一种文档类型0DAY漏洞检测方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及网络安全技术领域,特别涉及软件漏洞检测分析中,一种文档类型0DAY漏洞检测方法。
背景技术
随着信息化、数字化办公的不断发展,文档类型的软件功能越来越强大,文档格式也越来越复杂,在方便工作的同时,安全性上也受到越来越多的挑战。由于电子文档使用频繁,针对文档类型的漏洞利用一直是黑客攻击的热点。特别是随着企业文档资产的价值越来越大,针对企业文档等数字资产进行窃取、勒索等恶意攻击行为的破坏性也越来越受到重视。
在漏洞检测方面,传统的技术方法主要围绕已知漏洞,提取漏洞特征、漏洞利用特征,开展漏洞检测和发现研究。在0DAY漏洞(未公开漏洞)的研究方面,也出现了模糊测试(FUZZING)、基于污点分析、基于行为启发等检测技术,但由于文档格式的特殊性,漏洞的触发与文档结构密切相关,这些技术方法在0DAY漏洞的检测发现方面效率不高。
发明内容
本发明提出了一种文档类型0DAY漏洞检测方法,针对不同方式收到到的文档样本,首先断其文档格式,针对具体的文档格式,按照其官方公布的复合文档格式规范解析其数据结构及数据内容,判断是否为恶意文档。对于恶意文档,结合其中提取到的ShellCode数据内容,进一步检测判断是否为0DAY漏洞。该方法针对具体的文档格式开展深度检测与分析,弥补了现有的文档0DAY漏洞的检测效率不足的问题。
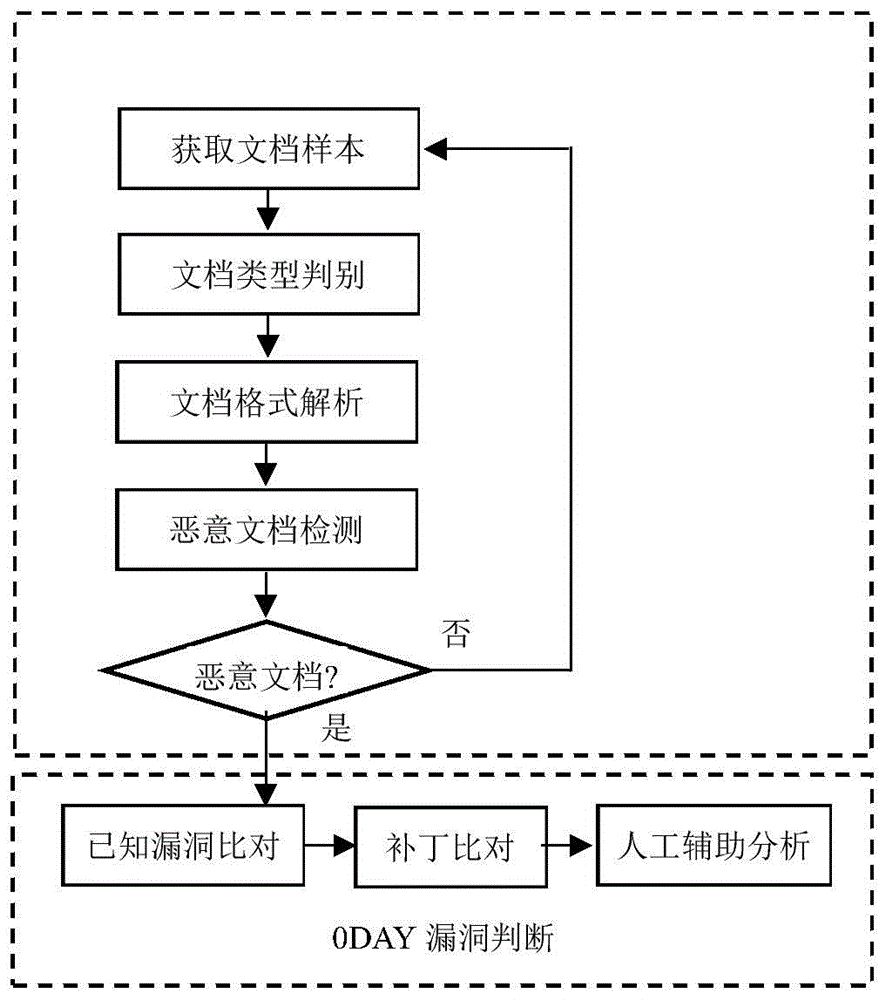
该方法基于对样本是否为恶意文档的检测、所用漏洞是否为0DAY漏洞的判断两个阶段的分析,实现文档类型的0DAY漏洞的检测和发现。由样本文档采集模块、文档类型判别模块、文档格式解析模块、恶意文档检测模块、已知漏洞比对模块、补丁比对测试模块、以及人工辅助分析模块模块等部分组成。具体包括如下步骤:
步骤1、从网络流量、终端设备、或者其他系统输出中采集文档样本:
通过部署在目标网络中的软、硬件采集组件,采集网络中传输的流量数据,从中分离出各种类型的文档附件;或者从终端设备中、从其他系统输出结果中采集文档样本。
步骤2、对文档样本的类型进行判别:
通过文档的文件头格式,辅以文件名后缀,对常用文档格式进行初步判别,确定目标样本的文档格式。
步骤3、对文档格式进行解析:
根据步骤2中识别出目标样本的文档格式,调用对应的文档格式解析引擎进行处理,对于无法识别出格式类型的文档,交由人工辅助分析处理。
步骤4、通过静态分析和动态测试进行恶意文档检测:
1、在步骤3解析出对应格式的敏感区域提取相应数据,对数据内容进行静态分析判断是否存在ShellCode恶意代码。
2、动态调用系统默认的目标样本文档对应的处理程序,监测文档打开时是否存在恶意操作。
步骤5、对判断为恶意文档的样本进行已知漏洞检测:
1)、基于已知漏洞特征库,静态比对恶意文档的特征,比对成功则判断为该种漏洞。
2)、基于多种杀软的组合,对目标恶意文档进行查杀,以确定恶意文档的漏洞类型。
步骤6、对于检测为恶意文档的样本进行补丁比较分析:
在安装有不同补丁的模拟环境下,对目标恶意文档进行打开测试,如果在具体补丁环境下没能触发恶意行为,则判断该补丁与样本文档的漏洞相对应。
步骤7、对于上述步骤仍无法判断的恶意文档进行人工分析判断:
对步骤5、6中无法判定漏洞信息的恶意文档,具体进行人工分析,以确认是否为未公开漏洞(0DAY漏洞)。
所述步骤1从网络流量、终端设备、或者其他系统输出采集文档样本:
