一种利用神经网络实现决策树分类的方法
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及机器学习领域,尤其涉及利用神经网络实现决策树分类的方法。
背景技术
神经网络在软件算法和开发中发挥着越来越重要的作用,应用行业也从互联网产业应用拓展至工业生产中,包括汽车软件(如高级驾驶辅助系统(ADAS)和自动驾驶系统(ADS))、质量检测(如基于图像的缺陷检测包括印刷电路板、光伏板等)等。此外,诸如神经网络等机器学习技术也已经开始被应用于高可靠性控制系统中。
相较于神经网络技术的广泛应用,目前对神经网络等机器学习技术的理解仍有许多挑战。与传统编程从规范出发不同,机器学习通过对数据样本的学习来完成建模。以汽车软件开发为例,高级功能(例如ADS等)需要对环境进行感知,并应用机器学习算法。这些高级功能无法规范化准确地描述,需要和数据样本一起完成功能建模。神经网络模型的应用为这些高级功能提供了实现的方法,但是在软件实现和高度的过程中,其准确性会遇到两个关键障碍:缺少规范和不可解释性。
由于类似感知和检测判断等复杂的功能很难明确规范,我们需要使用基于机器学习的方法来实现软件组件,通过从样本进行训练而不是从规范出发通过程序化编程来实现软件组件。包括神经网络在内的所有类型的机器学习模型都包含编码形式的知识,而这些编码通常不具备很好的可解释性。
机器学习模型的广泛应用通常以牺牲可解释性为代价以实现软件的功能。不可解释性使得手动白盒验证方法无法使用,如走查和检验,造成对功能安全保证的障碍。机器学习算法模型的可解释性与其他安全活动,如正式验证或静态分析密切相关。为此,我们需要加强对模型的了解,以更好的解释机器学习的结果,并提高神经网络实现的准确性和可调试性。
发明内容
本发明的目的是:加强对机器学习模型的了解,以更好的解释机器学习的结果,并提高神经网络实现的准确性和可调试性。
为了达到上述目的,本发明的技术方案是提供了一种利用神经网络实现决策树分类的方法,其特征在于,基于训练数据和分类标签,建立决策树神经网络的结构,模拟决策树分类模型的分类过程,并在此基础上进行进一步的训练;将决策树的信息转化为决策树神经网络所需要的全部信息,包括条件矩阵、权重矩阵、树结构矩阵和分类决定,其中,建立决策树神经网络包括以下步骤:
步骤1、建立决策树模型,记录决策树的结点数和相应的决策依据;
步骤2、建立条件矩阵,条件矩阵的每一行与决策树的非叶结点一一对应并记录下相应非叶结点的线性条件:
对应于一个含有2n+1个结点的决策树,条件矩阵为一个n*(m+1)的矩阵,其中,n为决策树的非叶结点数,决策树的n个非叶结点均依据一个线性条件对数据进行分类,m为被分类数据的特征维数;
步骤3、建立权重矩阵:
权重矩阵由两个l*n的矩阵表示,两个l*n的矩阵分别代表了每个非叶结点的左侧和右侧子结点的权重信息,其中n为决策树的非叶结点数,l为分类数据的类别数;
步骤4、建立树结构矩阵:
对应于一个含有2n+1个结点的决策树,树结构矩阵为一个(n+1)*n的矩阵,其中,n个列向量对应于决策树的n个非叶结点,n+1个行向量对应于决策树的n+1个叶结点;树结构矩阵的数值可取值为0、1或-1;
对于每个列向量,树结构矩阵的数值表示了该列向量对应的非叶结点与所有叶结点之间的关系:数值1表示相应叶结点在该非叶结点的右侧;数值-1表示相应叶结点在该非叶结点的左侧;数值0表示相应叶结点不是该非叶结点的后代;
