基于语音上下文动态特征的帕金森病检测方法
文献发布时间:2023-06-19 11:02:01
技术领域
本发明涉及信号处理和模式识别技术领域的一种方法,更确切地说,本发明涉及一种基于语音上下文动态特征的帕金森病检测方法。
背景技术
帕金森病(Parkinson disease,PD)是一种常见的神经退行性疾病,严重影响人类的健康。随着人口老龄化的加剧,帕金森病患者越来越多,并且有年轻化的趋势,帕金森病诊治形势日益严峻。随着时间的发展,该病症状越来越严重,并且不能彻底治愈,但早期干预和治疗能够缓解症状,提高患者生活质量。由于帕金森病发病初期症状不明显,而且没有一个普遍适用的标准能够快速准确地诊断帕金森病,很容易漏诊和误诊。大部分患者从出现症状到临床确诊,平均需要10个月时间,误诊率很高。如果能够实现帕金森病的可靠检测,使患者能在早期接受治疗,在延缓其病情发展,提高其生活质量,减轻家庭和社会负担等方面具有重要的意义。
研究表明,90%的帕金森病患者都有一定程度的语音障碍。利用语音障碍来诊断和治疗帕金森病,不但费用低廉,而且患者可通过非接触式方法自助测量,简单方便,易于实现远程诊断。通过语音信号进行帕金森病的诊断和康复治疗已经得到国内外研究学者的广泛关注。Little等人使用支持向量机(Support Vector Machine,SVM)对帕金森病患者的语音进行检测,判断用户是否患有帕金森病。叶晓江等人基于该研究,利用安卓技术开发出了基于语音的帕金森检测系统,用户在室内环境下自行采集持续的长元音/a/,然后将采集到的语音上传至该系统,由系统进行帕金森病的诊断。然而,在实际应用场景下,室内广泛存在的环境噪声无疑会对语音的平稳性及其它质量产生影响,进而影响语音特征提取的准确性,最终会影响基于语音和机器学习方法进行的帕金森病相关研究结果的准确性。
发明内容
针对现有的基于语音的帕金森预测技术中的特征过少、只采用静态特征、人为特征工程等问题导致的预测精度不高、系统的可用性不好的问题,本申请提供了一种基于语音上下文动态特征的帕金森病检测方法,通过利用双向长短时记忆循环神经网络建立帕金森语音检测模型,从而快速研判帕金森病。
为实现上述目的,本发明提供一种基于语音上下文动态特征的帕金森病检测方法,所述基于语音上下文动态特征的帕金森病检测方法包括以下步骤:
语音样本采集:在安静的环境下,对帕金森患者的声音进行采集,获得语音样本;
语音信号预处理:对采集的语音样本的频率进行重新采样;
语音特征的提取:对所采集的语音样本进行特征提取,包括发音特征和调音特征的提取;
建立语音检测模型:以双向长短时记忆循环神经网络为基础,结合语音特征建立帕金森语音检测模型;
利用帕金森语音检测模型对帕金森病的快速检测。
作为优选,在对语音信号的预处理过程中,对采集的语音样本的频率重新采样到48-96kHZ区间并保存。
作为优选,在对语音特征的提取步骤中,主要采用发音特征和调音特征进行提取,发音特征包括基音频率、基音频率的一次微分和二次微分,基频微扰,振幅微扰、振幅摄动商和对数能量;调音特征包括Bark带能量、梅尔倒谱系数、梅尔倒谱系数的一次微分和二次微分、第一共振峰频率和第二共振峰频率,第一共振峰的一次微分和二次微分以及第二共振峰频率的一次微分和二次微分。
作为优选,对所获取的语音信息进行分析,获得基音频率(F0),同时对基音频率进行一次微分(dF0)和二次微分(d
进行计算,其中N是语音发声的帧数,M
作为优选,振幅微扰(Shimmer)采用公式
