基于计算框架的数据处理方法、装置、设备和存储介质
文献发布时间:2023-06-19 11:29:13
技术领域
本申请涉及数据处理技术领域,尤其涉及一种基于计算框架的数据处理方法、装置、设备和存储介质。
背景技术
随着数据处理技术的发展,对于大数据的处理要求也越来越高。现在为了满足对实时性数据的处理需求,提供了一种Spark Streaming计算框架。Spark Streaming可以提供丰富的API、基于内存的高速执行引擎。
现在,可以通过Spark Streaming计算框架,在每一个时间片上接收数据;然后,将每一个时间片上的数据作为一个整体进行处理。具体的,通过Spark Streaming计算框架,规定了时间片的时间长度;在第一个时间片内接收数据,然后将与第一时间片对应的数据做为一个批次进行处理;然后,在第二时间片内接收数据,然后将与第二时间片对应的数据做为一个批次进行处理;以此类推。
然而现有技术中,在基于Spark Streaming计算框架接收数据和处理数据的时候,由于是将每一个时间片上的数据作为一个整体进行处理,需要先在一个时间片内接收数据,然后再将与该时间片对应的这些数据进行处理,从而会出现在与上一个时间片对应的数据没有处理结束时,下一个时间片的数据就开始进行接收了,进而会造成数据堆积的情况,进而会造成数据处理效率较低。
发明内容
本申请提供一种基于计算框架的数据处理方法、装置、设备和存储介质,用以解决基于计算框架的数据处理过程中的数据堆积、数据处理效率较低的问题。
第一方面,本申请提供了一种基于计算框架的数据处理方法,所述方法包括:
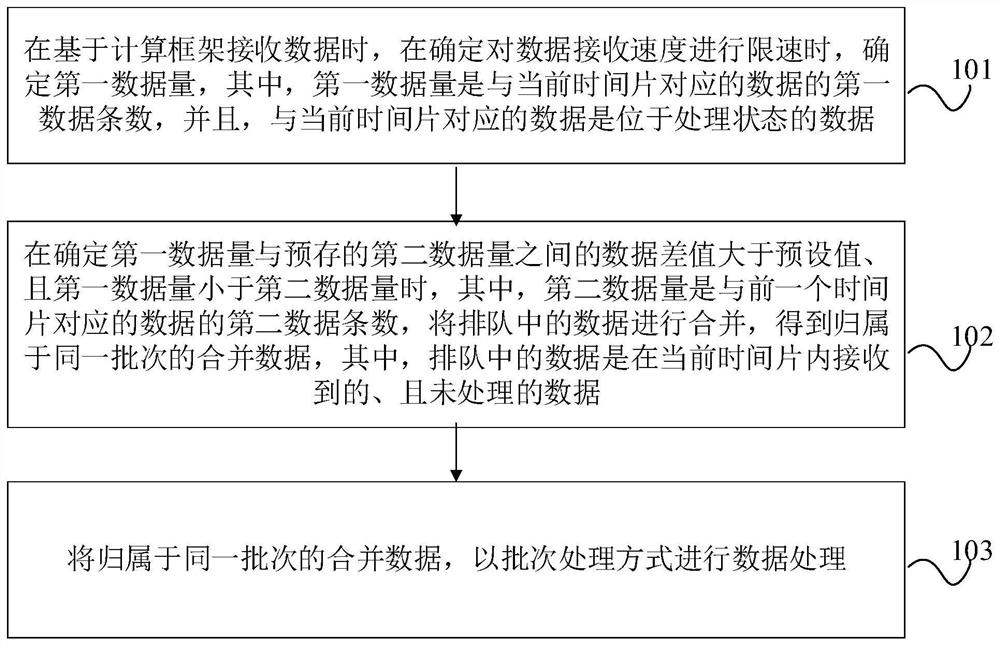
在基于计算框架接收数据时,在确定对数据接收速度进行限速时,确定第一数据量,其中,所述第一数据量是与当前时间片对应的数据的第一数据条数,并且,与当前时间片对应的数据是位于处理状态的数据;
在确定所述第一数据量与预存的第二数据量之间的数据差值大于预设值、且所述第一数据量小于所述第二数据量时,其中,所述第二数据量是与前一个时间片对应的数据的第二数据条数,将排队中的数据进行合并,得到归属于同一批次的合并数据,其中,所述排队中的数据是在所述当前时间片内接收到的、且未处理的数据;
将归属于同一批次的合并数据,以批次处理方式进行数据处理。
进一步地,所述将排队中的数据进行合并,得到归属于同一批次的合并数据,包括:
根据所述排队中的数据的数据总条数、以及预设的平均条数,确定批次个数N,其中,N为大于等于1的正整数;
根据所述批次个数N,将所述排队中的数据进行合并,得到N个批次的合并数据;
将归属于同一批次的合并数据,以批次处理方式进行数据处理,包括:
将N个批次的合并数据中的每一个批次的合并数据,分别以批次处理方式进行数据处理。
进一步地,所述批次个数
其中,S是所述数据总条数,T是所述平均条数。
进一步地,在根据所述排队中的数据的数据总条数、以及预设的平均条数,确定批次个数N之前,还包括:
获取与多个时间片中每一个时间片对应的数据的时间片内数据条数,其中,所述多个时间片为在所述的当前时间片之前的时间片;
将各所述时间片内数据条数的平均值,做为所述平均条数。
进一步地,所述在确定对数据接收速度进行限速时,确定第一数据量之前,还包括:
获取所述当前时间片的第一时间长度,并获取处理与当前时间片所对应的数据所需要的第二时间长度;
在确定所述第二时间长度大于所述第一时间长度时,对数据接收速度进行限速。
进一步地,所述方法,还包括:
在确定所述第二时间长度小于等于所述第一时间长度时,以预设速度对与每一个时间片对应的数据进行处理。
进一步地,所述方法,还包括:
在确定所述第一数据量与预存的第二数据量之间的数据差值小于等于预设值、且所述第一数据量小于所述第二数据量时,或者在确定所述第一数据量大于等于所述第二数据量时,以预设速度与每一个时间片对应的数据进行处理。
第二方面,本申请提供了一种基于计算框架的数据处理装置,所述装置包括:
第一确定单元,用于在基于计算框架接收数据时,在确定对数据接收速度进行限速时,确定第一数据量,其中,所述第一数据量是与当前时间片对应的数据的第一数据条数,并且,与当前时间片对应的数据是位于处理状态的数据;
合并单元,用于在确定所述第一数据量与预存的第二数据量之间的数据差值大于预设值、且所述第一数据量小于所述第二数据量时,其中,所述第二数据量是与前一个时间片对应的数据的第二数据条数,将排队中的数据进行合并,得到归属于同一批次的合并数据,其中,所述排队中的数据是在所述当前时间片内接收到的、且未处理的数据;
第一处理单元,用于将归属于同一批次的合并数据,以批次处理方式进行数据处理。
进一步地,所述合并单元,包括:
确定模块,用于根据所述排队中的数据的数据总条数、以及预设的平均条数,确定批次个数N,其中,N为大于等于1的正整数;
合并模块,用于根据所述批次个数N,将所述排队中的数据进行合并,得到N个批次的合并数据;
所述第一处理单元,具体用于:
将N个批次的合并数据中的每一个批次的合并数据,分别以批次处理方式进行数据处理。
进一步地,所述批次个数
其中,S是所述数据总条数,T是所述平均条数。
进一步地,所述装置,还包括:
第二确定单元,用于在所述确定模块根据所述排队中的数据的数据总条数、以及预设的平均条数,确定批次个数N之前,获取与多个时间片中每一个时间片对应的数据的时间片内数据条数,其中,所述多个时间片为在所述的当前时间片之前的时间片;将各所述时间片内数据条数的平均值,做为所述平均条数。
进一步地,所述装置,还包括:
