一种基于双目视觉的车辆三维目标检测算法
文献发布时间:2024-04-18 19:52:40
技术领域
本申请涉及智能感知技术领域,尤其涉及一种基于双目视觉的车辆三维目标检测算法。
背景技术
在自动驾驶、人工智能等视觉应用场景中,仅仅获取目标的二维框无法全面定位目标物体的位置信息。因为真实的世界中,物体不是一个二维平面,而是有三维形状的,这就包含了物体的二维目标框、物理尺寸、朝向角和中心点的地理坐标,来更好的定位物体。
由于应用场景广泛,目前三维目标检测技术已经得到越来越多的关注,常见的三维目标检测的方式有单目相机、双目相机、激光雷达。利用单目相机进行图像投影时由于深度估计困难,导致检测精度较低。采用激光雷达进行扫描可以得到深度信息作为输入,但是激光雷达价格昂贵成本高,不适合大规模的落地。而双目相机作为输入图像采集的设备,可利用左目和右目的图像视差关系来估计深度,不需要点云数据作为输入,降低了检测成本和网络复杂度,并且目前的三维目标检测精度可提升的空间大。
发明内容
为解决现有三维目标检测技术存在的检测精度低、网络复杂的问题,本发明提出一种基于双目视觉的车辆三维目标检测算法,减轻了网络计算量,并且提升了三维目标框的检测精度。
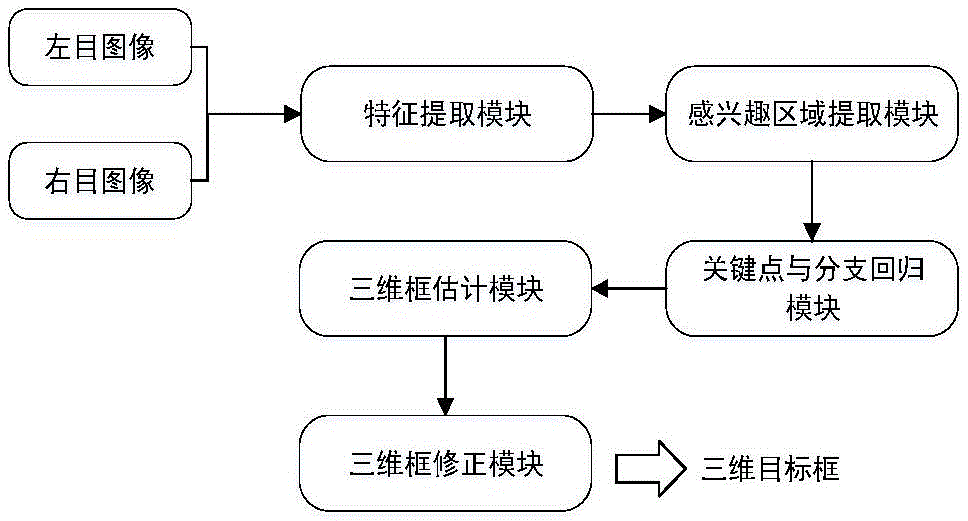
本发明提供一种基于双目视觉的车辆三维目标检测算法,包括特征提取模块、感兴趣区域提取模块、关键点与分支回归模块、三维框估计模块和三维框修正模块,其中,特征提取模块用于获取左目图像和右目图像的特征,感兴趣区域提取模块用于筛选目标的二维框,关键点与分支回归模块用于回归目标的类别、二维目标框坐标、目标物理尺寸、目标朝向角、三维投影中心点坐标,三维框估计模块是通过投影变换来求解三维目标框,三维框修正模块用于提供更加精确的三维目标框。
本发明是通过以下技术方案实现的,包括如下步骤:
步骤1:将图像数据集分为训练数据集和测试数据集,将训练数据集输入到以下模型中进行训练。
步骤2:将左目图像和右目图像输入到特征提取模块,分别进行图像的特征提取,获取特征图。
步骤3:将左右特征图拼接后输入至区域建议网络(Stereo RPN),生成二维目标候选框。
步骤4:利用感兴趣区域模块从大量二维目标框中选取候选框,由于感兴趣区域的尺寸可能不同,为了方便后处理,需要处理成固定大小的特征图输出。
步骤5:对左目感兴趣区域特征图的三维框关键点进行预测,并对右目感兴趣区域的二维目标框偏差、物理尺寸、朝向角进行回归。
步骤6:利用二维目标框和三维投影中心点的信息,再通过二维到三维投影变换的方式来求解粗略的三维目标框信息。
步骤7:利用密集对齐方式对粗略的三维目标框进行修正,得到更加精确的三维目标框。
步骤8:保存以上模型,并且用测试数据集输入到该模型中进行测试。
在步骤1中将数据集按照7:3的比例划分为训练集和测试集,训练集用来输入到模型中进行训练,测试集用来测试模型的效果,数据集包括左目图像、右目图像。
在步骤2中对输入图像进行特征提取。特征提取模块采用ResNeXt101+FPN+PANet网络结构,ResNeXt101在ResNet的基础上,不增加网络深度,引入了基数的概念来提升准确率,网络结构更加简明。ResNeXt101经过多次卷积之后的图像特征拥有很大的感受野,对于图像中的小物体目标检测效果差,因此引入FPN。该网络通过自下而上的不同维度特征生成、特征补充增强、网络层级间的特征关联表达增强图像特征表达能力,有效解决残差网络带来的小目标检测问题。为了保留更多的特征,采用PANet自底向上的路径增强方法,使定位信号在底层得到准确的增强,从而缩短了底层与顶层特征之间的信息传递路径。
