信息的识别方法、系统、计算设备及存储介质
文献发布时间:2023-06-19 10:57:17
技术领域
本申请涉及计算机技术领域,尤其涉及一种信息的识别方法、系统、计算设备及存储介质。
背景技术
随着信息技术的发展,通信网络可以实现信息之间的交互,从而方便人们的生活,例如,用户可以通过通信网络进行语音通信、线上购物、线上娱乐以及线上理财、缴费等等,相应的,作为信息的接收载体也成为用户生活中不可或缺的一部分,例如,手机、电脑等等。基于此,信息的接收载体会接收到大量不明信息,特别是语音信息,从而给用户带来许多不良的体验,更甚的还会给用户带来经济损失。
发明内容
本申请提供一种信息的识别方法、系统、计算设备及存储介质,用以较为自动地识别不明信息的类别,提高用户体验。
本申请实施例提供一种信息的识别方法,包括:接收通信语音请求,在所述通信语音请求的来源不属于预置来源的情况下,获取通信语音对应的语音文本;根据所述语音文本,获取语音文本对应的语音对话文本;根据所述语音对话文本,识别所述语音对话文本所属类别。
本申请实施例提供一种声纹库的建立方法,包括:建立非正常声纹库,所述非正常声纹库是根据非正常声纹得到的。
本申请实施例提供一种信息的识别方法,包括:接受转发的通信语音请求,并获取语音信息对应的语音文本;根据所述语音文本,获取语音文本对应的语音对话文本;根据所述语音对话文本,识别所述语音对话文本所属类别。
本申请实施例提供一种信息的识别方法,包括:当接收到通信语音请求,且在所述通信语音请求的来源不属于预置来源的情况下,通过智能音箱接收通信语音,并屏蔽接收用户语音以及屏蔽向用户提供通信语音;通过智能音箱获取通信语音对应的语音文本;通过智能音箱根据所述语音文本,获取语音文本对应的语音对话文本;通过智能音箱根据所述语音对话文本,识别所述语音对话文本所属类别。
本申请实施例还提供一种信息的设置方法,包括:获取用户通信语音标识;将所述用户通信语音标识与转接通信语音标识进行绑定,以使在预置条件下根据绑定关系,将通信语音请求转发至所述转接通信语音标识所属设备;设置所述预置条件。
本申请实施例还提供一种信息的设置方法,包括:提供通信语音标识的绑定界面,所述绑定界面中展示了用户通信语音标识输入区域、转接通信语音标识输入区域以及预置条件输入区域,所述用户通信语音标识与所述转接通信语音标识具有绑定关系;响应于用户的输入操作,确定对应输入区域中的所述用户通信语音标识以及转接通信语音标识;响应于用户的输入操作,确定对应输入区域中的所述预置条件,在所述预置条件下,转发通信语音请求至所述转接通信语音标识所属设备;响应于绑定操作,完成绑定关系的操作。
本申请实施例还提供一种信息的识别系统,包括:第一设备和第二设备;所述第一设备,接收通信语音请求,在所述通信语音请求的来源不属于预置来源的情况下,转发通信语音请求至所述第二设备;所述第二设备,接收通信语音请求,并获取通信语音对应的语音文本;根据所述语音文本,获取语音文本对应的语音对话文本;根据所述语音对话文本,识别所述语音对话文本所属类别。
本申请实施例还提供一种计算设备,包括存储器以及处理器;所述存储器,用于存储计算机程序;所述处理器,用于执行所述计算机程序,以用于:建立非正常声纹库,所述非正常声纹库是根据非正常声纹得到的。
本申请实施例还提供一种计算设备,包括存储器、处理器以及通信组件;所述存储器,用于存储计算机程序;所述通信组件,用于接收通信语音请求;所述处理器,用于执行所述计算机程序,以用于:在所述通信语音请求的来源不属于预置来源的情况下,获取通信语音对应的语音文本;根据所述语音文本,获取语音文本对应的语音对话文本;根据所述语音对话文本,识别所述语音对话文本所属类别。
本申请实施例还提供一种计算设备,包括存储器以及处理器;所述存储器,用于存储计算机程序;所述处理器,用于执行所述计算机程序,以用于:获取用户通信语音标识;将所述用户通信语音标识与转接通信语音标识进行绑定,以使在预置条件下根据绑定关系,将通信语音请求转发至所述转接通信语音标识所属设备;设置所述预置条件。
本申请实施例还提供一种计算设备,包括存储器以及处理器;所述存储器,用于存储计算机程序;所述处理器,用于执行所述计算机程序,以用于:提供通信语音标识的绑定界面,所述绑定界面中展示了用户通信语音标识输入区域、转接通信语音标识输入区域以及预置条件输入区域,所述用户通信语音标识与所述转接通信语音标识具有绑定关系;响应于用户的输入操作,确定对应输入区域中的所述用户通信语音标识以及转接通信语音标识;响应于用户的输入操作,确定对应输入区域中的所述预置条件,在所述预置条件下,转发通信语音请求至所述转接通信语音标识所属设备;响应于绑定操作,完成绑定关系的操作。
本申请实施例还提供一种计算设备,包括存储器以及处理器;所述存储器,用于存储计算机程序;所述处理器,用于执行所述计算机程序,以用于:接受转发的通信语音请求,并获取语音信息对应的语音文本;根据所述语音文本,获取语音文本对应的语音对话文本;根据所述语音对话文本,识别所述语音对话文本所属类别。
本申请实施例还提供一种计算设备,包括存储器以及处理器;所述存储器,用于存储计算机程序;所述处理器,用于执行所述计算机程序,以用于:当接收到通信语音请求,且在所述通信语音请求的来源不属于预置来源的情况下,通过智能音箱接收通信语音,并屏蔽接收用户语音以及屏蔽向用户提供通信语音;通过智能音箱获取通信语音对应的语音文本;通过智能音箱根据所述语音文本,获取语音文本对应的语音对话文本;通过智能音箱根据所述语音对话文本,识别所述语音对话文本所属类别。
本申请实施例还提供一种存储有计算机程序的计算机可读存储介质,计算机程序被一个或多个处理器执行时,致使所述一个或多个处理器实现上述方法中的步骤。
在本申请实施例中,接收通信语音请求,在通信语音请求的来源不属于预置来源的情况下,获取通信语音对应的语音文本;根据语音文本,获取语音文本对应的语音对话文本;根据语音对话文本,识别语音对话文本所属类别。从而实现通过不明通信语音直接自动识别不明通信语音的种类,进一步可以根据该种类,能够帮助用户对不明语音信息进行分类,特别是对于不良信息而言,帮助用户能够避免不良信息的骚扰,同时在识别过程中用户无感知,提高用户体验,还可以帮助用户提供所需的不明语音信息的类别。
此外,本申请实施例中,还可以建立非正常声纹库,非正常声纹库是根据非正常声纹得到的。以使得可以通过非正常声纹库中的非正常声纹对不明语音信息进行声纹自动识别,确定不明语音信息是否属于非正常声纹,从而可以进一步对该不明语音信息进行处理,自动帮助用户识别以及处理非正常语音信息,减少由不明语音信息带给用户的不良骚扰,提升用户的服务体验。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本申请一示例性实施例的信息的识别方法的流程示意图;
图2为本申请一示例性实例的来电识别方法的流程示意图;
图3为本申请一示例性实施例提供的通知消息的界面示意图;
图4为本申请一示例性实施例的声纹库的建立方法的流程示意图;
图5为本申请又一示例性实施例的信息的识别方法的流程示意图;
图6为本申请又一示例性实施例的信息的设置方法的流程示意图;
图7为本申请又一示例性实施例的信息的设置方法的流程示意图;
图8为本申请一示例性实施例提供的设置条件的界面示意图;
图9为本申请一示例性实施例的信息的识别系统的结构示意图;
图10为本申请一示例性实施例的信息的识别方法的流程示意图;
图11为本申请一示例性实施例提供的信息的识别装置的结构示意图;
图12为本申请一示例性实施例提供的信息的识别装置的结构示意图;
图13为本申请一示例性实施例提供的声纹库的建立装置的结构示意图;
图14为本申请一示例性实施例提供的信息的识别装置的结构示意图;
图15为本申请又一示例性实施例提供的信息的设置装置的结构示意图;
图16为本申请又一示例性实施例提供的信息的设置装置的结构示意图;
图17为本申请一示例性实施例提供的计算设备的结构示意图;
图18为本申请又一示例性实施例提供的计算设备的结构示意图;
图19为本申请又一示例性实施例提供的计算设备的结构示意图;
图20为本申请又一示例性实施例提供的计算设备的结构示意图;
图21为本申请又一示例性实施例提供的计算设备的结构示意图;
图22为本申请又一示例性实施例提供的计算设备的结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
由于通信网络的发展,人们每天都会接到大量的不明电话,其中大部分电话属于非正常电话,例如,骚扰电话、诈骗电话以及推销电话等。由于不能知晓当前的电话是不是非正常电话,而经常存在误接电话、遗漏电话等问题,同时也给用户带来了诸多不便和烦恼。
在现有技术中,通常需要依赖用户人工进行标记陌生电话中的非正常电话,特别是对不良陌生电话的标记,然而,用户在进行人工标记陌生电话时,由于该陌生电话的标记依赖于用户的手动触发,会占用用户较大的时间成本,从而用户向服务器上报的比例比较低,用户可能只会上报自己接到的骚扰欺诈类电话的10%。
此外,用户在接收到不良的陌生电话时,上报不良的陌生电话可能并不及时,可能只有不到3%的被骚扰用户会在被电话骚扰后,马上通过应用程序向服务器上报数据。
且由于,现在黑灰产的从业人员会频繁更换电话号码,或者使用换号器频繁更换电话号码,是非常常见的。当发现一个号码被多人举报后,黑灰产的从业人员即可用很低的成本再换一个号码,重新开始骚扰。所以上报电话号码,对阻止不明来电的防御能力是非常有限。
在本申请实施例中,接收通信语音请求,在通信语音请求的来源不属于预置来源的情况下,获取通信语音对应的语音文本;根据语音文本,获取语音文本对应的语音对话文本;根据语音对话文本,识别语音对话文本所属类别。从而实现通过不明通信语音直接自动识别不明通信语音的种类,进一步可以根据该种类,能够帮助用户对不明语音信息进行分类,特别是对于不良信息而言,帮助用户能够避免不良信息的骚扰,同时在识别过程中用户无感知,提高用户体验,还可以帮助用户提供所需的不明语音信息的类别。
以下结合附图,详细说明本申请各实施例提供的技术方案。
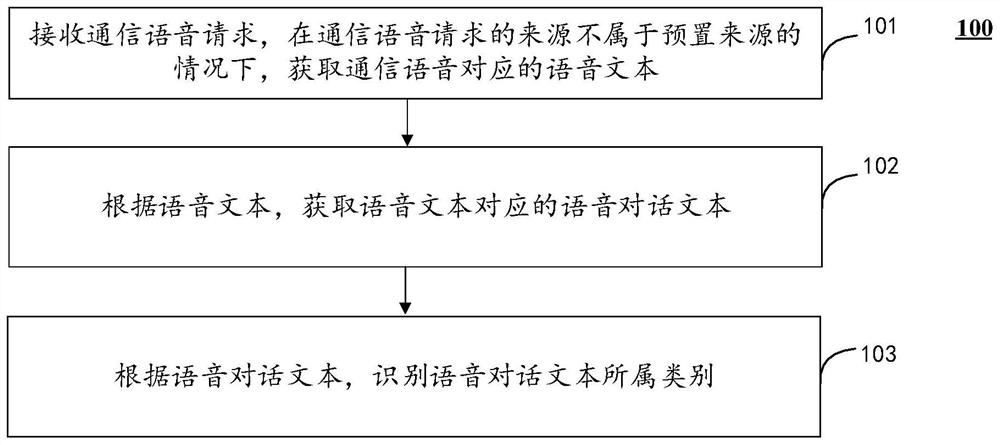
图1为本申请一示例性实施例的信息的识别方法的流程示意图。本申请实施例提供的该方法100由电子终端设备执行,如,手机、平板电脑、台式电脑等,该方法100包括以下步骤:
101:接收通信语音请求,在通信语音请求的来源不属于预置来源的情况下,获取通信语音对应的语音文本。
102:根据语音文本,获取语音文本对应的语音对话文本。
103:根据语音对话文本,识别语音对话文本所属类别。
以下针对步骤101-103进行详细地阐述:
101:接收通信语音请求,在通信语音请求的来源不属于预置来源的情况下,获取通信语音对应的语音文本。
其中,通信语音是指通过通信网络进行传输的语音,即语音信息。如通信设备(如,手机、座机、电脑等)之间的电话以及应用程序之间的网络电话。
通信语音请求的来源是指该语音的来源信息,如手机号码、座机号码、电脑IP等。
预置来源是指用户设置的通信语音请求的来源,也可以是设备自动设置的通信语音请求的来源。如手机电话簿、手机本地电话黑名单等。
语音文本是指记录语音信息传输的文字内容。
