人工智能加速器及其处理方法
文献发布时间:2023-06-19 12:07:15
技术领域
本发明是有关于人工智能加速器的技术,且特别是关于由分割的输入位与分割的权重区块所构成的人工智能加速器及其处理方法。
背景技术
人工智能加速器的应用包括例如类似过滤器的作用,其辨别输入数据所代表的形态与已知形态的吻合程度。一种应用例如对所摄取的影像中通过人工智能加速器辨别出是否包含有眼睛、鼻子、脸等等的信息。
人工智能加速器所要处的数据例如是一张影像的所有像素的数据,也就是其输入数据是很大量位的数据,这些数据平行输入后,进行存储在人工智能加速器内各种形态进行比对运算。这些形态是以权重的方式存储在的大量存储单元中。存储单元的架构是3D的架构,其由多层的2D存储单元层所构成,每一层代表一个特征形态,以权重值的方式存储于一层的存储单元阵列,其通过字线控制依序选择所要处理的一层的存储单元阵列。输入数据是由位线输入。输入数据与存储单元阵列进行回旋运算(convolution operation)得到对应此层的存储单元阵列的特征图案的吻合程度。
人工智能加速器要处理的运算量很大,如果多层的存储单元阵列集合在一个单元且以位当作运处理单位,其整体的电路会很大。而如此在操作上速度会延迟且耗能。就从人工智能加速器所要求能快速处理来过滤辨别输入图像的内容来看,一般单一电路芯片的设计是需要继续提升,例如操作速度的考虑。
发明内容
本发明的实施例提供一种人工智能加速器,由分割的输入位与分割的权重区块所构成的人工智能加速器,其后再通过移位与相加运算将分别平行运算的值组合还原到单一芯片所预期的运算结果。如此,人工智能加速器的处理速度可以有效提升,且可以减少耗能。
根据本发明的一实施例,本发明提供一种人工智能加速器,接收二位的一输入数据组与多层的整体权重形态中被选择的其一进行回旋运算。该输入数据组分为多个次数据组。人工智能加速器包括多个处理片及加总输出电路。每一个该处理片包括:接收端元件,分别接收一个该次数据组。权重存储部存储该整体权重形态的部分权重形态,其中该部分权重存储部包含多个权重区块,每一个该权重区块依照位顺序存储该部分权重形态的一区块部分,其中该权重存储部的存储单元阵列结构相对于所对应的该次数据组,规划成将该次数据组分别与每一个该区块部分进行回旋运算得到依序的多个权重运算值。逐块输出电路包含多个移位器及多个加法器,通过多阶的移位与相加运算将该多个权重运算值总和得到由该次数据组与该部分权重形态直接进行回旋运算所预期的权重输出值。加总输出电路包含多个移位器及多个加法器,通过多阶的移位与相加运算对该多个权重输出值总和得到由该输入数据组与该整体权重形态直接进行回旋运算所预期的总和值。
根据本发明的一实施例,对于所述的人工智能加速器,该输入数据组包含i个位,分为p个该次数据组,i与p是整数,每一个该次数据组包含i/p个位。
根据本发明的一实施例,对于所述的人工智能加速器,该输入数据组包含i个位,该多个处理片的数量是p个,该输入数据组分为p个该次数据组,该i与p是大于或等于2的整数,该i大于该p,每一个该次数据组包含i/p个位。
根据本发明的一实施例,对于所述的人工智能加速器,该部分权重存储部包含的该多个权重区块的数量是q个,q大于或等于2的整数,该部分权重存储部包含j个位,该j、q是大于或等于2的整数,该j大于该q,每一个该权重区块包含j/q个存储单元。
根据本发明的一实施例,对于所述的人工智能加速器,该多个处理片总合的该多个权重存储部的存储单元总量为p×q×2
根据本发明的一实施例,对于所述的人工智能加速器,对于该逐块输出电路,在每一阶的该移位与相加运算中包括至少一个该移位器与至少一个该加法器。对于每一阶的多个输入值以相邻两个为一处理单元,其中属于较高位的该输入值通过该移位器后与较低位的该输入值由该加法器相加后输出给下一阶,其中最后一阶输出单一值当作对应该处理片的该权重输出值。
