一种生物合成诺卡酮的方法及载体
文献发布时间:2023-06-19 19:30:30
技术领域
本申请属于诺卡酮生物合成领域,具体涉及一种生物合成诺卡酮的方法及载体。
背景技术
诺卡酮被发现存在于阿拉斯加黄柏、葡萄柚等植物中,其是一种天然的倍半萜酮,具有宜人的葡萄柚香味,因此诺卡酮可以用于制备香料或作为葡萄柚味的调味剂使用。此外人们还发现诺卡酮具有趋避蚊虫的作用,2020年8月美国环境保护署批准了诺卡酮作为驱虫剂或杀虫剂使用,因此诺卡酮也可以制成作驱蚊水和蜱虫趋避剂使用,目前也有相关的研究表明诺卡酮可以刺激人体交感神经分泌相关激素,起到燃脂减肥的作用。以上表明了诺卡酮具有很高的应用价值。
诺卡酮可以从植物中提取获得,但由于植物中诺卡酮含量低,限制了其应用。诺卡酮还可以由瓦伦烯化学合成获得,但反应过程涉及毒性重金属,也影响了此方式的应用。使用微生物细胞工厂全合成诺卡酮是一条具有潜力的方式。
发明内容
本申请的目的在于提供一种生物合成诺卡酮的方法及载体。
本申请为解决上述技术问题,提出了如下技术方案:
本申请第一方面提供了一种生物合成诺卡酮的方法,其包括采用能够表达瓦伦烯合成酶、细胞色素P450氧化酶、细胞色素P450氧化还原酶和醇脱氢酶的重组菌合成诺卡酮;其中,所述瓦伦烯合成酶、细胞色素P450氧化酶、细胞色素P450氧化还原酶和醇脱氢酶来自益智。
本申请第二方面提供了一种用于诺卡酮合成的酶,其具有与SEQ ID NO.1、SEQ IDNO.2、SEQ ID NO.3、SEQ ID NO.4、SEQ ID NO.5或SEQ ID NO.6所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
本申请第三方面提供了一种多核苷酸分子,其包含编码本申请第二方面所提供的酶的核苷酸序列或其互补序列的至少一种。
本申请第四方面提供了一种核酸构建体,其包含权本申请第三方面所提供的多核苷酸分子的至少一种。
本申请第五方面提供了一种重组菌,其包含本申请第三方面的多核苷酸分子,或本申请第四方面的核酸构建体;所述重组菌通过将所述多核苷酸分子或所述核酸构建体导入宿主细胞中获得;优选地,所述宿主细胞为真核细胞;更优选为酿酒酵母。
本申请第六方面提供了采用本申请第二方面的酶、本申请第三方面的多核苷酸分子、本申请第四方面的核酸构建体或本申请第五方面的重组菌生产瓦伦烯、诺卡醇和/或诺卡酮的用途。
本申请鉴定出由法尼基焦磷酸合成诺卡酮的全套酶及其编码基因,并提供了利用所述酶生物合成诺卡酮的方法,采用本申请的酶及生物合成方法,有利于获得诺卡酮高产菌株,提高生物合成诺卡酮的产量。
附图说明
图1为质粒pZY900构建示意图;
图2为质粒pDXYZ3构建示意图;
图3为质粒pDXVS1、pDXVS2构建示意图;
图4为质粒pDXNL1、pDXNL2、pDXNL3、pCK构建示意图;
图5为质粒pDXNT1构建示意图;
图6为JDXYZ3菌株发酵产物中瓦伦烯和瓦伦烯标准品的提取离子流色谱图;
图7为CK菌株、JDXNL1菌株(图中标记为CYP6),JDXNL2菌株(图中标记为CYP9)和JDXNL3菌株(图中标记为AoKo)摇瓶发酵产物,以及诺卡醇标准品提取离子流色谱图;
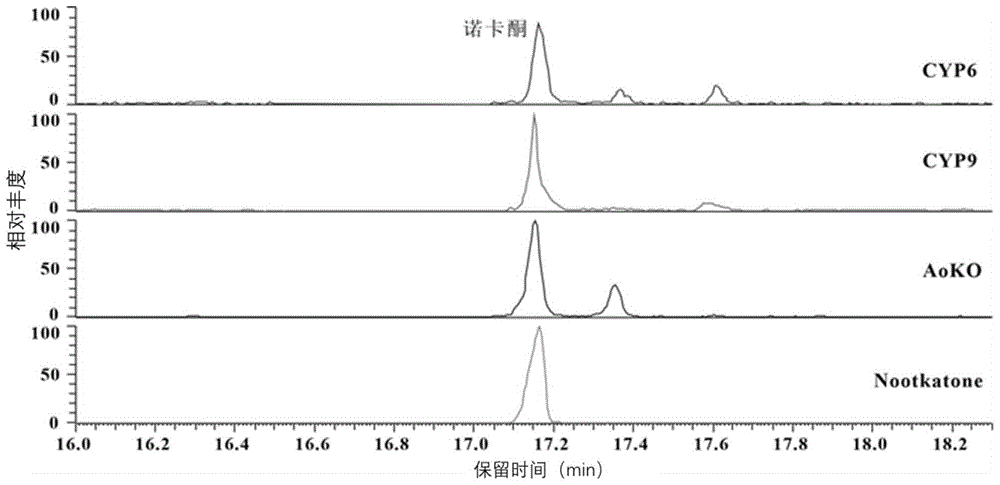
图8为JDXNT1菌株(图中标记为CYP6)、JDXNT2菌株(图中标记为CYP9)和JDXNT3菌株(图中标记为AoKo)摇瓶发酵产物,以及诺卡酮标准品提取离子流色谱图。
具体实施方式
本文使用的术语和说明仅仅是为了描述特定的实施方案,而不意在限制本申请。除非另有定义,本文所用的所有技术和科学术语具有与本公开所属领域的普通技术人员通常理解的相同含义。此外,除非上下文另有要求,否则单数术语应包括复数,并且复数术语应包括单数。
定义
如本文所用,术语“一个”和“一种”以及“所述”和类似的指代物指示单数和复数,除非本文另外指明或上下文明显矛盾。
如本文所用,术语“约”和“类似于”是指在本领域普通技术人员所确定的特定值的可接受误差范围内,所述误差范围可部分取决于该值的测量或确定方式,或取决于测量系统的局限性。
术语“核酸”或“多核苷酸”是指脱氧核糖核酸(DNA)或核糖核酸(RNA)及其呈单链或双链形式的聚合物。除非明确地限制,否则术语“核酸”或“多核苷酸”还包括含有已知的天然核苷酸的类似物的核酸,其具有与参照核酸相似的结合性质,并且以与天然存在的核苷酸相似的方式被代谢(参见,属于Kariko等人的美国专利No.8278036,其公开了尿苷被假尿苷替代的mRNA分子,合成所述mRNA分子的方法以及用于在体内递送治疗性蛋白的方法)。除非另有所指,否则特定核酸序列还隐含地包括其保守修饰的变体(例如,简并密码子取代)、等位基因、直系同源物、单核苷酸多态性(SNP)和互补序列以及明确指出的序列。
“构建体”是指任何重组多核苷酸分子(例如质粒、粘粒、病毒、自主复制多核苷酸分子、噬菌体、线性或环状单链或双链DNA或RNA多核苷酸分子),其可衍生自任何来源,能够与基因组整合或自主复制,其可以以可操作的方式连接一个或多个多核苷酸分子。本申请中,构建体通常包含本申请的多核苷酸分子,其可操作地连接至转录起始调节序列,这些序列会导引本申请的多核苷酸分子在宿主细胞中的转录。可使用异源启动子或内源启动子导引本申请的核酸的表达。
“载体”是指任何重组核酸构建体,该构建体可用于转化的目的(即将异源DNA引入到宿主细胞中)。载体可以包含用于在细菌中生长的细菌抗性基因和用于在生物体中表达目的蛋白质的启动子。某些载体能够在引入它们的宿主细胞中自主复制(例如,具有在宿主细胞中起作用的复制起点的载体)。其他载体可以引入宿主细胞后整合到宿主细胞的基因组中,并因此与宿主基因组一起复制。此外,某些优选的载体能够指导与它们连接的外源基因的表达。一种类型的载体是“质粒”,其通常是指可以连接入另外的DNA区段(外源基因)的环状双链DNA环,也可以包括线性双链分子,诸如从通过聚合酶链式反应(PCR)的扩增或用限制酶处理环状质粒得到线性双链分子。
质粒载体包括载体骨架(即空载体)与表达框架。
术语“表达框架”是指具有编码蛋白质潜能的序列。
术语"宿主细胞"指的是能够将目的基因导入,并为目的基因克隆和/或表达提供条件的细胞,诸如微生物。
术语“重组菌”指的经过基因工程改造的菌(如细菌、酵母菌、放线菌等),这意味着它们的菌体中引入了外源基因片段,其中,改造的一种方式包括菌体基因组被引入新的DNA片段后发生了改变,另一种方式包括菌体中引入了经过人工构建或改造过的质粒,从而使菌体获得表达目的基因的能力。
本申请第一方面提供了一种生物合成诺卡酮的方法,其包括采用能够表达瓦伦烯合成酶、细胞色素P450氧化酶、细胞色素P450氧化还原酶和醇脱氢酶的重组菌合成诺卡酮;其中,所述瓦伦烯合成酶、细胞色素P450氧化酶、细胞色素P450氧化还原酶和醇脱氢酶来自益智。
益智(拉丁学名:Alpinia oxyphylla Miq.),别名:益智仁、益智子。姜科,山姜属多年生草本植物。发明人通过对益智的深入研究,从益智中鉴定出参与诺卡酮合成的全套酶和编码基因,并基于此提供了一种生物合成诺卡酮的方法。其中,实施瓦伦烯合酶能够以法尼基焦磷酸为底物,合成瓦伦烯;瓦伦烯在细胞色素P450氧化酶和细胞色素P450氧化还原酶的共同作用下生成诺卡醇,再在醇脱氢酶的作用下得到诺卡酮。
在一些实施方式中,所述瓦伦烯合成酶具有与SEQ ID NO.1所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列;
所述细胞色素P450氧化酶选自细胞色素P450氧化酶CYP6、细胞色素P450氧化酶CYP9和细胞色素P450氧化酶AoKo的至少一种;其中,细胞色素P450氧化酶CYP6具有与SEQID NO.2所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列;细胞色素P450氧化酶CYP9具有与SEQ ID NO.3所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列;细胞色素P450氧化酶AoKo具有与SEQ ID NO.4所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列;
所述细胞色素P450氧化还原酶具有与SEQ ID NO.5所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列;
所述醇脱氢酶具有与SEQ ID NO.6所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
在一些实施方式中,所述瓦伦烯合成酶YZT3的氨基酸序列如下所示(氨基末端至羧基末端):
MEKQSVTLVRDDQGIVRKSTKYHPSVWGDYFIRNSPLNLSEESTQRMIERVEELKVQVKSMFKGTSDVLQIMNLIDSIQLLRLEYHFENEIDGALRLIYEVDDKNYGLYETSLRFRLLRQHGYNVSADTFNKFKDENGSFISILNGDAKGLLSLYNASYLATHGETILDEANNYTKSQLVSLLSELEQPLATQVSLFLEAPLCRRMKSILARKYIPIYEKEAMRSDDILELAKLDFNLLQSLHQEELKKASIWWNDLALAKSLSFTRDRIVEGYYWILSMCYEPQYSRARVMCAKAFCLLSIMDDIYDNYSILEERRLLTEAIKRWNHEAVDSLPEYIKDFYLKLLKAFEEFEAELEFNEKYRVQYLQNEFKAIAISYFEESKWCVERYVPSLDEHLRVSMITSGCSMVVCSMYLGMGEVATKEIFDWCSSFPKAMEASGVIARLLNDIRSHETEQGRDHAASTVESYMKEHGVDVKVARKKLQEIVEKAWKDLNKELLNPTPVARPIIERILNLTMSMEDIYRYIDEYTSPDNKTNGDVSLVLVESIPI*(SEQ ID NO.1)
在一些实施方式中,所述细胞色素P450氧化酶CYP6的氨基酸序列如下所示(氨基末端至羧基末端):
MAEVQLTPLLLIFLLLFLFLFLFLIGTERKLFSNSRGARLPPGPSKLPVIGNLHQLCGGLPHRVLRDLAGIHGPLMLLRLGQVDLAVVSSRNAVLQVTKIHDLNFAHRPQLLAPSKICYGCSDVAFSSYGDYWRQMRRICATDLFTAKRIKSFSAIRAEEVAKLLRDAEAAAAAGQPMNLNYKLTAISNSIVTRASFGFKFDNQHAFIETMKGAILLASGFCAADLFPSLKFVASICGLTSKLKMLHCKVDEILDATIKKHQSSKSEGDEENLLDVLLRLKDDGTLESPITFDNIKAVILDVFTGGTETSSTIVEWTMSELIRNPSAMAKAQGEVREAMMRRQSRDFDEEVIGELHYLKLVIKESLRLHPPLPLLVPRVAKEACQVLDYEVPAGTRVVINAWALGRDPLYWGADAERFRPERFEDGEVDYKGGHLEFIPFGAGRRICPGMRFGMATVELVLAQLLFHFDWELPGGGEGNTAAEELDMAEAFGATVVRKEELRLVPVLRYPLPPAA*(SEQ IDNO.2)
在一些实施方式中,所述细胞色素P450氧化酶CYP9的氨基酸序列如下所示(氨基末端至羧基末端):
MEAFTLKLIILFFAPLLLFLLFLRRSHGRRRGHGKPLPPGPFNLPVIGSLHHLLGPLLHQTLASMSQRYGPAILLKFGHVTTLVISSVEAAAEIMKTHDVSFATRPVIHSAKMIAYGGDGIVFAPYGTSWRELRKMSMVELLSAKRVQYFRYIREDEVLKFMRSITLAPQSVNLSSSFKVLANDIAARAIIGSKCQYQQEFLRLIMKGLQEAGGFNLADLYPSSPLLGLLSRLLSSKMQQLHLEVDAILDGIIKEHRQRSKTFAEQSAEEDMVDTLLKVQAEGSLPFPLTDLSIKAMIFDLFAAASETTSTTMEWAMSELMKNPVAMKQAQEEVRRVVGSKGKVTEDHVGEMSYLKQAVRESLRLHPPLPLLLPRECQEAMEVMGYWIPAKTRVLVNAWALARDPRYWDDATEFKPERFAAGGRSCGVDMKGTNLELIPFGAGRRMCPGSTFGMASVELVLACLLYYFDWEMPVPGDGGAAKKPTELDMEEQFILACHKKTQLRLRAIPRI*(SEQ ID NO.3)
在一些实施方式中,所述细胞色素P450氧化酶AoKo的氨基酸序列如下所示(氨基末端至羧基末端):
MISTAFASVAAAIFTVFILIRFRRRSRVSNLPPAVPGLPLIGNLLQLKDKKPHQTFTKWAQIYGPIYTIKTGASTMVVLNSTEVAKEAMVAKYSSISNRKLSKALTLLTSNKRMVAMSDYGEFHKMVKRYILTSLLGANAQKQNYGIRETLINNVVKFLYSDLSDNPNDAVNLRKSFQPELFRLAMKQALNLEPESIYVEELGRELSKEEIFNVLVVDPMMGAIEVDWRDFFPYLRWVPNRSFENKLKRMLMRRAAVMQVLITKRKNSKQSKEEISCYLDFLLSQGTLTDEEIISLVWEAVIESSDTTLVTTEWAMFELSKNPNKQERLYQEIQQVCGSENVTDEHLSRMPYLNCVFHETLRRHSPVPIVPLRYAHEDTQIGGFNILAGSEIAINLYGCNMDKMQWDEPNEWKPERFIDSKYEQMDSYKTMAFGAGKRICAGSLQASSIACTAIGRLVQEFEWRLKEGEEANVVTVQLTNLKLEPLLAYIKPRSTNDACL*(SEQ ID NO.4)
在一些实施方式中,所述细胞色素P450氧化还原酶AoCPR的氨基酸序列如下所示(氨基末端至羧基末端):
MQTDSGKASPLDLLSAVVASLSGGDGLDLGAGNPSVEYRRLIAVLSTVVAVLVGCAAIFFFRRSSGKKPAEPPKPLAVKTQLDAEEDQGKKKVTVFFGTQTGTAEGFAKALAEEAKARYPNAIFKVVDIDEYATEDDEYEENLKKESLVLFFLATYGDGEPTDNAARFYKWFTEGKERVTWLENLQFSVFGLGNRQYEHFNKVAKVVDELLQEQGAKRIVQVGLGDDDQCIEDDFSAWRELLWPELDKLLQDENETGASTPYTAAVPEYRVVFVKPEEVPYLDKSLSFANGHAIHDIQHPCRANVAVRRELHTSASDRSCIHLEFDIDGTGLVYGTGDHVGVFADNCSEIVEEAAKLLGYSPDTYFSIHTDKEDGTPLGGSLSPPFPSPCTLKTALTRYSDVLNSPKKSALLALAAHATDLSDAERLKFLASPIGKDEYSQWIVANQRSLLEVMAEFPSAKPPLGVFFAAIAPRLQPRYYSISSSPRMAPSRIHVTCALVYEKTPTGRIHKGVCSTWMKNSISLEENQECSWAPIFVRQSNFKLPVDPSVPVIMIGPGTGLAPFRGFLQERLALKKEGLELGHSILFFGCRNRKMDFIYEDELNNFVETGVLSEFIVAFSREGPTKQYVQHKMTEKASELWNIISQGGYVYVCGDAKGMARDVHRVLHTIVQEQGGMDSSKTESFVKSLQMEGRYSRDVW*(SEQ ID NO.5)
在一些实施方式中,所述醇脱氢酶AoADH的氨基酸序列如下所示(氨基末端至羧基末端):
MASSFVLSSVAKRLEGKVTLITGGASGLGECTAKLFARLGARVVVADIQDDKGRALCDSLGPDTASYVHCDVTKEPDVASAVDAAVARHGKLDVMFSNAGVGEVLQKSLPDCEVADFQRLMSVNVTGVFLATKHAARVMTPARRGSIVITGSTTSTIGGLGPHAYTCSKHAVVGLMRSAAVELGRHGVRVNCVSPHGMATPMTMAAFDLDKEGVEAMFERSANLKGVRLEAEDVAEAVAYLAGDESRYVSGVNLLVDGGFTIAKGLA*(SEQ ID NO.6)
在一些实施方式中,所述重组菌能够合成法尼基焦磷酸。
在一些实施方式中,所述重组菌能够表达乙酰乙酰辅酶A硫解酶、羟甲基戊二酰辅酶A合酶、羟甲基戊二酰辅酶A还原酶、甲羟戊酸激酶、甲羟戊酸-5-磷酸激酶、甲羟戊酸焦磷酸脱羧酶、异戊二烯焦磷酸异构酶、法尼基焦磷酸合酶的至少一种。
在一些实施方式中,所述羟甲基戊二酰辅酶A还原酶为截短的羟甲基戊二酰辅酶A还原酶,其截去了内质网定位序列,增强了酶在细胞质中的稳定性。
发明人发现,乙酰乙酰辅酶A硫解酶、羟甲基戊二酰辅酶A合酶、羟甲基戊二酰辅酶A还原酶、甲羟戊酸激酶、甲羟戊酸-5-磷酸激酶、甲羟戊酸焦磷酸脱羧酶、异戊二烯焦磷酸异构酶属于甲羟戊酸途径中的酶,甲羟戊酸途径可以合成异戊烯基二磷酸(IPP)和二甲基烯丙基二磷酸(DMAPP),二者可以作为前体,在法尼基焦磷酸合酶的催化下合成法尼基焦磷酸(FPP),而FPP是生物合成诺卡酮的底物,因此,当所述重组菌能够表达甲羟戊酸途径中的酶和法尼基焦磷酸合酶的至少一种时,有利于FPP的合成,进而有利于诺卡酮的生物合成。
本申请第二方面提供了一种用于诺卡酮合成的酶,其具有与SEQ ID NO.1、SEQ IDNO.2、SEQ ID NO.3、SEQ ID NO.4、SEQ ID NO.5或SEQ ID NO.6所示的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性的氨基酸序列。