例如,根据前文所述,如图2所示,用户手机接收到来电请求,手机获取到来电请求的电话号码,并根据本地存储的电话薄进行匹配,不属于电话簿时,则确定该来电请求为陌生来电请求,并安装在手机上的AI应用程序或智能音箱可以接受该请求,在通话连接建立后,陌生来电的对方会开始进行说话,手机接收对方发送的通信语音,将该通信语音通过预置ASR(语音识别,也可以称为自动语音识别Automatic Speech Recognition)模型转换为语音文本,如“您好,这里是xx保险”或“您好,请问是xx女士么”。
需要说明的是,为了提高用户体验,使得用户无感知该步骤的执行,手机可以直接屏蔽向用户屏蔽接收到通信语音,即手机暂时关闭语音外放听筒,以及屏蔽接收用户语音,即关闭接收用户的语音话筒。
此外,在请求属于用户设置的用户设置的通信语音请求的来源时,可以提示用户接通电话。
具体的,该方法100还可以包括:获取通信语音请求的来源,将来源与用户预置正常来源集合进行匹配;在匹配成功的情况下,将通信语音提供给用户。
其中,用户预置正常来源集合,即用户设置到可信的电话号码集合,即电话薄。
例如,根据前文所述,手机获取到来电请求的电话号码,并根据本地存储的电话薄进行匹配,属于电话簿时,则获取电话簿中的号码所属名称,如“妈妈”,并提供展示界面,向用户展示提示信息,“妈妈来电,接听”。
此外,为了更加准确地确定陌生来电的来源,还可以在陌生来电的号码与电话簿进行匹配后,在于本地电话黑名单进行比对,加大比对范围,提升比对准确度。
具体的,该方法100还可以包括:获取通信语音请求的来源,将来源与预置非正常来源集合进行匹配;在匹配成功的情况下,将是否接受通信语音的提示信息提供给用户。
其中,预置非正常来源集合用户或应用程序自动设置的电话号码黑名单,其中该名单内可以包括非法名单,如诈骗电话号码,还可以包括灰名单电话号码,如推销电话号码。
例如,根据前文所述,手机获取到来电请求的电话号码,并根据本地存储的电话薄进行匹配,不属于电话簿时,再与黑名单进行匹配,当属于黑名单时,可以根据黑名单中的类型向用户进行提示。手机提供界面并展示该类型,如“推销电话”,以及“接听或拒接”的提示信息。
更具体地,与预置非正常来源集合进行匹配;在匹配到其中非法来源的情况下,拒绝通信语音请求。
例如,根据前文所述,当属于黑名单时,且属于黑名单中的非法电话,如诈骗电话,则手机直接拒接该来电请求。102:根据语音文本,获取语音文本对应的语音对话文本。
其中,语音对话文本是指至少两方的语音交谈的信息。
具体的,获取语音对话文本的方式,可以包括:
1)、将获取到的语音文本直接作为语音对话文本。
例如,根据前文所述,手机上的AI应用程序或智能音箱可以直接将陌生来电中的第一句语音文本作为语音对话文本,如“您好,这里是xx保险”。
2)、确定语音文本对应的交互文本;将获取到的语音文本以及对应的交互文本作为一组对话文本,并将至少一组对话文本作为语音对话文本;当语音对话文本存在多组,针对任一两组对话文本,根据前一组对话文本获取后一组对话文本。
其中,交互文本是指基于人类语言逻辑或语法逻辑,与语音文本对应的交流文本。例如,语音文本为“你好么”,交互文本可以为“我很好”,从而形成一组对话文本。
例如,根据前文所述,如图2所示,手机上的AI应用程序或智能音箱通过预置ASR模型将接收到的语音信息转换为语音文本,如“您好,这里是xx保险”或“您好,请问是xx女士么”。服务器确定交互文本可以为“您好,您是哪位”。手机上的AI应用程序或智能音箱此时可以将语音文本以及交互文本组成第一组对话文本,即“您好,xx女士么”+“您好,您是哪位”;该语音对话文本可以随着语音的交互生成多组对话文本,如,陌生来电的对方接收到交互文本“您好,您是哪位”,可以继续发出通信语音,如“这里是xx保险,请问您有保险需求么”,手机上的AI应用程序或智能音箱接收到该语音文本后,可以确定交互文本为“都有什么险种”,以此类推确定出多组对话文本。可以看出任一两组对话文本是具有语言逻辑关系的,即后一组对话文本是根据前一组对话文本得到的。
具体的,根据前一组对话文本获取后一组对话文本,包括:根据前一组对话文本中交互文本,获取后一组对话文本中语音文本;在获取到语音文本后,执行确定语音文本对应的交互文本的步骤。
由于前文已经详细阐述过本实例,此处就不再赘述。通过该执行方式可以更加完善语音对话文本,增加语音对话文本的完整性。
其中,获取后一组对话文本中语音文本,包括:通过通信语音发送交互文本,并接收对应的通信语音,以获取到语音文本。通过接收语音信息来获取语音文本更能够了解呼叫方的意图,从而准确地对语音对话文本进行分类,同时消耗对方的时间成本,乃至人力成本。
其中,例如,根据前文所述,手机上的AI应用程序或智能音箱在确定完交互文本后,可以通过预置TTS(Text To Speech,语音合成)模型,将交互文本合成声音,并通过建立的语音通话发送至陌生来电方。然后接收陌生来电方(也可以称为陌生来电的对方)发送的通信语音,在获取对应语音文本。
需要说明的是,TTS模型是通过神经网络,把文字智能地转化为自然语音流。TTS模型可以对文本进行实时转换,转换时间之短可以秒计算。在其特有智能语音控制作用下,文本输出的语音音律流畅,使得听者在听取信息时感觉自然,毫无机器语音输出的冷漠与生涩感。TTS模型可以覆盖国标一、二级汉字,具有英文接口,自动识别中、英文,支持中英文混读。所有声音采用真人普通话为标准发音,实现了120-150个汉字/分钟的快速语音合成,朗读速度达3-4个汉字/秒,使用户可以听到清晰悦耳的音质和连贯流畅的语调。
TTS模型可以根据人工学习生成的,其具体的生成过程属于现有技术,此处就不再赘述。
具体的,确定语音文本对应的交互文本,包括:确定语音文本的语义;根据语义,从对话集合中确定与语音文本对应的交互文本。通过语义确定交互文本,能够更好地帮助用户了解更多用户所需的内容,增加用户的良好的体验感。同时也可以对语音对话文本进行分类。
其中,语义是指语音文本的语言含义。
对话集合是指具有多个语句的集合。
例如,根据前文所述,手机上的AI应用程序或智能音箱获取到语音文本“您好,是xx女士么”后,可以根据NLU(Natural Language Understanding,自然语言理解)模型确定语义,确定后可以从对话集合中查找与该语义对应的交互文本。
需要说明的是,NLU模型是的目标是将文本转换为语义表示。文本中的单词的确切含义并不重要。重要的是文本传达的语义信息。NLU也被称为语义解码。NLU模型可以根据人工学习生成的,其具体的生成过程属于现有技术,此处就不再赘述。
该对话集合可以是平时人们的习惯用语,每个习惯用语都可以标注出各自的语义以及与其可以成为一组对话文本中的语音文本的语义。
需要说明的是,为了使用户对该处理方式无感知,提升用户的体验,再通过通信语音发送语音文本时,可以向用户屏蔽外放声音,即用户无法听到发送的通信语音。
103:根据语音对话文本,识别语音对话文本所属类别。
其中,类别是指语音对话文本的种类,可以是指语言交流的目的,例如,推销类别,骚扰类别、诈骗类别等等。
具体的,识别语音对话文本所属类别,包括:确定语音对话文本的语义,根据语义确定语音对话文本对应的类别。通过语义确定语音对话文本,能够更准确地对语音对话文本进行分类。
例如,根据前文所述,如图2所示,手机上的AI应用程序或智能音箱在不能确定语音对话文本的类别时,可以持续更新该语音对话文本。当手机上的AI应用程序或智能音箱可以根据第一句语音文本就能确定出,后续语音对话文本的目的,如语音文本“您好,这里是xx保险”,根据NLU模型可以确定出该语义,则可以根据该NLU模型进行一步确定该语音文本的目的,即类别就是推销,更具体的是推销保险。此时,就可以直接该第一句语音文本作为语音对话文本。
当NLU模型暂时不能确定出当前语音对话文本的语义时,可以通过持续更新语音对话文本,直至NLU模型可以确定出当前语音对话文本的目的,即类别。
本申请实施例中,NLU模型可以放在服务端,上述其它模型都可以设置服务端,也就是说获取语音文本以及识别出所属类别的具体实施方式是可以通过服务端实现的,当服务端实现时,需要终端,如手机将通信语音请求转发至服务端即可。
而在本地终端实现时,需要用户较高的授权,但是可以有效防止用户的信息不被泄露。
在电话名单无法准确判定该来电请求时,为了提高识别进度,避免用户接到用户反感以及威胁用户经济安全的电话,还可以继续进行识别,如通过声纹库进行识别。以避免通过识别语音对话文本带来的资源占用。
具体的,该方法100还可以包括:在通信语音请求的来源不属于预置来源的情况下,获取通信语音的声纹;在声纹不属于非正常声纹库的情况下,执行获取通信语音对应的语音文本的步骤。
其中,非正常声纹库用于存储多个非正常声纹。声纹是指用电声学仪器显示的携带言语信息的声波频谱,是可唯一标识声音的属性,如,可唯一标识通信语音的声音,应理解,该声纹是指通信语音发起方(也可以称为呼叫方)的声纹。
非正常声纹是指黑灰产的声纹,既可以包括非法产业所属的声纹(也可以称为非法类别的声纹),诈骗类别的声纹,也可以包括游走在法律边缘产业所属的声纹(也可以称为灰色类别的声纹),如骚扰类别的声纹以及推销类别的声纹等。
例如,根据前文所述,手机上的AI应用程序或智能音箱在接收到通信语音后,则通过声纹识别模型从通信语音中提取出声纹,将声纹与非正常声纹库进行匹配,在不属于非正常声纹库的情况下,才执行步骤101。
此外,该方法100还可以包括:建立非正常声纹库,非正常声纹库是根据非正常声纹得到的。
例如,手机可以接收用户通过手机安装的上报应用程序上报到手机本地的多个非正常声纹,将这些非正常声纹集合在一起,生成非正常声纹库,用于存储这些非正常声纹。该非正常声纹库可以具有ID以及标签“非正常类别”。其中,每个非正常声纹都可以具有一个ID以及还可以根据自身具体的类别对自身进行打标。如,将ID为“aa”的诈骗类别的声纹标签设置为“非法类别-诈骗类别”等,将ID为“bb”的推销类别的声纹标签设置为“非正常类别-推销类别”等。
此外,还可以将该非正常声纹库中各个声纹,根据非法类别以及其它类别(即灰色类别)进行划分,在该非正常声纹库中设置两个子库,分别存储非法类别的声纹以及其它类别的声纹。
需要说明的是,获取非正常声纹的方式除了上报方式外,还可以通过应用程序的服务端、有关治安管理平台或其它平台获取其本地已经存储的多个非正常声纹,生成非正常声纹库。
通过建设黑灰产声纹库,即使黑灰产变换电话号码,声纹却无法改变,从而很快被识别出来黑灰产声纹,如果要继续营销或者诈骗,在换号的同时还需要不断换人,大大增加了黑灰产的人力成本。
为了能够帮助用户识别更多的声纹,建立好的非正常声纹库应当不断地进行更新,以保证有效地识别更多的声纹。其中,更新方式可以包括:
1)、当类别为非正常类别,将声纹作为非正常声纹更新至非正常声纹库。
例如,根据前文所述,手机上的AI应用程序或智能音箱可以根据NLU(NaturalLanguage Understanding,自然语言理解)模型确定语音文本的语义,确定后可以从不同类别的语义集合中查找该对应语义,当确定该语音属于非正常类别中的推销类别,则可以确定通信语音为非正常语音,则通过声纹识别模型从通信语音中提取出声纹,将提取出的声纹作为非正常声纹更新至非正常声纹库。
