学习驾驶员偏好并使车道居中控制适应驾驶员行为的系统和方法
文献发布时间:2023-06-19 12:02:28
技术领域
本公开涉及车辆导航,具体涉及用于使自动车辆的行为适应车辆驾驶员的行为的系统和方法。
背景技术
自动车辆或半自动车辆能够根据预定的行为在道路和高速公路上行驶。自动驾驶车辆的具体行为很可能不同于由驾驶人驾驶时的行为。例如,自动车辆通常通过保持自身位于弯道的外边缘和内边缘之间的中间来导航弯道,而驾驶员可能会贴近外边缘或内边缘。然而,使驾驶员对自动车辆的行为方式感到舒适是期望的。因此,希望训练自动车辆使其行为模仿驾驶员的行为。
发明内容
在一个示例性实施例中,公开了一种操作车辆的方法。当驾驶员导航路段时,在处理器处学习车辆驾驶员的驾驶员行为。基于驾驶员的行为和与路段相关联的阈值,在处理器处创建行为策略。处理器控制车辆使用行为策略来导航路段。
除了这里描述的一个或多个特征之外,通过学习驾驶员对于路段的多次导航的行为来构建知识矩阵,基于环境状态从知识矩阵中选择动作,并基于所选择的动作创建行为策略。所述知识矩阵基于环境状态、车辆状态和驾驶员状态中的至少一个。学习驾驶员的行为还包括测量当驾驶员在路段上驾驶车辆时由驾驶员选择的车辆速度、由驾驶员选择的车辆横向控制以及由驾驶员选择的车辆加速度或减速度中的至少一个。在一个实施例中,与路段相关联的阈值包括路段的安全限度,并且创建行为策略包括基于路段的安全限度来修改学习到的驾驶员行为。驾驶员行为包括驾驶员在路段的车道内的行为和驾驶员在路段中改变车道的行为中的至少一种。该方法还包括在离线学习模式和在线学习模式之一中学习驾驶员的行为,在离线学习模式中,车辆由驾驶员驾驶,在在线学习模式中,在驾驶员操作车辆的控制器时,车辆由处理器控制。
在另一个示例性实施例中,公开了一种用于操作车辆的系统。该系统包括处理器,该处理器被配置为在驾驶员导航路段时学习车辆驾驶员的驾驶员行为,基于驾驶员行为和与路段相关联的阈值创建行为策略,并使用行为策略控制车辆导航路段。
除了这里描述的一个或多个特征之外,所述处理器还被配置为通过学习驾驶员对于路段的多次导航的行为来构建知识矩阵,基于环境状态从知识矩阵中选择动作,并且基于所选择的动作来创建行为策略。知识矩阵基于环境状态、车辆状态和驾驶员状态中的至少一个。处理器还被配置为通过测量当驾驶员在路段上驾驶车辆时由驾驶员选择的车辆速度、由驾驶员选择的车辆横向控制、以及由驾驶员选择的车辆加速度或减速度中的至少一个来学习驾驶员的行为。与路段相关联的阈值包括路段的安全限度,并且处理器被配置为通过基于路段的安全限度修改学习到的驾驶员行为来创建行为策略。在一个实施例中,该系统还包括可转移到车辆和从车辆转移的电子组件。处理器还被配置成在离线学习模式和在线学习模式之一中学习驾驶员的行为,在离线学习模式中,车辆由驾驶员驾驶,在在线学习模式中,在驾驶员操作车辆的控制器时,车辆由处理器控制。
在又一示例性实施例中,公开了一种车辆。该车辆包括处理器。所述处理器被配置为在驾驶员导航路段时学习车辆驾驶员的驾驶员行为,基于驾驶员行为和与路段相关联的阈值创建行为策略,并使用行为策略控制车辆导航路段。