根据本发明的一实施例,对于所述的人工智能加速器,在第一阶的该移位器的移位量是j/q存储单元,后一阶的该移位器的移位量是前一阶的该移位器的移位量的两倍。
根据本发明的一实施例,对于所述的人工智能加速器,对于该加总输出电路,在每一阶的该移位与相加运算中包括至少一个该移位器与至少一个该加法器。对于每一阶的多个输入值以相邻两个为一处理单元,其中属于较高位的该输入值通过该移位器后与较低位的该输入值由该加法器相加后输出给下一阶,其中最后一阶输出单一值当作该总和值。
根据本发明的一实施例,对于所述的人工智能加速器,在第一阶的该移位器的移位量是i/p位,后一阶的该移位器的移位量是前一阶的该移位器的移位量的两倍。
根据本发明的一实施例,对于所述的人工智能加速器,其更包括正规化处理电路,对该总和值进行正规化处理得到正规化总和值,以及数量化处理电路,以一基数将正规化总和值数量化成为整数量值。
根据本发明的一实施例,对于所述的人工智能加速器,该处理电路包括多个感应放大器,分别感应每一个该区块部分进行回旋运算后得到多个感应值,当作该多个权重运算值。
根据本发明的一实施例,本发明更提供一种用于人工智能加速器的处理方法。该人工智能加速器接收二位的一输入数据组与多层的整体权重形态中被选择的其一进行回旋运算,该输入数据组分为多个次数据组。该处理方法包括使用多个处理片,每一个该处理片包括执行。使用接收端元件分别接收一个该次数据组。使用权重存储部存储该整体权重形态的部分权重形态,其中该部分权重存储部包含多个权重区块,每一个该权重区块依照位顺序存储该部分权重形态的一区块部分,其中该权重存储部的存储单元阵列结构相对于所对应的该次数据组,规划成将该次数据组分别与每一个该区块部分进行回旋运算得到依序的多个权重运算值。使用包含多个移位器及多个加法器的逐块输出电路,通过多阶的移位与相加运算将该多个权重运算值总和得到由该次数据组与该部分权重形态直接进行回旋运算所预期的权重输出值。使用包含多个移位器及多个加法器的加总输出电路,通过多阶的移位与相加运算对该多个权重输出值总和得到由该输入数据组与该整体权重形态直接进行回旋运算所预期的总和值。
根据本发明的一实施例,对于所述的人工智能加速器的处理方法,该输入数据组包含i个位,分为p个该次数据组,i与p是整数,每一个该次数据组包含i/p个位。
根据本发明的一实施例,对于所述的人工智能加速器的处理方法,该输入数据组包含i个位,该多个处理片的数量是p个,该输入数据组分为p个该次数据组,该i与p是大于或等于2的整数,该i大于该p,每一个该次数据组包含i/p个位。
根据本发明的一实施例,对于所述的人工智能加速器的处理方法,该部分权重存储部包含的该多个权重区块的数量是q个,q大于或等于2的整数,该部分权重存储部包含j个位,该j、q是大于或等于2的整数,该j大于该q,每一个该权重区块包含j/q个存储单元,该多个处理片总合的该多个权重存储部的存储单元总量为p×q×2
根据本发明的一实施例,对于所述的人工智能加速器的处理方法,对于该逐块输出电路的操作,在每一阶的该移位与相加运算中包括使用至少一个该移位器与至少一个该加法器。对于每一阶的多个输入值以相邻两个为一处理单元,其中属于较高位的该输入值通过该移位器后与较低位的该输入值由该加法器相加后输出给下一阶,其中最后一阶输出单一值当作对应该处理片的该权重输出值。
根据本发明的一实施例,对于所述的人工智能加速器的处理方法,在第一阶的该移位器的移位量是j/q存储单元,后一阶的该移位器的移位量是前一阶的该移位器的移位量的两倍。
