一种充电式吹风机及其控制方法
文献发布时间:2024-01-17 01:20:32
技术领域
本发明涉及吹风机技术领域,特别涉及一种充电式吹风机及其控制方法。
背景技术
目前,作为最常见的美发小家电,吹风机在我国城镇消费者中的普及率逐年升高,可以说,现在吹风机已经成为了城镇居民的必备小家电产品之一。吹风机不仅在普及率方面上有提高,而且用户在使用频率方面也有所提高。
随着人们对吹风机的需求越来越大,对吹风机的品质、功能都提出了更多的要求。传统意义上的吹风机都是通过使用电源线,接入220V交流电来驱动使用,这样的吹风机在使用过程中会始终受电源线束缚,存在使用不方便的问题,更不用说在脱离电源的环境中了。
另外,在使用吹风机的过程中,用户不仅不能直观了解出风的温度及风力,还常常要根据感觉对出风的温度和风力进行多次调节,但传统意义上的吹风机需要手动多次操作才能达到用户想要的效果,这个调节过程也是十分繁琐、不方便的。
发明内容
本发明旨在至少一定程度上解决上述技术中的技术问题之一。为此,本发明的目的在于提出一种充电式吹风机及其控制方法,旨在通过以充电驱动、直观显示出风温度及风力以及语音控制调节出风温度及风力的方式,提升用户使用吹风机的便捷性,从而提高用户的满意度。
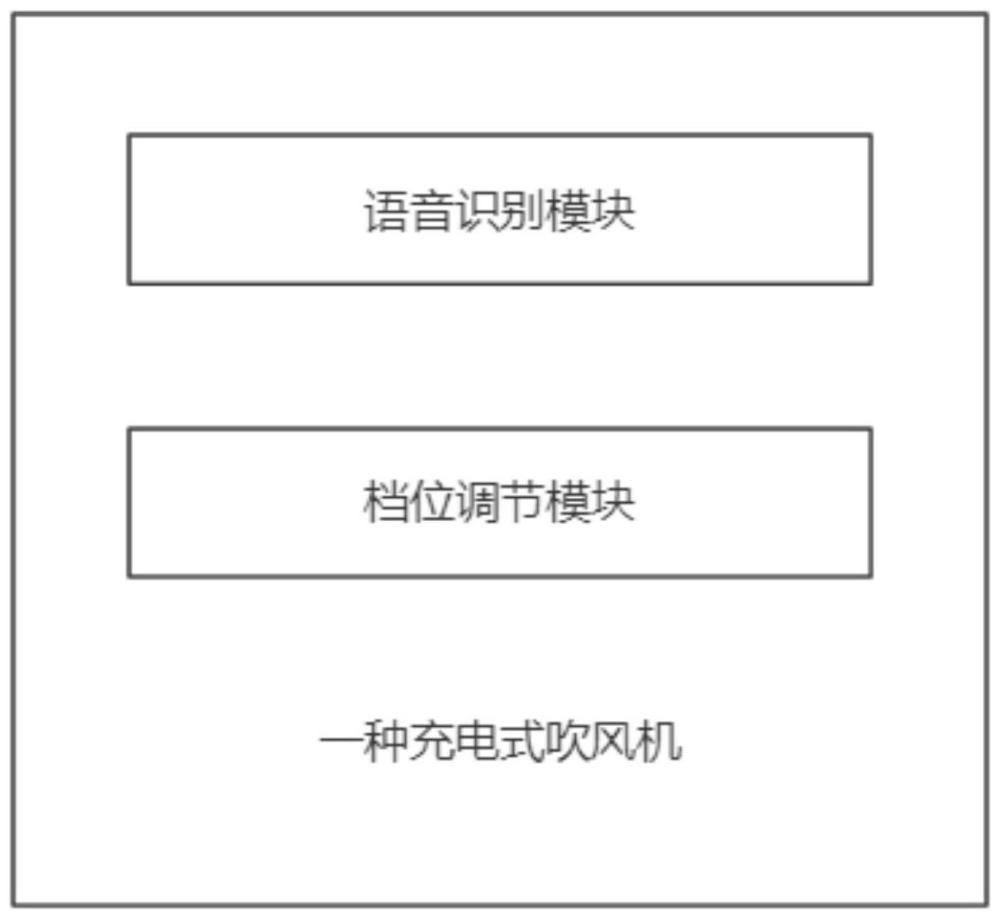
为达到上述目的,本发明实施例提出了一种充电式吹风机,包括:
语音识别模块,用于接收用户语音数据,并进行数据处理,对数据处理后的用户语音数据进行识别,确定控制指令;所述控制指令包括温度控制指令及风力控制指令;
档位调节模块,用于接收所述语音识别模块发送的控制指令,确定目标工作档位并进行调节。
根据本发明的一些实施例,所述充电式吹风机还包括:
可充电电池组;
电池管理模块,用于监测可充电电池组的储电及工作状态,并基于储电及工作状态对所述可充电电池组进行管理。
根据本发明的一些实施例,所述语音识别模块,包括:
第一接收子模块,用于接收用户语音数据;
处理子模块,用于对用户语音数据进行处理,得到待识别用户语音数据;
识别子模块,用于对待识别用户语音数据进行语音识别,确定控制指令。
根据本发明的一些实施例,所述处理子模块,包括:
降噪处理单元,用于降低用户语音数据中的噪声信号,得到第一中间语音数据;
语音分离单元,用于从第一中间语音数据中分离出用户的语音数据,并作为第二中间语音数据;
信号加强单元,用于将第二中间语音数据进行高频信号加强处理,得到待识别用户语音数据。
根据本发明的一些实施例,所述识别子模块,包括:
特征提取单元,用于将待识别用户语音数据输入至预先训练好的语音特征提取模型,得到待识别用户语音数据的特征向量信息,作为待匹配特征向量信息;
特征匹配单元,用于基于特征向量信息与预设的本地语音库中的关键词语音特征向量进行匹配,得到匹配结果;
语义获取单元,用于基于匹配结果及匹配的关键词语音特征向量对应的语义对应关系,得到第一用户语音语义;第一用户语音语义包括功能描述及调节度量描述;
判断单元,用于对第一用户语音语义进行有效性判断,将通过有效性判断的第一用户语音语义作为目标用户语音语义,根据目标用户语音语义确定控制指令。
根据本发明的一些实施例,所述判断单元,包括:
第一判断子单元,用于对第一用户语音语义中的功能描述进行判断,确定需要调节的功能;
第二判断子单元,用于在第一判断子单元确定需要调节的功能后,对第一用户语音语义中的调节度量描述进行判断,确定目标值;
第三判断子单元,用于:
确定需要调节的功能对应的调节范围;
在确定目标值在调节范围内时,确定通过有效性判断,将通过有效性判断的第一用户语音语义作为目标用户语音语义,根据目标用户语音语义确定控制指令。
