多模态情感交互方法、智能设备、系统、电子设备及介质
文献发布时间:2023-06-19 09:57:26
技术领域
本发明涉及人机情感交互领域,尤其涉及一种多模态情感交互方法、智能设备、系统、电子设备及介质。
背景技术
目前,人口老龄化的全球化趋势十分明显。随着人口老龄化程度加深,出现了越来越多的“空巢老人”家庭,这些老年人在日常生活中不仅面临着无人照顾的情况,而且还会面临着情感无人倾诉的困境,严重影响着老年人的身心健康。
为了解决老年人无人照顾的问题,目前市场上出现了照顾老年人的看护机器人。这些看护机器人虽然可以为老年人的日常生活提供一些护理和照顾,但价格较高且提供的看护功能十分有限,而且也不便于用户(如老年人)升级维护。另外,这些看护机器人往往缺乏多模态情感交互能力,很难与用户建立自然的情感交流,无法正确理解用户真实的情绪状态。
随着人工智能技术和虚拟现实技术的交叉融合发展,如何利用人工智能和虚拟现实技术,及时地针对用户(尤其是老年人用户)的情感交互给予及时、准确地反馈,已经成为当前情感识别交互领域需要解决的一个技术问题。
发明内容
本发明所要解决的第一个技术问题是针对上述现有技术提供一种多模态情感交互方法。
本发明所要解决的第二个技术问题是针对上述现有技术提供一种实现上述多模态情感交互方法的智能设备。
本发明所要解决的第三个技术问题是提供一种应用有上述智能设备的多模态情感交互系统。
本发明所要解决的第四个技术问题是提供一种实现上述多模态交互方法的多模态情感交互系统。
本发明所要解决的第五个技术问题是针对上述现有技术提供一种电子设备。该电子设备包括有存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现所述的多模态情感交互方法。
本发明所要解决的第六个技术问题是针对上述现有技术提供一种可读存储介质。该可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时,实现所述的多模态情感交互方法。
本发明解决第一个技术问题所采用的技术方案为:多模态情感交互方法,其特征在于,包括如下步骤:
多模态情感交互方法,其特征在于,包括如下步骤:
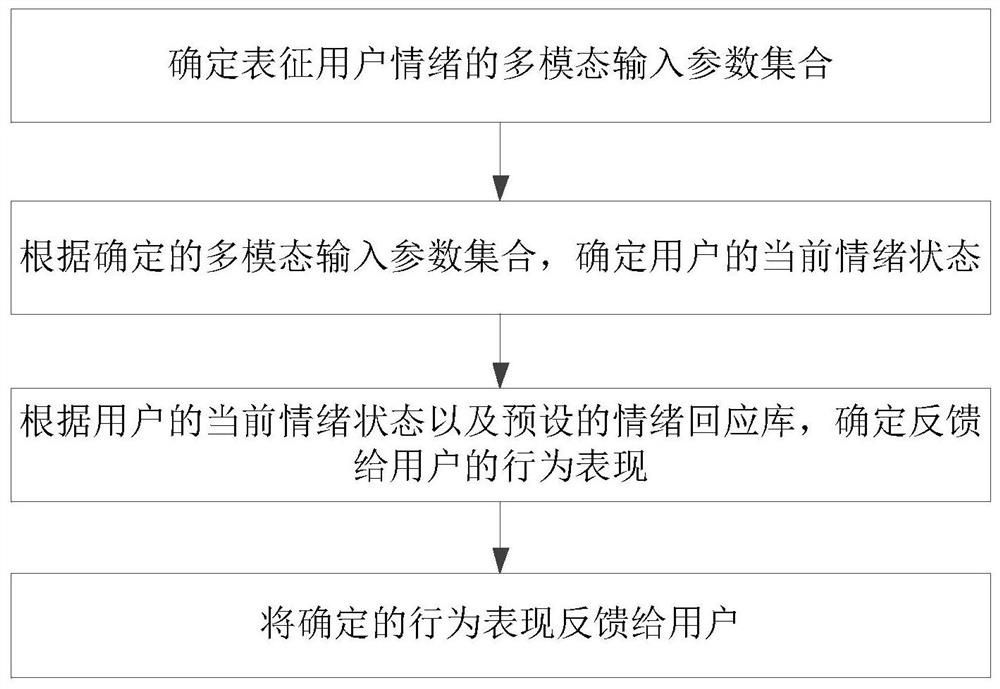
确定表征用户情绪的多模态输入参数集合;其中,多模态输入参数集合至少包括表征用户情绪的面部表情信息、语音对话文本信息和肢体动作信息;
根据确定的多模态输入参数集合,确定用户的当前情绪状态;
根据用户的当前情绪状态以及预设的情绪回应库,确定反馈给用户的行为表现;其中,预设的情绪回应库包括多个预设的情绪状态以及与每一个预设的情绪状态相对应的行为表现,行为表现包括反馈给用户的面部表情、姿态动作、对话文本、对话语音以及音乐音频中的至少一种;
将确定的行为表现反馈给用户;其中,该确定的行为表现由硬件设备或者虚拟智能体反馈给用户。
改进地,在本发明的所述多模态情感交互方法中,所述多模态输入参数集合中的面部表情信息按照如下步骤a1~a3的方式确定得到:
步骤a1,采集用户的面部图像;
步骤a2,根据采集的面部图像,提取得到用户的面部特征参数;
步骤a3,根据所得用户的面部特征参数以及训练好的表情分类器,得到用户的面部表情信息;其中,用户的面部表情信息包括面部表情类型和嘴部动作类型。