根据本发明的一实施例,对于所述的人工智能加速器的处理方法,对于该加总输出电路的操作,在每一阶的该移位与相加运算中包括至少一个该移位器与至少一个该加法器。对于每一阶的多个输入值以相邻两个为一处理单元,其中属于较高位的该输入值通过该移位器后与较低位的该输入值由该加法器相加后输出给下一阶,其中最后一阶输出单一值当作该总和值。
根据本发明的一实施例,对于所述的人工智能加速器的处理方法,在第一阶的该移位器的移位量是i/p位,后一阶的该移位器的移位量是前一阶的该移位器的移位量的两倍。
根据本发明的一实施例,对于所述的人工智能加速器的处理方法,更包括:使用正规化处理电路,对该总和值进行正规化处理得到正规化总和值;以及使用数量化处理电路,以一基数将正规化总和值数量化成为整数量值。
根据本发明的一实施例,对于所述的人工智能加速器的处理方法,该处理电路包括多个感应放大器,使用该多个感应放大器分别感应每一个该区块部分进行回旋运算后得到多个感应值,当作该多个权重运算值。
为让本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附附图作详细说明如下。
附图说明
图1是依据本发明一实施例,人工智能加速器的基本架构示意图。
图2是依据本发明一实施例,人工智能加速器的操作机制示意图。
图3是依据本发明一实施例,人工智能加速器的规划示意图。
图4是依据本发明一实施例,人工智能加速器的规划示意图。
图5是依据本发明一实施例,存储单元的存储单元架构示意图。
图6是依据本发明一实施例,对于一个处理片针对多个权重区块加总的机制示意图。
图7是依照本发明的一实施例,是依据本发明一实施例,对于多个处理片之间的加总电路的操作机制示意图。
图8是依据本发明一实施例,人工智能加速器的整体应用配置示意图。
图9是依据本发明一实施例,人工智能加速器的处理方法的流程示意图。
【符号说明】
20:人工智能加速器
50:输入数据
52:接收端元件
54:存储单元
56:存储单元阵列结构
58:输出数据
60:感应放大器
100_1、100_2、100_(p-1)、100_p:处理片
102_1、102_2、102_p:次输入数据组
104_1、104_2、104_p:输出数据
300:存储单元
302:权重区块
308、314、316:移位器
312、318:加法器
350、354、356:移位器
352、358:加法器
400:处理电路
402:乘法器
404:常数
406:加法器
408:偏移量
500:量化电路
502:除法器
504:基数
600:整体系统
602:人工智能加速器
604:控制单元
700:存储器
S100、S102、S104、S106、S108:步骤
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
本发明的实施例提供一种人工智能加速器,由分割的输入位与分割的权重区块所构成的人工智能加速器。利用分割的输入位与分割的权重区块平行,再通过移位与相加运算将分别平行运算的值做组合,以还原得到单一芯片所预期的运算结果。如此,人工智能加速器的处理速度可以有效提升,且可以减少耗能。
以下提供多个实施例来说明本发明,但是本发明不限于所举的实施例。
图1是依据本发明一实施例,人工智能加速器的基本架构示意图。参阅图1,人工智能加速器20包括以3D结构配置的NAND存储单元54,其包含多层的2D存储阵列。每一层的存储阵列的每一个存储单元分别存储一权重值。每一层的存储阵列的所有权重值依照预定的特征而构成权重形态。权重形态例如是所要辨识的形态的数据,例如脸、耳、眼睛、鼻子、嘴、或是对象等等的形状数据。每一种权重形态以2D存储阵列存储于3D NAND存储单元54的一层。
