一种基于深度学习双模型的语音连续事件提取方法
文献发布时间:2023-06-19 13:29:16
技术领域
本发明涉及语音事件提取技术领域,具体而言,涉及一种基于深度学习双模型的语音连续事件提取方法。
背景技术
语音事件提取的自动化虽然很早就被人们关注,深度学习中的自然语音处理技术也被应用其中,但在实际复杂情况下,提取效果并不理想:因信号间的干扰、噪声、信号太弱等因素,语音事件提取的漏检率较高,同时因人在对话中会有停顿等特征,语音事件提取往往并不完整。
发明内容
本发明旨在提供一种基于深度学习双模型的语音连续事件提取方法,以解决当前语音事件提取方法在实际复杂情况下提取效果不理想的问题。
本发明提供的一种基于深度学习双模型的语音连续事件提取方法,包括如下步骤:
步骤S10,对用于训练的语音信号文件进行相应的预处理分别得到VOC格式数据集和三元组数据集;
步骤S20,采用VOC格式数据集训练YOLOV3深度学习模型,得到训练好的YOLOV3深度学习模型;
步骤S30,采用三元组数据集训练构建的深度学习人声分类网络模型,得到训练好的深度学习人声分类网络模型;
步骤S40,对待预测语音信号文件进行预处理得到包含若干待预测语图样本文件的待预测数据集;
步骤S50,将待预测数据集输入训练好的YOLOV3深度学习模型进行语音事件位置预测,得到语音事件的位置信息;
步骤S60,使用步骤S50得到的语音事件的位置信息从原始的待预测语音信号文件中提取语音事件;
步骤S70,将步骤S60提取的语音事件输入训练好的深度学习人声分类网络模型进行人声预测,每个语音事件得到相应的一组特征向量;
步骤S80,对每个语音事件得到的一组特征向量通过相似性计算判断对应的语音事件是否是相同人声,并将相同人声的语音事件并进行合并后,再根据对应的位置信息从原始的待预测语音信号文件中提取语音事件。
进一步的,步骤S10中对用于训练的语音信号文件进行相应的预处理分别得到VOC格式数据集和三元组数据集的方法包括:
步骤S11,对用于训练的语音信号文件进行短时傅里叶变换并进行图像映射得到训练信号语图样本;
步骤S12,对训练信号语图样本进行切分处理得到若干训练语图样本文件;
步骤S13,对若干训练语图样本文件进行语音事件的框选标记,制作成VOC格式数据集;
步骤S14,对训练信号语图样本进行语音事件的框选,将框选出的语音事件切分出来作为语音事件样本,并将具有相同人声的语音事件样本放在一起制作成三元组数据集。
进一步的,步骤S30中采用三元组数据集训练构建的深度学习人声分类网络模型的方法包括:
步骤S31,将三元组数据集输入构建的深度学习人声分类网络模型:每次同时输入三个语音事件样本,其中两个语音事件样本为相同人声的语音事件样本,另一个语音事件样本为与前两个语音事件样本不同人声的语音事件样本;
步骤S32,对每次输入的三个语音事件样本使用四种尺度的卷积核进行特征提取并标准化,得到第一特征矩阵;
步骤S33,对第一特征矩阵进行叠加并池化,再对池化结果使用256个卷积核进行特征提取,得到第二特征矩阵;
步骤S34,对第二特征矩阵使用四种尺度的卷积核进行特征提取并标准化,得到第三特征矩阵;
步骤S35,对第三特征矩阵进行叠加并池化,再对池化结果使用512个卷积核进行特征提取,得到第四特征矩阵;
步骤S36,对第四特征矩阵使用四种尺度的卷积核进行特征提取并标准化,得到第五特征矩阵;
步骤S37,对第五特征矩阵进行叠加并池化,再对池化结果使用512个卷积核进行特征提取,得到第六特征矩阵;
步骤S38,对第六特征矩阵进行平坦化并全连接到长度为1的特征向量上,并进行非线性处理;
