从具有长写入时延的介质具有可预测读取时延的存储器系统
文献发布时间:2023-06-19 18:27:32
背景技术
传统的计算系统包括CPU,它可以与存储器系统耦合。CPU对内存执行读/写入操作,以访问存储在存储器系统中的数据。作为这些操作的一部分,CPU可以通过与存储器系统相关联的内存控制器向存储器发出命令。例如,写入命令可以提供用于写入存储器的地址和数据,而读取命令可以提供从存储器读取数据的地址。存储器系统可以包括具有存储单元的非易失性存储器,其执行写入操作所需的时间比执行读取操作所需时间要长。执行写入操作或读取操作所需的时间可能因存储单元的性质而异。
发明内容
在一个示例中,本发明涉及一种存储器系统。所述存储器系统可以包括N行瓦片和M列瓦片的至少一个阵列,其中N和M均为整数,其中每个所述瓦片被配置为存储与主机相关联的至少一个缓存行对应的数据,并且其中每个所述瓦片包括存储单元。所述存储器系统还可以包括控制逻辑。
所述控制逻辑可被配置为响应于来自主机的写入命令,发起第一缓存行向所述N行瓦片的第一行中的第一瓦片、第二缓存行向所述N行瓦片的第二行中的第二瓦片、第三缓存行向所述N行瓦片的第三行中的第三瓦片,以及所述N行瓦片的第四行中的第四缓存行的写入,并且由此响应于来自所述主机的所述写入命令而允许至少N个缓存行被写入。所述控制逻辑还可以被配置为响应于来自所述主机的读取命令,发起对存储在整行瓦片中的数据的读取,由此响应于来自所述主机的所述读取命令而允许至少M个缓存行被读取。
在另一示例中,本发明涉及一种存储器系统。所述存储器系统可以包括N行瓦片和M列瓦片的至少一个阵列,其中N和M均为整数,其中每个所述瓦片被配置为存储与主机相关联的至少一个缓存行所对应的数据,并且其中每个所述瓦片包括非易失性存储单元。所述存储器系统还可以包括控制逻辑。
控制逻辑可以被配置为响应于来自所述主机的写入命令,发起第一缓存行向所述N行瓦片的第一行中的第一瓦片、第二缓存行向所述N行瓦片的第二行中的第二瓦片、第三缓存行向所述N行瓦片的第三行中的第三瓦片、以及所述N行瓦片的第四行中的第四缓存行的写入,并且由此响应于来自所述主机的所述写入命令而允许至少N个缓存行被写入,并且生成针对所述N行瓦片的所述第一行中的瓦片的第一位级奇偶校验,针对所述N行瓦片的所述第二行中的瓦片的第二位级奇偶校验,针对所述N行瓦片的所述第三行中的瓦片的第三位级奇偶校验,以及针对所述N行瓦片的所述第四行中的瓦片的第四位级奇偶校验。所述控制逻辑还可以被配置为响应于来自所述主机的读取命令,发起对存储在整行瓦片中的数据的读取,并且由此响应于来自所述主机的所述读取命令而允许至少M个缓存行被读取。
在另一示例中,本发明涉及一种存储器系统。所述存储器系统可以包括N行瓦片和M列瓦片的至少一个阵列,其中N和M均为整数,其中每个所述瓦片被配置为存储与主机相关联的至少一个缓存行所对应的数据,并且其中每个所述瓦片包括非易失性存储单元。所述存储器系统还可以包括控制逻辑。
所述控制逻辑可以被配置为,响应于来自所述主机的尝试从所选择的瓦片读取数据的读取命令,发起对所述N行瓦片的一行中存储的数据的读取,除去来自所述N行瓦片的所述一行中的所述瓦片的所述所选择的瓦片,同时完成向来自所述N行瓦片的所述一行中的所述瓦片的所述所选择的瓦片的数据写入。所述控制逻辑还可以被配置为响应于来自所述主机的所述读取命令,使用来自所述N行瓦片的所述一行中的所述瓦片的数据、除去来自所述所选择的瓦片的数据,以及响应于来自所述主机的所述读取命令而被读取的与所述N行瓦片的所述一行对应的奇偶校验位,发起对来自所述N行瓦片的所述一行中的所述瓦片的所述所选择的瓦片中存储的数据的重建。
提供此发明内容是为了以简化的形式介绍一些概念,这些概念将在下文的详细说明中进一步描述。本发明内容并非旨在确定所要求保护的主题的关键特征或基本特征,也并非旨在限制所要求保护的主题的范围。
附图说明
本公开内容通过举例说明,不受附图的限制,在附图中类似的参考文献表示类似的元素。图中的元素是为了简单明了而说明的,不一定按比例绘制。
图1示出了根据一个示例的包括存储器系统的示意图;
图2示出了根据一个示例的存储体的示意图;
图3示出了根据一个示例的系统的示意图;
图4示出了根据一个示例的存储体的示意图;
图5示出了根据一个示例的存储体的示意图;
图6A和6B示出了根据一个示例的作为存储器的存储体的部分的奇偶校验位的旋转的示意图;
图7示出了根据一个示例的存储体的示意图;
图8示出了根据一个示例的存储体的示意图;
图9示出了根据一个示例的存储体的示意图;
图10示出了根据一个示例的与存储器系统相关联的方法的流程图;
图11示出了根据一个示例的与存储器系统相关联的另一种方法的流程图;以及
图12示出了根据一个示例与存储器系统相关联的另一个方法的流程图。
具体实施方式
本公开中描述的实例涉及从具有长写入时延的介质具有可预测读取时延的存储器系统。某些示例涉及用于与主机相关联的缓存行的读取和写入的存储器系统。某些示例涉及具有按行和列组织的瓦片阵列的存储器。在这样的存储器中,单个缓存行的写入操作可能会导致对与存储器相关联的多个瓦片的写入操作。某些示例涉及多个缓存行的写入,因为在类似的时间内,需要写入单个缓存行。