通过人工智能加速器20的存储单元阵列(cell array)结构56对应输入数据以线路安排,存储于存储单元的权重形态可以与经过接收端元件52所接收与转换的输入数据50进行回旋运算。此回旋运算一般例如是矩阵的相乘运算而得到一个输出值。依照对一层的权重形态通过存储单元阵列结构56进行回旋运算后得到输出数据58。输出数据58可表示输入数据50与权重形态的匹配程度。回旋运算可以依据本领域的一般方式来进行,无需别限制。于此其详细操作不再予描述。从效能而言,每一层的权重形态类似一个对象的过滤层,以辨识输入数据50与之相匹配的程度而达到辨识的功能。
图2是依据本发明一实施例,人工智能加速器的操作机制示意图。参阅图1、2,输入数据50例如是一张影像的数字数据。以动态的侦测的影像为例,摄影机随时拍摄的实际影像的部分或全部,会由人工智能加速器20进行辨别是否包含有存储于存储单元54的多种对象的至少其一。由于影像分辨率的提高,一张图像的数据报含大量的数据。存储单元54的架构是3D的多层的2D存储单元阵列。一层存储单元阵列包含i个用于输入数据的位线以及对应权重列(row)的j个选择线。也就是,存储权重的存储单元54是以多层的i×j的矩阵所构成。参数i与j是很大的整数。输入数据50会由存储单元54的位线接收,其分别接收影像的像素数据。通过外围配置的处理电路,输入数据50与权重进行包含矩阵相乘的回旋运算而输出运算后的输出数据58。
就较直接的回旋运算,其可以用分别的单一个位与单一个权重进行一一运算。然而由于要处理的数据量很大,因此整体的存储单元是很大,而构成一个相当大的处理芯片。在操作上,其速度会较慢。另外,大尺寸的芯片操作时所产生的耗能(热)也会较大。就人工智能加速器所需求的功能,其需要较快的辨识速度,而同时也希望能减低操作的耗能。
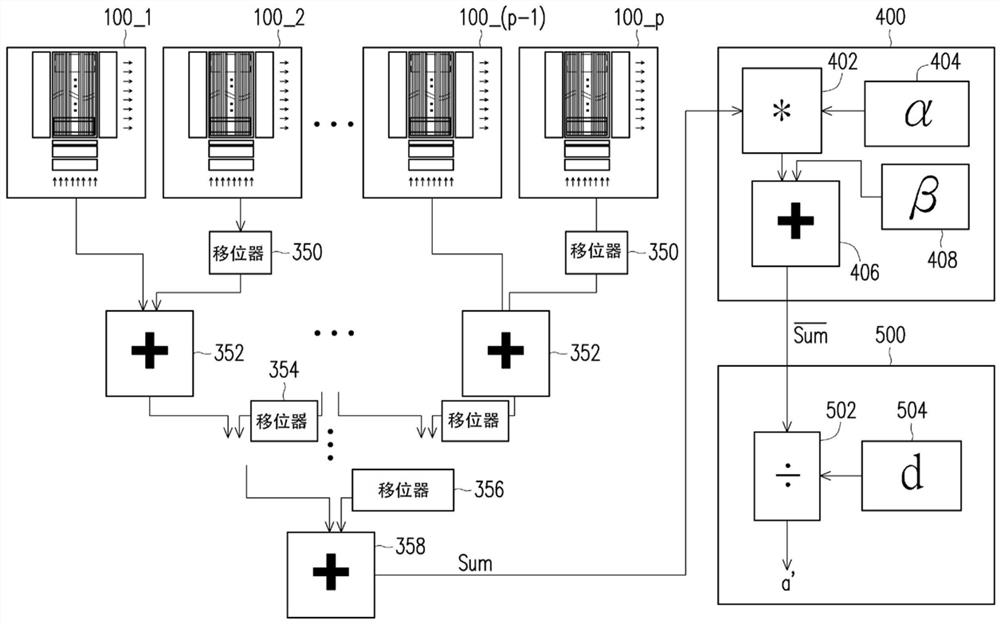
图3是依据本发明一实施例,人工智能加速器的规划示意图。参阅图3,本发明进一步提出人工智能加速器的运算规划方式。本发明的人工智能加速器维持接收平行输入的整体的输入数据50,但是将输入数据50(也称为输入数据组)分为多个次输入数据组102_1、…、102_p。每一个次输入数据组分别由一个处理片(processing tile)100_1、…、100_p进行针对次输入数据组102_1、…、102_p的回旋运算。每一个处理片100_1、…、100_p仅是处理整体回旋运算的一部分运算。如果以输入数据50包含i个位线为例,将i个位线分为p组,p为2或是大于2的整数。如此一个处理片包含i/p个位线,接收次输入数据组102_1、…、102_p,也就是次输入数据组是含有i/p个位数据。于此,参数i与p的关系是i可以被p整除的关系。然而,如果p个处理片不能整除i个位线,则其最后一个处理片仅处理余数的位线,其依照实际需要来规划,而无需限制。
依照图3的架构,其是采用p个处理片100_1、…、100_p来处理当前所选择的一层的权重形态,以进行回旋运算。整体的输入数据对应p个处理片也分为p个次输入数据组102_1、…、102_p而输入到对应的处理片100_1、…、100_p。经过p个处理片100_1、…、100_p所处理完的回旋运算后得到输出值104_1、…、104_p,例如是电流值。其后使用后面会描述的移位与相加的处理,可以得到相对应于以整体的输入数据组与整体的权重形态进行回旋运算后的结果。
就图3的分割方式,对于存储于处理片内的部分的权重形态是直接与次输入数据组进行回旋运算。回旋运算的效率可能可以再进一步提升。本发明在一实施例提出再进一步针对权重的区块规划。
图4是依据本发明一实施例,人工智能加速器的规划示意图。参阅图4,就整体预定的输入数据组例如包含排序从0到i-1的i个数据,其例是a
