基于自适应遗传学习粒子群算法的无人机任务分配方法
文献发布时间:2023-06-19 19:30:30
技术领域:
本发明涉及无人机智能巡检控制技术领域,尤其涉及基于自适应遗传学习粒子群算法的无人机任务分配方法。
背景技术:
面对日趋复杂的多样化任务需求,单架无人机携带的资源和执行任务的能力有限,难以独自完成。多无人机系统具有更灵活、容错性更高等优点,能有效且高效地执行各种复杂任务。然而,如果多架无人机只是简单地组成集群,没有良好的协同机制,则不仅不能提高无人机执行任务的效率,还可能由于系统规模的增大而带来严重的冲突和资源浪费。因此在多约束的复杂环境下,对任务进行合理的分配,是提高系统整体性能,实现多机协同的关键。
多无人机协同任务分配问题,是指将一个或一组有序任务分配给无人机,并保证系统的总体收益达到最优。该问题具有复杂度高、约束性强、计算难度大等特点,合理的问题建模和有效的求解算法对其处理至关重要。在建模时,既要考虑到无人机的数量、异构性、执行任务的能力等因素;又要考虑到任务的类别、分配的环境及各种协同的约束条件。目前已经有很多基于粒子群的方法用以处理多无人机协同任务分配问题。尽管如此,在处理不同任务场景下的多无人机协同任务分配时仍存在如下难点:1)如何建立符合实际问题的优化模型。2)如何快速有效地获得模型的最优方案。
发明内容:
为了弥补现有技术问题的不足,本发明的目的是提供一种基于自适应遗传学习粒子群算法的无人机任务分配方法,考虑设备所需援助类型的不同,定义无人机和设备之间的巡检关系未决策变量,将平均等待时间和航程距离作为任务分配方案的评价指标,并采用罚函数的方法处理问题中存在的多种约束,建立了更贴合实际的组合优化模型;采用实向量编码机制处理决策变量约束,以简化模型求解,通过两层级联结构提高算法搜索能力,有效地增强粒子群的寻优能力,灵活控制不同情况下粒子群的收敛速度,快速有效地获取模型的最优方案。
本发明的技术方案如下:
基于自适应遗传学习粒子群算法的无人机任务分配方法,包括以下步骤:
S1:针对于分散于多个机巢的n架不同类型无人机对m个分布在场景中不同位置的设备进行检测和补充物资,每个设备均需要不同数量、不同种类的物资补充,每架无人机均可携带不同数量的食物和物资以完成巡检任务,采用实向量编码机制表示无人机和任务之间的关系,构建多无人机多任务类型的模型;
S2:提出了一种自适应遗传学习粒子群算法用于求解步骤S1中的模型,获得无人机协同任务分配。
所述步骤S1具体如下:
S11:将问题具体描述为:分散于多个机巢的n架不同类型无人机对m个分布在场景中不同位置的设备进行检测和补充物资,其中,每个设备均需要不同数量、不同种类的物资补充;
S12:设全局设备集合T,其中每个设备都需要一定数量的食物、物资援助,分别对应任务集合K={1,2},无人机集合U,其中,每架无人机均可携带不同数量的食物和物资以完成巡检任务,对于每个设备,其物资援助可由不同无人机完成;
S13:定义无人机和设备之间的巡检关系未决策变量;
S14:将平均等待时间和航程距离作为任务分配方案的评价指标,并采用罚函数的方法处理问题中存在的多种约束。
所述步骤S2具体如下:
S21:采用遗传学习策略生成高质量精英种群,用以代替历史最优位置更新粒子位置,其具体包括交叉、变异、选择三种操作;
S22:在迭代进化过程中,如果连续sg次迭代生成的精英粒子适应度值均无变化,则认为该粒子的进化已经停滞,此时,对于精英粒子的每一维,通过锦标赛选择机制,选择适应度值较优的(前20%)两个pbest中更优的粒子进行修改,并且有很小的概率发生变异;
S23:通过精英种群指导粒子速度和位置更新;
S24:采用AGLPSO算法求解多无人机协同任务分配。
所述步骤S21具体如下:
首先,基于环形拓扑结构比较当前粒子i和随机粒子k的历史最优适应度值,以确定对应交叉个体中某一维度的值,进而实现交叉操作;
然后,判断交叉个体每一维度是否小于给定概率值,若是,则该维度对应的值重置为搜索空间中的一个随机值,进而实现变异操作;
最后,根据贪婪方法将变异生成的候选粒子与上一迭代中对应的精英粒子进行比较,选择更优的个体作为当前迭代的精英粒子,实现选择操作。
所述步骤S23具体如下:
采用一种自适应更新策略来改变ω的值,根据粒子群的进化速度和粒子的聚集程度灵活控制算法的收敛速度,设定进化速度阈值,当粒子群进化速度大于进化速度阈值时,算法应该保持大范围的全局寻优;当进化速度小于进化速度阈值时,算法应该进行小范围的局部搜索,以更快寻找到最优解;粒子的聚集程度取决于种群中粒子适应度值的接近程度。
所述步骤S24具体如下:
首先,根据巡检场景输入无人机和幸存者的初始信息设置算法最大迭代次数Gmax、粒子个数N、惯性权重基准值的初始值和终值、学习因子的上下限、变异率、最大停滞代数、比例因子;初始化迭代次数G=0,初始化粒子种群;
其次,计算粒子个体适应度,更新粒子历史最优位置和全局最优位置;接着,采用遗传学习策略生成精英粒子,更新全局最优位置;
然后,采用精英学习策略更新停滞精英粒子并计算惯性权重和学习因子;更新粒子速度和位置并计算粒子个体适应度,更新粒子历史最优位置和全局最优位置;
最后,得到的全局最优位置即为最优解,并对最优解解码得到算法规划出的最优巡检方案。
本发明的优点是:
1、本发明考虑设备所需援助类型的不同,定义无人机和设备之间的巡检关系未决策变量,将平均等待时间和航程距离作为任务分配方案的评价指标,并采用罚函数的方法处理问题中存在的多种约束,建立了更贴合实际的组合优化模型。
2、本发明根据无人机不同任务,采用一种实向量编码机制处理决策变量约束,能够的简化模型求解,降低问题的复杂度。
3、本发明通过两层级联结构提高算法搜索能力:第一层通过遗传学习策略生成高质量的精英粒子,并对进化停滞的粒子采用精英学习策略进行更新,以跳出局部最优;第二层利用精英粒子指导种群的搜索方向,并根据粒子群的进化速度和粒子的聚集程度,采用自适应进化策略提高算法在不同进化时期的寻优能力,两层级联结构有效地增强粒子群的寻优能力,灵活控制不同情况下粒子群的收敛速度。
附图说明:
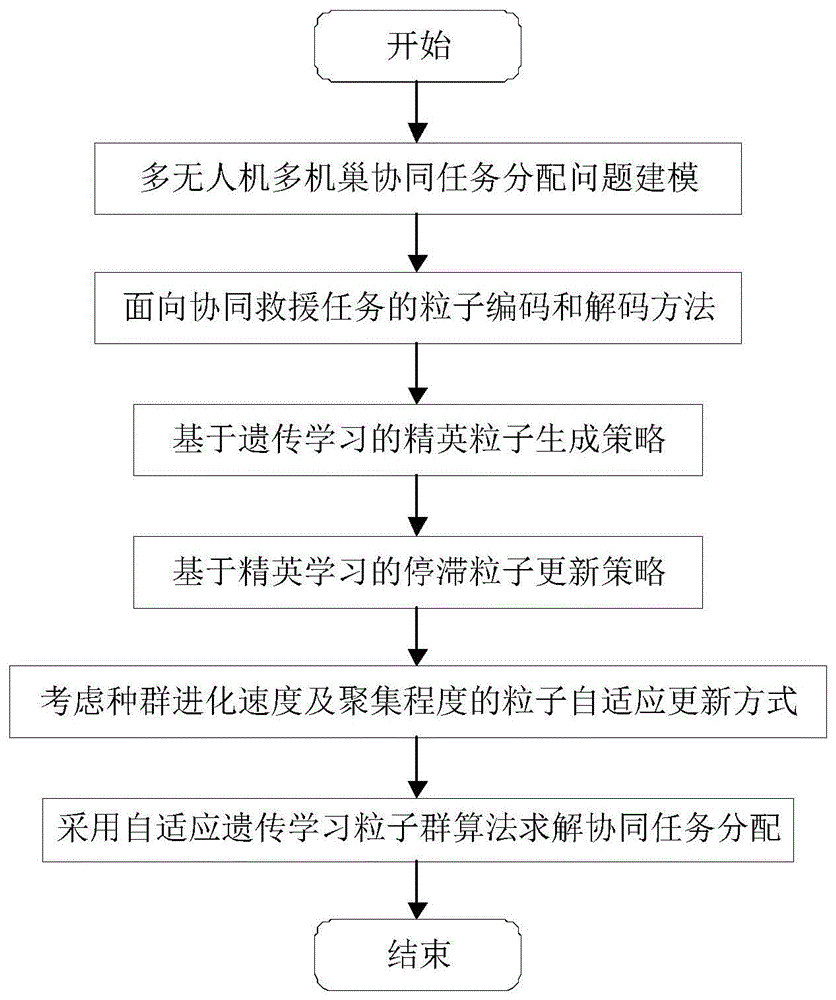
图1为本发明的方法流程图。
具体实施方式:
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