再改进地,在本发明的所述多模态情感交互方法中,所述多模态输入参数集合中的语音对话文本信息按照如下步骤b1~b4的方式确定得到:
步骤b1,采集用户的语音文本信息;
步骤b2,根据采集的语音文本信息做出初次判断处理:
当采集的语音文本信息中含有预设的情感词汇时,识别出用户的语音文本信息所对应的情感类型;否则,转入步骤b3;
步骤b3,根据所采集的语音文本信息做出二次判断处理:
当采集的语音文本信息中含有预设的聊天话题词汇时,将该语音文本信息中含有的聊天话题词汇作为用户的语音对话信息,调用预设的聊天话题库;否则,转入步骤b4;
步骤b4,调用预设的闲聊对话库,返回步骤b1。
改进地,在本发明的所述多模态情感交互方法中,所述多模态输入参数集合中的肢体动作信息按照如下步骤c1~c3的方式确定得到:
步骤c1,采集用户的肢体动作数据;其中,用户的肢体动作包括用户的手势动作和手臂动作的至少一种;肢体动作数据为记载有肢体动作的图像或者表征肢体动作的动作参数数据;
步骤c2,根据采集的肢体动作数据,提取得到用户的肢体动作特征参数;
步骤c3,根据所得用户的肢体动作特征参数以及预设的表征用户情绪的肢体动作特征参数,确定用户的肢体动作信息。
进一步地,在本发明的所述多模态情感交互方法中,所述行为表现按照如下步骤d1~d7的方式确定得到:
步骤d1,对所确定用户的当前情绪状态中有无面部表情做出判断:
当用户当前情绪状态中没有面部表情时,转入步骤d2;否则,转入步骤d4;
步骤d2,对所确定用户的当前情绪状态中有无对话语音做出判断:
当用户的当前情绪状态中没有对话语音时,转入步骤d3;否则,转入步骤d5;
步骤d3,向用户发出预设的提问语音,并转入步骤d1;
步骤d4,根据用户的面部表情,确定用户的当前情绪状态;
步骤d5,根据用户的对话语音文本信息,确定用户的当前情绪状态;
步骤d6,对步骤d4和步骤d5分别确定的当前情绪状态做一致性判断:
当两者一致时,转入步骤d7;否则,执行针对两者不一致的应对处理措施;
步骤d7,将位于预设的情绪回应库且与确定的当前情绪状态相对应的行为表现作为反馈给用户的行为表现。
进一步改进,本发明的所述多模态情感交互方法还包括:
设置供用户交互的情感交互场景任务;
确定用户在执行情感交互场景任务时的情绪;
根据所确定用户的情绪,调整情感交互场景任务的难度级别。
本发明解决第二个技术问题所采用的技术方案为:实现所述多模态情感交互方法的智能设备,其特征在于,包括:
多模态输入参数采集模块,采集表征用户情绪的多模态输入参数集合;其中,多模态输入参数集合至少包括表征用户情绪的面部表情信息、语音对话文本信息和肢体动作信息;
处理模块,连接多模态输入参数采集模块,根据确定的多模态输入参数集合,确定用户的当前情绪状态,以及根据所确定用户的当前情绪状态和预设的情绪回应库,确定反馈给用户的行为表现;其中,预设的情绪回应库包括多个预设的情绪状态以及与每一个预设的情绪状态相对应的行为表现,行为表现包括反馈给用户的面部表情、姿态动作、对话文本、对话语音以及音乐音频中的至少一种;
行为表现模块,连接处理模块,将确定的所述行为表现反馈给用户。
进一步地,在本发明的所述智能设备中,所述多模态输入参数采集模块包括:
第一摄像采集单元,连接处理模块,采集用户的面部图像;
第二摄像采集单元,连接处理模块,采集用户的肢体动作图像;
语音采集装置,连接处理模块,采集用户的语音数据。