需要说明的是,ASR模型是预置好的语音识别模型,其目标是将人类的语音中的词汇内容转换为计算机可读的输入文本,包括字符等。ASR模型是根据人工学习生成的,其具体的生成过程属于现有技术,此处就不再赘述。
NLU模型是的目标是将文本转换为语义表示。文本中的单词的确切含义并不重要。重要的是文本传达的语义信息。NLU也被称为语义解码。NLU模型可以根据人工学习生成的,其具体的生成过程属于现有技术,此处就不再赘述。
此外,声纹识别模型是根据说话人的声波特性进行身份辨识的服务。身份辨识与口音无关,与语言无关,可以用于说话人辨认和说话人确认,广泛应用于金融安全、智能家居、智慧建筑等领域。
声纹识别模型可以只对声纹进行提取,即提取声音的特征,该特征可以为声音的频谱以及声音波长等,或者,声纹识别模型中可以内置声纹库,直接做到对声纹进行识别的情况,如,声纹属于不良声纹或不属于不良声纹等。
无论声纹识别模型的功能是哪种,其的模型建立过程均属于现有技术,此处就不再赘述。应理解,该声纹库是一种记录不良声纹的载体,该声纹库不拘泥于一种实现形式,所有能实现该载体功能的实现形式均属于本申请实施例的保护范畴。
更新方式还可以包括:2)、接收上报的声纹以及上报类别,当上报类别为非正常类别,则将上报的声纹作为非正常声纹更新至非正常声纹库。
例如,根据前文所述,手机可以接收用户通过手机安装的上报应用程序上报到手机本地的多个声纹,随着声纹一起上报的还有声纹的类别,如销售类别。手机接收到上报的声纹后,确定声纹的类别属于非正常类别,则将该上报声纹作为非正常声纹存储至非正常声纹库中,进行声纹更新。
当上报声纹的类别属于其它类别,如,娱乐类别,亲朋类别等,服务器将上报声纹存储至对应类别的声纹库中,以便后续用户在漏接电话时,或用户不在电话旁时,可以为用户自动记录陌生来电对应类别的语音信息,并告知用户,以便用户尽快处理。
需要说明的是,在用户自主上报声纹时,用户通过手机在接听通话语音信息后,可以通过手机本地的声纹识别模块提取语音信息的声纹,并将该声纹上报至本地,并存储在手机本地外,还可以进行声纹上报服务端,将存储的声纹进行上报服务端时,明确声纹类别。在上报后,手机通过安装的上报应用程序将已上报的声纹存储至手机本地声纹库中,以记录。
为了防止在更新非正常声纹库时,更新后非正常声纹库存在多个冗余声纹,同时节省非正常声纹库的占用资源,该方法100还可以包括:当确定声纹不存在于非正常声纹库中,则将声纹作为非正常声纹更新至非正常声纹库。
例如,根据前文所述,手机上的AI应用程序或智能音箱在将声纹作为非正常声纹更新至非正常声纹库前,可以先将声纹与非正常声纹库中的多个声纹进行匹配,当未匹配到,则视为不存在与该非正常声纹库中,则可以将声纹更新至该非正常声纹库。否则,可以舍弃掉该声纹。服务端更新时也是一样的。
需要说明的是,对于其它类别的声纹库,该方式也同样使用,此处就不再赘述。
此外,非正常声纹库的识别方式可以包括:将声纹与非正常声纹库中的多个声纹进行匹配,当匹配成功,则确定声纹为非正常声纹。
例如,根据前文所述,如图2所示,手机上的AI应用程序或智能音箱在通话连接建立后,陌生来电的对方会开始进行说话,通过声纹识别模型从通信语音中提取出声纹,将提取出的声纹与非正常声纹库中的各个声纹进行匹配,当存在与该提取出的声纹相同的非正常声纹时,则确定该提取出的声纹为非正常声纹。
当接收到的通信语音属于通信语音请求,且确定提取出的声纹为非正常声纹,则可以对该语音信息进行处理,从而进一步自动帮助用户处理语音信息,提高用户的服务体验,减少用户被骚扰的概率。其中,处理方式可以包括:当匹配到的声纹属于非正常声纹中的非法声纹,则确定对应通信语音为非法通信语音,并终止接收语音信息。
例如,根据前文所述,手机上的AI应用程序或智能音箱在确定该提取出的声纹为非正常声纹后,确定该对应通信语音属于非正常通信语音,则手机上的AI应用程序或智能音箱可以自助结束该通信语音通话。
当手机上的AI应用程序或智能音箱确定声纹不存在与非正常声纹库中时,还可以通过其它方式对该声纹所属的通信语音信息作进一步的判断,确定该通信语音信息的类别,从而进行处理。
通过步骤101-103确定出类别为非正常类别,可以直接确定出语音信息的类型,从而进一步确定声纹类别或对该通信语音进行处理。
其中,非正常语音信息是指与非正常声纹对应的语音,如黑灰产的语音,既可以包括非法产业所属的语音(也可以称为非法类别的语音),诈骗类别的电话语音,也可以包括游走在法律边缘产业所属的语音(也可以称为灰色类别的语音),如骚扰类别的电话语音以及推销类别的电话语音。
确定通信语音类型的方式包括:当类别为非正常类别,确定语音信息为非正常语音信息。
例如,根据前文所,如图2所示,手机上的AI应用程序或智能音箱在确定语音对话文本的类别为推销类别,则确定语音对话文本为非正常类别,并确定对应的通信语音为推销语音。
为了更加准确地确定处理语音信息的方式,该方法100还包括:当类别为非正常类别中的非法类别,确定通信语音为非正常通信语音中的非法通信语音以及声纹为非正常声纹中的非法声纹,并终止通信接收语音。
例如,根据前文所述,如图2所示,手机上的AI应用程序或智能音箱在确定语音对话文本的类别为诈骗类别,则确定语音对话文本为非法类别,并确定对应的通信语音为诈骗语音,即非法语音,可以直接结束语音通话。同时,由于确定了类别为非正常类别的非法类别,则可以提取声纹,将声纹作为非法声纹存储至非正常声纹库,进一步更新该非正常声纹库。
此外,当用户对于非正常类别中其它类别的有获取需求时,如,用户想要对购买保险或购买住房有需求,那么用户对于保险推销语音信息以及购房推销语音信息有需求,为了满足用户的需求,同时提高用户的服务体验,帮助用户剔除掉不需要以及非法的通信语音,该方法100还包括:当类别为用户所需类别,则根据用户所需类别的内容,获取与内容匹配的语音对话文本,用户所需类别可属于非正常类别。
其中,用户所需类别可以预先设置。例如,用户直接在手机上的AI应用程序或智能音箱提供的设置条件页面上输入获取更多信息,更具体地,还可以为重大疾病保险的价格以及赔付等事宜。从而帮助了解用户所需内容,进一步完成后续对用户所需内容的获取,特别是对于对话集合的选取。
例如,根据前文所述,当手机上的AI应用程序或智能音箱根据NLU模型确定出语音对话文本为推销保险类,则根据用户的设置条件的信息,确定出用户需求保险推销中的重大疾病保险的购买情况,则手机上的AI应用程序或智能音箱替代用户与保险推销的电话进行对话。此时,服务器可以选择与保险咨询有关的对话集合。如,根据用户所需知道的信息,如重大疾病保险的价格,可以从该对应购买保险的对话集合中选择出语义为咨询保险的交互文本,如“重大疾病保险的价格”或“重大疾病怎么赔付”等,将该交互文本依次生成语音,发送至陌生来电方,等待对方语音回复。并确定对方回复的语音文本,继续更新语音对话文本,直到用户所需的信息都获取到,既可挂断电话。手机上的AI应用程序或智能音箱则获取到了用户所需的语音对话文本。
需要说明的是,用户所需类别可以与非正常类别重合,如推销电话,当用户有需求时,除了非法诈骗类的陌生来电,会给用户造成损失,其他类别的陌生来电可以以用户的需求为主。
在语音对话文本的类别为其它类别时,如娱乐类别、亲朋类别等,可以确定对应的声纹为其它类别声纹。并将其它类别声纹设置到对应类别声纹库中,如将亲朋类别的声纹设置到亲朋类别声纹库中。以便后续用户在漏接电话时,或用户不在电话旁时,可以为用户自动记录陌生来电对应类别的语音信息,并告知用户,以便用户尽快处理。其它类别也可以视为用户所需类别。
除了根据非正常声纹库以及语音对话文本所属类别来识别非正常语音信息,还可以通过其它方式来识别非正常语音信息。尤其在非正常声纹库无法识别时,可以通过其它方式来识别,提高识别率。或者在非正常声纹库进行识别前,先根据其它方式来识别,简化识别过程。
具体的,该方法100还包括:根据类别,确定通信语音请求的来源的类别。
其中,通信语音请求的来源也可以称为通信标识是可唯一标识该通信语音的来源,如,电话号码。
例如,根据前文所述,当手机上的AI应用程序或智能音箱确定了语音对话文本的类别后,根据该类别确定陌生来电的电话号码的类别,如类别为诈骗,则该电话号码则为诈骗电话号码。
需要说明的是,可以通过打标签的方式对电话号码进行标记。
此外,该方法100还包括:将通信语音请求的来源设置到对应来源类别集合中。从而能够丰富每个来源类别集合,识别出更多类别。
其中,来源类别集合,也可以称为通信标识类别集合,是由多个来源或通信标识组成的集合。在该集合里可以是同一类别的来源或通信标识,也可以是多个类别的来源或通信标识,当是多个类别时,每个类别都会进行标记。该集合可以为黑名单或非正常号码库。
例如,根据前文所述,如图2所示,手机上的AI应用程序或智能音箱还可以将确定了类别的电话号码,如诈骗电话号码,存储至诈骗的电话号码的黑名单内。
为了能够更好地识别语音信息,广泛地识别大量语音信息,进一步提高识别率,可以对通讯标识进行更新。其中更新方式可以包括:接收上报的通信语音请求的来源以及上报类别,根据上报类型,将上报的通信语音请求的来源存储至对应通信标识类别集合中。
例如,根据前文所述,手机上的AI应用程序或智能音箱可以接收用户通过手机安装的上报应用程序上报到手机本地的多个陌生来电号码,随着陌生来电号码一起上报的还有陌生来电号码的类别,如销售类别。手机上的AI应用程序或智能音箱接收到上报的陌生来电号码后,确定陌生来电号码的类别属于非正常类别,则将该上报陌生来电号码作为非正常号码存储至非正常号码库中,进行号码更新。
为了能够更加精准地对号码库进行更新,排除人为故意扰乱因素,该方法100还包括:针对任一上报类别,根据通信语音请求的来源的上报次数,将上报的通信语音请求的来源存储至对应来源类别集合中。
例如,根据前文所述,手机上的AI应用程序或智能音箱接收到上报的诈骗号码,当该诈骗号码被上报次数大于阈值,则认定该诈骗号码为真实的诈骗号码,并将其作为诈骗号码更新至非正常号码库中。
在通过上报次数来精准更新号码库的基础上,还可以通过上报用户数量来进一步提高更新的精准度。
具体的,该方式可以包括:针对任一上报类别,根据通信语音请求的来源的上报次数以及上报用户数量,将上报的通信语音请求的来源存储至对应来源类别集合中。
例如,根据前文所述,手机上的AI应用程序或智能音箱接收到上报手机本地的诈骗号码,当该诈骗号码被上报次数大于阈值,且上报该号码的用户数量大于阈值,则认定该诈骗号码为真实的诈骗号码,并将其作为诈骗号码更新至非正常号码库中。
通过非正常号码库进行识别非正常语音信息的过程可以包括:当接收到转发的通信语音请求,获取通信语音请求携带的来源;将来源与多个来源类别集合进行匹配,当来源匹配到非法类别的来源,则拒绝通信语音请求。
例如,根据前文所述,手机上的AI应用程序或智能音箱先获取到该陌生来电的号码,如,手机号码“186xxxxxx”,将该手机号码与可以本地存储的电话号码黑名单进行对比,确定该手机号码是否存在于该黑名单内,若是,则手机上的AI应用程序或智能音箱可以直接挂断陌生来电,并对该情况做好记录,如“手机号码“186xxxxxx”来电,属于诈骗类电话”并将该情况供用户查看。
