用于读取树数据结构中保存的数据的方法和装置
文献发布时间:2024-04-18 19:58:21
相关申请的交叉引用
本申请要求于2021年3月31日提交的美国专利申请第17/218,937号的优先权和权益,该申请通过全文引用的方式并入本文中。
技术领域
本发明涉及数据库数据处理和分布式数据库管理领域,尤其涉及使用云原生数据库中的近数据处理(near data processing,NDP)读取树数据结构中保存的数据的方法和装置。
背景技术
随着许多公司和政府机构使用的计算机应用、平台或基础设施现在越来越多地放置在云中,对基于云的数据库即服务(database as a service,DBaaS)的需求正在迅速增加。随着市场和商业模式的转变,此类DBaaS服务由Amazon
图1示出了使用传统数据库架构的典型数据库部署。参考图1,传统数据库架构100包括结构化查询语言(structured query language,SQL)主节点110、SQL副本120以及存储节点131和132。SQL主节点110和SQL副本120彼此通信连接。SQL主节点110和SQL副本120中的每一个分别通过网络140通信连接到存储节点131和132。SQL主节点110将日志写入其自己的存储节点131,并将日志传输到SQL副本120。SQL副本120中的每一个在各自的存储节点132上应用日志。数据库的数据页面将冗余地保存在三个存储节点中,即主存储节点和与副本关联的每个存储节点。假设云中的每个存储节点通常有3个副本,在该数据库架构100中,数据页面将被保存9次,从而造成大量的资源浪费。
因此,需要一种不受现有技术的一个或多个限制影响的用于读取数据库中数据的方法和装置。
背景技术的目的是揭示申请人认为可能与本发明相关的信息。没有必要承认也不应解释任何上述信息构成与本发明相对的现有技术。
发明内容
本发明实施例的目的是提供用于使用云原生数据库中的近数据处理(near dataprocessing,NDP)读取树数据结构中保存的数据的方法和装置。根据本发明的实施例,提供了用于响应于使用云原生数据库中的近数据处理(near data processing,NDP)的查询获得一个或多个页面的方法。所述方法包括:接收查询,所述查询包括指示一个或多个所需页面的信息,所述信息还指示所述一个或多个所需页面中的每个所需页面的版本;扫描通用缓冲池以标识所述所需页面中的一个或多个所需页面。在标识所述通用缓冲池中的所述所需页面中的一个或多个所需页面时,所述方法还包括:将经标识的一个或多个所需页面复制到与所述查询关联的专用缓冲池中。在标识所述通用缓冲池中没有其它所需页面时,所述方法还包括:向一个或多个存储节点发送对剩余待标识的所述所需页面中的一个或多个所需页面的请求。所述方法还包括:接收所述一个或多个剩余所需页面;将接收到的一个或多个剩余所需页面复制到所述专用缓冲池中。
在一些实施例中,所述方法还包括:在复制所述经标识的一个或多个所需页面之前,将共享锁应用于所述经标识的一个或多个所需页面。在一些实施例中,所述一个或多个所需页面的版本由日志序列号(log sequence number,LSN)定义。在一些实施例中,所述方法还包括:在与所述一个或多个所需页面关联的B+树的根上应用共享锁。在一些实施例中,所述方法还包括:将所述接收到的一个或多个剩余所需页面复制到所述通用缓冲池中。
根据本发明的实施例,提供了一种使用云原生数据库中的近数据处理(near dataprocessing,NDP)读取数据树中数据的方法。所述方法包括:以自上而下的方式在所述数据树的根页面和内部页面上应用共享页面锁,直到到达P0,所述P0是指位于紧接在所述数据树的叶级上方的级上的页面;获取期望的日志序列号(log sequence number,LSN),同时保持所述P0上的所述共享页面锁。在获取期望LSN之后,对于每个提取的子页面,所述方法还包括:将页面从缓冲池的空闲列表分配给所述缓冲池的NDP缓存区域,所述NDP缓存区域指定用于特定查询;在将所述页面分配给所述NDP缓存区域时,判断所述子页面是否在所述缓冲池的常规页面区域找到;基于所述确定,将所述子页面固定到在所述NDP缓存区域中分配的所述页面。所述方法还包括:释放所述P0上应用的所述共享页面锁;处理分配给所述NDP缓存区域的所述页面;在处理完成后,将分配给所述NDP缓存区域的所述页面中的每个页面释放回所述缓冲池的所述空闲列表。
根据本发明的实施例,提供了一种支持云原生数据库中的近数据处理(near dataprocessing,NDP)的设备。所述设备包括:网络接口,用于从连接到网络的设备接收数据和向连接到网络的设备发送数据;处理器;机器可读存储器,存储机器可执行指令。在所述指令由所述处理器执行时,使所述设备执行上面或本文其它地方定义的一个或多个方法。
上面结合本发明的方面描述了实施例,这些实施例可以基于这些方面实现。本领域技术人员将理解,实施例可以结合描述它们的方面来实现,但也可以与该方面的其它实施例一起实现。当实施例相互排斥或彼此不兼容时,本领域技术人员将是显而易见的。一些实施例可以结合一个方面进行描述,但也可以适用于其它方面,这对本领域技术人员来说是显而易见的。
附图说明
此外,通过阅读以下结合附图所作的详细描述将容易了解本发明的特征和优势,在附图中:
图1示出了现有技术提供的使用传统数据库架构的典型数据库部署。
图2示出了实施例提供的云原生关系数据库系统的架构的示例。
图3示出了实施例提供的云原生数据库系统的架构。
图4示出了实施例提供的执行近数据处理(near data processing,NDP)的云原生数据库系统的架构。