根据本发明的一些实施例,所述降噪处理单元,包括:
语音筛选处理子单元,用于将用户语音数据中的纯净静音数据段进行剔除,得到噪声用户语音数据;
语音数据处理子单元,用于确定噪声用户语音数据中的噪声帧及人声帧;
模型训练子单元,用于基于训练模型样本,训练得到目标降噪神经网络模型;
用户语音降噪子单元,用于基于人声帧及目标降噪神经网络模型,得到用户降噪语音数据,并将用户降噪语音数据作为第一中间语音数据。
根据本发明的一些实施例,所述语音分离单元,包括:
训练子单元,用于基于样本原始语音数据及对应的样本最终语音数据,对语音分割模型进行训练;
分离子单元,用于:
基于第一中间语音数据及训练好的语音分割模型,得到第一中间语音数据的分割语音嵌入特征序集;
基于分割语音嵌入特征序集,对第一中间语音数据进行语音聚类,得到第一中间语音数据中用户的语音数据,并作为第二中间语音数据。
根据本发明的一些实施例,所述档位调节模块,包括:
第二接收子模块,用于接收所述语音识别模块发送的控制指令;
确定子模块,用于确定目标工作档位并进行调节。
根据本发明的一些实施例,一种充电式吹风机的控制方法,包括:
基于语音识别模块接收用户语音数据,并进行数据处理,对数据处理后的用户语音数据进行识别,确定控制指令;所述控制指令包括温度控制指令及风力控制指令;
档位调节模块根据控制指令,确定目标工作档位并进行调节。
本发明通过接收用户语音数据,对用户语音数据进行数据处理,可以在噪声较多及多人声源的使用环境中,有效地获取清晰的使用用户的语音数据,从而保证得到的控制指令的准确性。同时,使用语音进行控制调节,便于提升用户进行调节的便捷性,使调节更加智能化。档位调节模块根据控制指令确定目标工作档位并进行调节,便于基于指令的响应方式,快速进行档位调节,提高充电式吹风机的控制调节效率,从而提高用户的满意度。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是根据本发明一种充电式吹风机的框图;
图2是根据本发明一个实施例的语音识别模块的框图;
图3是根据本发明一个实施例的处理子模块的框图;
图4是根据本发明一种充电式吹风机的控制方法的流程图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例1:
本发明实施例提出了一种充电式吹风机,如图1所示,包括:
语音识别模块,用于接收用户语音数据,并进行数据处理,对数据处理后的用户语音数据进行识别,确定控制指令;所述控制指令包括温度控制指令及风力控制指令;
档位调节模块,用于接收所述语音识别模块发送的控制指令,确定目标工作档位并进行调节。
该实施例中,用户语音数据,为用户使用充电式吹风机时发出的对温度或风力进行调节的语音数据。
该实施例中,目标工作档位,包括调节的功能类型及对应的档位。
上述技术方案的工作原理及有益效果:通过接收用户语音数据,对用户语音数据进行数据处理,可以在噪声较多及多人声源的使用环境中,有效地获取清晰的使用用户的语音数据,从而保证得到的控制指令的准确性。同时,使用语音进行控制调节,便于提升用户进行调节的便捷性,使调节更加智能化。档位调节模块根据控制指令确定目标工作档位并进行调节,便于基于指令的响应方式,快速进行档位调节,提高充电式吹风机的控制调节效率,从而提高用户的满意度。
实施例2:
在实施例1的基础上,所述充电式吹风机还包括:
可充电电池组;
电池管理模块,用于监测可充电电池组的储电及工作状态,并基于储电及工作状态对所述可充电电池组进行管理。
该实施例中,工作状态,包括工作、待机及关机。