动态随机存取存储器(DRAM)是大多数计算机系统中作为主存储器使用的主要选择。DRAM通常耦合至主机,如CPU、GPU或其他类型的处理器,用于为程序和数据提供易失性内存存储。然而,与DRAM相关的半导体技术并不像其他半导体技术那样具有良好的扩展性。因此,人们正在研究替代性内存技术作为可能的替代物。在许多这些存储技术中,写入操作比读取操作需要更长的时间。因为与这种存储技术相对应的介质有很长的写入时延,这反过来又导致了不可预测的读取时延。进一步地,在许多存储器技术中,当存储器被写入时,读取存储器可能无法发生。因此,如果读取操作紧随写入操作,与正常的读取时延相比,它可能会遇到长时延。作为示例,NAND闪存的写入操作需要擦除和编程存储单元,因此写入操作比读取操作需要更长的时间。总之,在这些存储器技术中,当读取操作跟随任何写入操作时,读取操作会经历尾部时延。
本文描述的某些示例是针对改善存储器技术的性能,存储器技术是写入操作比读取操作花费更长的时间为特征。示例的存储器技术包括但不限于非易失性存储器技术和准易失性存储器技术,例如闪存(例如NAND闪存)、铁电随机存取存储器(FeRAM)、磁性随机存取存储器(MRAM)、相变存储器(PCM)和电阻式随机存取存储器(RRAM)。广义上讲,本公开内容涉及任何存储器技术,存储器技术包括比读取操作需要更长的时间来执行的写入操作。虽然大多数写入操作需要更长的时间来执行的存储器技术包括非易失性存储器,但某些包括易失性存储器的存储器系统也可能容易受到这个问题的影响。在本说明中,一些示例假设具有100纳秒(ns)读取时间和1微秒(μs)写入时间的存储器系统。某些示例通过对写入操作和读取操作进行不同的处理来完成这种改进,依据响应于来自主机的命令瓦片被处理。某些示例进一步涉及系统,该系统中用于读取操作或写入操作的访问单元与缓存行与耦合至存储器的主机相关联的缓存行相称。
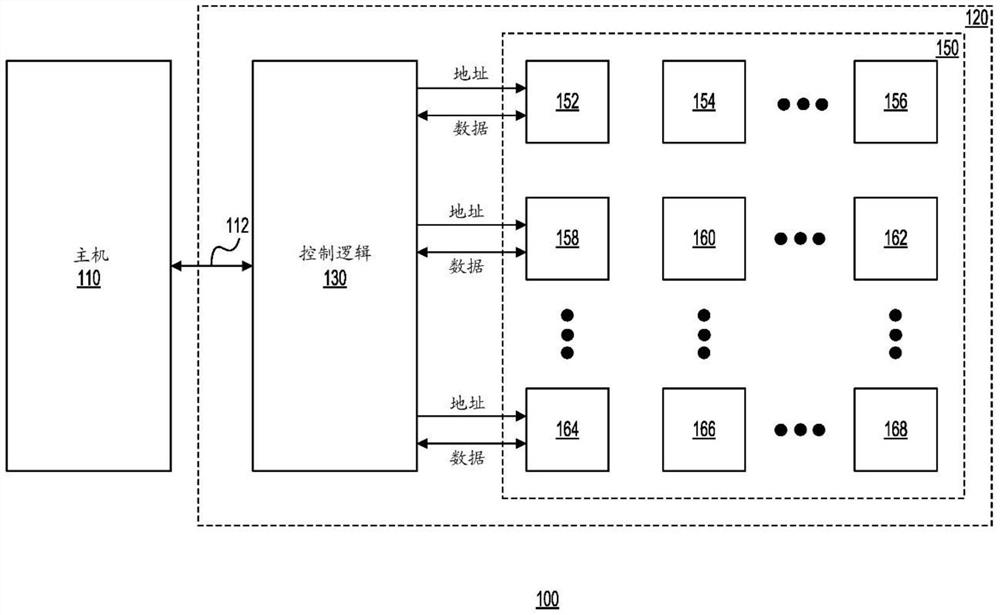
图1示出了根据一个示例的包括存储器系统120的系统100的示意图。地址信息可被用于选择芯片上的存储器位置。地址终端可被用于行和列地址的选择,该选择以多路复用的方式确定行和列地址。地址终端和内核存储体的数量和组织可能取决于存储器的大小和组织。地址信息可以对应于读取操作或写入操作。响应于读取操作,存储器系统120可以通过总线112向主机110提供数据。写入操作可能导致主机110通过总线112将数据提供给存储器系统120。存储器系统120可以包括控制逻辑130和存储器150,包括若干存储单元,以小组(例如,存储体)形式组织。因此,在这个示例中,存储器150可以包括存储体152,154,156,158,160,162,164,166和168。每个存储体可以进一步包括若干组存储单元。在本实施例中,每个存储体可以包括若干个瓦片。
继续参考图1,控制逻辑130可以包括用于执行至少部分或全部以下功能的逻辑:(1)接收来自主机110的外部命令,(2)向与存储器系统120相关联的解码器提供传入的地址,(3)传入的数据转移到相应的存储体,(4)从存储体接收数据,(5)与每个存储体相关联的解码器协调读取操作和写入操作,(6)生成存储体的特定地址,并向与每个存储体相关联的解码器提供这些存储体的特定地址,以及(7)在写入操作的情况下,提供要写入的数据,在读取操作的情况下,接收先前在该位置写入的数据。控制逻辑130与与存储器中的各存储体相关联的电路相结合,控制逻辑130可以被配置为执行进一步描述的任何操作。尽管图1示出了系统100和存储器系统120的一定数量的组件以某种方式排列,但系统100和存储器系统120的每个都可以包括更多或更少数量的以不同方式排列的组件。作为示例,尽管图1描述存储器150为具有存储体,存储器150不需要包括存储体。相反,存储单元可以按行和列组织。在其他的示例中,存储单元可以组织成组而不是存储体。此外,当使用存储体时,可以被组织成存储体组。此外,控制逻辑130可以以各种方式与作为存储器系统120一部分的存储器150集成。一种方式是在与存储器150相同的裸片上形成控制逻辑130。另外,控制逻辑130可以通过与存储器150紧密耦合的方式进行集成。关于其他实施方案的其他细节将结合图3进行描述。
图2示出了根据一个示例的存储器(例如,图1的存储器150)的存储体200的示意图。在这个示例中,存储体200可以包括若干解码器和若干以行和列组织的瓦片。作为部分地址所收到的地址位可被用于选择存储器的存储体,附加地址位可被用于选择该存储体中的行。每个瓦片可以包括一些数量的存储单元,这样每个存储单元可以存储数据单元(例如,逻辑位值0/1)。数据信号可以使用DATA总线提供给存储体200或从存储体200接收,地址信号可以使用ADDR总线提供给存储体200或从存储体200接收。在这个示例中,存储体200可以包括解码器210、230和250。存储体200可以进一步包括瓦片212、214、216、232、234、236、252、254和256,它们可以被组织成阵列的形式(例如,N乘M的阵列,其中N是阵列中的行数,M是列数)。存储体200可进一步包括读/写电路220、240和260。
