拆迁全流程制式文档数据提取与结构化方法
文献发布时间:2024-01-17 01:17:49
技术领域
本发明涉及技术领域,更具体地说,涉及拆迁全流程制式文档数据提取与结构化方法。
背景技术
在拆迁规划过程中,会产生大量制式文档,以及这些文档中包含的大量信息。这些制式文档涉及的内容广泛,包括政策文件、规划方案、拆迁协议、补偿方案等,其中包含了大量的重要信息,如拆迁地点、面积、补偿金额、拆迁进度等。这些信息对于政府、拆迁公司和居民等各方都非常重要,在现有技术中,一般都是通过工作人员手动提取和整理文档信息,然而,由于文档数量庞大、文档格式不统一、文档内容复杂等原因,手动提取和整理这些信息十分耗时、耗力,从而提高工作人员的劳动强度,且手动提取和整理这些信息,可能会使得工作人员由于工作强度过大导致出现错误,从而降低了工作人员的劳动强度。
基于此,本发明设计了拆迁全流程制式文档数据提取与结构化方法,以解决上述问题。
发明内容
1.要解决的技术问题
本发明的目的在于提供拆迁全流程制式文档数据提取与结构化方法,以解决上述背景技术中提出的问题:
在现有技术中,一般都是通过工作人员手动提取和整理文档信息,然而,由于文档数量庞大、文档格式不统一、文档内容复杂等原因,手动提取和整理这些信息十分耗时、耗力,从而提高工作人员的劳动强度,且手动提取和整理这些信息,可能会使得工作人员由于工作强度过大导致出现错误,从而降低了工作人员的劳动强度。
2.技术方案
拆迁全流程制式文档数据提取与结构化方法,包括:
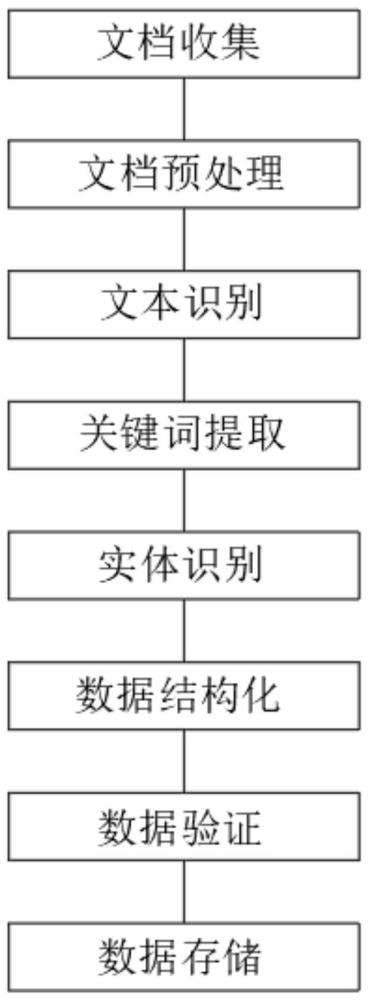
S1,文档收集:收集所有相关的拆迁制式文档;
S2,文档预处理:对于收集到的文档进行预处理;
S3,文本识别:使用OCR技术对文档进行识别,将文档中的文字内容提取出来,且如果文档中存在手写字体,可以使用手写体识别技术进行处理;
S4,关键词提取:使用关键词提取技术对文档中涉及的地点、涉及的拆迁项目、拆迁政策的关键词进行提取;
S5,实体识别:使用实体识别技术对文档中的人名、地名、组织机构名进行识别;
S6,数据结构化:将提取出来的关键词和实体按照一定的结构进行组织,形成结构化的数据;
S7,数据验证:对结构化的数据进行验证;
S8,数据存储:将结构化的数据存储到数据库中。
优选地,所述S2包括以下步骤:
S2-1,文档格式转换:将S1收集到的相关文档转换成统一的格式;
S2-2,去重:对于多份相同的文档,只保留其中的一份,减少重复的处理和存储;
S2-3,去噪:去除文档中的无关内容;
S2-4,文本切割:将文档中的文本按照一定的规则进行切割;
S2-5,格式规范化:对文档中的格式进行规范化;
S2-6,字符集转换:将文档中的字符集转换成一种统一的字符集;
S2-7,文档压缩:将所有文档进行压缩处理。
优选地,所述S2-2包括以下步骤:
S2-21,文本清洗:对文本数据进行清洗,去除无用信息;
S2-22,文本标准化:对文本进行标准化处理,以保证文本数据的一致性和可比性;
S2-23,特征提取:对文本数据进行特征提取,将文本转换成向量形式,以便于后续进行比较和计算;
S2-24,相似度计算:使用相似度算法,比较文本数据之间的相似度;
S2-25,去重处理:根据相似度计算的结果,确定哪些文本数据是相似的,哪些是重复的,进行去重处理。
优选地,所述S4包括以下步骤:
S4-1,分词:将文本按照一定规则切分成词语或短语;
S4-2,去除停用词:将分词后的文本中一些常用、无实际意义的词语过滤掉;
S4-3,词性标注:对分词后的词语进行词性标注;
S4-4,提取:从词性标注后的文本中抽取出关键词;
S4-5,关键词过滤和排序:根据实际需求,对提取出来的关键词进行过滤和排序,以得到更加准确、有用的关键词列表。
优选地,所述S4-4包括以下步骤:
S4-41,计算词频:对分词后的文本中的每个词语进行计数,得到每个词语在文本中出现的次数;
S4-42,计算TF值:对于每个词语,计算它在文本中的词频除以文本中所有词语的总数,得到该词语的TF值;
S4-43,计算逆文档频率IDF值:对于每个词语,计算它在文本集中出现的文档数,然后用总文档数除以该值,再取对数,得到该词语的IDF值;