本申请第三方面提供了一种多核苷酸分子,其包含编码本申请第二方面的酶的核苷酸序列或其互补序列的至少一种。
在一些实施方式中,所述多核苷酸分子包含与SEQ ID NO.7、SEQ ID NO.8、SEQ IDNO.9、SEQ ID NO.10、SEQ ID NO.11、SEQ ID NO.12或SEQ ID NO.13所示的核苷酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性的核苷酸序列。
在一些实施方式中,编码瓦伦烯合成酶YZT3(野生型)的核苷酸序列如下所示(5’末端至3’末端):
atggagaaacaatcagtaactctcgtgcgtgatgaccaagggatagttcgtaagtcgacaaaatatcatccaagcgtttggggtgattatttcatccgaaactcgcctctcaatctatcagaggagtccactcaaaggatgatagagagagtagaagaattaaaggtgcaagtaaagagcatgttcaagggcaccagtgacgtattgcagattatgaacttgattgattcaattcaacttctaagactagaatatcattttgagaatgaaatagatggtgcactaagattgatctatgaggtcgacgacaagaactatggactttatgaaacttctcttagatttcgattgcttaggcaacatggatataatgtttctgcagatacctttaacaagttcaaagatgagaatggaagctttatatctatcttgaatggagatgcaaagggattactaagcttatataatgcatcttaccttgcaacgcatggagagactatacttgatgaagccaataattatacaaagtctcagctagtatccttattgagtgaacttgaacaacctttagcgacacaagtatcacttttccttgaagcgcccctatgtcgaagaatgaaaagtatcttggcaagaaaatatatacctatttatgaaaaggaagcaatgcgaagtgatgacatattagaacttgcaaaattggatttcaatctactgcaatctcttcatcaagaggagttgaagaaagcttcgatatggtggaatgatttagcccttgctaaatctctaagttttactcgtgatcgaatcgtggaaggttattattggattcttagtatgtgttatgagcctcaatattctcgtgcacgagtgatgtgcgccaaagcattttgtcttctatcaattatggatgatatttatgacaactatagcatattggaagagcgcagattattaactgaggcaataaagaggtggaatcatgaagctgttgattctttaccagaatatataaaagatttttatctgaagctattaaaggcttttgaagaatttgaagcggaattggaatttaatgagaagtatcgtgtgcaataccttcaaaatgaatttaaagctatagccatatcatattttgaagaatccaagtggtgtgtggaaagatatgtgccgtcactcgacgaacacttgcgtgtttctatgatcacctctggatgttctatggtcgtttgttctatgtatcttggtatgggagaagtggcaacaaaagagattttcgattggtgttctagttttcccaaggcaatggaagcaagcggtgtaattgctagactcctcaatgatataagatcacacgagactgagcaagggagagaccatgctgcctctacagtggaaagttacatgaaagagcacggcgtagatgtaaaagttgcacgcaagaagctacaagagatagtggagaaagcgtggaaggatctaaataaggaacttctcaaccccacaccagtagctcgacctataattgaaagaatactcaaccttacaatgtcaatggaagacatatataggtacattgacgagtacaccagtcctgataataagacgaacggtgatgtctccttggtgttggttgaatctattcctatatga(SEQ IDNO.7)
在一些实施方式中,通过对野生型瓦伦烯合成酶YZT3的核苷酸序列按照酿酒酵母密码子偏好性优化后,得到瓦伦烯合酶的编码基因AoVS的核苷酸序列如下所示(5’末端至3’末端):
atggaaaagcaatctgttacattggttagagatgatcaaggtattgttagaaaatctacaaagtaccatccatctgtttggggtgattattttattagaaactctccattgaacctgtctgaagaatctactcaaagaatgattgaaagagttgaagaattgaaggttcaagttaaatctatgttcaagggtacatctgatgttttgcaaattatgaatctgatcgattctatccaattgttaagattagagtaccatttcgaaaacgaaattgatggtgctttaagattaatctacgaagttgatgataagaactacggtttgtatgaaacatctttaagattcagactgttgagacaacatggttataatgtttctgctgatacttttaacaagttcaaagatgaaaacggttcttttatctctatcttaaacggtgatgctaaaggtttgttatctttatataacgcttcctatctggctacacatggtgaaacaattttagatgaagctaataactacaccaagtctcaattagtttctttgttgtctgaattggaacaaccattagctactcaagtttctttatttttggaggctccattatgtagaagaatgaaatctattctggctagaaaatacatcccaatttatgaaaaggaggctatgagatctgatgatattttggaattggctaaattggatttcaacttattgcaatctctgcatcaagaagaattaaaaaaggcttctatctggtggaatgatttggctttagctaaatctttgtcttttacaagagacagaatcgttgaaggttattattggattttgtctatgtgttacgagccacaatattctagagctagagttatgtgtgctaaagctttttgtttattgtctatcatggacgatatctatgataattactctatcttggaggaaagaagattgttaacagaagctattaagagatggaatcatgaagctgttgattctttgccagaatatattaaagacttctacttgaagctgttgaaagcttttgaagaatttgaagctgaattggaattcaatgaaaagtatagagtccaatacttgcaaaatgaattcaaagctatcgctatttcttactttgaagaatctaagtggtgtgttgaaagatatgttccatctttggatgaacatttgagagtttctatgattacttctggttgttctatggttgtttgttctatgtatttgggtatgggtgaagttgctacaaaagaaatttttgattggtgttcttccttcccaaaagctatggaagcttctggtgttattgctagattattaaatgacatcaggtcacatgaaacagaacaaggtagagatcatgctgcttctacagttgaatcttatatgaaagaacacggtgttgatgttaaagttgctagaaaaaaactgcaagaaatcgttgaaaaggcttggaaagatttgaataaagaattgttgaaccccacaccagttgctagaccaattattgaaagaattttgaacctgactatgtctatggaagatatttatagatacatcgacgaatacacatctccagataataaaacaaacggtgatgtttctttggttttggttgaatctatcccaatttaa(SEQ IDNO.13)
在一些实施方式中,编码细胞色素P450氧化酶CYP6(野生型)的核苷酸序列如下所示(5’末端至3’末端):
atggcggaggtccaactcactcccctcctcttaatcttcctcctcctcttcctgttcctcttcctcttcctcatcggcacagagaggaagcttttctccaactccagaggagctcgcctcccgcccggtccgtcgaagctacccgtcattggcaacctgcaccaactttgcggcggcctaccccaccgtgtcctgcgcgacctcgccggcatccacggccccctcatgctcctccgccttggccaggtcgacctcgccgtcgtatcctcccgaaatgccgtcctgcaggtcaccaagatccacgacctcaacttcgcccatcgcccccagctcctggccccttccaaaatctgctacggctgctccgacgtcgccttctcttcctacggagactactggcgccagatgcgcaggatctgcgcaaccgatctcttcaccgccaagcgcatcaagtcattctctgccatccgcgcagaagaggtcgccaagctcctccgcgacgccgaggcggcagcggctgccggccagccgatgaacttgaactacaagctcacggcgatctcgaacagcatcgtgacccgcgcctctttcggtttcaaattcgataaccagcacgcgttcatcgagaccatgaagggggcgatactgctcgcgtcggggttttgcgccgcggatctgttcccgtctttgaagttcgtggcctcgatctgcggcctcacctccaagctgaagatgcttcactgcaaagtggatgaaattctcgacgcgaccatcaaaaagcaccaatcgagcaagagcgaaggggacgaagagaatctcctcgacgttctacttcgtctaaaagacgacggaaccctggaatccccaatcacattcgacaacatcaaagctgtgattttggacgtcttcacgggagggacggagacctcgtcgacgattgtagaatggacgatgtcggagctcatcaggaaccctagcgcgatggcgaaggcacaaggggaagtgcgagaagcgatgatgcgaaggcaaagcagggatttcgacgaggaagtcatcggcgagctccattacctgaagctagtgatcaaggagagtctgaggctacacccgccgctaccactgttggtgccgagggtggcgaaggaggcgtgccaggtgctggactacgaggtgccggcgggcacgagggtggtgatcaacgcctgggccctagggagggacccgctctactggggcgccgacgccgagcggttccggcccgagaggttcgaggacggtgaggtggactacaaggggggccacctggagttcattccattcggcgccgggaggaggatatgccccgggatgagattcgggatggcgacggtggaactcgtattggcgcagctgctgttccacttcgactgggagctaccaggaggaggagaagggaatacggcggcggaggaactggacatggcggaggcattcggggcgaccgtggtgaggaaggaggagctccgcctggttccggtgcttcgatatcccctgccgcccgctgcttag(SEQ ID NO.8)
在一些实施方式中,编码细胞色素P450氧化酶CYP9(野生型)的核苷酸序列如下所示(5’末端至3’末端):
atggaagcttttaccttgaagcttatcattctcttcttcgcccccctcctcctcttcctcctcttcctcaggcgcagccatggccgacggcggggccacggcaagcctctccctcctggcccattcaacctccccgtcatcggcagcctgcaccacctcctcggcccgttgctgcaccagacgctcgcgtctatgtcccagcgatacggccccgccatcctcctcaagttcggccatgtcaccaccctcgtcatctcctccgttgaggccgccgcagagatcatgaagacccatgacgtcagcttcgccacgcgtcccgtcatccattcagccaagatgatcgcctacggcggcgacggtattgtcttcgcgccatacggcaccagctggcgcgagctccgcaaaatgagcatggtggagctcctcagtgccaagcgcgtccagtacttccgctatatccgcgaggatgaggtgcttaaatttatgcgctccattacgttggcaccccaaagcgtgaatcttagtagcagttttaaggtgctcgcgaacgacatcgcggcgagggccatcattgggagcaagtgccagtatcagcaggagttcctgcggctgataatgaaggggctccaagaagcggggggattcaacttggccgacttgtacccgtcgtcgccgctcctcgggttgctcagccgcttgttgtcttccaagatgcagcagctgcacctcgaggtggatgccatcttggatggcatcatcaaggagcacagacagaggagtaaaacgttcgcagagcagagtgcagaggaggacatggtggataccctgctcaaggttcaagcggaaggcagccttccgttccccctcacggacttgtccatcaaagctatgatttttgatctttttgcagcggcgagcgagaccacctctacgaccatggaatgggcgatgtcggagctgatgaagaatccggtggcgatgaagcaggcgcaggaggaagtgaggcgggtggtgggaagcaaggggaaagtcaccgaagatcacgtcggcgagatgagttacctcaagcaggcggtaagggagtcgctgaggcttcaccctcccctgcctctgttgctgccgcgggagtgccaggaagcgatggaggtgatgggctactggattccggcgaagacgagggtgctggtgaacgcgtgggcgctggcgagagacccaaggtattgggacgacgccacggagttcaagccagagaggttcgccgctggtgggaggagctgcggggtggacatgaaaggcaccaacttggagctcataccgttcggggcgggtagaaggatgtgccctggtagcacgttcggaatggcgagcgtggagctggtgcttgcttgccttctctattactttgactgggagatgccggtcccgggcgacggaggagcggcgaagaaaccgacggagttggacatggaagaacagttcatactggcgtgtcataagaagacgcagcttcgcttgcgcgcgatccctcgtatatag(SEQ ID NO.9)
在一些实施方式中,编码细胞色素P450氧化酶AoKo(野生型)的核苷酸序列如下所示(5’末端至3’末端):
atgatttccacggccttcgcaagtgtcgctgccgccatcttcacggttttcatcctcatcaggttccgacgccgcagtcgcgtttccaatcttccgccggctgtccccgggcttcccttgattgggaatttgctccagctgaaggacaagaaacctcaccagacattcacgaaatgggcgcagatatatggcccgatttataccatcaagacgggcgcttccactatggtagtcctgaattctactgaggttgccaaagaggcaatggtggctaagtattcatccatctcaaatcggaaattgtcaaaggcattgacattgctcacttcaaataaacgtatggttgctatgagtgactatggagagttccacaaaatggtgaaacggtacatattgactagtttgttaggtgcaaatgctcagaagcaaaactatggtatcagggagacgttgattaataatgtcgtcaaatttctatattcggatttaagcgataaccctaatgatgcagtaaacctcagaaagtcatttcaacctgagttattccgattagccatgaagcaagctttgaacctggaacctgaatccatttatgtagaggaacttgggagggaactttcaaaggaagaaatattcaatgtgttggtggtagaccctatgatgggcgccattgaggtggactggagggactttttcccttacttgagatgggtccctaatcgaagctttgaaaataagctaaagagaatgctcatgcgcagggcggcagtgatgcaggttctgattacaaaaagaaagaacagtaaacaatccaaagaggagataagctgctatttggactttctgctatcccagggcactttgactgacgaagagataatatcgttagtatgggaagcggtaattgagtcatcggatacaactttagtcacaacagaatgggctatgtttgagctatctaagaatccaaataaacaggaacgtctttaccaagaaattcaacaagtatgtggatctgaaaacgtcaccgatgagcatttgtcacggatgccctacttgaactgtgtgttccatgagaccctaagacgtcattcccctgttcctatagtacctctcaggtatgcccatgaagatacccagatcggaggattcaacatccttgcggggtctgagattgccatcaatctttatggatgcaatatggacaagatgcagtgggatgaacctaatgaatggaagcctgagagattcatagacagcaaatatgagcaaatggactcgtataagactatggcctttggagctggaaagaggatttgtgccggatctctgcaggcatcgtcgattgcatgcactgccatcgggcgtttagtgcaagagttcgagtggaggctgaaggaaggagaagaggctaatgtcgtcactgttcagctcacaaaccttaagcttgaacctctgcttgcatacataaagcccagaagcaccaacgatgcatgcctttga(SEQ IDNO.10)
