数据管理方法、系统、设备和存储介质
文献发布时间:2023-06-19 12:24:27
技术领域
本申请涉及数据库管理领域,涉及但不限于一种数据管理方法、系统、设备和存储介质。
背景技术
相关技术中,主节点和备节点之间采用异步模式或半同步模式进行复制。在主节点和备节点之间采用异步模式进行复制的情况下,无法保证主节点和备节点之间数据的一致性;在主节点和备节点之间采用半同步模式进行复制的情况下,对主节点性能影响比较大。
发明内容
有鉴于此,本申请实施例提供一种数据管理方法、系统、设备和存储介质。
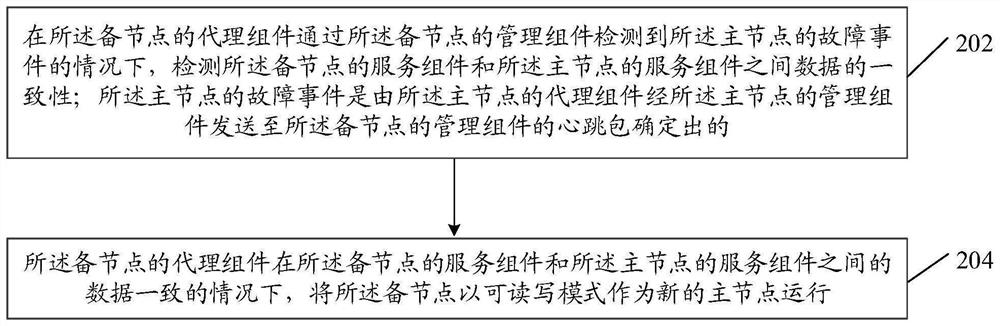
第一方面,本申请实施例提供一种数据管理方法,所述方法包括:在所述备节点的代理组件通过所述备节点的管理组件检测到所述主节点的故障事件的情况下,检测所述备节点的服务组件和所述主节点的服务组件之间数据的一致性;所述主节点的故障事件是由所述主节点的代理组件经所述主节点的管理组件发送至所述备节点的管理组件的心跳包确定出的;所述备节点的代理组件在所述备节点的服务组件和所述主节点的服务组件之间的数据一致的情况下,将所述备节点以可读写模式作为新的主节点运行。
第二方面,本申请实施例提供一种数据管理系统,所述数据管理系统包括主节点的服务组件、代理组件和管理组件,以及备节点的服务组件、代理组件和管理组件,其中:所述备节点的代理组件,用于在通过所述备节点的管理组件检测到所述主节点的故障事件的情况下,检测所述备节点的服务组件和所述主节点的服务组件之间数据的一致性;所述主节点的故障事件是由所述主节点的代理组件经所述主节点的管理组件发送至所述备节点的管理组件的心跳包确定出的;所述备节点的代理组件,还用于在所述备节点的服务组件和所述主节点的服务组件之间的数据一致的情况下,将所述备节点以可读写模式作为新的主节点运行。
第三方面,本申请实施例提供一种电子设备,包括存储器和处理器,所述存储器存储有可在处理器上运行的计算机程序,所述处理器执行所述程序时实现本申请实施例第一方面所述数据管理方法中的步骤。
第四方面,本申请实施例提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现本申请实施例第一方面所述数据管理方法中的步骤。
本申请实施例中,通过在主节点故障,且备节点和主节点之间的数据一致的情况下,将备节点切换为新的主节点以接管业务,并以可读写模式运行,从而能够在主节点故障情况下,由备节点及时对业务进行处理,及时进行自动故障转移,从而不影响业务的进行。
附图说明
图1为本申请实施例一种数据管理系统的示意图;
图2为本申请实施例一种数据管理方法的流程示意图;
图3为本申请实施例一种自动故障转移方法的流程示意图;
图4为本申请实施例另一种数据管理系统的示意图;
图5为本申请实施例一种MySQL主节点的添加结果示意图;
图6为本申请实施例一种MySQL备节点的添加过程示意图;
图7为本申请实施例一种MySQL备节点的添加结果示意图;
图8为本申请实施例一种MySQL空闲节点的添加结果示意图;
图9为本申请实施例一种添加备节点的方法对应的UML时序图;
图10为本申请实施例提供的一种备节点自愈方法的流程示意图;
图11为本申请实施例提供的一种二进制日志数据和中继日志的存储位置的示意图;
图12为本申请实施例一种备节点的IO线程进行中继日志的刷盘操作的方法示意图;
图13为本申请实施例一种监控和动态切换数据复制模式的方法流程示意图;
图14为本申请实施例电子设备的一种硬件实体示意图。
具体实施方式
下面结合附图和实施例对本申请的技术方案进一步详细阐述。
图1为本申请实施例一种数据管理系统的示意图,参见图1,所述数据管理系统又可以简称为系统,可以包括主节点11和备节点12,其中,所述主节点11包括服务组件101、代理组件102和管理组件103;同理,所述备节点12包括服务组件104、代理组件105和管理组件106;其中:
所述数据管理系统可以是MySQL数据库管理系统,对应地,所述主节点11可以是MySQL主节点,所述备节点1002可以是MySQL备节点。
管理组件,又可以称为集群管理组件(Cluster Manager),所有节点的ClusterManager可以组成一个集群,用于提供事件总线和心跳线以及持久化状态。集群可以是指一组松散或紧密连接在一起工作的计算机。由于这些计算机协同工作,在许多方面它们可以被视为单个系统。
服务组件,又可以称为MySQL服务,主节点和备节点的MySQL服务处于运行状态,且使用半同步(semi-sync)模式或异步模式(async)进行主节点和备节点之间的数据复制;所述半同步模式又可以称为半同步复制模式,所述异步模式又可以称为异步复制模式。
代理组件,又可以称为MySQL HA(Highly Available)agent,即MySQL高可用代理,用于处理各种事件,发送心跳包,向其他节点告知自己的存活状态;操作和监控服务组件,例如在主备节点之间网络抖动时切换半同步复制为异步复制、待网络恢复后再次恢复为半同步复制等。高可用可以是指系统经过专门的设计,在中断时能够快速恢复,从而减少停工时间,保持系统的高度可用性。
图2为本申请实施例一种数据管理方法的流程示意图,所述方法可以应用于图1所述的数据管理系统,如图2所示,该方法包括:
步骤202:在所述备节点的代理组件通过所述备节点的管理组件检测到所述主节点的故障事件的情况下,检测所述备节点的服务组件和所述主节点的服务组件之间数据的一致性;所述主节点的故障事件是由所述主节点的代理组件经所述主节点的管理组件发送至所述备节点的管理组件的心跳包确定出的;
其中,参见图1,在所述主节点11正常的情况下,所述主节点11的代理组件102可以通过所述主节点11的管理组件103向所述备节点12的管理组件106发送心跳包,以使所述备节点12的代理组件105感知所述主节点11的心跳;所述代理组件105可根据接收到的所述管理组件103发送的心跳包,确定是否检测到所述主节点11的故障事件。
同理,在所述备节点12正常的情况下,所述备节点12的代理组件105可以通过所述备节点12的管理组件106向所述主节点11的管理组件103发送心跳包,以使所述主节点11的代理组件102感知所述备节点12的心跳。
在一个实施例中,所述检测所述备节点的服务组件和所述主节点的服务组件之间数据的一致性,包括:检测所述备节点的服务组件的中继日志和所述主节点的二进制日志数据之间数据的一致性。
其中,所述中继日志可以是relay log,所述二进制日志数据可以是bin log。主节点上的数据发生改变时,主节点会将数据的改变记录在bin log中;在主节点和备节点之间进行数据复制(即主从复制)时,主节点可以通过异步模式或者半同步模式向备节点发送bin log,备节点将接收到的bin log保存至本地的relay log中;备节点启动SQL线程在本地重放relay log,使得备节点的relay log和主节点的服务组件之间的bin log保持一致。然而,可能由于备节点服务器延迟等原因,无法与主节点的数据同步,即主从同步延迟,从而可能造成备节点的服务组件的中继日志和所述主节点的二进制日志数据之间数据的不一致。
步骤204:所述备节点的代理组件在所述备节点的服务组件和所述主节点的服务组件之间的数据一致的情况下,将所述备节点以可读写模式作为新的主节点运行。
其中,在所述备节点的代理组件通过所述备节点的管理组件检测到所述主节点的故障事件的情况下,所述系统可以自动进行故障转移(Failover),将所述备节点的角色切换为主节点(即作为新的主节点运行)以接管业务,切换后的新的主节点可以正常读写。
本申请实施例中,通过在主节点故障,且备节点和主节点之间的数据一致的情况下,将备节点切换为新的主节点以接管业务,并以可读写模式运行,从而能够在主节点故障情况下,由备节点及时对业务进行处理,及时进行自动故障转移,从而不影响业务的进行。
在一个实施例中,当主节点出现故障后,系统会自动进行Failover,将备节点切换为新的主节点以接管业务;Failover,又可以称为故障转移,即当活动的服务或应用意外终止时,快速启用冗余或备用的服务器、系统、硬件或者网络接替它们工作。同时为了避免数据被错误地写入旧的主节点,系统会尝试将旧的主节点设置为只读模式,并停止旧的主节点的MySQL服务;
在一个实施例中,当备节点出现故障后,系统会自动在空闲节点中选举一个新的备节点;
在一个实施例中,当空闲节点出现故障后,系统只会向管理员发送告警。
图3为本申请实施例一种自动故障转移方法的流程示意图,参见图3,所述方法可以包括以下步骤,以下步骤在备节点的MySQL HA agent中执行:
步骤302:监控所有节点的心跳,节点故障时心跳会停止,然后会触发DELETE事件;
其中,可以通过如下语句实现监控所有节点的心跳:
clusterctl watch--prefix/mysql/ha/heartbeat;
DELETE事件如下语句所示:
DELETE
/mysql/ha/heartbeat/hostname1;
步骤304:获取集群成员信息;
其中,备节点的代理组件可以通过如下语句获取集群成员信息;
clusterctl get/mysql/ha/members;
步骤306:判断故障节点是否为主节点;
若是,则执行步骤308;若否,则执行步骤332;
步骤308:判断主节点和备节点的数据是否一致;若否,则执行步骤310;若是,则执行步骤312。
其中,可通过如下语句查询主节点和备节点之间数据的一致性:
ctusterctl get/mysal/ha/consistent;
步骤310:尝试从故障的主节点拉取和补齐落后的binlog;拉取成功后,主备数据变为一致,失败则不一致;
步骤312:停止IO线程;
其中,可以通过如下语句停止IO线程:
mysql>STOP SLAVE IO_THREAD;
步骤314:等待SQL线程重放完剩余relay log;重复执行对备节点的状态查询,直至备节点的第一参数的状态值为目标状态值;
其中,SQL线程可以是SQL写库线程,所述第一参数可以为Slave_SQL_Running_State,所述目标状态值可以是"Slave has read all relay log;waiting for moreupdates";
可以通过如下语句执行备节点的状态查询:
mysql>SHOW SLAVE STATUS;
步骤316:重置所有复制信息;
其中,可以通过如下语句重置备节点的所有复制信息:
mysql>RESET SLAVE ALL;
步骤318:删除所有binlog文件;
其中,可以通过如下语句删除主节点的binlog文件:
mysql>RESET MASTER;
步骤320:设置全局变量;
其中,可以通过如下语句设置全局变量:
mysgl>SET GLOBAL server_id=1,sync-binlog=1;
innodb-flush-log-at-trx-commit=1;
步骤322:判断主节点和备节点数据是否一致,若否,则执行步骤324;若是,则执行步骤326;
步骤324:向管理员发送告警,此时需要人工介入恢复故障的主节点,而新的主节点会以只读模式运行;
步骤326:备节点恢复为可写模式;
其中,可以通过如下语句将备节点恢复为可写模式:
mysgl>SET GLOBAL read_only=0,super_read_only=0;
步骤328:备节点切换为新的主节点;
步骤330:从空闲节点中选举出新的备节点;
步骤332:结束。
图4为本申请实施例另一种数据管理系统的示意图,参见图4,所述数据管理系统又可以简称为系统,可以包括主节点41、备节点42和空闲节点43,其中,所述主节点41包括服务组件401、代理组件402、管理组件403和Restful API(Application ProgrammingInterface,应用程序接口)404;同理,所述备节点42包括服务组件405、代理组件406、管理组件407和Restful API408;所述空闲节点43包括服务组件409、代理组件410、管理组件411和Restful API412;其中:
所述数据管理系统可以是MySQL数据库管理系统,为了提升宕机容忍度和避免脑裂问题,本数据管理系统(以下简称系统)建议的节点数量至少为3个且为奇数,这些节点的角色分别为:MySQL主节点,有且仅有一个;MySQL备节点,有且仅有一个;MySQL空闲节点,可以有多个。对应地,所述主节点4001可以是MySQL主节点,所述备节点4002可以是MySQL备节点,所述空闲节点4003可以是MySQL空闲节点。主节点和备节点的MySQL处于运行状态;空闲节点的MySQL则处于停止状态。
需要说明的是,所述代理组件同时对外提供Restful API,例如增删节点API等。
从产品侧分析,可以利用SCP平台部署MySQL主节点、MySQL备节点和MySQL空闲节点。
图5为本申请实施例一种MySQL主节点的添加结果示意图,所述MySQL主节点又可以称为单节点;参见图5,所述部署方式可以是集群模式,一般建议部署1或3个节点,可以通过“添加节点”控件501进行主节点的添加,主节点添加成功后,可以在节点IP(InternetProtocol,网际互连协议)502中查看主节点的IP地址:10.134.87.222(主控),并可以继续通过“添加节点”控件501进行备节点和空闲节点的添加。
图6为本申请实施例一种MySQL备节点的添加过程示意图;参见图6,点击如图5所示的“添加节点”控件501,可以弹出节点信息输入界面601,所述节点信息输入界面600中可以填写节点IP601、用户名602和密码603,填写完成后,可以点击“确定”控件604进行节点添加,或者在节点信息输入错误的情况下,点击“取消”控件605,以取消对该节点的添加,所述备节点的IP601可以是10.134.87.223,用户名602可以是admin,新增节点可以自动充当MySQL备节点。
图7为本申请实施例一种MySQL备节点的添加结果示意图;参见图7,所述IP701为添加成功的备节点的IP地址10.134.87.223。
图8为本申请实施例一种MySQL空闲节点的添加结果示意图;参见图8,后续的新增节点全部充当MySQL空闲节点。所述MySQL空闲节点的IP801可以是10.134.887.224。
在添加第一个节点时,因为系统此时没有备节点,所以新增节点会被主节点选举为备节点,图9为本申请实施例一种添加备节点的方法对应的UML(Unified ModelingLanguage,统一建模语言)时序图,所述方法可以包括以下步骤:
步骤901:管理员90调用主节点的MySQL HA agent91对外提供的添加节点API进行备节点的添加:
其中,可以通过如下语句实现备节点的添加:
步骤902:主节点的MySQL HA agent91添加Iptables规则:
其中,可以允许新增节点访问本机的TCP 3306(MySQL)端口、22345(SSH)端口、10086(Cluster Manager)端口。
步骤903:主节点的MySQL HA agent91配置SSH(Secure Shell,安全外壳协议)互信:实现2个节点之间的SSH免密码登录。
步骤904:主节点的MySQL HA agent91向主节点的Cluster Manager92添加Cluster Manager集群成员;
其中,主节点的MySQL HA agent91接收主节点的Cluster Manager92的响应信息;可以通过如下语句添加集群成员:
clusterctl members add
--name hostname2
--host 10.134.87.223
步骤905:主节点的MySQL HA agent91向所述主节点的Cluster Manager92处获取已有的集群成员信息;
其中,主节点的MySQL HA agent91还获取主节点的Cluster Manager92返回的响应信息;可以通过如下语句获取已有的集群成员信息:
步骤906:主节点的MySQL HA agent91选举备节点;
其中,只有新增节点这1个候选节点,所以由其充当备节点;
步骤907:主节点的MySQL HA agent91创建MySQL用户;
其中,可以为新增节点创建MySQL用户用于进行主备复制;
步骤908:主节点的MySQL HA agent91持久化集群成员信息;
其中,可以通过如下语句持久化集群成员信息:
步骤909:新增节点(备节点)的MySQL HA agent93通过新增节点的ClusterManager94监听MySQL集群事件;
其中,新增节点(备节点)的MySQL HA agent93还接收新增节点的ClusterManager94发来的响应消息,可以通过如下语句监听MySQL集群事件:
WATCH/mysql/ha/members PUT/mysql/ha/members
步骤910:新增节点的MySQL HA agent93判断角色变更;
其中,新增节点通过MySQL集群事件发现自己的角色变为slave(备节点),则开始切换角色为备节点。
步骤911:备节点的MySQL HA agent93拷贝MySQL备份:
其中,MySQL备份包括MySQL全量和增量备份,从主节点MySQL中拷贝最新的MySQL全量和增量备份,如果不存在或者比较旧,则使用innobackupex实时生成。
步骤912:备节点的MySQL HA agent93从所述MySQL备份中恢复数据;
其中,可以通过如下语句使用innobackupex从备份恢复数据:
innobackupex--apply-log;
innobackupex--copy-back;
chown-R mysql:mysql/var/lib/my sql;
步骤913:备节点的MySQL HA agent93启动MySQL服务;
其中,可以通过如下语句启动备节点的MySQL服务:
systemctl start mysqldl;
步骤914:备节点的MySQL HA agent93配置备节点的MySQL;
其中,可以通过如下语句配置备节点的MySQL:
RESET MASTER;
RESET SLAVE;
CHANGE MASTER TO;
步骤915:备节点的MySQL HA agent93启动复制;
其中,可以通过如下语句启动备节点的复制:
START SLAVE;
步骤916:备节点的MySQL HA agent93设置备节点的MySQL为只读模式;
其中,可以通过如下语句设置备节点的MySQL为只读模式:
SET GLOBAL read_only=1,super_read_only=1。
本申请实施例还提供一种数据管理方法,所述方法可以应用于如图4所示的数据管理系统,所述方法可以包括以下步骤:
步骤S202:在所述备节点的代理组件通过所述备节点的管理组件检测到所述主节点的故障事件的情况下,检测所述备节点的服务组件和所述主节点的服务组件之间数据的一致性;所述主节点的故障事件是由所述主节点的代理组件经所述主节点的管理组件发送至所述备节点的管理组件的心跳包确定出的;
步骤S204:所述备节点的代理组件在所述备节点的服务组件和所述主节点的服务组件之间的数据一致的情况下,将所述备节点以可读写模式作为新的主节点运行;
步骤S206:所述备节点的代理组件在所述备节点的服务组件和所述主节点的服务组件之间的数据不一致的情况下,将所述备节点以只读模式作为新的主节点运行,并输出第一告警信息,所述第一告警信息用于表征所述主节点的服务组件和所述备节点的服务组件之间的数据不一致;
步骤S208:所述备节点的代理组件在检测到所述备节点的故障事件的情况下,对所述备节点进行恢复;
其中,某些异常场景下例如relay log损坏或丢失,会导致备节点的复制出错并停止。为了应对这些场景,所述系统中的备节点的代理组件可以对备节点的健康状态进行监控,并在备节点的复制出错时,尝试自动恢复备节点,即备节点自愈。
本申请实施例中,通过在主节点故障,且备节点和主节点之间的数据不一致的情况下,将备节点切换为新的主节点以接管业务,并以只读模式运行,输出告警信息,从而能够在主节点故障情况下,由备节点及时对业务进行处理,及时进行自动故障转移,从而不影响业务的进行;另外,通过以只读模式运行备节点,可以保证数据安全,通过输出告警信息,可以使管理员及时获知主节点故障,从而更及时对备节点进行故障处理。
另外,通过在备节点的代理组件检测到备节点故障的情况下,自动尝试对备节点进行恢复,并在备节点难以自动恢复的情况下,将备节点降级为空闲节点,从而可以进行节点自愈,并在遇到硬盘损坏、网络分区等难以自愈的问题时,使管理员及时获知备节点故障,从而更及时对备节点进行故障处理。
在一个实施例中,所述备节点的故障事件可以包括以下几种:所述备节点的服务组件服务未正常运行;所述备节点的业务状态不正常;所述备节点配置的主节点信息不正确;所述备节点的复制IO线程和SQL线程未处于运行状态;所述备节点的服务组件与所述主节点的服务组件之间的数据不够接近(可以理解为数据之间的相似度小于相似度阈值)。
在一个实施例中,可以通过查询备节点接收和已执行的GTID(GlobalTransaction Identity document,全局事务标识符)集合,以及主节点已执行的GTID集合,确定所述备节点的服务组件与所述主节点的服务组件之间的数据是否接近。
在一个实施例中,对所述备节点进行恢复,可以包括:所述备节点的代理组件重启所述备节点的服务组件的服务;所述备节点的代理组件重启所述备节点的复制IO线程和SQL线程。
步骤S210:所述备节点的代理组件在确定所述备节点无法恢复的情况下,将所述备节点作为新的空闲节点运行,并输出第二告警信息。
其中,可以对所述备节点的恢复次数进行计数,在尝试恢复次数达到预设的次数阈值的情况下,确定所述备节点无法恢复,则需要将所述备节点的角色降级为新的空闲节点;所述次数阈值可以是5次、10次等。
图10为本申请实施例提供的一种备节点自愈方法的流程示意图,参见图10,所述方法可以包括以下步骤,以下步骤在备节点的MySQL HA agent中周期性执行,默认配置下5秒执行一次:
步骤1002:备节点的MySQL HA agent检查备节点的MySQL服务是否正常运行;若是,则执行步骤1004;若否,则执行步骤1016;
其中,可以通过如下语句查看备节点的MySQL服务是否正常运行:
systemctl is-active mysqld.service;
步骤1004:检查业务状态是否正常;若是,则执行步骤1006;若否,则执行步骤1016;
其中,可以通过如下语句查看业务状态是否正常;
mysql>SELECT 1;
步骤1006:检查配置的主节点信息是否正确;若是,则执行步骤1008;若否,则执行步骤1020;
其中,可以通过如下语句查看配置的主节点信息是否正确:
mysql>SHOW SLAVE STATUS;Master Host:10.134.87.222
Master Port:3306
步骤1008:检查复制IO和SQL线程是否处于运行状态;若是,则执行步骤1010;若否,则执行步骤1018;
其中,可以通过如下语句查看复制IO和SQL线程是否处于运行状态:
mysql>SHOW SLAVE STATUS;Slave_IO_Running:Yes
Slave SQL_Running:Yes
步骤1010:检查备节点的数据是否接近于主节点的数据;
若是,则执行步骤1012;若否,则执行步骤1020;
其中,可以先查询备节点接收和已执行的GTID集合,再查询主节点已执行的GTID集合,并将两个GTID集合进行比较,以判断备节点的数据是否接近于主节点的数据;
可以通过如下语句查看备节点接收和已执行的GTID集合:
mysql>SHOW SLAVE STATUS;
Retrieved Gtid Set:uuid:15624-21718
Executed Gtid Set:uuid:1-2171
可以通过如下语句查看主节点已执行的GTID集合:
mysql>SHOW MASTER STATUS;
Executed Gtid Set:uuid:1-21718
步骤1012:确定备节点处于健康状态;
步骤1014:删除备节点的不健康标记;
其中,可以通过如下语句删除备节点的不健康标记:
clusterctl del/mysql/ha/slave/unhealthy;
步骤1016:重启MySQL服务;
其中,可以通过如下语句重启备节点的MySQL服务:
systemctl restart mysqld.service;
步骤1018:尝试重启复制;
其中,可以通过如下语句尝试重启复制:
mysql>STOP SLAVE;
mysql>START SLAVE;
步骤1020:确定备节点处于不健康状态;
步骤1022:获取备节点处于不健康状态的起始时间和尝试恢复次数;
其中,假设起始时间表示为start_at,尝试恢复次数表示为recover_cnt,则如下语句可以表征查询到的备节点处于不健康状态的起始时间和尝试恢复次数:
clusterctl get/mysql/ha/slave/unhealthy
["start_at":"2021-05-07 19:18:05","recover_cnt":0}
步骤1024:判断是否难以恢复备节点;
其中,可以在尝试恢复次数达到5次(recover_cnt>=5)的情况下,确定备节点难以恢复。
若是,则执行步骤1026;若否,则执行步骤1028;
步骤1026:从空闲节点随机选取新的备节点,并降级当前备节点为空闲节点;
步骤1028:判断备节点是否长期处于不健康状态;
其中,可设置健康状态判断阈值,例如可以是300秒、600秒等;在备节点处于不健康状态达到300秒的情况下,确定所述备节点长期处于不健康状态。
其中,可将如下语句作为备节点是否长期处于不健康状态的判断条件:
start at&&|now()-start_at|>=300s;
若否,则执行步骤1030;若是,则执行步骤1032;
步骤1030:标记备节点处于不健康状态;
其中,如果备节点已存在不健康状态的标记,就跳过该步骤;
步骤1032:尝试恢复备节点;
其中,可以重新执行添加备节点的后半段流程;
步骤1034:尝试恢复次数加1;
其中,可以通过如下语句查询尝试恢复次数:
clusterctl put/mysq/ha/slave/unhealthy
{"start at":"2021-05-07 19:18:05","recover_cnt":1}
步骤1036:结束。
本申请实施例还提供一种数据管理方法,所述方法可以应用于如图4所示的数据管理系统,所述方法可以包括以下步骤:
步骤S302:在所述备节点的代理组件在预设的宕机时间阈值内,未接收到所述备节点的管理组件发送的所述主节点的心跳包的情况下,确定检测到所述主节点的故障事件;其中,所述宕机时间阈值是根据网络质量和负载确定出的。
其中,所述预设的宕机时间阈值可以是6秒、8秒等;所述心跳包的发送频次是3秒一次、5秒一次等,即心跳的间隔时间为3秒或5秒等。
任一节点基于watch机制实现的心跳线,可高效感知其他节点的故障事件,所述故障事件可以包括宕机情况。默认配置下各节点每3秒发送一次心跳,如果6秒内未发送心跳即视为该节点宕机,备节点可以在20ms(毫秒)内感知到主节点的宕机事件,随即进行自动Failover。可根据实际的网络和负载情况,对心跳的间隔时间(hearbeat_interval)和裁定宕机的宕机时间阈值(downtime_threshold)进行调整,以满足更苛刻的downtime(宕机时间)需求或者避免较差网络环境下系统的频繁抖动。
其中,可通过如下语句进行节点的心跳监测,以感知节点的宕机情况:
#节点上线时执行
clusterctl put/mysql/ha/heartbeat/hostname1'{"metadata":{}}'--ttl 6;
#周期性执行以发送心跳
clusterctl keep-alive/mysql/ha/heartbeat/hostname1;
步骤S304:在所述备节点的代理组件通过所述备节点的管理组件检测到所述主节点的故障事件的情况下,检测所述备节点的服务组件和所述主节点的服务组件之间数据的一致性;所述主节点的故障事件是由所述主节点的代理组件经所述主节点的管理组件发送至所述备节点的管理组件的心跳包确定出的;
步骤S306:所述备节点的代理组件在所述备节点的服务组件和所述主节点的服务组件之间的数据一致的情况下,将所述备节点以可读写模式作为新的主节点运行;
步骤S308:所述备节点的代理组件在所述备节点的服务组件和所述主节点的服务组件之间的数据不一致的情况下,将所述备节点以只读模式作为新的主节点运行,并输出第一告警信息,所述第一告警信息用于表征所述主节点的服务组件和所述备节点的服务组件之间的数据不一致;
步骤S310:所述备节点的代理组件在检测到所述备节点的故障事件的情况下,对所述备节点进行恢复;
步骤S312:所述备节点的代理组件在确定所述备节点无法恢复的情况下,将所述备节点作为新的空闲节点运行,并输出第二告警信息。
步骤S314:在所述备节点的代理组件通过所述备节点的管理组件检测到所述主节点的故障事件,或者所述备节点的代理组件在检测到所述备节点的故障事件的情况下,新的主节点的代理组件将所述空闲节点中的目标空闲节点选举为新的备节点;
其中,所述新的主节点可以是当前切换为主节点角色的节点。
步骤S316:所述目标空闲节点的代理组件检测所述目标空闲节点的管理组件发送的选举事件;所述选举事件是由所述新的主节点的代理组件经所述新的主节点的管理组件发送至所述目标空闲节点的管理组件的;
步骤S318:在检测到所述选举事件的情况下,将所述目标空闲节点作为新的备节点运行。
本申请实施例中,通过在备节点故障或者备节点被选为新的主节点的情况下,从空闲节点中选举备节点,从而进一步可以自动进行故障转移,空闲节点可以切换为新的备节点的角色以接管业务。通过在预设的宕机时间阈值内是否接收到心跳包,来判断节点是否故障,从而可以更高效地感知节点故障;另外,根据网络质量和负载确定宕机时间阈值,从而可以更准确地确定节点是否故障。
本申请实施例还提供一种数据管理方法,所述方法应用于数据管理系统,所述数据管理系统包括主节点的服务组件、代理组件和管理组件,备节点的服务组件、代理组件和管理组件,所述方法可以包括以下步骤:
步骤S402:在所述备节点的代理组件通过所述备节点的管理组件检测到所述主节点的故障事件的情况下,检测所述备节点的服务组件和所述主节点的服务组件之间数据的一致性;所述主节点的故障事件是由所述主节点的代理组件经所述主节点的管理组件发送至所述备节点的管理组件的心跳包确定出的;
步骤S404:所述备节点的代理组件在所述备节点的服务组件和所述主节点的服务组件之间的数据一致的情况下,将所述备节点以可读写模式作为新的主节点运行。
步骤S406:所述主节点的代理组件在检测到所述备节点的故障事件的情况下,将所述主节点的服务组件和所述备节点的服务组件之间的数据复制模式由半同步模式切换为异步模式;
步骤S408:所述主节点的代理组件在检测到所述备节点恢复正常的情况下,将所述主节点的服务组件和所述备节点的服务组件之间的数据复制模式由所述异步模式切换为所述半同步模式。
其中,半同步复制模式可以保证主节点和备节点之间数据的一致性,但是在主节点和备节点之间的网络或者备节点的硬盘出现问题时,会影响到整个系统的写请求,严重时甚至无法写入;而异步模式在任何情况下都不会影响系统的写入,但是却难以保证主备数据的一致性。相关技术中,在启用半同步复制模式时,MySQL在备节点数量不足或者等待备节点的半同步ACK超时的情况下,会自行切换至异步模式;待备节点数量满足要求或者备节点接收的binlog文件追赶上主节点时,又会自行恢复至半同步模式。这些切换过程对外是不可见的,因此主节点故障时,难以准确判断主节点和备节点之间数据是否一致。
为了解决相关技术中存在的以上问题,本系统通过以下2个配置项“禁用”掉了MySQL复制模式的自行切换;改由MySQL HA agent监控主备之间的复制状态,然后动态切换这两种复制模式,在不影响业务和保证数据一致性这二者之间寻求平衡。
动态切换这两种复制模式的部分语句可以如下所示:
通过如下语句设置等待备节点半同步ACK的超时时间为30天或者更长:
#/etc/my.cnf
[mysqld]
rpl-semi-sync-master-timeout=2592000000;
通过如下语句设置在没有备节点的情况下也等待半同步ACK直至超时:
rpl-semi-sync-master-wait-no-slave=on;
由自动故障转移方法的流程示意图可知,在备节点切换成新的主节点之前,需要执行一系列步骤,但是只有“等待SQL线程重放完剩余relay log”这一步的耗时可能十分严重,它取决于SQL线程重放relay log的效率,所以是影响切换速度的瓶颈所在。本系统基于组提交(group commit)的并行复制,对备节点重放relay log的效率进行优化;并结合数据库监控,动态调优以下步骤S410和步骤S412中的配置项,最大化SQL线程的并行度,最终能大幅缩小主备之间的数据延迟。
步骤S410:所述主节点的SQL线程根据事务的繁忙程度,动态设置所述二进制日志数据提交刷盘的延迟时间和延迟等待的最大事务数;
其中,所述二进制日志数据提交刷盘的延迟时间和延迟等待的最大事务数用于控制主节点打包的事务数;binlog提交刷盘的延迟时间可以通过如下语句进行设置:
binlog-group-commit-sync-delay=1000000微秒
中止当前延迟等待的最大事物数可以通过如下语句进行设置:
binlog-group-commit-sync-no-delay-count=5
步骤S412:所述备节点的SQL线程根据事务的冲突程度和分布的数据库,动态切换所述备节点的并行复制的策略;所述策略包括:根据不同数据库之间的事务进行并行复制,以及根据同一个组提交中的事务进行并行复制。
步骤S414:所述备节点的SQL线程根据硬件配置,设置所述备节点的并行复制的线程数。
所述并行复制的策略和所述并行复制的线程数可以用于控制备节点的并行复制;可以用DATABASE表示根据不同数据库之间的事务进行并行复制,可以用LOGICAL_CLOCK表示同一个组提交中的事务进行并行复制;根据“局部性原理”,本系统会监控最近一段时间内发生的事务,通过事务的冲突程度和分布的数据库,动态在这2种策略间进行切换;可以通过如下语句实现策略之间的切换:
slave-parallel-type=DATABASE|LOGICAL_CLOCK
在一定范围内,线程数越大并行度越高,过多的线程会增加线程间同步的开销;本系统会根据硬件配置自动设置较优值为4,可以通过如下语句对所述备节点的并行复制的线程数进行设置:
slave-parallel-workers=4
步骤S416:所述主节点的IO线程将所述二进制日志数据存储在临时文件系统tmpfs上。
一方面,可以通过减少主节点IO(Input/Output)的方式优化吞吐量;备节点已经对二进制日志数据(binlog)进行了持久化,那么主节点事实上没有太大必要持久化binlog了。
图11为本申请实施例提供的一种二进制日志数据和中继日志的存储位置的示意图,参见图11,可以使用SSD(Solid State Disk,固态硬盘)或者HDD1101(Hard DiskDrive,硬盘驱动器)的数据目录(/var/lib/mysql/)存储数据。内存条件允许的情况下,可以将主节点的binlog存储在RAM1102中的tmpfs(临时文件系统)上,binlog存储在binlog目录(/var/run/mysgld/binlog/)下,这样几乎可以完全去除持久化binlog带来的IO开销;虽然重启主节点会导致binlog丢失,导致备节点的复制出错,但是借助备节点自愈机制能很快恢复备节点。
在一个实施例中,MySQL提供一个sync_binlog参数来控制数据库的bin log刷到磁盘上去,在内存条件不允许的情况下,可以设置sync_binlog=0,表示MySQL不控制binlog的刷新,由文件系统自己控制它的缓存的刷新。这样也能大幅减少持久化binlog的IO。
步骤S418:所述备节点的IO线程将所述中继日志的刷盘时机调整至事务级别。
另一方面,可以通过减少备节点IO的方式优化吞吐量;半同步复制模式下,主节点在应答客户端提交的事务前需要保证至少有一个备节点接收并写到中继日志(relay log)中,所以备节点的IO性能是影响系统吞吐量的一个重要因素。条件允许的情况下,参见图11,通常使用SSD或者HDD1103存储relay log,然后配置sync_relay_log(多少个事件进行一次刷盘操作)为1,1个事务或者事件进行一次刷盘操作;这样性能高且数据最安全;条件不允许的情况下,则可以根据实际业务在数据安全方面的要求,适当增大sync_relay_log的值(即配置为大于1的数)或者配置为0以减少IO。
其中,可以通过如下语句实现1个事务进行一次刷盘操作:
#/etc/my.cnf
[mysqld]
sync_relay_log用于设置备节点在接收到指定个数的binlog events时执行一次刷盘操作fdatasync(和fsync类似);
sync_relay_log的值为0时,不执行fdatasync,由操作系统来进行不定期刷盘,性能最高,但数据最不安全;
sync_relay_log的值>0时,数值越大,性能越高,但数据越不安全;
综上所述,sync_relay_log的值配置为1,性能最低,但数据最安全,可通过如下语句设置sync_relay_log的值。
sync_relay_log=1
为了提高系统的通用性和易用性,需要减少不必要的配置,并在性能和安全性两个方面寻求平衡。因此,系统可以对MySQL源码进行优化修改,一个事务通常由多个events组成,默认在接收到需要返回ACK的event(ACK标志事务结束)时才执行fsyncdata进行刷盘,不仅能极大降低备节点IO,同时也能保证极端情况下最多丢失一个事务的数据。该优化修改可以通过如下配置进行关闭:
#/etc/my.cnf
[mysqld]
#是否在事务结束时执行fdatasync
sync-relay-log-at-trx-commit=off
本申请实施例中,正常情况下,主节点和备节点之间使用半同步(semi-sync)模式进行复制,此时两者数据满足最终一致性;当备节点出现问题时,系统会自动切换主备复制模式为异步模式(async),避免对主节点的业务造成影响;待备节点恢复正常(例如网络抖动结束)后,系统会再次恢复主备复制模式为半同步模式。从而可以最大程度保障主节点和备节点之间数据的一致性,并且不影响业务。基于组提交的并行复制以及动态调优一系列配置项,用于优化备节点重放relay log的性能,减少主备之间的数据延迟。当主节点出现故障时,备节点只需要重放完剩余的少量relay log即可实现秒级切换。所述主节点的IO线程将所述二进制日志数据存储在临时文件系统tmpfs上,可以省去fsync刷盘操作的开销;所述备节点的IO线程将所述中继日志的刷盘时机调整至事务级别;所述备节点的IO线程将所述中继日志的刷盘时机调整至事务级别,以减少备节点的硬盘IO,在尽可能保证数据安全的情况下,大幅度降低对主节点的性能影响。最终主节点的TPS与单机MySQL十分接近。
图12为本申请实施例一种备节点的IO线程进行中继日志的刷盘操作的方法示意图,所述方法包括以下步骤,以下步骤在备节点的IO线程中执行:
步骤1202:备节点IO线程入口点函数;
其中,所述入口点函数可以是handle_slave_io(void*arg)
步骤1204:判断IO线程是否被停止;
若是,则执行步骤1206;若否,则执行步骤1224;
步骤1206:从主节点读取一个binlog事务;
其中,可以通过如下语句从主节点读取binlog事务;
read_event(mysql,mi,&suppress_warnings)
步骤1208:判断事务是否需要返回ACK;若是,则执行步骤1210;
其中,可以通过如下语句判断事务是否需要返回ACK:
Event_buf[1]==ReplSemiSyncBase::kPacketMagicNum&&eventbuf[2]==ReplSemiSyncBas e::kPacketFlagsync
步骤1210:标记当前需要进行relay log刷盘;
其中,可以通过如下语句标记当前需要进行relay log刷盘操作:
mi->is_need_synced=true;
步骤1212:将事务放入队列;
其中,可以通过如下语句将事务放入队列:
queue_event(mi,event buf,event_len)
步骤1214:将事务追加到relay log缓冲区;
其中,可以通过如下语句将事务追加到relay log缓冲区:
rli->relay_log.append_buffer(buf,event len,mi)
其中,在追加到relay log缓冲区以后(after_append_to_relay_log(mi)),执行relay log刷盘操作:flush_and_sync(0);所述刷盘操作可以包括步骤1216至1222:
步骤1216:是否开启优化开关;若是,则执行步骤1218;若否,则执行步骤1204;
其中,可以通过如下语句判断是否开启优化开关:
sync_relay_log_at_trx_commit
步骤1218:是否需要刷盘;若是,则执行步骤1220;若否,则执行步骤1204;
其中,可以通过如下语句判断是否需要刷盘:
mi->is_need_synced
步骤1220:使用fsync|fdatasync进行刷盘;
其中,可以采用函数fsync或fdatasync进行刷盘操作,例如可以采用如下函数执行刷盘操作:mysql_file_sync(log_file.file,MYF(MY_WME|MY_IGNORE_BADFD))
步骤1222:使用原生刷盘流程进行刷盘;
其中,原生刷盘流程受sync_relay_log配置影响,可通过sync_binlog_file执行刷盘操作;
步骤1224:结束。
本申请实施例还提供一种数据管理方法,所述方法应用于数据管理系统,所述数据管理系统包括主节点的服务组件、代理组件和管理组件,备节点的服务组件、代理组件和管理组件,所述方法可以包括以下步骤:
步骤S502:在所述备节点的代理组件通过所述备节点的管理组件检测到所述主节点的故障事件的情况下,检测所述备节点的服务组件和所述主节点的服务组件之间数据的一致性;所述主节点的故障事件是由所述主节点的代理组件经所述主节点的管理组件发送至所述备节点的管理组件的心跳包确定出的;
步骤S504:所述备节点的代理组件在所述备节点的服务组件和所述主节点的服务组件之间的数据一致的情况下,将所述备节点以可读写模式作为新的主节点运行。
步骤S506:所述主节点的代理组件在检测到所述备节点的故障事件的情况下,将所述主节点的服务组件和所述备节点的服务组件之间的数据复制模式由半同步模式切换为异步模式;