图5示出了B+树修改引起的潜在问题。
图6示出了B+树修改引起的另一个潜在问题。
图7示出了实施例提供的包含常规页面和NDP页面的SQL节点缓冲池。
图8示出了实施例提供的用于使用云原生数据库中的近数据处理(near dataprocessing,NDP)执行查询的方法。
图9示出了实施例提供的使用NDP读取B+树数据结构中保存的数据的方法。
图10示出了实施例提供的电子设备的示意图。
需要说明的是,在所有附图中,相同的特征由相同的元件符号标识。
具体实施方式
在本发明中,术语“数据库页面”或“页面”是指用于组织数据库文件中的数据的基本内部结构。例如,数据库页面可以是一个存储单元,其大小可以在系统范围、数据库范围或集团特定的基础上配置。页面可以由标识符(identifier,ID)标识,例如页面ID或空间ID。数据库中的数据是基于数据库页面组织的。数据库页面的大小可以有所不同,例如4KB、8KB、16KB或64KB。通常,数据库页面是基于树结构(例如“B树”)组织的。
在本发明中,术语“重做日志”是指记录对数据库所做的所有更改的历史的平均值(例如文件)。通常,重做日志记录(或更通常是数据库日志)指示页面内容上的一个或多个物理更改,例如,“在页面11上,偏移120,写入5字节内容”。每个重做日志包含一个或多个重做日志记录(或更通常是数据库日志记录)。重做日志记录,也称为重做条目或日志条目,保存一组更改向量,每个更改向量描述或表示对数据库中单个块或页面所做的更改。术语“重做日志”可能源于特定的数据库管理系统(database management system,DBMS)模型;但是,重做日志也可以通常以通用方式使用,以指代数据库日志。MySQL
在本发明中,术语“日志序列号(log sequence number,LSN)”是指示日志文件中日志记录的位置或方位的数字。LSN顺序是日志生成时间的逻辑顺序。日志记录在全局重做日志缓冲区中基于LSN顺序排序。通常,日志记录按递增的LSN排序。必须严格遵守LSN顺序;否则,从数据库检索的数据将不正确。每个页面还有一个LSN值,称为页面lsn。页面lsn是最后一个页面更新时重做日志的LSN。
在本发明中,计算节点(例如SQL节点)使用“期望LSN”来请求从一个或多个数据库组件检索到的特定页面版本(例如,保存多个页面版本的Huawei Taurus
在本发明中,术语“近数据处理(near data processing,NDP)”是指能够就近对数据进行处理而不是将数据传输到处理器的数据库处理类型。一些数据库处理(例如列投影、谓词计算和数据聚合)可以推送到存储节点(如Huawei Taurus
在本发明的一些实施例中,术语“节点”是指用于执行本文定义的并与“节点”关联的一个或多个动作的物理设备或电子设备。在本发明的一些实施例中,“节点”可以被配置为逻辑结构,例如被配置为软件、硬件和固件中的一个或多个,用于执行本文定义的并与“节点”关联的一个或多个动作。
本发明提供了用于使用云原生数据库中的近数据处理(near data processing,NDP)读取/搜索树数据结构(例如B+树)中保存的数据的方法和装置。根据实施例,NDP扫描(NDP中的数据读取/搜索)不阻止B+树的并发修改,并且即使B+树正在并发修改中,也会检索一致的B+树页面。根据实施例,NDP扫描还可以与常规数据扫描共享相同的内存池(例如缓冲池)。此外,根据实施例,NDP可以利用缓冲池(例如,与常规数据扫描共享的内存池)中已经存在的页面,因此可以避免在该页面上的输入/输出(input/output,IO)。技术优势可能是搜索和读取数据树不会阻止其它查询对B+树的并发修改,同时即使B+树正在并发修改中,也会检索一致的B+树页面。
本发明提供了一种使用云原生数据库中的近数据处理(near data processing,NDP)读取在树数据结构中保存的数据的方法,所述树数据结构例如是B+树。根据实施例,期望LSN将用于主计算节点(例如主SQL节点)上的NDP页面读取。当所述主计算节点(例如主SQL节点)读取常规页面时,将使用所述常规页面的最大期望LSN(例如最新的页面版本号)。本发明的实施例使用期望LSN和页面锁定的特征。可以实现的是,页面的正确版本可以通过使用与页面关联的期望LSN结合页面锁定获得,并且可以实现一致的树结构的读取,并实现良好的读/写并发。
本发明的实施例利用NDP页面的缓冲池中的现有常规页面。这减少了输入/输出(input/output,IO),并可以确保存储节点可以服务从主计算节点(主SQL节点)请求的页面版本。
根据实施例,常规页面和NDP页面(例如定制的NDP数据)可以共享相同的内存池(即缓冲池)。在各种实施例中,内存池(缓冲池)可以通过将完整的缓冲池划分为逻辑区域来共享:用于每个NDP查询的常规页面区域和NDP缓存区域或专用缓冲池。如果当前没有执行的NDP查询,则NDP缓存区域不存在,因此所有缓冲池内存都可以由常规页面使用。
本发明的实施例在处理分布式存储节点的同时提供读/写并发。例如,当存储节点和SQL节点正在处理当前批次的叶页面时,B+树可以与NDP读取中期望LSN并发修改。
本发明的实施例在提供读/写并发的同时,可以实现内存和IO资源的高效使用。当没有发生NDP读取时,整个缓冲池可用于常规页面。此外,缓冲池中现有的常规页面可由NDP使用。
本发明的实施例能够使用短时期望LSN(即,寿命短的期望LSN)。具体地,特定的期望LSN值只能在读取该批叶页面的时段(例如读取特定等级1页面的叶页面的时段)内有效。这可能是有益的,因为存储节点不需要保留大量旧页面版本。如果使用长时期望LSN,则将给存储节点带来沉重的负担(例如开销),例如当数据库上有大量更新时,因为存储节点必须保留许多旧版本的页面。