继续参考图2,在本实施例中,解码器210可对应于顶行的瓦片,顶行的瓦片包括瓦片212、214和216,并且可通过字线耦合到这些瓦片。因此,解码器210可以解码通过其各自的ADDR总线收到的行地址。虽然在图2中没有示出,但存储体200可以进一步包括列解码器,以解码瓦片212、214和216的列地址。读/写电路220、240和260可以耦合到它们对应的DATA总线。在这个示例中,解码器230可以对应于另一行瓦片,包括瓦片232、234和236,并可以通过字线耦合到这些瓦片。因此,解码器230可以解码通过对应的ADDR总线收到的行地址。尽管在图2中没有示出,存储体200可以进一步包括列解码器,以解码瓦片232、234和236的列地址。在这个示例中,解码器250可以对应于存储体200的底行的瓦片,底行的瓦片包括瓦片252、254和256,并可以通过字线耦合至这些瓦片。因此,解码器250可以解码通过对应的ADDR总线收到的行地址。尽管在图2中没有示出,存储体200可以进一步包括列解码器,以解码瓦片252、254和256的列地址。
仍然参考图2,在一个示例中,写入操作可以包括跟随编程操作的擦除操作。解码器和读/写电路可在适当的时间内驱动适当的电流以执行擦除操作和编程操作。电荷泵可被用来为擦除操作和编程操作提供电流。如果脉冲电流被用于执行这些操作,电荷泵可以耦合至时钟电路。在一个示例中,读/写电路可以包括锁存器、开关和其他逻辑来临时存储数据,这样数据就可以写入瓦片或从瓦片中读取。读/写电路和解码器可以使用至少一个有限状态机(FSM)或类似的控制逻辑来控制。作为一个示例,电压驱动器被配置为驱动编程或擦除与瓦片相关联的非易失性单元所需的电流,可以使用FSM或类似的控制逻辑来控制电压驱动器。因此,根据非易失性单元的类型和与这些单元相关联的规格,电压驱动器可以对存储单元的栅极、漏极和/或源极施加适当的电压。此外,可以使用锁存器和电压驱动器电路来执行编程和擦除操作,以便它们可以在后台自主地进行,即使是在与存储体200相关联的瓦片被读取的时候。尽管图2示出了以某种方式排列的存储体200的一定数量的组件,但存储体200可以包括更多或更少数量的以不同方式排列的组件。
图3示出了根据一个示例的系统300的示意图。系统300可以包括连接到中介器320的封装衬底310。中介器320可进一步连接到控制逻辑裸片330和主机350。控制逻辑裸片330可以实现与图1的控制逻辑130相关的功能。主机350可以是图形处理器单元(GPU),中央处理单元(CPU),或片上系统(SOC)。存储器裸片340可以堆叠在控制逻辑裸片330的顶部。存储器裸片340可以实现与图1的存储器150相关联的功能。控制逻辑裸片330可包括组件(例如PHY 332),而主机350也可包括类似的组件(例如PHY 352)。这些组件可被用于通过中介器320将两者物理互连。控制逻辑裸片330和堆叠的存储器可以通过微凸块和硅通孔(TSV)进行互连。尽管图3示出的是单个存储器裸片340,但系统300可以包括多个堆叠的存储器裸片。此外,通过与控制逻辑裸片330的紧密耦合,存储器裸片340可以接收附加的命令/指令。尽管图3示出了系统300的一定数量的以某种方式排列的组件,但可以有更多,或更少数量的组件以不同方式排列。作为示例,控制逻辑裸片和存储器芯片不需要堆叠。同样,尽管图3示出了用于控制逻辑裸片、主机和存储器裸片互连的中介器,但也可以使用其他互连安排来整合逻辑与存储器。作为示例,这些组件可以是安装在PCB或其他共享衬底上的封装。控制逻辑裸片和存储器裸片可以使用各种键合技术进行键合。控制逻辑裸片和存储器裸片也可以在其他配置中相互耦合,包括封装叠加、系统级封装或其他配置。主机和存储器裸片也可以并排封装在单个封装衬底中。
在一个示例中,系统300可以包括存储体地址终端、地址终端、地址锁存器、多路复用器(根据需要)和输入/输出终端。地址信息可用于选择芯片上的存储器位置,芯片包括存储体、瓦片和行/列。地址终端可被用于行和列的地址选择,该选择是以多路复用的方式断定行和列的地址。地址终端的数量和组织可能取决于存储器的大小和组织。
为了解释与图1的存储器系统120相关的操作,图4示出了根据一个示例配置操作的存储体400。存储体400可以包括像图2的存储体200的组件。像存储体200一样,存储体400可以包括一些组织在阵列中的瓦片。此外,为了便于解释,前面示出的关于图1和图2的细节已被省略,作为图4和其他类似的图的部分,有助于描述存储器系统120的操作。每行瓦片可以包括相应的解码器(例如,DEC 0、DEC1或DEC7中的任何一个)。为了描述存储器的存储体(例如,存储体200)的操作,图4包括由字母T和瓦片的行/列号标识的瓦片。因此,瓦片T00是作为第0行和第0列的部分所包括的瓦片,瓦片T01是作为第0行和第1列的部分所包括的瓦片。为了便于解释,图4示出了具有64块瓦片的存储体;存储体可以包括更大数量(或更少数量)的瓦片。在操作方面,存储体400被配置为:读取操作需要整个行的读取,但写入操作则是写到行中的单个瓦片。这允许将数据写入八个不同的瓦片,每行一个,从而同时执行八个写入操作。作为示例,第0行和第3列的瓦片T03,第1行和第1列的瓦片T11,第2行和第4列的瓦片T24,第3行和第6列的瓦片T36,第4行和第1列的瓦片T41,第5行和第5列的瓦片T55,第6行和第2列的瓦片T62,以及第7行和第7列的瓦片T77可以作为单独的写入操作的部分。请注意,图4中所选择的瓦片的特定组合只是示例,其他的瓦片组合也可以作为单独的写入操作的部分被包括进来。在这个示例中,唯一的限制是,在写入操作期间,每行只有一个瓦片处于写入状态。然而,对每行中所选择的瓦片没有限制。有利的是,在这种瓦片的排列中,因为每个被写入的瓦片都有自己的地址解码器与瓦片行相关联,可以为不同行中的瓦片指定不同的地址。