一个次输入数据组102_1、102_2…由对应的一个处理片100_1、100_2…进行回旋运算。此处理片100_1、100_2…的回旋运算是整体回旋运算的一部分运算。每一个处理片100_1、100_2…对应接收的次输入数据组102_1、102_2…分别平行处理。次输入数据组102_1、102_2…通过接收端元件66而进入到存储单元90中所关联的存储单元。
根据本发明的一实施例,对于存储权重的存储单元在列(row)的数量例例如是j个,j是大的整数。也就是说,对应一条位线有j个存储单元。每一个存储单元存储一个权重值。于此,存储单元列也可以称为选择线。根据本发明的一实施例,j个存储单元例如分割为q个权重区块92。在j可以被q整除的实施例,一个权重区块包含j/q个存储单元。对于一个存储单元,从输出端来看,其也是相当于二进制数串的一个位。这些权重区块也是依照权重的排序,从0到j-1分割成q个权重区块92。
对于整个回旋运算,其要得到加总值,以Sum表示,其如式(1)所示:
Sum=∑a*W (1)
其中“a”代表输入数据组,W代表存储单元中所选择的一层权重的二维阵列。
对于输入的次输入数据组以包含8个位的数据为例,其以二进制的数字串表示是[a
如此,整个回旋运算如式(2)表示:
SUM=(W
+(W
+…
+(W
(2)
对于如图2所示i×j的二维阵列所存储的权重形态,Sum是权重形态与整体输入数据组(a
每一个处理片100_1、100_2…也设置有处理电路70进行回旋运算。另外处理片100_1、100_2…也设置有逐块(block-wise)输出电路80,其包含多阶的移位与相加运算,对平行的零阶输出数据,依照位(存储单元)顺序,得到对应例如[W
在如上的规划下,对于一个处理片的一个权重区块的处理所使用的存储量是2
以下较详细描述根据分割的权重区块以及分割的处理片来得到整体运算的结果。
图5是依据本发明一实施例,存储单元的存储单元架构示意图。参阅图5,对于一个处理片存储单元,其对应一条位线BL_-1、BL_2…,会包含多个存储单元串,垂直分布连接到位线BL,构成3D的结构。存储单元串的每一个存储单元是属于一层的存储单元阵列,存储权重形态其中的一个权重值。在位线BL_-1、BL_2…的存储单元串是由选择线SSL启动。对应多个选择线SSL的存储单元构成权重区块,如Block_n所标示。输入数据由位线BL输入,经控制而流入对应的存储单元,如此到回旋运算。其后由输出端SL_n结合而输出。存储单元会包含q个区块,如Block_n×q所标示。
图6是依据本发明一实施例,对于一个处理片针对多个权重区块加总的机制示意图。参阅图6,在一个处理片的存储单元300中,其分割为多个权重区块302。每一个权重区块302会与次输入数据组进行回旋运算,而平行输出每个权重区块302的运算值,如粗箭头表示。其后通过感应放大器SA的感应分别输出一感信号,其例如是电流值。由于权重是依照二进制的排列且是平行输出。要得到十进制的数值,本发明一实施例提出逐块输出电路的配置,使用加法器312将相邻的相个输出值相加,这两个输出值中属于较高位的输出值先通过可以移位预定数字元的移位器308,将其移位到所对应的位顺序。例如一个权重区块包含j/q个位(存储单元),其属于较高位的输出值需要移位提高j/q个位,因此第一阶的移位与相加运算的移位器308具有移位j/q个位的效果。经过第一阶加法器的相加后,其代表2×j/q个位的数值。如此,对于其后的第二阶的移位与相加运算,其机制相同,但是移位器314的移位量是2×j/q个位。依此类推,最后一阶的输入值是仅是两个,因此只需要一个移位器316,但是移位量是例如是
于此要另外说明,一层的权重形态权重区块也可以分散由多个不同的处理片,其依照权重区块的规划与组合。也就是,一个处理片所存储的权重区块不需要同一层的权重数据。从另一方面来看,一层的权重数据的权重区块是分散到多个处理片。因此处理片可以平行运算。也就是,所涉及的多个处理片的每一个仅针对属于要处理一层层的区块进行运算即可,其后再将属与相同层的运算数据组合即可。