在一个实施例中,所述备节点的故障事件可以是备节点数量不足或者等待备节点的半同步ACK超时等;在所述数据复制模式为半同步复制模式的情况下,所述主节点的代理组件可以在检测到有线程阻塞在等待备节点的半同步ACK上超过配置时间的情况下,认为所述备节点发生故障,将所述数据复制模式切换为异步复制模式。
步骤S508:所述主节点的代理组件在检测到所述备节点恢复正常的情况下,将所述主节点的服务组件和所述备节点的服务组件之间的数据复制模式由所述异步模式切换为所述半同步模式;
在一个实施例中,所述主节点的代理组件在所述数据模式为异步模式的情况下,检测所述备节点的服务组件和所述主节点的服务组件之间数据的一致性;
在所述主节点的代理组件在所述备节点的服务组件和所述主节点的服务组件之间数据一致的情况下,可以确定所述备节点恢复正常。
步骤S510:所述主节点的代理组件在检测到所述数据复制模式为半同步模式、且未检测到所述备节点的故障事件的情况下,检测所述备节点的服务组件和所述主节点的服务组件之间数据的一致性;
步骤S512:所述主节点的代理组件在所述备节点的服务组件和所述主节点的服务组件之间数据一致的情况下,标记所述主节点的服务组件和所述备节点的服务组件之间的数据一致;
步骤S514:所述主节点的代理组件在所述备节点的服务组件和所述主节点的服务组件之间数据不一致的情况下,标记所述主节点的服务组件和所述备节点的服务组件之间的数据不一致;
步骤S516:所述主节点的代理组件在检测到所述数据复制模式为半同步模式、且检测到所述备节点的故障事件的情况下,标记所述主节点的服务组件和所述备节点的服务组件之间的数据不一致,并结束所述备节点的数据转存线程;
其中,所述数据转存线程可以是二进制日志数据转存线程,可以表示为bin logdump线程。
步骤S518:所述主节点的代理组件在检测到所述数据复制模式为异步模式的情况下,标记所述主节点的服务组件和所述备节点的服务组件之间的数据不一致。
本申请实施例中,通过根据数据复制模式的不同,以及备节点是否故障,对主节点的服务组件和备节点的服务组件之间的数据一致性进行标记,从而可以更准确、便捷地确定主节点的服务组件和备节点的服务组件之间的数据是否一致。
图13为本申请实施例一种监控和动态切换数据复制模式的方法流程示意图,所述方法包括以下步骤,以下步骤会在主节点的MySQL HA agent中周期性执行,默认配置下3秒执行一次:
步骤1302:主节点的MySQL HA agent判断主节点和备节点之间的数据复制模式是否为半同步复制模式;若是,执行步骤1304;若否,则执行步骤1318;
其中,可以通过如下语句查看所述数据复制模式是否为半同步复制模式:
mysql>SHOW GLOBAL STATUS LIKE
WRpl-semisync_master_status";
步骤1304:判断是否有线程阻塞在等待备节点的半同步ACK上超过5(时间可配置)秒;
其中,可以通过如下语句查询是否有线程阻塞在等待备节点的半同步ACK上超过5秒:
mysq>SELECT*FROM
information_schema.processlist WHERE state="Waiting for semi-syncACK from slave"AND time>=5
LIMIT 1;
需要说明的是,线程阻塞的时间阈值可以预先进行配置,例如4秒、6秒和7秒等。
若是,则执行步骤1306;若否,则执行步骤1312;
步骤1306:在Cluster Manager中标记主备之间数据不一致;
其中,可以通过如下语句标记主备之间数据不一致:
PUT/mysql/ha/consistent
False;
步骤1308:将主备之间的数据复制模式切换为异步复制模式;
其中,可以通过如下语句令半同步复制模式使能为0,从而将主备之间的数据复制模式切换为异步复制模式。
mysql>SET GLOBAL rpl_semi_sync_master_enabled
=0;
步骤1310:结束备节点的binlog dump线程;
其中,可以通过如下语句结束备节点的binlog dump线程:
mysgl>SELECT id FROM
information_schema.processlist WHERE host LIKE
"10.134.87.223:%"AND command IN("Binlog Dump","Binlog Dump GTID");
mysgl>KILL 1267;
步骤1312:判断备节点的relay log是否与主节点的bin log一致;
其中,可以通过如下语句查询备节点的relay log是否与主节点的bin log一致:
SELECT*FROM
information_schema.processlist WHERE host LIKE"10.134.87.223:%"ANDstate="Master has sent all binlog-to slave;waiting for more updates"LMIT 1
若是,则执行步骤1314;若否,则执行步骤1316;
步骤1314:在Cluster Manager中标记主备之间数据一致;
其中,可以通过如下语句标记主备之间数据一致:
PUT/mysal/ha/consistent true;
步骤1316:在Cluster Manager中标记主备之间数据不一致;
其中,可以通过如下语句标记主备之间数据不一致:
PUT/mysql/ha/consistent false;
步骤1318:在Cluster Manager中标记主备之间数据不一致;
同理,可以通过如下语句标记主备之间数据不一致:
PUT/mysq/ha/consistent false;
步骤1320:判断备节点的relay log是否与主节点的bin log一致;
若是,则执行步骤1322;若否,则执行步骤1324;
其中,可以通过如下语句判断备节点的relay log是否与主节点的bin log一致:
SELECT*FROM
information_schema.processlist WHERE host LIKE"10.134.87.223:%"ANDstate="Master has sent all binlog to slave;waiting for more updates"LIMIT 1
步骤1322:将主备之间的数据复制模式切换为半同步复制模式;
其中,可以通过如下语句令半同步复制模式使能为1,从而将主备之间的数据复制模式切换为半同步复制模式。
mysql>SET GLOBAL rpl_semi_sync_master_enabled
=1;
步骤1324:结束。
相关技术中的数据管理方法主要包括以下几种:
第一种,基于异步复制的MySQL主备:主节点和备节点之间采用异步模式进行复制。
MySQL原生支持的主备方案,主节点异步地向备节点发送二进制日志数据,即binlog文件。
该方法的优点是对主节点的性能基本无影响。
该方法的缺点是无法保证主节点和备节点之间数据的一致性;无法自动进行故障转移,即无法自动Failover。
第二种,基于半同步复制的MySQL主备:主节点和备节点之间采用半同步模式进行复制。
MySQL插件支持的主备方案,主节点在应答客户端提交的事务前需要保证至少有一个备节点接收并写到中继日志,即relay log文件中。
该方法的优点是可以尽力保证主节点和备节点之间数据的一致性。
该方法的缺点是对主节点性能影响比较大;无法自动Failover。在等待备节点的ACK(Acknowledge character,确认字符)超时后,主节点会自动退化为异步复制模式,导致主节点和备节点之间数据的不一致。因为这一切模式的切换对外界都是不可见的,所以Failover时无法准确判断主节点和备节点之间数据是否一致。
第三种:MMM(Master-Master replication manager for MySQL):是一套支持双主故障切换和双主日常管理的脚本程序。
MMM使用Perl语言(实用报表提取语言)开发,主要用来监控和管理MySQL Master-Master(双主)复制,虽然叫做双主复制,但是业务上同一时刻只允许对一个主节点进行写入,另一台备选主节点上提供部分读服务,以加速在主主切换时刻备选主的预热。
该方法的优点是自动Failover,且尽力保证主节点和备选主节点之间数据的一致性。