如上所述,传统的数据库架构,至少在一些情况下,会导致性能不佳和可扩展性较差。因此,云提供商最近构建了新的云原生关系数据库系统,专为云基础架构设计。通常,许多云原生数据库将计算层与存储层分开,并提供有益的特征,如读取副本支持、快速故障切换和恢复、硬件共享和可扩展性,例如高达100太字节(terabyte,TB)。
在概念层面上,云原生关系数据库系统具有类似的架构,例如如图2所示。图2示出了Amazon Aurora
虽然每个云原生数据库系统可以具有不同的组件,但关于云原生数据库系统的进一步细节将在下面说明,例如关于数据库系统的组件和替代实现。
图3示出了实施例提供的云原生数据库系统的架构。图3所示的云原生数据库系统的架构与华为Taurus
根据实施例,云原生数据库系统300中存在四个主要组件。四个主要组件是日志存储器321、页面存储器322、存储抽象层(storage abstraction layer,SAL)330和数据库前端。这四个主要组件分布在两个物理层(即计算层310和存储层320)之间。由于只有两个物理层,因此可以最小化通过网络334发送的数据量,并且可以减少请求的时延(例如,请求可以通过网络上的单个调用完成)。SAL330是分离计算层310和存储层320的逻辑层。
计算层310包括单个SQL主节点(数据库(database,DB)主节点)311和多个读取副本(DB副本)312。单个SQL主节点(DB主节点)311处理读和写查询,因此负责处理所有数据库更新和数据定义语言(data definition language,DDL)操作。读取副本(DB副本)312只能执行读取查询,因此负责处理只读事务。数据库的读取副本视图可以设想为稍微落后于SQL主节点311的读取副本视图。包括插入、更新、删除、选择(即读取请求)等多个语句的数据库事务由计算层310中的数据库节点311和312处理。需要说明的是,数据库节点311和312可以不是物理硬件服务器,而是运行在云的物理处理资源上的软件。数据库节点311和312可以是运行在由云提供的虚拟机(例如抽象机器)或容器(例如抽象操作系统(operatingsystem,OS))上的软件(例如数据库节点311和312的实例)。通常,数据库节点311和312的实例可以被认为具有物理性,因为任何实例都是在物理机器上实现的。
数据库节点311和312中的每一个通过相应的主SAL模块331或副本SAL模块332与存储抽象层(storage abstraction layer,SAL)330通信。可以认为,SAL 330跨越数据库服务和虚拟化存储资源,并提供一个抽象层,该抽象层汇集物理资源以服务数据库服务和虚拟化存储资源。需要说明的是,SAL 330不是典型的传统数据库服务(例如,传统云服务提供商提供的数据库服务)层。云原生数据库系统300包括SAL 330,并且可以使用SAL 330来实现如下文和本文其它地方进一步讨论的功能。每个SAL模块331、332可以是在SAL 330中实现的软件实例。为了简单起见,本文中,SAL模块331、332的实例可以简称为SAL模块331、332。SAL模块331、332提供逻辑SAL330的功能。在一些示例中,SAL模块331、332的一个或多个功能可以替代地在存储层320中实现。SAL 330用于将面向客户端的前端(由计算层310提供)与数据库的组织和管理方式隔离开来。
数据(包括数据库的重做日志和页面)存储在存储层320中。存储层320可通过网络访问,例如通过远程直接内存访问(remote direct memory access,RDMA)网络访问。存储层320可以是例如由虚拟化层提供的分布式存储系统,提供相对快速、可靠和可扩展的存储。存储层320包括日志存储服务器321和页面存储服务器322。换句话说,日志存储器321和页面存储器322完全属于存储层320。日志存储器321主要用于存留由SQL主节点311生成的日志记录。日志存储器321可以保存数据库事务日志、所有重做日志和预写日志(writeahead log,WAL)。页面存储器322主要用于服务来自数据库(database,DB)主节点311或读取副本节点312的页面读取请求(即,从一个或多个页面读取数据的请求)。页面存储器322可以基于来自SQL主节点311的重做日志构造页面,并提供页面查找服务。页面存储器322可以重新创建数据库节点311和312可以请求的页面的版本(例如早期版本或当前版本)。在基于云的数据库系统300中,一个或多个页面存储器322由存储资源集群运行。每个页面存储服务器322接收或有权访问为其负责的页面产生的所有日志记录。然后,页面存储服务器322将日志合并到数据库页面中。
尽管在上面单个数据库的上下文中描述,但应当理解,在一些示例中,两个或两个以上数据库可以使用云原生数据库系统300管理(例如,利用逻辑分离来分隔各个数据库)。每个数据库都被划分为称为切片的较小的固定大小(例如10千兆字节(gigabyte,GB))的页面子集。每个页面存储器322负责相应的多个切片。由单个页面存储器322管理的切片可以包括具有来自不同数据库的页面的切片。此外,每个页面存储服务器322仅接收属于该页面存储服务器管理的切片的页面的(重做)日志。通常,数据库可以有多个切片,每个切片可以复制到多个页面存储器322,以获得持久性和可用性。例如,在一个特定页面存储器322不可用的情况下,切片已被复制到的另一个页面存储器322可用于继续服务访问来自该切片的数据(即从该切片读取数据)或修改存储在该切片中的数据(即写入该切片)的请求。在一些实施例中,日志存储器321的功能可以集成到页面存储器322中。