获取单元,用于所述第一确定单元在确定对数据接收速度进行限速时,确定第一数据量之前,获取所述当前时间片的第一时间长度,并获取处理与当前时间片所对应的数据所需要的第二时间长度;
限速单元,用于在确定所述第二时间长度大于所述第一时间长度时,对数据接收速度进行限速。
进一步地,所述装置,还包括:
第二处理单元,用于在确定所述第二时间长度小于等于所述第一时间长度时,以预设速度对与每一个时间片对应的数据进行处理。
进一步地,所述装置,还包括:
第三处理单元,用于在确定所述第一数据量与预存的第二数据量之间的数据差值小于等于预设值、且所述第一数据量小于所述第二数据量时,或者在确定所述第一数据量大于等于所述第二数据量时,以预设速度与每一个时间片对应的数据进行处理。
第三方面,本申请提供了一种基于计算框架的数据处理设备,包括用于执行以上第一方面的任一方法各个步骤的单元或者手段(means)。
第四方面,本申请提供了一种基于计算框架的数据处理设备,包括处理器、存储器以及计算机程序,其中,所述计算机程序存储在所述存储器中,并被配置为由所述处理器执行以实现第一方面的任一方法。
第五方面,本申请提供了一种基于计算框架的数据处理设备,包括用于执行以上第一方面的任一方法的至少一个处理元件或芯片。
第六方面,本申请提供了一种计算机程序,该计算程序在被处理器执行时用于执行以上第一方面的任一方法。
第七方面,本申请提供了一种计算机可读存储介质,其上存储有第六方面的计算机程序。
本申请提供的基于计算框架的数据处理方法、装置、设备和存储介质,通过在基于计算框架接收数据时,在确定对数据接收速度进行限速时,确定第一数据量,其中,第一数据量是与当前时间片对应的数据的第一数据条数,并且,与当前时间片对应的数据是位于处理状态的数据;在确定第一数据量与预存的第二数据量之间的数据差值大于预设值、且第一数据量小于第二数据量时,其中,第二数据量是与前一个时间片对应的数据的第二数据条数,将排队中的数据进行合并,得到归属于同一批次的合并数据,其中,排队中的数据是在当前时间片内接收到的、且未处理的数据;将归属于同一批次的合并数据,以批次处理方式进行数据处理。可以在基于Spark Streaming计算框架进行数据处理的过程中,基于当前时间片所接收到的数据量远小于上一个时间片所接收到的数据量,可以确定SparkStreaming的背压机制生效了,此时,从而当前时间片开始之后的各个时间片内所接收到数据量,都较小;那么,可以得到多个时间片内所接收到的数据,这些数据都在等待被处理,这些数据组成了排队中的数据。然后,由于背压机制生效之后各个时间片的数据的数据量较小,为了避免数据持续积压,可以将排队中的数据进行合并处理,得到至少一个批次的合并数据;将每一个批次的合并数据做为一个批次,进而将每一个批次的合并数据以批次处理方式进行数据处理。从而将排队中的数据进行合并处理,可以将数据提前进行处理,避免了数据持续积压和堆积;提高数据处理的吞吐量,有效的提升了基于Spark Streaming计算框架的数据处理效率。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本申请的实施例,并与说明书一起用于解释本申请的原理。
图1为本申请实施例提供的应用场景示意图;
图2为本申请实施例提供的一种基于计算框架的数据处理方法的流程示意图;
图3为本申请实施例提供的另一种基于计算框架的数据处理方法的流程示意图;
图4为本申请实施例提供的基于Spark Steaming的数据处理示意图;
图5为本申请实施例提供的Spark Steaming计算框架的架构示意图;
图6为本申请实施例提供的基于Spark Steaming计算框架的背压机制的执行过程;
图7为本申请实施例提供的一种基于计算框架的数据处理装置的结构示意图;
图8为本申请实施例提供的另一种基于计算框架的数据处理装置的结构示意图;
图9为本申请实施例提供的一种基于计算框架的数据处理设备的结构示意图。
通过上述附图,已示出本申请明确的实施例,后文中将有更详细的描述。这些附图和文字描述并不是为了通过任何方式限制本申请构思的范围,而是通过参考特定实施例为本领域技术人员说明本申请的概念。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。
本申请实施例可以应用到数据处理技术领域中,本申请实施例应用采用基于计算框架的数据处理装置、或者基于计算框架的数据处理设备、或者终端设备、或者服务器、或者其他装置或设备进行实现。
首先对本申请涉及的名词进行解释:
1)数据仓库(Data Warehouse,简称DW):是数据的存储结合。
2)Spark:是专为大规模数据处理而设计的快速通用的计算引擎,能更好地适用于数据挖掘、机器学习等需要迭代的算法。
3)、Spark Streaming:构建在Spark上处理Stream数据的框架;可以将数据流分成小的时间片断(单位:秒),以类似批量处理的方式来处理每一个时间片断内的数据。
4)弹性分布式数据集(Resilient Distributed Datasets,简称RDD):是分布式内存的一个抽象概念,RDD提供了一种高度受限的共享内存模型。
5)分区(Partition):一个RDD在物理上被切分为多个Partition;这些Partition可以分布在不同的节点上。Partition是Spark计算任务的基本处理单位。
6)Hadoop:是一个分布式系统基础架构;主要解决海量数据的分布式计算和存储问题。