需要说明的是,该黑名单可以记录诈骗电话号码,还可以记录推销电话号码以及骚扰电话号码等,也可以记录多种类别的电话号码,并通过各个电话标签来区分。应理解,该黑名单是一种记录不良号码的载体,该黑名单不拘泥于一种实现形式,所有能实现该载体功能的实现形式均属于本申请实施例的保护范畴。
此外,服务器也可以根据用户上报的方式更新号码库。
此外:若未匹配到非法类别的通信语音请求的来源,则接收通信语音请求以及接收语音信息,并确定语音信息对应的声纹。通过声纹来进行语音信息的识别。
为了能够进一步提高服务,增强用户体验可以将自动识别出的通信语音、号码以及声纹告知用户。
具体的,该方法100还包括:向用户提供类别以及通信语音的来源。
例如,根据前文所述,如图2所示,手机上的AI应用程序或智能音箱在确定了语音信息的类别后,可以直接向用户提供界面消息,该消息可以记录了来电的电话号码,以及该电话号码属于诈骗的类别。用户在接收到该消息后,可以点击该消息进行查看。
此外,服务器由于也可以执行识别类别,那么服务器也可以在确定了语音信息的类别后,可以通过短信形式或者应用通知形式,向用户手机发送通知消息,用户可以点击该消息进行查看。
需要说明的是,当来电不属于用户所需类别时,可只发送上述内容。
为了提高用户的体验感,当来电属于用户所需类别,该方法100还包括:通知用户语音对话文本。
例如,根据前文所述,如图2所示,手机上的AI应用程序或智能音箱还可以将语音对话文本设置在该消息中,与来电的电话号码以及其类别一起展示给用户,用户在查看该通知消息时,可以看到语音对话文本。服务器同样可以将这些内容发生给用户的手机端,使得用户进行消息查看。
其中,图3示出了该通知消息的展示界面300,在界面300中记录的是该来电记录,即电话记录,其中包括呼入号码,如陌生来电的电话号码,类别,即标记:营销类.贷款(也可以称为推销类.贷款),号码状态和声纹状态:自动举报入库的,以及语音对话文本,即聊天记录的内容。
此外,还可以记录陌生来电时间以及通话时长等。
需要说明的是,无论类别是否是用户所需的,还是非法类别,该通知消息都可以携带聊天记录。可以使用户更加了解陌生来电的目的。
在发现非正常类别的来电以后,特别是非法类别的来电,可以采用最简单的策略挂断,也可以伪装成真人提升对方成本,如果用户真的对营销信息有需求,也可以代为询问信息。用户可以配置策略,让服务器代为执行。此外,本申请实施例还可以实现自动记录来电内容的功能,当用户在一段时间内,或一定条件下,不方便接听电话时,但又有需求需要知道期间内来电的内容,可以通过本申请实施例的方式实现对不方便接听的电话进行文本记录,等到用户方便时通过查看记录的文本,知道期间内有什么事情发生,是否需要回电等。
为了提升人工智能中对语音对话文本的类别识别的精准性,还可以接收用户对语音信息类别的矫正信息。具体的,该方法200还包括:接收类别的调整信息;根据调整信息调整类别;将调整后类别以及对应的语音对话文本作为用于优化模型的样本;其中,模型用于确定语音对话文本的语义,根据语义确定语音对话文本对应的类别。
其中。调整信息是指用于修改类别的修改信息。
模型可以是指NUL模型。
例如,根据前文所述,如图2所示,用户在接收到通知消息后,用户可以根据通知消息中记载的内容,如陌生来电的电话号码和/或聊天记录,来确定当前手机上的AI应用程序或智能音箱确定的类别是否正确。当用户确定该类别不正确,用户可以通过手机向AI应用程序或智能音箱发送调整信息,如将类别“诈骗”修改为“骚扰”。手机上的AI应用程序或智能音箱接收用户手机发送的调整信息,手机上的AI应用程序或智能音箱会向人工审核人员的前端,如电脑,发送审核通知,由人工审核人员进行调整信息的审核,当审核通过后,手机上的AI应用程序或智能音箱会接收到人工审核人员通过电脑发送的审核通过的消息。手机上的AI应用程序或智能音箱收到该消息后,可以根据该调整信息修改类别。如,将诈骗类别修改为骚扰类别。此外,与该类别关联的声纹、电话号码、聊天记录都要修改为骚扰类别。此外,手机上的AI应用程序或智能音箱还会将该聊天记录作为训练NLU模型的负样本进行存储,用于优化NLU模型,使得NLU模型能够更加优化以及处理精度更高。
此外,服务器也可以执行手机上的AI应用程序或智能音箱实现的上述内容。
其中,图3的界面300还示出了调整信息的调整框“不准确,人工重新标记”。用户可以点击该调整框,可以通过重新对类别进行标记,如用户自己输入类型,或用户从该界面300提供的多个类别中进行选择,用户在标记完新类别后,执行确定操作,使得用户手机可以响应该操作,向手机上的AI应用程序或智能音箱发送调整信息。
此外,该方法100还包括:在获取语音文本对应的语音对话文本后,该方法100还包括:向用户提供语音对话文本的查看地址。
例如,根据前文所述,手机上的AI应用程序或智能音箱在与陌生来电进行通话中时,可以一边获取语音对话文本,一边对该语音对话文本进行记录或保存,并将记录本地地址或本地保存地址(即本地查看地址)通过消息的形式展示给用户,用户可以点击该记录本地地址,查看该语音对话文本。
需要说明的是,由于该语音对话文本是可以持续更新的。所以用户看到该语音对话文本时,可以通过刷新的方式持续查看更新的内容。此时,当语音对话文本更新后,手机上的AI应用程序或智能音箱可以发送更新消息至语音对话文本的页面,提示用户执行更新操作,查看更新的内容。
为了提高用户的参与感,对人工智能更加了解,同时知道自身的需求是否被满足。该方法100还包括:记录语音对话文本所属对话语音;向用户提供语音对话文本所属对话语音的收听地址。
例如,根据前文所述,手机上的AI应用程序或智能音箱在与陌生来电进行通话中时,可以一边获取语音对话文本,一边记录或保存陌生来电的通信语音以及交互文本的通信语音,即语义对话文本的通信语音,并将记录本地地址或保存本地地址(即本地收听地址)通过消息的形式展示给用户,用户可以点击该记录地址,收听该语音对话文本的通信语音。
由于该语音对话文本是持续更新的,那么其通信语音也是持续更新的,该通信语音可以通过直播的形式持续进行更新,无需用户去更新,手机上的AI应用程序或智能音箱可以持续将通信语音的媒体流持续记录或保存,使得用户可以持续收听该通信语音,直至通话结束。
需要说明的是,对于本申请实施例而言,无论是通信语音的类别、还是来源的类别、或是语音对话文本的类别,乃至声纹的类别是彼此关联的。如,一个手机号码的类别与该号码对应的声纹类别、对应通信语音类别以及语音对话文本的类别是相同的。知道其中一个的类别,其它的类别也都可以知晓。
本申请实施例采用人工学习,全方位主动发掘的方式来建设黑灰产电话号码库,如通过NLU模型挖掘营销诈骗电话,来扩大电话号码的黑名单,大大提升黑灰产电话发现效率。其挖掘效率以及发行效率可以做到人工挖掘的10倍甚至更高。
本申请实施例可以以软件形式嵌入了APP中,并安装在终端中。或嵌入到小程序中,可以随用户直接通过网络拉取该小程序应用,无需下载,减少对终端的资源占用。
在服务端也可以执行终端设备所实现的内容,如执行方法100,执行步骤与前文中服务器执行步骤相似,此处就不再赘述。当服务端执行方法100时,则需进行通信语音请求转发,接收该请求,获取声纹,确定声纹类别、确定语音对话文本的类别以及确定号码的类别。
由于从事黑灰产业的人员通过频繁更换电话号码的成本非常低,使得准确地识别众多不同的号码是非常不易的。为了遏制这种频繁更换号码骚扰用户的情况,加强识别黑灰产业的从事人员。本发明申请实施例还提供了一种声纹库的建立方法。
图4为本申请一示例性实施例的声纹库的建立方法的流程示意图。本申请实施例提供的该方法400由电子设备执行,如,常规服务器、云服务器、中终端设备,如手机、平板电脑以及台式电脑等,该方法400包括以下步骤:
401:建立非正常声纹库,非正常声纹库是根据非正常声纹得到的。
由于步骤401的具体实施方式在前文已经详细阐述过了,此处就不再赘述。
通过建设黑灰产声纹库,即使黑灰产变换电话号码,声纹却无法改变,从而很快被识别出来黑灰产声纹,如果要继续营销或者诈骗,在换号的同时还需要不断换人,大大增加了黑灰产的人力成本。
为了能够帮助用户识别更多的声纹,建立好的非正常声纹库应当不断地进行更新,以保证有效地识别更多的声纹。该方法400还包括:接收通信语音,并确定通信语音对应的声纹;当确定通信语音为非正常通信语音,将声纹作为非正常声纹更新至非正常声纹库。
该方法400还包括:接收上报的声纹以及上报类别,当上报类别为非正常类别,则将上报的声纹作为非正常声纹更新至非正常声纹库。
此外,该方法400还包括:接收通信语音,并确定通信语音对应的声纹;将声纹与非正常声纹库中的多个声纹进行匹配,当匹配成功,则确定声纹为非正常声纹。
在识别出声纹后,可以直接对该声纹对应通信语音进行处理,方便又快捷。该方法400还包括:当匹配到的声纹属于非正常声纹中的非法声纹,则确定对应通信语音为非法通信语音,并终止接收通信语音。
为了防止在更新非正常声纹库时,更新后非正常声纹库存在多个冗余声纹,同时节省非正常声纹库的占用资源,更新至非正常声纹库前,该方法400还包括:当确定声纹不存在于非正常声纹库中,则将声纹作为非正常声纹更新至非正常声纹库。
在声纹库无法识别出声纹还可以通过识别语音对话文本所属类别来准确地识别来电来源,提高识别进度,该方法400还包括:当声纹不存在于非正常声纹库中,获取通信语音对应的语音文本;根据语音文本,获取语音文本对应的语音对话文本;根据语音对话文本,识别语音对话文本所属类别。
还需要注意的是,由于前文已经详细阐述了本申请实施例的具体实施方式,此处就不再赘述。
此外,本实施例未详细描述的其它部分,可参考上述方法100所示实施例的相关说明,在此不再赘述。
为了效率高且大规模地挖掘出潜在的黑灰产业的陌生来电,同时加大黑灰产的人力成本,从而降低黑灰产的产生。本申请实施例还提供了一种信息的识别方法。
图5为本申请一示例性实施例的一种信息的识别方法的流程示意图。本申请实施例提供的该方法500由电子设备执行,如,常规服务器或云服务器,该方法500包括以下步骤:
501:接受转发的通信语音请求,并获取语音信息对应的语音文本。
502:根据语音文本,获取语音文本对应的语音对话文本。
503:根据语音对话文本,识别语音对话文本所属类别。
由于步骤501-步骤503的具体实施方式在前文已经详细阐述过了,此处就不再赘述。仅说明,服务器通过其上部署的虚拟号码运营商接收到用户手机呼叫转移的通信语音请求,该请求来自于陌生来电,服务器通过虚拟号码运营商接受该请求,从而通过虚拟号码运营商建立陌生来电与服务器之间的通话连接,在通话连接建立后,陌生来电的对方会开始进行说话,服务器接收对方发送的通信语音,将该通信语音通过预置ASR模型转换为语音文本。
具体的,获取语音文本对应的语音对话文本,包括:将获取到的语音文本直接作为语音对话文本。
具体的,获取语音文本对应的语音对话文本,包括:确定语音文本对应的交互文本;将获取到的语音文本以及对应的交互文本作为一组对话文本,并将至少一组对话文本作为语音对话文本;当语音对话文本存在多组,针对任一两组对话文本,根据前一组对话文本获取后一组对话文本。
具体的,根据前一组对话文本获取后一组对话文本,包括:根据前一组对话文本中交互文本,获取后一组对话文本中语音文本;在获取到语音文本后,执行确定语音文本对应的交互文本的步骤。
具体的,获取后一组对话文本中语音文本,包括:通过通信语音发送交互文本,并接收对应的通信语音,以获取到语音文本。