由主SAL模块331执行的操作包括从数据库主节点311向一个或多个数据库副本节点312发送重做日志记录更新(箭头302);发送关于重做日志的物理位置的信息(即,标识日志存储器321),以使一个或多个数据库副本节点312能够知道在哪里访问(即,读取)最新的重做日志记录,例如也如箭头302所示。主模块331还可以执行的操作包括从一个或多个页面存储器322访问(即读取)页面(即,如虚线箭头304所示);将重做日志记录写入一个或多个日志存储器321(即,如箭头305所示)和一个或多个页面存储器322(即,如箭头306所示)。由副本SAL模块332执行的操作包括从数据库主节点311接收重做日志记录更新(即,如箭头302所示);从一个或多个日志存储器321接收重做日志记录的更新(即,如箭头308所示)。
存储抽象层(storage abstraction layer,SAL)330是一个库,它将现有数据库前端(例如MySQL
每个数据库节点311、312可以由相应的SAL模块331、332(如图所示)服务。在一些示例中,服务于SAL模块331和副本SAL模块332两者的功能的SAL模块的单个实例可以服务两个或两个以上数据库节点311、312。在一些示例中,这样的SAL模块的单个实例可以服务云原生数据库系统300中的所有数据库节点311、312。在一些示例中,SAL 330可以使用可以在虚拟机上、容器中或物理服务器上运行的一个或多个独立SAL模块331、332来实现。在一些实施例中,SAL330的功能可以直接集成到现有数据库代码中,而不使用单独的库。但是,应理解,解析日志并将解析后的日志发送到不同的页面存储器322的功能在传统的数据库内核代码中并不存在。
每当数据库被创建或扩展时,SAL330选择页面存储器322并在所选择的页面存储器上创建切片。每当数据库前端决定刷新日志记录时,全局刷新缓冲区中的日志记录就会被发送到SAL 330。SAL 330首先将日志记录写入当前活动的日志存储副本321,以保证它们的持久性。一旦日志记录成功写入所有日志存储副本321,其写入可以被确认到数据库,并且日志记录被解析,随后也被分发到每切片刷新缓冲区。这些切片缓冲区随后在缓冲区已满或超时到期时被刷新。
在传统的数据处理中,结构化查询语言(structured query language,SQL)查询需要将网络上的所有数据从数据存储器中提取到计算节点(如SQL节点),然后在计算节点中执行投影、谓词计算和聚合等。这可能是一个重要的过程,特别是对于分析查询,因为分析查询可能需要访问和聚合大量数据。此外,这种分析查询可能需要执行完整的数据库表扫描,这可能是一个非常大的任务,因为分析查询通常是临时的,因此没有预先构建索引来为它们服务。
如上所述,近数据处理(near data processing,NDP)能够就近对数据进行处理,例如将一些SQL运算符带入存储节点。因此,NDP在存储节点内部进行预评估,以过滤掉不必要的数据集,然后仅将此数据的匹配子集返回给计算节点(如SQL节点)进行进一步处理。
部署NDP后,可以避免分析查询产生大量页面流量。例如,NDP查询任务的一部分(例如一些数据库处理任务,如投影、谓词计算和聚合)可以移动到存储节点,从而释放至少一些资源(例如SQL层中央处理单元(central processing unit,CPU))。因此,使用NDP,分析查询对在线事务处理(online transaction processing,OLTP)操作的影响较小。在一些情况下,事务处理(例如OLTP)和分析处理(例如在线分析处理(online analyticalprocessing,OLAP))可以在一定程度上并发执行。例如,当OLAP任务使用较少的计算节点(例如SQL节点)资源,从而使更多的计算节点(例如SQL节点)资源可用于OLTP任务时,这种并行处理是可能的。
如上所述,NDP减少了页面读取和其它网络输入/输出(input/output,IO)操作,因此可以加快查询速度。因此,由于数据量的减少和页面读取的数量的减少,所需的带宽和每秒输入/输出操作次数(input/output operations per second,IOPS)可以相应地减少。
以下查询示例说明了如何执行NDP:
SELECT c_name FROM customer WHERE c_age>20
参考上面的查询,考虑到列投影,只需要从存储节点向计算节点(例如SQL节点)发送列c_name。考虑到谓词计算,只有满足“c_age>20”的行才需要从存储节点发送到计算节点(例如SQL节点)。
以下是另一个查询示例,说明如何在考虑聚合的情况下执行NDP。
SELECT count(*)FROM customer
上面的查询返回行数,因此只需要从存储节点发送“行数”到计算节点(例如SQL节点)。
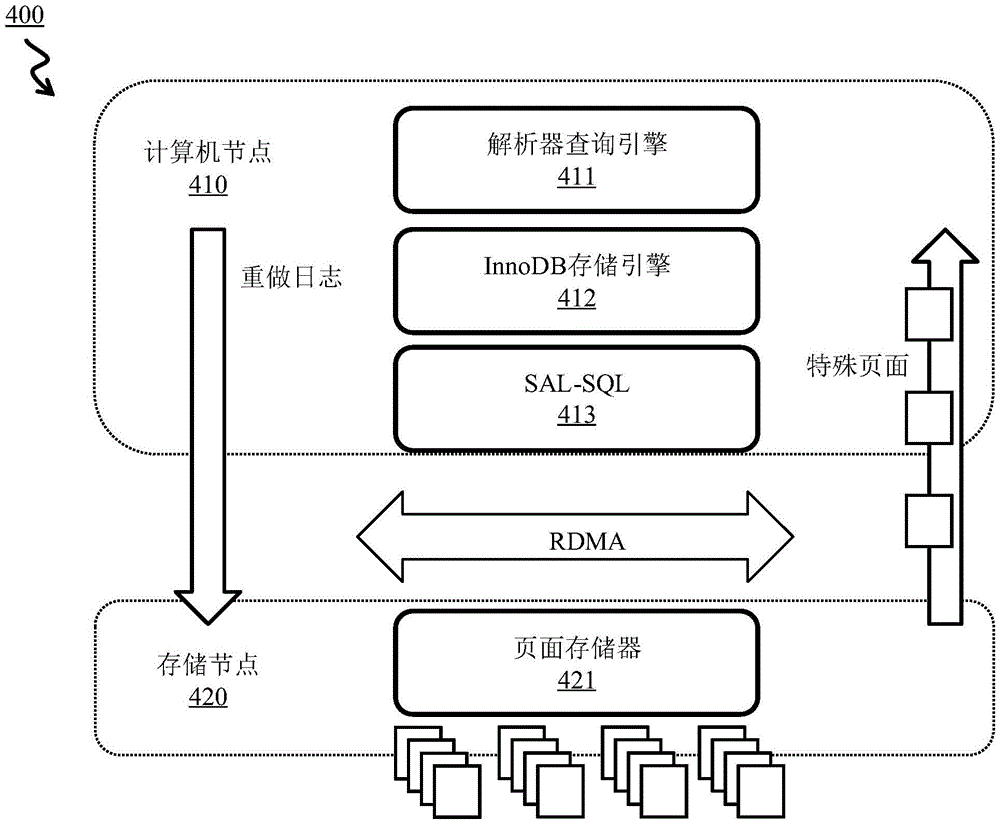
图4示出了实施例提供的执行近数据处理(near data processing,NDP)的云原生数据库系统的架构。图4所示的云原生数据库系统的架构与GaussDB
