGAAGTGAAGTTCAATTGGTACGTGGACGGCGTGGAAGTGCACAATGCCAAGACCAAGCCTAGAGAGGAACAGTACGCCTCCACCTACAGAGTGGTGTCCGTGCTGACTGTGCTGCACCAGGATTGGCTGAACGGCAAAGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCTGCTCCTATCGAAAAGACCATCAGCAAGGCCAAGGGCCAGCCTAGGGAACCCCAGGTTTACACCCTGCCTCCAAGCCGGGAAGAGATGACCAAGAACCAGGTGTCCCTGACCTGCCTCGTGAAGGGCTTCTACCCTTCCGATATCGCCGTGGAATGGGAGAGCAATGGCCAGCCTGAGAACAACTACAAGACAACCCCTCCTGTGCTGGACTCCGACGGCTCATTCTTCCTGTACTCCAAGCTGACCGTGGACAAGTCCAGATGGCAGCAGGGCAACGTGTTCTCCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGTCCCTGTCTCTGAGCCCTGGAAAAGGCGGCGGAGGATCTGGCGGAGGTGGTAGCGGAGGCGGTGGATCTCAGTCTGTTCTGACCCAGCCTCCTTCCGCTTCTGGCACCCCTGGAAGAAGAGTGACCATCTCTTGCTCCGGCTCCTCCTCCAACATCGGCAACAACTACGTGACCTGGTATCAGCAGCTGCCCGGCACAGCTCCCAAACTGCTGATCTACGCCGACTCTCACAGACCTTCCGGCGTGCCCGATAGATTCTCCGGCTCTAAGTCTGGCACCTCTGCCAGCCTGGCTATCAGCGGCCTGAGATCTGAGGACGAGGCCGACTACTACTGCGCCACCTGGGATTATTCCCTGTCCGGCTACGTGTTCGGCTGCGGCACAAAACTGACAGTGCTCGGAGGCGGAGGAAGTGGTGGCGGAGGTTCAGGTGGTGGTGGTAGTGGCGGAGGCGGATCAGAAGTTCAGCTGTTGGAGTCAGGTGGCGGCTTGGTGCAACCAGGTGGAAGTCTGAGACTCAGCTGTGCTGCCAGCGGCTTTACCTTCAGCTCCTACGACATGAGCTGGGTTCGACAAGCTCCCGGAAAGTGCTTGGAGTGGGTTTCCTGGATCTCCTACTCCGGCGGCAGCATCTATTACGCCGACAGCGTGAAAGGCCGGTTTACCATCTCTCGGGATAACAGCAAGAATACCCTCTACCTCCAAATGAACTCTCTGAGAGCCGAGGACACTGCTGTGTACTATTGCGCCAGAGATGccCAGCGGCAATCCATGAGAGAGTTCGACTACTGGGGACAAGGCACCCTGGTCACCGTGTCTAGTTGA
SEQ ID NO: 240
DNA
人工序列(Arificial Sequence)
ABLPNB.06的轻组分
GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGCAGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCCGAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGAGAACCGTGGCCGCTCCCTCCGTGTTCATCTTCCCACCATCTGACGAGCAGCTGAAGTCCGGCACCGCTTCTGTCGTGTGCCTGCTGAACAACTTCTACCCTCGGGAAGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGTCCGGCAACTCCCAAGAGTCTGTGACCGAGCAGGACTCCAAGGACAGCACCTACTCCCTGTCCTCTACCCTGACCCTGTCCAAGGCCGACTACGAGAAGCACAAGGTGTACGCCTGCGAAGTGACCCACCAGGGACTGTCTAGCCCCGTGACCAAGTCCTTCAACAGAGGCGAGTGCTGA
SEQ ID NO: 241
蛋白质
人工序列(Arificial Sequence)
ABLPNB.07的重组分中的B6的重链
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 242
蛋白质
人工序列(Arificial Sequence)
ABLPNB.07的重组分的接头
GGGGSGGGGSGGGGS
SEQ ID NO: 243
蛋白质
人工序列(Arificial Sequence)
ABLPNB.07中的41B01.03的scFv的VL
QSVLTQPPSASGTPGQRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL
SEQ ID NO: 244
蛋白质
人工序列(Arificial Sequence)
ABLPNB.07中的41B01.03的scFv的接头
GGGGSGGGGSGGGGSGGGGS
SEQ ID NO: 245
蛋白质
人工序列(Arificial Sequence)
ABLPNB.07中的41B01.04的scFv的VH
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRNSMREFDYWGQGTLVTVSS
SEQ ID NO: 246
DNA
人工序列(Arificial Sequence)
ABLPNB.07的重组分
GAAGTGCAGCTGGTTGAATCTGGCGGCGGATTGGTTCAGCCTGGCGGATCTCTGAGACTGTCTTGTGCCGCCTCCGGCTTCACCTTCTCCAGCTACGATATGTCCTGGGTCCGACAGGCCCCTGGCAAGTCTTTGGAATGGGTCGCCACCATCTCTGACGCTGGCGGCTACATCTACTACCGGGACTCTGTGAAGGGCAGATTCACCATCAGCCGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACAGCCTGCGCGACGAGGATACCGCCGTGTACATCTGTGCTAGAGAGCTGCCTTGGAGATACGCCCTGGATTATTGGGGCCAGGGCACCACAGTGACCGTGTCCTCTGCTTCTACCAAGGGACCCAGCGTGTTCCCTCTGGCTCCTTCCAGCAAGTCTACCTCTGGCGGAACAGCTGCTCTGGGCTGCCTGGTCAAGGACTACTTTCCTGAGCCTGTGACAGTGTCCTGGAACTCTGGCGCTCTGACATCTGGCGTGCACACCTTTCCAGCAGTGCTGCAGTCCTCCGGCCTGTACTCTCTGTCCTCTGTCGTGACCGTGCCTTCCAGCTCTCTGGGAACCCAGACCTACATCTGCAATGTGAACCACAAGCCTTCCAACACCAAGGTGGACAAGAAGGTGGAACCCAAGTCCTGCGACAAGACCCACACCTGTCCTCCATGTCCTGCTCCAGAACTGCTCGGCGGACCTTCCGTGTTCCTGTTTCCTCCAAAGCCTAAGGACACCCTGATGATCTCTCGGACCCCTGAAGTGACCTGCGTGGTGGTGGATGTGTCCCACGAGGATCCAGAAGTGAAGTTCAATTGGTACGTGGACGGCGTGGAAGTGCACAATGCCAAGACCAAGCCTAGAGAGGAACAGTACGCCTCCACCTACAGAGTGGTGTCCGTGCTGACTGTGCTGCACCAGGATTGGCTGAACGGCAAAGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCTGCTCCTATCGAAAAGACCATCAGCAAGGCCAAGGGCCAGCCTAGGGAACCCCAGGTTTACACCCTGCCTCCAAGCCGGGAAGAGATGACCAAGAACCAGGTGTCCCTGACCTGCCTCGTGAAGGGCTTCTACCCTTCCGATATCGCCGTGGAATGGGAGAGCAATGGCCAGCCTGAGAACAACTACAAGACAACCCCTCCTGTGCTGGACTCCGACGGCTCATTCTTCCTGTACTCCAAGCTGACCGTGGACAAGTCCAGATGGCAGCAGGGCAACGTGTTCTCCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGTCCCTGTCTCTGAGCCCTGGAAAAGGCGGCGGAGGATCTGGCGGAGGTGGTAGCGGAGGCGGTGGATCTCAGTCTGTTCTGACCCAGCCTCCTTCCGCTTCTGGCACCCCTGGAcAGAGAGTGACCATCTCTTGCTCCGGCTCCTCCTCCAACATCGGCAACAACTACGTGACCTGGTATCAGCAGCTGCCCGGCACAGCTCCCAAACTGCTGATCTACGCCGACTCTCACAGACCTTCCGGCGTGCCCGATAGATTCTCCGGCTCTAAGTCTGGCACCTCTGCCAGCCTGGCTATCAGCGGCCTGAGATCTGAGGACGAGGCCGACTACTACTGCGCCACCTGGGATTATTCCCTGTCCGGCTACGTGTTCGGCTGCGGCACAAAACTGACAGTGCTCGGAGGCGGAGGAAGTGGTGGCGGAGGTTCAGGTGGTGGTGGTAGTGGCGGAGGCGGATCAGAAGTTCAGCTGTTGGAGTCAGGTGGCGGCTTGGTGCAACCAGGTGGAAGTCTGAGACTCAGCTGTGCTGCCAGCGGCTTTACCTTCAGCTCCTACGACATGAGCTGGGTTCGACAAGCTCCCGGAAAGTGCTTGGAGTGGGTTTCCTGGATCTCCTACTCCGGCGGCAGCATCTATTACGCCGACAGCGTGAAAGGCCGGTTTACCATCTCTCGGGATAACAGCAAGAATACCCTCTACCTCCAAATGAACTCTCTGAGAGCCGAGGACACTGCTGTGTACTATTGCGCCAGAGATGccCAGCGGAACTCCATGAGAGAGTTCGACTACTGGGGACAAGGCACCCTGGTCACCGTGTCTAGTTGA