上述技术方案的工作原理及有益效果:通过配备可充电电池组,使吹风机摆脱了传统接线插电的使用方法,使吹风机能够更加轻便灵活的进行操作。通过电池管理模块对可充电电池组的储电及工作状态进行监测,便于用户及时了解可充电电池组的状态,从而进行充电或取消充电操作。
实施例3:
在实施例1的基础上,所述语音识别模块,如图2所示,包括:
第一接收子模块,用于接收用户语音数据;
处理子模块,用于对用户语音数据进行处理,得到待识别用户语音数据;
识别子模块,用于对待识别用户语音数据进行语音识别,确定控制指令。
该实施例中,控制指令,包括温度控制指令及风力控制指令。
上述技术方案的工作原理及有益效果:通过接收用户语音数据,并对用户语音数据进行处理,并于得到能够进行语音识别的清晰的属于用户的待识别用户语音数据,从而提高对待识别用户语音数据进行语音识别的准确性,保证控制指令的精准。
实施例4:
在实施例3的基础上,所述处理子模块,如图3所示,包括:
降噪处理单元,用于降低用户语音数据中的噪声信号,得到第一中间语音数据;
语音分离单元,用于从第一中间语音数据中分离出用户的语音数据,并作为第二中间语音数据;
信号加强单元,用于将第二中间语音数据进行高频信号加强处理,得到待识别用户语音数据。
该实施例中,第一中间语音数据,为对用户语音数据进行降噪后的数据;
该实施例中,第二中间语音数据,为从降噪后的数据中分离出多声源场景中用户的语音数据。
该实施例中,待识别用户语音数据,为将第二中间语音数据进行高频信号加强处理的数据。
上述技术方案的工作原理及有益效果:通过对用户语音数据进行降噪、分离及信号增强,有效获取到了在噪声场景或多声源场景中的使用用户的高质量的语音数据,便于进行语音识别,降低语音识别难度,提高识别效率。
实施例5:
在实施例3的基础上,所述识别子模块,包括:
特征提取单元,用于将待识别用户语音数据输入至预先训练好的语音特征提取模型,得到待识别用户语音数据的特征向量信息,作为待匹配特征向量信息;
特征匹配单元,用于基于特征向量信息与预设的本地语音库中的关键词语音特征向量进行匹配,得到匹配结果;
语义获取单元,用于基于匹配结果及匹配的关键词语音特征向量对应的语义对应关系,得到第一用户语音语义;第一用户语音语义包括功能描述及调节度量描述;
判断单元,用于对第一用户语音语义进行有效性判断,将通过有效性判断的第一用户语音语义作为目标用户语音语义,根据目标用户语音语义确定控制指令。
该实施例中,有效性判断,包括判断功能描述与其对应的调节度量描述的完整性以及合理性。例如:当第一用户语音语义为“温度、调至x度”,此时,首先判断“温度”与“度”的对应关系是完整的,其次,判断“x度”是否在充电式吹风机的温度调节范围内,若在,则“x度”的调节度量也是合理的,从而该第一用户语音语义通过有效性判断,可作为目标用户语音语义。
上述技术方案的工作原理及有益效果:通过对待识别用户语音数据进行特征提取,便于将得到的待匹配特征向量信息与本地语音库中的关键词语音特征向量进行匹配,提高匹配速度。基于得到的匹配结果及匹配的关键词语音特征向量对应的语义对应关系,得到第一用户语音语义,便于快速得到用户语音数据的语义。对第一用户语音语义进行有效性判断,能够保证第一用户语音语义的逻辑及控制合理性,从而生成有效的控制指令,提高用户使用充电式吹风机的满意度。
实施例6:
在实施例5的基础上,所述判断单元,包括:
第一判断子单元,用于对第一用户语音语义中的功能描述进行判断,确定需要调节的功能;
第二判断子单元,用于在第一判断子单元确定需要调节的功能后,对第一用户语音语义中的调节度量描述进行判断,确定目标值;