S4-44,计算TF-IDF值:将每个词语的TF值与它的IDF值相乘,得到该词语的TF-IDF值;
S4-45,选取关键词:从计算出来的TF-IDF值中,选取值较高的词语作为关键词,可以根据实际需求设定一个阈值,只选取TF-IDF值大于等于该阈值的词语作为关键词。
优选地,所述S6包括以下步骤:
S6-1,数据清洗:清除数据中的噪声和错误数据;
S6-2,数据整合:将多个来源的数据进行整合,合并成一个数据集,便于后续的处理;
S6-3,数据变换:对数据进行变换,使数据更符合分析和建模的要求;
S6-4,特征选择:选择对建模有用的特征,去除对建模无用或冗余的特征;
S6-5,特征提取:从原始数据中提取对建模有用的特征;
S6-6,数据建模:根据具体问题选择合适的建模方法,并进行训练和验证;
S6-7,结果评估:对建模结果进行评估和分析,判断模型的精度和可靠性;
S6-8,结果展示:将结构化后的数据和建模结果进行可视化和展示,以便于理解和应用。
优选地,所述S7包括以下步骤:
S7-1,数据类型检查:检查数据的类型是否正确;
S7-2,数据范围检查:检查数据是否在预期的范围内;
S7-3,数据唯一性检查:检查数据是否具有唯一性;
S7-4,数据逻辑关系检查:检查数据之间的逻辑关系是否符合预期;
S7-5,数据完整性检查:检查数据是否完整;
S7-6,数据一致性检查:检查数据是否在不同数据源和数据集中保持一致;
S7-7,数据异常值检查:检查是否存在异常值或不合理的数据。
3.有益效果
相比于现有技术,本发明的优点在于:
1)、本发明中,通过对所有的原始文档进行初步处理,从而便于后续的数据提取和分析,同时通过对文档进行去重处理,确定哪些文本数据是相似的,哪些是重复的,从而进行去重处理,能给有效的降低文档在储存时的储存空间。
2)、本发明中,通过对原始文档进行关键词提取,使得工作人员能给快速的从文档中提取到该文档中涉及到的地点、拆迁项目、拆迁政策等信息,从而有利于工作人员在对文档数据进行提取时的工作效率。
3)、本发明中,通过使用拆迁全流程制式文档数据提取与结构化方法,可以快速、准确地提取和整理这些信息,使其变成结构化的数据,方便后续的分析和利用。这不仅可以提高工作效率,也可以减少人工错误的发生,从而更好地保障拆迁工作的公平、公正和透明。
附图说明
图1为本发明的整体流程示意图;
图2为本发明的文档预处理流程示意图;
图3为本发明的关键词提取流程示意图;
图4为本发明的数据结构化流程示意图;
图5为本发明的数据验证流程示意图。
具体实施方式
在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”、“顺时针”、“逆时针”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的设备或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“设置有”、“套设/接”、“连接”等,应做广义理解,例如“连接”,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
实施例:请参阅图1,拆迁全流程制式文档数据提取与结构化方法,包括:
S1,文档收集:收集所有相关的拆迁制式文档,包括政策文件、规划方案、拆迁协议、补偿方案等;
S2,文档预处理:对于收集到的文档进行预处理,包括文档格式转换、去重、去噪等;
S3,文本识别:使用OCR技术对文档进行识别,将文档中的文字内容提取出来,且如果文档中存在手写字体,可以使用手写体识别技术进行处理;
S4,关键词提取:使用关键词提取技术对文档中涉及的地点、涉及的拆迁项目、拆迁政策的关键词进行提取;
S5,实体识别:使用实体识别技术对文档中的人名、地名、组织机构名进行识别;
S6,数据结构化:将提取出来的关键词和实体按照一定的结构进行组织,形成结构化的数据;
S7,数据验证:对结构化的数据进行验证,从而确保数据的正确性和完整性;
S8,数据存储:将结构化的数据存储到数据库中,从而方便后续的查询和分析。
具体的,所述S2包括以下步骤:
S2-1,文档格式转换:将S1收集到的相关文档转换成统一的格式,例如将PDF文件转换成文本格式,从而方便后续的文本处理;
S2-2,去重:对于多份相同的文档,只保留其中的一份,减少重复的处理和存储,有效的减小了文档之间的重复率,从而降低文档的处理速度和储存空间;
S2-3,去噪:去除文档中的无关内容,避免无关内容过多导致影响提取速度;
S2-4,文本切割:将文档中的文本按照一定的规则进行切割,从而方便后续的文本处理和提取;
S2-5,格式规范化:对文档中的格式进行规范化,使得文本更易于阅读和处理;
S2-6,字符集转换:将文档中的字符集转换成一种统一的字符集,方便后续的文本处理和存储;
S2-7,文档压缩:将所有文档进行压缩处理,进一步降低文档的储存空间。
具体的,所述S2-2包括以下步骤:
S2-21,文本清洗:对文本数据进行清洗,去除无用信息;
S2-22,文本标准化:对文本进行标准化处理,以保证文本数据的一致性和可比性;
S2-23,特征提取:对文本数据进行特征提取,将文本转换成向量形式,以便于后续进行比较和计算;
S2-24,相似度计算:使用相似度算法,比较文本数据之间的相似度;
S2-25,去重处理:根据相似度计算的结果,确定哪些文本数据是相似的,哪些是重复的,进行去重处理。
具体的,所述S4包括以下步骤:
S4-1,分词:将文本按照一定规则切分成词语或短语;
S4-2,去除停用词:将分词后的文本中一些常用、无实际意义的词语过滤掉;
S4-3,词性标注:对分词后的词语进行词性标注;
S4-4,提取:从词性标注后的文本中抽取出关键词;
S4-5,关键词过滤和排序:根据实际需求,对提取出来的关键词进行过滤和排序,以得到更加准确、有用的关键词列表。
具体的,所述S4-4包括以下步骤:
S4-41,计算词频:对分词后的文本中的每个词语进行计数,得到每个词语在文本中出现的次数;
S4-42,计算TF值:对于每个词语,计算它在文本中的词频除以文本中所有词语的总数,得到该词语的TF值;
S4-43,计算逆文档频率IDF值:对于每个词语,计算它在文本集中出现的文档数,然后用总文档数除以该值,再取对数,得到该词语的IDF值;
S4-44,计算TF-IDF值:将每个词语的TF值与它的IDF值相乘,得到该词语的TF-IDF值;
S4-45,选取关键词:从计算出来的TF-IDF值中,选取值较高的词语作为关键词,可以根据实际需求设定一个阈值,只选取TF-IDF值大于等于该阈值的词语作为关键词。
具体的,所述S6包括以下步骤:
S6-1,数据清洗:清除数据中的噪声和错误数据;
S6-2,数据整合:将多个来源的数据进行整合,合并成一个数据集,便于后续的处理;
S6-3,数据变换:对数据进行变换,使数据更符合分析和建模的要求;
S6-4,特征选择:选择对建模有用的特征,去除对建模无用或冗余的特征;
S6-5,特征提取:从原始数据中提取对建模有用的特征;
S6-6,数据建模:根据具体问题选择合适的建模方法,并进行训练和验证;
S6-7,结果评估:对建模结果进行评估和分析,判断模型的精度和可靠性;
S6-8,结果展示:将结构化后的数据和建模结果进行可视化和展示,以便于理解和应用。
具体的,所述S7包括以下步骤:
S7-1,数据类型检查:检查数据的类型是否正确;
S7-2,数据范围检查:检查数据是否在预期的范围内;
S7-3,数据唯一性检查:检查数据是否具有唯一性;
S7-4,数据逻辑关系检查:检查数据之间的逻辑关系是否符合预期;
S7-5,数据完整性检查:检查数据是否完整;
S7-6,数据一致性检查:检查数据是否在不同数据源和数据集中保持一致;
S7-7,数据异常值检查:检查是否存在异常值或不合理的数据。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的仅为本发明的优选例,并不用来限制本发明,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。词语第一、第二、以及第三等的使用不表示任何顺序,可将这些词语解释为标识。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。