计算节点(SQL节点)410包括解析器查询引擎411、InnoDB存储引擎412和SAL SQL模块413。解析器查询引擎411是分析SQL查询(例如解析和识别查询)并确定NDP等高效执行机制的SQL优化器。解析器查询引擎411支持一些SQL命令(例如“排序”、“聚合”、“连接”和“分组”)的多线程并行执行。解析器查询引擎411提供代码生成(code-gen)技术(例如,基于低级虚拟机(low level virtual machine,LLVM)的代码生成技术)以提高查询的执行性能。InnoDB存储引擎412支持批量页面向下推送到存储节点,从而减少输入/输出请求。InnoDB存储引擎412是多版本并发控制(multi-version concurrency control,MVCC)存储引擎,使得单行的多个版本可以同时存在。SAL SQL模块413使计算节点410能够与底层存储节点420交互。
存储节点420包括服务来自计算节点(SQL节点)410的页面读取请求的页面存储器421。存储节点420支持NDP操作,例如投影、预测、聚合和MVCC。
假设计算节点410和存储节点420分离,没有近数据处理(near data processing,NDP),数据必须穿过计算节点410与存储节点420之间的网络。例如,在处理计算节点410之后,数据将被来回几次写回存储节点420,效率较低。使用NDP,计算节点410将重做日志传输到存储节点420,并且存储节点420仅向计算节点410返回具有过滤掉不必要数据集的匹配子集(例如特殊页面)。由于大量数据集不必通过网络传输,因此所需的网络带宽和I/O资源可以显著减少。
计算节点(例如SQL节点)具有其本地页面缓存(或缓冲池),以保存数据库事务要访问的页面。在传统的查询处理下(即没有NDP),所有B+树页面都被读入缓冲池,使用页面锁定来协调同一数据页面上的并发读写。但是,由于从存储节点接收的NDP数据是为特定查询定制的,因此此类NDP数据不应与其它查询共享。此外,分布式云存储节点可以在不同的时间接收数据页面上的更新。这些因素对如何协调NDP读取B+树和同时修改B+树的其它事务提出了挑战。
图5示出了B+树修改引起的潜在问题。参考图5,B+树500包括内部页面P1 510及其四个子页面P3 530、P4 540、P5 550和P6 560。子节点P3 530、P4 540、P5 550和P6 560可以是叶页面。包含在页面P5 550中的数据位于存储节点501中,而包含在页面P6 560中的数据位于存储节点502中。换句话说,页面P5 550可以直接访问存储节点501,页面P6560可以直接访问存储节点502。
在图5中,假设已经进行页面P5 550和页面P6 560上的NDP请求,但该请求当前尚未到达存储节点501和502。在这个假设下,当并发事务修改页面P5 550和页面P6 560时,存储节点501将接收包含在新页面P5 551中的数据,但存储节点502将不接收包含在新页面P6561中的数据。换句话说,在NDP请求时,存储节点501和502将分别返回包含新页面P5 551和旧页面P6 560的数据,因此在扫描期间在旧页面P6 560中找不到数字“20”,从而呈现不正确的查询结果。
图6示出了B+树修改引起的另一个潜在问题。类似于图5中所示的B+树500,图6中的B+树600包括内部页面P1 610及其四个子页面P3 630、P4 640、P5 650和P6 660。子页面P3 630、P4 640、P5 650和P6 660可以是叶页面。
在图6中,假设页面P4 640上的NDP请求已经完成,并且查询正在处理页面P4 640中的行。还假设,在处理查询时,发生了导致删除页面P5 650的另一个事务。
作为删除页面P5 650的一部分,页面P4 640的“下一个页面”标识符(identifier,ID)应改为页面P6 660的页面ID,如图6底部所示。但是,由于页面P4 640是针对上述查询(即,处理页面P4 640中的行的查询)定制的,因此在处理查询时,页面P4 640将页面P5650作为下一个页面。当NDP查询继续读取页面P5 650时,这将呈现不正确的查询结果,因为例如页面P5 650已经被重新分配到B+树600的另一部分,或者甚至被重新分配到不同的B+树。
Amazon Aurora
可以意识到,Amazon Aurora
本发明的实施例提供了一种使用云原生数据库中的近数据处理(near dataprocessing,NDP)读取在树数据结构中保存的数据的方法,所述树数据结构例如是B+树。根据实施例,NDP扫描(例如,NDP中的数据读取/搜索)不阻止B+树的并发修改,并且即使B+树正在并发修改中,也会检索一致的B+树页面。NDP扫描还与常规数据扫描共享相同的内存池(例如,相同的缓冲池)。此外,NDP可以利用缓冲池(例如,与常规数据扫描共享的内存池)中已经存在的一个或多个页面,并且可以避免这些一个或多个页面的输入/输出(input/output,IO)。
根据实施例,缓冲池中的内存用于存储从存储节点接收的NDP页面。与特定查询关联的NDP所使用的缓冲池页面不保存在计算节点(例如SQL节点)中的缓冲池数据管理结构中,如哈希映射、最近最少使用(least recently used,LRU)列表和刷新列表中。因此,与特定查询关联的NDP的缓冲池页面可以被有效地隐藏或与其它数据库事务分离,因此不受计算节点(例如SQL节点)中的缓冲池刷新和驱逐过程的影响。NDP页面的分配和释放完全受请求NDP的查询的控制。这样做的优点是在常规扫描与NDP扫描之间共享内存池,同时保持NDP页面和常规页面彼此分离。
根据实施例,期望日志序列号(log sequence number,LSN)包括在对存储节点的NDP请求中。由于期望LSN指示页面版本,因此存储节点可以使用期望LSN提供所请求页面的特定版本。与该查询关联的NDP不会看到对这些页面的任何并发修改,因为仅读取特定版本的页面(例如,版本化页面读取)。为了便于说明,基于期望LSN读取页面可以被视为在某个时间点拍摄B+树的快照。使用期望LSN的优点在于,即使在存储节点和计算节点(例如SQL节点)处理NDP页面时,B+树数据结构被并发修改(即对B+树并发修改),也可以为NDP B+树读取保持页面一致性。