本申请具体的应用场景为:随着网络技术的发展,网络数据在各个领域中已经广泛应用。并且,在互联网中中,会产生很大的数据流量;并且,数据通常具有较大的波动性,例如,在各类活动或者突发热点事件中,数据的业务流量会在短时间内剧增,进而形成巨大的流量毛刺。尤其在电商行业中,数据的上述特征会更加明显。
在数据流入的速度远高于数据处理的速度时,即,在数据接收速度远大于数据处理速度时,会对处理数据的流处理系统构成巨大的负载压力;当不能很好的缓解流处理系统的负载压力的时候,会导致集群资源耗尽,甚至导致集群的崩溃。从而需要保证处理数据的流处理系统的稳定性。
提供了批处理框架MapReduce,MapReduce是一种编程模型,MapReduce可以用于大规模数据集的并行运算。MapReduce可以对数据进行离线计算处理,但是MapReduce无法满足实时性要求较高的数据,例如,对于实时数据仓库、实时推荐、用户行为分析等场景下的数据,MapReduce不能及时的对这些数据进行处理。
现在为了便于进行分布式计算,提供了Spark。Spark是一个类似于MapReduce的分布式计算框架,Spark的核心是弹性分布式数据集,但是,Spark提供了比MapReduce更丰富的模型,Spark可以快速的在内存中对数据集进行多次迭代;从而,基于以上特征,Spark可以支持复杂的数据挖掘算法、图形计算算法等算法。
基于Spark,提出了Streaming。Spark Streaming是一种构建在Spark上的实时计算框架,Spark Streaming扩展了Spark处理大规模流式数据的能力。并且,SparkStreaming可以对实时性要求较高的数据进行及时处理。Spark Streaming可以提供丰富的应用程序接口(Application Programming Interface,简称API),并且,Spark Streaming可以基于内存完成数据的处理;进而,Spark Streaming结合流式、批处理、用户交互试方式,完成数据的查询和数据。
基于以上介绍,可知,Spark Streaming的优势在于:能运行在百个节点上,并达到秒级延迟;Spark Streaming使用基于内存的Spark作为执行引擎,从而具有高效和容错的特性;Spark Streaming集成了Spark的批处理能力和交互查询能力;Spark Streamin提供了与批处理类似的简单接口,但是可以实现复杂的算法。
但是,在通过Spark Streaming计算框架,在每一个时间片上接收数据;然后,将每一个时间片上的数据作为一个整体进行处理。具体的,通过Spark Streaming计算框架,规定了时间片的时间长度;在第一个时间片内接收数据,然后将与第一时间片对应的数据做为一个批次进行处理;然后,在第二时间片内接收数据,然后将与第二时间片对应的数据做为一个批次进行处理;以此类推。
然而在基于Spark Streaming计算框架接收数据和处理数据的时候,由于是将每一个时间片上的数据作为一个整体进行处理,需要先在一个时间片内接收数据,然后再将与该时间片对应的这些数据进行处理,从而会出现在与上一个时间片对应的数据没有处理结束时,下一个时间片的数据就开始进行接收了,进而会造成数据堆积的情况,进而会造成数据处理效率较低。
本申请提供的基于计算框架的数据处理方法、装置、设备和存储介质,旨在解决现有技术的如上技术问题。
下面以具体地实施例对本申请的技术方案以及本申请的技术方案如何解决上述技术问题进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例中不再赘述。下面将结合附图,对本申请的实施例进行描述。
图1为本申请实施例提供的应用场景示意图,如图1所示,可以从各个数据源中获取数据,然后将数据输入Spark Streaming中;Spark Streaming可以对数据进行处理;然后,将处理后的数据输入到各个数据接收源中。其中,数据源包括但不限于以下的数据源:Kafka、水槽(Flume)、HDFS(Hadoop Distributed File System,HDFS)、Kinesis。数据接收源包括但不限于以下的数据接收源:数据库(Databases)、仪表面板(Dashboards)。其中,Kafka是一种高吞吐量的分布式发布订阅消息系统;Flume是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统;HDFS是一个高度容错性的系统,能提供高吞吐量的数据访问,非常适合大规模数据集上的应用;Kinesis是AWS的一项用于收集实时流数据的云服务。
图2为本申请实施例提供的一种基于计算框架的数据处理方法的流程示意图。如图2所示,该方法包括:
101、在基于计算框架接收数据时,在确定对数据接收速度进行限速时,确定第一数据量,其中,第一数据量是与当前时间片对应的数据的第一数据条数,并且,与当前时间片对应的数据是位于处理状态的数据。
在本实施例中,本实施例的执行主体可以是基于计算框架的数据处理装置、或者基于计算框架的数据处理设备、或者终端设备、或者服务器、或者其他装置或设备。
在基于Spark Steaming这个计算框架进行数据处理的过程中,由于可以为SparkSteaming提供背压机制(back-pressure),从而可以在基于Spark Steaming这个计算框架进行数据处理的过程中,在确定数据接收速度远小于数据处理速度的时候,可以对数据接收速度进行降速,从而,可以降低基于计算框架接收数据的数据量。