在一些实施方式中,编码细胞色素P450氧化还原酶AoCPR(野生型)的核苷酸序列如下所示(5’末端至3’末端):
atgcagacggattccgggaaggcttcgccgctcgatctcttgtcggctgtcgtcgcctcgctatccggtggagatgggctcgatttaggcgccgggaatccctcggtggagtaccggcggctgatcgccgtcctgagtactgtcgtcgccgtgctagttggctgcgcggcgatattcttcttccggagatcgagcggaaagaagccggccgagccgccgaagccgctggcggttaagactcagctggatgcggaggaggaccaagggaagaagaaggtcaccgtcttcttcggcacgcagaccgggacggccgaggggtttgcgaaggcgctggctgaggaggccaaggcacggtaccctaatgccatatttaaagtcgtggatatcgacgaatatgctactgaggacgatgagtacgaggagaacctgaaaaaggagagcttggttttgttcttcttggctacgtatggagatggcgagcctactgataatgctgcccggttctacaaatggtttacagaggggaaagagagagtaacctggttggaaaatcttcaattttctgtgtttggtttgggcaatcggcaatatgaacattttaataaggttgctaaggtagttgatgaactgcttcaagagcaaggtgccaaacgcattgtccaagtgggattgggagatgatgatcagtgtattgaggatgacttctctgcatggagggaacttctttggccggagttggataagttgcttcaggacgaaaatgagacaggtgcatctactccttatacagctgctgttcctgaataccgggttgtatttgtcaagccagaagaagttccatatctggataaaagtttgagttttgcaaatggccatgctattcatgacatacaacatccatgcagggctaatgtggctgtgagacgagagcttcatacttcagcttcagaccgatcctgcatccacttggagtttgacatagatggcactggccttgtgtacggaacaggagaccatgttggtgtattcgcggacaactgttctgagattgtagaggaggctgcaaagttgttaggttattcacctgacacatatttctctattcatactgacaaggaggatggcacgccacttggaggctctttgtcacctcctttcccatctccatgcactctcaaaaccgctcttactcgatactctgatgttctaaattcacctaaaaagagtgcattacttgcccttgccgcacacgcaacagatcttagtgatgctgagcgacttaaatttttggcttctcctattggaaaggatgaatattctcaatggattgttgctaatcagaggagtcttcttgaagtcatggccgaatttccctctgcaaagcctcctctaggagtcttctttgccgcaatagccccacgtttgcagccaagatattattcaatttcctcttctccgaggatggcacctagtagaattcatgtgacttgtgcattagtttatgaaaagacaccaactggcaggattcataaaggggtttgttccacctggatgaagaattccatttcgctcgaagagaaccaagaatgcagctgggctcctatttttgtgaggcagtctaactttaaactccctgttgatccttcggtacctgtcatcatgattggaccgggcacagggttggcacctttcaggggcttcttacaggaaaggttggcattgaaaaaggaagggttggaacttggtcattctattctcttcttcggatgcagaaaccgcaaaatggacttcatctacgaggatgagttgaacaactttgtcgaaacaggcgtgctttccgagtttattgtggccttctcccgtgagggtccaactaaacaatatgtgcaacacaaaatgaccgagaaagcatcagaactttggaatatcatctcccaaggtggatatgtatacgtgtgtggagatgctaagggcatggctagagatgttcacagagttcttcatactattgttcaagagcagggaggtatggatagctccaaaacagaaagcttcgtcaagagcttgcaaatggaagggagatattcaagggatgtatggtga(SEQ ID NO.11)
在一些实施方式中,编码醇脱氢酶AoADH(野生型)的核苷酸序列如下所示(5’末端至3’末端):
atggcaagctcctttgttctctcctctgtagcaaaaaggctcgaagggaaggtgacattgatcaccggcggggcgagcgggctcggcgagtgcaccgccaagctgttcgcccgcctcggcgcccgagtagtcgtcgcagacatccaagacgacaaaggccgcgccctgtgcgactcactcggccccgacaccgcctcctacgtccactgcgacgtcaccaaggagcccgacgtggcaagcgccgtcgacgccgccgtcgcccgacacgggaagctcgacgtcatgttcagcaacgccggagtcggggaagtgttgcagaagtcgttgcccgactgcgaggtggctgacttccagcgattgatgtcggtgaacgtgacgggggtgttcctggccaccaagcacgcggcgcgggtgatgacgccggcgaggcgggggagcatcgtgatcacggggagcaccacgtcgactattgggggactagggccgcacgcatacacgtgctcaaagcacgcggtggtggggctaatgaggagcgcggcggtcgagctgggcaggcacggtgttcgggtcaactgcgtgtcgccgcacgggatggcaacgccgatgacgatggcagcgtttgacttagacaaggagggggttgaggccatgtttgagaggtcggccaacctgaaaggtgtgaggctcgaagcggaggacgtggcggaggcagtggcgtacctcgccggcgacgagtccaggtatgtgagcggcgtcaatctgctggtggacggaggcttcaccattgccaagggattggcgtag(SEQ ID NO.12)
本申请第四方面提供了一种核酸构建体,其包含本申请第三方面的多核苷酸分子的至少一种。本申请中,将连接入所述核酸构建体的多核苷酸分子称为目的基因,将所述多核苷酸分子编码的酶称为目标蛋白。
在一些实施方式中,所述核酸构建体中还包含调控编码目的基因表达的调控元件,例如启动子、终止子等,示例性的,所述启动子可以为组成型启动子如P
在一些实施方式中,所述核酸构建体中还包含用于筛选包含目的基因或目标蛋白的重组菌的标记基因,例如亮氨酸筛选标记、组氨酸筛选标记、色氨酸筛选标记、尿嘧啶筛选标记等,本领域技术人员可根据需要具体选择,本申请在此不做限定。
在一些实施方式中,所述核苷酸序列位于两个插入元件之间,所述插入元件用于将所述核苷酸序列整合入宿主细胞的基因组中。
在一些实施方式中,两端连接有插入元件的核苷酸序列连接于核酸构建体,例如质粒载体的质粒骨架中,所述核酸构建体用于向宿主细胞导入目的基因时,可以通过限制性内切酶等工具,将所述核酸构建体酶切,从而获得两端连接有插入元件的线性化的目的基因片段,通过将所述线性化的目的基因片段导入宿主细胞中,使其通过两端的插入元件插入宿主细胞基因组的相应位置,从而获得本申请的重组菌。
本领域技术人员可采用常规的方法将线性化的目的基因片段导入宿主细胞中,例如对于酵母菌,可采用醋酸锂法,对于大肠杆菌,可采用钙转法等,此为本领域的常规操作,本申请在此不做限定。
在一些实施方式中,所述两个插入元件成对出现,例如可以是leu2的左右同源臂、Ura3的左右同源臂、YPRCdelta15左右同源臂等,不同基因的同源臂可以将目的基因整合入宿主细胞基因组的不同位置,本领域技术人员可根据希望整合入宿主细胞基因组的位置具体选择同源臂的种类,本申请在此不做限定。
在一些实施方式中,所述两个插入元件之间还包括用于调控目的基因表达的启动子、终止子等调控元件。本申请对所述启动子和终止子的种类不做限定。
在一些实施方式中,所述核酸构建体还包含编码乙酰乙酰辅酶A硫解酶(ERG10)、羟甲基戊二酰辅酶A合酶(ERG13)、羟甲基戊二酰辅酶A还原酶(HMG1)、截短的羟甲基戊二酰辅酶A还原酶(tHMG1)、甲羟戊酸激酶(ERG12)、甲羟戊酸-5-磷酸激酶(ERG8)、甲羟戊酸焦磷酸脱羧酶(MVD1)、异戊二烯焦磷酸异构酶(IDI1)、法尼基焦磷酸合酶(ERG20)的核苷酸序列的至少一种;其中括号中显示了编码这些酶的基因名称。
编码以上酶的基因的示例性而非限制性的公开如下:
ERG10(Accession/GENE ID:856079)、ERG13(Accession/GENE ID:854913)、tHMG1(Accession/GENE ID:854900,截去4-1659bp)、ERG12(Accession/GENE ID:NM_001182715.1)、ERG8(Accession/GENE ID:CP046093.1,689693..691048)、MVD1(Accession/GENE ID:NM_001183220.1)、IDI1(Accession/GENE ID:NM_001183931.1)、ERG20(Accession/GENE ID:853272)。
在一些实施方式中,所述核酸构建体为质粒载体;优选地,所述质粒载体为真核表达载体。
在一些实施方式中,所述的核酸构建体包括pRS426质粒骨架。发明人发现,pRS426质粒骨架中包含适用于大肠杆菌的AmpR筛选标记,适用于酿酒酵母的URA3筛选标记,以及适用于大肠杆菌的复制子和酿酒酵母的多拷贝复制子,采用所述pRS426质粒骨架有利于含有目的基因的质粒在导入酿酒酵母中后维持质粒的高拷贝。
在一些实施方式中,所述pRS426质粒骨架中存在的突变,所述突变消除了pRS426质粒骨架中的酶切位点BsaI,从而可以在使用Goldengate方法构建载体时,以BsaI作为限制性内切酶。
在一些实施方式中,所述的核酸构建体包括pESC-TRP质粒骨架。发明人发现,pESC-TRP质粒骨架中包含适用于大肠杆菌的AmpR筛选标记,适用于酿酒酵母的TRP1筛选标记,以及适用于大肠杆菌的复制子和酿酒酵母的多拷贝复制子,采用所述pESC-TRP质粒骨架有利于含有目的基因的质粒在导入酿酒酵母中后维持质粒的高拷贝。
在一些实施方式中,所述质粒载体为pDXYZ3、pDXVS1、pDXVS2、pDXNL1、pDXNL2、pDXNL3、pDXNT1的至少一种,所述质粒载体的构建示意图如图2、图3、图4或图5所示;其中,质粒pDXYZ3的构建示意图如图2所示,质粒pDXVS1、pDXVS2的构建示意图如图3所示,质粒pDXNL1、pDXNL2、pDXNL3的构建示意图如图4所示,质粒pDXNT1的构建示意图如图5所示。
在一些实施方式中,可以将所述质粒载体直接导入宿主细胞中,也可以通过酶切所述质粒载体,获得包含插入元件的目的基因片段,进一步将所述基因片段整合入所述宿主细胞的基因组中。
本申请第五方面提供了一种重组菌,其包含本申请第三方面的多核苷酸分子,或本申请第四方面的核酸构建体;所述重组菌通过将所述多核苷酸分子或所述核酸构建体导入宿主细胞中获得;优选地,所述宿主细胞为真核细胞;更优选为酿酒酵母。
在一些实施方式中,所述重组菌中可以直接包含所述核酸构建体,例如,所述核酸构建体以质粒的形式单独存在于宿主细胞中,表达合成诺卡酮所需的酶。
在另一些实施方式中,所述多核苷酸分子整合入所述宿主细胞的基因组中。所述多核苷酸分子整合入所述宿主细胞的基因组中,有利于所述目的基因的长期稳定表达,从而获得能够稳定遗传的重组菌。
本领域技术人员可采用常规的方法将多核苷酸分子整合入所述宿主细胞的基因组中,本申请在此不做限定,例如可以将目的基因连接于两个插入元件之间,通过插入元件将所述目的基因插入宿主细胞的基因组中,示例性的,所述插入元件可以为leu2的左右同源臂、Ura3的左右同源臂、YPRCdelta15左右同源臂,不同基因的同源臂用于将目的基因插入宿主细胞基因组的不同位置,发明人发现,将目的基因插入不干扰宿主细胞正常生理代谢的位点,均能够获得本申请的重组菌。
在一些实施方式中,所述多核苷酸分子在所述重组菌的基因组中的拷贝数至少1个,优选至少2个,更优选至少3个。增加所述多核苷酸分子的拷贝数,有利于其编码的酶的高表达。
在一些实施方式中,所述重组菌能够表达乙酰乙酰辅酶A硫解酶、羟甲基戊二酰辅酶A合酶、羟甲基戊二酰辅酶A还原酶、甲羟戊酸激酶、甲羟戊酸-5-磷酸激酶、甲羟戊酸焦磷酸脱羧酶、异戊二烯焦磷酸异构酶、法尼基焦磷酸合酶的至少一种。
发明人发现,酿酒酵母可以内源合成FPP,因此在一些优选地实施方式中,采用酿酒酵母作为宿主细胞,有利于获得高效合成诺卡酮的重组菌。
本申请第六方面提供了本申请第二方面的酶、本申请第三方面的多核苷酸分子、本申请第四方面的核酸构建体或本申请第五方面的重组菌生产瓦伦烯、诺卡醇和/或诺卡酮的用途。
下面通过具体实施例来说明本申请的生物合成诺卡酮的方法及载体。下面的实施例仅用于说明本发明,而不应视为限定本发明的范围。以下实施例中所涉及的质粒均为本领域技术人员公知质粒。实施例中未注明具体技术或条件的,按照本领域内的文献所描述的技术或条件或者按照产品说明书进行。所用试剂或仪器未注明生产厂商者,均为可以通过市购获得的常规产品。
实施例1表达载体和菌株构建
1.1酵母表达通用载体的构建
质粒pZY900具体构建过程:以酿酒酵母S288c基因组(提取方法见:李晓伟.工程乙酰辅酶A通路构建酿酒酵母高效合成平台[D].武汉大学,2015.2.3.6酵母基因组DNA提取方法)为模板,用引物900-1F/1R、900-2F/2R、900-6F/6R、900-7F/7R分别扩增获得片段9001(Leu2的左同源臂)、9002(终止子tTDH2)、9006(基因ERG20与终止子tERG20)、9007(Leu2右同源臂);以酿酒酵母CEN.PK2-1D的基因组(提取方法见:李晓伟.工程乙酰辅酶A通路构建酿酒酵母高效合成平台[D].武汉大学,2015.2.3.6酵母基因组DNA提取方法)为模板,用引物900-3F/3R、900-5F/5R分别扩增获得片段9003(终止子tCYC1)和9005(启动子pGAL1和pGAL10);用引物900-4F/4R以pCAS(见文献Zhang,Yueping et al.“A gRNA-tRNA arrayfor CRISPR-Cas9 based rapid multiplexed genome editing in Saccharomycescerevisiae.”Nature communications vol.10,1 1053.5Mar.2019,doi:10.1038/s41467-019-09005-3)为模板扩增获得片段9004(无义基因lacZ,用于目的基因的替换);以pRS426为模板,用引物900-8F/8R、900-9F/9R、900-10F/10R扩增获得质粒骨架(引入MssI酶切位点,筛选标记(AmpR、URA3等))。通过DNA assemble(又称酵母组装,李晓伟.工程乙酰辅酶A通路构建酿酒酵母高效合成平台[D].武汉大学,2015.)的方法将以上片段在酿酒酵母体内重组构建pZY900,然后在大肠杆菌内扩增,酶切验证以及测序正确后,得到pZY900。质粒pZY900构建示意图见图1,其中,片段9001(HA)、9002(T)、9003(T)、9004、9005、9006、9007(HA)从左至右依次连接,其余部分来自pRS426的质粒骨架。