根据实施例,在向存储节点发送NDP请求之前,搜索缓冲池,以确定(请求的)页面是否已经存在于缓冲池中。如果存在这样的页面,则该页面将复制到预分配的NDP页面内存(也是缓冲池的一部分)中,从而避免与该页面的存储节点关联的一个或多个额外IO事务。
图7示出了本发明的实施例提供的包含常规页面和NDP页面的SQL节点缓冲池。参考图7,SQL节点缓冲池700包括空闲列表710、哈希映射720、LRU列表730和刷新列表740。在另一方面,SQL节点缓冲池700在逻辑上被划分为公共常规页面区域760或通用缓冲池以及专用NDP缓存区域770和780,每个区域都是与特定查询关联的专用缓冲池。常规页面包含在公共常规页面区域760中,NDP页面包含在专用NDP缓存区域770和780中。常规页面由缓冲池结构管理,例如哈希映射720、LRU列表730和刷新列表740。NDP页面由请求NDP页面的(NDP)查询Q1 751和Q2 752管理。常规页面和NDP页面都是从空闲列表710获取的,并且在被驱逐或释放时可以返回到空闲列表710。常规页面和NDP页面共享SQL节点缓冲池700。
根据实施例,期望LSN将用于NDP页面读取。当所述主计算节点(例如主SQL节点)读取常规页面时,将使用所述常规页面的最大期望LSN(例如最新的页面版本号)。在图7的情况下,NDP查询Q2 752从其专用NDP缓存区域780读取页面P3。NDP页面读取携带期望LSN,例如LSN=5000。该主SQL节点中的另一个事务是从常规页面区域760读取页面P3。假设SQL节点缓冲池700在主SQL节点中,常规页面读取(例如,从常规页面区域760读取页面P3)总是携带最大期望LSN。这意味着需要请求的常规页面的最新版本。
根据实施例,如果页面已经存在于公共常规页面区域中,则根据NDP查询对这些页面的请求,现有常规页面将被复制到NDP查询的专用缓存区域。参考图7,假设NDP查询Q1751需要读取页面P2、P3和P4。在这个示例中,由于页面P3已经存在于公共常规页面区域760中,因此页面P3将被复制到NDP查询Q1 751的专用NDP缓存区域770中。NDP查询Q1 751使用期望LSN(例如LSN=6000)读取页面P2和P4。
图8示出了实施例提供的用于使用云原生数据库中的近数据处理(near dataprocessing,NDP)获取用于查询的页面的方法。应当理解,使用NDP可以定义执行处理的方式,例如NDP是指能够就近对数据进行处理的数据库处理范式,例如将一些SQL运算符带入存储节点。
该方法包括接收(810)查询,该查询包括指示一个或多个所需页面的信息,该信息还指示一个或多个所需页面中的每个所需页面的版本。应当理解的是,查询可以定义一个问题或要在存储在数据库中的一个或多个所需页面上采取或执行的一组动作。该方法还包括扫描(820)通用缓冲池以标识所需页面中的一个或多个。例如,扫描可以是指可以执行的一个或多个动作,以便确定、查找或标识通用缓冲池中存在所需页面。例如,扫描可能需要搜索标记、哈希、日志序列号、可能与所需页面关联的其它标识符。扫描也可以被解释为对通用缓冲池中存在的页面与所需页面进行完整或部分比较。应当理解的是,扫描的类型可以取决于包括在查询中的信息。
在标识通用缓冲池中的一个或多个所需页面时,该方法还包括将经标识的一个或多个所需页面复制(830)到与查询相关联的专用缓冲池中。根据实施例,专用缓冲池是与节点关联的缓冲区的一部分,专门分配给查询。通过分配给查询,专用缓冲池与例如另一个查询分离,并且不可访问。
在标识通用缓冲池中没有其它所需页面时,该方法还包括向一个或多个存储节点发送(840)对剩余待标识的所需页面中的一个或多个所需页面的请求。该方法还包括接收(850)一个或多个剩余所需页面,并将接收到的一个或多个剩余所需页面复制(860)到专用缓冲池。根据实施例,一个或多个剩余所需页面可用于定义在通用缓冲池中不存在的一个或多个所需页面。由于查询需要这些一个或多个所需页面,节点仍然必须获取这些未找到的所需页面(剩余所需页面),以便执行与查询关联的一个或多个动作。例如,如果查询包括指示页1和2是所需页面的信息,并且在扫描通用缓冲池期间,只有页1被标识为存在于通用缓冲池中,则可以意识到页2是剩余所需页面。
根据实施例,一旦所需页面存在于专用缓冲池内,就可以采取其它动作来满足或响应查询。例如,查询可以定义与存储在数据库中的一些数据相关的问题,并且其它动作可以定义与所需页面关联执行的一个或多个步骤,以便确定、评估或计算查询的答案或结果。
在一些实施例中,所述方法还包括:在复制所述经标识的一个或多个所需页面之前,将共享锁应用于所述经标识的一个或多个所需页面。例如,共享锁可以定义一个特征,其中,页面被锁定以防止修改,但页面仍保持打开状态,以供其它搜索访问。在一些实施例中,该方法还包括一旦经标识的一个或多个所需页面被复制,则释放共享锁。
在一些实施例中,该方法还包括:在与所述一个或多个所需页面关联的B+树的根上应用共享锁。在一些实施例中,该方法还包括释放B+树的根上的共享锁。
在一些实施例中,一个或多个所需页面的版本由日志序列号(log sequencenumber,LSN)定义。在一些实施例中,该方法还包括:将接收到的一个或多个剩余所需页面复制到通用缓冲池中。