步骤S39,对步骤S31~步骤S38的处理过程采用损失函数进行训练,待损失值收敛后停止训练,得到训练好的深度学习人声分类网络模型。
进一步的,步骤S40中对待预测语音信号文件进行预处理的方法包括:
步骤S41,对待预测语音信号文件进行短时傅里叶变换并进行图像映射得到待预测信号语图样本;
步骤S42,对待预测信号语图样本进行切分处理得到若干待预测语图样本文件;
步骤S43,将若干待预测语图样本文件作为待预测数据集。
进一步的,步骤S70中将步骤S60提取的语音事件输入训练好的深度学习人声分类网络模型进行人声预测的处理过程包括:
步骤S71,将步骤S60提取的语音事件输入构建的深度学习人声分类网络模型;
步骤S72,对输入的语音事件使用四种尺度的卷积核进行特征提取并标准化,得到第七特征矩阵;
步骤S77,对第七特征矩阵进行叠加并池化,再对池化结果使用257个卷积核进行特征提取,得到第八特征矩阵;
步骤S74,对第八特征矩阵使用四种尺度的卷积核进行特征提取并标准化,得到第九特征矩阵;
步骤S75,对第九特征矩阵进行叠加并池化,再对池化结果使用512个卷积核进行特征提取,得到第十特征矩阵;
步骤S77,对第十特征矩阵使用四种尺度的卷积核进行特征提取并标准化,得到第十一特征矩阵;
步骤S77,对第十一特征矩阵进行叠加并池化,再对池化结果使用512个卷积核进行特征提取,得到第十二特征矩阵;
步骤S78,对第十二特征矩阵进行平坦化并全连接到长度为1的特征向量上,并进行非线性处理,得到每个语音事件的一组特征向量。
进一步的,步骤S80包括如下子步骤:
步骤S81,对每个语音事件得到的一组特征向量中的相邻特征向量进行欧式距离计算,当计算得到的欧式距离小于设定距离阈值则认为该相邻特征向量对应的语音事件是相同人声;
步骤S82,对相同人声的语音事件判断其时间长度是否小于设定时间长度,若不小于设定时间长度则进行合并;
步骤S83,对合并后的语音事件对应的位置信息从原始的待预测语音信号文件中提取语音事件。
进一步的,每个训练语图样本文件的长度相等。
进一步的,每个待预测语图样本文件的长度相等。
进一步的,每个训练语图样本文件和待预测语图样本文件的长度均相等。
进一步的,若有训练语图样本文件和/或待预测语图样本文件的长度不足则进行补0处理。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1、相比传统图像特征匹配方式提取语音事件,本发明通过深度学习双模型的方式提取语音事件,模拟了人去识别语音事件的过程,抗噪声能力强,灵敏度高,即使在语音信号较弱的情况下效果依然显著。
2、本发明使用所构建的深度学习人声分类网络模型对语音事件进行特征提取,通过特征比对来判断是否为相同人声(同一个人的声音),相邻两个语音事件若为相同人声则认为是同一语音事件,这样就能够完整的提取出一个语音事件。
3、在通用的深度学习分类网络训练中,所要进行识别的类别需要参加训练,未参与训练的类别是不能够被预测的,而对人声进行分类,往往在真实环境下要预测的声音是之前未参与训练的,所以通用的深度学习分类方法不能够对人声进行直接分类。本发明使用所构建的深度学习人声分类网络模型,相同人声的语音事件的特征向量的欧氏距离较小,不同人声的语音事件的特征向量的欧式距离较大,即使未参与训练的语音事件也能进行声音的特征提取,从而判断是否为相同人声。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