除了这里描述的一个或多个特征之外,所述处理器还被配置为通过学习驾驶员对于路段的多次导航的行为来构建知识矩阵,基于环境状态从知识矩阵中选择动作,并且基于所选择的动作来创建行为策略。该车辆还包括可转移到车辆和从车辆转移的附加处理器,该附加处理器被配置为基于所学习的驾驶员行为修改路径规划命令和/或使车道居中控制命令适应所学习的驾驶员行为。处理器还被配置为通过测量当驾驶员在路段上驾驶车辆时由驾驶员选择的车辆速度、由驾驶员选择的车辆横向控制、以及由驾驶员选择的车辆加速度或减速度中的至少一个来学习驾驶员的行为。与路段相关联的阈值包括路段的安全限度,并且处理器被配置为通过基于路段的安全限度修改学习到的驾驶员行为来创建行为策略。处理器还被配置成在离线学习模式和在线学习模式之一中学习驾驶员的行为,在离线学习模式中,车辆由驾驶员驾驶,在在线学习模式中,在驾驶员操作车辆的控制器时,车辆由处理器控制。
当结合附图时,根据以下详细描述,本公开的上述特征和优点以及其他特征和优点将变得显而易见。
附图说明
其他特征、优点和细节仅作为示例在以下详细描述中呈现,该详细描述参考附图,其中:
图1示出了根据示例性实施例的车辆;
图2示出了流程图,其示出了用于训练车辆以模仿所选驾驶员行为的行为来导航路段的方法;
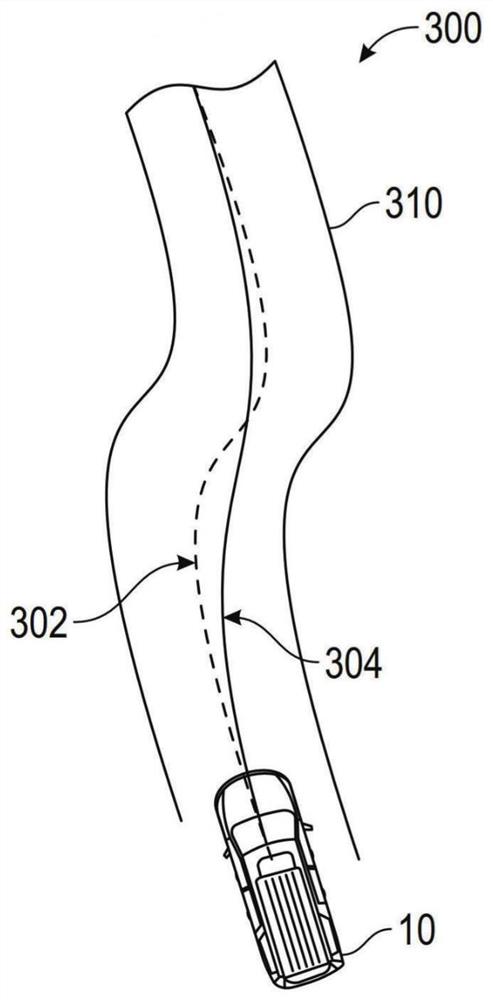
图3示出了包括弯曲部分的路段的俯视图;
图4示出了图3的路段的俯视图;
图5A-5E示出了驾驶员可能表现出的各种驾驶行为;
图6示出了行为学习和修改系统的示意图,该系统适于学习驾驶员的行为并操作自动车辆以模仿驾驶员的行为;
图7示出了说明方法的流程图,通过该方法系统学习驾驶员的行为,并随后基于所学习的行为导航车辆;
图8示出了道路的俯视图,示出了自动车辆的学习操作;
图9示出了图8的道路的道路和环境因素的分类;
图10示出了可以在图8的道路上量化的受益(Reward)曲线。
具体实施方式
以下描述本质上仅仅是示例性的,并不旨在限制本公开、其应用或使用。应当理解,在所有附图中,相应的附图标记表示相似或相应的部件和特征。如这里所使用的,术语模块指的是处理电路,其可以包括专用集成电路、电子电路、处理器(共享的、专用的或成组的)和执行一个或多个软件或固件程序的存储器、组合逻辑电路和/或提供所述功能的其他合适的组件。
根据示例性实施例,图1示出了车辆10。在示例性实施例中,车辆10是半自动或自动车辆。在各种实施例中,车辆10包括至少一个驾驶员辅助系统,用于使用关于驾驶环境的信息进行转向和加速/减速,例如巡航控制和车道居中。虽然驾驶员可以通过将他或她的手从方向盘上移开并同时将脚从踏板上移开来脱离对车辆10的物理操作,但是驾驶员必须准备好控制车辆。
通常,轨迹规划系统100确定用于车辆10的自动驾驶的轨迹规划。车辆10通常包括底盘12、车身14、前轮16和后轮18。车身14布置在底盘12上,并且基本上封闭车辆10的部件。车身14和底盘12可以共同形成框架。车轮16和18每个都在车身14的相应拐角附近可旋转地连接到底盘12上。
