一种适用于多跳中继通信的网络编解码方法
文献发布时间:2023-06-19 10:03:37
技术领域
本发明涉及通信技术领域,具体地说设计一种多跳中继通信下的编码传输方案。
背景技术
多跳中继通信模型包含源节点、中继节点和目的节点。源节点生成初始的编码分组;中继节点对分组进行再编码并转发;目的节点对接收的分组进行解码。可以通过网络编码来提高多跳中继通信的信道容量。
现有的网络编码技术根据香农编码定理,通过构造足够长的编码分组长度来逼近多跳中继通信的香农信道容量。例如公开号为“CN102130746A”的中国发明专利,公开了“多点协作传输系统中的网络编码反馈方法”,其通过将需要反馈的信息(如PMI信息)和自身固定要发送的信息(如RS信息)进行网络编码后再发送出去,可以提高通信的有效性和系统的吞吐量。不过,这类编码方式会造成较长的编码分组长度,造成较高的信息传输时延。同时,由于多跳中继通信中所有中继节点均会参与编码,所以此类编码的冗余度和解码开销较高,造成通信系统的传输有效性降低。
发明内容
为了解决现有的网络编码技术在多跳中继通信中造成的高时延、高冗余度和高解码开销问题,本发明提供一种适用于多跳中继通信的编解码方案。通过链路条件调整编码密度,降低分组在多跳中继通信中的丢包率,冗余度和解码开销。
本发明解决其技术问题所采用的技术方案是:在源节点,待传输的信息被分成若干源分组,根据多跳中继通信的链路条件调整参与网络编码的源分组个数,并将编码密度等编码信息放置在分组包头;在中继节点,根据分组包头中的编码信息对分组进行筛选,将有利于降低高冗余度和高解码开销的分组优先转发;在目的节点,根据分组包头中的编码信息对分组进行分类,将编码密度较小的分组优先解码。
上述的适用于多跳中继通信的编解码方案中,在源节点设置参与网络编码的源分组个数远小于源分组总数,并且根据链路条件进行调整。当链路的信噪比降低时,根据香农定理,信道容量也降低。所以参与编码的源分组个数会减少。当链路的信噪比升高时,参与编码的源分组个数也会增加。源节点将参与编码的源分组分别乘以编码系数后相加形成编码分组,编码系数和参与编码的分组个数的比值(编码密度)作为编码信息放置在编码分组的包头。
上述的适用于多跳中继通信的编解码方案中,中继节点可以接收和暂存编码分组。根据编码分组包头中的编码信息,对分组进行筛选。由于编码密度较小时,编码冗余度和解码开销较低,所以中继节点将编码密度较小的编码分组优先发送,编码密度较大的编码分组将暂存于中继节点。当中继节点缓存满载时,优先发送缓存中编码密度较小的编码分组。
上述的适用于多跳中继通信的编解码方案,目的节点收到中继节点转发的编码分组后,根据包头中的编码信息,对编码分组进行分类,将编码密度相同的编码分组归为一类。分类完成后,优先对编码密度较小的编码分组进行解码,如果成功解码出源分组,则将此源分组带入之后的解码过程。
本发明的有益效果是,在源节点阶段,根据多跳中继通信链路信息调整参与编码的源分组个数并设置了“参与网络编码的源分组个数远小于源分组总数”的编码规则,有效降低了多跳中继通信过程中编码的冗余度;在中继节点阶段,通过对不同编码分组的筛选,进一步降低了编码冗余度;在目的节点阶段,通过对编码分组分类后依次解码,有效降低了解码开销。
