一种基于词频排序及剪枝的非监督多关键词文本聚类方法
文献发布时间:2023-06-19 18:58:26
技术领域
本发明属于文本分析的技术领域,特别是涉及一种基于词频排序及剪枝的非监督多关键词文本聚类方法。
背景技术
在很多行业的工单系统或者其它文本类业务系统中,经常会涉及到要将不同的文本记录进行归类的数据挖掘问题,有些文本分类是可以通过人工归纳出来的,但还有很多文本分类无法通过人的经验总结出来。此时就需要我们想办法通过一定的算法去挖掘出可能的分类,然后再通过人工去二次确认分类。对于人工确认分类的情形,那么使用的模型算法就属于监督方法。反之,不由人工确认分类的模型算法则属于非监督方法。通过非监督方法能在很大程度上解决人工分析的局限性,比如人力成本高、分析方向无从下手、分析问题没有针对性、效率低下等等问题。
如中国发明专利CN201811508368.3公开了一种文本聚类方法、文本聚类装置及终端设备,包括:获取训练文本,并对所述训练文本进行分词预处理得到多个待训练词语;利用所述待训练词语对预设的转换模型进行训练,得到训练后的转换模型;获取待聚类文本,对所述待聚类文本进行分词预处理得到多个文本特征词;利用所述训练后的转换模型分别将所述文本特征词转换为词向量,并将所述待聚类文本中的所有词向量进行叠加得到所述待聚类文本的文本向量;对所述文本向量进行聚类得到聚类结果。
但是上述中国发明专利CN201811508368.3中,并没有针对词频排序及剪枝提出排序及质量、效率的分析方案。
发明内容
基于此,本发明的目的在于提供一种基于词频排序及剪枝的非监督多关键词文本聚类方法,能解决人工分析文本的局限性,提供有意义的初步分类结果供分析人员参考,辅助分析人员作进一步的分析。首先基于词频排序在一定程度上能很好地代表文本内容的重要性排序,其次提出了多关键词来描述文本分类,最后通过剪枝的方式提供一种兼顾结果质量和执行效率的分析方式。
本发明的技术方案是:一种基于词频排序及剪枝的非监督多关键词文本聚类方法,其中,包括以下步骤:
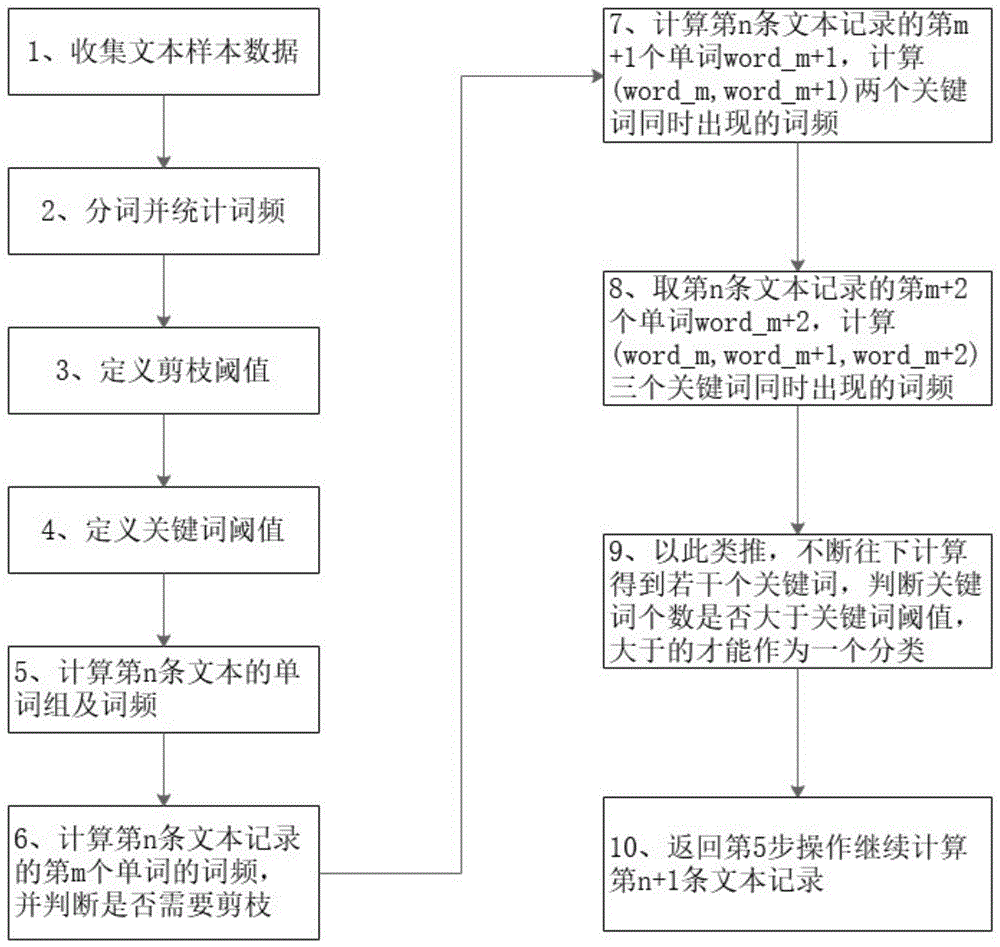
步骤S1.收集文本样本数据;
步骤S2.分词并统计词频;
步骤S3.定义剪枝阈值;
步骤S4.定义关键词阈值;
步骤S5.计算第n条文本的单词组及词频;
步骤S6.计算第n条文本记录的第m个单词的词频,并判断是否需要剪枝;
步骤S7.计算第n条文本记录的第m+1个单词word_m+1,计算word_m和word_m+1两个关键词同时出现的词频;
步骤S8.取第n条文本记录的第m+2个单词word_m+2,计算word_m,word_m+1,word_m+2三个关键词同时出现的词频;
步骤S9.以此类推,不断往下计算得到若干个关键词,判断关键词个数是否大于关键词阈值,大于的才能作为一个分类;
步骤S10.返回步骤S5操作继续计算第n+1条文本记录。
本发明中,通过上述的技术方案,解决文本分类分析方向无从下手、分析问题没有针对性、效率低下等等问题。基于词频排序在一定程度上能很好地代表文本内容的重要性排序。提出了多关键词来描述文本分类,帮助业务人员总结。通过剪枝的方式提供一种兼顾结果质量和执行效率的分析方式。
在一种具体的实施方案中,所述的步骤S1中,文本样本数据为生产业务系统中一定时间内的文本数据。
在一种具体的实施方案中,所述的步骤S2中,具体为,对所有收集的文本数据进行分词操作,然后统计每个分词在多少个工单出现过,将该结果作为词频。
在一种具体的实施方案中,所述的步骤S3中,具体为,定义一个词频阈值作为剪枝的判定依据。
在一种具体的实施方案中,所述的步骤S4中,具体为,定义一个关键词阈值作为分类依据。
在一种具体的实施方案中,所述的步骤S5中,具体为,对于第n条文本记录,其中n为所有训练样本数据的第n条,计算它所包含的单词组及词频,记为word_1,word_2,word_3,...和freq_1,freq_2,freq_3,...。
在一种具体的实施方案中,所述的步骤S6中,具体为,取第n条文本记录的第m个单词word_m,判断对应的词频freq_m是否大于剪枝阈值T,大于等于则往下继续,小于则跳过此次计算。