对于每个行向量,树结构矩阵的数值表示了从根结点到该行向量对应的叶结点的路径,数值1表示在相应结点向右,数值-1表示在相应结点向左,数值0表示从要结点到叶结点的路径不经过相应结点;
步骤5、构造决策树神经网络:
决策树神经网络是一个两层的神经网络:第一层神经网络的参数为条件矩阵,第二层神经网络的参数为一个三维矩阵,由权重矩阵和树结构矩阵构造;决策树神经网络的激活函数选择符号函数sign或sigmoid函数:若激活函数选取为符号函数sign,则决策树神经网络的分类结果与决策树的结果完全一致;若激活函数选取为sigmoid函数,则决策树神经网络的分类结果与决策树基本一致,其分类边缘较决策树更为平滑,并可以在已有的模型参数基础上进行进一步的训练。
优选地,步骤1中,一个决策树含有2n+1个结点,其中n个非叶结点对应于决策条件,n+1个叶结点对应于分类决策。
优选地,步骤2中,n*(m+1)的矩阵中(m+1)维的行向量为m维输入数据的系数和截距项。
优选地,步骤3中,权重矩阵可以进一步表示为子结点类别矩阵和权重级别的乘积。
优选地,子结点类别矩阵由两个l*n的0-1矩阵表示,其中n为决策树的非叶结点树,l分类数据的类别树,两个l*n的0-1矩阵分别代表了每个非叶结点的左侧和右侧子结点的类别信息,分别定义为左侧子结点类别矩阵及右侧子结点类别矩阵,其中:
l*n的左侧子结点类别矩阵的n个列向量对应于决策树的n个非叶结点,列向量的维数对应于数据的分类,以0-1布尔值的方式表示左侧结点是否包含相应分类的数据;
l*n的右侧子结点类别矩阵的n个列向量对应于决策树的n个非叶结点,列向量的维数对应于数据的分类,以0-1布尔值的方式表示右侧结点是否包含相应分类的数据。
优选地,以n维数组表示相应非叶结点的权重,作为子结点类别矩阵的补充,一起表示权重矩阵;非叶结点的权重为2
优选地,获得子结点类别矩阵和权重级别以后,将子结点类别矩阵的每一列乘以相应的权重级别以后即可得权重矩阵。
优选地,步骤5中,所述第二层神经网络的三维矩阵为一个(n+1)*l*n的三维矩阵,将树结构矩阵中数值为1的参数替换为右侧子结点矩阵的相应类别向量,将树结构矩阵中数值为-1的参数替换为左侧子结点矩阵的相应类别向量的反向量,将树结构矩阵中数值为0的参数替换为零向量。
优选地,选取激活函数sign或sigmoid,并在函数输出的结果上减去1/2以规范化输出,即激活函数表达为f(x)–1/2,其中f为sign或sigmoid。
优选地,应用条件矩阵、第二层神经网络的三维矩阵和激活函数,输入m维的数据向量,和m*n维的条件矩阵相乘得到隐藏层输出的n维向量,并应用激活函数f(x)-1/2,将输出结果和第二层神经网络(n+1)*l*n维的三维矩阵相乘得到(n+1)*l的输出,输出结果分为数据类别和叶结点两个维数,输出结果中数值最大的值所对应的数据类别即为分类决策的结果。
神经网络在软件算法和开发中发挥着越来越重要的作用,应用行业也从互联网产业应用拓展至工业生产中。此外,诸如神经网络等机器学习技术也已经开始被应用于高可靠性控制系统中。相较于神经网络技术的广泛应用,目前对神经网络等机器学习技术的理解仍有许多挑战。本发明提出了一种用神经网络实现决策树分类的方法,基于训练数据和分类标签,建立分类神经网络的结构,模拟决策树分类模型的分类过程,并在此基础上进行进一步的训练,以更好的解释机器学习的结果,并提高神经网络实现的准确性和可调试性。