图9示出了本发明的实施例提供的使用近数据处理(near data processing,NDP)读取B+树数据结构中保存的数据的方法900。应当理解,下面所示的步骤可以由图3所示的云原生数据库系统300的组件执行。例如,涉及与数据库主节点的通信的步骤可以由主SAL模块331(即,与数据库主节点311关联的SAL模块)执行,并且涉及与数据库副本节点的通信的步骤可以由副本SAL模块332(即,与数据库副本节点312关联的SAL模块)执行。
在步骤910,数据库系统的计算节点(例如SQL节点)从顶层向下遍历B+树结构,并在根和每个内部页面上应用共享页面锁,直到到达级别1页面。术语“级别1”是指B+树数据结构中紧靠叶级别(即级别0)上方的级别。级别1页面在下文中称为页面P0。根据实施例,查询缓存到其NDP缓存区域(例如,与查询关联的专用缓冲池)中的所有页面都是叶页面(即级别0页面)。
在页面P0上,计算节点搜索指向接下来要访问的级别0页面(叶级别页面或叶页面)的记录。接下来要访问的该级别0页面在下文中称为页面Ps。在各种实施例中,B+树搜索可以以定位树中的最小值或特定值为目标启动。
在步骤920,如果计算节点是主SQL节点,则在保持页面P0上的共享锁的同时,计算节点将页面的最新LSN记录为用于在步骤940要提交的NDP请求的期望LSN。如果计算节点是副本SQL节点,则使用页面读取中的期望LSN,因为页面读取携带期望LSN。
根据实施例,计算节点在保持页面P0上的共享锁的同时记录最新的LSN。共享锁防止另一个查询对页面P0进行修改,以便LSN可以表示以页面P0为根的一致子树(例如,确保树结构的一致性)。换句话说,共享锁确保没有其它事务(例如来自其它查询的动作)可以更改以页面P0为根的子树上的树结构,因为要执行的任何此类更改都需要在页面P0上使用排他锁。例如,没有其它事务可以删除页P0的子叶页面或将行从子叶转移到其同级等。因此,LSN表示以页面P0为根的一致子树结构。
根据实施例,特定期望LSN的值仅在读取特定等级1页面的叶页面的时段内有效。也就是说,特定期望LSN值的生存期很短,因此存储节点不需要保留所有旧版本的页面。如果期望LSN具有较长的生存期,这可能会给存储节点带来沉重的负担(例如,增加所需的开销),例如当数据库上有大量更新时,因为存储节点必须保留许多旧版本的页面,以便在较长的生存期内为期望LSN提供服务。
从页面Ps之后的记录开始,对页面P0上的剩余记录重复步骤910和920。页面P0上的每个记录指示页面P0的每个子页面Pi的页面ID,其中,1≤i≤n,并且,n是页面P0的子页面的数量。需要说明的是,对于特定的P0,步骤910和920仅执行一次。一旦P0被共享锁定,P0上的记录的迭代将继续。需要说明的是,在这些迭代期间,P0保持共享锁定。因此,在P0上的记录的迭代期间,P0没有释放和重新锁定(共享锁)。
在步骤930,计算节点从页面P0上的每个记录中提取页面ID。提取的页面ID被记录或表示为页面Pi的页面ID。换句话说,计算节点从页面P0中提取子页面ID。
对于每个页面Pi,重复步骤940至950所示的以下任务,直到页面P0中的所有记录都被处理,或直到满足预定义的条件。在步骤940,计算节点分配缓冲池空闲列表(例如,图7中的空闲列表710)中的页面以存储页面。计算节点将缓冲池空闲列表中的页面分配到查询的NDP缓存区域(例如与特定查询关联的专用缓冲池)。计算节点不将缓冲池中的页面分配到指定用于哈希映射(例如图7中的哈希映射720)、LRU列表(例如图7中的LRU列表730)或刷新列表(例如图7中的刷新列表740)的内存区域中。
一旦缓冲池空闲列表中的页面被分配,计算节点就会从缓冲池的常规页面区域中搜索页面Pi的页面ID。如果在缓冲池的常规页面区域中找到页面Pi,则计算节点将共享锁应用于页面Pi,将页面Pi复制到分配的页面(例如,从而保护分配的页面Pi),然后释放页面Pi上的共享锁。例如,共享锁可以定义一个特征,其中,页面被锁定以防止修改,但页面仍保持打开状态,以供其它搜索访问。但是,如果页面Pi上有排他锁,这表明有另一个事务正在修改页面Pi,则计算节点将不会将共享锁应用到页面Pi,直到排他锁被释放。例如,排他锁可以定义一个特征,其中,页面被锁定以防止所有修改和访问,直到排他锁被释放,但页面仍保持打开状态,以供其它搜索访问。在这种情况下,复制到NDP缓存区域的页面Pi可以被认为是比期望LSN更新的版本。但是,可以意识到,将共享锁应用于页面Pi的延迟是可以接受的,因为在排他锁期间修改页面Pi不会改变子树结构。
另一方面,如果在缓冲池的常规页面区域中没有找到页面Pi,则计算节点使用期望LSN向存储节点提交页面Pi的NDP请求。此请求可以是异步NDP请求。计算节点随后将从存储节点获取页面Pi,并且获取的页面将被分配到缓冲池空闲列表中,此外还将保存在查询的NDP缓存区域,即与查询关联的专用缓冲池。
根据实施例,从缓冲池的常规页面区域搜索页面P
根据实施例,在步骤930和940中发送到存储节点的最后一个页面被标记为“最后一个页面”。当存储节点处理该“最后一个页面”时,在步骤950,存储节点可以将最后一个页面(Pn)的最后一行发送回计算节点(SQL节点),即使查询不需要该行。这个值(例如,页面上最后记录的值)将在步骤970中使用。根据实施例,存储节点将最后一个页面(Pn)的最后一行发送回计算节点的动作不必作为单独的IO请求提供,并且该动作可以包括在对最后一个页面的请求中。
根据实施例,在步骤930和940产生的页面按其逻辑顺序(例如叶页面的同级顺序)在列表中链接或排序。如果该页面尚未出现在常规页面区域中,则计算节点将页面Ps加载到常规页面区域中。共享页面锁将被释放,但页面Ps上的共享锁除外。需要说明的是,页面Ps(即在下一次NDP B+树遍历期间访问的第一页面)被读取为常规页面。