具体的,确定语音文本对应的交互文本,包括:确定语音文本的语义;根据语义,从对话集合中确定与语音文本对应的交互文本。
具体的,识别语音对话文本所属类别,包括:确定语音对话文本的语义,根据语义确定语音对话文本对应的类别。
此外,该方法500还包括:接收上报的通信语音请求的来源以及上报类别,根据上报类型,将通信语音请求的来源存储至对应来源类别集合中。
此外,该方法500还包括:针对任一上报类别,根据来源的上报次数,将上报的通信语音请求的来源存储至对应来源类别集合中。
此外,该方法500还包括:针对任一上报类别,根据来源的上报次数以及上报用户数量,将上报的通信语音请求的来源存储至对应来源类别集合中。
此外,该方法500还包括:将更新后的来源类别集合下发至对应的设备,以进行更新。
需要说明的是,由于前文方法100的实施例中已经详细阐述了具体实施方式,而方法500的具体实施方式与前文中方法100的具体实施方式相似,此处就不再细述。
还需要注意的是,本实施例未详细描述的其它部分,可参考上述方法100所示实施例的相关说明,在此不再赘述。
为了保证用户对自动语音信息识别无感知,同时帮助用户对可能给用户造成骚扰以及经济损失的陌生来电进行筛选,本申请实施例还提供了一种信息的识别方法。
图6为本申请一示例性实施例的一种信息的设置方法的流程示意图。本申请实施例提供的该方法600由电子终端设备执行,如,手机终端,该方法600包括以下步骤:
601:获取用户通信语音标识。
602:将用户通信语音标识与转接通信语音标识进行绑定,以使在预置条件下根据绑定关系,将通信语音请求转发至转接通信语音标识所属设备。
603:设置预置条件。
以下针对步骤601-步骤603进行详细地阐述:
601:获取用户通信语音标识。
其中,通信语音标识,也称为通信标识,如电话号码。
例如,手机通过安装的应用程序上获取应用小程序的执行代码,根据执行代码运行该应用小程序在手机上,并展示应用小程序的界面。该应用小程序可以提供一个号码绑定界面。该绑定界面需要用户输入用户手机号码以及来电呼叫转移的号码。
用户在界面上输入用户手机号码,手机响应于该输入操作,获取到该手机号码,可以展示在该界面上。
602:将用户通信语音标识与转接通信语音标识进行绑定,以使在预置条件下根据绑定关系,将通信语音请求转发至转接通信语音标识所属设备。
其中,转接通信语音标识,也是通信标识,用于接收转接语音请求的设备的通信标识,如转接号码。
例如,根据前文所述,用户在界面上输入来电呼叫转移号码,手机响应于该输入操作,获取到该来电呼叫转移号码,可以展示在该界面上。响应于用户的绑定操作,将两个号码进行绑定,从而实现呼叫转移。
603:设置预置条件。
其中,预置条件是指用户预先设置好的语音请求转接的条件,如陌生来电,即将陌生来电进行呼叫转移。
例如,根据前文所述,用户在界面上输入预置条件:陌生来电,手机响应于该输入操作,获取到该预置条件:陌生来电,可以展示在该界面上。在完成绑定操作后,则可以在陌生来电时,将陌生来电请求转发至转接号码的设备上。应理解,该设备部署有虚拟号码运营商。
此外,该方法600还包括:设置在预置条件下对对应语音的处理方式。
其中,处理方式可以包括:结束语音信息即挂断来电、记录来电语音信息的文本等。
例如,根据前文所述,用户在界面上输入处理方式:挂断来电,手机响应于该输入操作,获取到该处理方式,可以展示在该界面上。在完成绑定操作后,则可以在陌生来电时,将陌生来电请求转发至转接号码的设备上。当陌生来电属于非法类别的来电,则直接挂断来电。
此外,该方法600还包括:接收通信语音请求,并获取通信语音请求对应的通信语音标识;当获取到的通信语音标识满足预置条件,则根据绑定关系,将通信语音请求转发至转接通信语音标识所属设备。
此外,该方法600还包括:获取通信语音的声纹,将声纹以及声纹的类别进行上报。
此外,该方法600还包括:将声纹与本地声纹库中已上报声纹进行对匹配,当未匹配到对应声纹,则执行将声纹以及声纹的类别进行上报的步骤。
此外,该方法600还包括:获取通信语音标识,将通信语音标识以及通信语音标识的类别进行上报。
此外,该方法600还包括:接收并展示通信语音请求对应的通信语音类别以及通信语音对应的语音对话文本。
此外,该方法600还包括:接收通信语音请求对应通信语音的语音对话文本;响应于用户的输入操作,确定通信语音的类别;上报类别以及对应的语音对话文本。
需要说明的是,由于前文方法100的实施例中已经详细阐述了上述的具体实施方式,此处就不再细述。
还需要注意的是,本实施例未详细描述的其它部分,可参考上述方法100所示实施例的相关说明,在此不再赘述。
为了保证用户对自动语音信息识别无感知,同时帮助用户对可能给用户造成骚扰以及经济损失的陌生来电进行筛选,本申请实施例还提供了一种信息的识别方法。
图7为本申请一示例性实施例的一种信息的设置方法的流程示意图。本申请实施例提供的该方法700由电子终端设备执行,如,手机终端,该方法700包括以下步骤:
701:提供通信语音标识的绑定界面,绑定界面中展示了用户语音通信标识输入区域、转接通信语音标识输入区域以及预置条件输入区域,用户通信语音标识与转接通信语音标识具有绑定关系。
702:响应于用户的输入操作,确定对应输入区域中的用户通信语音标识以及转接通信语音标识。
703:响应于用户的输入操作,确定对应输入区域中的预置条件,在预置条件下,转发通信语音请求至转接通信语音标识所属设备。
704:响应于绑定操作,完成绑定关系的操作。
需要说明的是,由于前文方法600的实施例中已经详细阐述了上述步骤701-步骤704的具体实施方式,此处就不再细述。
此外,该方法700还包括:将绑定关系发送至通信语音转接设备。
例如,用户在自己的手机中开通呼叫转移操作,同时该手机号码的运营商支持该呼叫转移操作,用户在手机开通呼叫转移操作时,输入呼叫转移的输入转接号码、输入转接条件,同时还需要通过web网页端或者以小程序的方式,访问服务器,获取服务器提供的设置条件的页面,在该设置条件的页面上输入呼叫转移的条件,如输入本机号码、输入转接号码、输入转接条件以及对话策略等等。其中,图8示出了设置条件的界面800,在该界面800中,设置了本机号码的输入框,用户在该输入框中输入“138xxxxxxx”,还设置了虚拟转接号码的输入框,用户在该输入框中输入“17xxxxxxx”,还设置了转接条件的输入框,用户在该输入框中选择“不存在于电话簿”以及设置了对话策略的输入框,用户在该输入框中选择“更多信息”,还可以选择“推销类:保险,更多信息”。此外,在设置完该信息后,服务器会接收到该设置信息,同时用户手机也会开始执行呼叫转移操作。
在设置完成后,用户手机接收到陌生来电,用户手机先拦截该陌生来电,即不执行响铃操作,先获取到该陌生来电的号码,并查询用户手机本地存储的电话本或电话簿中记录的号码,当陌生来电的号码不存在于电话本中时,则用户手机不会执行响铃操作,直接根据呼叫转移设置信息,执行拨号虚拟转接号码,该虚拟转接号码是设置在具有虚拟号码运营商的服务端,从而完成呼叫转移。
服务器接收到该呼叫转移的通信语音请求时,可以接受该请求,从而建立陌生来电与服务器之间的通话连接,在通话连接建立后,陌生来电的对方会开始进行说话,服务器接收对方发送的通信语音,将该通信语音通过预置ASR(语音识别,也可以称为自动语音识别Automatic Speech Recognition)模型转换为语音文本,如“您好,这里是xx保险”或“您好,请问是xx女士么”。
需要说明的是,除了用户手机自动进行呼叫转移,还可以在用户不方便接电话的情况下进行自动转接,如,用户在开车,长时间没有接听电话,可以展示提示信息给用户,让用户自主选择是否进行呼叫转移,还可以避免误转的情况发生。或者,当用户长时间没有接听电话,可能用户不在手机旁,用户手机可以直接进行呼叫转移,同时为用户做好文本记录,以及文本分类等。
还需要注意的是,本实施例未详细描述的其它部分,可参考上述方法100和方法600所示实施例的相关说明,在此不再赘述。
为了保证用户对自动语音信息识别无感知,同时能够快速自动识别语音信息,帮助用户避免过多陌生电话的骚扰,同时减少资源消耗以及占用。本申请实施例还提供了一种信息的识别系统。
图9为本申请一示例性实施例提供的一种信息的识别系统的结构示意图。如图9所示,该识别系统900可以包括:第一设备901以及第二设备902,该识别系统900还可以包括第三设备903。
其中,第一设备901可以是有一定计算能力的设备,主要负责将来电呼叫请求转移到第二设备902。第一设备901的基本结构可以包括:至少一个处理器。处理器的数量可以取决于具有一定计算能力装置的配置和类型。具有一定计算能力装置也可以包括存储器,该存储器可以为易失性的,例如RAM,也可以为非易失性的,例如只读存储器(Read-OnlyMemory,ROM)、闪存等,或者也可以同时包括两种类型。存储器内通常存储有操作系统(Operating System,OS)、一个或多个应用程序,也可以存储有程序数据等。除了处理单元和存储器之外,具有一定计算能力装置还包括一些基本配置,例如网卡芯片、IO总线、显示组件以及一些外围设备等。可选地,一些外围设备可以包括,例如键盘、输入笔等。其它外围设备在本领域中是众所周知的,在此不做赘述。可选地,第一设备901可以为智能终端,如手机。
第二设备902是指可以在网络虚拟环境中提供计算处理服务的设备,通常是指利用网络进行信息识别的服务器。在物理实现上,第二设备902可以是任何能够提供计算服务,响应服务请求,并进行处理的设备,例如可以是常规服务器、云服务器、云主机、虚拟中心等。第二设备902的构成主要包括处理器、硬盘、内存、系统总线等,和通用的计算机架构类似。
第三设备903可以是有一定计算能力的设备。第三设备903的基本结构可以包括:至少一个处理器。处理器的数量可以取决于具有一定计算能力装置的配置和类型。具有一定计算能力装置也可以包括存储器,该存储器可以为易失性的,例如RAM,也可以为非易失性的,例如只读存储器(Read-Only Memory,ROM)、闪存等,或者也可以同时包括两种类型。存储器内通常存储有操作系统(Operating System,OS)、一个或多个应用程序,也可以存储有程序数据等。除了处理单元和存储器之外,具有一定计算能力装置还包括一些基本配置,例如网卡芯片、IO总线、显示组件以及一些外围设备等。可选地,一些外围设备可以包括,例如键盘、输入笔等。其它外围设备在本领域中是众所周知的,在此不做赘述。可选地,第三设备903可以为智能终端,如手机。
在本实施例中,第一设备901,接收通信语音请求,在通信语音请求的来源不属于预置来源的情况下,转发通信语音请求至第二设备902。
第二设备902,接收通信语音请求,并获取语音信息对应的语音文本;根据语音文本,获取语音文本对应的语音对话文本;根据语音对话文本,识别语音对话文本所属类别。
第三设备903,发送通信语音请求至第一设备901。
具体的,第二设备902,确定语音文本对应的交互文本;将获取到的语音文本以及对应的交互文本作为一组对话文本,并将至少一组对话文本作为语音对话文本;当语音对话文本存在多组,针对任一两组对话文本,根据前一组对话文本获取后一组对话文本。