该方法的缺点是通常也是基于半同步复制来实现双主复制,所以也存在第二种方法中的缺点:对主节点性能影响比较大;无法自动Failover。在等待备节点的ACK(Acknowledge character,确认字符)超时后,主节点会自动退化为异步复制模式,导致主节点和备选主节点之间数据的不一致。因为这一切模式的切换对外界都是不可见的,所以Failover时无法准确判断主节点和备选主节点之间数据是否一致。同时,MMM也是一款比较老的高可用产品,在业内使用的并不多,社区也不活跃,该产品的技术开发团队很早就不再维护MMM的代码分支,存在大量Bug。
第四种:MHA(MySQL Master High Availability):目前比较成熟及流行的MySQL高可用解决方案,很多互联网公司正是直接使用或者基于MHA的架构进行改造实现MySQL的高可用。MHA能在30秒内完成Failover,并最大程度的保障主节点和备节点之间数据的一致性。
该方法的优点是自动Failover,且尽力保证数据的一致性。
该方法的缺点通常也是基于半同步复制来实现主备复制,所以也存在第二种方法中的缺点;Failover耗时比较长。另外,MHA由两个模块组成:Manager和Node,Manager需要部署在独立的节点上,负责检查MySQL复制状态、主库状态以及执行切换操作,存在单点故障问题。
第五种:PXC(Percona XtraDB Cluster):一种开源的基于Galera协议的MySQL高可用集群方案,可以实现多主同步复制,保证数据的强一致性。在任何时刻集群中任意节点上的数据状态都是完全一致的,并且整个架构实现了去中心化,所有节点都是对等的,即允许在任意节点上进行读写,集群会把数据状态同步至其他节点。
该方法的优点是数据的强一致性;可以扩展读性能;少数节点故障后,集群仍然可以正常运转。
该方法的缺点是:根据“木桶效应”,整个集群的写吞吐量受限于性能最差的节点;任意节点的写入都需要同步数据状态至其他节点,所以写吞吐量显著低于单机MySQL;只支持InnoDB存储引擎,所有表必须有主键;在实践过程中,也出现过丢失数据的现象。
第六种:MGR(MySQL Group Replication,MySQL组复制):MySQL组复制是MySQL官方发布的高可用架构,使用插件实现。
类似PXC一样,支持多主模式,但是多个节点间的事务可能有比较大的冲突,从而显著影响性能;所以官方推荐单主模式,即只有主节点可以处理写请求,所有节点都可以处理读请求。
该方法与PXC有相同的优点。
该方法与PXC一样,有“木桶效应”问题,也会显著降低系统的写吞吐量;使用上也有诸多限制,例如只支持InnoDB存储引擎、所有表必须有主键、不支持表锁和命名锁、不支持超大事务等。最后,因为技术比较新还有很多Bug,稳定性相对较差,所以目前应用的较少。
目前比较流行的MySQL高可用方案有上述六种,不难看出这些方案或多或少存在以下一些缺点:
无法自动Failover;Failover耗时长;无法保证数据一致性,数据一致性是高可用方案要解决的关键问题,需要尽力保证,否则会出现数据丢失或错误的问题;低吞吐量;不支持告警。
本申请实施例提供一种数据管理方法,应用于数据管理系统,所述方法包括以下内容:
自动Failover(故障转移)。在MySQL主节点(Master)出现故障后的几秒内,备节点会自动切换为新的主节点的角色以接管业务。如果切换时备节点与主节点数据一致,那么切换后新的主节点可正常读写;反之切换后的新的主节点以只读模式运行,并向管理员发送告警。
最大程度保障主节点和备节点之间数据的一致性,并且不影响业务。正常情况下,主节点和备节点之间使用半同步(semi-sync)模式进行复制,此时两者数据满足最终一致性;当备节点出现问题时,系统会自动切换主备复制模式为异步模式(async),避免对主节点的业务造成影响;待备节点恢复正常(例如网络抖动结束)后,系统会再次恢复主备复制模式为半同步模式。
节点自愈。系统会监控每个节点的健康状态,如果节点状态异常,会自动尝试进行恢复。例如在备节点的复制停止时,系统会自动重启复制;而当备节点故障或数据长时间落后于主节点时,系统则会从空闲节点中选举一个新的备节点,并降级旧的备节点,同时向管理员发送告警,以应对一些短时间内难以自动恢复的场景例如硬盘损坏、网络分区等。
高吞吐量。以半同步模式进行复制在满足主节点和备节点之间数据的最终一致性的同时,也会大大降低主节点的TPS(Transaction per second,每秒事务量)。为了解决该问题,系统可以将主节点的bin log(二进制日志)文件存储在tmpfs(基于内存的临时文件系统)上,以省去fsync刷盘操作的开销,fsync函数同步内存中所有已修改的文件数据到储存设备;同时优化备节点的relay log刷盘时机到事务级别,以减少备节点的硬盘IO,在尽可能保证数据安全的情况下,大幅度降低对主节点的性能影响。最终主节点的TPS与单机MySQL十分接近。备节点接收主节点的bin log文件,并写到relay log文件里,备节点的slave sql线程从relay log文件里读取bin log文件,在本地重放relay log,使得备节点的数据和主节点的数据保持一致。
秒级切换。基于组提交的并行复制以及动态调优一系列配置项,用于优化备节点重放relay log的性能,减少主备之间的数据延迟。当主节点出现故障时,备节点只需要重放完剩余的少量relay log即可实现秒级切换。
自治。采用预防性保护机制来防范所有计划外和计划内的中断,并且无需停机和人工干预就能自动、快速地从故障中恢复。
本申请实施例中通过自动Failover,可以保证业务的高可用性;最大程度保障主备数据的一致性,从而提升数据的安全性;高吞吐量,主备节点之间网络直连或者使用专线的情况下,TPS可以达到单机MySQL的80%以上;秒级切换,从主节点故障到备节点切换为新的主节点,可以在6+3=9秒内完成,其中,前6秒为感知主节点故障的最长耗时,可通过配置进一步缩短;后3秒为备切主的平均耗时。而目前流行的MHA方案,则需要在30秒内才能完成切换。相比之下,本方案可以大幅缩短系统的downtime;灵活可配的告警方式,助力管理员提前或及时发现系统问题。
基于前述的实施例,本申请实施例提供一种数据管理系统,该系统所包括的各组件,可以通过电子设备中的处理器来实现;当然也可通过具体的逻辑电路实现;在实施的过程中,处理器可以为中央处理器(CPU,Central Processing Unit)、微处理器(MPU,Microprocessor Unit)、数字信号处理器(DSP,Digital Signal Processing)或现场可编程门阵列(FPGA,Field Programmable Gate Array)等。
如图1所示的数据管理系统,所述系统包括主节点11的服务组件101、代理组件102和管理组件103,以及备节点12的服务组件104、代理组件105和管理组件106,其中:
所述备节点12的代理组件105,用于在通过所述备节点12的管理组件106检测到所述主节点11的故障事件的情况下,检测所述备节点12的服务组件104和所述主节点11的服务组件101之间数据的一致性;所述主节点11的故障事件是由所述主节点11的代理组件102经所述主节点11的管理组件103发送至所述备节点12的管理组件106的心跳包确定出的;
所述备节点12的代理组件105,还用于在所述备节点12的服务组件104和所述主节点的服务组件101之间的数据一致的情况下,将所述备节点12以可读写模式作为新的主节点运行。
在一个实施例中,所述备节点12的代理组件105在所述备节点12的服务组件104和所述主节点11的服务组件101之间的数据不一致的情况下,将所述备节点12以只读模式作为新的主节点运行,并输出第一告警信息,所述第一告警信息用于表征所述主节点11的服务组件101和所述备节点12的服务组件104之间的数据不一致。
在一个实施例中,所述备节点12的代理组件105在检测到所述备节点12的故障事件的情况下,对所述备节点12进行恢复;所述备节点12的代理组件105在确定所述备节点无法恢复的情况下,将所述备节点12作为新的空闲节点运行,并输出第二告警信息。
在一个实施例中,所述数据管理系统还包括空闲节点的服务组件、代理组件和管理组件,所述空闲节点的服务组件为停止运行状态,在所述备节点12的代理组件105通过所述备节点12的管理组件106检测到所述主节点11的故障事件,或者所述备节点12的代理组件105在检测到所述备节点12的故障事件的情况下,新的主节点的代理组件将所述空闲节点中的目标空闲节点选举为新的备节点;所述目标空闲节点的代理组件检测所述目标空闲节点的管理组件发送的选举事件;所述选举事件是由所述新的主节点的代理组件经所述新的主节点的管理组件发送至所述目标空闲节点的管理组件的;在检测到所述选举事件的情况下,将所述目标空闲节点作为新的备节点运行。