在基于Spark Steaming这个计算框架进行数据处理的过程中,基于计算框架进行数据的接收,可以在每一个时间片内接收数据,然后接收到数据之后,再对与每一个时间片对应的数据进行处理,在处理的过程中,下一个时间片又开始了,进而,又会在下一个时间片内接收数据。从而每一个时间片具有对应的数据量,数据量具有数据条数。
基于以上过程,在对数据接收速度进行限速之后,在当前时间片内还会接收数据,进而得到与当前时间片对应的数据,然后,就可以确定出与当前时间片对应的数据的数据条数,为了便于区分,将与当前时间片对应的数据的数据条数,称为第一数据条数;从而,就可以得到与当前时间片对应的数据的第一数据量,第一数据量为第一数据条数。
并且,此时,接收到了与当前时间片对应的数据,并且开始对与当前时间片对应的数据进行处理,即,与当前时间片对应的数据位于处理状态。此时,是将与当前时间片对应的数据,做为了一个批次的数据去进行批量处理。
举例来说,基于Spark Steaming进行数据的处理的过程中,在时间片1内接收数据,进而得到与时间片1对应的数据,然后以预设速度对与时间片1对应的数据进行处理,即,将与时间片1对应的数据作为一个批次的数据进行批量处理;在时间片1之后的时间片2内接收数据,进而得到与时间片2对应的数据,然后以预设速度对与时间片2对应的数据进行处理,即,将与时间片2对应的数据作为一个批次的数据进行批量处理;然后基于背压机制对时间片2之后的时间片3的数据接收速度进行限速,此时,接收到了时间片3对应的数据,进而得到第一数据量,第一数据量是与时间片3对应的数据的第一数据条数;此时开始对与当前时间片3对应的数据进行处理,但是还没有处理完与当前时间片3对应的数据。
102、在确定第一数据量与预存的第二数据量之间的数据差值大于预设值、且第一数据量小于第二数据量时,其中,第二数据量是与前一个时间片对应的数据的第二数据条数,将排队中的数据进行合并,得到归属于同一批次的合并数据,其中,排队中的数据是在当前时间片内接收到的、且未处理的数据。
在本实施例中,由于已经接收到了在当前时间片之前的一个时间片的数据,即,已经接收到了前一个时间片的数据,进而可以确定出与前一个时间片对应的数据的第二数据条数,从而,将第二数据条数作为第二数据量。
然后,将步骤101的第一数据量与该第二数据量进行对比,判断第一数据量是否小于第二数据量;在确定第一数据量小于第二数据量时,将第二数据量减去第一数据量之后得到数据差值;然后,判断数据差值是否大于预设值;在确定数据差值大于预设值时,确定第一数据量远远小于第二数据量。从而可以确定在当前时间片内接收的数据量,远小于在前一个时间片内接收的数据量,进而可以确定确实降低了数据接收速度,即,确定基于Spark Streaming的背压机制生效了。例如,正常接收每个批次20万条数据,背压机制生效后每个批次500条数据。
此时,由于已经完全接收到了与当前时间片对应的数据,正在对与当前时间片对应的数据进行批量处理,但是还没有将与当前时间片对应的数据全部处理完毕,就已经开始接收下一个时间片内的数据,从而,下一个时间片内的数据就进入了排队状态,下一个时间片内的数据等待进行数据处理,此时下一个时间片内的数据作为同一批次的数据,等待进行批量处理。并且,在对与当前时间片对应的数据进行处理的过程中,下一个时间片之后的时间片的数据,有可能也会被接收,从而这些都进入到排队状态,都成为了排队中的数据;可知,排队中的数据中的与每一个时间片对应的数据,分别作为了一个批次的数据。
由于已经对数据接收速度进行限速,并且已经确定了第一数据量远小于第二数据量,即,所接收到的数据量已经明显减小了。
此时,若是将当前时间片之后的每一个时间片内的数据,分别做为一个批次的数据进行处理,那么当前时间片之后的每一个时间片内的数据,还需要继续等待进行处理,并且在处理与当前时间片对应的数据的过程中,还会继续接收后续的时间片7内的数据,那么数据就会持续积压。本实施例中,可以将排队中的数据进行合并了,然后,将排队中的数据划分到至少一个批次中,得到至少一个批次的合并数据,每一个批注的合并数据中的数据是归属于当前批次的;通过合并数据,减少数据的批次。
例如,可以将排队中的数据,都合并到一个批次中。或者,将排队中的数据,均分为多个批次。
举例来说,基于Spark Steaming进行数据的处理的过程中,在时间片1内接收数据,进而得到与时间片1对应的数据,然后以预设速度对与时间片1对应的数据进行处理,即,将与时间片1对应的数据作为一个批次的数据进行批量处理;在时间片1之后的时间片2内接收数据,进而得到与时间片2对应的数据,然后以预设速度对与时间片2对应的数据进行处理,即,将与时间片2对应的数据作为一个批次的数据进行批量处理;然后基于背压机制对时间片2之后的时间片3的数据接收速度进行限速;在时间片3内接收到数据之后,将与时间片3对应的数据进行处理,在处理的过程中,会进行下面的时间片的数据的接收过程,此时还没有对与时间片3对应的数据处理完毕;会在时间片4内接收数据、在时间片5内接收数据、在时间片6内接收数据,即,得到与时间片4对应的数据、与时间片5对应的数据、与时间片6对应的数据;可知在处理完与时间片3对应的数据之后,得到了排队中的数据,排队中的数据包括了与时间片4对应的数据、与时间片5对应的数据、与时间片6对应的数据。若是将与时间片4对应的数据做为一个批次的数据进行处理,那么与时间片5对应的数据、与时间片6对应的数据还需要继续等待进行处理,并且在处理与时间片4对应的数据的过程中,还会接收到与时间片7对应的数据,那么数据就会持续积压。此时,可以将与时间片4对应的数据、与时间片5对应的数据、与时间片6对应的数据进行合并处理,得到至少一个批次的合并数据,例如,得到两个批次的合并数据。