作为优选,振幅设动商(APQ)采用公式
作为优选,语音特征的提取是采用连续的发言特征和调音特征形成动态发音矩阵和动态调音矩阵;动态发音矩阵由帧数和发音特征组成,动态调音矩阵由帧数和调音特征组成。
作为优选,对一段语音输入信号进行拆分处理,从而获得多个分段语音信号,将每一段语音信号拆分为发音特征和调音特征,然后采用双向长短时记忆循环神经网络建立帕金森语音检测模型。
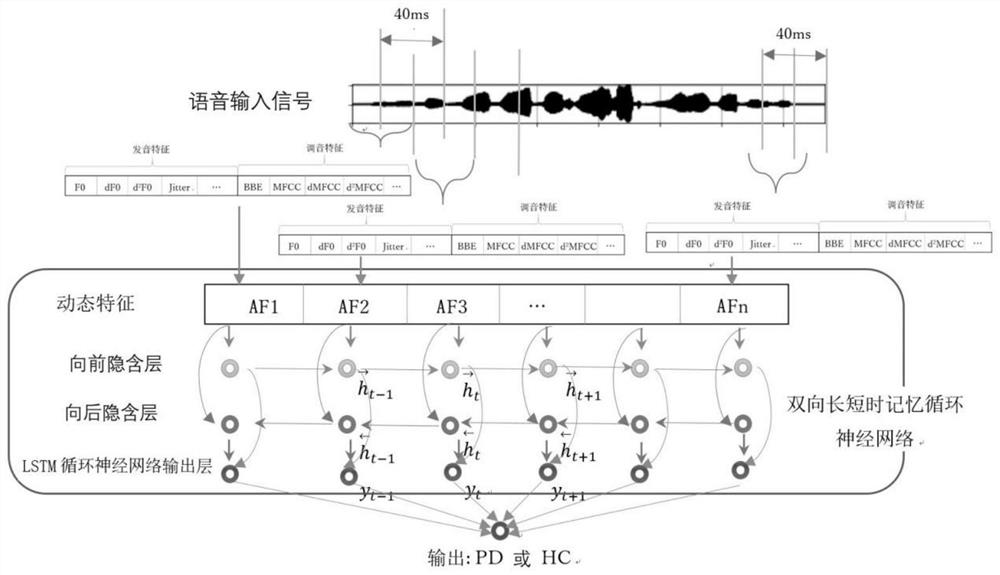
作为优选,双向长短时记忆循环神经网络包括动态特征、向前隐含层、向后隐含层和LSTM循环神经网络输出层,向前隐含层和向后隐含层对动态特征进行计算,最后通过LSTM循环神经网络输出层得到相关的信息,从而判断是否为帕金森患者。
作为优选,双向长短时记忆循环神经网络中的相关的计算公式为
其中W为权矩阵,b为偏置向量,S为向量每个元素的隐含层函数。
本发明的有益效果是:针对现有的基于语音的帕金森预测技术中的特征过少,、只采用静态特征、人为特征工程等问题导致的预测精度不高、系统的可用性不好的问题,本发明提出了从连续语音中提取上下文相关的动态特征。
采用PD动态语音特征,除了可以检测到常用的基于静态语音特征可检测到的语音震颤、呼吸急促和虚弱等PD典型特征,还能够通过语音波动及上下文依存关系捕获到采用一般的静态特征无法检测到的发音过程中由PD引起的异常清音,以及发声的开始和停止困难等特点,从而可以从很大程度上提高系统检测的精度。同时利用Bi-directional LSTM的记忆性、参数共享以及图灵完备(Turing completeness),实现高效地对语音序列的非线性特征进行学习。同时,通过在检测模式和语音时沿连续的抽象级别自动选择层次特征,避免了常规机器学习算法的特征工程,实现高效的PD检测。
附图说明
图1为本发明的基于双向长短时记忆循环神经网络的帕金森语音检测模型;
图2为本发明的LSTM处理方式示意图。
具体实施方式
为了更清楚地表述本发明,下面结合附图对本发明作进一步地描述。
帕金森病(Parkinson disease,PD)是一种慢性进展性神经变性疾病,其诊断通常是基于病史和神经系统检查发现的特殊临床特征,现有技术中采用了多种方式针对帕金森的诊断,例如公开了一种基于功率归一化倒谱系数特征的帕金森病语音检测方法,为克服帕金森病语音检测中易受噪声干扰的问题,通过Gammatone滤波器、去除噪声、功率归一化等方法增强所提取特征的鲁棒性,检测方法步骤:1)建立帕金森病语音库和健康语音库;2)对语音信号进行功率归一化倒谱系数特征提取:首先对语音信号进行预处理,然后利用Gammatone滤波器进行滤波,得到语音短时功率谱,接下来对语音短时功率谱进行加权平滑,最后计算功率归一化倒谱系数特征;3)利用外积得到特征向量;4)对特征向量进行功率和l2范数归一化;5)利用SVM训练帕金森病语音和健康语音模型;6)利用SVM分类方法进行分类,实现帕金森病语音检测,但是该方案用于帕金森病语音检测采用的语音短时功率谱是一种离散的静态语音特征,主要问题在于:1)特征参数过少;2)只采用了静态特征;此外,3)基于SVM模型的分类需要人为特征工程;这些因素会导致系统检测精度不高、效率低的问题。后续采用了一种基于PSO卷积核优化稀疏迁移学习的帕金森语音识别系统,但是该方法采用的公共语音数据集的语音特征与帕金森病的关联性不明确;同时只采用了静态特征;这些因素会导致系统检测精度不高的问题。