如图1所示,本发明公开的基于自适应遗传学习粒子群算法的无人机任务分配方法,包括以下步骤:
S1:针对于分散于多个机巢的n架不同类型无人机对m个分布在场景中不同位置的设备进行检测和补充物资,每个设备均需要不同数量、不同种类的物资补充,每架无人机均可携带不同数量的食物和物资以完成巡检任务,采用实向量编码机制表示无人机和任务之间的关系,构建多无人机多任务类型的模型;机巢设置在干路杆塔上;
S2:提出了一种自适应遗传学习粒子群算法用于求解步骤S1中的模型,获得无人机协同任务分配。
步骤S1具体如下:
S11:将问题具体描述为:分散于多个机巢的n架不同类型无人机对m个分布在场景中不同位置的设备进行检测和补充物资,其中,每个设备均需要不同数量、不同种类的物资补充;
S12:设全局设备集合T,其中每个设备都需要一定数量的食物、物资援助,分别对应任务集合K={1,2),无人机集合U,其中,每架无人机均可携带不同数量的食物和物资以完成巡检任务,对于每个设备,其物资援助可由不同无人机完成;
S13:定义无人机和设备之间的巡检关系未决策变量;
S14:将平均等待时间和航程距离作为任务分配方案的评价指标,并采用罚函数的方法处理问题中存在的多种约束。
步骤S2具体如下:
S21:采用遗传学习策略生成高质量精英种群,用以代替历史最优位置更新粒子位置,其具体包括交叉、变异、选择三种操作;
S22:在迭代进化过程中,如果连续sg次迭代生成的精英粒子适应度值均无变化,则认为该粒子的进化已经停滞,此时,对于精英粒子的每一维,通过锦标赛选择机制,选择适应度值较优的(前20%)两个pbest中更优的粒子进行修改,并且有很小的概率发生变异;
S23:通过精英种群指导粒子速度和位置更新;
S24:采用AGLPSO算法求解多无人机协同任务分配。
步骤S21具体如下:
首先,基于环形拓扑结构比较当前粒子i和随机粒子k的历史最优适应度值,以确定对应交叉个体中某一维度的值,进而实现交叉操作;
然后,判断交叉个体每一维度是否小于给定概率值,若是,则该维度对应的值重置为搜索空间中的一个随机值,进而实现变异操作;
最后,根据贪婪方法将变异生成的候选粒子与上一迭代中对应的精英粒子进行比较,选择更优的个体作为当前迭代的精英粒子,实现选择操作。
步骤S23具体如下:
采用一种自适应更新策略来改变ω的值,根据粒子群的进化速度和粒子的聚集程度灵活控制算法的收敛速度,设定进化速度阈值,当粒子群进化速度大于进化速度阈值时,算法应该保持大范围的全局寻优;当进化速度小于进化速度阈值时,算法应该进行小范围的局部搜索,以更快寻找到最优解;粒子的聚集程度取决于种群中粒子适应度值的接近程度。
步骤S24具体如下:
首先,根据巡检场景输入无人机和幸存者的初始信息设置算法最大迭代次数Gmax、粒子个数N、惯性权重基准值的初始值和终值、学习因子的上下限、变异率、最大停滞代数、比例因子;初始化迭代次数G=0,初始化粒子种群;
其次,计算粒子个体适应度,更新粒子历史最优位置和全局最优位置;接着,采用遗传学习策略生成精英粒子,更新全局最优位置;
然后,采用精英学习策略更新停滞精英粒子并计算惯性权重和学习因子;更新粒子速度和位置并计算粒子个体适应度,更新粒子历史最优位置和全局最优位置;