103、将归属于同一批次的合并数据,以批次处理方式进行数据处理。
在本实施例中,在步骤102之后,得到了至少一个批次的合并数据;然后,将归属于同一批次的合并数据,以批次处理方式进行数据处理。
举例来说,得到了2个批次的合并数据,分别为批次A的合并数据、批次B的合并数据。然后,可以将批次A的合并数据,以批次处理方式进行数据处理;在对将批次A的合并数据处理完毕之后,将批次B的合并数据,以批次处理方式进行数据处理。或者,可以调取2个线程,同时分别处理批次A的合并数据和批次B的合并数据,例如,调取线程1处理处理批次A的合并数据,同时调取线程2处理批次B的合并数据。
本实施例,通过在基于计算框架接收数据时,在确定对数据接收速度进行限速时,确定第一数据量,其中,第一数据量是与当前时间片对应的数据的第一数据条数,并且,与当前时间片对应的数据是位于处理状态的数据;在确定第一数据量与预存的第二数据量之间的数据差值大于预设值、且第一数据量小于第二数据量时,其中,第二数据量是与前一个时间片对应的数据的第二数据条数,将排队中的数据进行合并,得到归属于同一批次的合并数据,其中,排队中的数据是在当前时间片内接收到的、且未处理的数据;将归属于同一批次的合并数据,以批次处理方式进行数据处理。可以在基于Spark Streaming计算框架进行数据处理的过程中,基于当前时间片所接收到的数据量远小于上一个时间片所接收到的数据量,可以确定Spark Streaming的背压机制生效了,此时,从而当前时间片开始之后的各个时间片内所接收到数据量,都较小;那么,可以得到多个时间片内所接收到的数据,这些数据都在等待被处理,这些数据组成了排队中的数据。然后,由于背压机制生效之后各个时间片的数据的数据量较小,为了避免数据持续积压,可以将排队中的数据进行合并处理,得到至少一个批次的合并数据;将每一个批次的合并数据做为一个批次,进而将每一个批次的合并数据以批次处理方式进行数据处理。从而将排队中的数据进行合并处理,可以将数据提前进行处理,避免了数据持续积压和堆积;提高数据处理的吞吐量,有效的提升了基于Spark Streaming计算框架的数据处理效率。
图3为本申请实施例提供的另一种基于计算框架的数据处理方法的流程示意图。如图3所示,该方法包括:
201、在基于计算框架接收数据时,获取当前时间片的第一时间长度,并获取处理与当前时间片所对应的数据所需要的第二时间长度。
在本实施例中,本实施例的执行主体可以是基于计算框架的数据处理装置、或者基于计算框架的数据处理设备、或者终端设备、或者服务器、或者其他装置或设备。
在基于Spark Steaming这个计算框架进行数据处理的过程中,在接收数据流的过程中,可以以时间片为单位将数据流进行拆分,其中,时间片可以为秒级;然后,就对每一个时间片对应的数据,以批处理的方式进行处理,即,将每一个时间片对应的数据作为每一个批次,依次对每一个批次的数据进行的处理。
举例来说,图4为本申请实施例提供的基于Spark Steaming的数据处理示意图,如图4所示,将数据流输入基于Spark Steaming的计算框架中,采用Spark Steaming对数据流进行处理;基于Spark Steaming,可以在时间片t1内接收数据,即,将在时间长度为t1内所接收到的数据作为一个批次,然后对时间片t1内所接收到的数据进行处理;在对时间片t1内所接收到的数据进行处理的过程中,还会在时间片t2内接收数据,即,将在时间长度为t2内所接收到的数据作为一个批次,在对时间片t1内所接收到的数据进行处理之后,对时间片t2内所接收到的数据进行处理;并且在时间片t2内接收数据之后,还会继续在时间片t3内接收数据,依次类推。在对每一个时间片内所接收到的数据进行处理之后,可以得到与每一个时间片对应的数据处理结果。
数据源会持续的产生数据,从而,基于Spark Streaming进行数据处理的时候,数据接收速度可以是数据源的数据产生速度;Spark Streaming可以采用Receiver-based数据接收器,或者,;Spark Streaming可以采用直接接收方式(Direct Approach)。在接收到一个时间片内的数据之后,需要对一个时间片内的数据进行处理;在处理的过程中,下一个时间片又开始了,进而,又会在下一个时间片内接收数据;以此类推。当处理数据所需要的时间(batch processing time),大于时间片之间的时间间隔(batch interval,又称批处理间隔)时,也就是每个批次数据处理的时间要比Spark Streaming的批处理间隔时间长,从而越来越多的数据被接收、积压;此时,数据的处理速度没有跟上,进而导致开始出现数据堆积,进一步的甚至会导致内存溢出(OOM)问题,进而导致整个数据处理过程失败。
为了避免数据积压,可以限制每秒可以接收数据的最大数据接收量。例如,在Spark Streaming中,可以是针对每一个Receiver-based数据接收器,配置参数spark.streaming.receiver.maxRate来限制每秒的最大数据接收量;或者,在Spark Streaming中,在采用Direct Approach方式进行数据接收时,可以配置参数spark.streaming.kafka.maxRatePerPartition,去限制每次作业中每个Kafka分区最多读取的数据条数,进而限制数据读取速度,以限制每秒的最大数据接收量。