也正是基于此,本申请在这些技术的技术上进行进一步的研究,采用双向长短时记忆循环神经网络对语音的动态特征进行建模,从而解决现有技术所存在的问题。
更为具体的是,本发明提供一种基于语音上下文动态特征的帕金森病检测方法,其特征在于,所述基于语音上下文动态特征的帕金森病检测方法包括以下步骤:语音样本采集:在安静的环境下,对帕金森患者的声音进行采集,获得语音样本;语音信号预处理:对采集的语音样本的频率进行重新采样;语音特征的提取:对所采集的语音样本进行特征提取,包括发音特征和调音特征的提取;建立语音检测模型:以双向长短时记忆循环神经网络为基础,结合语音特征建立帕金森语音检测模型;利用帕金森语音检测模型对帕金森病的快速检测。在本实施例中,首先要对声音信息进行采集,从而得到帕金森患者的语音特征;声音是由于声带的振动而产生的,因此声带在振动过程中的有关变量,例如基频微扰、振幅微扰以及振幅扰动商和基音扰动商都会造成影响。
在对语音特征的提取步骤中,主要采用发音特征和调音特征进行提取,发音特征包括基音频率、基音频率的一次微分和二次微分,基频微扰,振幅微扰、振幅摄动商和对数能量;调音特征包括Bark带能量、梅尔倒谱系数、梅尔倒谱系数的一次微分和二次微分、第一共振峰频率和第二共振峰频率,第一共振峰的一次微分和二次微分以及第二共振峰频率的一次微分和二次微分。
对所获取的语音信息进行分析,获得基音频率(F0),同时对基音频率进行一次微分(dF0)和二次微分(d
进行计算,其中N是语音发声的帧数,M
发音特征主要是与唇、舌头和颌运动的幅度和速度降低有关,现有技术利用持续元音或连续语音对发音进行分析得知,发音特征主要包括元音空间面积、声五角面积和共振峰集中化比有关,且通过进一步单音/a/的持续发音分析表明,健康人(HC)说话的轮廓比帕金森患者(PD)的轮廓更加稳定,对于连续语音,通过计算清音段到清音段过渡过程中的能量含量来测量清晰度特征以及过渡偏移量,最后通过对语音信号中清音帧的频率内容和清音与清音之间的转换进行建模,从而得到语音信号中存在的噪声。
请参阅图1和图2,本申请采用双向LSTM模型捕获语音信号的时间序列特征来检测PD。双向LSTM模型以语音信号的动态时间序列发音特征(DF)作为输入。每个发音转换的DF包含58个测度,包括22个Bark带能量、12个梅尔倒谱系数、12个梅尔倒谱系数的一次微分和12个梅尔倒谱系数的二次微分。在输入双向LSTM模型之前,所有的动态特征序列将被零填充到相同的长度,本申请的动态发音特征矩阵由为40ms的帧(时移为20ms)的8个发音特征构成,动态调音矩阵由为40ms的帧(时移为20ms)的10个调音特征构成,利用发音特征和调音特征与双向长短时记忆循环神经网络相结合,实现建模,从而快速实现对PD患者的检测。
利用双向LSTM通过迭代来自t=(1,…,n)的前向层和来自t=(N,…,1)的后向层来计算前向隐藏序列h
其中W表示权重矩阵,b表示偏差向量,S是向量每个元素上的隐藏层函数,在双向LSTM网络中,每个神经网络单元是一个LSTM单元,
f
i
o
c
h
其中σ逻辑sigmoid函数f
下面以具体实施例来阐述本申请的技术方案,当然本申请的保护范围不仅仅于此,任何在本申请的基础上,在没有付出任何创造性劳动的前提下所做的改变,都属于本申请的保护范围。
