一种按类特征加权的语音情感识别算法
文献发布时间:2023-06-19 10:06:57
技术领域
本发明涉及语音情感识别领域,尤其设计了一种基于按类特征预加权的多分类识别方法。
背景技术
情感识别任务是情感计算的首要目标之一,其主要目的在于通过计算机根据不同的场合情景,正确分析人类的情感状态,再根据分析的结果用正确的情感回馈给人类,从而实现一个更好的人机交互体验。随着人工智能技术的研究日趋成熟,深度学习算法的研究日益深入,语音情感识别已被广泛应用在人机交互、医学治疗、辅助教学、电话客服、驾驶检测以及公共安全等许多重要领域。然而,随着技术的不断进步,语音情感识别问题仍面临着许多挑战。其中之一便是对于语音特征的处理。语音特征的处理是实现语音情感识别技术的第一步,也是最为关键的一步,一个好的特征处理方法不仅会大大减少语音情感识别算法的成本,还能一定程度上提高最终的识别准确率,可谓是十分的关键。
在早期的时候,研究者对于特征的处理通常都是统一的,没有针对性。比如研究者常常在提取完所需的语音特征后不加后续处理直接送入模型进行训练。然而影响一个人情绪变化的因素是复杂多样的,愤怒或恐惧情感的平均音调(pitch)普遍高于中立或厌恶情感。愤怒、快乐或惊讶等高唤醒情绪产生的能量(energy)偏高,而厌恶和悲伤的能量偏低。同样,对于悲伤情感,响度(loudness)的标准差更高,而对于快乐情感来说,则相反。愤怒持续时间比悲伤持续时间短。这些不同特征间的细微差异,使得情感之间产生了不同。因此,充分利用这种特征间的不同,对于提升语音情感识别的分类能力有着很大的帮助。
传统的处理语音特征的方式主要有三种:第一类是对原始语言信号不做处理,直接使用;第二类是对原始语言信号进行分帧然后逐帧的提取语音特征用于后续的模型输入;第三类则是对逐帧提取得到的语音特征进行统计学上的分析,比如最大值,最小值,方差等,从而提取基于统计学的语音特征。
目前,三类方法都有各自的不足。第一类方法对于语音信号缺乏处理,原始语音信号包含很多无用的噪音信息,对这些信息不做处理会大大影响最终的识别准确率;第二类方法提取了语音特征,但缺乏对于语音特征的分析,从很多隐藏在特征背后的信息没有被发掘出来;第三类方法不仅提取了特征,还做了统计上的分析,但并没有充分利用这种信息来获取特征的内在本质,同样有很大的分析空间。
发明内容
技术问题:本发明提供一种按类特征加权的语音情感识别算法,通过在模型训练之前对特征进行按类的预加权的操作。通过利用统计学分析,特征选择优先度分析来对各个不同情感类中的不同特征进行分析,获得对应各类情感的特定权值,来重构各个特征的表示能力,一方面提升不同情感中区分度比较高的特征的识别能力,另一方面减少不同情感中表示能力比较弱的特征的识别作用,从而提升最终的情感区分能力。
技术方案:首先,我们将原始数据根据每一种情感类别按照一定的比例分为训练集和测试集。其次,提取所需的语音特征并对其用特征选择算法按照特征优先度降序重新排列特征。接着,用统计学的方法分析特征的能力,并计算出对应不同情感类别的独特权重输入模型进行训练。最后,在测试阶段,对测试集的样本分别赋予各个权重值,分别测试获得的概率通过投票法得到最终的识别结果,获得模型的性能。
本发明所采用的技术方案可以进一步完善。所述训练方法使用的特征选择算法可以使用各种改进的方法,只要修正的方法保证是基于权值的方法即可。进一步,该模型在划分数据集时使用的是按照特定比例划分的方法,可以先通过样本采样的方法优化数据集划分,提高训练的效率。最后,统计学的分析使用也能有很多的改进。例如卡方分析、t检验等。