构建质粒pZY900所用引物的序列见下表1。
表1
1.2不同基因表达载体构建
以益智果的cDNA(采用TIANGEN公司RNAprep Pure Plant Plus Kit试剂盒(货号DP441)提取益智果实组织RNA,使用Vazyme的HiScript II 1st Strand cDNA SynthesisKit(+gDNA wiper)试剂盒(货号R212)对RNA进行反转录获得cDNA)为模板,以引物对P5/P6为引物,利用Takara公司的Prime STAR高保真酶通过PCR扩增益智的cDNA获得基因片段命名为YZT3,经天根胶回收试剂盒胶回收后,通过翊圣公司同源重组试剂盒,采用同源重组的方法连接到BsaI切后的酵母表达通用载体pZY900中,经过测序确认无误后,获得含有YZT3基因的酵母表达载体,命名为pDXYZ3,其质粒构建示意图见图2,其中,以YZT3基因替代了pZY900中的lacZ基因。
引物对P5/P6序列如下表2所示:
表2
使用引物对P7/P8,以合成的AoVS基因(核苷酸序列如SEQ ID NO.13所示)为模板扩增得到AoVS基因片段。采用翊圣公司同源重组试剂盒,将扩增得到的AoVS基因片段连接到BsaI切后的pZY900中,经过测序确认无误后,获得含有AoVS基因的酵母表达载体,命名为pDXVS1,其质粒构建示意图见图3中的pDXVS1,其中,以AoVS基因替代了pZY900中的lacZ基因。
引物对P7/P8序列如下表3所示:
表3
使用引物对P9/P10,以合成的AoVS基因(核苷酸序列如SEQ ID NO.13所示)为模板扩增得到AoVS基因片段。使用引物P11/P12,以质粒pHM001(pHM001的构建见文献Deng etal.“Systematic identification of Ocimum sanctum sesquiterpenoid synthases and(-)-eremophilene overproduction in engineered yeast”.Metabolic Engineering,2022,69:122-133)为模板,扩增包含PKG1终止子(T)、URA同源臂(HA)、载体骨架、HIS3标签、CYC1终止子(T)、tHMG1与pGAL1-pGAL10启动子(P
引物序列如下表4所示:
表4
使用引物对P13/P14,利用Prime STAR高保真酶从益智果cDNA模板中克隆得到CYP6基因;使用引物对P15/P16,利用Prime STAR高保真酶从益智果cDNA模板中克隆得到AoCPR基因;使用引物对P17/P18,利用Prime STAR高保真酶从pESC-TRP质粒中克隆得到pGAL1-pGAL10启动子片段;使用SacI/XhoI双酶切pESC-TRP质粒得到载体骨架。采用翊圣公司同源重组试剂盒,将上述四个片段连接,获得质粒pDXNL1,其质粒构建示意图见图4中的pDXNL1。
引物序列如下表5所示:
表5
使用引物对P19/P20,利用Prime STAR高保真酶从益智果cDNA模板中克隆得到CYP9基因;使用引物对P15/P16利用Prime STAR高保真酶从益智果cDNA模板中克隆得到AoCPR基因;使用引物对P17/P18利用Prime STAR高保真酶从pESC-TRP质粒中克隆得到pGAL1-pGAL10启动子片段;使用SacI/XhoI双酶切pESC-TRP质粒得到载体骨架。采用翊圣公司同源重组试剂盒,将上述四个片段连接,获得质粒pDXNL2,其质粒构建示意图见图4中的pDXNL2。
引物序列如下表6所示:
表6
使用引物对P21/P22,利用Prime STAR高保真酶从益智果cDNA模板中克隆得到AoKo基因(核苷酸序列如SEQ ID NO.10所示);使用引物对P15/P16,利用Prime STAR高保真酶从益智果cDNA模板中克隆得到AoCPR基因;使用引物对P17/P18,利用Prime STAR高保真酶从pESC-TRP质粒中克隆得到pGAL1-pGAL10启动子片段;使用SacI/XhoI双酶切pESC-TRP质粒得到载体骨架。采用翊圣公司同源重组试剂盒,将上述四个片段连接,获得质粒pDXNL3,其质粒构建示意图见图4中的pDXNL3。
引物序列如下表7所示:
表7
使用引物对P23/P24,从益智果cDNA模板中克隆得到AoADH基因片段,通过BamHI/XhoI双酶切获得切后片段,随后与BamHI/XhoI双酶切后的pESC-URA质粒载体利用T4 DNA连接酶进行连接,获得的质粒命名为pDXNT1,其质粒构建示意图见图5。
引物序列如下表8所示:
表8
将使用引物对P15/P16克隆得到的AoCPR基因片段与经EcoRI/SacI双酶切pESC-TRP质粒回收的载体片段进行同源重组,得到pCK质粒,其质粒构建示意图见图4中的pCK。
1.3菌株构建
通过醋酸锂转化法方法将pDXYZ3质粒转化至酵母YZL141菌株中(YZL141菌株的构建见Bian,G.,Hou,A.,Yuan,Y.,Hu,B.,Cheng,S.,Ye,Z.,Di,Y.,Deng,Z.,&Liu,T.(2018).Metabolic Engineering-Based Rapid Characterization of a SesquiterpeneCyclase and the Skeletons of Fusariumdiene and Fusagramineol from Fusariumgraminearum.Organic letters,20(6),1626–1629.https://doi.org/10.1021/acs.orglett.8b00366),涂布于SD-URA筛选平板上,挑取单克隆获得突变菌株命名为JDXYZ3。
利用MssI内切酶酶切pDXVS1质粒,回收含有AoVS的基因片段,通过醋酸锂方法将该片段导入酵母菌株JCR27中(JCR27的构建见Siemon,T.,Wang,Z.,Bian,G.,Seitz,T.,Ye,Z.,Lu,Y.,Cheng,S.,Ding,Y.,Huang,Y.,Deng,Z.,Liu,T.,&Christmann,M.(2020).Semisynthesis of Plant-Derived Englerin A Enabled by Microbe Engineering ofGuaia-6,10(14)-diene as Building Block.Journal of the American ChemicalSociety,142(6),2760–2765.https://doi.org/10.1021/jacs.9b12940),进行酵母菌落PCR验证后,将阳性菌命名为JDXVS1。进一步的,利用PmeI内切酶酶切pDXVS2质粒,回收含有AoVS的基因片段,通过醋酸锂方法将该片段导入JDXVS1中,进行酵母菌落PCR验证后,将阳性菌命名为JDXVS2。
利用醋酸锂方法分别将pCK,pDXNL1,pDXNL2和pDXNL3质粒转化JDXVS2中,获得CK对照菌株,JDXNL1,JDXNL2和JDXNL3突变体菌株。将pDXNT1质粒分别与pDXNL1,pDXNL2和pDXNL3质粒共转化入JDXVS2中,分别获得JDXNT1,JDXNT2和JDXNT3突变体菌株。
实施例2基因功能鉴定
2.1瓦伦烯合成基因功能鉴定
将JDXYZ3菌株接种于Sc-Ura液体培养基,30℃,200rpm摇床培养过夜;次日按照初始OD600=0.1转接至45毫升YPDHG液体培养基(20g/L蛋白胨,10g/L酵母粉,10g/L葡萄糖,10g/L半乳糖)中,加入5毫升肉豆蔻酸异丙酯,30℃,200rpm摇床培养72小时,收集油层,使用正己烷稀释至合适的浓度,使用GC-MS检测产物,检测条件如下:
Thermo Fisher Scientific配备AS 3000自动进样,分流/不分流进样器的TRACEGC ULTRA气相色谱,以及配备三重四极杆检测器的TSQ QUANTUM XLS MS。
色谱柱为TR-5MS column(30m×0.25mm×0.25um)。载气为高纯氦气,流速1mL/min。丙酮作为洗针液。进样量1uL,分流比50。进样口温度240℃,离子传输管温度270℃。
检测程序:起始柱温为50℃,保持1min;按15℃/min升温至280℃,保持1min;按20℃/min升温至300℃,保持2min。
JDXYZ3发酵产物(图中标记为YZT3)和瓦伦烯标准品(Valencene,Sigma(#75056,CAS:4630-07-3))提取离子流色谱图如图6所示,通过和瓦伦烯标准品进行色谱图保留时间比对,可以确定菌株JDXYZ3可以合成瓦伦烯。此结果表明YZT3基因所编码的蛋白为瓦伦烯合成酶。
2.2细胞色素P450氧化酶、细胞色素P450氧化还原酶功能鉴定
将仅转入含AoCPR基因载体的菌株CK,以及同时包含细胞色素P450氧化酶和细胞色素P450氧化还原酶基因载体的菌株JDXNL1、JDXNL2和JDXNL3分别接种于Sc-Trp液体培养基,30℃,200rpm摇床培养过夜;次日按照初始OD600=0.1转接至50毫升含10g/L葡萄糖和10g/L半乳糖的Sc-Trp液体培养基中,30℃,200rpm摇床培养72小时,收集菌体,加入10mL正己烷萃取菌体。萃取液经GC-MS检测产物,检测仪器与2.1相同,检测程序如下:起始柱温为80℃,保持1min;按8℃/min升温至280℃,保持5min;按20℃/min升温至300℃,保持2min。
CK菌株、JDXNL1菌株(图中标记为CYP6),JDXNL2菌株(图中标记为CYP9)和JDXNL3菌株(图中标记为AoKo)摇瓶发酵产物,以及诺卡醇标准品(Nootkatol使用源叶的诺卡酮由氢化铝锂还原后获得)提取离子流色谱图如图7所示。通过和诺卡醇标准品进行色谱图保留时间比对可以看出,对照菌株CK不能合成获得诺卡醇,菌株JDXNL1,JDXNL2和JDXNL3可以合成诺卡醇。此结果表明了在细胞色素P450氧化还原酶AoCPR和细胞色素P450氧化酶CYP6、CYP9和AoKO的至少一种同时存在时,能够氧化瓦伦烯生成诺卡醇。
2.3醇脱氢酶功能鉴定
将JDXNT1、JDXNT2和JDXNT3菌株分别接种于Sc-Ura-Trp液体培养基,30℃,200rpm摇床培养过夜;次日按照初始OD600=0.1转接至50毫升Sc-Ura-Trp液体培养基(含10g/L葡萄糖,10g/L半乳糖)中,30℃,200rpm摇床培养72小时,收集菌体,加入10mL正己烷萃取菌体。萃取液经GC-MS检测产物,检测条件与2.2相同。
JDXNT1菌株(图中标记为CYP6)、JDXNT2菌株(图中标记为CYP9)和JDXNT3菌株(图中标记为AoKo)摇瓶发酵产物,以及诺卡酮标准品(Nootkatone,源叶B20925)提取离子流色谱图如图8所示,通过和诺卡酮标准品进行色谱图保留时间比对,可以确定菌株JDXNT1,JDXNT2和JDXNT3可以合成诺卡酮。此结果表明了AoADH编码的醇脱氢酶能够将诺卡醇进一步氧化生成终产物诺卡酮。
实施例3发酵罐发酵合成诺卡酮
参照文献(SIEMON T,WANG Z,BIAN G,et al.2020.Semisynthesis of Plant-Derived Englerin A Enabled by Microbe Engineering of Guaia-6,10(14)-diene asBuilding Block.Journal of the American Chemical Society[J],142:2760-2765.)中所记载的发酵罐培养基和发酵方法,对所构建的菌株JDXNT1、JDXNT2、JDXNT3进行分批补料发酵,在发酵过程中添加覆盖剂以实现原位萃取,覆盖剂为肉豆蔻酸异丙酯。发酵过程控制溶氧在20%以上,pH为5,葡萄糖浓度为1-2g/L,乙醇浓度为5g/L以下。最终在7L发酵罐上,菌株JDXNT1中瓦伦烯、诺卡醇、诺卡酮的产量分别达到了500mg/L、30mg/L、1.2g/L;菌株JDXNT2中瓦伦烯、诺卡醇、诺卡酮的产量分别达到了350mg/L、25mg/L、1.5g/L;菌株JDXNT3中瓦伦烯、诺卡醇、诺卡酮的产量分别达到了500mg/L、60mg/L、1.9g/L。
序列表
<110> 武汉合生科技有限公司
<120> 一种生物合成诺卡酮的方法及载体
<130> MTI220210
<160> 53
<170> SIPOSequenceListing 1.0
<210> 1
<211> 550
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetical protein
<400> 1
Met Glu Lys Gln Ser Val Thr Leu Val Arg Asp Asp Gln Gly Ile Val
1 5 1015
Arg Lys Ser Thr Lys Tyr His Pro Ser Val Trp Gly Asp Tyr Phe Ile
202530
Arg Asn Ser Pro Leu Asn Leu Ser Glu Glu Ser Thr Gln Arg Met Ile
354045
Glu Arg Val Glu Glu Leu Lys Val Gln Val Lys Ser Met Phe Lys Gly
505560
Thr Ser Asp Val Leu Gln Ile Met Asn Leu Ile Asp Ser Ile Gln Leu
65707580
Leu Arg Leu Glu Tyr His Phe Glu Asn Glu Ile Asp Gly Ala Leu Arg
859095
Leu Ile Tyr Glu Val Asp Asp Lys Asn Tyr Gly Leu Tyr Glu Thr Ser
100 105 110
Leu Arg Phe Arg Leu Leu Arg Gln His Gly Tyr Asn Val Ser Ala Asp
115 120 125
Thr Phe Asn Lys Phe Lys Asp Glu Asn Gly Ser Phe Ile Ser Ile Leu
130 135 140
Asn Gly Asp Ala Lys Gly Leu Leu Ser Leu Tyr Asn Ala Ser Tyr Leu
145 150 155 160
Ala Thr His Gly Glu Thr Ile Leu Asp Glu Ala Asn Asn Tyr Thr Lys
165 170 175
Ser Gln Leu Val Ser Leu Leu Ser Glu Leu Glu Gln Pro Leu Ala Thr
180 185 190
Gln Val Ser Leu Phe Leu Glu Ala Pro Leu Cys Arg Arg Met Lys Ser
195 200 205
Ile Leu Ala Arg Lys Tyr Ile Pro Ile Tyr Glu Lys Glu Ala Met Arg
210 215 220
Ser Asp Asp Ile Leu Glu Leu Ala Lys Leu Asp Phe Asn Leu Leu Gln
225 230 235 240
Ser Leu His Gln Glu Glu Leu Lys Lys Ala Ser Ile Trp Trp Asn Asp
245 250 255
Leu Ala Leu Ala Lys Ser Leu Ser Phe Thr Arg Asp Arg Ile Val Glu
260 265 270
Gly Tyr Tyr Trp Ile Leu Ser Met Cys Tyr Glu Pro Gln Tyr Ser Arg
275 280 285
Ala Arg Val Met Cys Ala Lys Ala Phe Cys Leu Leu Ser Ile Met Asp
290 295 300
Asp Ile Tyr Asp Asn Tyr Ser Ile Leu Glu Glu Arg Arg Leu Leu Thr
305 310 315 320
Glu Ala Ile Lys Arg Trp Asn His Glu Ala Val Asp Ser Leu Pro Glu
325 330 335
Tyr Ile Lys Asp Phe Tyr Leu Lys Leu Leu Lys Ala Phe Glu Glu Phe
340 345 350
Glu Ala Glu Leu Glu Phe Asn Glu Lys Tyr Arg Val Gln Tyr Leu Gln
355 360 365
Asn Glu Phe Lys Ala Ile Ala Ile Ser Tyr Phe Glu Glu Ser Lys Trp
370 375 380
Cys Val Glu Arg Tyr Val Pro Ser Leu Asp Glu His Leu Arg Val Ser
385 390 395 400
Met Ile Thr Ser Gly Cys Ser Met Val Val Cys Ser Met Tyr Leu Gly
405 410 415
Met Gly Glu Val Ala Thr Lys Glu Ile Phe Asp Trp Cys Ser Ser Phe
420 425 430
Pro Lys Ala Met Glu Ala Ser Gly Val Ile Ala Arg Leu Leu Asn Asp
435 440 445
Ile Arg Ser His Glu Thr Glu Gln Gly Arg Asp His Ala Ala Ser Thr
450 455 460