但是上述限制每秒的最大数据接收量的方式,需要预先估计出数据集群的数据处理速度、数据的产生速度;并且由于需要通过配置参数的方式,去限制每秒的最大数据接收量,在Spark Streaming中,在修改参数之后,还需要重启基于Spark Streaming的应用程序,进而导致数据处理的中断,影响数据处理效率;并且,在数据的产生速度较高的时候,会导致数据不能够及时处理,导致集群资源利用率低下。进而,可以在Spark Streaming的基础上,提供背压机制,以解决上述问题。背压机制,通过动态控制数据接收速率来适配集群数据处理能力,不需要预估数据处理速度和数据产生速度。
图5为本申请实施例提供的Spark Steaming计算框架的架构示意图,如图5所示,Spark Steaming至少包括了Executor框架、Spark Streaming Driver、SparkContext。其中,Executor框架中至少包括了以下组件:接收器(Receiver)、Block Manager。SparkStreaming Driver中至少包括了以下组件:Receiver Tracker、Job Generator、JobScheduler。从而在启动背压机制的时候,可以根据组件JobScheduler反馈数据处理作业的执行信息,进而动态调整接收器(Receiver)的数据接收速率。并且,通过属性参数“spark.streaming.backpressure.enabled”来控制是否启用背压机制;属性参数的默认值false,表征不启用背压机制;属性参数为true时,表征启用背压机制。
在基于Spark Steaming这个计算框架进行数据处理的过程中,首先开启背压功能,将参数spark.streaming.backpressure.enabled设置为true;但是此时还没有启用背压机制,即,背压还没有生效。然后,在数据接收和处理的过程中,在当前时间片内接收数据的时候,可以确定出当前时间片的时间长度;将当前时间片的时间长度,称为第一时间长度T1。在对于当前时间片对应的数据进行处理的过程中,可以确定出处理与当前时间片所对应的数据所需要的时间长度;将处理与当前时间片所对应的数据所需要的时间长度,称为第二时间长度T2。
202、在确定第二时间长度大于第一时间长度时,对数据接收速度进行限速。
在本实施例中,在步骤201之后,比较第一时间长度T1与第二时间长度T2之间的大小。
在确定第二时间长度T2大于第一时间长度T1的时候,确定数据处理所需要的时间大于数据接收所需要的时间,进而确定数据处理速度小于数据接收速度,进而确定基于Spark Streaming的数据处理能力不足;此时,确定背压生效。在确定背压生效的时候,对数据接收速度进行限速。
一个示例中,图6为本申请实施例提供的基于Spark Steaming计算框架的背压机制的执行过程,如图6所示,背压机制的执行过程为:在Spark Streaming的原始架构中增加一个新的组件ReceiverRateController,组件ReceiverRateController负责监听“OnBatchCompleted”事件;然后,组件ReceiverRateController抽取处理延迟(processingDelay)信息和安排延迟(scheduling Delay)信息.;然后组件Estimator依据这些信息,估算出最大处理速度,即,根据这些信息,可以动态控制数据接收速率;由基于接收器(Receiver)的组件Input Stream将最大处理速度,通过组件ReceiverTracker、组件ReceiverSupervisor,转发给组件BlockGenerator。从而实现对数据接收速度进行限速了。
203、在确定对数据接收速度进行限速时,确定第一数据量,其中,第一数据量是与当前时间片对应的数据的第一数据条数,并且,与当前时间片对应的数据是位于处理状态的数据。
在本实施例中,在背压机制生效之后,对数据按照批次进行处理。并且,背压之后,在对数据接收速度进行限速之后,在当前时间片内还会接收数据,进而得到与当前时间片对应的数据,然后,就可以确定出与当前时间片对应的数据的数据条数,为了便于区分,将与当前时间片对应的数据的数据条数,称为第一数据条数;从而,就可以得到与当前时间片对应的数据的第一数据量,第一数据量为第一数据条数。
并且,此时,接收到了与当前时间片对应的数据,并且开始对与当前时间片对应的数据进行处理,即,与当前时间片对应的数据位于处理状态。此时,是将与当前时间片对应的数据,做为了一个批次的数据去进行批量处理。
204、获取与多个时间片中每一个时间片对应的数据的时间片内数据条数,其中,多个时间片为在的当前时间片之前的时间片;将各时间片内数据条数的平均值,做为平均条数。
在本实施例中,步骤204可以在步骤205之前执行,也可以在步骤205的执行过程中进行执行。在步骤204中,需要确定一个参数,该参数为平均条数。
预先获取到多个时间片中每一个时间片对应的数据的时间片内数据条数,这些时间片都是在当前时间片之前的时间片;即,针对每一个时间片,一个时间片的时间片内数据条数,是在该时间片内所接收到的数据的数据条数之和;然后将各个时间片对应的数据的时间片内数据条数进行累加,得到条数之和,然后对条数之和,求平均值,得到平均条数。
例如,也在执行背压机制的过程中,已经执行了P个时间片了,P个时间片中每一个时间片内都接收到了数据,P个时间片中每一个时间片的时间片内数据条数为Q,Q可以相同或不同;将P个时间片的时间片内数据条数求平均值,得到平均条数。
