一种基于注意力权重计算的差分隐私加噪方法及系统
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及隐私保护、信息传播技术领域,尤其是涉及一种基于注意力权重计算的差分隐私加噪方法及系统。
背景技术
由于网络应用平台具有交流消息的及时性、共享性和用户发布评论的自由性等优点,网络在线活动变得越来越复杂化和多样性,这些网络平台为人们的生活和交流带来了极大的方便。与此同时,数据网络中包含多种敏感信息,如连接关系和属性信息等也会暴露,很容易引发隐私泄露问题。
目前,针对数据发布环节的隐私保护方案有很多,包括:(1)k-匿名及其衍生方法:该方法会改变原有数据结构,无法保证其数据效用,也无法从经过保护的数据合成图中发现更多社区特征。(2)随机化方法:由于匿名化网络的特征会在随机化过程的变化发生改变,要发布的数据效用的稳定性也可能会受到破坏;(3)泛化方法:将节点和边划分为若干组再进行分类,但这种方法发布的数据并不利于分析数据网络的局部结构,因此已发布的数据效用也会受到影响;现有方法均不同程度的影响了已发布数据的数据效用。
为不影响已发布数据的数据效用,研究者论证了差分隐私在隐私保护中应用的可行性,即,通过使用随机噪声来确保查询请求信息的结果不会泄露个体的隐私信息,例如:在输入或输出上加入随机化的噪音:拉普拉斯噪音,高斯噪音,指数机制等。
但,目前差分隐私在隐私保护中的应用还存在以下问题:(1)隐私保护在数据模型的价值利用方面会带来不同程度噪声的影响,噪声添加隐私预算越小,对准确性的影响通常越大。(2)在集中式的隐私噪声添加过程中需要计算每个样本的加噪参数,这会在数据处理的过程中引入过多计算的开销。(3)在数据分析中隐私预算的选择问题,预算越小,保护力度越强,如何衡量隐私预算的大小也是目前研究的重点。
发明内容
针对上述问题,本发明提供了一种基于注意力权重计算的差分隐私加噪方法及系统,通过结合图形数据网络的属性分类方法与注意力权重计算算法,设计一种权重分配制的噪声添加方法,通过对数据本身关联关系的考虑,在能够满足实际数据研究需求的前提下,通过合理分配噪声来保证信息的隐私性,且最大化保留数据的效用和研究价值。
为实现上述目的,本发明提供了一种基于注意力权重计算的差分隐私加噪方法,包括:将待处理的敏感数据预处理为图形数据,所述图形数据中包括各节点的节点数据和属性数据;
对所述图形数据进行随机采样,得到一组随机采样数据,包括节点的节点数据和属性数据;
基于该组节点的节点数据和属性数据,通过注意力机制得到所有节点的权重矩阵,计算各相邻节点间的注意力关系数,基于各相邻节点间的所述注意力关系数进行归一化计算,得到各节点的保护度权重;
根据各节点的所述保护度权重为各节点分配隐私预算;
基于随机采样数据对随机梯度优化算法的最佳梯度进行计算优化,在所述最佳梯度的优化过程中,根据不同的隐私预算为不同节点的数据加入不同程度的噪声;
持续对所述图形数据中的剩余数据进行随机采样,完成全部敏感数据的噪声的加入。
作为本发明的进一步改进,对待处理的敏感数据进行预处理时,对所述敏感数据的数据类型和计算维度进行统一处理;所述节点数据包括姓名、身份证号、身份ID,所述属性数据为辅助数据类型,包括性别、家庭住址。
作为本发明的进一步改进,所述基于该组节点的节点数据和属性数据,通过注意力机制得到所有节点的权重矩阵,计算各相邻节点间的注意力关系数,基于各相邻节点间的所述注意力关系数进行归一化计算,得到各节点的保护度权重;包括:
将该组节点的节点数据和属性数据均转换为线性特征,注意力机制基于所述线性特征计算该组节点的属性关系得到权重矩阵;
基于所述权重矩阵通过正则化得到不同节点间的注意力关系数;
基于各相邻节点间的所述注意力关系数进行归一化计算,得到各节点与该组节点中其他节点的关联程度,将各节点的所述关联程度对应定义为该节点的保护度权重。
作为本发明的进一步改进,所述根据各节点的所述保护度权重为各节点分配隐私预算;包括:
根据各节点的保护度权重的比值为各节点分配隐私预算。
作为本发明的进一步改进,所述基于随机采样数据对随机梯度优化算法的最佳梯度进行计算优化;包括:
基于随机梯度优化算法根据随机采样数据计算梯度的裁剪值和平均值;
若梯度的裁剪值大于平均值,则选用平均值作为最佳梯度,否则选用裁剪值作为最佳梯度。
本发明还提供了一种基于注意力权重计算的差分隐私加噪系统,包括:复杂数据预处理模块、保护度权重计算模块和噪声添加模块;
所述复杂数据预处理模块,用于:
将待处理的敏感数据预处理为图形数据,所述图形数据中包括各节点的节点数据和属性数据;
所述保护度权重计算模块,用于:
对所述图形数据进行随机采样,得到一组随机采样数据,包括节点的节点数据和属性数据;
基于该组节点的节点数据和属性数据,通过注意力机制得到所有节点的权重矩阵,计算各相邻节点间的注意力关系数,基于各相邻节点间的所述注意力关系数进行归一化计算,得到各节点的保护度权重;
所述噪声添加模块,用于:
根据各节点的所述保护度权重为各节点分配隐私预算;
基于随机采样数据对随机梯度优化算法的最佳梯度进行计算优化,在所述最佳梯度的优化过程中,根据不同的隐私预算为不同节点的数据加入不同程度的噪声;
持续对所述图形数据中的剩余数据进行随机采样,完成全部敏感数据的噪声的加入。
作为本发明的进一步改进,对待处理的敏感数据进行预处理时,对所述敏感数据的数据类型和计算维度进行统一处理;所述节点数据包括姓名、身份证号、身份ID,所述属性数据为辅助数据类型,包括性别、家庭住址。
作为本发明的进一步改进,所述基于该组节点的节点数据和属性数据,通过注意力机制得到所有节点的权重矩阵,计算各相邻节点间的注意力关系数,基于各相邻节点间的所述注意力关系数进行归一化计算,得到各节点的保护度权重;包括:
将该组节点的节点数据和属性数据均转换为线性特征,注意力机制基于所述线性特征计算该组节点的属性关系得到权重矩阵;
基于所述权重矩阵通过正则化得到不同节点间的注意力关系数;
基于各相邻节点间的所述注意力关系数进行归一化计算,得到各节点与该组节点中其他节点的关联程度,将各节点的所述关联程度对应定义为该节点的保护度权重。
作为本发明的进一步改进,所述根据各节点的所述保护度权重为各节点分配隐私预算;包括:
根据各节点的保护度权重的比值为各节点分配隐私预算。
作为本发明的进一步改进,所述基于随机采样数据对随机梯度优化算法的最佳梯度进行计算优化;包括:
基于随机梯度优化算法根据随机采样数据计算梯度的裁剪值和平均值;
若梯度的裁剪值大于平均值,则选用平均值作为最佳梯度,否则选用裁剪值作为最佳梯度。
与现有技术相比,本发明的有益效果为:
本发明采用注意力权重来衡量隐私预算的大小,对具有强依赖关系的特征数据进行较小的扰动,选择依赖关系较弱的进行较大程度的扰动,保护对模型重要性较高的数据,保证模型的价值较少受到噪声的影响;同时,本发明在梯度优化过程中加入噪声,梯度的值由随机采样数据计算而来,包含了随机采样数据的信息,对梯度进行扰动保证了后续用户更新参数值的操作不会泄露用户信息。