最后,得到的全局最优位置即为最优解,并对最优解解码得到算法规划出的最优巡检方案。
本发明采用两层级联结构增强算法寻优能力,具体实施如下:
步骤2.1,根据遗传学习策略生成精英种群,用于指导粒子群的搜索方向,同时根据精英学习策略对进化停滞的精英粒子进行更新
采用遗传学习策略生成高质量精英种群,用以代替历史最优位置更新粒子位置。其具体包括交叉、变异、选择三种操作,详细描述如下:
首先,基于环形拓扑结构比较当前粒子i和随机粒子k的历史最优适应度值,以确定对应交叉个体中某一维度的值,进而实现交叉操作:
其中,O
然后,交叉个体每一维度以一个很小的概率p
其中,lb
最后,根据贪婪方法将变异生成的候选粒子与上一迭代中对应的精英粒子进行比较,选择更优的个体作为当前迭代的精英粒子,实现选择操作:
其中,e
在迭代进化过程中,如果连续sg次迭代生成的精英粒子适应度值均无变化,则认为该粒子的进化已经停滞。此时,对于精英粒子的每一维,通过锦标赛选择机制,选择适应度值较优的(前20%)两个pbest中更优的粒子进行修改,并且有很小的概率p
此时,精英粒子的每一维可以从不同的较优粒子处进行学习,并有一定概率发生变异,进一步增强了种群的多样性,协助粒子跳出局部最优区域,向潜在的更优区域进行搜索。
步骤2.2,粒子群根据自适应进化策略,动态调整惯性权重和学习因子,使种群可以根据实际搜索情况,灵活控制收敛速度
通过精英种群指导粒子速度和位置更新,公式如下:
其中,x
惯性权重ω的取值对算法性能有着重要的影响。当ω较大时,算法具有较强的全局搜索能力;当ω较小时,算法则更倾向于进行局部搜索。许多文献中采用线性变化的方式更新ω的值,但是其在面对问题中具有的复杂、非线性特性时,不够灵活,性能不佳。因此,本文中采用一种自适应更新策略来改变ω的值,根据粒子群的进化速度和粒子的聚集程度灵活控制算法的收敛速度。粒子群的进化速度取决于全局最优值的变化。由于本文描述的任务分配问题是最小化目标函数的过程,所以粒子群的进化速度因子h定义如下:
其中,F
步骤3,采用自适应遗传学习粒子群算法求解多无人机协同任务分配。
采用AGLPSO算法求解多无人机协同任务分配问题过程如下:
step1:根据巡检场景输入无人机和幸存者的初始信息;
step2:设置算法最大迭代次数Gmax、粒子个数N、惯性权重ω基准值的初始值和终值ω
step3:计算粒子个体适应度,更新粒子历史最优位置和全局最优位置;
step4:采用遗传学习策略生成精英粒子,更新全局最优位置;
step5:采用精英学习策略更新停滞精英粒子;
step6:计算惯性权重和学习因子;
step7:更新粒子速度和位置;
step8:计算粒子个体适应度,更新粒子历史最优位置和全局最优位置;
step9:更新迭代次数G=G+1,判断是否满足G≤Gmax,若是则转到step4,否则算法结束,step8中得到的全局最优位置即为最优解;
step10:对最优解解码得到算法规划出的最优巡检方案。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。