一种自动学习索引方法及系统
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及一种学习索引方法及系统,具体涉及一种根据计算机数据特征自动推荐最佳索引的方法及系统,属于数据库索引领域。
背景技术
现有计算机索引结构的优化大多是基于计算机数据最差的情况,并且是对读写相对均匀的计算机索引进行优化,所以对于一些特殊的情况,例如,某计算机数据集中的数据按照1-100M顺序排列,由于数据key值本身就可以作为偏移量使用,此时采用常用的B-Tree索引进行计算机数据查询就不是最优解,反而会因为B-Tree的构建增加B-Tree索引的查询时间复杂度和空间复杂度。B-Tree或B+Tree索引结构使用简单的条件判断语句进行递归地划分空间,不考虑每条计算机数据和其索引键值间是否具有联系,也没有利用已知数据的分布特点,因此,它们具有次优的空间代价和查询性能,且在现实中并没有一种已知的计算机数据模式分布可以遵循,就导致求出的实际计算机数据的分布模型的成本开销太大,以及索引结构推荐面向的计算机数据比较复杂,利用大规模的神经网络模型学习参数较多,模型灵活性也不足。为了解决这些问题,现有技术采用强化学习方法,但此方法应用于计算机数据查询时需要人为定义好当前计算机数据集和对应工作负载下的可选索引配置集,以及每个索引的层数和每个节点相应的模型,无法实现计算机查询数据从零开始的索引推荐,增加了索引建立的时间复杂度和空间复杂度,导致索引建立时的空间代价较大,建立过程难度较高,建立时间较长。
发明内容
本发明为了解决现有计算机的学习索引在建立时,需要人为定义学习索引的层数以及每个节点相应的模型,导致索引建立的空间代价较大,建立过程难度较高,建立时间较长的问题,进而提出了一种自动学习索引方法及系统。
本发明采取的技术方案是:
它包括以下步骤:
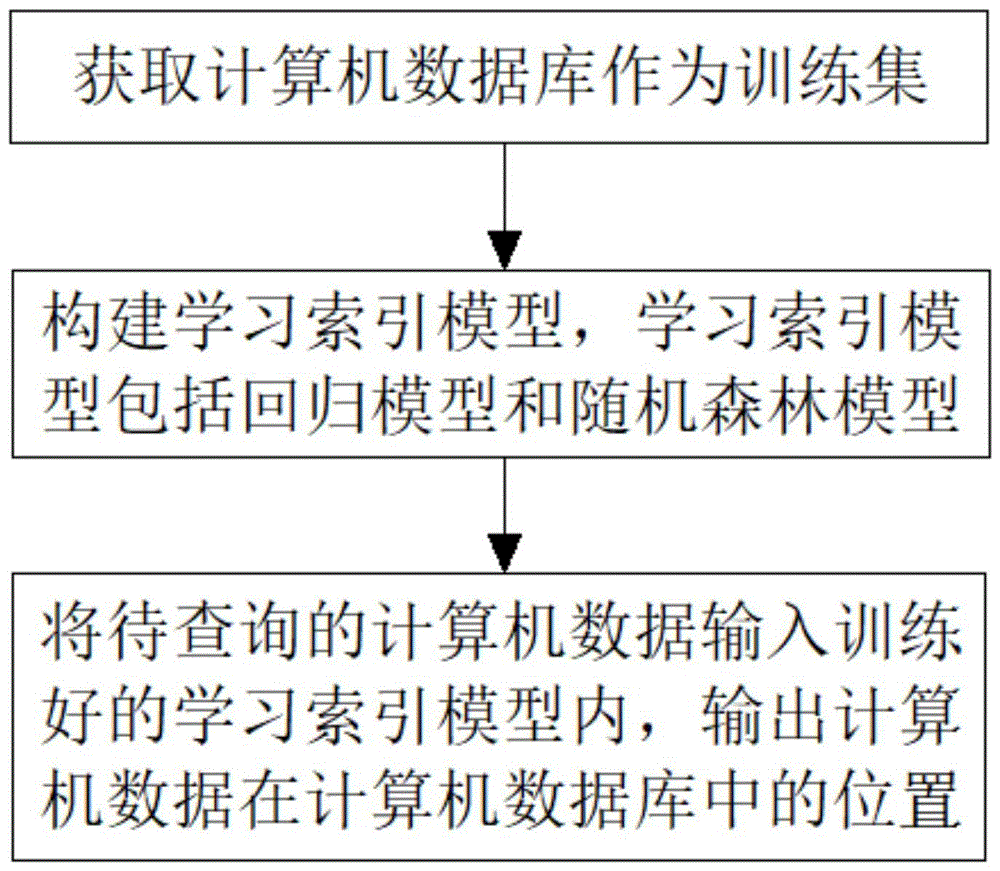
S1、获取计算机数据库作为训练集;
S2、构建学习索引模型,学习索引模型包括回归模型和随机森林模型,利用训练集对学习索引模型进行训练,输入训练数据的键key,输出训练数据在计算机数据库中的位置,得到训练好的学习索引模型;
S3、将待查询的计算机数据输入训练好的学习索引模型内,输出计算机数据在计算机数据库中的位置。
进一步地,S2中回归模型包括线性回归模型,多项式回归模型,弹性回归模型,梯度提升树,极限树。
进一步地,S2中构建学习索引模型,学习索引模型包括回归模型和随机森林模型,利用训练集对学习索引模型进行训练,输入训练数据的键key,输出训练数据在计算机数据库中的位置,得到训练好的学习索引模型,具体过程为:
将训练集中某个训练数据的键key分别输入回归模型的线性回归模型,多项式回归模型,弹性回归模型,梯度提升树,极限树内进行训练,每个回归模型均输出某个训练数据键key在计算机数据库中的位置,即得到训练数据在计算机数据库中的位置;
训练完成后,记录每个回归模型的训练参数,利用打分函数对每个回归模型的输出结果进行打分,选取打分最高的多个回归模型与某个训练数据建立关联,得到每个训练数据及其对应的打分最高的多个回归模型;