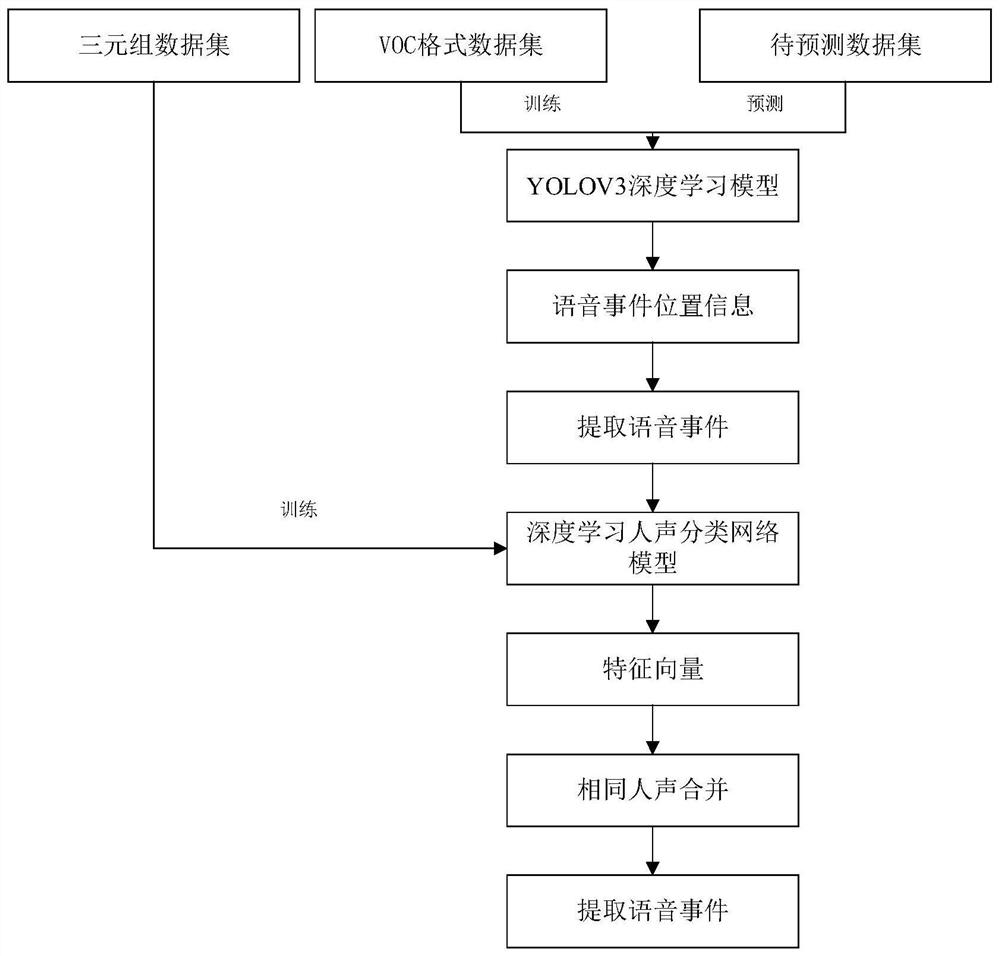
图1为本发明实施例的基于深度学习双模型的语音连续事件提取方法的总体流程图。
图2为本发明实施例的深度学习人声分类网络模型的结构图。
图3为本发明实施例的对待预测语音信号文件进行语音事件提取的流程图。
图4为本发明实施例的判断是否为相同人声的流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
如图1所示,本实施例提出一种基于深度学习双模型的语音连续事件提取方法,包括如下步骤:
步骤S10,对用于训练的语音信号文件进行相应的预处理分别得到VOC格式数据集和三元组数据集;具体包括如下步骤:
步骤S11,对用于训练的语音信号文件进行短时傅里叶变换并进行图像映射得到训练信号语图样本;
步骤S12,对训练信号语图样本进行切分处理得到若干训练语图样本文件;本实施例中,每个训练语图样本文件的长度均为W,W为正整数,本实施例取W=512;进一步,对于长度不足W的训练语图样本文件进行补0处理直至长度为W=512;
步骤S13,对若干训练语图样本文件进行语音事件的框选标记,制作成VOC格式数据集;
步骤S14,对训练信号语图样本进行语音事件的框选,将框选出的语音事件切分出来作为语音事件样本,并将具有相同人声的语音事件样本放在一起制作成三元组数据集。
步骤S20,采用VOC格式数据集训练YOLOV3深度学习模型,得到训练好的YOLOV3深度学习模型;所述YOLOV3深度学习模型为现有技术,其结构以及训练过程在此不再赘述。
步骤S30,采用三元组数据集训练构建的深度学习人声分类网络模型,得到训练好的深度学习人声分类网络模型;所述深度学习人声分类网络模型的结构如图2所示,步骤S30具体包括如下步骤:
步骤S31,将三元组数据集输入构建的深度学习人声分类网络模型:每次同时输入三个语音事件样本,其中两个语音事件样本为相同人声的语音事件样本,另一个语音事件样本为与前两个语音事件样本不同人声的语音事件样本;其中,每个语音事件样本输入尺寸为256×512×3,表示长度为512、高度为256的三通语音事件样本;
步骤S32,对每次输入的三个语音事件样本使用四种尺度的卷积核(如图2中的Block 1×1,64;Block 3×3,64;Block 5×5,64;Block 7×7,64)进行特征提取并标准化,得到第一特征矩阵;
步骤S33,对第一特征矩阵进行叠加并池化,再对池化结果使用256个卷积核进行特征提取,得到第二特征矩阵;
步骤S34,对第二特征矩阵使用四种尺度的卷积核(如图2中的Block 1×1,256;Block 3×3,256;Block 5×5,256;Block 7×7,256)进行特征提取并标准化,得到第三特征矩阵;
步骤S35,对第三特征矩阵进行叠加并池化,再对池化结果使用512个卷积核进行特征提取,得到第四特征矩阵;
步骤S36,对第四特征矩阵使用四种尺度的卷积核(如图2中的Block 1×1,512;Block 3×3,512;Block 5×5,512;Block 7×7,512)进行特征提取并标准化,得到第五特征矩阵;
步骤S37,对第五特征矩阵进行叠加并池化,再对池化结果使用512个卷积核进行特征提取,得到第六特征矩阵;
步骤S38,对第六特征矩阵进行平坦化并全连接到长度为1的特征向量上,并进行非线性处理;
步骤S39,对步骤S31~步骤S38的处理过程采用损失函数进行训练,待损失值收敛(损失值小于预设阈值即为收敛,预设阈值一般可取0.02)后停止训练,得到训练好的深度学习人声分类网络模型。其中,损失函数可以选用常用的损失函数,如MAE损失函数。