本发明在梯度优化过程中计算平均梯度,相较于计算每个样本的梯度,减少了计算开销,提高了计算效率。
本发明对梯度进行有限制的扰动,在一定程度上减小了噪声对数据原有准确率的影响。
附图说明
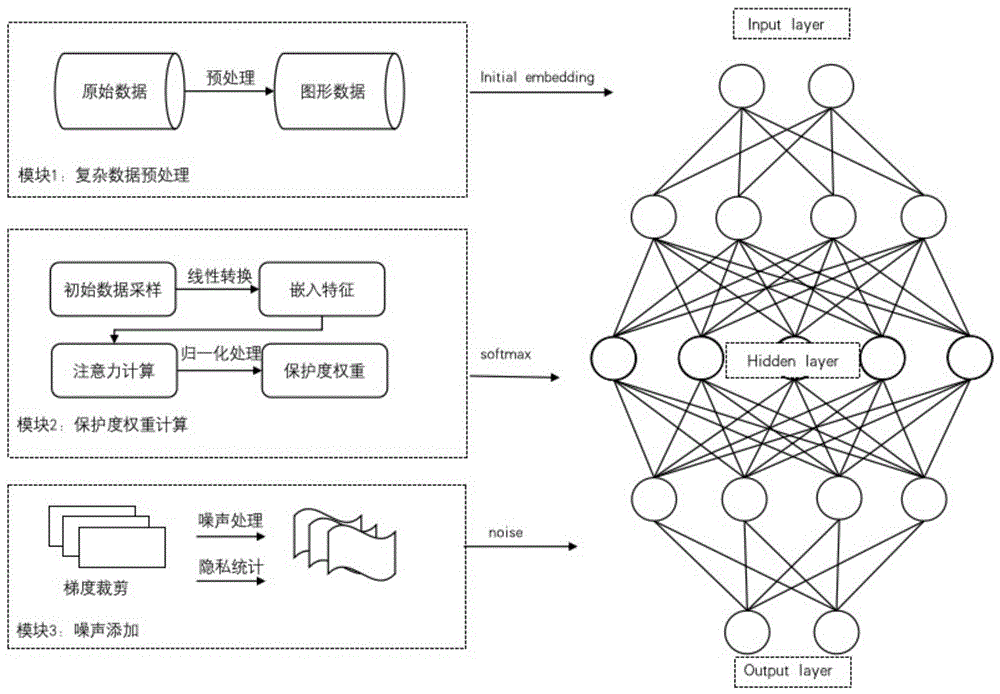
图1为本发明一种实施例公开的基于注意力权重计算的差分隐私加噪系统的加噪方法示意图;
图2为本发明一种实施例公开的复杂数据预处理模块示意图;
图3为本发明一种实施例公开的保护度权重计算模块流程示意图;
图4为本发明一种实施例公开的噪声添加模块流程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面结合附图对本发明做进一步的详细描述:
如图1所示,本发明提供的一种基于注意力权重计算的差分隐私加噪方法,包括:
S1、将待处理的敏感数据预处理为图形数据,图形数据中包括各节点的节点数据和属性数据;
其中,
如图2所示,对待处理的敏感数据进行预处理时,对敏感数据的数据类型和计算维度进行统一处理;
节点数据选取重点人员信息,包括姓名、身份证号、身份ID等主键信息,属性数据为辅助数据类型,Attribute1、Attribute2、Attribute3......,包括性别、家庭住址等,如果有这个属性就定义为1,无这个属性则为0。
S2、对图形数据进行随机采样,得到一组随机采样数据,包括节点的节点数据和属性数据;
其中,
随机采样数据中的节点数据和属性数据通过输入层处理转化为线性特征。
S3、基于该组节点的节点数据和属性数据,通过注意力机制得到所有节点的权重矩阵,计算各相邻节点间的注意力关系数,基于各相邻节点间的注意力关系数进行归一化计算,得到各节点的保护度权重;
其中,
注意力机制基于线性特征计算该组节点的属性关系得到权重矩阵;
基于权重矩阵通过正则化得到不同节点间的注意力关系数;
基于各相邻节点间的注意力关系数进行归一化计算,得到各节点与该组节点中其他节点的关联程度,将各节点的关联程度对应定义为该节点的保护度权重。
进一步的,
在网络中应用Attention Layer(注意力层),它可以通过使用权重矩阵的输出进行参数化。其中具体内容为输入为N个节点的数据,这其中包括了节点关键信息,即常见的个人ID信息,也包括其他的属性信息,例如性别、家庭住址和其他隐私类信息等。然后需要对所有节点属性关系通过Attention Mechanism算法计算出一个权重矩阵W,通过正则化得到的不同节点之间的注意力关系数b
保护度权重在一定程度上代表了受保护的目标节点在样本数据集中的可能会受到的攻击可能性,保护度系数(权重)越高,代表样本节点需要加入更多的扰动。
具体的,
保护度权重计算如图3所示,首先进行数据采样,随机选取数据集D
S4、根据各节点的保护度权重为各节点分配隐私预算;
其中,
根据各节点的保护度权重的比值为各节点分配隐私预算;
若节点的保护度权重高,则w比值高、噪声大;反之,若节点的保护度权重低,则w比值低、噪声小。
S5、基于随机采样数据对随机梯度优化算法的最佳梯度进行计算优化,在最佳梯度的优化过程中,根据不同的隐私预算为不同节点的数据加入不同程度的噪声;
其中,
基于随机梯度优化算法根据随机采样数据计算梯度的裁剪值和平均值;