一共采用45名志愿者(25名女性,20名男性)参与实验,其中15名为健康人士(HC),30名为帕金森患者(PD),其中帕金森患者中包含有1-5期帕金森病的患者,个体年龄在37-75岁之间,对于所有的志愿者,收集记录了5-6个声音样本,包括持续时间约为5秒的单声道/a/和持续时间约为5秒的短句,总共包括268个样本。并且将这些声音进行重新编辑,以96kHz的频段进行保存,采样NeuroSpeech软件对这些声音进行特征提取,获得发音特征和调音特征。
采用两种评价方法:1)10倍交叉验证;2)将数据集分割成训练集和测试集,其中没有一个个体的样本重叠,以确保无偏倚的结果。
1.采用传统的ML模型来检测PD
采用下表的配制参数来进行实验
利用不同的静态语音特征,比较几种传统的最大似然模型,下表列出了语音特征的尺寸和主要分析后的尺寸:
评估指标包括准确性(Accuracy),F-score、特异性(Specifity)、敏感性(Sensitivity、),Matthews相关系数(MCC),Fit_time和Score_time,这些指标的公式如下:
其中TP、TN、FP、FN为真阳性、真阴性、假阳性、假阴性的数目。敏感性和特异性是正确分类阳性和阴性病例的统计指标。f分数是精确度和召回率的调和平均值。MCC是一个用于量化值在-1到+1之间的二元分类质量的指标。而+1表示完美的预测,-1表示预测与实际标签不一致,0表示分类并不比随机预测好,Fit_time是每个CV分割对训练集上的估计量进行拟合的时间;Score_time是对每个CV分割在测试集中对估计量进行评分的时间。
利用动态语音特征在局部放电检测中的作用,并预先定义网络结构和参数并预先定义网络结构和参数。对于CNN模型,测试了卷积层中的三个激活函数(Relu,Tanh,Sigmoid)。卷积只在时间轴上进行。对于RNN模型,测试双向LSTM网络结构。
参数信息如下:
此外,还使用CNN模型转化为DL模型(CTD),对应的时频表示:a)线性标度-傅立叶变换;b)梅尔标度STFT谱图;3)恒Q变换(CQT)谱图;
对于RNN模型,参数信息如下:
通过处理得到以下结果:
经过10倍交叉验证进行评估,可以发现通过RNN模型,所获得的结果从准确度、得分(F-score)以及特异性都具有良好的结果。更进一步的分析得知,在短句上使用动态发音特征的双向LSTM模型获得了最佳的准确度、得分(F-score)以及特异性。但是单个计算时间比CNN长。与使用静态特征的传统ML模型相比,使用动态特征的基本DL模型显著提高了性能。
通过最大似然法检测帕金森病患者的语音变化已被证明是帕金森病早期检测的一种有前途的方法。在从语音中检测局部放电的任务中,基于最大似然方法的性能主要受语音特征和最大似然模型结构的影响。本申请利用与帕金森病检测相关的静态和动态语音特征。对发音过渡特征的比较分析表明,在HC说话者和PD患者之间,发音过渡的次数和基频曲线的趋势是显著不同的。采用配对t检验来评估说话人组和帕金森病组之间的发音转换次数的差异,得到的p值为0.042(<0.05),这表明这种差异不是偶然发生的,利用这一点,在使用动态语音特征中,采用双向LSTM模型,对于短句子的输入语音信号,双向LSTM提高了分类精度达到了84.29%,具有较好的应用前景。
以上公开的仅为本发明的几个具体实施例,但是本发明并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
- 基于语音上下文动态特征的帕金森病检测方法
- 基于上下文的语音情感检测方法、装置、设备及存储介质