继续参考图4,在一个示例中,每个瓦片被配置为存储一个或多个缓存行(例如,对应于与图1的主机110相关联的缓存行)。这样,在这个示例中,一个单独的写入操作可以把八个不同的缓存行写到八个不相关的地址。为了能够同时写入八个缓存行,与存储器相关的控制逻辑需要确保八个缓存行的八个地址中的每个都映射到八行瓦片组(例如,图2的存储体200)中的不同行。尽管图4示出了以某种方式排列的存储体400的一定数量的组件,但存储体400可以包括以不同方式排列的更多或更少数量的组件。
仍然参考图4,为了执行本实施例中描述的操作,控制逻辑(例如,图1的控制逻辑130或图3的控制逻辑裸片330)可以包括针对每个瓦片行的写缓冲区。在图4所示的示例中,有8行瓦片,因此控制逻辑裸片330可以包括8个写缓冲区。当从主机(例如,主机110或主机350)收到写入命令时,在一个示例中,写入命令被转发到适当的写缓冲区,基于与写入命令相关联的地址内的三比特组。这是因为,在这个示例中,有8个写缓冲区(每行一个),因此三个比特就足够了。每个存储体可以有自己的调度器(未显示),它可以调度计划执行的写入命令。随后,与每个存储体相关联的控制逻辑可以从8个相应的写缓冲区中提取数据,以及发起写入列中。在一个示例中,从与控制逻辑裸片330相关联的写缓冲区中收到的数据可以暂时存储在数据缓冲区或锁存器(例如,与图2的读/写电路220、240和260相关联的数据缓冲区或锁存器),数据缓冲区或锁存器作为存储器裸片340的部分。如果一个或多个写缓冲区是空的,相应的瓦片不需要被写入,如果只一个缓存行被写入,则可能需要进行读-修改-写入,如果被写入存储器的最小数据单位大于缓存行的大小。这个示例的方法导致了以下的写入性能:(1)八个存储体可以同时写入(基于功率限制);(2)每个存储体写入八个缓存行;(3)写入操作可能需要大约1微秒。这些操作指标转化为:(8*8)/1μs=每秒6400万次写入。
为了确保从单个瓦片读取的针对整个缓存行的适当的错误检测和纠正,错误纠正代码(ECC)可以存储在同一瓦片中。适当的ECC发生器被用于执行基于奇偶性的操作以生成代码。在这个示例中,ECC的使用将导致页面尺寸的增加,以存储所需数量的ECC位和元数据。当瓦片在为缓存行的读取提供服务时,可能需要对写缓冲区进行窥视。否则,读取操作可能会返回陈旧的数据。
如图5所示,如果需要瓦片故障后的生存能力作为存储器系统的部分,那么瓦片的每行需要附加的瓦片。附加的瓦片将存储其余八个瓦片的位级奇偶校验。根据一个示例,图5示出了存储体500,存储体500具有用于奇偶校验相关操作的附加的瓦片。存储体500可以包括如图4的存储体400所述的所有的解码器和瓦片。此外,存储体500可包括列,该列可包括针对每行瓦片的附加的瓦片。作为示例,瓦片T08可以作为顶行的部分。同样地,其他行可以包括附加的瓦片T18、T28、T38、T48、T58、T68和T78。在一个示例中,瓦片T08的给定索引的页面可以被配置为存储针对瓦片T01-T07具有相同索引的页面的位级奇偶校验。在这个示例中,在整个瓦片或其任何子集发生故障的情况下,可以通过简单的奇偶性计算重新创建数据。在这个示例中,每组8个缓存行的写入需要两列写入,所以写入性能可能被削减一半。尽管图5示出了以某种方式排列的存储体500的一定数量的组件,存储体500可以包括更多或更少数量的不同排列的组件。
继续参考图5,在本例中,每次缓存行被写入,来自瓦片行相应的页面必须被读取,以计算新的奇偶校验,然后将其写入奇偶校验瓦片中。这意味着奇偶校验瓦片的写入次数是其他瓦片的八倍。这可能会导致大量使用的存储单元出现更多的磨损,所以可能需要磨损平衡机制。造成磨损的原因至少有两个:(1)应用程序有可能以非常高的频率重复写入同样的位置(这可能是恶意行为);(2)奇偶校验瓦片将获得八倍于其他瓦片的写入次数。通过使用将逻辑地址映射到与存储器相关联的物理地址的技术,可以降低磨损。
作为示例,逻辑地址和物理地址之间的基于Start-Gap的映射可被使用。为了实现Start-Gap技术,额外的行可以添加至存储器。这个额外的行,可以被称为GAP-LINE,不包括任何有用的数据。也使用了与存储器的控制逻辑相关联的两个内部寄存器-START和GAP。START寄存器最初指向第0行,GAP寄存器总是指向与GAP-LINE对应的行。为了执行磨损均衡,每写入预定次数,存储在寄存器GAP中的值就会改变1,这导致奇偶校验位的物理地址移动到不同的物理地址。作为示例,该移动的完成是通过将GAP-1对应的行的内容复制到GAP-LINE对应的行,并且递减存储在GAP寄存器中的值。这样,每次间隙移动,逻辑地址将映射到不同的物理地址。使用与本公开内容有关的描述的存储器系统的这种技术降低了以非常高的频率向同样的位置重复写入所造成的磨损。
在示例中,为了解决对用于存储奇偶校验位的瓦片造成的磨损,可以使用用于存储奇偶校验位的不同位置。作为示例,针对缓存行地址的模操作(例如,缓存行地址模9)可以被用于选择瓦片行中的瓦片,该瓦片被选择是为了存储奇偶校验位。这有效地创造了针对连续地址的奇偶校验位置的旋转模式,根据本示例如图6A中关于存储体600所示。图6B示出了根据本示例的存储体600的下八个地址的奇偶校验位置的模式。
附加地,在示例中,行中奇偶校验位置的选择取决于逻辑地址,而不是取决于物理地址。这确保每次物理位置被映射到新的逻辑地址时,奇偶校验位置会移动到不同的瓦片上。这样,随着时间的推移,所有位置用于奇偶校验的时间大致相等,这就导致了磨损均衡化。