若梯度的裁剪值大于平均值,则选用平均值作为最佳梯度,否则选用裁剪值作为最佳梯度。
进一步的,
差分隐私的两个性质帮助证明了本方案采样的可行性,包括可组合性和群组隐私性。其中可组合性保证了整体流程的模块化设计,即如果本方案采样中的数据处理模块满足差分隐私,则它们的组合也满足差分隐私。除此之外,当数据集中包含关于某个节点的多条属性信息时,群组隐私性使得(该节点的)隐私性缓慢降低,这也意味着方案中的目标节点受保护后,隐私性将不受其它由攻击者掌握的信息所影响。
本申请以机器学习中的SGD算法(随机梯度下降算法)为例,最后噪声添加的具体方法为:
首先,在SGD计算过程中,为了优化数学问题,会对待处理的敏感数据集进行计算并对优化函数L进行最佳梯度g的寻找,再根据随机采样数据样本的信息不断进行迭代和更新。
本发明选择在梯度优化更新中加入噪声,因为梯度的值由待处理的敏感数据集计算而来,包含了数据集上的信息,对梯度进行扰动就能保证后续更新参数值的操作不会泄露用户信息。另一方面,由于包含个人隐私的数据信息通常都具有节点性质和属性关系,所以在保护度权重计算中对数据节点进行注意力权重计算,得到各个节点的依赖关系和受保护程度w
具体的,
如图4所示,首先进行算法参数的初始化,再根据模块2的步骤进行数据采样和保护度计算,得到样本归一化的保护度权重w。然后进行梯度g的裁剪以及平均计算,梯度的裁剪使用l
S6、持续对图形数据中的剩余数据进行随机采样,完成全部敏感数据的噪声的加入。
其中,再次选择随机采样数据后,在基于上一次样本数据的梯度进行扰动之后,继续优化函数,再次选取新的样本数据进行迭代,直到优化函数寻找到最佳梯度,从而完成对复杂数据的隐私保护处理。
如图1-4所示,本发明提供了一种基于注意力权重计算的差分隐私加噪系统,包括:复杂数据预处理模块、保护度权重计算模块和噪声添加模块;
(1)复杂数据预处理模块,用于:
如图2所示,将待处理的敏感数据预处理为图形数据,图形数据中包括各节点的节点数据和属性数据;
其中,
对待处理的敏感数据进行预处理时,对敏感数据的数据类型和计算维度进行统一处理;
节点数据选取重点人员信息,包括姓名、身份证号、身份ID等主键信息,属性数据为辅助数据类型,Attribute1、Attribute2、Attribute3......,包括性别、家庭住址等,如果有这个属性就定义为1,无这个属性则为0。
(2)保护度权重计算模块,用于:
对图形数据进行随机采样,得到一组随机采样数据,包括节点的节点数据和属性数据;
基于该组节点的节点数据和属性数据,通过注意力机制得到所有节点的权重矩阵,计算各相邻节点间的注意力关系数,基于各相邻节点间的注意力关系数进行归一化计算,得到各节点的保护度权重;
其中,
随机采样数据中的节点数据和属性数据通过输入层处理转化为线性特征;
注意力机制基于线性特征计算该组节点的属性关系得到权重矩阵;
基于权重矩阵通过正则化得到不同节点间的注意力关系数;
基于各相邻节点间的注意力关系数进行归一化计算,得到各节点与该组节点中其他节点的关联程度,将各节点的关联程度对应定义为该节点的保护度权重。
进一步的,
在网络中应用Attention Layer(注意力层),它可以通过使用权重矩阵的输出进行参数化。其中具体内容为输入为N个节点的数据,这其中包括了节点关键信息,即常见的个人ID信息,也包括其他的属性信息,例如性别、家庭住址和其他隐私类信息等。然后需要对所有节点属性关系通过Attention Mechanism算法计算出一个权重矩阵W,通过正则化得到的不同节点之间的注意力关系数b