根据实施例,如果在步骤930至950中存在多个页面要提交给存储节点,则这些页面可以放入一个IO请求中。这种向存储节点进行页面提交的优化可以降低计算节点(SQL节点)与存储节点之间的每秒输入/输出操作次数(input/output operations per second,IOPS)。
在步骤960,计算节点释放应用于页面P0的共享锁,从而可以对子树进行并发修改。根据实施例,如果在步骤940期间使用异步IO,则一旦Pn上的IO请求(例如最后一个页面)被提交,P0上的共享锁就可以被释放。因此,在这种情况下,不要求计算节点在释放P0上的共享锁之前等待IO请求完成。因此,能够在IO完成之前释放共享锁在NDP上下文中可能是有益的,因为NDP-IO通常比常规IO需要更长的时间才能完成,例如,因为存储节点必须为NDP-IO执行SQL相关计算。
在完成对页面Ps上的行的处理之后,在步骤970,计算节点处理第一缓存页面(在步骤930和940产生的NDP页面,例如已经复制到与查询关联的专用缓冲池中的页面)。缓存页面(NDP页面)按逻辑顺序处理(例如,基于它们在列表中链接的事实)。当完成对特定缓存页面的处理时,计算节点将该特定页面释放回缓冲池空闲列表。重复步骤970,直到处理所有缓存页面。
当没有更多的缓存页面要处理时(即,在完成NDP页面P1至Pn上的行处理之后),计算节点基于当前页面是在NDP缓存区域还是在常规页面区域中确定下一个页面ID(例如,重新定位到B+树中)。如果当前页面在NDP缓存区域中,则页面上最后一个记录的值用于发起B+树搜索(即返回步骤910),因为页面Pn中记录的下一个页面ID不是可信任的。页面Pn的下一个页面ID(例如,位于下一个同级叶中的页面Pn+1的页面ID)不是可信任的,因此无法使用,因为页面Pn+1可能已从B+树中删除。因此,需要另一个B+树搜索来定位下一个同级叶页面。
另一方面,如果当前页面是常规页面,则下一个页面ID是可信的,因为共享锁被应用在常规页面上。因此,下一个页面ID是页面Pn的下一个页面ID。如果计算节点是主SQL节点,则计算节点在保持页面P0上的共享锁的同时,将所需页面的最新LSN记录或表示为期望LSN。如果计算节点是副本SQL节点,则使用页面读取中的期望LSN,因为页面读取携带期望LSN。计算节点释放当前页面上的共享锁,并执行如上所述的步骤940。页面Pn的页面ID可以标记为“最后一个页面”。计算节点随后执行步骤970。
图10是本发明的不同实施例提供的可以执行本文中显式或隐式描述的上述方法和特征的任何或全部操作的电子设备1000的示意图。例如,能够执行用于上述方法和特征操作的指令的专用硬件可以配置为电子设备1000。电子设备1000可以是形成协调器、平台控制器、物理机器或服务器、物理存储服务器或数据存储设备的一部分的设备。
如图所示,设备包括处理器1010,例如,中央处理单元(central processingunit,CPU)或专用处理器,例如图形处理单元(graphics processing unit,GPU)或其它这样的处理器单元、存储器1020、非瞬时性大容量存储器1030、I/O接口1040、网络接口1050和收发器1060,所有这些都通过双向总线1070通信耦合。根据某些实施例,可以使用任何或所有所描绘的元件,或者仅使用元件的子集。此外,设备1000可以包括某些元件的多个实例,例如多个处理器、存储器或收发器。此外,硬件设备的元件可以直接耦合到没有双向总线的其它元件。除了处理器和存储器之外,可以使用集成电路等其它电子元件来执行所需的逻辑操作。
存储器1020可包括任何类型的非瞬时性存储器,例如静态随机存取存储器(static random access memory,SRAM)、动态随机存取存储器(dynamic random accessmemory,DRAM)、同步DRAM(synchronous DRAM,SDRAM)、只读存储器(read-only memory,ROM)或其组合等。大容量存储器1030可以包括任何类型的非瞬时性存储设备,例如固态驱动器、硬盘驱动器、磁盘驱动器、光盘驱动器、USB驱动器或用于存储数据和机器可执行程序代码的任何计算机程序产品。根据某些实施例,存储器1020或大容量存储器1030可以在其上记录了由处理器1010可执行的用于执行上述任何方法操作的语句和指令。
通过上述实施例的描述,本发明可以仅通过硬件实现,也可以通过软件和必要的通用硬件平台实现。基于这样的理解,本发明的技术方案可以以软件产品的形式体现。软件产品可以存储在非易失性或非瞬时性存储介质中,非易失性或非瞬时性存储介质可以是光盘只读存储器(compact disk read-only memory,CD-ROM)、USB闪存盘或移动硬盘。软件产品包括许多指令,这些指令使得计算机设备(个人计算机、服务器或网络设备)能够执行本发明实施例中提供的方法。例如,这样的执行可以对应于如本文所述的逻辑操作的模拟。根据示例性实施例,软件产品可以附加地或替代地包括多个指令,这些指令使得计算机设备能够执行配置或编程数字逻辑装置的操作。
尽管已经参考本发明的特定特征和实施例描述了本发明,但是明显在不脱离本发明的情况下可以制定本发明的各种修改和组合。说明书和附图仅被视为所附权利要求书所定义的本发明的说明并且考虑落于本说明书的范围内的任何和所有修改、变体、组合或均等物。
- 一种用于使数字信号和相关码相关的方法、装置、计算机程序、芯片组或数据结构
- 数据写入方法、数据读取方法、装置和服务器
- 数据结构管理装置、数据结构管理系统、数据结构管理方法以及用于记录数据结构管理程序的计算机可读介质
- 适用于闪存的数据结构及其数据写入方法和数据读取方法