(1)、通过部署在目标网络中的软件组件/系统、或者硬件设备进行采集,并从这些采集到的网络传输流量数据中,分离出各种类型的样本文档附件;
(2)、从目标网络中的终端设备中采集获取文档样本;
(3)、从其他系统的处理结果中,批量导入样本文档,如从恶意样本搜集蜜罐中捕获文档,或者其他文档检测系统中判定为可疑的结果文档。
所述步骤2对文档样本的类型进行判别,通过文档的文件头及文件名后缀,对常用的Microsoft Office、WPS Office、Adobe Reader、ZIP、各类图像文档格式进行初步判别,方便后续调用不同的文档格式解析引擎进行处理。
所述步骤3对文档格式进行解析,根据已识别出的文档格式,调用对应的文档格式解析引擎进行处理,根据官方文档格式规范提取出其中的格式内容。对于无法识别出格式类型的文档,交由人工辅助分析处理。
所述步骤4中异常操作包括除文档打开处理之外的创建进程、访问网络、写注册表。
对于检测为恶意文档的,需要进一步判断是否为0DAY漏洞,检测为非恶意文档的,无需进一步检测。
所述步骤5对于检测为恶意文档的样本,进行已知漏洞检测:
1)、基于已知漏洞特征库的静态比对,对检测出的样本的恶意特征,到自建已知漏洞库中进行特征比对,如果特征比对成功,则判断为已知漏洞。
2)、基于杀软组合的查杀检测,搭建多种杀毒软件环境,对检测出的恶意文档进行查杀检测,通过杀软组合对样本的查杀判断恶意文档的漏洞类型。
所述步骤6对于检测为恶意文档的样本进行补丁比较分析:
对于无法判断为已知漏洞的恶意文档,在安装有不同补丁的模拟环境下,对目标恶意文档进行打开测试,观察待检测文档的恶意行为触发状况,如果没能触发恶意行为,则判断该补丁与样本文档的漏洞相对应,由此获得样本对应的漏洞信息。
所述步骤7对于上述步骤仍无法判断的恶意文档进行人工分析判断,对于无法进行格式解析的文档,以及无法判定漏洞信息的恶意文档,进行人工分析,最终确认其是否为未公开漏洞。
该方法针对具体的文档格式开展检测与分析,通过恶意文档检测、0DAY漏洞的判断两个阶段的检测分析处理,实现文档类型的0DAY漏洞的检测发现,检测时充分考虑了具体文档格式结构、以及敏感结构中的数据内容,使得检测更有针对性、更高效,弥补了现有的文档0DAY漏洞的检测效率不足的问题。
附图说明
图1为本发明文档类型0DAY漏洞检测方法流程图;
图2为本发明文档类型0DAY漏洞检测方法组成结构图;
图3为本发明实例PDF文档格式结构图;
图4为本发明恶意文档执行流程图。
具体实施方式
下面根据附图举例对本发明做进一步解释:
如图1所示,一种文档类型0DAY漏洞检测方法,通过判断样本是否为恶意文档、所用漏洞是否为0DAY漏洞的分析,实现文档类型的0DAY漏洞的检测发现。如图2所示,包括样本文档采集模块、文档类型判别模块、文档格式解析模块、恶意文档检测模块、已知漏洞比对模块、补丁比对测试模块、以及人工辅助分析模块。
步骤1、从网络流量、终端设备、或者其他系统输出采集文档样本:
(1)通过部署在目标网络中的软件组件/系统、或者硬件设备进行采集,并从这些采集到的网络传输流量数据中,分离出各种类型的样本文档附件;
(2)从目标网络中的终端设备中采集获取文档样本;
(3)从其他系统的处理结果中,批量导入样本文档,如从恶意样本搜集蜜罐中捕获文档,或者其他文档检测系统中判定为可疑的结果文档。
步骤2、对文档样本的类型进行判别