如图所示,车辆10通常包括推进系统20、传动系统22、转向系统24、制动系统26、传感器系统28、致动器系统30、至少一个数据存储设备32、至少一个控制器34和通信系统36。在各种实施例中,推进系统20可以包括内燃机、诸如牵引马达的电机和/或燃料电池推进系统。传动系统22被配置成根据可选择的速度比将动力从推进系统20传递到车轮16和18。根据各种实施例,传动系统22可包括有级自动变速器、无级变速器或其他合适的变速器。制动系统26被配置为向车轮16和18提供制动扭矩。在各种实施例中,制动系统26可包括摩擦制动器、线控制动器、再生制动系统如电机和/或其他合适的制动系统。转向系统24影响车轮16和18的位置。虽然为了说明的目的而被描述为包括方向盘,但在本公开范围内设想的一些实施例中,转向系统24可以不包括方向盘。
传感器系统28包括一个或多个感测设备40a-40n,其感测车辆10的外部环境和/或内部环境的可观察条件。感测设备40a-40n可以包括但不限于雷达、激光雷达、全球定位系统、光学相机、热相机、超声传感器和/或用于观察和测量外部环境参数的其他传感器。感测设备40a-40n还可以包括制动传感器、转向角度传感器、车轮速度传感器等,用于观察和测量车辆的车内参数。相机可以包括两个或多个彼此间隔选定距离的数字相机,该两个或多个数字相机用于获得周围环境的立体图像用以获得三维图像。致动器系统30包括一个或多个致动器装置42a-42n,其控制一个或多个车辆特征,例如但不限于推进系统20、传动系统22、转向系统24和制动系统26。在各种实施例中,车辆特征可进一步包括内部和/或外部车辆特征,例如但不限于门、行李箱和车厢特征,例如空气、音乐、照明等(未编号)。
至少一个控制器34包括至少一个处理器44和计算机可读存储设备或介质46。所述至少一个处理器44可以是任何定制的或商业上可获得的处理器、中央处理单元(CPU)、图形处理单元(GPU)、与至少一个控制器34相关联的几个处理器中的辅助处理器、基于半导体的微处理器(微芯片或芯片组的形式)、宏处理器、它们的任何组合、或通常用于执行指令的任何设备。计算机可读存储设备或介质46可以包括例如只读存储器(ROM)、随机存取存储器(RAM)和保活存储器(KAM)中的易失性和非易失性存储。KAM是持久或非易失性存储器,其可用于在至少一个处理器44断电时存储各种操作变量。计算机可读存储设备或介质46可以使用多种已知存储设备中的任何一种来实现,例如PROM(可编程只读存储器)、EPROM(电学PROM)、EEPROM(电可擦除PROM)、闪存或能够存储数据的任何其他电、磁、光或组合存储设备,其中一些表示可执行指令,由至少一个控制器34在控制车辆10时使用。
所述指令可以包括一个或多个单独的程序,每个程序包括用于实现逻辑功能的可执行指令的有序列表。当由至少一个处理器44执行时,这些指令接收并处理来自传感器系统28的信号,执行用于自动控制车辆10的部件的逻辑、计算、方法和/或算法,并产生控制信号给致动器系统30,以基于逻辑、计算、方法和/或算法自动控制车辆10的部件。虽然图1中仅示出了一个控制器,但是车辆10的实施例可以包括任意数量的控制器,这些控制器通过任意合适的通信介质或通信介质的组合进行通信,并且协作处理传感器信号、执行逻辑、计算、方法和/或算法,并且生成控制信号以自动控制车辆10的特征。
