一种生成大批量点云数据集的方法
文献发布时间:2023-06-19 10:24:22
技术领域
本发明涉及机器视觉的研究领域,特别涉及一种生成大批量点云数据集的方法。
背景技术
目前点云数据处理是机器视觉领域中一种比较热门的领域,点云作为一种三维数据,能够为物体与环境提供详细的三维信息,其数据处理是三维视觉技术的一个重要方面,在各个领域中有广大应用。
受到深度学习以及神经网络在二维图像中可以学习特征的启发,基于神经网络的点云处理方法目前正在不断发展。但不同的是,目前用于处理二维图像的神经网络的训练数据集来源广泛,而三维点云的获取相对于二维图像来说则困难得多,用于训练神经网络的点云数据集目前更是稀缺。针对一些特殊应用下的场景,点云的获取则更加困难。这对于神经网络的训练以及其最终的性能都有着较大的影响。
发明内容
本发明的主要目的在于克服现有技术的缺点与不足,提供一种生成大批量点云数据集的方法,目的在于提高用于点云处理的神经网络的训练数据量,同时,根据不同的应用场景以及处理任务,可相应地生成对应的场景点云数据,针对用户自定的场景以及处理任务有着针对性,从而提高相应神经网络的性能。
本发明的目的通过以下的技术方案实现:
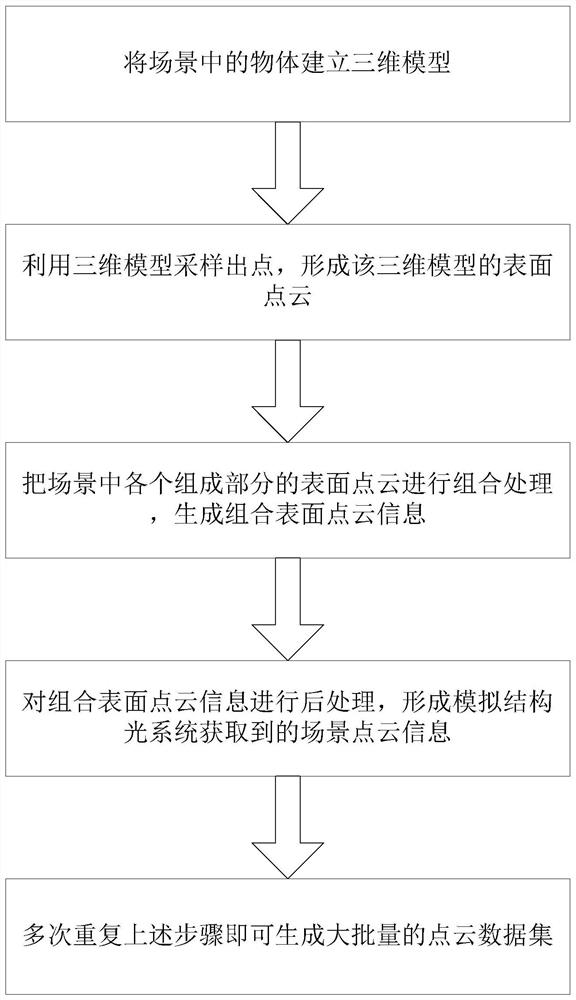
一种生成大批量点云数据集的方法,包括以下步骤:
将场景中的物体建立三维模型;
利用三维模型采样出点,形成该三维模型的表面点云;
把场景中各个组成部分的表面点云进行组合处理,生成组合表面点云信息;
对组合表面点云信息进行后处理,形成模拟结构光系统获取到的模拟场景点云信息;
多次重复即可生成大批量的点云数据集。
进一步地,所述将场景中的物体建立三维模型,具体为:将场景中的各个不同的物体分别建立三维模型,并转化为易于读取其模型中顶点与面片信息的模型格式,例如.obj格式。
进一步地,所述针对三维模型中各顶点与面片重新采样出点,形成该三维模型的表面点云,具体为:利用模型中的顶点与面片信息,重采样出该模型的表面点云;假设模型中已将模型表面划分成若干细小的三角面片;其中一个三角面片的三个顶点三维坐标分别为A(x
x=ax
y=ay
z=az
其中,a,b,c都为随机数;
以随机或顺序方式遍历模型中的各个面片,并且每次采样这三个随机数a,b,c都进行重新随机,直到采样出足够数量的点,并与原来的面片顶点,组成一个模型的表面点云。
进一步地,所述表面点云包含表面点云各点的三维坐标信息,用m×3的矩阵来表示该表面点云,其中,m为该表面点云中点的个数。
进一步地,所述把场景中各个组成部分的表面点云进行组合处理,生成组合表面点云信息,具体为:采用随机的位置关系将场景中各个组成部分的模型表面点云进行组合;以场景组成部分中的地面为基础,其他的组成部分的表面点云在允许的位置范围内用随机位置变换,最后将各点云的数据矩阵拼接在一起,即将场景中各部分组合起来,生成组合表面点云信息。
进一步地,所述随机位置变换为用随机的旋转矩阵以及平移矩阵进行随机的位置变换。
进一步地,所述对组合表面点云信息进行后处理,形成模拟结构光系统获取到的场景点云信息,具体为:
建立相机投影模型,设o
其中R为3×3旋转矩阵,t为3×1平移矩阵,由世界坐标系与相机坐标系的相对位置决定;
以非常大的数值K初始化一个二维矩阵作为图像,该数值K要确保比组合表面点云中最大的距离要大,以米为距离单位时在大多数场景中可设置该数值为100,具体可根据场景的大小设定。将组合表面点云中的各个点在世界坐标下的坐标值转换成该视点下的图像坐标系,以相机坐标系下的z
点云中的点逐一进行转换后,得到一张关于场景的深度图,再从该深度图按原来的转换方法逆转换,得到处理后的点云,此时该场景点云为模拟结构光系统得到的点云,用N×3的数据矩阵进行表示,N为点云中点的个数,将点云顺序打乱后,下采样到统一的n个点,得到n×3的场景点云数据矩阵。
进一步地,额外的过滤方法,在转换中,设置一个阈值,新像素值减去阈值后比周围像素值小,才能进行转换。该阈值应设为数倍于点云中各点间的平均间距,以免一些凹面中的点被误去除,但应比场景中厚度最薄的物体的厚度值小,以免背面点不能有效去除。
进一步地,所述多次重复即可生成大批量的点云数据集,具体为:每次重复采用不同的随机数,使得每一次生成场景中各部分的相对位置关系不同。
进一步地,所述重复次数为f次,将所有数据拼接并保存,得到f×n×3的点云数据集张量。