第三判断子单元,用于:
确定需要调节的功能对应的调节范围;
在确定目标值在调节范围内时,确定通过有效性判断,将通过有效性判断的第一用户语音语义作为目标用户语音语义,根据目标用户语音语义确定控制指令。
该实施例中,功能描述,包括温度及风力。
该实施例中,调节度量描述,即温度对应的衡量温度的度量数据及风力对应的衡量风力的度量数据。
该实施例中,目标值,表示为温度或风力的目标大小。
上述技术方案的工作原理及有益效果:通过第一判断子单元确定需要调节的功能,再通过第二判断子单元确定目标值,最后通过第三判断子单元确定需要调节的功能与目标值的有效性判断,便于得到一个合理有效的目标用户语音语义,从而保证生成的控制指令的有效性。
实施例7:
在实施例4的基础上,所述降噪处理单元,包括:
语音筛选处理子单元,用于将用户语音数据中的纯净静音数据段进行剔除,得到噪声用户语音数据;
语音数据处理子单元,用于确定噪声用户语音数据中的噪声帧及人声帧;
模型训练子单元,用于基于训练模型样本,训练得到目标降噪神经网络模型;
用户语音降噪子单元,用于基于人声帧及目标降噪神经网络模型,得到用户降噪语音数据,并将用户降噪语音数据作为第一中间语音数据。
该实施例中,将用户语音数据中的纯净静音数据段进行剔除,得到噪声用户语音数据,具体包括:
基于用户语音数据的语音波动周期,对用户语音数据进行分段划分,得到若干个用户语音数据段;
将每个用户语音数据段进行分层,得到每个用户语音数据段对应的若干个用户语音数据层;
获取每个用户语音数据段对应的若干个用户语音数据层的语音振幅数据,并基于语音振幅数据判断每个用户语音数据段是否为纯净静音数据段,并确定出是纯净静音数据段的用户语音数据段;
确定用户语音数据中纯净静音数据段的位置,将用户语音数据中的纯净静音数据段进行剔除,得到噪声用户语音数据;
该实施例中,基于语音振幅数据判断每个用户语音数据段是否为纯净静音数据段,即把语音振幅数据为0的用户语音数据段确定为纯净静音数据段。
该实施例中,确定噪声用户语音数据中的噪声帧及人声帧,具体包括:
将噪声用户语音数据进行分帧,得到多帧用户语音噪声块;
计算多帧用户语音噪声块包括的每帧用户语音噪声块的均方根值,并获取其中最大的均方根值;
基于最大的均方根值,将每帧用户语音噪声块的均方根值进行归一化处理,得到对应的判断值;
依次将每帧用户语音噪声块的判断值与预设的噪声阈值进行比较,将判断值小于预设的噪声阈值的用户语音噪声块确定为噪声帧;
将判断值大于等于预设的噪声阈值的用户语音噪声块确定为人声帧;
该实施例中,基于最大的均方根值,将每帧用户语音噪声块的均方根值进行归一化处理,得到对应的判断值,具体为:将每帧用户语音噪声块的均方根值与预设归一化参数相乘后,除以最大的均方根值,得到将每帧用户语音噪声块的均方根值进行归一化后的均方根值,并作为判断值。
该实施例中,基于训练模型样本,训练得到目标降噪神经网络模型,具体包括:
将预设的带噪语音数据与对应的纯净语音数据作为训练模型样本;
将训练模型样本中的带噪语音数据输入至降噪神经网络模型,得到第一降噪语音数据;
基于傅里叶变换原理,获取第一降噪语音数据对应的第一降噪语音实部及第一降噪语音虚部,并获取纯净语音数据对应的纯净语音实部及纯净语音虚部;
将第一降噪语音数据与纯净语音数据基于si-snr损失函数进行损失计算,得到第一损失参数;
将第一降噪语音实部、第一降噪语音虚部、纯净语音实部及纯净语音虚部进行均方损失计算,得到第二损失参数;
获取模型训练人员输入的权重参数,对第一损失参数及第二损失参数进行加权后做加法运算,得到加权和损失参数,并基于加权和损失参数对降噪神经网络模型的参数进行校正,持续迭代至降噪神经网络模型收敛,得到目标降噪神经网络模型;