本文公开的方法根据基于对驾驶员行为的观察的学习行为或行为策略来自主操作车辆。在一个实施例中,本文公开的方法可以在处理器44上执行。在替代实施例中,单独的驾驶行为系统50可以固定到车辆上,并与车辆电子设备如处理器44通信耦合。驾驶员行为系统50通过观察驾驶员的行为并基于驾驶员的行为来执行车辆自主驾驶的方法。在各种实施例中,驾驶员行为系统50基于所学习的驾驶员行为修改路径规划命令和/或使车道居中控制命令适应所学习的驾驶员行为。驾驶员行为系统50可以是电子组件或处理器,其可以根据需要添加到车辆10或从车辆10移除,并且可以转移到车辆或从车辆转移。
通信系统36被配置成与其他实体48无线通信信息,例如但不限于其他车辆(“V2V”通信)、基础设施(“V2I”通信)、远程系统和/或个人设备。在一个示例性实施例中,通信系统36是被配置为使用IEEE 802.11标准或通过使用蜂窝数据通信经由无线局域网(WLAN)进行通信的无线通信系统。然而,附加的或替代的通信方法,例如专用短程通信(DSRC)信道,也被认为在本公开的范围以内。DSRC信道是指专为汽车使用而设计的单向或双向短程至中程的无线通信信道,以及相应的一组协议和标准。
图2示出了流程图200,其示出了用于训练车辆以模仿所选驾驶员行为的行为来导航路段的方法。驾驶员的行为由驾驶员如何导航特定路段或路段类型来表征。驾驶员在路段上的行为可以通过各种参数来量化,例如被驾驶车辆的速度或平均速度、车辆在车道内的相对位置(即,居中、偏左、偏右)等。对于车辆改变车道,驾驶员的行为可以通过驾驶员改变车道的突然性或平稳性如何、如何改变速度等来量化。驾驶员的行为可以通过在车辆的各种感测设备40a-40n处记录驾驶员的速度、横向控制或转向命令等来确定。
在框202中,确定车辆的环境状态。车辆的环境状态可以基于车辆正在行驶或导航的道路或路段的几何形状、障碍物的存在以及它们的相对位置和速度等。在框204中,当驾驶员在路段上驾驶车辆时,车辆学习驾驶员对环境状态的行为。驾驶员的行为包括车速和横向控制等。在框206中,所学习的行为被用于建立或构建针对驾驶员的知识库。在框208中,自动车辆随后使用基于知识矩阵的行为策略在路段上行驶。
驾驶员的行为可以离线或在线学习。在离线学习模式中,当驾驶员完全控制车辆时,处理器44记录驾驶员的行为(即,没有自动驾驶模式被激活)。在在线学习模式中,当驾驶员同时操作方向盘时,处理器44根据车辆的预定驾驶行为来操作车辆。处理器44记录驾驶员行为和自动车辆行为之间的差异,并在安全和稳定的驾驶行为限度内使车辆的行为(“车辆行为”)适应驾驶员行为。
虽然这里描述为学习单个驾驶员的驾驶行为,但是处理器44也可以使用来自与车辆相关联的合适的识别传感器的数据来识别驾驶员。处理器44因此可以学习多个驾驶员的驾驶行为,并且可以改变其行为以适应当前在方向盘后面的驾驶员的驾驶行为。
图3示出了包括弯曲部分的路段310的俯视图300。俯视图300示出了车辆10和车道居中控制轨迹302,该轨迹302由自动车辆10选择,通过将车辆10保持在车道的中心,特别是在弯曲部分,来导航路段310。还示出了由驾驶员在路段310上采取的驾驶员期望轨迹304。驾驶员期望轨迹304在路段的弯曲部分贴近曲线的内边缘。记录车道居中控制轨迹302和驾驶员期望轨迹304之间的差异,以便了解驾驶员的行为。