在步骤3中与单目的区域建议网络(RPN)不同的是,立体区域建议网络(StereoRPN)需要将左右目结合起来再输入到立体区域建议网络(Stereo RPN)。先使用滑动窗口去遍历整个特征图,滑动窗口设置三种比例的目标框,在特征图上获取左目与右目的锚框。将左目与右目锚框的并集指定为对象分类的目标。
在步骤4中使用软性非极大抑制算法(Soft Non MaximumSuppression,Soft NMS)方法,选择高斯加权给候选框赋予一定权重,对候选框进行筛选,来解决候选框对目标遮挡的情况。将候选框与原始特征图共同输入到ROI Align层中,将候选框映射在特征图上裁剪至尺寸为14×14输出作为感兴趣区域。
在步骤5中将左目感兴趣区域输入到6×256的3×3卷积通道中,每一层后面都有一个激活函数(Rectified Linear Activation Function,ReLU),最后使用一个2×2反褶积层将输出尺度放大到28×28,这6个卷积层中,有4层是用来预测车底四个角的投影点是三维框中心投影点的概率,并且使用softmax函数选取一个概率最大的投影点,另外2层是预测车辆左右两边的边界。将右目的感兴趣区域输入到4个分支中,输入到模型中训练,分别预测目标类别、目标框二维坐标、物理尺寸、朝向角。通过梯度损失求解多任务的损失,可以缓解任务中损失差距较大而导致某些任务学习受到影响,损失函数如以下式子:
其中,
是全局梯度标准化的值:
r
在步骤6中使用已经得到的三维目标框投影中心点坐标和预测的分支信息,通过联合左右视图,使用投影变换来求解三维框的信息。在遮挡、正交投影的情况下没有透视点,这时是使用视角来补偿不可观测状态。
在步骤7中使用密集对齐模块提供更加精确的深度估计,我们在步骤5中定义了目标左右边界的范围,这是一个有效的ROI,在这个区域内利用视差信息来求解三维边界框中心的深度。
附图说明
图1为本发明实施例提供的一种基于双目视觉的车辆三维目标检测算法的框架图。
具体实施方式
如图1所示,本实例提出一种基于双目视觉的车辆三维目标检测算法。其中包含:特征提取模块、感兴趣区域提取模块、关键点与分支回归模块、三维框估计模块和三维修正模块。首先,输入到网络中的为左目图像与右目图像。特征提取模块对左目图像输入和右目图像输入分别做特征提取,然后将提取后的特征拼接输入到二维目标检测模块中,得到二维目标检测框的坐标,再输入到三维目标检测模块中,预测物体的目标类别、物理尺寸、朝向角以及中心投影点的坐标。利用双目视差可以得到物体深度信息的原理,对检测出来的物体进行光密集对齐修正,从而提高物体的三维检测精度。
步骤1:将图像数据集分为训练数据集和测试数据集,将训练数据集输入到以下模型中进行训练。
步骤2:将左目图像和右目图像输入到特征提取模块,分别进行图像的特征提取,获取特征图。
步骤3:将左右特征图拼接后输入至立体区域建议网络(Stereo RPN),生成二维目标候选框。
步骤4:利用感兴趣区域模块从大量二维候选框中选取一部分候选框作为感兴趣区域,由于感兴趣区域的尺寸可能不同,为了方便后处理,需要处理成固定大小的特征图输出。
步骤5:对左目感兴趣区域特征图的三维框关键点进行预测,并对右目感兴趣区域的目标框偏差、物理尺寸、朝向角进行回归。
步骤6:利用二维目标框信息和三维投影中心点信息,再通过二维到三维投影变换的方式来求解粗略的三维目标框信息。
步骤7:利用密集对齐方式对粗略的三维目标框进行修正,得到更加精确的三维目标框。
步骤8:保存以上模型,并且用测试数据集输入到该模型中进行测试。