具体的,第二设备902,根据前一组对话文本中交互文本,获取后一组对话文本中语音文本;在获取到语音文本后,执行确定语音文本对应的交互文本的步骤。
具体的,第二设备902,通过通信语音发送交互文本,并通过通信语音接收对应的通信语音,以获取到语音文本。
具体的,第二设备902,确定语音文本的语义;根据语义,从对话集合中确定与语音文本对应的交互文本。
具体的,第二设备902,确定语音对话文本的语义,根据语义确定语音对话文本对应的类别。
具体的,第二设备902,发送类别、语音对话文本以及通信语音请求对应的通信标识。
还需要注意的是,本实施例未详细描述的其它部分,可参考上述方法100、方法400-方法700所示实施例的相关说明,在此不再赘述。
此外,在本实施例中,第一设备901,转发通信语音请求至第二设备902。第二设备902,接收通信语音请求,并获取语音信息对应声纹;当声纹为非正常声纹,根据非正常声纹建立非正常声纹库。
第一设备901,还可以直接上报非正常声纹至第二设备902。
在本申请实施例的应用场景中,例如,打电话的应用场景中,陌生来电的手机向用户手机发起呼叫请求,用户手机接收到该呼叫请求后,先拦截该请求,根据预置转发规则,查找该陌生来电的手机号码是否属于用户手机的电话簿,若不属于,则执行呼叫来电转移功能,拨打预置的转移号码,将该呼叫请求转移到预置的转移号码上,如,服务器的虚拟运营商平台,服务器的虚拟运营商平台接收到该呼叫请求后,可以先查找该陌生来电的手机号码是否属于服务器的黑名单,若属于,可直接拒绝该呼叫请求,该黑名单可以记录诈骗电话号码。若不属于,服务器可以接受该呼叫请求,建立语音通话,服务器接收陌生来电的手机发送的语音,服务器还可以获取该语音的声音声纹,并将该声纹与声纹库进行比对,若比对成功,服务器可挂断该电话,该声纹库可以记录诈骗者的声纹。若比对不成功,服务器可将该语音转换为语音文本,确定该语音文本的语义,从语义库中获取与该语义对应的交互文本,并通过通信语音,将该语音文本发送给陌生来电的手机。从而服务器生成语音对话文本,应理解,该语音对话文本是持续更新的。服务器根据对该语音对话文本的语义进行理解,确定出该对话发生的对话场景,从而确定该语音对话文本的类别,从而确定出陌生来电的手机的意图。
当该类别属于诈骗类别时,服务器可直接挂断电话,并将该类别情况、陌生来电的手机号码以及语音对话文本发送至用户手机,使得用户可知晓。
当该类别属于用户所需类型,如推销保险,则服务器可以根据用户需求,着重生成用户所需的交互文本,通过通信语音发送该交互文本,并得到用户所需的内容,并更新语音对话文本。并将最终的语音对话文本、该类别情况以及陌生来电的手机号码发送至用户手机,使得用户可知晓。
此外,在本实施例中,第二设备902,接收类别以及对应的语音对话文本,第二设备902,发送语音对话文本。
第一设备901,获取语音对话文本;根据语音对话文本,识别语音对话文本所属类别,展示类别以及对应的语音对话文本;发送类别以及对应的语音对话文本至第二设备902。
在该应用场景中,与前文所述的应用场景相似,不同的是,服务器将语音对话文本返回至用户手机,且该语音对话文本是持续更新发送到用户手机上,用户手机接收到后,由用户手机对该语音对话文本进行识别,确定类别,直接向用户展示最终的语音对话文本、该类别情况,还可以从服务器获取陌生来电的手机号码进行展示。并将语音对话文本以及该类别情况返回至服务器,使得服务器进行存储,同时用户手机可以直接向用户展示最终的语音对话文本、该类别情况以及陌生来电的手机号码。
在上述本实施例中,第一设备901可以与第二设备902以及第三设备903进行网络连接,该网络连接可以是无线连接。若第一设备901与第二设备902以及第三设备903是通信连接,该移动网络的网络制式可以为2G(GSM)、2.5G(GPRS)、3G(WCDMA、TD-SCDMA、CDMA2000、UTMS)、4G(LTE)、4G+(LTE+)、WiMax、5G等中的任意一种。
为了更好地提高用户的服务,且减少信息被攻击以及泄露的可能,本申请实施例还提供了一种信息的识别方法。
图10为本申请一示例性实施例的一种信息的识别方法的流程示意图。本申请实施例提供的该方法1000由电子终端设备执行,如,手机终端,该方法700包括以下步骤:
1001:当接收到通信语音请求,且在通信语音请求的来源不属于预置来源的情况下,通过智能音箱接收通信语音,并屏蔽接收用户语音以及屏蔽向用户提供通信语音。
1002:通过智能音箱获取通信语音对应的语音文本。
1003:通过智能音箱根据语音文本,获取语音文本对应的语音对话文本。
1004:通过智能音箱根据语音对话文本,识别语音对话文本所属类别。
需要说明的是,由于前文方法1000的实施例中已经详细阐述了上述步骤1001-步骤1004的具体实施方式,此处就不再细述。
仅说明,在执行设备终端中可以设置智能音箱,该智能音箱可以执行步骤1001-1004,执行的具体方式与方法100相似,此处就不再赘述。智能音箱在接受请求后,会暂时关闭用户终端,如手机声音播放的功能以及收集用户声音的功能,如暂停听筒以及喇叭以及话筒的功能。
此外,在使用智能音箱前,需要对智能音箱进行设置,该方法100还包括:响应于用户的开启以及授权操作,开启智能音箱,并使智能音箱在通信语音请求的来源不属于预置来源的情况下,接收通信语音。
例如,向用户提供设置界面,用户根据该界面上的提示信息,打开使用智能音箱的按钮,即启动智能音箱,并对智能音箱进行授权,使得智能音箱有权限获取通信语音,并实现本方案。此外,智能音箱提供的该服务可能会带来通信费用,当用户启动智能音箱,则视为同意收取通信费用。否则,智能音箱不会不用被开启。
此外,该方法1000还包括:提供用户接收通信语音的提示信息;响应于用户的接收操作,撤销屏蔽动作,接收用户语音以及屏蔽向用户提供通信语音。
在智能音箱进行工作时,可以持续性地向用户提供提示信息,询问用户是否自己进行语音接听的操作,当用户同意接听,则智能音箱打开听筒以及话筒功能,使得用户可以与来电用户进行通话。提高用户的体验。
此外,智能音箱还可以在无法准确回答来电用户的通话时,将问题以文字形式展示给用户,提示用户是否亲自与来电用户进行作答,当用户同意时,则智能音箱打开听筒以及话筒功能,使得用户可以与来电用户进行通话。智能音箱停止进行通话。当用户接收该通话后,如果用户直接挂断电话,则智能音箱不再执行。当用户仅仅是停止与来电用户进行通话,则继续由智能音箱进行通话。
图11为本申请一示例性实施例提供的信息的识别装置的结构框架示意图。该装置1100可以应用于电子终端设备中,例如,手机、平板电脑以及台式电脑等,该装置1100包括获取模块1101以及识别模块1102,以下针对各个模块的功能进行详细的阐述:
获取模块1101,用于接收通信语音请求,在通信语音请求的来源不属于预置来源的情况下,获取通信语音对应的语音文本。
获取模块1101,用于根据语音文本,获取语音文本对应的语音对话文本。
识别模块1102,用于根据语音对话文本,识别语音对话文本所属类别。
此外,获取模块1101,还用于获取通信语音请求的来源,将来源与用户预置正常来源集合进行匹配;该装置1100还包括:提供模块,用于在匹配成功的情况下,将通信语音提供给用户。
获取模块1101,还用于获取通信语音请求的来源,将来源与预置非正常来源集合进行匹配;提供模块,还用于在匹配成功的情况下,将是否接受通信语音的提示信息提供给用户。
获取模块1101,还用于获取通信语音请求的来源,将来源与预置非正常来源集合进行匹配;该装置1100还包括:拒绝模块,用于在匹配到其中非法来源的情况下,拒绝通信语音请求。
获取模块1101,还用于在通信语音请求的来源不属于预置来源的情况下,获取通信语音的声纹;在声纹不属于非正常声纹库的情况下,执行获取通信语音对应的语音文本的步骤。
此外,该装置1100还包括:建立模块,用于建立非正常声纹库,非正常声纹库是根据非正常声纹得到的。
此外,该装置1100还包括:更新模块,用于当类别为非正常类别,将声纹作为非正常声纹更新至非正常声纹库。
此外,该装置1100还包括:确定模块,用于将声纹与非正常声纹库中的多个声纹进行匹配,当匹配成功,则确定声纹为非正常声纹。
确定模块,还用于当匹配到的声纹属于非正常声纹中的非法声纹,则确定对应通信语音为非法通信语音,并终止接收通信语音。
更新模块,还用于接收上报的声纹以及上报类别,当上报类别为非正常类别,则将上报的声纹作为非正常声纹更新至非正常声纹库。
在更新非正常声纹库前,更新模块,用于当确定声纹不存在于非正常声纹库中,则将声纹作为非正常声纹更新至非正常声纹库。
确定模块,还用于当类别为非正常类别,确定通信语音为非正常通信语音。
确定模块,还用于当类别为非正常类别中的非法类别,确定通信语音为非正常通信语音中的非法通信语音以及声纹为非正常声纹中的非法声纹,并终止接收通信语音。
具体的,获取模块1101,用于将获取到的语音文本直接作为语音对话文本。
具体的,获取模块1101,包括:确定单元,用于确定语音文本对应的交互文本;将获取到的语音文本以及对应的交互文本作为一组对话文本,并将至少一组对话文本作为语音对话文本;获取单元,用于当语音对话文本存在多组,针对任一两组对话文本,根据前一组对话文本获取后一组对话文本。
具体的,获取单元,用于根据前一组对话文本中交互文本,获取后一组对话文本中语音文本;在获取到语音文本后,执行确定语音文本对应的交互文本的步骤。
具体的,获取单元,用于通过通信语音发送交互文本,并接收对应的通信语音,以获取到语音文本。
具体的,确定单元,用于确定语音文本的语义;根据语义,从对话集合中确定与语音文本对应的交互文本。
具体的,识别模块1102,用于确定语音对话文本的语义,根据语义确定语音对话文本对应的类别。
获取模块1101,还用于当类别为用户所需类别,则根据用户所需类别的内容,获取与内容匹配的语音对话文本,用户所需类别可属于非正常类别。
此外,确定模块,还用于当类别为其它类别,确定声纹为其它类别声纹。
此外,该装置1100还包括:设置模块,用于将其它类别声纹设置到对应类别声纹库。
此外,确定模块,还用于根据类别,确定通信语音请求的来源的类别。
此外,设置模块,还用于将通信语音请求的来源设置到对应来源类别集合中。
此外,提供模块,还用于向用户提供类别以及通信语音请求的来源。
此外,提供模块,还用于向用户提供语音对话文本。
此外,该装置1100还包括:接收模块,用于接收类别的调整信息;调整模块,用于根据调整信息调整类别;将调整后类别以及对应的语音对话文本作为用于优化模型的样本;其中,模型用于确定语音对话文本的语义,根据语义确定语音对话文本对应的类别。
在获取语音文本对应的语音对话文本后,提供模块,还用于向用户提供语音对话文本的查看地址。
此外,该装置1100还包括:记录模块,用于记录语音对话文本所属对话语音;提供模块,用于向用户提供语音对话文本所属对话语音的收听地址。
此外,该装置1100还包括:屏蔽模块,用于在通信语音请求的来源不属于预置来源的情况下,接受通信语音请求,并屏蔽接收用户语音以及屏蔽向用户提供通信语音。
此外,提供模块,还用于在通信语音请求的来源属于预置来源的情况下,向用户提供通信语音请求的来源。