附图说明
下面结合附图对本发明作进一步的说明。
图1是本发明适用的多跳模型;
图2是本发明在应用层、编码层和物理层的操作;
图3是本发明通过马尔可夫链进行的多跳中继通信传输完成时间模型;
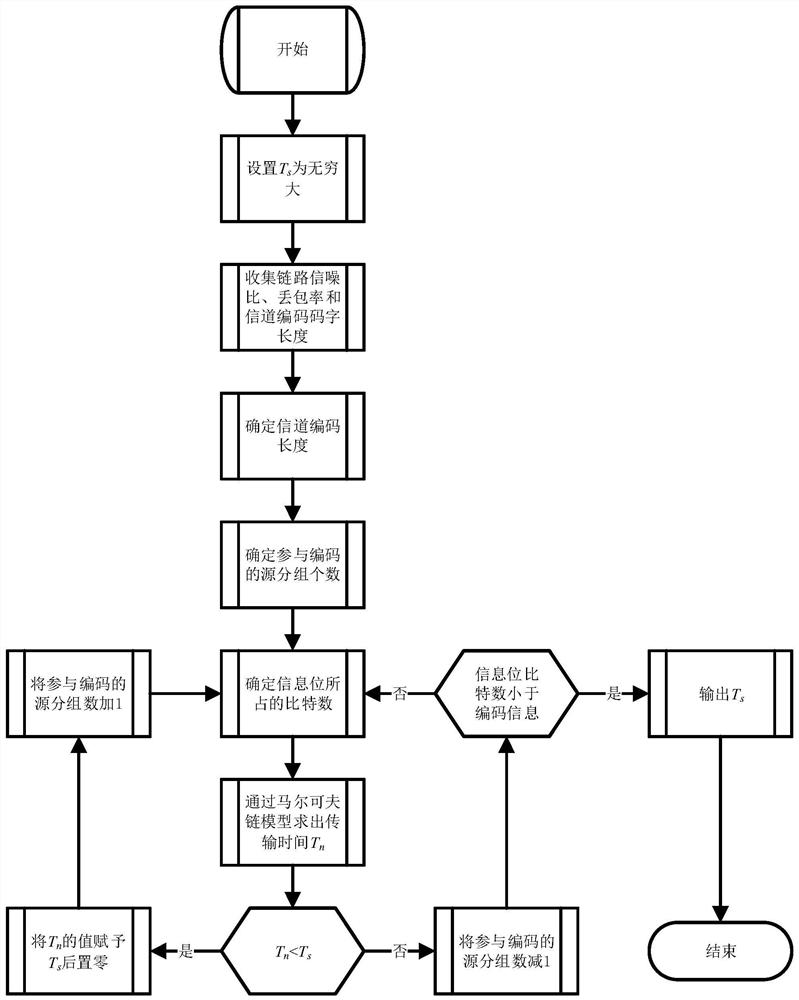
图4是本发明通过链路信息确定编码长度后遍历编码密度的流程图;
图5是本发明编码分组的组成形式;
图6是本发明在各节点阶段的具体操作;
图7是本发明在目的节点阶段的解码过程;
图8是本发明在应对特殊情况下的解码过程。
具体实施方式
下面结合附图和具体实施例对本发明做进一步说明。
本发明实施例基于信道条件(包括信噪比、信道编码码字的长度)进行网络编码方案的设计,包括以下步骤:
第一步、通过对信道统计特性的测量,收集多跳中继通信网络的链路丢包率、信噪比和信道编码码字长度。
信道统计特性包括噪声的功率谱密度和丢包率。通过噪声的功率谱密度得到信道噪声的功率值。同时设置信息传输需要的功率,将传输信息需要的功率与噪声功率的比值得到信道的信噪比。而信道编码码字长度可以人为设置,一般可设置为500~1000符号,本例中信道编码码字长度设置为500符号。
第二步、根据第一步得到的丢包率、信噪比和信道编码码字长度求出信道允许的编码分组长度。
Polyanskiy在“Channel coding rate in the finite block length regime”一文中总结并证明了有损信道下丢包率ε和编码分组长度N的关系表达式:
C=Blog(1+SNR)
式中,Q(x)表示标准正态分布的右尾函数,V表示信道色散,SNR表示信噪比,e表示自然常量,n表示信道编码码字的长度,C表示信道容量,B表示传输信道带宽。
第三步、根据信息传输的限制条件求得源分组的个数M的范围。
设需要传输的信息长度为F比特,F比特信息在源节点被分成若干源分组,每个源分组的长度至少为1比特。同时根据第二步求出的信道允许的编码分组长度N,可以得到M的范围为:
F≥M≥F/N
第四步、参与编码的源分组个数W必定小于源分组总数,所以有W∈[1,M]。
第五步、根据确定的源分组个数M和参与编码的源分组个数W,结合信道丢包率,基于吸收马尔可夫链模型,可以求出对应的传输完成时间T
在L跳中继通信系统中(L为多跳中继系统的跳数),S表示源节点,R
在多跳中继通信中,当采用随机线性网络编码时,所有源分组均参与编码,编码系数和表示参与编码的源分组个数的信息放置在分组包头中,开销为Mlog
其中,K表示编码分组中信息编码后的长度,a
在随机线性网络编码的基础上,设置参与编码的源分组个数远小于源分组总数,这就是稀疏编码方式。在这种编码方式下,每b次链路使用前,随机选择W(W≤M)个源分组构成Batch子集,b称为子集传输大小(Batch Transmission Size,BTS)。在b次链路使用中,源节点S对Batch中的W个分组进行随机线性网络编码并传输。在b次链路使用后,源节点S重新选择W个分组构成新的Batch,重复上述过程。每次编码有W个分组参与,编码系数开销为Wlog