进一步改进,在该发明的智能设备中,所述行为表现模块包括:
显示单元,连接处理模块,显示与用户当前情绪状态相对应的面部表情;
语音播放装置,连接处理模块,播放与用户当前情绪状态相对应的语音信息;
肢体动作执行装置,连接处理模块,执行与用户当前情绪状态相对应的肢体动作。
本发明解决第三个技术问题所采用的技术方案为:多模态情感交互系统,其特征在于,应用有任一项所述的智能设备。
本发明解决第四个技术问题所采用的技术方案为:多模态情感交互系统,其特征在于,包括:
虚拟智能体生成装置,形成展示给用户的虚拟智能体外形;
多模态输入参数采集模块,采集表征用户情绪的多模态输入参数集合;其中,多模态输入参数集合至少包括表征用户情绪的面部表情信息、语音对话文本信息和肢体动作信息;
处理模块,分别连接虚拟智能体生成装置和多模态输入参数采集模块,根据确定的多模态输入参数集合,确定用户的当前情绪状态,以及根据所确定用户的当前情绪状态和预设的情绪回应库,确定虚拟智能体反馈给用户的行为表现;其中,预设的情绪回应库包括多个预设的情绪状态以及与每一个预设的情绪状态相对应的行为表现,行为表现包括反馈给用户的面部表情、姿态动作、对话文本、对话语音以及音乐音频中的至少一种;
其中,虚拟智能体生成装置根据处理模块确定的所述行为表现做出处理,以由虚拟智能体将所述行为表现反馈给用户。
本发明解决第五个技术问题所采用的技术方案为:电子设备,其特征在于,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现任一项所述的多模态情感交互方法。
本发明解决第六个技术问题所采用的技术方案为:可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时,实现任一项所述的多模态情感交互方法。
与现有技术相比,本发明的优点在于:
首先,该发明中的多模态情感交互方法通过多通道分别采集表征用户情绪的多种模态参数(如面部表情信息、语音对话文本信息和肢体动作信息),再通过对所采集的这些多模态参数做融合处理,全面准确得到用户的当前面部情绪,避免了传统情感交互方法仅仅基于单通道所采集用户模态参数(诸如仅仅通过面部表情信息)来识别用户情绪时的不准确、容易误判的缺陷和不足;
其次,该发明中的多模态情感交互方法结合了虚拟现实技术,引入了“虚拟智能体”这一特定对象,在多模态情感交互过程中,虚拟智能体可以准确地“感知”到用户的当前情绪,并且还可以针对用户的当前情绪做出诸如面部表情、语音对话和肢体动作等方面的行为表现反馈,满足用户情绪体验需求,尤其是老年人用户独处时的聊天和情感交互需要,而且整个情感交互场景可以模拟日常生活情景;
最后,该发明的多模态情感交互方法充分考虑不同用户在情感交互时的差异性,通过预设情感交互场景任务,且根据用户执行预设情感交互场景任务过程中的情绪调整情感交互的难度,从而可以更好地满足不同用户针对人机交互过程中的个性化需求。
附图说明
图1为本发明实施例中的多模态情感交互方法流程示意图;
图2为本发明实施例的多模态输入参数集合中的面部表情信息确定流程示意图;
图3为本发明实施例的多模态输入参数集合中的语音对话文本信息确定流程示意图;
图4为本发明实施例的多模态输入参数集合中的肢体动作信息确定流程示意图;
图5为本发明实施例的智能设备的主要组成部件连接示意图;