在一个实施例中,在所述备节点12的代理组件105在预设的宕机时间阈值内,未接收到所述备节点12的管理组件106发送的所述主节点11的心跳包的情况下,确定检测到所述主节点11的故障事件;其中,所述宕机时间阈值是根据网络质量和负载确定出的。
在一个实施例中,所述主节点11的代理组件102在检测到所述备节点12的故障事件的情况下,将所述主节点11的服务组件101和所述备节点12的服务组件104之间的数据复制模式由半同步模式切换为异步模式;所述主节点11的代理组件102在检测到所述备节点12恢复正常的情况下,将所述主节点11的服务组件101和所述备节点12的服务组件104之间的数据复制模式由所述异步模式切换为所述半同步模式。
在一个实施例中,所述主节点11的代理组件102在检测到所述数据复制模式为半同步模式、且未检测到所述备节点12的故障事件的情况下,检测所述备节点12的服务组件104和所述主节点11的服务组件101之间数据的一致性;所述主节点11的代理组件102在所述备节点12的服务组件104和所述主节点11的服务组件101之间数据一致的情况下,标记所述主节点11的服务组件101和所述备节点12的服务组件104之间的数据一致;所述主节点11的代理组件102在所述备节点12的服务组件104和所述主节点11的服务组件101之间数据不一致的情况下,标记所述主节点11的服务组件101和所述备节点12的服务组件104之间的数据不一致。
在一个实施例中,所述主节点11的代理组件102在检测到所述数据复制模式为半同步模式、且检测到所述备节点12的故障事件的情况下,标记所述主节点11的服务组件101和所述备节点12的服务组件104之间的数据不一致,并结束所述备节点12的数据转存线程;所述主节点11的代理组件102在检测到所述数据复制模式为异步模式的情况下,标记所述主节点11的服务组件101和所述备节点12的服务组件104之间的数据不一致。
在一个实施例中,所述主节点11的代理组件102在所述数据模式为异步模式的情况下,检测所述备节点12的服务组件104和所述主节点11的服务组件101之间数据的一致性;在所述主节点11的代理组件102在所述备节点12的服务组件104和所述主节点11的服务组件101之间数据一致的情况下,确定所述备节点12恢复正常。
在一个实施例中,所述备节点12的代理组件105,用于检测所述备节点12的服务组件104的中继日志和所述主节点11的二进制日志数据之间数据的一致性。
在一个实施例中,所述主节点11的SQL线程根据事务的繁忙程度,设置所述二进制日志数据提交刷盘的延迟时间和延迟等待的最大事务数;所述备节点12的SQL线程根据事务的冲突程度和分布的数据库,动态切换所述备节点12的并行复制的策略;所述策略包括:根据不同数据库之间的事务进行并行复制,以及根据同一个组提交中的事务进行并行复制。所述备节点12的SQL线程根据硬件配置,设置所述备节点12的并行复制的线程数。
在一个实施例中,所述主节点11的IO线程将所述二进制日志数据存储在临时文件系统tmpfs上。所述备节点12的IO线程将所述中继日志的刷盘时机调整至事务级别。
需要说明的是,本申请实施例中,如果以软件功能模块的形式实现上述的数据管理方法,并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请实施例的技术方案本质上或者说对相关技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得电子设备(可以是手机、平板电脑、台式机、个人数字助理、导航仪、数字电话、视频电话、电视机、传感设备等)执行本申请各个实施例所述方法的全部或部分。而前述的存储介质包括:U盘、移动硬盘、只读存储器(Read Only Memory,ROM)、磁碟或者光盘等各种可以存储程序代码的介质。这样,本申请实施例不限制于任何特定的硬件和软件结合。
以上系统实施例的描述,与上述方法实施例的描述是类似的,具有同方法实施例相似的有益效果。对于本申请系统实施例中未披露的技术细节,请参照本申请方法实施例的描述而理解。
对应地,本申请实施例提供一种电子设备,图14为本申请实施例电子设备的一种硬件实体示意图,如图14所示,该电子设备1400的硬件实体包括:包括存储器1401和处理器1402,所述存储器1401存储有可在处理器1402上运行的计算机程序,所述处理器1402执行所述程序时实现上述实施例数据管理方法中的步骤。
存储器1401配置为存储由处理器1402可执行的指令和应用,还可以缓存待处理器1402以及通话设备1400中各模块待处理或已经处理的数据(例如,图像数据、音频数据、语音通信数据和视频通信数据),可以通过闪存(FLASH)或随机访问存储器(Random AccessMemory,RAM)实现。
对应地,本申请实施例提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述实施例中提供的数据管理方法中的步骤。
这里需要指出的是:以上存储介质和设备实施例的描述,与上述方法实施例的描述是类似的,具有同设备实施例相似的有益效果。对于本申请存储介质和方法实施例中未披露的技术细节,请参照本申请设备实施例的描述而理解。
应理解,说明书通篇中提到的“一个实施例”或“一实施例”意味着与实施例有关的特定特征、结构或特性包括在本申请的至少一个实施例中。因此,在整个说明书各处出现的“在一个实施例中”或“在一实施例中”未必一定指相同的实施例。此外,这些特定的特征、结构或特性可以任意适合的方式结合在一个或多个实施例中。应理解,在本申请的各种实施例中,上述各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本申请实施例的实施过程构成任何限定。上述本申请实施例序号仅仅为了描述,不代表实施例的优劣。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
在本申请所提供的几个实施例中,应该理解到,所揭露的设备和方法,可以通过其它的方式实现。以上所描述的设备实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,如:多个单元或组件可以结合,或可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的各组成部分相互之间的耦合、或直接耦合、或通信连接可以是通过一些接口,设备或单元的间接耦合或通信连接,可以是电性的、机械的或其它形式的。
上述作为分离部件说明的单元可以是、或也可以不是物理上分开的,作为单元显示的部件可以是、或也可以不是物理单元;既可以位于一个地方,也可以分布到多个网络单元上;可以根据实际的需要选择其中的部分或全部单元来实现本实施例方案的目的。另外,在本申请各实施例中的各功能单元可以全部集成在一个处理单元中,也可以是各单元分别单独作为一个单元,也可以两个或两个以上单元集成在一个单元中;上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:移动存储设备、只读存储器(Read Only Memory,ROM)、磁碟或者光盘等各种可以存储程序代码的介质。或者,本申请上述集成的单元如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请实施例的技术方案本质上或者说对相关技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得计算机设备(可以是手机、平板电脑、台式机、个人数字助理、导航仪、数字电话、视频电话、电视机、传感设备等)执行本申请各个实施例所述方法的全部或部分。而前述的存储介质包括:移动存储设备、ROM、磁碟或者光盘等各种可以存储程序代码的介质。
本申请所提供的几个方法实施例中所揭露的方法,在不冲突的情况下可以任意组合,得到新的方法实施例。本申请所提供的几个产品实施例中所揭露的特征,在不冲突的情况下可以任意组合,得到新的产品实施例。本申请所提供的几个方法或设备实施例中所揭露的特征,在不冲突的情况下可以任意组合,得到新的方法实施例或设备实施例。
以上所述,仅为本申请的实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
- 数据管理方法、数据读取方法、存储介质、数据管理系统及终端设备
- 使用访问控制证书的数据访问管理系统及管理方法数据访问管理系统、存储器安装设备、数据访问管理方法