图12为本申请又一示例性实施例提供的一种信息的识别装置的结构框架示意图。该装置1200可以应用于电子设备,如,常规服务器;该装置1200包括:获取模块1201以及识别模块1202,以下针对各个模块的功能进行详细的阐述:
获取模块1201,用于接受转发的通信语音请求,并获取语音信息对应的语音文本。
识别模块1202,用于根据语音文本,获取语音文本对应的语音对话文本;根据语音对话文本,识别语音对话文本所属类别。
具体的,获取模块1201,用于将获取到的语音文本直接作为语音对话文本。
具体的,获取模块1201,包括:确定单元,用于确定语音文本对应的交互文本;将获取到的语音文本以及对应的交互文本作为一组对话文本,并将至少一组对话文本作为语音对话文本;获取单元,用于当语音对话文本存在多组,针对任一两组对话文本,根据前一组对话文本获取后一组对话文本。
具体的,获取单元,用于根据前一组对话文本中交互文本,获取后一组对话文本中语音文本;在获取到语音文本后,执行确定语音文本对应的交互文本的步骤。
具体的,获取单元,用于通过通信语音发送交互文本,并接收对应的通信语音,以获取到语音文本。
具体的,确定单元,用于确定语音文本的语义;根据语义,从对话集合中确定与语音文本对应的交互文本。
具体的,识别模块1202,用于确定语音对话文本的语义,根据语义确定语音对话文本对应的类别。
此外,该装置1200还包括:存储模块,用于接收上报的通信语音请求的来源以及上报类别,根据上报类型,将通信语音请求的来源存储至对应来源类别集合中。
存储模块,还用于针对任一上报类别,根据来源的上报次数,将上报的通信语音请求的来源存储至对应来源类别集合中。
存储模块,用于针对任一上报类别,根据来源的上报次数以及上报用户数量,将上报的通信语音请求的来源存储至对应来源类别集合中。
此外,该装置1200还包括:下发模块,用于将更新后的来源类别集合下发至对应的设备,以进行更新。
需要注意的是,本实施例未详细描述的部分,可参考上述识别装置所示实施例的相关说明,在此不再赘述。
图13为本申请又一示例性实施例提供的一种声纹库的建立装置的结构框架示意图。该装置1300可以应用于电子设备,如,常规服务器或手机等;该装置1300包括:建立模块1301,以下针对各个模块的功能进行详细的阐述:
建立模块1301,用于建立非正常声纹库,非正常声纹库是根据非正常声纹得到的。
此外,该装置1300包括:确定模块,用于接收通信语音,并确定通信语音对应的声纹;更新模块,用于当确定通信语音为非正常通信语音,将声纹作为非正常声纹更新至非正常声纹库。
此外,确定模块,还用于接收通信语音,并确定通信语音对应的声纹;将声纹与非正常声纹库中的多个声纹进行匹配,当匹配成功,则确定声纹为非正常声纹。
此外,确定模块,还用于当匹配到的声纹属于非正常声纹中的非法声纹,则确定对应通信语音为非法通信语音,并终止接收通信语音。
此外,该装置1300包括:接收模块,用于接收上报的声纹以及上报类别,当上报类别为非正常类别,则将上报的声纹作为非正常声纹更新至非正常声纹库。
更新至非正常声纹库前,更新模块,还用于当确定声纹不存在于非正常声纹库中,则将声纹作为非正常声纹更新至非正常声纹库。
此外,该装置1300包括:获取模块,用于当声纹不存在于非正常声纹库中,获取通信语音对应的语音文本;根据语音文本,获取语音文本对应的语音对话文本;识别模块,用于根据语音对话文本,识别语音对话文本所属类别。
需要注意的是,本实施例未详细描述的部分,可参考上述识别装置所示实施例的相关说明,在此不再赘述。
图14为本申请又一示例性实施例提供的一种信息的识别装置的结构框架示意图。该装置1400可以应用于电子设备,如,终端;该装置1400包括:屏蔽模块1401、获取模块1402以及识别模块1403,以下针对各个模块的功能进行详细的阐述:
屏蔽模块1401,用于当接收到通信语音请求,且在通信语音请求的来源不属于预置来源的情况下,通过智能音箱接收通信语音,并屏蔽接收用户语音以及屏蔽向用户提供通信语音。
获取模块1402,用于通过智能音箱获取通信语音对应的语音文本。
获取模块1402,用于通过智能音箱根据语音文本,获取语音文本对应的语音对话文本。
识别模块1403,用于通过智能音箱根据语音对话文本,识别语音对话文本所属类别。
此外,该装置1400还包括:开启模块,用于响应于用户的开启以及授权操作,开启智能音箱,并使智能音箱在通信语音请求的来源不属于预置来源的情况下,接收通信语音。
此外,该装置1400还包括:提供模块,用于提供用户接收通信语音的提示信息;撤销模块,用于响应于用户的接收操作,撤销屏蔽动作,接收用户语音以及屏蔽向用户提供通信语音。
需要注意的是,本实施例未详细描述的部分,可参考上述识别装置所示实施例的相关说明,在此不再赘述。
图15为本申请又一示例性实施例提供的一种信息的设置装置的结构框架示意图。该装置1500可以应用于电子设备,如,终端;该装置1500包括:获取模块1501、绑定模块1502以及设置模块1503,以下针对各个模块的功能进行详细的阐述:
获取模块1501,用于获取用户通信语音标识。
绑定模块1502,用于将用户通信语音标识与转接通信语音标识进行绑定,以使在预置条件下根据绑定关系,将通信语音请求转发至转接通信语音标识所属设备。
设置模块1503,用于设置预置条件。
设置模块1503,还用于设置在预置条件下对对应通信语音的处理方式。
此外,该装置1500还包括:接收模块,用于接收通信语音请求,并获取通信语音请求对应的通信语音标识;转发模块,用于当获取到的语音通信标识满足预置条件,则根据绑定关系,将通信语音请求转发至转接通信语音标识所属设备。
获取模块1501,还用于获取通信语音的声纹,将声纹以及声纹的类别进行上报。
此外,该装置1500还包括:匹配模块,用于将声纹与本地声纹库中已上报声纹进行对匹配,当未匹配到对应声纹,则执行将声纹以及声纹的类别进行上报的步骤。
获取模块1501,还用于获取通信语音标识,将通信语音标识以及通信语音标识的类别进行上报。
接收模块,还用于接收并展示通信语音请求对应的通信语音类别以及通信语音对应的语音对话文本。
接收模块,还用于接收通信语音请求对应通信语音的语音对话文本;该装置1500还包括:确定模块,用于响应于用户的输入操作,确定通信语音的类别;上报模块,用于上报类别以及对应的语音对话文本。
需要注意的是,本实施例未详细描述的部分,可参考上述识别装置所示实施例的相关说明,在此不再赘述。
图16为本申请又一示例性实施例提供的一种信息的设置装置的结构框架示意图。该装置1600可以应用于电子设备,如,终端;该装置1600包括:提供模块1601、确定模块1602以及绑定模块1603,以下针对各个模块的功能进行详细的阐述:
提供模块1601,用于提供通信语音标识的绑定界面,绑定界面中展示了用户通信语音标识输入区域、转接通信语音标识输入区域以及预置条件输入区域,用户通信语音标识与转接通信语音标识具有绑定关系。
确定模块1602,用于响应于用户的输入操作,确定对应输入区域中的用户通信语音标识以及语音转接通信标识。
确定模块1602,用于响应于用户的输入操作,确定对应输入区域中的预置条件,在预置条件下,转发通信语音请求至转接通信语音标识所属设备。
绑定模块1603,用于响应于绑定操作,完成绑定关系的操作。
此外,该装置1600还包括:发送模块,用于将绑定关系发送至通信语音转接设备。
需要注意的是,本实施例未详细描述的部分,可参考上述识别装置所示实施例的相关说明,在此不再赘述。
以上描述了图11所示的识别装置1100的内部功能和结构,在一个可能的设计中,图11所示的识别装置1100的结构可实现为终端设备,如图17所示,该设备1700可以包括:存储器1701、处理器1702以及通信组件1703;
存储器1701,用于存储计算机程序;
通信组件1703,用于接收通信语音请求。
处理器1702,用于执行计算机程序,以用于:在通信语音请求的来源不属于预置来源的情况下,获取通信语音对应的语音文本;根据语音文本,获取语音文本对应的语音对话文本;根据语音对话文本,识别语音对话文本所属类别。
此外,处理器1702,还用于,获取通信语音请求的来源,将来源与用户预置正常来源集合进行匹配;在匹配成功的情况下,将通信语音提供给用户。
此外,处理器1702,还用于,获取通信语音请求的来源,将来源与预置非正常来源集合进行匹配;在匹配成功的情况下,将是否接受通信语音的提示信息提供给用户。
此外,处理器1702,还用于,获取通信语音请求的来源,将来源与预置非正常来源集合进行匹配;在匹配到其中非法来源的情况下,拒绝通信语音请求。
此外,处理器1702,还用于,在通信语音请求的来源不属于预置来源的情况下,获取通信语音的声纹;在声纹不属于非正常声纹库的情况下,执行获取通信语音对应的语音文本的步骤。
此外,处理器1702,还用于,建立非正常声纹库,非正常声纹库是根据非正常声纹得到的。
此外,处理器1702,还用于,当类别为非正常类别,将声纹作为非正常声纹更新至非正常声纹库。
此外,处理器1702,还用于,将声纹与非正常声纹库中的多个声纹进行匹配,当匹配成功,则确定声纹为非正常声纹。
此外,处理器1702,还用于,当匹配到的声纹属于非正常声纹中的非法声纹,则确定对应通信语音为非法通信语音,并终止接收通信语音。
此外,处理器1702,还用于,接收上报的声纹以及上报类别,当上报类别为非正常类别,则将上报的声纹作为非正常声纹更新至非正常声纹库。
在更新非正常声纹库前,此外,处理器1702,还用于,当确定声纹不存在于非正常声纹库中,则将声纹作为非正常声纹更新至非正常声纹库。
此外,处理器1702,还用于,当类别为非正常类别,确定通信语音为非正常通信语音。
此外,处理器1702,还用于,当类别为非正常类别中的非法类别,确定通信语音为非正常通信语音中的非法通信语音以及声纹为非正常声纹中的非法声纹,并终止接收通信语音。
具体的,处理器1702,具体用于,将获取到的语音文本直接作为语音对话文本。
具体的,处理器1702,具体用于,确定语音文本对应的交互文本;将获取到的语音文本以及对应的交互文本作为一组对话文本,并将至少一组对话文本作为语音对话文本;当语音对话文本存在多组,针对任一两组对话文本,根据前一组对话文本获取后一组对话文本。
具体的,处理器1702,具体用于,根据前一组对话文本中交互文本,获取后一组对话文本中语音文本;在获取到语音文本后,执行确定语音文本对应的交互文本的步骤。
具体的,处理器1702,具体用于,通过通信语音发送交互文本,并接收对应的通信语音,以获取到语音文本。
具体的,处理器1702,具体用于,确定语音文本的语义;根据语义,从对话集合中确定与语音文本对应的交互文本。
具体的,处理器1702,具体用于,确定语音对话文本的语义,根据语义确定语音对话文本对应的类别。
此外,处理器1702,还用于,当类别为用户所需类别,则根据用户所需类别的内容,获取与内容匹配的语音对话文本,用户所需类别可属于非正常类别。
此外,处理器1702,还用于,当类别为其它类别,确定声纹为其它类别声纹。
此外,处理器1702,还用于,将其它类别声纹设置到对应类别声纹库。
此外,处理器1702,还用于,根据类别,确定通信语音请求的来源的类别。
此外,处理器1702,还用于,将通信语音请求的来源设置到对应来源类别集合中。
此外,处理器1702,还用于,向用户提供类别以及通信语音请求的来源。