在一种具体的实施方案中,所述的步骤S7中,具体为,再取第n条文本记录的第m+1个单词word_m+1,计算word_m和word_m+1两个关键词同时出现的词频,若大于等于剪枝阈值T则往下继续,否则跳过此次计算。
在一种具体的实施方案中,所述的步骤S8中,继续取第n条文本记录的第m+2个单词word_m+2,计算word_m,word_m+1,word_m+2三个关键词同时出现的词频,根据剪枝阈值进行剪枝。
本发明的有益效果如下:
本发明能解决人工分析文本的局限性,提供有意义的初步分类结果供分析人员参考,辅助分析人员作进一步的分析。首先基于词频排序在一定程度上能很好地代表文本内容的重要性排序,其次提出了多关键词来描述文本分类,最后通过剪枝的方式提供一种兼顾结果质量和执行效率的分析方式。
本发明解决文本分类分析方向无从下手、分析问题没有针对性、效率低下等等问题。基于词频排序在一定程度上能很好地代表文本内容的重要性排序。提出了多关键词来描述文本分类,帮助业务人员总结。通过剪枝的方式提供一种兼顾结果质量和执行效率的分析方式。
为了更好地理解和实施,下面结合附图详细说明本发明。
附图说明
图1为本发明方法流程示意图。
具体实施方式
在本说明书中提到或者可能提到的上、下、左、右、前、后、正面、背面、顶部、底部等方位用语是相对于其构造进行定义的,它们是相对的概念。因此,有可能会根据其所处不同位置、不同使用状态而进行相应地变化。所以,也不应当将这些或者其他的方位用语解释为限制性用语。
以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与本公开的一些方面相一致的实施方式的例子。
在本公开使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本公开。在本公开中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本公开中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。除非有相反的说明,本公开提及的“第一”、“第二”等序数词用于对多个对象进行区分,不用于限定多个对象的顺序、时序、优先级或者重要程度。
另外,还应当理解,当在本说明书和所附权利要求书中使用时,术语“包括”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
还应当理解,在此本申请说明书中所使用的术语仅仅是出于描述特定实施例的目的而并不意在限制本申请。如在本申请说明书和所附权利要求书中所使用的那样,除非上下文清楚地指明其它情况,否则单数形式的“一”、“一个”及“该”意在包括复数形式。
还应当进一步理解,在本申请说明书和所附权利要求书中使用的术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。
如在本说明书和所附权利要求书中所使用的那样,术语“如果”可以依据上下文被解释为“当...时”或“一旦”或“响应于确定”或“响应于检测到”。类似地,短语“如果确定”或“如果检测到[所描述条件或事件]”可以依据上下文被解释为意指“一旦确定”或“响应于确定”或“一旦检测到[所描述条件或事件]”或“响应于检测到[所描述条件或事件]”。
下面将结合附图对本发明提供的技术方案作进一步地详细描述。
请参考图1所示,一种基于词频排序及剪枝的非监督多关键词文本聚类方法,其中,包括以下步骤:
步骤S1.收集文本样本数据;
步骤S2.分词并统计词频;
步骤S3.定义剪枝阈值;
步骤S4.定义关键词阈值;
步骤S5.计算第n条文本的单词组及词频;
步骤S6.计算第n条文本记录的第m个单词的词频,并判断是否需要剪枝;
步骤S7.计算第n条文本记录的第m+1个单词word_m+1,计算word_m和word_m+1两个关键词同时出现的词频;