SEQ ID NO: 247
DNA
人工序列(Arificial Sequence)
ABLPNB.07的轻组分
GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGCAGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCCGAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGAGAACCGTGGCCGCTCCCTCCGTGTTCATCTTCCCACCATCTGACGAGCAGCTGAAGTCCGGCACCGCTTCTGTCGTGTGCCTGCTGAACAACTTCTACCCTCGGGAAGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGTCCGGCAACTCCCAAGAGTCTGTGACCGAGCAGGACTCCAAGGACAGCACCTACTCCCTGTCCTCTACCCTGACCCTGTCCAAGGCCGACTACGAGAAGCACAAGGTGTACGCCTGCGAAGTGACCCACCAGGGACTGTCTAGCCCCGTGACCAAGTCCTTCAACAGAGGCGAGTGCTGA
SEQ ID NO: 248
蛋白质
人工序列(Arificial Sequence)
ABLPNB.08的重组分中的B6的重链
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 249
蛋白质
人工序列(Arificial Sequence)
ABLPNB.08的重组分的接头
GGGGSGGGGSGGGGS
SEQ ID NO: 250
蛋白质
人工序列(Arificial Sequence)
ABLPNB.08中的41B01.04的scFv的VL
QSVLTQPPSASGTPGQRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL
SEQ ID NO: 251
蛋白质
人工序列(Arificial Sequence)
ABLPNB.08中的41B01.04的scFv的接头
GGGGSGGGGSGGGGSGGGGS
SEQ ID NO: 252
蛋白质
人工序列(Arificial Sequence)
ABLPNB.08中的41B01.04的scFv的VH
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKCLEWVSWISYSGGSIYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARDAQRQSMREFDYWGQGTLVTVSS
SEQ ID NO: 253
DNA
人工序列(Arificial Sequence)
ABLPNB.08的重组分
GAAGTGCAGCTGGTTGAATCTGGCGGCGGATTGGTTCAGCCTGGCGGATCTCTGAGACTGTCTTGTGCCGCCTCCGGCTTCACCTTCTCCAGCTACGATATGTCCTGGGTCCGACAGGCCCCTGGCAAGTCTTTGGAATGGGTCGCCACCATCTCTGACGCTGGCGGCTACATCTACTACCGGGACTCTGTGAAGGGCAGATTCACCATCAGCCGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACAGCCTGCGCGACGAGGATACCGCCGTGTACATCTGTGCTAGAGAGCTGCCTTGGAGATACGCCCTGGATTATTGGGGCCAGGGCACCACAGTGACCGTGTCCTCTGCTTCTACCAAGGGACCCAGCGTGTTCCCTCTGGCTCCTTCCAGCAAGTCTACCTCTGGCGGAACAGCTGCTCTGGGCTGCCTGGTCAAGGACTACTTTCCTGAGCCTGTGACAGTGTCCTGGAACTCTGGCGCTCTGACATCTGGCGTGCACACCTTTCCAGCAGTGCTGCAGTCCTCCGGCCTGTACTCTCTGTCCTCTGTCGTGACCGTGCCTTCCAGCTCTCTGGGAACCCAGACCTACATCTGCAATGTGAACCACAAGCCTTCCAACACCAAGGTGGACAAGAAGGTGGAACCCAAGTCCTGCGACAAGACCCACACCTGTCCTCCATGTCCTGCTCCAGAACTGCTCGGCGGACCTTCCGTGTTCCTGTTTCCTCCAAAGCCTAAGGACACCCTGATGATCTCTCGGACCCCTGAAGTGACCTGCGTGGTGGTGGATGTGTCCCACGAGGATCCAGAAGTGAAGTTCAATTGGTACGTGGACGGCGTGGAAGTGCACAATGCCAAGACCAAGCCTAGAGAGGAACAGTACGCCTCCACCTACAGAGTGGTGTCCGTGCTGACTGTGCTGCACCAGGATTGGCTGAACGGCAAAGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCTGCTCCTATCGAAAAGACCATCAGCAAGGCCAAGGGCCAGCCTAGGGAACCCCAGGTTTACACCCTGCCTCCAAGCCGGGAAGAGATGACCAAGAACCAGGTGTCCCTGACCTGCCTCGTGAAGGGCTTCTACCCTTCCGATATCGCCGTGGAATGGGAGAGCAATGGCCAGCCTGAGAACAACTACAAGACAACCCCTCCTGTGCTGGACTCCGACGGCTCATTCTTCCTGTACTCCAAGCTGACCGTGGACAAGTCCAGATGGCAGCAGGGCAACGTGTTCTCCTGCTCCGTGATGCACGAGGCCCTGCACAATCACTACACCCAGAAGTCCCTGTCTCTGAGCCCTGGAAAAGGCGGCGGAGGATCTGGCGGAGGTGGTAGCGGAGGCGGTGGATCTCAGTCTGTTCTGACCCAGCCTCCTTCCGCTTCTGGCACCCCTGGAcAGAGAGTGACCATCTCTTGCTCCGGCTCCTCCTCCAACATCGGCAACAACTACGTGACCTGGTATCAGCAGCTGCCCGGCACAGCTCCCAAACTGCTGATCTACGCCGACTCTCACAGACCTTCCGGCGTGCCCGATAGATTCTCCGGCTCTAAGTCTGGCACCTCTGCCAGCCTGGCTATCAGCGGCCTGAGATCTGAGGACGAGGCCGACTACTACTGCGCCACCTGGGATTATTCCCTGTCCGGCTACGTGTTCGGCTGCGGCACAAAACTGACAGTGCTCGGAGGCGGAGGAAGTGGTGGCGGAGGTTCAGGTGGTGGTGGTAGTGGCGGAGGCGGATCAGAAGTTCAGCTGTTGGAGTCAGGTGGCGGCTTGGTGCAACCAGGTGGAAGTCTGAGACTCAGCTGTGCTGCCAGCGGCTTTACCTTCAGCTCCTACGACATGAGCTGGGTTCGACAAGCTCCCGGAAAGTGCTTGGAGTGGGTTTCCTGGATCTCCTACTCCGGCGGCAGCATCTATTACGCCGACAGCGTGAAAGGCCGGTTTACCATCTCTCGGGATAACAGCAAGAATACCCTCTACCTCCAAATGAACTCTCTGAGAGCCGAGGACACTGCTGTGTACTATTGCGCCAGAGATGccCAGCGGCAATCCATGAGAGAGTTCGACTACTGGGGACAAGGCACCCTGGTCACCGTGTCTAGTTGA
SEQ ID NO: 254
DNA
人工序列(Arificial Sequence)
ABLPNB.08的轻组分
GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGCAGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCCGAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGAGAACCGTGGCCGCTCCCTCCGTGTTCATCTTCCCACCATCTGACGAGCAGCTGAAGTCCGGCACCGCTTCTGTCGTGTGCCTGCTGAACAACTTCTACCCTCGGGAAGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGTCCGGCAACTCCCAAGAGTCTGTGACCGAGCAGGACTCCAAGGACAGCACCTACTCCCTGTCCTCTACCCTGACCCTGTCCAAGGCCGACTACGAGAAGCACAAGGTGTACGCCTGCGAAGTGACCCACCAGGGACTGTCTAGCCCCGTGACCAAGTCCTTCAACAGAGGCGAGTGCTGA
SEQ ID NO: 255
蛋白质
人工序列(Arificial Sequence)
ABLPNB.09的重组分中的B6的重链