此外,处理器1702,还用于,向用户提供语音对话文本。
此外,处理器1702,还用于,接收类别的调整信息;根据调整信息调整类别;将调整后类别以及对应的语音对话文本作为用于优化模型的样本;其中,模型用于确定语音对话文本的语义,根据语义确定语音对话文本对应的类别。
在获取语音文本对应的语音对话文本后,此外,处理器1702,还用于,向用户提供语音对话文本的查看地址。
此外,处理器1702,还用于,记录语音对话文本所属对话语音;向用户提供语音对话文本所属对话语音的收听地址。
此外,处理器1702,还用于,在通信语音请求的来源不属于预置来源的情况下,接受通信语音请求,并屏蔽接收用户语音以及屏蔽向用户提供通信语音。
此外,处理器1702,还用于,在通信语音请求的来源属于预置来源的情况下,向用户提供通信语音请求的来源。
另外,本发明实施例提供了一种计算机存储介质,计算机程序被一个或多个处理器执行时,致使一个或多个处理器实现图1-图3方法实施例中信息的识别方法的步骤。
以上描述了图12所示的识别装置1200的内部功能和结构,在一个可能的设计中,图12所示的识别装置1200的结构可实现为服务器,如图18所示,该设备1800可以包括:存储器1801、处理器1802;
存储器1801,用于存储计算机程序;
处理器1802,用于执行计算机程序,以用于:接受转发的通信语音请求,并获取语音信息对应的语音文本;根据语音文本,获取语音文本对应的语音对话文本;根据语音对话文本,识别语音对话文本所属类别。
具体的,处理器1802,具体用于:将获取到的语音文本直接作为语音对话文本。
具体的,处理器1802,具体用于:确定语音文本对应的交互文本;将获取到的语音文本以及对应的交互文本作为一组对话文本,并将至少一组对话文本作为语音对话文本;当语音对话文本存在多组,针对任一两组对话文本,根据前一组对话文本获取后一组对话文本。
具体的,处理器1802,具体用于:根据前一组对话文本中交互文本,获取后一组对话文本中语音文本;在获取到语音文本后,执行确定语音文本对应的交互文本的步骤。
具体的,处理器1802,具体用于:通过通信语音发送交互文本,并接收对应的通信语音,以获取到语音文本。
具体的,处理器1802,具体用于:确定语音文本的语义;根据语义,从对话集合中确定与语音文本对应的交互文本。
具体的,处理器1802,具体用于:确定语音对话文本的语义,根据语义确定语音对话文本对应的类别。
此外,处理器1802,还用于:接收上报的通信语音请求的来源以及上报类别,根据上报类型,将通信语音请求的来源存储至对应来源类别集合中。
此外,处理器1802,还用于:针对任一上报类别,根据来源的上报次数,将上报的通信语音请求的来源存储至对应来源类别集合中。
此外,处理器1802,还用于:针对任一上报类别,根据来源的上报次数以及上报用户数量,将上报的通信语音请求的来源存储至对应来源类别集合中。
此外,处理器1802,还用于:将更新后的来源类别集合下发至对应的设备,以进行更新。
需要注意的是,本实施例未详细描述的部分,可参考上述电子设备1700所示实施例的相关说明,在此不再赘述。
另外,本发明实施例提供了一种计算机存储介质,计算机程序被一个或多个处理器执行时,致使一个或多个处理器实现图5方法实施例中信息的识别方法的步骤。
以上描述了图13所示的建立装置1300的内部功能和结构,在一个可能的设计中,图13所示的建立装置1300的结构可实现为服务器,如图19所示,该设备1900可以包括:存储器1901、处理器1902;
存储器1901,用于存储计算机程序;
处理器1902,用于执行计算机程序,以用于:建立非正常声纹库,非正常声纹库是根据非正常声纹得到的。
此外,该设备1900可以包括:通信组件,用于接收通信语音,此外,处理器1902,还用于确定通信语音对应的声纹;更新模块,用于当确定通信语音为非正常通信语音,将声纹作为非正常声纹更新至非正常声纹库。
此外,通信组件,还用于接收通信语音,此外,处理器1902,还用于确定通信语音对应的声纹;将声纹与非正常声纹库中的多个声纹进行匹配,当匹配成功,则确定声纹为非正常声纹。
此外,处理器1902,还用于当匹配到的声纹属于非正常声纹中的非法声纹,则确定对应通信语音为非法通信语音,并终止接收通信语音。
此外,处理器1902,还用于接收上报的声纹以及上报类别,当上报类别为非正常类别,则将上报的声纹作为非正常声纹更新至非正常声纹库。
更新至非正常声纹库前,此外,处理器1902,还用于当确定声纹不存在于非正常声纹库中,则将声纹作为非正常声纹更新至非正常声纹库。
此外,处理器1902,还用于当声纹不存在于非正常声纹库中,获取通信语音对应的语音文本;根据语音文本,获取语音文本对应的语音对话文本;识别模块,用于根据语音对话文本,识别语音对话文本所属类别。
需要注意的是,本实施例未详细描述的部分,可参考上述电子设备1700所示实施例的相关说明,在此不再赘述。
另外,本发明实施例提供了一种计算机存储介质,计算机程序被一个或多个处理器执行时,致使一个或多个处理器实现图4方法实施例中声纹库的建立方法的步骤。
以上描述了图14所示的识别装置1400的内部功能和结构,在一个可能的设计中,图14所示的识别装置1400的结构可实现为服务器,如图20所示,该设备2000可以包括:存储器2001、处理器2002;
存储器2001,用于存储计算机程序;
处理器2002,用于执行计算机程序,以用于:用于当接收到通信语音请求,且在通信语音请求的来源不属于预置来源的情况下,通过智能音箱接收通信语音,并屏蔽接收用户语音以及屏蔽向用户提供通信语音;通过智能音箱获取通信语音对应的语音文本;通过智能音箱根据语音文本,获取语音文本对应的语音对话文本;通过智能音箱根据语音对话文本,识别语音对话文本所属类别。
此外,处理器2002,还用于响应于用户的开启以及授权操作,开启智能音箱,并使智能音箱在通信语音请求的来源不属于预置来源的情况下,接收通信语音。
此外,处理器2002,还用于提供用户接收通信语音的提示信息;撤销模块,用于响应于用户的接收操作,撤销屏蔽动作,接收用户语音以及屏蔽向用户提供通信语音。
需要注意的是,本实施例未详细描述的部分,可参考上述电子设备1700所示实施例的相关说明,在此不再赘述。
另外,本发明实施例提供了一种计算机存储介质,计算机程序被一个或多个处理器执行时,致使一个或多个处理器实现图10方法实施例中信息的识别方法的步骤。
以上描述了图15所示的设置装置1500的内部功能和结构,在一个可能的设计中,图15所示的设置装置1500的结构可实现为智能终端设备,如,手机,如图21所示,该设备2100可以包括:存储器2101以及处理器2102;
存储器2101,用于存储计算机程序;
处理器2102,用于执行计算机程序,以用于:获取用户通信语音标识;将用户通信语音标识与转接通信语音标识进行绑定,以使在预置条件下根据绑定关系,将通信语音请求转发至转接通信语音标识所属设备;设置预置条件。
此外,处理器2102,还用于设置在预置条件下对对应通信语音的处理方式。
此外,处理器2102,还用于接收通信语音请求,并获取通信语音请求对应的通信语音标识;当获取到的语音通信标识满足预置条件,则根据绑定关系,将通信语音请求转发至转接通信语音标识所属设备。
此外,处理器2102,还用于获取通信语音的声纹,将声纹以及声纹的类别进行上报。
此外,处理器2102,还用于将声纹与本地声纹库中已上报声纹进行对匹配,当未匹配到对应声纹,则执行将声纹以及声纹的类别进行上报的步骤。
此外,处理器2102,还用于获取通信语音标识,将通信语音标识以及通信语音标识的类别进行上报。
此外,处理器2102,还用于接收并展示通信语音请求对应的通信语音类别以及通信语音对应的语音对话文本。
此外,处理器2102,还用于接收通信语音请求对应通信语音的语音对话文本;响应于用户的输入操作,确定通信语音的类别;上报类别以及对应的语音对话文本。
需要注意的是,本实施例未详细描述的部分,可参考上述电子设备1700所示实施例的相关说明,在此不再赘述。
另外,本发明实施例提供了一种计算机存储介质,计算机程序被一个或多个处理器执行时,致使一个或多个处理器实现图6方法实施例中信息的设置方法的步骤。
以上描述了图16所示的设置装置1600的内部功能和结构,在一个可能的设计中,图16所示的设置装置1600的结构可实现为智能终端设备,如,手机,如图22所示,该设备2200可以包括:存储器2201以及处理器2202;
存储器2201,用于存储计算机程序;
处理器2202,用于执行计算机程序,以用于:用于提供通信语音标识的绑定界面,绑定界面中展示了用户通信语音标识输入区域、转接通信语音标识输入区域以及预置条件输入区域,用户通信语音标识与转接通信语音标识具有绑定关系;响应于用户的输入操作,确定对应输入区域中的用户通信语音标识以及语音转接通信标识;响应于用户的输入操作,确定对应输入区域中的预置条件,在预置条件下,转发通信语音请求至转接通信语音标识所属设备;响应于绑定操作,完成绑定关系的操作。
此外,处理器2202,还用于将绑定关系发送至通信语音转接设备。
需要注意的是,本实施例未详细描述的部分,可参考上述电子设备1700所示实施例的相关说明,在此不再赘述。
另外,本发明实施例提供了一种计算机存储介质,计算机程序被一个或多个处理器执行时,致使一个或多个处理器实现图7方法实施例中信息的设置方法的步骤。
另外,在上述实施例及附图中的描述的一些流程中,包含了按照特定顺序出现的多个操作,但是应该清楚了解,这些操作可以不按照其在本文中出现的顺序来执行或并行执行,操作的序号如201、202、203等,仅仅是用于区分开各个不同的操作,序号本身不代表任何的执行顺序。另外,这些流程可以包括更多或更少的操作,并且这些操作可以按顺序执行或并行执行。需要说明的是,本文中的“第一”、“第二”等描述,是用于区分不同的消息、设备、模块等,不代表先后顺序,也不限定“第一”和“第二”是不同的类型。
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助加必需的通用硬件平台的方式来实现,当然也可以通过硬件和软件结合的方式来实现。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以计算机产品的形式体现出来,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程多媒体数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程多媒体数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程多媒体数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程多媒体数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM)。内存是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 信息的识别方法、系统、计算设备及存储介质
- 拓扑信息识别方法、装置、计算设备及存储介质