通过文档的文件头及文件名后缀,对常用的Microsoft Office、WPS Office、Adobe Reader、ZIP、各类图像等主流文档格式进行初步判别,方便后续调用不同的文档格式解析引擎进行处理。如Word97-2003文档的文件头为“D0 CF 11E0”,Adobe Acrobat(pdf)文档的文件头为“25 50 44 46 2D 31 2E”,ZIP文档的文件头为“50 4B 03 04”,JPEG(jpg)文档的文件头为“FF D8 FF”等,可以根据样本文档的文件头判断文档的格式类型。
步骤3、对文档格式进行解析:
根据已识别出的文档格式,调用对应的文档格式解析引擎进行处理,根据官方公布的文档格式规范提取出其中的格式数据及对应的内容数据。对于无法识别出格式类型的文档,交由人工辅助分析处理。内置了Microsoft Office、WPS Office、Adobe Reader、ZIP、各类图像等主流文档格式解析引擎,对文档进行格式解析处理。
以PDF格式为例,如图3所示,PDF文档生整体上分为文件头(Header)、对象集合(Body)、交叉引用表(Xref table)、文件尾(Trailer)四个部分。经编辑修改过的PDF结构会有部分变化,每次修改内容都追加到文档的后面。
文件头(Header)是PDF文件的第一行,格式为%PDF-1.7;
对象集合(Body)是PDF文件最重要的部分,文件中用到的所有对象,包括文本、图象、音乐、视频、字体、超连接、加密信息、文档结构信息等等,都在这里定义。格式为:
2 0obj
...
end obj
一个对象的定义包含4个部分:前面的2是对象序号,用来唯一标记一个对象;0是生成号,按照PDF规范,如果一个PDF文件被修改,那这个数字是累加的,它和对象序号一起标记是原始对象还是修改后的对象,但是实际开发中,很少有用这种方式修改PDF的,都是重新编排对象号;obj和endobj是对象的定义范围,可以抽象的理解为这就是一个左括号和右括号;省略号部分是PDF规定的任意合法对象。
交叉引用表(Xref table)是PDf文件内部一种特殊的文件组织方式,可以很方便的根据对象号随机访问一个对象。以xref作为开始标志,后面为一个交叉引用表的内容,每个交叉引用表又可以分为若干个子段。
文件尾(Trailer)可以快速的找到交叉引用表的位置,进而可以精确定位每一个对象;还可以通过它本身的字典还可以获取文件的一些全局信息(作者,关键字,标题等),加密信息等。
在对PDF文档解析过程中,需要通过敏感区域的内容来判断是否为恶意文档。如不包含关键字段xref或trailer的PDF文档,一般不是恶意文档。而包含JS、Javascript,AA、OpenAction、Acroform或者URI关键字段的PDF文档,则需要进一步检测是否存在风险。
步骤4、通过静态分析和动态监测进行恶意文档检测:
(1)利用对文档格式解析的结果,在对应格式的敏感区域提取相应数据,进行静态分析,判断文档中是否存在ShellCode恶意代码。以PDF文档为例,需要静态分析JS、Javascript,AA、OpenAction、Acroform或者URI关键字段的内容,来判断文档中是否存在ShellCode恶意代码。
根据文档中的ShellCode恶意代码,与已知漏洞库中的恶意代码检测比对,如果比对结果为新的恶意代码(即未能成功匹配),即可判断为未公开漏洞(0DAY漏洞)。这种方方法直接提取复合文件格式中易被恶意利用的敏感区域,针对利用代码进行判断比较,是目前已经效率最高的未知漏洞检测方法。