图4示出了图3的路段310的俯视图400。俯视图400示出了基于应用于图3的驾驶员期望轨迹304的学习算法更新的车道居中控制轨迹402。更新的车道居中控制轨迹402偏离图3的车道居中控制轨迹302,以便与驾驶员的期望轨迹304更加一致。更新的车道居中控制轨迹402位于由处理器设置的路段的安全限度404内,该安全限度404定义了安全远离路段边缘的路段310的宽度。更新的车道居中控制轨迹402基于修改驾驶员的期望轨迹位于路段的安全界限404内。安全限度可以定义路段边界、最大车速、路段内的最大加速度或减速度等。在更新的车道居中控制轨迹402受安全限度404限制的实施例中,更新的车道居中控制轨迹402不完全模仿驾驶员期望轨迹304。
图5A-5E示出了驾驶员可以表现出的各种驾驶行为。图5A示出了在与有迎面而来的车辆的车道相邻的车道上的驾驶员。在远处的车辆在迎面车道中靠近时,驾驶员暂时转向车道的一侧(即,右侧)(如箭头502所示),以便实现车辆和远处的车辆之间的距离。图5B示出了沿着乡村道路的车辆,其中驾驶员倾向于偏向车道的一侧行驶(即,如箭头504所示,车道的外侧)。图5C示出了多车道道路,其中车辆在多车道道路中的最左侧车道上紧靠车道的栅栏一侧(如箭头506所示)。图5D示出了相邻车道中具有锥形物的车道,以及机动到车道一侧以远离锥形物的车辆(如箭头508所示)。图5E示出了沿着道路的弯曲部分的车辆。一些驾驶员可能倾向于靠近弯道内侧,而其他驾驶员可能倾向于靠近弯道外侧(如箭头510所示)。
图6示出了行为学习和修改系统600的示意图,该系统适用于学习驾驶员的行为并操作自动车辆以模仿驾驶员的行为。系统600包括传感器模块602、车辆和环境模块604以及路径规划模块606。传感器模块602包括各种相机、激光雷达、雷达或其他传感器,用于确定车辆周围相对于道路的状态,以及远处车辆、行人、障碍物等的位置。车辆和环境模块604提供来自环境的数据,例如道路几何形状、位置、车辆的速度和方向以及环境中的其他障碍物等。来自传感器模块602和车辆与环境模块604的数据被提供给路径规划模块606,路径规划模块606为自动车辆规划选定的路径或轨迹。
系统600还包括学习模块608和自适应控制模块610,用于学习驾驶员的行为并在车辆上实施所学习的行为。学习模块608接收来自转向或控制传感器612的驾驶员转向信号、由车辆从自适应控制模块610获取的转向信号、以及来自车辆和环境模块604的状态数据S
其中S
通过将驾驶员输入与当前状态数据S
Q(i,j)=αP(i,j)+(1-α)Q(i,j) 等式(2)
其中α=用户选择的更新知识矩阵的学习率。
自适应控制模块610接收来自路径规划模块606的规划轨迹、来自车辆和环境模块604的状态数据S
自适应控制模块610基于输入数据计算包括转向信号δ
δ
其中K是作为δq的函数的元素的矩阵。在替代实施例中,行为策略和转向信号δ
δ
其中K是车道跟随控制的设计参数,而e是基于各种参数的预测误差,例如车辆的横向位置和航向、道路曲率、控制输入、驾驶员输入、学习的控制输入、期望的车轮角度、控制器扭矩和驾驶员扭矩。驾驶员输入扭矩δ
δ
自适应控制模块610向转向模块614以及学习模块608提供行为策略和转向信号δ