附图说明
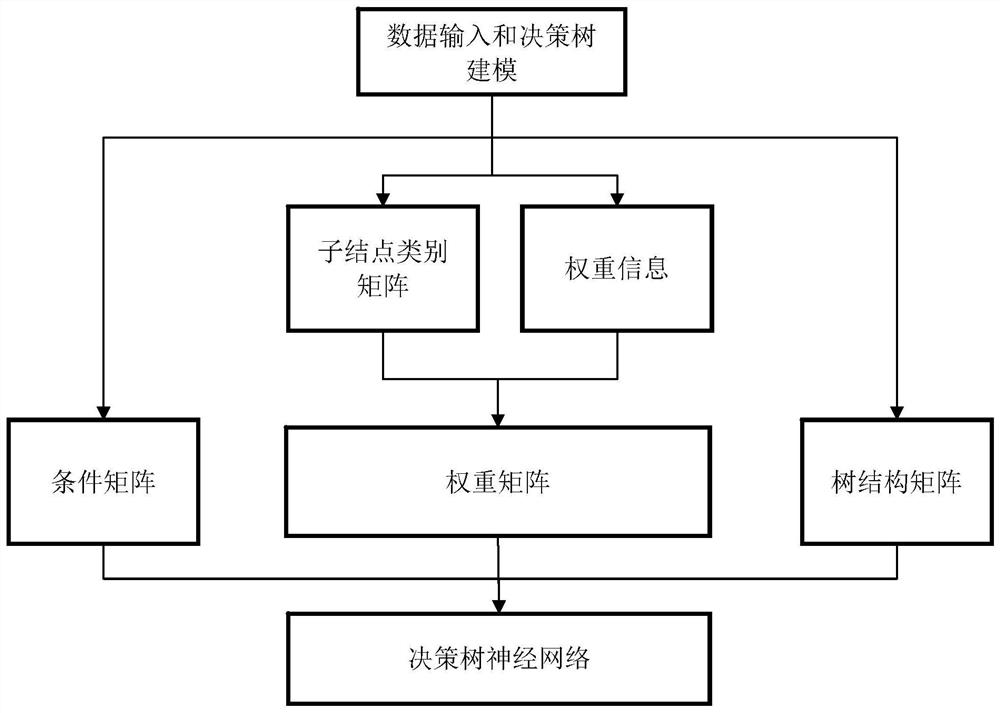
图1为决策树神经网络建立流程图;
图2为实施例中建立的决策树模型;
图3为实施例中各个分类器在鸢尾花数据上的分类结果。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
鉴于神经网络算法和开发中所遇到的问题,本发明提出一种用神经网络实现决策树分类的方法,基于训练数据和分类标签,建立分类神经网络的结构,模拟决策树分类模型的分类过程,并在此基础上进行进一步的训练。将这些决策树的信息转化为决策树神经网络所需要的全部信息有:条件矩阵、权重矩阵、树结构矩阵和分类决定。为了建立决策树神经网络模型,需要以下步骤:
步骤一:建立传统的决策树模型,记录决策树的结点树和相应的决策依据。通常,一个决策树含有2n+1个结点,其中n个非叶结点对应于决策条件,n+1个叶结点对应于分类决策。
以鸢尾花数据集为例,我们建立如图2所示的决策树模型。图2所示的决策树一共有17个结点,包括8个非叶结点和9个叶结点。
步骤二:建立条件矩阵对应于一个含有2n+1个结点的决策树,条件矩阵为一个n*(m+1)的矩阵,其中n为决策树的非叶结点树,m为被分类数据的特征维数。决策树的n个非叶结点均依据一个线性条件对数据进行分类,条件矩阵的每一行与决策树的非叶结点一一对应,并记录下相应非叶结点的线性条件,(m+1)维的行向量为m维输入数据的系数和截距项。
对应前述决策树,我们获得如下8*5的条件矩阵:
dt=np.array([[0,0,0,1,-0.8],
[0,0,0,1,-1.75],
[0,0,1,0,-4.95],
[0,0,0,1,-1.65],
[0,0,0,1,-1.55],
[1,0,0,0,-6.95],
[0,0,1,0,-4.85],
[0,1,0,0,-3.1]],dtype=
上述条件矩阵的每一行对应于一个非叶结点的线性分类条件,最后一列为截距项。
步骤三:建立权重矩阵。权重矩阵由两个I*n的矩阵表示,其中n为决策树的非叶结点树,I分类数据的类别树,两个矩阵分别代表了每个非叶结点的左侧和右侧子结点的权重信息。权重矩阵可以进一步表示为子结点类别矩阵和权重级别的乘积。其中:
子结点类别矩阵由两个I*n的0-1矩阵表示,其中n为决策树的非叶结点树,I为分类数据的类别数,两个矩阵分别代表了每个非叶结点的左侧和右侧子结点的类别信息。以左侧子结点类别矩阵为例,I*n的矩阵的n个列向量对应于决策树的n个非叶结点,列向量的维数对应于数据的分类,以0-1布尔值的方式表示左侧结点是否包含相应分类的数据;
对应上例的子结点矩阵为:
_weight_l=np.array([[1,0,0,0,0,0,0,0],
[0,1,1,1,0,1,1,0],
[0,1,1,0,1,0,1,1]])
_weight_r=np.array([[0,00,0,0,0,0,0],
[1,1,1,0,1,0,0,1]
[1,1,1,1,1,1,1,0]])
权重级别以n维数组表示相应非叶结点的权重,作为子结点类别矩阵的补充,一起表示权重矩阵。非叶结点的权重为2-
对应上例的权重信息为[1,1/2,1/4,1/8,1/8,1/16,1/4,1/8]。