步骤S8.取第n条文本记录的第m+2个单词word_m+2,计算word_m,word_m+1,word_m+2三个关键词同时出现的词频;
步骤S9.以此类推,不断往下计算得到若干个关键词,判断关键词个数是否大于关键词阈值,大于的才能作为一个分类;
步骤S10.返回步骤S5操作继续计算第n+1条文本记录。
本实施例中,步骤S1中,文本样本数据为生产业务系统中一定时间内的文本数据。比如是工单系统的话那么就可以收集近一年的工单文本数据。
具体的,上述的生产业务系统可以是专项生产业务管理系统,专项生产业务管理系统该适用于专项生产行业,含BOM填报与变更、ERP与供应商协作、编程单报工,可以实现交期跟踪、物料追踪、质量追踪、成本追踪、效率追踪等信息化需求。
进一步的,所述的步骤S2中,具体为,对所有收集的文本数据进行分词操作,然后统计每个分词在多少个工单出现过,将该结果作为词频。
具体的,所述的步骤S3中,具体为,定义一个词频阈值作为剪枝的判定依据。比如设定剪枝阈值T=1000,则表示词频小于1000的会被剪枝。
再进一步的,所述的步骤S4中,具体为,定义一个关键词阈值作为分类依据。比如设定关键词阈值Y=5,则表示当关键词个数大于5时才会成为一个分类。
再进一步的,所述的步骤S5中,具体为,对于第n条文本记录,其中n为所有训练样本数据的第n条,计算它所包含的单词组及词频,记为word_1,word_2,word_3,...和freq_1,freq_2,freq_3,...。
具体的,所述的步骤S6中,具体为,取第n条文本记录的第m个单词word_m,判断对应的词频freq_m是否大于剪枝阈值T,大于等于则往下继续,小于则跳过此次计算。
进一步的,所述的步骤S7中,具体为,再取第n条文本记录的第m+1个单词word_m+1,计算word_m和word_m+1两个关键词同时出现的词频,若大于等于剪枝阈值T则往下继续,否则跳过此次计算。
再进一步的,所述的步骤S8中,继续取第n条文本记录的第m+2个单词word_m+2,计算word_m,word_m+1,word_m+2三个关键词同时出现的词频,根据剪枝阈值进行剪枝。
通过本实施例的方法,获取工单系统中几十万条文本记录,对它们进行分词,然后定义剪枝阈值和关键词阈值,接着对所有工单记录循环计算词频并得到若干个关键词,由于普通的多关键词聚类算法的时间复杂度达到指数级别,计算量大几乎很难计算执行,所以使用了本发明中提供的剪枝机制大大减少计算耗时。通过本发明文本聚类方法得到分析结果,然后将聚类结果交付业务人员,由人工筛选确定关键词组合能成为一个类别的结果,然后再确认收集无用的关键词。接着再继续迭代分析,通过这个闭环让聚类效果越来越好。本发明是一种独特的文本聚类分析方法,同时包括词频排序、剪枝、多关键词特性的聚类方法。
另外,可选的,本发明还可以包括一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本申请实施例方法的步骤。
在进一步的,还可以提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被一个或多个处理器执行时实现本申请实施例提供的所述方法的步骤。
本发明具有以下的技术效果:
本发明能解决人工分析文本的局限性,提供有意义的初步分类结果供分析人员参考,辅助分析人员作进一步的分析。首先基于词频排序在一定程度上能很好地代表文本内容的重要性排序,其次提出了多关键词来描述文本分类,最后通过剪枝的方式提供一种兼顾结果质量和执行效率的分析方式。
本发明解决文本分类分析方向无从下手、分析问题没有针对性、效率低下等等问题。基于词频排序在一定程度上能很好地代表文本内容的重要性排序。提出了多关键词来描述文本分类,帮助业务人员总结。通过剪枝的方式提供一种兼顾结果质量和执行效率的分析方式。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 一种基于词频排序及等间距取词的英语词汇量检测方法
- 一种融合成对约束和关键词的半监督文本聚类方法及装置
- 一种基于关键词词频统计的舆情趋势分析方法和系统