(2)通过调用对应的文档处理程序,监测文档在打开处理时的行为,是否存在除文档打开处理之外的创建进程、访问网络、写注册表等异常操作。恶意文档执行流程如图4所示,在打开恶意文档时触发漏洞,通过调用嵌入在文档中的ShellCode代码,执行恶意行为,其中创建新的恶意进程是最常用的方法,需要监测文档打开时启动的软件进程信息、以及关联启动的进程信息。通常对文档打开时,启动和关联启动的进程是固定的,可以用白名单方式进行判断,如出现启动白名单之外的进程,可判断为恶意文档。
对于检测为恶意文档的,需要进一步判断是否为未公开漏洞(0DAY漏洞),检测为非恶意文档的,无需进一步检测。
步骤5、对于检测为恶意文档的样本,进行已知漏洞检测:
(1)基于已知漏洞特征库的静态比对,对检测出的样本的恶意特征,到自建已知漏洞库中进行特征比对,如果特征比对成功,则判断为已知漏洞。
在判断为恶意文档的基础上,进行特征比对,如果未能匹配上现有特征,则表明用逐个排除的方式判断为未知漏洞,特征比对是高效的漏洞检测方法。
(2)基于杀软组合的查杀检测,搭建多种杀毒软件环境,对检测出的恶意文档进行查杀检测,通过杀软组合对样本的查杀判断恶意文档的漏洞类型。通过搭建360、BitDefender、火绒、小红伞或Kaspersky等不同的杀毒软件,对目标文档进行查杀,可以快速检测出的恶意文档所使用的漏洞信息。
利用杀软进行协助查杀检测,可以充分利用各厂商的最新研究成果,特别是对1DAY或者NDAY恶意文档样本的发现效率非常高。在0DAY检测方面,如果通过现有查杀方法无法检出,也提供了一种0DAY检测的高效判断方法。
步骤6、对于检测为恶意文档的样本进行补丁比较分析:
对于无法判断为已知漏洞的恶意文档,在安装有不同补丁的模拟环境下,对目标恶意文档进行打开测试,观察待检测文档的恶意行为触发状况,如果没能触发恶意行为,则判断该补丁与样本文档的漏洞相对应,由此获得样本对应的漏洞信息。
如果在安装完最新的补丁,恶意文档的行为依然能触发,则表明该恶意样本能突破软件厂商现有的安全机制,即可可判断为0DAY漏洞,也是一种比较高效的检测判断方法。
步骤7、对于上述步骤仍无法判断的恶意文档进行人工分析判断:
对于无法进行格式解析的文档,以及无法判定漏洞信息的恶意文档,进行人工分析,最终确认其是否为0DAY漏洞。漏洞判定部分主要是采用类似专家系统的思想对恶意文档的漏洞信息进行上述自动化分析,由于输入文档是己经确认的恶意文档,通过与已知的漏洞信息进行对比分析,对未能检测出漏洞信息的恶意样本可以判定为使用了0DAY漏洞。同时考虑到自动检测可能造成的误报以及使用了漏洞的样本数量较少,因此对于漏洞的信息的最终确认可以采用人工分析进行辅助。
漏洞挖掘与利用,是网络对抗中攻防双方都非常关注的核心技术。围绕未知漏洞的挖掘,出现了很多研究成果,如针对代码和二进制程序的静态分析和动态测试,根据对被测目标掌握的资源情况又分为白盒测试、灰盒测试和黑盒测试等不同方法,还有基于模型检测、基于行为传播的分析等方法。与漏洞挖掘相比,漏洞检测与响应,在效率方面有着更强的要求。传统的漏洞检测中也使用一些与漏洞挖掘类似的方法,但检测效率非常低下。本申请在参考漏洞检测领域现有研究技术的基础上,探索未知漏洞的快速发现方法,通过多种渠道收集、诱捕文档样本,利用代码比对、特征比对、杀软辅助查杀判断、补丁比对等多种技术方法,实现对未知漏洞的快速检测,将有效提升漏洞的发现和响应效率,减轻因漏洞利用对企业信息系统造成的破坏和影响。