利用每个训练数据及其对应的打分最高的多个回归模型对随机森林模型进行训练,利用随机森林模型优化每个回归模型的训练参数,得到每个训练数据对应的最佳回归模型,利用最佳回归模型查找对应训练数据在计算机数据库中的位置,得到训练好的学习索引模型。
进一步地,S2中学习索引模型在训练过程中,记录回归模型索引错误的计算机数据位置E,比较计算机数据正确位置R和错误位置E的相对关系,根据正确位置R和错误位置E的相对关系采用搜索策略对回归模型进行纠错。
进一步地,S2中学习索引模型在训练过程中还包括:自定义索引出错报警阈值,若索引出错概率超出阈值,在索引错误位置的自定义区域内以遍历查找的方式,根据区域内索引错误率最低的原则确定索引正确位置。
一种自动学习索引系统,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如一种自动学习索引方法任一步骤。
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如一种自动学习索引方法任一步骤。
有益效果:
本发明将学习索引看作是一种非层次模型结构,利用回归模型和随机森林模型构建了学习索引模型,在进行计算机数据查询时,从计算机数据的分布角度出发,回归模型会根据计算机数据的特征推荐最佳的回归模型,随机森林模型对最佳的回归模型进行优化与加强,以回归模型作为索引,从而输出计算机数据在计算机数据库中最准确的存储位置。
本发明实现了计算机数据从零开始的索引推荐,在计算机索引的建立过程中,无需人为定义学习索引的层数以及每个节点相应的模型,根据学习索引的回归模型能够自动构建多种索引,且在计算机数据查询时能够快速的得到最佳的索引推荐,降低了计算机索引的时间复杂度、空间复杂度、空间代价和建立难度,减少了计算机索引的建立时间,还提高了计算机数据的查询性能、查询时间和工作运行效率。本发明在维持运行时间稳定的基础上,在空间上比现有研究中的模型节约了大量的空间资源。这使得本发明和现有技术相比,具有更广泛的适用性和更高的灵活性。
附图说明
图1是本发明的流程图;
图2是本发明的结构图;
具体实施方式
具体实施方式一:结合图1-图2说明本实施方式,本实施方式所述一种自动学习索引方法,它包括以下步骤:
S1、获取计算机数据库作为训练集;
S2、构建学习索引模型,学习索引模型包括回归模型和随机森林模型,利用训练集对学习索引模型进行训练,输入训练数据的键key,输出训练数据在计算机数据库中的位置position,得到训练好的学习索引模型,具体过程为:
回归模型包括线性回归模型、多项式回归模型、弹性回归模型、梯度提升树、极限树等。
将训练集中某个训练数据的键key分别输入回归模型的线性回归模型、多项式回归模型、弹性回归模型、梯度提升树、极限树内进行训练,每个回归模型均输出键key在计算机数据库中的位置(键值),即得到训练数据在计算机数据库中的位置position。回归模型学习了计算机数据的分布规律,并有针对性的训练了若干个性能优异、数据分布类型覆盖面广的回归模型。