在某些示例中,存储器可以被优化,通过跨彼此相邻的瓦片组共享一些写入电路。如图7所示,而不是以八个瓦片的任何组合(每行一个瓦片)写入瓦片,与存储器相关的控制逻辑被配置为确保所有八个瓦片被存储在单独的一列,如图7所示。因此,在这个示例中,响应于来自于主机的写入命令,缓存行被存储在单独的一列中,该列包括T04、T14、T24、T34、T44、T54、T64和T74。列的选择仅是示例,因此只要所有的八个瓦片都存储在单独的一列中,其他列的瓦片也可以被写入。控制逻辑可以被配置为支持每次任何列的写入。作为示例,当选择要完成的写入,与非易失性存储器相关联的控制逻辑可以被配置为选择落在同列中但不同行的八个瓦片。为了实现这点,写缓冲区被提供给每个瓦片,而不仅仅是每行瓦片。
在存储体700的示例结构中,调度器可以针对写入选择连续的列,并从相应的写缓冲区中卸载写入并完成它们。不同于先前的方法,先前关于图4的存储体400所描述的方法要求每行瓦片有一个写缓冲区,这种方法要求每个瓦片有写缓冲区。附加地,调度器可以要求奇偶校验位被写入列,而不是以前面描述的关于图6A和6B的方式旋转奇偶校验位。在存储体700所示的示例结构中,通过定期改变用于存储奇偶校验位的瓦片列来实现磨损均衡。当进行这样的改变时,数据将不得不被重新写入,在这段时间内,存储器系统将遭受性能的降低。为了减少磨平操作的影响,在这个示例中,在系统遇到较低的需求时用于奇偶校验位的列可能被改变--例如在每天的特定时间。尽管图7示出了以某种方式排列的存储体700的一定数量的组件,存储体700可以包括更多或更少数量的不同排列的组件。作为示例,奇偶校验数据不是作为存储器150的一部分存储,而是奇偶校验数据可以存储在外部动态随机存取存储器(DRAM)中。由于DRAM在写入操作方面有更高的性能,而且写的持久性问题可以忽略不计,所以DRAM可能是存储奇偶校验的合适选择。这个示例将消除上述关于图6描述的在瓦片之间旋转奇偶校验的需要。增加外部DRAM将增加存储器系统的成本,但增加的一些成本可能被与存储器150相关联的下降的成本所抵消,不包括每行附加的奇偶校验瓦片。虽然可以使用任何类型的DRAM,但具有内置ECC的DRAM可能更适合于存储奇偶校验位。
如前所述,当瓦片正在被写入(例如,编程或擦除)时,它不能同时被读取。这意味着卡在写入后面的读取可能会经历显著的尾部时延。由于存储器的某些结构可能受到写带宽的限制,存储器可以被配置为至少在繁忙时期以接近全速的性能执行写入。即使以接近满负荷的性能执行写入,也可能意味着32个存储体中的8个存储体将忙于写入。因此,每四个读取操作中至少有一个可能会出现尾部时延。
与本公开内容的存储器相关联的示例结构被配置为允许读取瓦片行中的其余瓦片,同时瓦片被写入处于相同的瓦片行。作为示例,图8示出的存储体800在瓦片T34被写入的同时,对其他瓦片(例如,瓦片T30、T31、T32、T33、T35、T36、T37和T38)的读取。在这个示例中,在对瓦片T34的写入操作期间,瓦片T34没有被读取。继续参考图8,因为在这个示例中,瓦片T38存储奇偶校验,瓦片T34的数据可以被重建。这样一来,在响应于来自主机的读取命令,来自整行瓦片的数据都是可用的。因此,在这个示例中,当没有对关于正在被读取的瓦片行执行写入操作时,读取操作可以以与读取操作所产生的时延类似的时延完成。在示例中,包括排他性OR(XOR)门的逻辑电路可被用于瓦片T34的数据的重建。作为示例,假设数据D34对应于瓦片T34中的数据,并假设奇偶校验位LP存储在瓦片T38中,那么当使用XOR门和其他逻辑电路实现时,以下公式可被用于重建数据D34=D30⊕D31⊕D32⊕D33⊕D35⊕D36⊕D37⊕LP。在这个示例中,增加用于执行XOR逻辑操作的逻辑电路可能会在执行读取命令期间引入附加的时延。在示例中,与存储体800相关联的控制逻辑可以被配置为使所有读取命令经历相同数量的时延。作为示例,控制电路可以被配置为引入时延,该时延与通过XOR逻辑操作所引入的时延量相称,用于读取不要求瓦片的重建的瓦片行。也可以对电路进行其他改动,以确保读取/写入操作的时间一致。尽管图8示出了以某种方式排列的存储体800的一定数量的组件,存储体800可以包括更多或更少数量的不同排列的组件。
仍然参考图8,在示例存储体800中,尽管标为DEC3的解码器在读取操作和写入操作均被需要,但读地址和写地址是不一样的。因此,在这个示例中,当写入操作被发起时,行解码的结果可以被存储在与瓦片T34相应的锁存器中,这样,随后的读取可以使用标记为DEC3的解码器而不干扰正在进行的写入操作。在这个示例中,这意味着由标记为DEC3的解码器驱动的字线不能直接在瓦片内被使用,相反,读取操作可能需要经过锁存器和电压驱动电路,然后被一组独立的字线驱动。因此,在这个示例中,存储体800可能需要两组字线,这些字线将被路由到瓦片上。在示例中,这两组字线可以包括在跨瓦片行共享的全局字线(例如,图2中连接解码器和瓦片的字线)和仅在内部使用的局部字线。根据设计上的其他限制,局部字线的增加可能会或不会引起存储器裸片尺寸的增加。如果裸片尺寸的增加很小,重复的字线和锁存器可以被使用。在一个示例中,在半导体制造过程中,全局字线可以在与用于形成局部字线的金属层不同的金属层中形成。锁存器和其他电压驱动电路可以使用半导体加工技术形成。如果字线和锁存器的重复是极其昂贵的,另一种方法可以被使用。