Val Glu Ser Tyr Met Lys Glu His Gly Val Asp Val Lys Val Ala Arg
465 470 475 480
Lys Lys Leu Gln Glu Ile Val Glu Lys Ala Trp Lys Asp Leu Asn Lys
485 490 495
Glu Leu Leu Asn Pro Thr Pro Val Ala Arg Pro Ile Ile Glu Arg Ile
500 505 510
Leu Asn Leu Thr Met Ser Met Glu Asp Ile Tyr Arg Tyr Ile Asp Glu
515 520 525
Tyr Thr Ser Pro Asp Asn Lys Thr Asn Gly Asp Val Ser Leu Val Leu
530 535 540
Val Glu Ser Ile Pro Ile
545 550
<210> 2
<211> 515
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetical protein
<400> 2
Met Ala Glu Val Gln Leu Thr Pro Leu Leu Leu Ile Phe Leu Leu Leu
1 5 1015
Phe Leu Phe Leu Phe Leu Phe Leu Ile Gly Thr Glu Arg Lys Leu Phe
202530
Ser Asn Ser Arg Gly Ala Arg Leu Pro Pro Gly Pro Ser Lys Leu Pro
354045
Val Ile Gly Asn Leu His Gln Leu Cys Gly Gly Leu Pro His Arg Val
505560
Leu Arg Asp Leu Ala Gly Ile His Gly Pro Leu Met Leu Leu Arg Leu
65707580
Gly Gln Val Asp Leu Ala Val Val Ser Ser Arg Asn Ala Val Leu Gln
859095
Val Thr Lys Ile His Asp Leu Asn Phe Ala His Arg Pro Gln Leu Leu
100 105 110
Ala Pro Ser Lys Ile Cys Tyr Gly Cys Ser Asp Val Ala Phe Ser Ser
115 120 125
Tyr Gly Asp Tyr Trp Arg Gln Met Arg Arg Ile Cys Ala Thr Asp Leu
130 135 140
Phe Thr Ala Lys Arg Ile Lys Ser Phe Ser Ala Ile Arg Ala Glu Glu
145 150 155 160
Val Ala Lys Leu Leu Arg Asp Ala Glu Ala Ala Ala Ala Ala Gly Gln
165 170 175
Pro Met Asn Leu Asn Tyr Lys Leu Thr Ala Ile Ser Asn Ser Ile Val
180 185 190
Thr Arg Ala Ser Phe Gly Phe Lys Phe Asp Asn Gln His Ala Phe Ile
195 200 205
Glu Thr Met Lys Gly Ala Ile Leu Leu Ala Ser Gly Phe Cys Ala Ala
210 215 220
Asp Leu Phe Pro Ser Leu Lys Phe Val Ala Ser Ile Cys Gly Leu Thr
225 230 235 240
Ser Lys Leu Lys Met Leu His Cys Lys Val Asp Glu Ile Leu Asp Ala
245 250 255
Thr Ile Lys Lys His Gln Ser Ser Lys Ser Glu Gly Asp Glu Glu Asn
260 265 270
Leu Leu Asp Val Leu Leu Arg Leu Lys Asp Asp Gly Thr Leu Glu Ser
275 280 285
Pro Ile Thr Phe Asp Asn Ile Lys Ala Val Ile Leu Asp Val Phe Thr
290 295 300
Gly Gly Thr Glu Thr Ser Ser Thr Ile Val Glu Trp Thr Met Ser Glu
305 310 315 320
Leu Ile Arg Asn Pro Ser Ala Met Ala Lys Ala Gln Gly Glu Val Arg
325 330 335
Glu Ala Met Met Arg Arg Gln Ser Arg Asp Phe Asp Glu Glu Val Ile
340 345 350
Gly Glu Leu His Tyr Leu Lys Leu Val Ile Lys Glu Ser Leu Arg Leu
355 360 365
His Pro Pro Leu Pro Leu Leu Val Pro Arg Val Ala Lys Glu Ala Cys
370 375 380
Gln Val Leu Asp Tyr Glu Val Pro Ala Gly Thr Arg Val Val Ile Asn
385 390 395 400
Ala Trp Ala Leu Gly Arg Asp Pro Leu Tyr Trp Gly Ala Asp Ala Glu
405 410 415
Arg Phe Arg Pro Glu Arg Phe Glu Asp Gly Glu Val Asp Tyr Lys Gly
420 425 430
Gly His Leu Glu Phe Ile Pro Phe Gly Ala Gly Arg Arg Ile Cys Pro
435 440 445
Gly Met Arg Phe Gly Met Ala Thr Val Glu Leu Val Leu Ala Gln Leu
450 455 460
Leu Phe His Phe Asp Trp Glu Leu Pro Gly Gly Gly Glu Gly Asn Thr
465 470 475 480
Ala Ala Glu Glu Leu Asp Met Ala Glu Ala Phe Gly Ala Thr Val Val
485 490 495
Arg Lys Glu Glu Leu Arg Leu Val Pro Val Leu Arg Tyr Pro Leu Pro
500 505 510
Pro Ala Ala
515
<210> 3
<211> 511
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetical protein
<400> 3
Met Glu Ala Phe Thr Leu Lys Leu Ile Ile Leu Phe Phe Ala Pro Leu
1 5 1015
Leu Leu Phe Leu Leu Phe Leu Arg Arg Ser His Gly Arg Arg Arg Gly
202530
His Gly Lys Pro Leu Pro Pro Gly Pro Phe Asn Leu Pro Val Ile Gly
354045
Ser Leu His His Leu Leu Gly Pro Leu Leu His Gln Thr Leu Ala Ser
505560
Met Ser Gln Arg Tyr Gly Pro Ala Ile Leu Leu Lys Phe Gly His Val
65707580
Thr Thr Leu Val Ile Ser Ser Val Glu Ala Ala Ala Glu Ile Met Lys
859095
Thr His Asp Val Ser Phe Ala Thr Arg Pro Val Ile His Ser Ala Lys
100 105 110
Met Ile Ala Tyr Gly Gly Asp Gly Ile Val Phe Ala Pro Tyr Gly Thr
115 120 125
Ser Trp Arg Glu Leu Arg Lys Met Ser Met Val Glu Leu Leu Ser Ala
130 135 140
Lys Arg Val Gln Tyr Phe Arg Tyr Ile Arg Glu Asp Glu Val Leu Lys
145 150 155 160
Phe Met Arg Ser Ile Thr Leu Ala Pro Gln Ser Val Asn Leu Ser Ser
165 170 175
Ser Phe Lys Val Leu Ala Asn Asp Ile Ala Ala Arg Ala Ile Ile Gly
180 185 190
Ser Lys Cys Gln Tyr Gln Gln Glu Phe Leu Arg Leu Ile Met Lys Gly
195 200 205
Leu Gln Glu Ala Gly Gly Phe Asn Leu Ala Asp Leu Tyr Pro Ser Ser
210 215 220
Pro Leu Leu Gly Leu Leu Ser Arg Leu Leu Ser Ser Lys Met Gln Gln
225 230 235 240
Leu His Leu Glu Val Asp Ala Ile Leu Asp Gly Ile Ile Lys Glu His
245 250 255
Arg Gln Arg Ser Lys Thr Phe Ala Glu Gln Ser Ala Glu Glu Asp Met
260 265 270
Val Asp Thr Leu Leu Lys Val Gln Ala Glu Gly Ser Leu Pro Phe Pro
275 280 285
Leu Thr Asp Leu Ser Ile Lys Ala Met Ile Phe Asp Leu Phe Ala Ala
290 295 300
Ala Ser Glu Thr Thr Ser Thr Thr Met Glu Trp Ala Met Ser Glu Leu
305 310 315 320
Met Lys Asn Pro Val Ala Met Lys Gln Ala Gln Glu Glu Val Arg Arg
325 330 335
Val Val Gly Ser Lys Gly Lys Val Thr Glu Asp His Val Gly Glu Met
340 345 350
Ser Tyr Leu Lys Gln Ala Val Arg Glu Ser Leu Arg Leu His Pro Pro
355 360 365
Leu Pro Leu Leu Leu Pro Arg Glu Cys Gln Glu Ala Met Glu Val Met
370 375 380
Gly Tyr Trp Ile Pro Ala Lys Thr Arg Val Leu Val Asn Ala Trp Ala
385 390 395 400
Leu Ala Arg Asp Pro Arg Tyr Trp Asp Asp Ala Thr Glu Phe Lys Pro
405 410 415
Glu Arg Phe Ala Ala Gly Gly Arg Ser Cys Gly Val Asp Met Lys Gly
420 425 430
Thr Asn Leu Glu Leu Ile Pro Phe Gly Ala Gly Arg Arg Met Cys Pro
435 440 445
Gly Ser Thr Phe Gly Met Ala Ser Val Glu Leu Val Leu Ala Cys Leu
450 455 460
Leu Tyr Tyr Phe Asp Trp Glu Met Pro Val Pro Gly Asp Gly Gly Ala
465 470 475 480
Ala Lys Lys Pro Thr Glu Leu Asp Met Glu Glu Gln Phe Ile Leu Ala
485 490 495
Cys His Lys Lys Thr Gln Leu Arg Leu Arg Ala Ile Pro Arg Ile
500 505 510
<210> 4
<211> 500
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetical protein
<400> 4
Met Ile Ser Thr Ala Phe Ala Ser Val Ala Ala Ala Ile Phe Thr Val
1 5 1015
Phe Ile Leu Ile Arg Phe Arg Arg Arg Ser Arg Val Ser Asn Leu Pro
202530
Pro Ala Val Pro Gly Leu Pro Leu Ile Gly Asn Leu Leu Gln Leu Lys
354045
Asp Lys Lys Pro His Gln Thr Phe Thr Lys Trp Ala Gln Ile Tyr Gly
505560
Pro Ile Tyr Thr Ile Lys Thr Gly Ala Ser Thr Met Val Val Leu Asn
65707580
Ser Thr Glu Val Ala Lys Glu Ala Met Val Ala Lys Tyr Ser Ser Ile
859095
Ser Asn Arg Lys Leu Ser Lys Ala Leu Thr Leu Leu Thr Ser Asn Lys
100 105 110
Arg Met Val Ala Met Ser Asp Tyr Gly Glu Phe His Lys Met Val Lys
115 120 125
Arg Tyr Ile Leu Thr Ser Leu Leu Gly Ala Asn Ala Gln Lys Gln Asn
130 135 140
Tyr Gly Ile Arg Glu Thr Leu Ile Asn Asn Val Val Lys Phe Leu Tyr
145 150 155 160
Ser Asp Leu Ser Asp Asn Pro Asn Asp Ala Val Asn Leu Arg Lys Ser
165 170 175
Phe Gln Pro Glu Leu Phe Arg Leu Ala Met Lys Gln Ala Leu Asn Leu
180 185 190
Glu Pro Glu Ser Ile Tyr Val Glu Glu Leu Gly Arg Glu Leu Ser Lys
195 200 205
Glu Glu Ile Phe Asn Val Leu Val Val Asp Pro Met Met Gly Ala Ile
210 215 220
Glu Val Asp Trp Arg Asp Phe Phe Pro Tyr Leu Arg Trp Val Pro Asn
225 230 235 240
Arg Ser Phe Glu Asn Lys Leu Lys Arg Met Leu Met Arg Arg Ala Ala
245 250 255
Val Met Gln Val Leu Ile Thr Lys Arg Lys Asn Ser Lys Gln Ser Lys
260 265 270
Glu Glu Ile Ser Cys Tyr Leu Asp Phe Leu Leu Ser Gln Gly Thr Leu
275 280 285
Thr Asp Glu Glu Ile Ile Ser Leu Val Trp Glu Ala Val Ile Glu Ser
290 295 300
Ser Asp Thr Thr Leu Val Thr Thr Glu Trp Ala Met Phe Glu Leu Ser
305 310 315 320
Lys Asn Pro Asn Lys Gln Glu Arg Leu Tyr Gln Glu Ile Gln Gln Val
325 330 335
Cys Gly Ser Glu Asn Val Thr Asp Glu His Leu Ser Arg Met Pro Tyr
340 345 350
Leu Asn Cys Val Phe His Glu Thr Leu Arg Arg His Ser Pro Val Pro
355 360 365
Ile Val Pro Leu Arg Tyr Ala His Glu Asp Thr Gln Ile Gly Gly Phe
370 375 380
Asn Ile Leu Ala Gly Ser Glu Ile Ala Ile Asn Leu Tyr Gly Cys Asn
385 390 395 400
Met Asp Lys Met Gln Trp Asp Glu Pro Asn Glu Trp Lys Pro Glu Arg
405 410 415
Phe Ile Asp Ser Lys Tyr Glu Gln Met Asp Ser Tyr Lys Thr Met Ala
420 425 430
Phe Gly Ala Gly Lys Arg Ile Cys Ala Gly Ser Leu Gln Ala Ser Ser
435 440 445
Ile Ala Cys Thr Ala Ile Gly Arg Leu Val Gln Glu Phe Glu Trp Arg
450 455 460