训练完成后,记录每个回归模型的训练参数,利用打分函数对每个回归模型的输出结果进行打分,选取打分最高的多个回归模型与某个训练数据建立关联,得到每个训练数据及其对应的打分最高的多个回归模型。打分函数由回归模型常见的评估指标得到,例如MSE等,根据打分结果比较各回归模型的训练效果。
利用每个训练数据及其对应的打分最高的多个回归模型对随机森林模型进行训练,利用随机森林模型优化每个回归模型的训练参数,得到每个训练数据对应的最佳回归模型,利用最佳回归模型查找对应训练数据在计算机数据库中的位置,完成了学习索引模型的训练,得到训练好的学习索引模型。
在某种程度上可以将计算机索引视作模型,则B/B+Tree索引可以视作是将计算机数据键映射到已排好序的计算机数据中记录位置的模型;Hash-Maps可以视作将计算机数据键映射到无序的计算机数据中记录位置的模型;位图索引可以视作是判断计算机数据是否存在的模型,若能对计算机索引模型进行优化就能够提高计算机索引在计算机数据集上的执行效率,所以本发明构建了一个学习索引模型,它包括回归模型和随机森林模型,此学习索引模型先通过计算机数据的特征找到其对应的最佳回归模型(最佳索引),无需再用所有的回归模型进行学习训练,根据最佳回归模型(最佳索引)得到计算机数据在计算机数据库中精确的位置,实现计算机数据从零开始的索引推荐,训练过程中不需要人为参与,即可实现计算机索引模型建立的自动化,学习索引模型能够直接根据输入的计算机数据得到最佳索引和在计算机数据库中的准确位置。
本发明利用机器学习技术中的回归模型来反映计算机数据的模式,能够以低成本自动构建针对已知计算机数据集的模式索引,构建的学习索引使用多层次机器学习模型替代传统的索引结构,对于静态数据环境,可以大幅度地降低传统索引的空间代价并提高查询性能。
回归模型自身具有纠错功能。在训练过程中,记录回归模型索引错误的计算机数据位置E,比较计算机数据正确位置R和错误位置E的相对关系,通过在大规模数据集上实验,得到|E-R|≤5。由此可见回归模型索引出错时,计算机数据的正确位置和错误位置非常接近,根据正确位置R和错误位置E的相对关系采用简单的搜索策略就可以实现纠错。在回归模型进行索引时,本发明利用相关实验数据,自定义索引的出错报警阈值,当索引的出错概率超出阈值,在索引预测错误位置的自定义区域内以遍历查找的方式,依据区域内索引错误率最低的原则,确定索引的正确位置position。
S3、将待查询的计算机数据输入训练好的学习索引模型内,根据学习索引模型自动为输入数据选择回归模型,输出计算机数据在计算机数据库中的位置。
具体实施方式二:结合图1-图2说明本实施方式,本实施方式所述一种自动学习索引系统,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如一种自动学习索引方法的任一步骤。
具体实施方式三:结合图1-图2说明本实施方式,本实施方式所述一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如一种自动学习索引方法的任一步骤。