EVQLVESGGGLVQPGGSLRLSCAASGFTFSSYDMSWVRQAPGKSLEWVATISDAGGYIYYRDSVKGRFTISRDNAKNSLYLQMNSLRDEDTAVYICARELPWRYALDYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 256
蛋白质
人工序列(Arificial Sequence)
ABLPNB.09的重组分的接头
GGGGSGGGGSGGGGS
SEQ ID NO: 257
蛋白质
人工序列(Arificial Sequence)
ABLPNB.09中的41B02的scFv的VL
QSVLTQPPSASGTPGRRVTISCSGSSSNIGNNYVTWYQQLPGTAPKLLIYADSHRPSGVPDRFSGSKSGTSASLAISGLRSEDEADYYCATWDYSLSGYVFGCGTKLTVL
SEQ ID NO: 258
蛋白质
人工序列(Arificial Sequence)
ABLPNB.09中的41B02的scFv的接头
GGGGSGGGGSGGGGSGGGGS
SEQ ID NO: 259
蛋白质
人工序列(Arificial Sequence)
ABLPNB.09中的41B02的scFv的VH
EVQLLESGGGLVQPGGSLRLSCAASGFTFSGYDMSWVRQAPGKCLEWVSVIYPDDGNTYYADSVKGRFTISRDNSKNTLYLQMNSLRAEDAAVYYCAKHGGQKPTTKSSSAYGMDGWGQGTLVTVSS
SEQ ID NO: 260
DNA
人工序列(Arificial Sequence)
ABLPNB.09的重组分
GAAGTGCAGCTGGTTGAATCTGGCGGCGGATTGGTTCAGCCTGGCGGATCTCTGAGACTGTCTTGTGCCGCCTCCGGCTTCACCTTCTCCAGCTACGATATGTCCTGGGTCCGACAGGCCCCTGGCAAGTCTTTGGAATGGGTCGCCACCATCTCTGACGCTGGCGGCTACATCTACTACCGGGACTCTGTGAAGGGCAGATTCACCATCAGCCGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACAGCCTGCGCGACGAGGATACCGCCGTGTACATCTGTGCTAGAGAGCTGCCTTGGAGATACGCCCTGGATTATTGGGGCCAGGGCACCACAGTGACCGTGTCCTCTGCTTCTACCAAGGGACCCAGCGTGTTCCCTCTGGCTCCTTCCAGCAAGTCTACCTCTGGCGGAACAGCTGCTCTGGGCTGCCTGGTCAAGGACTACTTTCCTGAGCCTGTGACAGTGTCCTGGAACTCTGGCGCTCTGACATCTGGCGTGCACACCTTTCCAGCAGTGCTGCAGTCCTCCGGCCTGTACTCTCTGTCCTCTGTCGTGACCGTGCCTTCCAGCTCTCTGGGCACCCAGACCTACATCTGCAACGTGAACCACAAGCCCTCCAACACCAAGGTGGACAAGAAGGTGGAACCCAAGTCCTGCGACAAGACCCACACCTGTCCTCCATGTCCTGCTCCAGAACTGCTGGGCGGACCCTCCGTGTTCCTGTTCCCTCCAAAGCCTAAGGACACCCTGATGATCTCCCGGACCCCTGAAGTGACCTGCGTGGTGGTGGATGTGTCCCACGAGGATCCCGAAGTGAAGTTCAATTGGTACGTGGACGGCGTGGAAGTGCACAACGCCAAGACCAAGCCTAGAGAGGAACAGTACgccTCCACCTACCGGGTGGTGTCCGTGCTGACCGTTCTGCACCAGGATTGGCTGAACGGCAAAGAGTACAAGTGCAAGGTGTCCAACAAGGCCCTGCCTGCCCCTATCGAAAAGACCATCTCTAAGGCCAAGGGCCAGCCCCGGGAACCTCAAGTGTACACCTTGCCTCCCAGCCGGGAAGAGATGACCAAGAACCAGGTGTCCCTGACCTGCCTGGTTAAGGGCTTCTACCCCTCCGATATCGCCGTGGAATGGGAGTCTAACGGCCAGCCCGAGAACAACTACAAGACCACCCCTCCTGTGCTGGACTCCGACGGCTCATTCTTCCTGTACTCCAAGCTGACCGTGGACAAGTCTCGGTGGCAGCAGGGCAACGTGTTCTCCTGCTCTGTGATGCACGAGGCCCTGCACAACCACTACACCCAGAAGTCCCTGTCCCTGTCTCCCGGCAAAGGTGGGGGGGGATCTGGTGGTGGTGGATCAGGGGGTGGGGGGTCTCAAAGCGTACTCACCCAACCTCCATCTGCATCCGGTACACCTGGTCGGCGAGTAACCATCTCCTGCTCTGGGAGCTCTTCTAATATTGGTAACAACTATGTCACCTGGTATCAGCAGTTGCCTGGGACAGCACCCAAACTTCTTATATATGCCGATAGCCATCGGCCTTCCGGCGTACCCGATCGCTTCTCCGGGTCAAAATCTGGAACATCTGCCTCACTCGCAATTAGTGGATTGCGATCTGAGGATGAAGCAGATTATTATTGCGCTACCTGGGATTATTCACTTTCTGGCTACGTCTTTGGTtgtGGAACAAAACTTACCGTGTTGGGCGGCGGAGGAAGCGGAGGCGGCGGTTCTGGTGGTGGCGGTAGCGGAGGTGGTGGATCTGAGGTTCAACTGTTGGAGTCAGGTGGCGGACTTGTCCAGCCTGGCGGGTCTCTGAGGCTGAGTTGCGCTGCTTCTGGGTTTACTTTTTCAGGATATGACATGAGTTGGGTACGTCAGGCTCCAGGTAAGtgcCTCGAATGGGTCTCCGTTATCTATCCCGATGATGGAAATACTTACTACGCTGACAGTGTGAAAGGCAGGTTCACAATCAGTAGGGACAATTCTAAAAATACACTCTACCTCCAGATGAACTCACTTCGAGCCGAGGACGCCGCCGTATATTACTGTGCCAAACACGGCGGGCAAAAACCCACTACTAAATCCAGTAGTGCTTACGGGATGGATGGCTGGGGACAGGGGACATTGGTCACTGTATCTTCCtga
SEQ ID NO: 261
DNA
人工序列(Arificial Sequence)
ABLPNB.09的轻组分
GACATCCAGATGACCCAGAGCCCTAGCAGCCTGAGCGCTAGCGTGGGCGACAGGGTGACCATCACCTGCAAGGCCAGCCAGGATGTGACCCCTGCCGTGGCCTGGTACCAGCAGAAGCCCGGCAAGGCCCCCAAGCTGCTGATCTACAGCACCAGCAGCAGGTACACCGGCGTGCCCAGCAGGTTTAGCGGAAGCGGCAGCGGCACCGACTTCACCTTCACCATCAGCAGCCTGCAGCCCGAGGACATCGCCACCTACTACTGCCAGCAGCACTACACCACCCCTCTGACCTTCGGCCAGGGCACCAAGCTGGAGATCAAGAGAACCGTGGCCGCTCCCTCCGTGTTCATCTTCCCACCATCTGACGAGCAGCTGAAGTCCGGCACCGCTTCTGTCGTGTGCCTGCTGAACAACTTCTACCCTCGGGAAGCCAAGGTGCAGTGGAAGGTGGACAATGCCCTGCAGTCCGGCAACTCCCAAGAGTCTGTGACCGAGCAGGACTCCAAGGACAGCACCTACTCCCTGTCCTCTACCCTGACCCTGTCCAAGGCCGACTACGAGAAGCACAAGGTGTACGCCTGCGAAGTGACCCACCAGGGACTGTCTAGCCCCGTGACCAAGTCCTTCAACAGAGGCGAGTGCTGA
SEQ ID NO: 262
DNA
人工序列(Arificial Sequence)
抗PD-L1抗体的VH CDR3
EFGKRYALDS
SEQ ID NO: 263
DNA
人工序列(Arificial Sequence)
抗PD-L1抗体的VH CDR3
EIFNRYALDY
SEQ ID NO: 264
DNA
人工序列(Arificial Sequence)
抗PD-L1抗体的VH CDR3
ELHFRYALDY
SEQ ID NO: 265
DNA
人工序列(Arificial Sequence)
抗PD-L1抗体的VH CDR3
ELYFRYALDY
SEQ ID NO: 266
DNA
人工序列(Arificial Sequence)
抗PD-L1抗体的VH CDR3
ELLHRYALDY
SEQ ID NO: 267
DNA
人工序列(Arificial Sequence)
抗PD-L1抗体的VH CDR3
ELRGRYALDY
SEQ ID NO: 268
DNA
人工序列(Arificial Sequence)
抗PD-L1抗体的VL CDR1
KAKQDVTPAVA
SEQ ID NO: 269
DNA
人工序列(Arificial Sequence)
抗PD-L1抗体的VL CDR1
KASQDVWPAVA
SEQ ID NO: 270
DNA
人工序列(Arificial Sequence)
抗PD-L1抗体的VL CDR3
MQHYTTPLT
SEQ ID NO: 271
DNA
人工序列(Arificial Sequence)
抗PD-L1抗体的VL CDR3
QQHSTTPLT
SEQ ID NO: 272
DNA
人工序列(Arificial Sequence)
抗PD-L1抗体的VL CDR3
QQHSDAPLT
- 抗PD-L1/抗4-1BB双特异性抗体及其用途
- 抗PD-L1/4-1BB双特异性抗体及其用途