Leu Lys Glu Gly Glu Glu Ala Asn Val Val Thr Val Gln Leu Thr Asn
465 470 475 480
Leu Lys Leu Glu Pro Leu Leu Ala Tyr Ile Lys Pro Arg Ser Thr Asn
485 490 495
Asp Ala Cys Leu
500
<210> 5
<211> 700
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetical protein
<400> 5
Met Gln Thr Asp Ser Gly Lys Ala Ser Pro Leu Asp Leu Leu Ser Ala
1 5 1015
Val Val Ala Ser Leu Ser Gly Gly Asp Gly Leu Asp Leu Gly Ala Gly
202530
Asn Pro Ser Val Glu Tyr Arg Arg Leu Ile Ala Val Leu Ser Thr Val
354045
Val Ala Val Leu Val Gly Cys Ala Ala Ile Phe Phe Phe Arg Arg Ser
505560
Ser Gly Lys Lys Pro Ala Glu Pro Pro Lys Pro Leu Ala Val Lys Thr
65707580
Gln Leu Asp Ala Glu Glu Asp Gln Gly Lys Lys Lys Val Thr Val Phe
859095
Phe Gly Thr Gln Thr Gly Thr Ala Glu Gly Phe Ala Lys Ala Leu Ala
100 105 110
Glu Glu Ala Lys Ala Arg Tyr Pro Asn Ala Ile Phe Lys Val Val Asp
115 120 125
Ile Asp Glu Tyr Ala Thr Glu Asp Asp Glu Tyr Glu Glu Asn Leu Lys
130 135 140
Lys Glu Ser Leu Val Leu Phe Phe Leu Ala Thr Tyr Gly Asp Gly Glu
145 150 155 160
Pro Thr Asp Asn Ala Ala Arg Phe Tyr Lys Trp Phe Thr Glu Gly Lys
165 170 175
Glu Arg Val Thr Trp Leu Glu Asn Leu Gln Phe Ser Val Phe Gly Leu
180 185 190
Gly Asn Arg Gln Tyr Glu His Phe Asn Lys Val Ala Lys Val Val Asp
195 200 205
Glu Leu Leu Gln Glu Gln Gly Ala Lys Arg Ile Val Gln Val Gly Leu
210 215 220
Gly Asp Asp Asp Gln Cys Ile Glu Asp Asp Phe Ser Ala Trp Arg Glu
225 230 235 240
Leu Leu Trp Pro Glu Leu Asp Lys Leu Leu Gln Asp Glu Asn Glu Thr
245 250 255
Gly Ala Ser Thr Pro Tyr Thr Ala Ala Val Pro Glu Tyr Arg Val Val
260 265 270
Phe Val Lys Pro Glu Glu Val Pro Tyr Leu Asp Lys Ser Leu Ser Phe
275 280 285
Ala Asn Gly His Ala Ile His Asp Ile Gln His Pro Cys Arg Ala Asn
290 295 300
Val Ala Val Arg Arg Glu Leu His Thr Ser Ala Ser Asp Arg Ser Cys
305 310 315 320
Ile His Leu Glu Phe Asp Ile Asp Gly Thr Gly Leu Val Tyr Gly Thr
325 330 335
Gly Asp His Val Gly Val Phe Ala Asp Asn Cys Ser Glu Ile Val Glu
340 345 350
Glu Ala Ala Lys Leu Leu Gly Tyr Ser Pro Asp Thr Tyr Phe Ser Ile
355 360 365
His Thr Asp Lys Glu Asp Gly Thr Pro Leu Gly Gly Ser Leu Ser Pro
370 375 380
Pro Phe Pro Ser Pro Cys Thr Leu Lys Thr Ala Leu Thr Arg Tyr Ser
385 390 395 400
Asp Val Leu Asn Ser Pro Lys Lys Ser Ala Leu Leu Ala Leu Ala Ala
405 410 415
His Ala Thr Asp Leu Ser Asp Ala Glu Arg Leu Lys Phe Leu Ala Ser
420 425 430
Pro Ile Gly Lys Asp Glu Tyr Ser Gln Trp Ile Val Ala Asn Gln Arg
435 440 445
Ser Leu Leu Glu Val Met Ala Glu Phe Pro Ser Ala Lys Pro Pro Leu
450 455 460
Gly Val Phe Phe Ala Ala Ile Ala Pro Arg Leu Gln Pro Arg Tyr Tyr
465 470 475 480
Ser Ile Ser Ser Ser Pro Arg Met Ala Pro Ser Arg Ile His Val Thr
485 490 495
Cys Ala Leu Val Tyr Glu Lys Thr Pro Thr Gly Arg Ile His Lys Gly
500 505 510
Val Cys Ser Thr Trp Met Lys Asn Ser Ile Ser Leu Glu Glu Asn Gln
515 520 525
Glu Cys Ser Trp Ala Pro Ile Phe Val Arg Gln Ser Asn Phe Lys Leu
530 535 540
Pro Val Asp Pro Ser Val Pro Val Ile Met Ile Gly Pro Gly Thr Gly
545 550 555 560
Leu Ala Pro Phe Arg Gly Phe Leu Gln Glu Arg Leu Ala Leu Lys Lys
565 570 575
Glu Gly Leu Glu Leu Gly His Ser Ile Leu Phe Phe Gly Cys Arg Asn
580 585 590
Arg Lys Met Asp Phe Ile Tyr Glu Asp Glu Leu Asn Asn Phe Val Glu
595 600 605
Thr Gly Val Leu Ser Glu Phe Ile Val Ala Phe Ser Arg Glu Gly Pro
610 615 620
Thr Lys Gln Tyr Val Gln His Lys Met Thr Glu Lys Ala Ser Glu Leu
625 630 635 640
Trp Asn Ile Ile Ser Gln Gly Gly Tyr Val Tyr Val Cys Gly Asp Ala
645 650 655
Lys Gly Met Ala Arg Asp Val His Arg Val Leu His Thr Ile Val Gln
660 665 670
Glu Gln Gly Gly Met Asp Ser Ser Lys Thr Glu Ser Phe Val Lys Ser
675 680 685
Leu Gln Met Glu Gly Arg Tyr Ser Arg Asp Val Trp
690 695 700
<210> 6
<211> 267
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetical protein
<400> 6
Met Ala Ser Ser Phe Val Leu Ser Ser Val Ala Lys Arg Leu Glu Gly
1 5 1015
Lys Val Thr Leu Ile Thr Gly Gly Ala Ser Gly Leu Gly Glu Cys Thr
202530
Ala Lys Leu Phe Ala Arg Leu Gly Ala Arg Val Val Val Ala Asp Ile
354045
Gln Asp Asp Lys Gly Arg Ala Leu Cys Asp Ser Leu Gly Pro Asp Thr
505560
Ala Ser Tyr Val His Cys Asp Val Thr Lys Glu Pro Asp Val Ala Ser
65707580
Ala Val Asp Ala Ala Val Ala Arg His Gly Lys Leu Asp Val Met Phe
859095
Ser Asn Ala Gly Val Gly Glu Val Leu Gln Lys Ser Leu Pro Asp Cys
100 105 110
Glu Val Ala Asp Phe Gln Arg Leu Met Ser Val Asn Val Thr Gly Val
115 120 125
Phe Leu Ala Thr Lys His Ala Ala Arg Val Met Thr Pro Ala Arg Arg
130 135 140
Gly Ser Ile Val Ile Thr Gly Ser Thr Thr Ser Thr Ile Gly Gly Leu
145 150 155 160
Gly Pro His Ala Tyr Thr Cys Ser Lys His Ala Val Val Gly Leu Met
165 170 175
Arg Ser Ala Ala Val Glu Leu Gly Arg His Gly Val Arg Val Asn Cys
180 185 190
Val Ser Pro His Gly Met Ala Thr Pro Met Thr Met Ala Ala Phe Asp
195 200 205
Leu Asp Lys Glu Gly Val Glu Ala Met Phe Glu Arg Ser Ala Asn Leu
210 215 220
Lys Gly Val Arg Leu Glu Ala Glu Asp Val Ala Glu Ala Val Ala Tyr
225 230 235 240
Leu Ala Gly Asp Glu Ser Arg Tyr Val Ser Gly Val Asn Leu Leu Val
245 250 255
Asp Gly Gly Phe Thr Ile Ala Lys Gly Leu Ala
260 265
<210> 7
<211> 1653
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 7
atggagaaac aatcagtaac tctcgtgcgt gatgaccaag ggatagttcg taagtcgaca 60
aaatatcatc caagcgtttg gggtgattat ttcatccgaa actcgcctct caatctatca 120
gaggagtcca ctcaaaggat gatagagaga gtagaagaat taaaggtgca agtaaagagc 180
atgttcaagg gcaccagtga cgtattgcag attatgaact tgattgattc aattcaactt 240
ctaagactag aatatcattt tgagaatgaa atagatggtg cactaagatt gatctatgag 300
gtcgacgaca agaactatgg actttatgaa acttctctta gatttcgatt gcttaggcaa 360
catggatata atgtttctgc agataccttt aacaagttca aagatgagaa tggaagcttt 420
atatctatct tgaatggaga tgcaaaggga ttactaagct tatataatgc atcttacctt 480
gcaacgcatg gagagactat acttgatgaa gccaataatt atacaaagtc tcagctagta 540
tccttattga gtgaacttga acaaccttta gcgacacaag tatcactttt ccttgaagcg 600
cccctatgtc gaagaatgaa aagtatcttg gcaagaaaat atatacctat ttatgaaaag 660
gaagcaatgc gaagtgatga catattagaa cttgcaaaat tggatttcaa tctactgcaa 720
tctcttcatc aagaggagtt gaagaaagct tcgatatggt ggaatgattt agcccttgct 780
aaatctctaa gttttactcg tgatcgaatc gtggaaggtt attattggat tcttagtatg 840
tgttatgagc ctcaatattc tcgtgcacga gtgatgtgcg ccaaagcatt ttgtcttcta 900
tcaattatgg atgatattta tgacaactat agcatattgg aagagcgcag attattaact 960
gaggcaataa agaggtggaa tcatgaagct gttgattctt taccagaata tataaaagat 1020
ttttatctga agctattaaa ggcttttgaa gaatttgaag cggaattgga atttaatgag 1080
aagtatcgtg tgcaatacct tcaaaatgaa tttaaagcta tagccatatc atattttgaa 1140
gaatccaagt ggtgtgtgga aagatatgtg ccgtcactcg acgaacactt gcgtgtttct 1200
atgatcacct ctggatgttc tatggtcgtt tgttctatgt atcttggtat gggagaagtg 1260
gcaacaaaag agattttcga ttggtgttct agttttccca aggcaatgga agcaagcggt 1320
gtaattgcta gactcctcaa tgatataaga tcacacgaga ctgagcaagg gagagaccat 1380
gctgcctcta cagtggaaag ttacatgaaa gagcacggcg tagatgtaaa agttgcacgc 1440
aagaagctac aagagatagt ggagaaagcg tggaaggatc taaataagga acttctcaac 1500
cccacaccag tagctcgacc tataattgaa agaatactca accttacaat gtcaatggaa 1560
gacatatata ggtacattga cgagtacacc agtcctgata ataagacgaa cggtgatgtc 1620
tccttggtgt tggttgaatc tattcctata tga 1653
<210> 8
<211> 1548
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 8
atggcggagg tccaactcac tcccctcctc ttaatcttcc tcctcctctt cctgttcctc 60
ttcctcttcc tcatcggcac agagaggaag cttttctcca actccagagg agctcgcctc 120
ccgcccggtc cgtcgaagct acccgtcatt ggcaacctgc accaactttg cggcggccta 180
ccccaccgtg tcctgcgcga cctcgccggc atccacggcc ccctcatgct cctccgcctt 240
ggccaggtcg acctcgccgt cgtatcctcc cgaaatgccg tcctgcaggt caccaagatc 300
cacgacctca acttcgccca tcgcccccag ctcctggccc cttccaaaat ctgctacggc 360
tgctccgacg tcgccttctc ttcctacgga gactactggc gccagatgcg caggatctgc 420
gcaaccgatc tcttcaccgc caagcgcatc aagtcattct ctgccatccg cgcagaagag 480
gtcgccaagc tcctccgcga cgccgaggcg gcagcggctg ccggccagcc gatgaacttg 540
aactacaagc tcacggcgat ctcgaacagc atcgtgaccc gcgcctcttt cggtttcaaa 600