作为示例,图9示出了存储体900,存储体900包括在瓦片行的两侧的解码器。在瓦片行的另一侧有第二列解码器。作为示例,顶行瓦片包括左侧的解码器DEC0和右侧的解码器DEC0A。在示例中,针对行(例如,DEC0和DEC0A)的每个解码器解码与另一个解码器相同的地址,并在相同的字线上驱动该地址。在这个示例中,附加的电路(例如,电路902、904、906、908、910、912、914和916)被安排在瓦片之间的空隙之间。在这个示例中,安排在每个空隙中的电路有两个功能:(1)能够有选择地切断与字线的连接;(2)有选择地锁存字线的状态,用锁存状态仅驱动局部瓦片。在一个示例中,电路902、904、906、908、910、912、914和916可以包括触发器以锁存字线的状态。
继续参考图9,为了发起在瓦片T34中数据的写入,该瓦片的地址可以被对应于该瓦片行(例如,图9中所示的DEC3和DEC3A)的两个解码器驱动。瓦片T34和T35之间的电路可以切断连接,这样两个解码器(例如DEC3和DEC3A)就不会试图同时驱动共享字线上的地址。附加地,瓦片T33和T34之间的电路可以包括电路,如锁存器以锁存字线解码器。随后,瓦片T33和T34之间的电路可以切断与标记为DEC3的解码器的连接,并在适当的写入电压下驱动解码器选择到针对瓦片T34的字线。由于在本例中,在瓦片T34两侧的连接被切断,该电压被限制在瓦片T34上。
仍然参考图9,当关于瓦片T34的写入操作被执行时,与存储器系统相关联的控制逻辑可通过驱动来自解码器DEC3和DEC3A的地址来发起读取操作。在这个示例中,解码器DEC3可以驱动瓦片T30、T31、T32和T33,解码器DEC3A可以驱动瓦片T35、T36、T37和T38。这允许在被访问的瓦片行中除去T34以外的所有瓦片的读取,读取包括响应于来自主机的读取命令而对瓦片T30、T31、T32、T33、T35、T36、T37和T38的读取。如前所述,关于图8,来自瓦片T34的数据可能通过以类似的方式使用XOR逻辑门而被重建。使用瓦片行的每侧的解码器,类似的读/写入操作通过关于作为存储体900的部分示出的任何瓦片行而被执行。
尽管存储体900的结构允许读取操作和写入操作同时发生,在本实施例中,操作可能不会在相同时间内被发起。这是因为,由于相同解码器被用于解码读取操作和写入操作的地址,因此每次只能一个操作被发起。在一个示例中,当发起读取操作或写入操作时,解码器的选择被锁定以允许该操作继续进行,而另一个操作则由新的解码器选择发起。尽管图9示出了以某种方式排列的存储体900的一定数量的组件,但存储体900可以包括更多或更少数量的不同排列的组件。尽管本文描述的与存储器系统相关的结构和操作是针对存储体来解释的,但存储器系统不需要包括任何存储体。相反,瓦片可以被组织成行和列的阵列。瓦片阵列可以被组织成类似于存储体的组,也可以不组织。
图10示出了根据一个示例的方法的流程图1000。在一个示例中,该方法中描述的步骤可由与存储器系统相关的控制逻辑执行。作为示例,图1的控制逻辑130和与存储器150相关的其他电路可被用于执行这些步骤。步骤1010可包括响应于来自主机的写入命令,发起第一缓存行向N行瓦片的第一行中的第一瓦片、第二缓存行向N行瓦片的第二行中的第二瓦片、第三缓存行向N行瓦片的第三行中的第三瓦片,以及N行瓦片的第四行中的第四缓存行的同步写入,并且由此响应于来自主机的写入命令而允许至少N个缓存行被写入。作为示例,作为该步骤的部分的写入操作可以包括写入图4的存储体400中所示的瓦片。因此,如前所述,来自主机(例如,图1的主机110)的单个缓存行的写入命令可能导致第0行和第3列的瓦片T03、第1行和第1列的瓦片T11、第2行和第4列的瓦片T24、第3行和第6列的瓦片T36、第4行和第1列的瓦片T41、第5行和第5列的瓦片T55、第6行和第2列的瓦片T62,以及第7行和第7列的瓦片T77被写入。
步骤1020可包括响应于来自主机的读取命令,发起对存储在整行瓦片中的数据的读取,由此响应于来自主机的读取命令而允许至少M个缓存行被读取。因此,正如前面所解释的,关于图4,没有被写入的任何行瓦片都可以被读取。作为示例,假设瓦片T03没有被写入,来自主机(例如,图1的主机110)的缓存行读取命令可能导致存储在该行中的所有缓存行被读取。
图11示出了根据一个示例的与存储器系统相关的方法的流程图1100。在示例中,该方法中描述的步骤可以被与存储器系统相关的控制逻辑执行。作为示例,图1的控制逻辑130和与存储器150相关的其他电路可被用于执行这些步骤。步骤1110可包括响应于来自主机的写入命令,发起第一缓存行向N行瓦片的第一行中的第一瓦片、第二缓存行向N行瓦片的第二行中的第二瓦片、第三缓存行向N行瓦片的第三行中的第三瓦片、以及N行瓦片的第四行中的第四缓存行的写入,并且由此响应于来自主机的写入命令而允许至少N个缓存行被写入,并且生成针对N行瓦片的第一行中的瓦片的第一位级奇偶校验,针对N行瓦片的第二行中的瓦片的第二位级奇偶校验,针对N行瓦片的第三行中的瓦片的第三位级奇偶校验,以及针对N行瓦片的第四行中的瓦片的第四位级奇偶校验。作为示例,作为这个步骤的部分的写入操作可以包括写入瓦片,如图4的存储体400中所示。因此,如前所述,来自主机(例如,图1的主机110)的缓存行写入命令可能导致写入第0行和第3列的瓦片T03、第1行和第1列的瓦片T11、第2行和第4列的瓦片T24、第3行和第6列的瓦片T36、第4行和第1列的瓦片T41、第5行和第5列的瓦片T55、第6行和第2列的瓦片T62,以及第7行和第7列的瓦片T77。此外,正如前面就图5的存储体500所解释的那样,在使用奇偶校验发生器或ECC引擎计算出奇偶校验后,奇偶校验位可以被存储在另外瓦片列中。作为示例,如图5存储体500的部分所示,可以生成奇偶校验位,然后存储在瓦片T08、T18、T28、T38、T48、T58、T68和T78。如前所述,生成的奇偶校验位可以以旋转模式存储,该旋转模式如前面所解释的关于图6A和6B所示的存储体600。最后,在另一示例中,生成的奇偶校验位可以被存储在外部DRAM中。