以下描述将多个处理片整合的移位与相加运算。图7是依据本发明一实施例,对于多个处理片之间的加总电路的操作机制示意图。参阅图7,p个处理片100_1、100_2、…、100_p分别依照图6的输出值进行移位与相加运算。于此的每一个处理片100_1、100_2、…、100_p是指同一层权重形态中分别对应次输入数据的回旋运算结果。
类似图6的情形,输入数据组是二进制输字符串,但是对于每一个次输入数据组例如都是i/p个位。因此第一阶的移位与相加运算也是取每一对相邻的输出由加法器352进行相加,其中属于较高位的数值先通过移位器350做i/p个位的移位。下一阶的移位与相加运算的移位器354是2×i/p个位的移位。最后一阶的移位器356的移位量是
此阶段的总和值Sum是初步的数值,在实际应用上,其后续需要进行正规处理,其例如使用正规化处理电路400,对总和值进行正规化处理,以得到正规化总和值。正规化处理电路例如包括式(3)的运算:
常数α404是缩放值通过乘法器402调整总和值Sum,其后再使用加法器406调整偏移量β408。
得到正规化后的总和值再通过量化电路500,其使用除法器502除以基数d 504进行量化,如式(4):
其中0.5表示取整数的运算。一般而言,如果输入数据组愈能吻合此层的特征形态,其数量化的值a′会愈大。
完成一层的权种形态的回旋运算,其利用字线继续选择下一层的权种形态进行回旋运算。
图8是依据本发明一实施例,人工智能加速器的整体应用配置示意图。参阅图8,整体系统600的人工智能加速器602与可以与主机的控制单元604进行双向交流。主机的控制单元604例如从外部的存储器700取得输入数据,例如是影像的数字数据,而输入给人工智能加速器602进行特征形态的辨别处理,而回复给主机的控制单元604。整体系统600的应用可以随实际需要配置,不限于所举的被置方式。
本发明一实施例也提供人工智能加速器的处理方法。图9是依据本发明一实施例,人工智能加速器的处理方法的流程示意图。
参阅图9,本发明一实施例更提供一种用于人工智能加速器的处理方法。人工智能加速器接收二位的一输入数据组与多层的整体权重形态中被选择的其一进行回旋运算,该输入数据组分为多个次数据组。处理方法包括步骤S100使用多个处理片,每一个该处理片包括执行。步骤S102使用接收端元件分别接收一个该次数据组。步骤S104使用权重存储部存储该整体权重形态的部分权重形态,其中该部分权重存储部包含多个权重区块,每一个该权重区块依照位顺序存储该部分权重形态的一区块部分,其中该权重存储部的存储单元阵列结构相对于所对应的该次数据组,规划成该次数据组分别与每一个该区块部分进行回旋运算得到依序的多个权重运算值。步骤S106使用包含多个移位器及多个加法器的逐块输出电路,通过多阶的移位与相加运算将该多个权重运算值总和得到由该次数据组与该部分权重形态直接进行回旋运算所预期的权重输出值。步骤S108使用包含多个移位器及多个加法器的加总输出电路,通过多阶的移位与相加运算对该多个权重输出值总和得到由该输入数据组与该整体权重形态直接进行回旋运算所预期的总和值。
如上所述,本发明的实施例提出将存储单元的权重数据分割由多个处理片进行回旋运算,同时在每一个处理片的存储单元也分割成多个权中驱块分别处理。其后通过移位与相加运算,可以得到最后的整体总合值。由于处理片的电路较小,指令周期可以提升,另外处理片处理时所耗能量,例如产生热,可以减少。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 人工智能加速器及其处理方法
- 人工智能加速器、设备、芯片以及数据处理方法