ttcgataacc agcacgcgtt catcgagacc atgaaggggg cgatactgct cgcgtcgggg 660
ttttgcgccg cggatctgtt cccgtctttg aagttcgtgg cctcgatctg cggcctcacc 720
tccaagctga agatgcttca ctgcaaagtg gatgaaattc tcgacgcgac catcaaaaag 780
caccaatcga gcaagagcga aggggacgaa gagaatctcc tcgacgttct acttcgtcta 840
aaagacgacg gaaccctgga atccccaatc acattcgaca acatcaaagc tgtgattttg 900
gacgtcttca cgggagggac ggagacctcg tcgacgattg tagaatggac gatgtcggag 960
ctcatcagga accctagcgc gatggcgaag gcacaagggg aagtgcgaga agcgatgatg 1020
cgaaggcaaa gcagggattt cgacgaggaa gtcatcggcg agctccatta cctgaagcta 1080
gtgatcaagg agagtctgag gctacacccg ccgctaccac tgttggtgcc gagggtggcg 1140
aaggaggcgt gccaggtgct ggactacgag gtgccggcgg gcacgagggt ggtgatcaac 1200
gcctgggccc tagggaggga cccgctctac tggggcgccg acgccgagcg gttccggccc 1260
gagaggttcg aggacggtga ggtggactac aaggggggcc acctggagtt cattccattc 1320
ggcgccggga ggaggatatg ccccgggatg agattcggga tggcgacggt ggaactcgta 1380
ttggcgcagc tgctgttcca cttcgactgg gagctaccag gaggaggaga agggaatacg 1440
gcggcggagg aactggacat ggcggaggca ttcggggcga ccgtggtgag gaaggaggag 1500
ctccgcctgg ttccggtgct tcgatatccc ctgccgcccg ctgcttag 1548
<210> 9
<211> 1536
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 9
atggaagctt ttaccttgaa gcttatcatt ctcttcttcg cccccctcct cctcttcctc 60
ctcttcctca ggcgcagcca tggccgacgg cggggccacg gcaagcctct ccctcctggc 120
ccattcaacc tccccgtcat cggcagcctg caccacctcc tcggcccgtt gctgcaccag 180
acgctcgcgt ctatgtccca gcgatacggc cccgccatcc tcctcaagtt cggccatgtc 240
accaccctcg tcatctcctc cgttgaggcc gccgcagaga tcatgaagac ccatgacgtc 300
agcttcgcca cgcgtcccgt catccattca gccaagatga tcgcctacgg cggcgacggt 360
attgtcttcg cgccatacgg caccagctgg cgcgagctcc gcaaaatgag catggtggag 420
ctcctcagtg ccaagcgcgt ccagtacttc cgctatatcc gcgaggatga ggtgcttaaa 480
tttatgcgct ccattacgtt ggcaccccaa agcgtgaatc ttagtagcag ttttaaggtg 540
ctcgcgaacg acatcgcggc gagggccatc attgggagca agtgccagta tcagcaggag 600
ttcctgcggc tgataatgaa ggggctccaa gaagcggggg gattcaactt ggccgacttg 660
tacccgtcgt cgccgctcct cgggttgctc agccgcttgt tgtcttccaa gatgcagcag 720
ctgcacctcg aggtggatgc catcttggat ggcatcatca aggagcacag acagaggagt 780
aaaacgttcg cagagcagag tgcagaggag gacatggtgg ataccctgct caaggttcaa 840
gcggaaggca gccttccgtt ccccctcacg gacttgtcca tcaaagctat gatttttgat 900
ctttttgcag cggcgagcga gaccacctct acgaccatgg aatgggcgat gtcggagctg 960
atgaagaatc cggtggcgat gaagcaggcg caggaggaag tgaggcgggt ggtgggaagc 1020
aaggggaaag tcaccgaaga tcacgtcggc gagatgagtt acctcaagca ggcggtaagg 1080
gagtcgctga ggcttcaccc tcccctgcct ctgttgctgc cgcgggagtg ccaggaagcg 1140
atggaggtga tgggctactg gattccggcg aagacgaggg tgctggtgaa cgcgtgggcg 1200
ctggcgagag acccaaggta ttgggacgac gccacggagt tcaagccaga gaggttcgcc 1260
gctggtggga ggagctgcgg ggtggacatg aaaggcacca acttggagct cataccgttc 1320
ggggcgggta gaaggatgtg ccctggtagc acgttcggaa tggcgagcgt ggagctggtg 1380
cttgcttgcc ttctctatta ctttgactgg gagatgccgg tcccgggcga cggaggagcg 1440
gcgaagaaac cgacggagtt ggacatggaa gaacagttca tactggcgtg tcataagaag 1500
acgcagcttc gcttgcgcgc gatccctcgt atatag 1536
<210> 10
<211> 1503
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 10
atgatttcca cggccttcgc aagtgtcgct gccgccatct tcacggtttt catcctcatc 60
aggttccgac gccgcagtcg cgtttccaat cttccgccgg ctgtccccgg gcttcccttg 120
attgggaatt tgctccagct gaaggacaag aaacctcacc agacattcac gaaatgggcg 180
cagatatatg gcccgattta taccatcaag acgggcgctt ccactatggt agtcctgaat 240
tctactgagg ttgccaaaga ggcaatggtg gctaagtatt catccatctc aaatcggaaa 300
ttgtcaaagg cattgacatt gctcacttca aataaacgta tggttgctat gagtgactat 360
ggagagttcc acaaaatggt gaaacggtac atattgacta gtttgttagg tgcaaatgct 420
cagaagcaaa actatggtat cagggagacg ttgattaata atgtcgtcaa atttctatat 480
tcggatttaa gcgataaccc taatgatgca gtaaacctca gaaagtcatt tcaacctgag 540
ttattccgat tagccatgaa gcaagctttg aacctggaac ctgaatccat ttatgtagag 600
gaacttggga gggaactttc aaaggaagaa atattcaatg tgttggtggt agaccctatg 660
atgggcgcca ttgaggtgga ctggagggac tttttccctt acttgagatg ggtccctaat 720
cgaagctttg aaaataagct aaagagaatg ctcatgcgca gggcggcagt gatgcaggtt 780
ctgattacaa aaagaaagaa cagtaaacaa tccaaagagg agataagctg ctatttggac 840
tttctgctat cccagggcac tttgactgac gaagagataa tatcgttagt atgggaagcg 900
gtaattgagt catcggatac aactttagtc acaacagaat gggctatgtt tgagctatct 960
aagaatccaa ataaacagga acgtctttac caagaaattc aacaagtatg tggatctgaa 1020
aacgtcaccg atgagcattt gtcacggatg ccctacttga actgtgtgtt ccatgagacc 1080
ctaagacgtc attcccctgt tcctatagta cctctcaggt atgcccatga agatacccag 1140
atcggaggat tcaacatcct tgcggggtct gagattgcca tcaatcttta tggatgcaat 1200
atggacaaga tgcagtggga tgaacctaat gaatggaagc ctgagagatt catagacagc 1260
aaatatgagc aaatggactc gtataagact atggcctttg gagctggaaa gaggatttgt 1320
gccggatctc tgcaggcatc gtcgattgca tgcactgcca tcgggcgttt agtgcaagag 1380
ttcgagtgga ggctgaagga aggagaagag gctaatgtcg tcactgttca gctcacaaac 1440
cttaagcttg aacctctgct tgcatacata aagcccagaa gcaccaacga tgcatgcctt 1500
tga 1503
<210> 11
<211> 2103
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 11
atgcagacgg attccgggaa ggcttcgccg ctcgatctct tgtcggctgt cgtcgcctcg 60
ctatccggtg gagatgggct cgatttaggc gccgggaatc cctcggtgga gtaccggcgg 120
ctgatcgccg tcctgagtac tgtcgtcgcc gtgctagttg gctgcgcggc gatattcttc 180
ttccggagat cgagcggaaa gaagccggcc gagccgccga agccgctggc ggttaagact 240
cagctggatg cggaggagga ccaagggaag aagaaggtca ccgtcttctt cggcacgcag 300
accgggacgg ccgaggggtt tgcgaaggcg ctggctgagg aggccaaggc acggtaccct 360
aatgccatat ttaaagtcgt ggatatcgac gaatatgcta ctgaggacga tgagtacgag 420
gagaacctga aaaaggagag cttggttttg ttcttcttgg ctacgtatgg agatggcgag 480
cctactgata atgctgcccg gttctacaaa tggtttacag aggggaaaga gagagtaacc 540
tggttggaaa atcttcaatt ttctgtgttt ggtttgggca atcggcaata tgaacatttt 600
aataaggttg ctaaggtagt tgatgaactg cttcaagagc aaggtgccaa acgcattgtc 660
caagtgggat tgggagatga tgatcagtgt attgaggatg acttctctgc atggagggaa 720
cttctttggc cggagttgga taagttgctt caggacgaaa atgagacagg tgcatctact 780
ccttatacag ctgctgttcc tgaataccgg gttgtatttg tcaagccaga agaagttcca 840
tatctggata aaagtttgag ttttgcaaat ggccatgcta ttcatgacat acaacatcca 900
tgcagggcta atgtggctgt gagacgagag cttcatactt cagcttcaga ccgatcctgc 960
atccacttgg agtttgacat agatggcact ggccttgtgt acggaacagg agaccatgtt 1020
ggtgtattcg cggacaactg ttctgagatt gtagaggagg ctgcaaagtt gttaggttat 1080
tcacctgaca catatttctc tattcatact gacaaggagg atggcacgcc acttggaggc 1140
tctttgtcac ctcctttccc atctccatgc actctcaaaa ccgctcttac tcgatactct 1200
gatgttctaa attcacctaa aaagagtgca ttacttgccc ttgccgcaca cgcaacagat 1260
cttagtgatg ctgagcgact taaatttttg gcttctccta ttggaaagga tgaatattct 1320
caatggattg ttgctaatca gaggagtctt cttgaagtca tggccgaatt tccctctgca 1380
aagcctcctc taggagtctt ctttgccgca atagccccac gtttgcagcc aagatattat 1440
tcaatttcct cttctccgag gatggcacct agtagaattc atgtgacttg tgcattagtt 1500
tatgaaaaga caccaactgg caggattcat aaaggggttt gttccacctg gatgaagaat 1560
tccatttcgc tcgaagagaa ccaagaatgc agctgggctc ctatttttgt gaggcagtct 1620
aactttaaac tccctgttga tccttcggta cctgtcatca tgattggacc gggcacaggg 1680
ttggcacctt tcaggggctt cttacaggaa aggttggcat tgaaaaagga agggttggaa 1740
cttggtcatt ctattctctt cttcggatgc agaaaccgca aaatggactt catctacgag 1800
gatgagttga acaactttgt cgaaacaggc gtgctttccg agtttattgt ggccttctcc 1860
cgtgagggtc caactaaaca atatgtgcaa cacaaaatga ccgagaaagc atcagaactt 1920
tggaatatca tctcccaagg tggatatgta tacgtgtgtg gagatgctaa gggcatggct 1980
agagatgttc acagagttct tcatactatt gttcaagagc agggaggtat ggatagctcc 2040
aaaacagaaa gcttcgtcaa gagcttgcaa atggaaggga gatattcaag ggatgtatgg 2100
tga 2103
<210> 12
<211> 804
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 12
atggcaagct cctttgttct ctcctctgta gcaaaaaggc tcgaagggaa ggtgacattg 60
atcaccggcg gggcgagcgg gctcggcgag tgcaccgcca agctgttcgc ccgcctcggc 120
gcccgagtag tcgtcgcaga catccaagac gacaaaggcc gcgccctgtg cgactcactc 180
ggccccgaca ccgcctccta cgtccactgc gacgtcacca aggagcccga cgtggcaagc 240