图7示出了流程图700,其示出了系统600学习驾驶员行为并随后基于所学习的行为导航车辆的方法。
在框701中,接收驾驶员的动作或输入。在框702中,基于驾驶员的动作或输入量化驾驶员的行为,如矢量q所表示的。在框704中,系统600评估驾驶员的行为是否用于学习目的。当q大于或等于选定阈值时,该方法前进到框705,在框705,驾驶员的行为不用于学习而仅用于驾驶车辆。然而,当q小于阈值时,系统600学习驾驶员的行为。
在框706中,估计环境状态和车辆将采取的相应行动。在框708中,基于估计的状态和动作计算受益函数P(i,j)。在框708,从框712接收驾驶员的输入和道路意识,并且从框706接收车辆的估计动作。受益函数P(i,j)是基于该输入计算的。在框710中,基于计算出的受益和期望的学习率更新知识矩阵Q(i,j)。
在框714中,从框710中确定的知识矩阵和框712中的环境状态选择策略Aj。策略和环境状态用于计算导航车辆的动作。
在框716中,执行所选动作的稳定性检查,以确保该动作在安全驾驶要求内。如果由所选策略执行的动作大于安全阈值,则该方法返回到框714,以便获得更新的动作。如果由所选策略执行的动作在安全阈值内,则该方法前进到框720。在框720,控制动作(以及因此的行为策略)被应用于车辆。
图8示出了道路800的俯视图,示出了自动车辆的学习操作。道路800包括左车道标志802和右车道标志804。道路800的第一段(段A)以直线延伸约25米。在大约x=25米处,道路800向左转弯,并沿着第二段(段B)继续直线前进。在大约x=32.5米处,道路800向右转弯,并沿着第三段(段C)继续直线前进。在大约x=40米处,道路800再次向左转弯,并沿着第四段(段D)继续直线前进。路段D的行进方向与路段A相同。
由自动车辆选择的第一车辆轨迹806被示出为在道路800的所有路段上保持距离左车道标志802和右车道标志804相等距离。车辆驾驶员选择的第二车辆轨迹808显示为在路段A中位于车道中心。然而,在路段B中,第二车辆轨迹从中心向右车道标志804偏离。在路段C中,第二车辆轨迹向左车道标志802偏离。在路段D中,第二条车辆轨迹回到车道的中心。
图9示出了图8的道路800的道路和环境因素的分类。记录在自动车辆的路径和驾驶员的路径之间的位置误差状态902。还记录道路800的曲率状态904以及道路800的曲率变化率状态906。这些位置误差状态902、曲率状态904和曲率变化率状态906是等式(1)的状态变量的相应分量。
图10示出了可以在图8的道路800上量化的受益曲线。受益曲线示出了在驾驶员轨迹和车辆选择轨迹相同的路段(即,直线路段A和路段D)上的最大受益。受益曲线在驾驶员选择的轨迹不同于车辆选择的轨迹的道路路段(即,路段B和路段C)上降低。
虽然已经参考示例性实施例描述了上述公开,但是本领域技术人员将理解,在不脱离本发明的范围的情况下,可以进行各种改变,并且等同物可以替代其元件。此外,在不脱离本公开的基本范围的情况下,可以进行许多修改以使特定情况或材料适应本公开的教导。因此,意图是本公开不限于所公开的特定实施例,而是将包括落入其范围内的所有实施例。
- 学习驾驶员偏好并使车道居中控制适应驾驶员行为的系统和方法
- 一种基于驾驶员行为学习的远光灯控制优化方法