205、在确定第一数据量与预存的第二数据量之间的数据差值大于预设值、且第一数据量小于第二数据量时,其中,第二数据量是与前一个时间片对应的数据的第二数据条数,根据排队中的数据的数据总条数、以及预设的平均条数,确定批次个数N,其中,N为大于等于1的正整数;其中,排队中的数据是在当前时间片内接收到的、且未处理的数据。
一个示例中,批次个数
在本实施例中,由于已经接收到了在当前时间片之前的一个时间片的数据,即,已经接收到了前一个时间片的数据,进而可以确定出与前一个时间片对应的数据的第二数据条数,从而,将第二数据条数作为第二数据量。
然后,将步骤203的第一数据量与该第二数据量进行对比,参见图2中的步骤102的介绍,在确定第一数据量与预存的第二数据量之间的数据差值大于预设值、且第一数据量小于第二数据量时,确定需要将排队中的数据进行合并;可以获取到排队中的数据的数据总条数S,可知,数据总条数S是排队中的数据的总数据条数;将数据总条数S,除以平均条数T,得到批次个数N。
一个示例中,数据总条数S,不能整除平均条数T的时候,可以采用向上取整公式
206、根据批次个数N,将排队中的数据进行合并,得到N个批次的合并数据。
在本实施例中,在步骤205之后,得到需要生成的批次的个数N;然后将排队中的数据,分配为N个批次的合并数据。例如,将排队中的数据均分为N个批次的合并数据。
207、将N个批次的合并数据中的每一个批次的合并数据,分别以批次处理方式进行数据处理。
在本实施例中。在步骤206之后,得到N个批次的合并数据;就可以针对每一个批次的合并数据,以批次处理方式进行数据处理。
208、在确定第一数据量与预存的第二数据量之间的数据差值小于等于预设值、且第一数据量小于第二数据量时,或者在确定第一数据量大于等于第二数据量时,以预设速度与每一个时间片对应的数据进行处理。
在本实施例中,在步骤204之后,将步骤101的第一数据量与该第二数据量进行对比,判断第一数据量是否小于第二数据量。
在确定第一数据量大于等于第二数据量时,确定在当前时间片内接收的数据量,没有小于在前一个时间片内接收的数据量;或者,在确定第二数据量减去第一数据量之后得到数据差值,小于等于预设值时,可以确定在当前时间片内接收的数据量,没有远小于在前一个时间片内接收的数据量。这两种情况,都可以认为没有降低数据接收速度,即,基于Spark Streaming的背压机制没有作用,背压机制不生效。
然后,就可以原始的预设速度与每一个时间片对应的数据进行处理;此时,依然将与每一个时间片对应的数据,视为一个批次;对每一个批次的数据,按照批处理方式依次处理。
209、在确定第二时间长度小于等于第一时间长度时,以预设速度对与每一个时间片对应的数据进行处理。
在本实施例中,在步骤201之后,在确定第二时间长度T2小于等于第一时间长度T1的时候,确定数据处理所需要的时间小于等于数据接收所需要的时间,进而确定数据处理速度大于等于数据接收速度,进而确定基于Spark Streaming的数据处理能力足够;此时,确定背压不生效,不需要对数据接收速度进行限速。继续在后续的每一个时间片内接收数据。
然后,就可以原始的预设速度与每一个时间片对应的数据进行处理;此时,依然将与每一个时间片对应的数据,视为一个批次;对每一个批次的数据,按照批处理方式依次处理。
本实施例,在上述实施例的基础上,基于Spark Streaming计算框架的背压机制,通过对时间片内的数据的数据量的判断,来确定出需要合并的数据的批次个数;然后,将排队中的数据,作为多个批次的数据进行合并;可以将数据提前进行处理,避免了数据持续积压和堆积;提高数据处理的吞吐量,有效的提升了基于Spark Streaming计算框架的数据处理效率。并且,在确定不启动背压机制的时候,以原始的预设速度与每一个时间片对应的数据进行处理;此时,依然将与每一个时间片对应的数据,视为一个批次。
图7为本申请实施例提供的一种基于计算框架的数据处理装置的结构示意图,如图7所示,本实施例的基于计算框架的数据处理装置,可以包括:
第一确定单元31,用于在基于计算框架接收数据时,在确定对数据接收速度进行限速时,确定第一数据量,其中,第一数据量是与当前时间片对应的数据的第一数据条数,并且,与当前时间片对应的数据是位于处理状态的数据。
合并单元32,用于在确定第一数据量与预存的第二数据量之间的数据差值大于预设值、且第一数据量小于第二数据量时,其中,第二数据量是与前一个时间片对应的数据的第二数据条数,将排队中的数据进行合并,得到归属于同一批次的合并数据,其中,排队中的数据是在当前时间片内接收到的、且未处理的数据。
第一处理单元33,用于将归属于同一批次的合并数据,以批次处理方式进行数据处理。
本实施例的基于计算框架的数据处理装置可执行上述任一实施例提供的基于计算框架的数据处理方法,其实现原理和技术效果相类似,此处不再赘述。
图8为本申请实施例提供的另一种基于计算框架的数据处理装置的结构示意图,在图7所示实施例的基础上,如图8所示,本实施例的基于计算框架的数据处理装置,合并单元32,包括:
确定模块321,用于根据排队中的数据的数据总条数、以及预设的平均条数,确定批次个数N,其中,N为大于等于1的正整数。
合并模块322,用于根据批次个数N,将排队中的数据进行合并,得到N个批次的合并数据。
第一处理单元33,具体用于:将N个批次的合并数据中的每一个批次的合并数据,分别以批次处理方式进行数据处理。
一个示例中,批次个数