在步骤2中提取左右图像中的特征图。将左右图像输入到特征提取模块中,特征提取模块采用ResNeXt101作为骨干网络,ResNeXt101的卷积有5层。但是ResNeXt101输出的特征层之间关联性不强,导致损失了小目标的像素信息和空间信息,为了提高小目标检测精度,引入FPN特征金字塔,采用ResNeXt101+FPN+PANet的网络架构来提取特征,每一层的输出通道,并且将5层的特征进行融合,使其具有更加丰富的语义信息。
在步骤3中:左右图像的特征提取完成后,输出的是特征图,采取拼接的方式将左右图像的特征输入到立体区域建议网络(Stereo RPN)中,而不是取平均的方式,这是因为特征拼接保留了更多的左右目信息,通过滑动窗口的方式对特征图遍历生成锚框输出,滑动窗口的长和宽有0.5、1、2三种比例,每种比例的面积有32
在步骤4中:使用软非极大抑制算法(Soft Non MaximumSuppression,Soft NMS)保留前1000个锚框进行训练,在测试时筛选出前100个锚框。使用ROI Align来对不同大小的锚框进行双线性插值采样四个点,将其裁剪为固定维度大小的14×14特征图,使特征能更好的对齐原图上的ROI区域。
在步骤5中:在ROI Align之后,将14×14大小的左目ROI特征输入到6个卷积层中,进行6次3×3的256-d的卷积来预测关键点,每次卷积后跟一个激活函数(RectifiedLinear Activation Function,ReLU)层,最后一层使用2×2反褶积层将输出比例增加到28×28,生成6×28×28的通道。由于车辆是规则物体,车底的4个轮胎也是规则的菱形,因此用6个通道中的4个通道分别用来回归车底的4个角,另外2个通道用来预测目标左右的边界。车底的4个角中,有一个是最接近三维框的中间位置,因此使用softmax函数选择四个通道中概率最大的作为三维框中心投影点坐标。为了简化任务,将高度通道合并,通道为6×28。另外右目输出的ROI特征用来训练4条支路的回归,分别是目标类别、目标框二维坐标、物理尺寸(L、W、H)、朝向角(α)。通过梯度损失求解多任务的损失,损失函数如式子所示,可以缓解任务中损失差距较大而导致某些任务学习受到影响。
其中,
是全局梯度标准化的值:
r
在步骤6中:三维边界框的状态可以用{x,y,z,α}表示,{x,y,z}表示目标三维目标中心点对于相机的坐标,α表示目标朝向。从左目与右目二维框和三维框中心投影点中提取七个关键值:{x
其中,W,H,L分别表示车辆的长、宽、高。某些情况下,{x,y,z}表示目标三维目标中心点对于相机的坐标,B表示双目的基线长度。如果观测的角度小于2个面,则使用以下公式来补偿不可观测的状态,其中θ表示车辆位于摄像机框架的方位,x和z表示三维中心点的相机坐标系下的横坐标与距离坐标。
α=θ+rectan(-x/z)
在步骤7中:通过左右图像的像素差,能够利用视差信息来进行深度估计,从而提升三维框目标中心的坐标精度。为了充分利用左右检测框像素差信息,本方法利用前文得到的左右边界ROI范围,在这个范围内的计算目标的深度信息,通过深度信息来修正得到的目标物体的中心点地理坐标,以此来提高三维目标框的精度。本文不是利用单个像素得到物体的深度值,而是在左右边界的ROI区域内计算所有像素的平方差之和,并且通过枚举深度以找到一个最小化成本的深度。将对象ROI视为一个几何约束整体,本文的密集对齐方法避免了立体深度估计中遮挡问题和不连续问题,因为有效ROI中的每个像素都有利于对象深度的估计。
上述仅为本发明的优选实施例,不是用来限制发明的实施与权利范围,凡依据本发明申请专利保护范围所述的内容做出的等效变化、修饰、替换等,均应包括在本发明申请专利范围内。本领域技术人员将认识到在不脱离本发明的范围和精神的情况下,可在更广阔的各方面中进行改变和修改。