步骤1120可包括响应于来自主机的读取命令,发起对存储在整行瓦片中的数据的读取,并且由此响应于来自主机的读取命令而允许至少M个缓存行被读取。因此,正如前面所解释的,关于图4,没有被写入的任何瓦片行可能被读取。作为示例,假设瓦片T03没有被写入,来自主机(例如,图1的主机110)的缓存行读取命令可能导致存储在该行的所有缓存行被读取。
图12示出了根据一个示例的与存储器系统相关的方法的流程图1200。在一个示例中,该方法中描述的步骤可以被与存储器系统相关联的控制逻辑执行。作为示例,图1的控制逻辑130和与存储器150相关联的其他电路可被用于执行这些步骤。步骤1210可包括响应于来自主机的尝试从所选择的瓦片读取数据的读取命令,发起对N行瓦片的一行中存储的数据的读取,除去来自N行瓦片的该一行中的瓦片的所选择的瓦片,同时完成数据向来自N行瓦片的该一行中的瓦片的所选择的瓦片的写入。作为示例,作为这个步骤的部分的读取操作可以包括如图8的存储体800中所示的读取瓦片。因此,如前所述,来自主机(例如,图1的主机110)的缓存行读取命令可能导致瓦片T30、T31、T32、T33、T35、T36、T37和T38被读取。
步骤1220可包括响应于来自主机的读取命令,使用来自N行瓦片的一行中的瓦片的数据、除去来自所选择的瓦片的数据,以及响应于来自主机的读取命令而被读取的与N行瓦片的该一行对应的奇偶校验位,发起对来自N行瓦片的该一行中的瓦片的所选择的瓦片中存储的数据的重建。作为示例,图8的存储体800示出了正在读取其他瓦片(例如,瓦片T30、T31、T32、T33、T35、T36、T37和T38),而瓦片T34正在被写入。正如前面关于图8的存储体800所解释的那样,在对瓦片T34的写入操作期间,瓦片T34没有被读取。继续参考图8,由于瓦片T38存储了奇偶校验,瓦片T34的数据可以被重新构建。这样一来,响应于来自主机的读取命令时,整行瓦片的数据都可以被使用。如前所述,包括排他性OR(XOR)门的逻辑电路可被用来重建瓦片T34的数据。作为示例,假设数据D34对应于瓦片T34中的数据,并且假设奇偶校验位LP被存储在瓦片T38中,那么当使用XOR门和其他逻辑电路实现时,以下公式可用于重建数据D34=D30⊕D31⊕D32⊕D33⊕D35⊕D36⊕D37⊕LP。
总之,本公开内容涉及一种存储器系统,包括N行瓦片和M列瓦片至少一个阵列,其中N和M中均为整数,其中每个瓦片被配置为存储与主机相关联的至少一个缓存行所对应的数据,并且其中每个瓦片包括存储单元。该存储器系统可进一步包括控制逻辑。
控制逻辑可被配置为,响应于来自主机的写入命令,发起第一缓存行向N行瓦片的第一行中的第一瓦片、第二缓存行向N行瓦片的第二行中的第二瓦片、第三缓存行向N行瓦片的第三行中的第三瓦片,以及N行瓦片的第四行中的第四缓存行的写入,并且由此响应于来自主机的写入命令而允许至少N个缓存行被写入。控制逻辑可进一步被配置为,响应于来自主机的读取命令,发起对存储在整行瓦片中的数据的读取,由此响应于来自主机的读取命令而允许至少M个缓存行被读取。
在该存储器系统中,第一瓦片、第二瓦片、第三瓦片和第四瓦片不共享列。存储器系统可以进一步包括附加瓦片列,其中该附加瓦片列被配置为存储奇偶校验位。对一行瓦片中用于存储奇偶校验位的瓦片的位置的选择,是基于与瓦片的位置相关联的逻辑地址。
控制逻辑可进一步被配置为以降低对与瓦片相关联的存储单元的重复写入所造成的磨损的方式,将与缓存行相关联的逻辑地址映射到与缓存行相关联的物理地址。存储器系统可以进一步包括N个解码器,其中每个解码器对应于N行瓦片的相应行。
在另一个示例中,本公开涉及一种存储器系统。该存储器系统可包括N行瓦片和M列瓦片的至少一个阵列,其中N和M均为整数,其中每个瓦片被配置为存储与主机相关联的至少一个缓存行所对应的数据,并且其中每个瓦片包括非易失性存储单元。该存储器系统可以进一步包括控制逻辑。
控制逻辑可以被配置为,响应于来自主机的写入命令,发起第一缓存行向N行瓦片的第一行中的第一瓦片、第二缓存行向N行瓦片的第二行中的第二瓦片、第三缓存行向N行瓦片的第三行中的第三瓦片、以及N行瓦片的第四行中的第四缓存行的写入,并且由此响应于来自主机的写入命令而允许至少N个缓存行被写入,并且生成针对N行瓦片的第一行中的瓦片的第一位级奇偶校验,针对N行瓦片的第二行中的瓦片的第二位级奇偶校验,针对N行瓦片的第三行中的瓦片的第三位级奇偶校验,以及针对N行瓦片的第四行中的瓦片的第四位级奇偶校验。控制逻辑可以进一步被配置为,响应于来自主机的读取命令,发起对存储在整行瓦片中的数据的读取,并且由此响应于来自主机的读取命令而允许至少M个缓存行被读取。