该实施例中,将第一降噪语音实部、第一降噪语音虚部、纯净语音实部及纯净语音虚部进行均方损失计算,得到第二损失参数,具体为:基于MSE(Mean Square Error)均方损失计算原理,分别以第一降噪语音实部与纯净语音实部、第一降噪语音虚部与纯净语音虚部为一组计算参数,计算其整体的损失,得到第二损失参数。
该实施例中,基于人声帧及目标降噪神经网络模型,得到用户降噪语音数据,并将用户降噪语音数据作为第一中间语音数据,具体包括:
基于用户语音数据的时序关系,依次将多个人声帧输入至目标降噪神经网络模型,得到对应的多个降噪人声帧;
基于多个降噪人声帧,得到用户降噪语音数据,并将用户降噪语音数据作为第一中间语音数据。
上述技术方案的工作原理及有益效果:通过筛选出用户语音数据中的噪声用户语音数据,便于将用户语音数据中的无用数据进行排除,以便节省语音降噪资源,提高降噪效率。通过确定出噪声用户语音数据中的噪声帧及人声帧,便于将人声帧输入至训练好的目标降噪神经网络模型,从而快速得到降噪后的降噪人声帧,不仅能够提高语音的降噪效率,同时能够提升降噪质量,便于提高后续对用户语音数据进行识别的效率。
实施例8:
在实施例4的基础上,所述语音分离单元,包括:
训练子单元,用于基于样本原始语音数据及对应的样本最终语音数据,对语音分割模型进行训练;
分离子单元,用于:
基于第一中间语音数据及训练好的语音分割模型,得到第一中间语音数据的分割语音嵌入特征序集;
基于分割语音嵌入特征序集,对第一中间语音数据进行语音聚类,得到第一中间语音数据中用户的语音数据,并作为第二中间语音数据。
该实施例中,基于样本原始语音数据及对应的样本最终语音数据,对语音分割模型进行训练,具体包括:
获取样本原始语音数据及对应的样本最终语音数据;
提取样本原始语音数据中每一语音帧的特征信息,并基于特征信息生成原始语音特征图;
构建语音分割模型,并对模型参数进行初始化;
将原始语音特征图输入至语音分割模型,得到多个不同分割维度的分割特征图;
分别对不同分割维度的分割特征图进行卷积,计算得到对应的多个向量数据;
基于多个向量数据中对应包括的多个元素的信息,得到样本最终语音数据的样本分割预测数据;
获取样本最终语音数据在原始语音特征图中的标注数据;
将样本分割预测数据与标注数据进行误差计算,得到误差结果,并基于误差结果,调整语音分割模型的参数,循环迭代至误差结果小于预设的误差阈值,并将误差结果小于预设的误差阈值的语音分割模型作为训练好的语音分割模型;
该实施例中,语音分割模型,包括一个基础分割模型及多个不同的卷积核对应的卷积层。
该实施例中,多个向量数据,其中每个向量数据中的每个元素对应一组分割点,样本最终原始语音数据的预测信息即为每个元素的值。
该实施例中,标注数据,包括标注类型数据及对应的标注位置数据。
该实施例中,样本分割预测数据,包括类型预测数据及对应的位置预测数据。
该实施例中,基于第一中间语音数据及至训练好的语音分割模型,得到第一中间语音数据的分割语音嵌入特征序集,具体包括:
将第一中间语音数据输入至训练好的语音分割模型,得到多个不同分割维度的分割特征图,并将符合预设目标维度的分割特征图作为目标分割特征图;
基于目标分割特征图,得到对应的分割语音特征信息序集;
将分割语音特征信息序集输入至预设的语音特征模型,得到分割语音嵌入特征序集;
该实施例中,基于分割语音嵌入特征序集,对第一中间语音数据进行语音聚类,得到第一中间语音数据中用户的语音数据,并作为第二中间语音数据,具体包括:
将分割语音嵌入特征序集按序输入至预先基于神经网络构建的用户语音聚类模型中,得到分割语音嵌入特征序集对应的至少一个声源标签预测序集;
获取用户预先录入的标准识别语音数据对应的标准语音嵌入特征;
将标准语音嵌入特征输入至用户语音聚类模型中,得到标准声源标签;
将声源标签预测序集及标准声源标签进行匹配,得到声源标签预测子序集;
获取声源标签预测子序集对应的第一中间语音数据的多个语音片段;
基于多个语音片段对第一中间语音数据进行有序还原并进行去混响处理,得到第一中间语音数据中用户的语音数据,并作为第二中间语音数据。
该实施例中,声源标签预测序集,为将预测的声源的身份标签按序排列的有序集合。
该实施例中,标准声源标签,为充电式吹风机使用用户的身份标签。
该实施例中,声源标签预测子序集,为声源标签预测序集中与标准声源标签相符的有序集合。
上述技术方案的工作原理及有益效果:通过训练语音分割模型,从第一中间语音数据中获取分割语音嵌入特征序集,便于提高获取分割语音嵌入特征序集的准确性,将第一中间语音数据进行语音聚类,能够获得在多人发声的环境中分离出用户的语音数据,提高获取用户的语音数据的精准性,从而提高充电式吹风机根据用户语音进行响应的效率,提升用户的使用体验。
实施例9:
在实施例1的基础上,所述档位调节模块,包括:
第二接收子模块,用于接收所述语音识别模块发送的控制指令;
确定子模块,用于确定目标工作档位并进行调节。
上述技术方案的工作原理及有益效果:通过接收所述语音识别模块发送的控制指令从而确定目标工作档位并进行调节,便于根据控制指令快速调整至目标工作档位,提高调节效率,从而提升用户的使用体验。
实施例10:
根据本发明的一些实施例,一种充电式吹风机的控制方法,如图4所示,包括:
基于语音识别模块接收用户语音数据,并进行数据处理,对数据处理后的用户语音数据进行识别,确定控制指令;所述控制指令包括温度控制指令及风力控制指令;
档位调节模块根据控制指令,确定目标工作档位并进行调节。
该实施例中,用户语音数据,为用户使用充电式吹风机时发出的对温度或风力进行调节的语音数据。
该实施例中,目标工作档位,包括调节的功能类型及对应的档位。
上述技术方案的工作原理及有益效果:通过接收用户语音数据,对用户语音数据进行数据处理,可以在噪声较多及多人声源的使用环境中,有效地获取清晰的使用用户的语音数据,从而保证得到的控制指令的准确性。同时,使用语音进行控制调节,便于提升用户进行调节的便捷性,使调节更加智能化。档位调节模块根据控制指令确定目标工作档位并进行调节,便于基于指令的响应方式,快速进行档位调节,提高充电式吹风机的控制调节效率,从而提高用户的满意度。
实施例11:
在实施例1的基础上,所述确定子模块确定目标工作档位的方法,包括:
根据控制指令确定为温度控制指令时,获取温度控制指令的目标值与对应的当前值的差值;
基于差值确定温控工作元件的工作功率,根据工作功率确定目标工作档位。
上述技术方案的工作原理及有益效果:通过获取温度控制指令的目标值与对应的当前值的差值,从而根据确定温控工作元件的工作功率来确定目标工作档位,便于提高确定目标工作档位的准确性,保证充电式吹风机安全可靠运行。
实施例12:
在实施例1的基础上,所述充电式吹风机还包括:
显示模块,用于将当前档位在运行时的温度数据及风力数据进行显示。
上述技术方案的工作原理及有益效果:通过显示温度数据及风力数据,能够直观让用户对当前运行的温度数据及风力数据进行了解,当用户存在调节需求时.能够帮助用户进一步明确调节的度量,提升用户的使用体验感。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。