在应用层中,各源分组的长度之和不小于F,即MN≥F;在编码层中,编码系数开销和编码输出长度之和不得大于编码分组长度N,即Wlog
在传输完成时间建模阶段,设第i个中继节点所含线性无关分组数为r
以L元组(r
其中,Q表示L元组从非吸收态到非吸收态的转移概率矩阵。R表示L元组从非吸收态到吸收态的转移概率矩阵。Q和R中的每个元素表示每种状态可能的转移概率,可以通过多跳中继通信的链路丢包率来求出,
根据以上分析,可通过搜索编码分组长度N(或丢包率ε)、源分组总数M、参与编码的源分组数W和子集传输大小b得到最短传输完成时间。
在b次链路使用后,目的节点线性无关分组数的概率分布为:
其中,Y表示b次链路使用后目的节点线性无关分组数,y表示实际确认的目的节点含有线性无关分组数,m
由于不同Batch间涵盖的线性无关分组可能有重叠,需要确定所收到的Batch内线性无关分组是否与之前已解码的源分组线性无关,即全局线性无关。可引入状态(r,c)的吸收马尔可夫链模型,其中r为目的节点已收到的全局线性无关源分组数,c为目的节点收到的Batch中已涵盖的源分组数。1个Batch内含有z个全局线性无关源分组的概率为:
其中,C表示是组合符号,z表示新增的全局线性无关源分组数。设Batch包含y个线性无关分组,需要对(r,c)的变化分情况讨论:
a)当0≤z≤y时,目的节点收到的Batch含有z个全局线性无关源分组,r值至少增加z,min(y-z,c-r)表示Batch中剩余的全局线性无关源分组数。(r,c)状态转移概率可表示为:
P{(r,c)→(r+z+min(y-z,c-r),c+z)}=f
b)当y<z≤W时,新增的y个线性无关分组全部都是全局线性无关源分组,(r,c)状态转移概率可表示为:
P{(r,c)→(r+y,c+z)}=f
由此可知(r,c)各个状态之间的转移概率。以(r=0,c=0)为初始状态,(r=M,c)为吸收状态,可得(r,c)状态转移概率矩阵:
其中,Q
其中,n
其中,L表示多跳中继系统的跳数,b表示链路使用次数,n
第六步、通过遍历源分组总数M和参与编码的源分组数W下的传输完成时间,可以求得最短的传输完成时间。即:确定最小的信息传输完成时间T
将传输完成时间作为图4中确定参与编码的源分组个数的判断依据。在图4中,通过收集链路的丢包率、信噪比和信道编码码字长度,可以得到信道容量,进而得到在此链路条件下的编码分组长度。根据编码分组长度,可以判断出参与编码的源分组个数;根据图2中的分析,可以确定编码信息和信息位所占的比特数;根据图3中的分析,通过马尔可夫链模型,可以求出参与编码的源分组个数不同的情况下传输完成时间。设置信息位小于编码信息时终止遍历,得到此链路条件下的最短传输完成时间以及最短时间对应的编码分组长度和参与编码的源分组个数。根据图4遍历的结果,确定编码方案。由于每一跳链路的丢包率、信噪比和信道编码码字长度都可能存在差异,所以在每一跳链路上都需要重新进行编码分组长度和参与编码的源分组个数的重新选择。本发明考虑了通过最小化传输完成时间来优化参与编码的源分组个数和控制编码信息所占的比特数,以避免传输效率低和解码开销高。