图6为本发明实施例中的一种多模态情感交互系统示意图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
参见图1所示,本实施例提供一种多模态情感交互方法,实现与用户的情感交互。具体地,该实施例的多模态情感交互方法包括如下步骤1~4:
步骤1,确定表征用户情绪的多模态输入参数集合;其中,多模态输入参数集合至少包括表征用户情绪的面部表情信息、语音对话文本信息和肢体动作信息;在该实施例中,表征用户情绪的面部表情信息为高兴、恐惧、惊奇、悲伤、厌恶和愤怒这6种面部表情;表征用户情绪的语音对话文本信息可以是含有情感词汇的语音或者含有聊天话题词汇的语音;表征用户情绪的肢体动作信息可以是手势形状和手臂运动状态;其中:
在该实施例中,参见图2所示,多模态输入参数集合中的面部表情信息按照如下步骤a1~a3的方式确定得到:
步骤a1,采集用户的面部图像;例如,此处优选采集用户面部的正面图像;
步骤a2,根据采集的面部图像,提取得到用户的面部特征参数;比如说,在所采集到的用户面部的正面图像中,用户嘴部所展现的情况为“张嘴”或者“撇嘴”,那么就将“张嘴”和“撇嘴”所对应的图像特征分别作为用户的一个面部特征参数;
步骤a3,根据所得用户的面部特征参数以及训练好的表情分类器,得到用户的面部表情信息;其中,用户的面部表情信息包括面部表情类型和嘴部动作类型。假设,该实施例将“撇嘴”所对应的图像特征作为表征用户“厌恶”的情绪,那么,在提取到用户的面部特征参数为“撇嘴”时,就得到用户的面部表情信息为“厌恶”。
在该实施例中,参见图3所示,多模态输入参数集合中的语音对话文本信息按照如下步骤b1~b3的方式确定得到:
步骤b1,采集用户的语音文本信息;
步骤b2,根据采集的语音文本信息做出初次判断处理:
当采集的语音文本信息中含有预设的情感词汇时,识别出用户的语音文本的情感类型;否则,转入步骤b3;其中,预设的情感词汇可以是“生气”、“讨厌”、“喜好”或者“高兴”等日常生活沟通交流中常见的情感词汇;
步骤b3,根据所采集的语音文本信息做出二次判断处理:
当采集的语音文本信息中含有预设的聊天话题词汇时,将该语音文本信息中含有的聊天话题词汇作为用户的语音对话信息,调用预设的聊天话题库;否则,转入步骤b4;其中,预设的聊天话题词汇可以根据需要设置,比如此处的聊天话题词汇可以是“健康养生”、“老年医疗保健”或者“老年休闲运动”等日常生活沟通交流中常见的聊天话题词汇。
步骤b4,调用预设的闲聊对话库,返回步骤b1。其中,该实施例中预设的闲聊对话库可以是一些针对闲聊的话题词汇。
在该实施例中,参见图4所示,多模态输入参数集合中的肢体动作信息按照如下步骤c1~c3的方式确定得到:
步骤c1,采集用户的肢体动作数据;其中,用户的肢体动作包括用户的手势动作和手臂动作;肢体动作数据为记载有肢体动作的图像;比如说,采集到的用户的一个肢体动作图像记载有用户“挥手”的动作;
步骤c2,根据所采集的肢体动作数据,提取得到用户的肢体动作特征参数;例如,根据所采集的肢体动作图像中的“挥手”动作,提取得到用户的手臂与胳膊之间所形成的弯折角度;
步骤c3,根据所得用户的肢体动作特征参数以及预设的表征用户情绪的肢体动作特征参数,得到用户的肢体动作信息。假设,预先设置上述的弯折角度为θ,那么,一旦在肢体动作图像中提取到了弯折角度θ,就认定该用户的肢体动作信息为“挥手”动作。