获得子结点类别矩阵和权重级别以后,将子结点类别矩阵的每一列乘以相应的权重级别以后即可得权重矩阵。
步骤四:建立树结构矩阵。对应于一个含有2n+1个结点的决策树,树结构矩阵为一个(n+1)*n的矩阵,其中n个列向量对应于决策树的n个非叶结点,n+1个行向量对就于决策树的n+1个叶结点。树结构矩阵的数值可取值为0、1或-1。对于每个列向量,树结构矩阵的数值表示了该列向量对应的非叶结点与所有叶结点之间的关系:数值1表示相应叶结点在该非叶结点的右侧;数值-1表示相应叶结点在该非叶结点的左侧;数值0表示相应叶结点不是该非叶结点的后代。每个行向量表示了从根结点到该行向量对应的叶结点的路径,数值1表示在相应结点向右,数值-1表示在相应结点向左,数值0表示从要结点到叶结点的路径不经过相应结点。
对应上例的树结构矩阵如下:
tree=np.array([[-1,0,0,0,0,0,
[1,-1,-1,-1,0,0,0,0],
[1,-1,-1,1,0,0,0,0],
[1,-1,1,0,-1,0,0,0],
[1,-1,1,0,1,-1,0,0],
[1,-1,1,0,1,1,0,0],
[1,1,0,0,0,0,-1,-1],
[1,1,0,0,0,0,-1,1],
[1,1,0,0,0,0,1,0]])
步骤五:构造决策树神经网络。决策树神经网络是一个两层的神经网络:第一层神经网络的参数为条件矩阵,第二层神经网络的参数为一个三维矩阵,由权重矩阵和树结构矩阵构造。参数矩阵为一个(n+1)*I*n的三维矩阵,将树结构矩阵中数值为1的参数替换为右侧子结点矩阵的相应类别向量,将树结构矩阵中数值为-1的参数替换为左侧子结点矩阵的相应类别向量的反向量,将树结构矩阵中数值为0的参数替换为零向量。神经网络的激活函数可以选择符号函数sign或sigmoid函数。可以选取激活函数sign或sigmoid,并在函数输出的结果上减去1/2以规范化输出,即激活函数可表达为f(x)–1/2,其中f为sign或sigmoid。应用条件矩阵、第二层神经网络参数矩阵和激活函数,输入m维的数据向量,和条件矩阵(m*n维)相乘得到隐藏层输出的n维向量,并应用激活函数f(x)-1/2,将输出结果和第二层神经网络参数矩阵((n+1)*l*n维)相乘得到(n+1)*l的输出。输出结果分为数据类别和叶结点两个维数,输出结果中数值最大的值所对应的数据类别即为分类决策的结果。若激活函数选取为sign函数,则决策树神经网络的分类结果与决策树的结果完全一致;若激活函数选取为sigmoid函数,则决策树神经网络的分类结果与决策树基本一致,其分类边缘较决策树更为平滑,并可以在已有的模型参数基础上进行进一步的训练。
各个分类器在鸢尾花数据上的分类结果如图3所示。为了将数据在二维进行可视化,我们选取了特征一和特征三两个维度的特征进行训练和展示。其中第一列为决策树,第二列为相对应的决策树神经网络,第三列和第四列为决策树神经网络训练后的分类边界,分别对应于sigmoid和sign激活函数。图中其他使用的分类器有Logistic Regression、KNN、Kernel SVM和Soft Voting。第一行的决策树是完全训练的,即每个叶结点只包含一种类别的数据;第二行所用的决策树深度限制为4。
- 一种利用神经网络实现决策树分类的方法
- 一种利用级联卷积神经网络实现人脸检测的方法