本发明与现有技术相比,具有如下优点和有益效果:
本发明目的在于提高用于点云处理的神经网络的训练数据量。同时,根据不同的应用场景以及处理任务,可相应地生成对应的场景点云数据,具有广泛应用性。针对用户自定的场景以及处理任务有着针对性,从而提高相应神经网络的性能。
附图说明
图1是本发明所述一种生成大批量点云数据集的方法的流程图;
图2是本发明所述实施例中生成数据集流程图;
图3是本发明所述实施例中三角面片坐标示意图;
图4是本发明所述实施例中相机投影成像模型图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例:
一种生成大批量点云数据集的方法,如图1所示,专门针对解决基于点云处理的神经网络训练时数据集稀缺的问题,使基于神经网络的点云处理算法性能有所提升。图2为生成数据集的流程以及对应的示例图,主要的步骤为建模、由模型转化为物体表面点云、场景各部分点云合成、后续处理;包括以下步骤:
将场景中的物体建立三维模型;
利用三维模型采样出点,形成该三维模型的表面点云;
把场景中各个组成部分的表面点云进行组合处理,生成组合表面点云信息;
对组合表面点云信息进行后处理,形成模拟结构光系统获取到的场景点云信息;
多次重复上述步骤即可生成大批量的点云数据集;
具体过程如下:
首先利用建模软件建立好场景中各部分的三维模型。再模型文件中读取出顶点与面片信息,假设模型中已将模型表面划分成许多细小的三角面片,以图3中举例,某一个三角面片的三个顶点三维坐标分别为A(x
x=ax
y=ay
z=az
以随机或顺序方式遍历模型中的各个面片,并且每次采样这三个随机数a,b,c都进行重新随机,直到采样出足够数量的点,并与原来的面片顶点,组成一个模型的表面点云,该点云包含各点的三维坐标信息,用m×3的矩阵来表示该表面点云,其中,m为该表面点云中点的个数,各个模型中的点云个数m并不一定相等。
之后以场景组成部分中的“地面”为基础,其他的组成部分的点云在允许的位置范围内用随机的旋转矩阵以及平移矩阵进行随机的位置变换,最后将各点云的数据矩阵拼接在一起,即将场景中各部分组合起来,形成组合表面点云。
将组合的物体表面点云去除不需要的点,模拟出使用结构光系统获取的点云的效果。如图4的相机投影成像模型图,设o
其中R为3×3旋转矩阵,t为3×1平移矩阵,由世界坐标系与相机坐标系的相对位置决定。
以非常大的数值K初始化一个二维矩阵作为“图像”,该数值K要确保比组合表面点云中最大的距离要大,以米为距离单位时在大多数场景中可设置该数值为100,具体可根据场景的大小设定。将组合表面点云中的各个点在世界坐标下的坐标值转换成该视点下的图像坐标系,以相机坐标系下的zc轴坐标值作为图像像素值,通过各个点“投影”到图像坐标系中,并与“图像”中相应位置的距离值作比较,取两者中较小值作为“图像”中该像素的值,以此将“相机没有拍摄到的被遮挡的物体的背面的点”去除。这个过程中,偶尔会有“背面”的点会由于处在“前面”的点的缝隙间而没被遮挡,保留了下来,即在组合表面点云中的点较为稀疏的情况下,有一些在实物上理应被遮挡的背面点没有被前面的点遮挡而保留,则需要额外的过滤方法进行处理;为尽量避免这种情况,像素值替换时不仅需要比原像素值小,还应设置一个阈值,该阈值应设为数倍于点云中各点间的平均间距,以免一些凹面中的点被误去除,但应比场景中厚度最薄的物体的厚度值小,以免背面点不能有效去除。新像素值减去阈值后比周围像素值小,才能进行替换,该阈值主要用来区别在同一个表面但该表面是凹面的点和在“背面”的点。点云中的点逐一进行转换后,得到一张关于场景的“深度图”,再从该深度图按原来的转换方法逆转换,得到处理后的点云,此时该场景点云为模拟结构光系统得到的点云,可用N×3的数据矩阵进行表示,N为点云中点的个数,不同的场景中N的数值不一定相等。将点云顺序打乱后,下采样到统一的n个点,得到n×3的场景点云数据矩阵。
最后每次采用不同的随机数,使得每一次生成场景中各部分的相对位置关系不同。设重复上述过程f次,将所有数据拼接并保存,得到f×n×3的点云数据集张量。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 一种生成大批量点云数据集的方法
- 一种大批量机载LiDAR点云数据整体优化的方法