一种改进的匹配追踪LDPC码的译码方法
文献发布时间:2023-06-19 09:32:16
技术领域
本发明涉及通信信道编码领域,尤其涉及一种改进的匹配追踪LDPC码的译码方法。
背景技术
空间激光通信、水下光通信、灯光通信等无线光通信技术一直是研究的热点。在无线光通信中,由于背景光、湍流的影响,通信环境十分恶劣,突发错误严重,需要纠错码来提高抗干扰能力。LDPC(Low Density Parity Check)码性能优异,被广泛研究应用于光通信中。LDPC码有硬判决和软判决两种译码方案,其中软判决译码性能接近香农限,但译码复杂,延时大;硬判决译码只涉及二进制整数运算,译码简单,延时小,但性能和前者差距较大。除此以外,软判决译码(包括软信息译码)要求光模块输出原始电压或电流,然后进行模数转换,大大增加了硬件实现难度和成本;而在硬判决译码中,光模块只需输出“0”或“1”信号,大大降低了系统的复杂度。因此,探索好的硬判决译码方法,提高LDPC码的纠错能力,且保持较低的译码复杂度,以满足不同通信系统的要求,是长期研究的课题。
近年来提出的基于匹配追踪的LDPC译码算法就是一种性能好、复杂度低的硬判决译码方法。匹配追踪算法以內积作为匹配度量,每次挑选与残差內积最大的原子(校验矩阵的列)作为最佳匹配,并以此列所在校验矩阵中的位置序号为差错位置的序号,继而求出差错图案。GF(2)域上的匹配追踪算法不同于实数域,它有以下两个特点:(1)由于LDPC码校验矩阵的稀疏性,在求匹配时会以大概率出现多个列与残差的內积相同,即匹配度量相同,甚至包括没有出错的列,这给二进制匹配选择带来了困难;(2)因为求残差是模2和运算,若匹配出错一次,则残差计算的可导致后面多次出错(即出现差错传播),从而差错位置和差错图案都出错,无法纠正误码。
综上所述,选择匹配是该译码方法最关键的环节。本发明就是要提出一种方法,从这些度量相同的匹配中选择正确的匹配,剔除错误的匹配,以降低误码率。
发明内容
本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种改进的匹配追踪LDPC码的译码方法,这种方法的核心在于降低误配率,提高译码准确率。经典的匹配追踪算法建立在希尔伯特空间,在求稀疏解时,不存在误配的问题。基于匹配追踪的LDPC译码是建立在GF(2)域上,且校验矩阵是稀疏的,容易出现內积相同而发生误配。误配容易导致差错传播,只有每一步都选出正确的匹配,残差才会逐渐减小最终收敛为0;若出现一次误配,则导致残差出错,继而导致后续误配,经过多次迭代,残差不收敛,还会出现某些列被反复匹配。
针对上述问题和现象,本发明提出一种改进的方法:设置一个列表或向量,用来存放差错位置的序号,这些序号与校验矩阵的列标相对应。在后续的匹配迭代中,如果再出现这一序号,则表示它是误配,我们从差错列表中将该序号删去,将残差与该序号对应的矩阵的列进行模2和运算,以还原误配前的残差,然后将检验矩阵对应的列置零,以后匹配将不会再选到这一列。
本发明解决其技术问题所采用的技术方案是:
本发明提供一种改进的匹配追踪LDPC码的译码方法,该方法包括以下步骤:
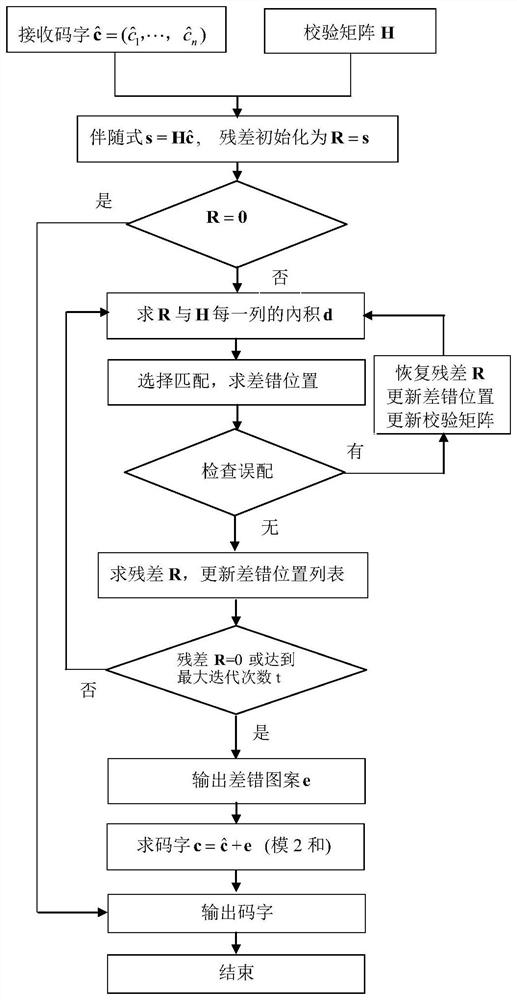
步骤1:接收待译码的码字,并输入校验矩阵;根据接收码字计算伴随式,并以此作为残差初值对译码器初始化;
步骤2:计算残差与校验矩阵每一列的內积,作为匹配度量;
步骤3:选择內积最小的首个列作为最佳匹配,并记录该列在校验矩阵中的序号即为差错位置;
步骤4:检查选出匹配的列是否存在误配;
步骤5:根据选出的列,进行残差处理和迭代更新处理;
步骤6:根据差错位置求出差错图案,计算译码输出码字。
进一步地,本发明的步骤1中所述根据接收码字计算伴随式,并对译码器初始化的具体过程包括以下步骤:
步骤1.1:根据码字向量
其中,
步骤1.2:译码器的初始化包括,将残差R
进一步地,本发明的步骤2中所述计算残差与校验矩阵每一列內积的具体过程为:
在第k(1≤k≤t)轮迭代中,求残差R
其中,符号<,>表示求两个向量的內积运算,內积用来度量残差和检验矩阵每列之间的匹配程度,內积越大,匹配度就越高。
进一步地,本发明的步骤3中所述选择內积最小的首个列作为最佳匹配,并记录该列在校验矩阵中的序号的具体过程为:
在第k轮迭代中,从
进一步地,本发明的步骤4中所述检查选出匹配的列是否存在误配的具体过程为:
在第k轮迭代中,对于选出的列