有益效果:本发明与现有的技术相比,具有以下优点:
与传统的对语音特征进行同等处理的语音情感识别方法不同,本方法通过计算不同语音特征在不同情绪下的显著性来挖掘语音特征的潜在性,并充分利用这种潜在性来增强特征与情绪之间的差异。
附图说明
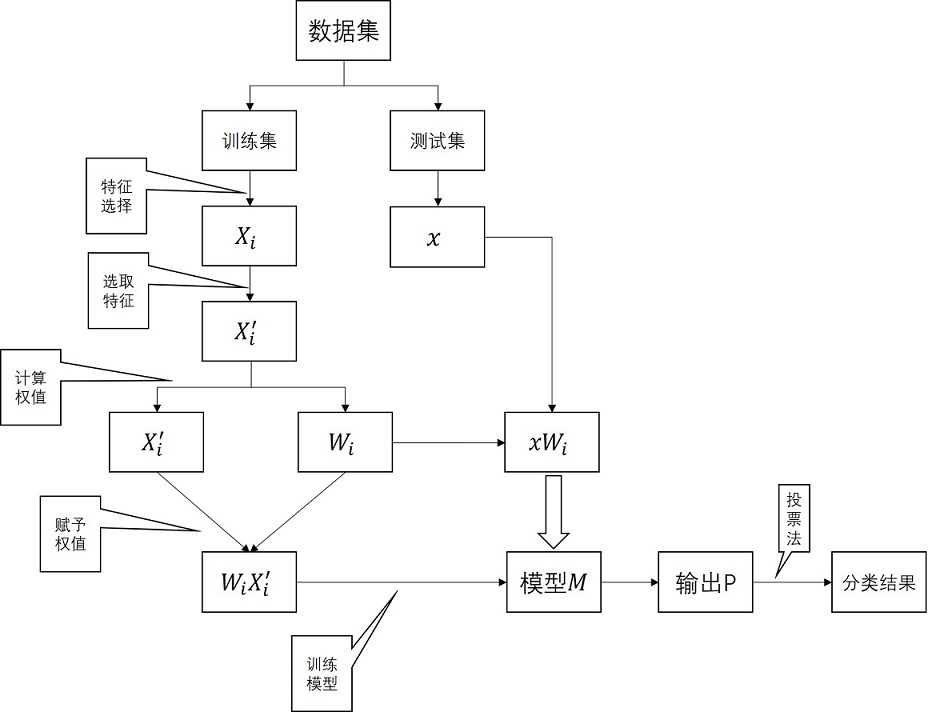
图1是本发明应用在语音情感识别领域的整体框架;
图2是本发明方法示意图;
具体实施方式
为了更清楚的描述本发明的内容,下面结合实例进一步说明。本方法名称为一种按类特征加权的语音情感识别算法(ECFW)包括以下步骤:
步骤1:划分多类语音情感数据集
步骤2:使用特征选择算法从x
步骤3:计算每个情感类别对应的权重w
计算对应的类方差v
计算对应的特征选择得分Rank
其中d表示特征的维度数量,集合所得类内和类间均值,类方差以及特征选择得分,计算每个类对应的权重w
因此,通过上述方法,可以得到每个情绪对应的权重。也就是说,对于第i类情感,对应的权重为W
经过特征选择算法之后,得到所选择的特征X’
测试阶段将S中的每一个测试样本x分别乘以各个权重值构造出c个新的语段样本{x′W
选取
实验设计
实验数据集选取:本文使用了三个目前比较常用的语音情感数据库分别为德文语音情感数据集(Berlin Database of Emotional Speech,EMO-DB)、英文语音情感数据集(Interactive Emotional Dyadic Motion Capture,IEMOCAP)以及中文语音情感数据集(Mandarin Affective Speech Corpus,MASC)。选取的数据集所用的情感样本具体数量列在下表中。
网络训练方法:在本章中选用说话人独立的训练策略,在三个数据集中选用留一组法(Leave One Group Out,LOGO)的训练策略,总共执行五轮,每一轮用其中四个会话中的句子作为训练集,剩下一个会话作为测试集。提取的特征集为Interspeech'10,特征选择算法分别测试了ReliefF,MRMR以及Laplas法。使用的网络模型为两层的全连接神经网络构成的深度模型,分别有1024个节点。BatchNorm层和Dropout层也用于每个层之后,其中Dropout层的保留可能性P=0.5。
验证指标:选择加权平均召回率(Weighted Accuracy,WA)和未加权平均召回率(Unweighted Accuracy,UA)作为模型的评价指标。WA指的是在整个测试集上分类正确的数量。UA指的是每种类别分类正确率的平均结果。WA注重的是整体的分类结果,而UA注重的是各个类的分类结果。
对比算法:发明选用的算法ECFW,以及进行对比的算法为不应用ECFW方法原始方法Baseline。
实验结果
本算法在IEMOCAP、EMO-DB和MASC三个数据集上的结果列在下表。
由表中的数据可知,ECFW算法在三个不同的Baseline下,得到了2%到5%之间得到了改进。在IEMOCAP、EMO-DB和MASC中获得的最佳准确率WA分别为60.97%、75.60%和69.95%。可以由此得出结论,ECFW算法能够更改的学习特征表示能力,从而提高分类准确率。
- 一种按类特征加权的语音情感识别算法
- 一种基于特征加权和改进贝叶斯算法的摔倒检测方法