第七步、根据编码分组长度N和编码密度W
将F比特信息分成M
在本发明中,设计含有编码密度信息的BATCH编码方式(Code-density-information-involved BATCH Encoding,CDBE),CDBE分组包含编码密度信息、编码系数和编码后的源分组,如图5所示。将参与编码的源分组个数称为编码密度,编码密度信息采用二进制形式表示,如“7”应当表示为111。编码系数来自于有限域GF(2
下面介绍编码后的信息转发方法,其主要思想是:中继节点优先发送编码密度较小的编码分组。
具体来说,中继节点阶段设置编码密度的筛选值,若编码分组的编码密度不大于该筛选值,则该编码分组转发至下游节点;若编码分组的编码密度大于筛选值,则该编码分组暂时缓存在中继节点,当中继节点缓存满载后,再次收到编码密度大于筛选值的编码分组时,缓存中的编码分组按照编码密度从小到大的排列方式依次发送。当目的节点解码成功时,向各个节点反馈,源节点停止产生新的编码分组,中继节点停止转发,并且清空缓存中的编码分组。
中继节点在接收到CDBE分组时,会查看包头的编码密度信息,当编码密度信息对应的编码密度较小时,中继节点会将CDBE分组转发到目的节点。而对应的编码密度较大时,中继节点会将CDBE分组暂存,当中继缓存饱和时,会优先向目的节点转发缓存中编码密度较小的CDBE分组。CDBE编码主要过程如图6所示。
下面介绍目的节点解码方法,本发明中的解码方案是基于目的节点收到M
本本发明解码包含分类过程和求值过程两个步骤:
1)分类过程、目的节点根据接收到的编码分组包头中的信息将编码分组分类,具体来说通过编码分组包头的编码密度对编码分组进行分类,编码密度越小的分组享有越高的解码权。
目的节点将编码密度相同的CDBE分组归为一类,同类分组中的编码系数和编码后的源分组分别存放到矩阵D
2)求值过程:经过分类得到解码优先级最高的分组是编码密度最小的编码分组,将这些编码分组与其编码密度分别组合成编码分组矩阵和编码系数矩阵,将编码分组矩阵右侧点乘编码系数矩阵的逆矩阵,得到源分组,将可以解码得到的源分组存放到已解码的分组矩阵中;随后进行编码密度第二小的编码分组解码,通过编码系数信息确定编码密度最小的编码分组所包含的源分组与编码密度第二小的编码分组所包含的源分组,比较这两类编码分组所包含的源分组是否重合,如果存在重合,则将编码密度最小的编码分组解码成功的源分组代入编码密度第二小的编码分组中辅助解码,如果不存在重合,则根据解多元一次方程的步骤,依次求出可以解码成功的源分组,并将可以解码的源分组存放到已解码的分组矩阵中;然后再求解第三小编码密度的编码分组可以解码成功的源分组,按照这样的方式推进解码,直至所有源分组全部解码成功。
设矩阵S
当“求值过程”进行到D
除上述实施例外,本发明还可以有其他实施方式。凡采用等同替换或等效变换形成的技术方案,均落在本发明要求的保护范围。
- 一种适用于多跳中继通信的网络编解码方法
- 一种适用于双向中继通信网络源节点的随机能量调度方法