一个示例中,本实施例提供的装置,还包括:
第二确定单元41,用于在确定模块321根据排队中的数据的数据总条数、以及预设的平均条数,确定批次个数N之前,获取与多个时间片中每一个时间片对应的数据的时间片内数据条数,其中,多个时间片为在的当前时间片之前的时间片;将各时间片内数据条数的平均值,做为平均条数。
一个示例中,本实施例提供的装置,还包括:
获取单元42,用于第一确定单元在确定对数据接收速度进行限速时,确定第一数据量之前,获取当前时间片的第一时间长度,并获取处理与当前时间片所对应的数据所需要的第二时间长度。
限速单元43,用于在确定第二时间长度大于第一时间长度时,对数据接收速度进行限速。
一个示例中,本实施例提供的装置,还包括:
第二处理单元44,用于在确定第二时间长度小于等于第一时间长度时,以预设速度对与每一个时间片对应的数据进行处理。
一个示例中,本实施例提供的装置,还包括:
第三处理单元45,用于在确定第一数据量与预存的第二数据量之间的数据差值小于等于预设值、且第一数据量小于第二数据量时,或者在确定第一数据量大于等于第二数据量时,以预设速度与每一个时间片对应的数据进行处理。
本实施例的基于计算框架的数据处理装置可执行上述任一实施例提供的基于计算框架的数据处理方法,其实现原理和技术效果相类似,此处不再赘述。
图9为本申请实施例提供的一种基于计算框架的数据处理设备的结构示意图,如图9所示,本申请实施例提供了一种基于计算框架的数据处理设备,可以用于执行图2-图6所示实施例中基于计算框架的数据处理方法的动作或步骤,具体包括:处理器2701,存储器2702和通信接口2703。
存储器2702,用于存储计算机程序。
处理器2701,用于执行存储器2702中存储的计算机程序,以实现图2-图6所示实施例中基于计算框架的数据处理方法的动作,不再赘述。
可选的,基于计算框架的数据处理设备还可以包括总线2704。其中,处理器2701、存储器2702以及通信接口2703可以通过总线2704相互连接;总线2704可以是外设部件互连标准(Peripheral Component Interconnect,简称PCI)总线或扩展工业标准结构(Extended Industry Standard Architecture,简称EISA)总线等。上述总线2704可以分为地址总线、数据总线和控制总线等。为便于表示,图9中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
在本申请实施例中,上述各实施例之间可以相互参考和借鉴,相同或相似的步骤以及名词均不再一一赘述。
或者,以上各个模块的部分或全部也可以通过集成电路的形式内嵌于该基于计算框架的数据处理设备的某一个芯片上来实现。且它们可以单独实现,也可以集成在一起。即以上这些模块可以被配置成实施以上方法的一个或多个集成电路,例如:一个或多个特定集成电路(Application Specific Integrated Circuit,简称ASIC),或,一个或多个微处理器(Digital Singnal Processor,简称DSP),或,一个或者多个现场可编程门阵列(FieldProgrammable Gate Array,简称FPGA)等。
在示例性实施例中,还提供了一种包括指令的非临时性计算机可读存储介质,例如包括指令的存储器2702,上述指令可由上述基于计算框架的数据处理设备的处理器2701执行以完成上述方法。例如,非临时性计算机可读存储介质可以是ROM、随机存取存储器(RAM)、CD-ROM、磁带、软盘和光数据存储设备等。
一种非临时性计算机可读存储介质,当该存储介质中的指令由基于计算框架的数据处理设备的处理器执行时,使得基于计算框架的数据处理设备能够执行上述基于计算框架的数据处理方法。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行计算机程序指令时,全部或部分地产生按照本申请实施例的流程或功能。计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,计算机指令可以从一个网站站点、计算机、终端设备或数据中心通过有线(例如,同轴电缆、光纤、数字用户线(digitalsubscriber line,DSL))或无线(例如,红外、无线、微波等)方式向另一个网站站点、计算机、终端设备或数据中心进行传输。计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的终端设备、数据中心等数据存储设备。可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如,固态硬盘(solid state disk,SSD))等。
本领域技术人员应该可以意识到,在上述一个或多个示例中,本申请实施例所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。计算机可读介质包括计算机存储介质和通信介质,其中通信介质包括便于从一个地方向另一个地方传送计算机程序的任何介质。存储介质可以是通用或专用计算机能够存取的任何可用介质。
应当理解的是,本申请并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本申请的范围仅由所附的权利要求书来限制。
- 基于计算框架的数据处理方法、装置、设备和存储介质
- 基于联合学习框架的设备使用寿命的预测方法、装置、计算机设备及计算机可读存储介质