在存储器系统中,第一瓦片、第二瓦片、第三瓦片和第四瓦片不共享列。在另一个示例中,在存储器系统中,第一瓦片、第二瓦片、第三瓦片和第四瓦片共享列。
与第一位级奇偶校验、第二位级奇偶校验、第三位级奇偶校验和第四位级奇偶校验对应的奇偶校验位被存储在一个单独的存储器中。与第一位级奇偶校验、第二位级奇偶校验、第三位级奇偶校验和第四位级奇偶校验对应的奇偶校验位被存储在瓦片中。控制逻辑可以进一步被配置为以降低对与瓦片相关联的存储单元的重复写入所造成的磨损的方式,将与缓存行相关联的逻辑地址映射到与缓存行相关联的物理地址。
在又一个示例中,本公开涉及一种存储器系统。该存储器系统可包括N行瓦片和M列瓦片的至少一个阵列,其中N和M均为整数,其中每个瓦片被配置为存储与主机相关联的至少一个缓存行所对应的数据,并且其中每个瓦片包括非易失性存储单元。该存储器系统可进一步包括控制逻辑。
控制逻辑可以被配置为,响应于来自主机的尝试从所选择的瓦片读取数据的读取命令,发起对N行瓦片的一行中存储的数据的读取,除去来自N行瓦片的该一行中的瓦片的所选择的瓦片,同时完成数据向来自N行瓦片的该一行中的瓦片的所选择的瓦片的写入。控制逻辑可以进一步被配置为,响应于来自主机的读取命令,使用来自N行瓦片的一行中的瓦片的数据、除去来自所选择的瓦片的数据,以及响应于来自主机的读取命令而被读取的与N行瓦片的该一行对应的奇偶校验位,发起对来自N行瓦片的该一行中的瓦片的所选择的瓦片中存储的数据的重建。
存储器系统可以进一步包括耦合到一组全局字线组的第一组电压驱动电路和锁存器以及耦合到一组局部字线组的第二组电压驱动电路和锁存器。存储器系统可进一步包括被配置为锁存的电路,在锁存器的其中之一,锁存与来自N行瓦片的一行瓦片中所选择的瓦片相关联的任何全局字线的状态,断开与全局字线的连接,并使用其中一个电压驱动电路驱动与来自N行瓦片的一行瓦片中所选择的瓦片相关联的任何局部字线。
存储器系统可以包括K个解码器,其中K是N的整数倍,并且其中来自K个解码器中的至少两个解码器对应于N行瓦片中的对应行。至少来自N行瓦片的一行瓦片中的瓦片的所选择的瓦片被耦合至一组全局字线和一组局部字线,一组全局字线至少跨N行瓦片的该一行瓦片而被共享,一组局部字线与来自N行瓦片的该一行中的瓦片的所选择的瓦片结合使用。存储器系统可进一步包括与该组全局字线耦合的第一组电压驱动电路和锁存器以及与该组局部字线耦合的第二组电压驱动电路和锁存器。
应当理解,此处描述的方法、模块和组件仅仅是示例性的。替代地,或附加地,本文描述的功能可以至少部分地由一个或多个硬件逻辑组件执行。例如,可以使用的硬件逻辑组件的说明性类型包括现场可编程门阵列(FPGA)、特定应用集成电路(ASIC)、特定应用标准产品(ASSP)、片上系统(SOC)、复杂可编程逻辑器件(CPLD),等等。在一个抽象的、但仍是确定的意义上,任何实现相同功能的元件排列都是有效的"关联",从而实现了所需的功能。因此,这里的任何两个组件结合起来实现一个特定的功能,可以被看作是相互"关联"的,从而实现了所需的功能,而不考虑结构或介质间的组件。同样,任何两个如此关联的组件也可被视为彼此"可操作地连接"或"耦合",以实现所需的功能。
与本公开内容中描述的一些示例相关的功能还可以包括存储在非临时性介质中的指令。本文使用的术语"非暂时性介质"是指存储导致机器以特定方式运行的数据和/或指令的任何介质。示例性的非暂时性介质包括非易失性介质和/或易失性介质。非易失性介质包括,例如,硬盘、固态驱动器、磁盘或磁带、光盘或磁带、闪存、EPROM、NVRAM、PRAM或其他此类介质,或此类介质的网络版本。易失性介质包括,例如,动态存储器,如DRAM、SRAM、缓存或其他此类介质。非暂时性介质与传输介质不同,但可以与传输介质一起使用。传输介质用于将数据和/或指令传输到机器上或从机器上传输。示例性的传输介质包括同轴电缆、光纤电缆、铜线和无线介质,例如无线电波。
此外,本领域的技术人员将认识到,上述操作的功能之间的界限仅仅是说明性的。多个操作的功能可以组合成一个操作,和/或一个操作的功能可以分布在其他操作中。此外,替代性实施例可包括特定操作的多个示例,并且操作的顺序可在各种其他实施例中被改变。
尽管本公开内容提供了具体的示例,但在不偏离下面的权利要求书中规定的公开范围的情况下,可以进行各种修改和改变。因此,应以说明性而非限制性的意义来看待说明书和数字,并且所有此类修改都旨在包括在本公开的范围内。此处就具体实例描述的任何好处、优势或对问题的解决方案不打算被解释为任何或所有权利要求的关键、必需或基本特征或元素。
此外,本文使用的术语“一个”或“一种”被定义为一个或多个。另外,在权利要求中使用诸如“至少一个”和“一个或多个”的介绍性短语,不应理解为暗示通过不确定条款““一个”或“一种”引入另一个权利要求元素,将包含这种引入的权利要求元素的任何特定权利要求限制为只包含一个这种元素的发明,即使同一权利要求包括介绍性短语“一个或多个”或“至少一个”和不确定条款诸如“一个”或“一种”。对于定冠词的使用也是如此。
除非另有说明,诸如“第一”和“第二”等术语被用来任意区分这些术语所描述的元素。因此,这些术语不一定是为了表明此类元素的时间或其他优先次序。
- 具有时延管理功能的广域保护系统及实现时延管理功能的方法
- 具有时延管理功能的广域保护系统及实现时延管理功能的方法