进一步地,本发明的步骤5中所述根据选出的列,对残差进行处理和迭代更新处理的具体过程包括以下步骤:
步骤5.1:在第k轮迭代中,在无误配时,根据匹配挑选出来的列
其中符号
步骤5.2:在第k轮迭代中,有误配时,根据匹配挑选出来的列
步骤5.3:判断是否满足迭代终止条件R
进一步地,本发明的步骤6中所述根据差错位置求出差错图案,计算译码输出码字的具体过程包括以下步骤:
步骤6.1:根据前面迭代选出的差错位置向量Λ,求解差错图案,求解方法是将差错图案即E中对应位置的元素
步骤6.2:根据差错图案,计算译码输出的码字,计算方法为:
本发明产生的有益效果是:本发明对基于匹配追踪的LDPC硬判决译码方法进行改进,提出一种降低误配的方法,大大提高了译码过程中匹配的准确度,从而降低了误码率。同时,降低误配也加快了残差的收敛速度,减少的实际迭代次数,加快了译码速度。此外,除了计算內积外,本译码方法的核心操作都是在GF(2)域,空间复杂度和时间复杂度低,容易硬件实现,因此,本发明提供的方法很适合高速通信和存储系统的纠错码译码方案。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例的方法流程图;
图2是本发明实施例的算法与常用经典算法的纠错性能对比图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1和图2所示,本发明实施例的基于匹配追踪的LDPC码的硬判决译码方法,具体包括以下步骤:
步骤1:接收待译码的码字,并输入校验矩阵;根据接收码字计算伴随式,并以此作为残差初值对译码器初始化;
步骤2:计算残差与校验矩阵每一列的內积,作为匹配度量;
步骤3:选择內积最小的首个列作为最佳匹配,并记录该列在校验矩阵中的序号即为差错位置;
步骤4:检查选出匹配的列是否存在误配;
步骤5:根据选出的列,进行残差处理和迭代更新处理;
步骤6:根据差错位置求出差错图案,计算译码输出码字。
进一步地,本发明的步骤1中所述根据接收码字计算伴随式,并对译码器初始化的具体过程包括以下步骤:
步骤1.1:根据码字向量
其中,
步骤1.2:译码器的初始化包括,将残差R
进一步地,本发明的步骤2中所述计算残差与校验矩阵每一列內积的具体过程为:
在第k(1≤k≤t)轮迭代中,求残差R
其中,符号<,>表示求两个向量的內积运算,內积用来度量残差和检验矩阵每列之间的匹配程度,內积越大,匹配度就越高;
进一步地,本发明的步骤3中所述选择內积最小的首个列作为最佳匹配,并记录该列在校验矩阵中的序号的具体过程为:
在第k轮迭代中,从
进一步地,本发明的步骤4中所述检查选出匹配的列是否存在误配的具体过程为:
在第k轮迭代中,对于选出的列
进一步地,本发明的步骤5中所述根据选出的列,对残差进行处理和迭代更新处理的具体过程包括以下步骤:
步骤5.1:在第k轮迭代中,在无误配时,根据匹配挑选出来的列
其中符号
步骤5.2:在第k轮迭代中,有误配时,根据匹配挑选出来的列
步骤5.3:判断是否满足迭代终止条件R
进一步地,本发明的步骤6中所述根据差错位置求出差错图案,计算译码输出码字的具体过程包括以下步骤:
步骤6.1:根据前面迭代选出的差错位置向量Λ,求解差错图案,求解方法是将差错图案即E中对应位置的元素
步骤6.2:根据差错图案,计算译码输出的码字,计算方法为:
如图2所示为本发明改进方法与以前方法的纠错性能对比图,从图中可以看出,本译码方法的纠错性能明显优于经典的基于匹配追踪的LDPC硬判决译码方法,在误码率为10
本发明的改进的匹配追踪LDPC码的译码方法,改进主要是通过两个关键环节来降低误配:(1)误配的识别;(2)误配的处理。误配的识别是根据误配的原子(校验矩阵的列)会被反复选中匹配这一现象进行来进行识别的;误配的处理分为三步,一是将该原子对应的序号从差错位置列表中删除,二是将误配过的残差进行还原,三是将校验矩阵中相应的原子置零,以保证这个原子以后不再被选中。仿真结果表明,本方法比经典方法的误码率降低了约1个数量级,在误码率为10
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形(如将內积匹配度量改为其它的匹配度量方式),均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 一种改进的匹配追踪LDPC码的译码方法
- 一种改进的LDPC码的线性规划译码方法