保护度权重在一定程度上代表了受保护的目标节点在样本数据集中的可能会受到的攻击可能性,保护度系数(权重)越高,代表样本节点需要加入更多的扰动。
具体的,
保护度权重计算如图3所示,首先进行数据采样,随机选取数据集D
(3)噪声添加模块,用于:
根据各节点的保护度权重为各节点分配隐私预算;
基于随机采样数据对随机梯度优化算法的最佳梯度进行计算优化,在最佳梯度的优化过程中,根据不同的隐私预算为不同节点的数据加入不同程度的噪声;
持续对图形数据中的剩余数据进行随机采样,完成全部敏感数据的噪声的加入。
其中,
基于随机梯度优化算法根据随机采样数据计算梯度的裁剪值和平均值;
若梯度的裁剪值大于平均值,则选用平均值作为最佳梯度,否则选用裁剪值作为最佳梯度。
进一步的,
差分隐私的两个性质帮助证明了本方案采样的可行性,包括可组合性和群组隐私性。其中可组合性保证了整体流程的模块化设计,即如果本方案采样中的数据处理模块满足差分隐私,则它们的组合也满足差分隐私。除此之外,当数据集中包含关于某个节点的多条属性信息时,群组隐私性使得(该节点的)隐私性缓慢降低,这也意味着方案中的目标节点受保护后,隐私性将不受其它由攻击者掌握的信息所影响。
本申请以机器学习中的SGD算法(随机梯度下降算法)为例,最后噪声添加的具体方法为:
首先,在SGD计算过程中,为了优化数学问题,会对待处理的敏感数据集进行计算并对优化函数L进行最佳梯度g的寻找,再根据随机采样数据样本的信息不断进行迭代和更新。
本发明选择在梯度优化更新中加入噪声,因为梯度的值由待处理的敏感数据集计算而来,包含了数据集上的信息,对梯度进行扰动就能保证后续更新参数值的操作不会泄露用户信息。另一方面,由于包含个人隐私的数据信息通常都具有节点性质和属性关系,所以在保护度权重计算中对数据节点进行注意力权重计算,得到各个节点的依赖关系和受保护程度w
具体的,
如图4所示,首先进行算法参数的初始化,再根据模块2的步骤进行数据采样和保护度计算,得到样本归一化的保护度权重w。然后进行梯度g的裁剪以及平均计算,梯度的裁剪使用l
再次选择随机采样数据后,在基于上一次样本数据的梯度进行扰动之后,继续优化函数,再次选取新的样本数据进行迭代,直到优化函数寻找到最佳梯度,从而完成对复杂数据的隐私保护处理。
本发明的优点:
本发明采用注意力权重来衡量隐私预算的大小,对具有强依赖关系的特征数据进行较小的扰动,选择依赖关系较弱的进行较大程度的扰动,保护对模型重要性较高的数据,保证模型的价值较少受到噪声的影响;同时,本发明在梯度优化过程中加入噪声,梯度的值由随机采样数据计算而来,包含了随机采样数据的信息,对梯度进行扰动保证了后续用户更新参数值的操作不会泄露用户信息。
本发明在梯度优化过程中计算平均梯度,相较于计算每个样本的梯度,减少了计算开销,提高了计算效率。
本发明对梯度进行有限制的扰动,在一定程度上减小了噪声对数据原有准确率的影响。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 触控显示组件、触控显示组件的贴合方法及触控显示装置
- 应用于电容触摸屏的触控方法、触控装置以及触控系统
- 整合型触控屏幕多轨录音编曲方法
- 触控屏幕的触控与显示电路及触控与显示控制模块,以及触控屏幕的控制方法