步骤S40,对待预测语音信号文件进行预处理得到包含若干待预测语图样本文件的待预测数据集;对待预测语音信号文件进行预处理的方法与步骤S10中类似,具体包括如下步骤:
步骤S41,对待预测语音信号文件进行短时傅里叶变换并进行图像映射得到待预测信号语图样本;
步骤S42,对待预测信号语图样本进行切分处理得到若干待预测语图样本文件;同样地,每个待预测语图样本文件的长度均也为W,W为正整数,W=512;进一步,对于长度不足W的待预测语图样本文件进行补0处理直至长度为W=512;
步骤S43,将若干待预测语图样本文件作为待预测数据集。
步骤S50,将待预测数据集输入训练好的YOLOV3深度学习模型进行语音事件位置预测,得到语音事件的位置信息;YOLOV3深度学习模型为现有技术,因此应用该YOLOV3深度学习模型进行语音事件位置预测的过程在此不再赘述。
步骤S60,如图3所示,使用步骤S50得到的语音事件的位置信息从原始的待预测语音信号文件中提取语音事件;
步骤S70,将步骤S60提取的语音事件输入训练好的深度学习人声分类网络模型进行人声预测,每个语音事件得到相应的一组特征向量;具体包括如下步骤:
步骤S71,将步骤S60提取的语音事件输入构建的深度学习人声分类网络模型;输入的语音事件尺寸为256×512×3,表示长度为512、高度为256的三通语音事件;
步骤S72,对输入的语音事件使用四种尺度的卷积核(如图2中的Block 1×1,64;Block 3×3,64;Block 5×5,64;Block 7×7,64)进行特征提取并标准化,得到第七特征矩阵;
步骤S77,对第七特征矩阵进行叠加并池化,再对池化结果使用257个卷积核进行特征提取,得到第八特征矩阵;
步骤S74,对第八特征矩阵使用四种尺度的卷积核(如图2中的Block 1×1,256;Block 3×3,256;Block 5×5,256;Block 7×7,256)进行特征提取并标准化,得到第九特征矩阵;
步骤S75,对第九特征矩阵进行叠加并池化,再对池化结果使用512个卷积核进行特征提取,得到第十特征矩阵;
步骤S77,对第十特征矩阵使用四种尺度的卷积核(如图2中的Block 1×1,512;Block 3×3,512;Block 5×5,512;Block 7×7,512)进行特征提取并标准化,得到第十一特征矩阵;
步骤S77,对第十一特征矩阵进行叠加并池化,再对池化结果使用512个卷积核进行特征提取,得到第十二特征矩阵;
步骤S78,对第十二特征矩阵进行平坦化并全连接到长度为1的特征向量上,并进行非线性处理,得到每个语音事件的一组512维的特征向量。
步骤S80,对每个语音事件得到的一组特征向量通过相似性计算判断对应的语音事件是否是相同人声,并将相同人声的语音事件并进行合并后,再根据对应的位置信息从原始的待预测语音信号文件中提取语音事件;如图4所示,具体包括如下步骤:
步骤S81,对每个语音事件得到的一组特征向量中的相邻特征向量进行欧式距离计算,当计算得到的欧式距离小于设定距离阈值则认为该相邻特征向量对应的语音事件是相同人声;
步骤S82,对相同人声的语音事件判断其时间长度是否小于设定时间长度,若不小于设定时间长度(如10秒)则进行合并;
步骤S83,对合并后的语音事件对应的位置信息从原始的待预测语音信号文件中提取语音事件。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。