gccgtcgacg ccgccgtcgc ccgacacggg aagctcgacg tcatgttcag caacgccgga 300
gtcggggaag tgttgcagaa gtcgttgccc gactgcgagg tggctgactt ccagcgattg 360
atgtcggtga acgtgacggg ggtgttcctg gccaccaagc acgcggcgcg ggtgatgacg 420
ccggcgaggc gggggagcat cgtgatcacg gggagcacca cgtcgactat tgggggacta 480
gggccgcacg catacacgtg ctcaaagcac gcggtggtgg ggctaatgag gagcgcggcg 540
gtcgagctgg gcaggcacgg tgttcgggtc aactgcgtgt cgccgcacgg gatggcaacg 600
ccgatgacga tggcagcgtt tgacttagac aaggaggggg ttgaggccat gtttgagagg 660
tcggccaacc tgaaaggtgt gaggctcgaa gcggaggacg tggcggaggc agtggcgtac 720
ctcgccggcg acgagtccag gtatgtgagc ggcgtcaatc tgctggtgga cggaggcttc 780
accattgcca agggattggc gtag 804
<210> 13
<211> 1653
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 13
atggaaaagc aatctgttac attggttaga gatgatcaag gtattgttag aaaatctaca 60
aagtaccatc catctgtttg gggtgattat tttattagaa actctccatt gaacctgtct 120
gaagaatcta ctcaaagaat gattgaaaga gttgaagaat tgaaggttca agttaaatct 180
atgttcaagg gtacatctga tgttttgcaa attatgaatc tgatcgattc tatccaattg 240
ttaagattag agtaccattt cgaaaacgaa attgatggtg ctttaagatt aatctacgaa 300
gttgatgata agaactacgg tttgtatgaa acatctttaa gattcagact gttgagacaa 360
catggttata atgtttctgc tgatactttt aacaagttca aagatgaaaa cggttctttt 420
atctctatct taaacggtga tgctaaaggt ttgttatctt tatataacgc ttcctatctg 480
gctacacatg gtgaaacaat tttagatgaa gctaataact acaccaagtc tcaattagtt 540
tctttgttgt ctgaattgga acaaccatta gctactcaag tttctttatt tttggaggct 600
ccattatgta gaagaatgaa atctattctg gctagaaaat acatcccaat ttatgaaaag 660
gaggctatga gatctgatga tattttggaa ttggctaaat tggatttcaa cttattgcaa 720
tctctgcatc aagaagaatt aaaaaaggct tctatctggt ggaatgattt ggctttagct 780
aaatctttgt cttttacaag agacagaatc gttgaaggtt attattggat tttgtctatg 840
tgttacgagc cacaatattc tagagctaga gttatgtgtg ctaaagcttt ttgtttattg 900
tctatcatgg acgatatcta tgataattac tctatcttgg aggaaagaag attgttaaca 960
gaagctatta agagatggaa tcatgaagct gttgattctt tgccagaata tattaaagac 1020
ttctacttga agctgttgaa agcttttgaa gaatttgaag ctgaattgga attcaatgaa 1080
aagtatagag tccaatactt gcaaaatgaa ttcaaagcta tcgctatttc ttactttgaa 1140
gaatctaagt ggtgtgttga aagatatgtt ccatctttgg atgaacattt gagagtttct 1200
atgattactt ctggttgttc tatggttgtt tgttctatgt atttgggtat gggtgaagtt 1260
gctacaaaag aaatttttga ttggtgttct tccttcccaa aagctatgga agcttctggt 1320
gttattgcta gattattaaa tgacatcagg tcacatgaaa cagaacaagg tagagatcat 1380
gctgcttcta cagttgaatc ttatatgaaa gaacacggtg ttgatgttaa agttgctaga 1440
aaaaaactgc aagaaatcgt tgaaaaggct tggaaagatt tgaataaaga attgttgaac 1500
cccacaccag ttgctagacc aattattgaa agaattttga acctgactat gtctatggaa 1560
gatatttata gatacatcga cgaatacaca tctccagata ataaaacaaa cggtgatgtt 1620
tctttggttt tggttgaatc tatcccaatt taa 1653
<210> 14
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 14
actaaaggga acaaaagctg gagctctagt agtttaaaca taacgagaac acacagggg 59
<210> 15
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 15
cattaaagta acttaaggag ttaaatttaa gcaaggattt tcttaacttc ttc 53
<210> 16
<211> 56
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 16
gaagttaaga aaatccttgc ttaaatttaa ctccttaagt tactttaatg atttag 56
<210> 17
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 17
tcgaaggctt taatttgcgc gaaaagccaa ttagtgtgat a 41
<210> 18
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 18
tagtatcaca ctaattggct tttcgcgcaa attaaagcct tcgagc 46
<210> 19
<211> 49
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 19
gggacgcgcc ctgtagcggc tgaggtctca acaggcccct tttcctttg 49
<210> 20
<211> 55
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 20
catgatatcg acaaaggaaa aggggcctgt tgagacctca gccgctacag ggcgc 55
<210> 21
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 21
gaatttttga aaattcaata taaatgtgag accaccatga ttacgccaag cg 52
<210> 22
<211> 57
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 22
taatcatggt ggtctcacat ttatattgaa ttttcaaaaa ttcttacttt ttttttg 57
<210> 23
<211> 62
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 23
atctctctct cctaatttct ttttctgaag ccattatagt tttttctcct tgacgttaaa 60
gt 62
<210> 24
<211> 50
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 24
ttaacgtcaa ggagaaaaaa ctataatggc ttcagaaaaa gaaattagga 50
<210> 25
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 25
atgtacaaat atcataaaaa aagagaatct ttttaaaaaa aatccttgga ctagtcacg 59
<210> 26
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 26
actagtccaa ggattttttt taaaaagatt ctcttttttt atgatatttg tacataaac 59
<210> 27
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 27
gcgccattcg ccattcaggc tgcgcaactg ttgtttaaac gacaacgacc aagctcaca 59
<210> 28
<211> 50
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 28
gatgtgagct tggtcgttgt cgtttaaaca acagttgcgc agcctgaatg 50
<210> 29
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 29
tcaacagtat agaaccgtgg atgatgtggt ttctacagga tctgacatta ttattgttg 59
<210> 30
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 30
atagtcctct tccaacaata ataatgtcag atcctgtaga aaccacatca tccacggtt 59
<210> 31
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 31
agggcttacc atctggcccc agtgctgcaa tgataccgcg cgacccacgc tcaccggct 59
<210> 32
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 32
tgataaatct ggagccggtg agcgtgggtc gcgcggtatc attgcagcac tggggccag 59
<210> 33
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 33
cgatagcgcc cctgtgtgtt ctcgttatgt ttaaactact agagctccag cttttgttc 59
<210> 34
<211> 67
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 34
gtccatccaa aaaaaaagta agaatttttg aaaattcaat ataaatggag aaacaatcag 60
taactct 67
<210> 35
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 35
atcgacaaag gaaaaggggc ctgttcatat aggaatagat tcaaccaa 48
<210> 36
<211> 67
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 36
gtccatccaa aaaaaaagta agaatttttg aaaattcaat ataaatggaa aagcaatctg 60
ttacatt 67
<210> 37
<211> 49
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 37
atcgacaaag gaaaaggggc ctgtttaaat tgggatagat tcaaccaaa 49
<210> 38
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 38
actttaacgt caaggagaaa aaactataat ggaaaagcaa tctgttacat tg 52
<210> 39
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 39
gatctatcga tttcaattca attcaattta aattgggata gattcaacca aaac 54
<210> 40
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 40
tttggttgaa tctatcccaa tttaaattga attgaattga aatcgataga tc 52
<210> 41
<211> 51
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 41
aatgtaacag attgcttttc cattatagtt ttttctcctt gacgttaaag t 51
<210> 42
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 42
gagaaaaaac cccggatcca tggcggaggt ccaactcac 39
<210> 43
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 43
ggtaccaagc ttactcgagc taagcagcgg gcggcagggg 40
<210> 44
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 44
aattgttaat taagagctct caccatacat cccttgaata tc 42
<210> 45
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 45
atttttgaaa attcgaattc atgcagacgg attccgggaa 40
<210> 46
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 46
gaattcgaat tttcaaaaat tc 22
<210> 47
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 47
ggatccgggg ttttttctcc 20
<210> 48
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 48
gagaaaaaac cccggatcca tggaagcttt taccttgaag ctt 43
<210> 49
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 49
ggtaccaagc ttactcgagc tatatacgag ggatcgcgcg 40
<210> 50
<211> 37
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 50
gagaaaaaac cccggatcca tgatttccac ggccttc 37
<210> 51
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 51
ggtaccaagc ttactcgagt caaaggcatg catcgttgg 39
<210> 52
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 52
cgggatccat ggcaagctcc tttgttct 28
<210> 53
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetical nucleic acid
<400> 53
cgctcgagct acgccaatcc cttggcaa 28