步骤2,根据确定的多模态输入参数集合,确定用户的当前情绪状态;
假设在该实施例中,当经过步骤1的处理,确定用户的面部表情为“张嘴”、语音对话信息中含有“情感词汇”和“聊天话题词汇”以及肢体动作信息中存在有预设的肢体动作信息时,此处就判定该用户的当前情绪为“高兴”;其中,该实施例会提前建立用户的多模态输入参数集合与对应各多模态输入参数集合的情绪之间的预设情绪列表;
步骤3,根据用户的当前情绪状态以及预设的情绪回应库,确定反馈给用户的行为表现;其中,预设的情绪回应库包括多个预设的情绪状态以及与每一个预设的情绪状态相对应的行为表现,行为表现包括反馈给用户的面部表情、姿态动作、对话文本、对话语音以及音乐音频中的至少一种;面部表情可以伴随有眨眼和皱眉头等动作;对话文本是带有词汇的日常对话文本,对话语音也可以是带有词汇的日常对话语音,音乐音频可以是针对不同类型情绪的音乐数据。
在该实施例中,所述行为表现按照如下步骤d1~d7的方式确定得到:
步骤d1,对所确定用户的当前情绪中有无面部表情做出判断:
当用户当前情绪中没有面部表情时,转入步骤d2;否则,转入步骤d4;
步骤d2,对所确定用户的当前情绪中有无对话语音做出判断:
当用户的当前情绪中没有对话语音时,转入步骤d3;否则,转入步骤d5;
步骤d3,向用户发出预设的提问语音,并转入步骤d1;
步骤d4,根据用户的面部表情,确定用户的当前情绪状态;
步骤d5,根据用户的对话语音文本信息,确定用户的当前情绪状态;
步骤d6,对步骤d4和步骤d5分别确定的当前情绪状态做一致性判断:
当两者一致时,转入步骤d7;否则,执行针对两者不一致的应对处理措施;例如,此处的应对处理措施为执行针对两者不一致的对话引导,通过后续的对话来确认用户的情绪类型。
步骤d7,将位于预设的情绪回应库且与确定的当前情绪状态相对应的行为表现作为虚拟智能体反馈给用户的行为表现。此处的“回应”可以是显示面部表情或者展示执行的肢体动作或者反馈对话语音或者显示面部表情、展示执行的肢体动作以及反馈对话语音中的任意结合。
步骤4,将确定的行为表现由虚拟智能体反馈给用户。此处的虚拟智能体可以是通过投射设备投射出来的虚拟人物模型或者虚拟动物模型。当然,该虚拟智能体也可以是由显示屏所显示出来的虚拟人物模型或者虚拟动物模型。此处需要说明的是,本领域技术人员熟知,人工智能技术的应用在于部署各种智能体的应用,智能体(agents)是人工智能领域的核心概念,智能体是具有自主决策能力的智能单元。而此处的虚拟智能体(intelligent virtual agents)是智能体概念在虚拟现实领域中的延伸。虚拟智能体是具有自主行为的类人型图形化实体,用以模拟人或者其他生命体。它具有内在的认知结构设计,具有自主行为和情绪能力。
另外,也可以根据实际的需要,将确定的行为表现由类似看护机器人的这种实体硬件设备反馈给用户。
在实际的情况中,还可以根据需要,在该实施例的多模态情感交互方法中设置情感交互场景,以增强用户的情感交互体验。例如,该实施例的多模态情感交互方法可以包括如下步骤:
设置供用户交互的情感交互场景任务;其中,情感交互场景可以是客厅聊天场景或者室内健身运动场景等日常生活中的常见场景;
确定用户在执行情感交互场景任务时的情绪;其中,用户在执行情感交互场景任务时的情绪可以利用步骤1和步骤2的方式确定得到;
根据所确定用户的情绪,调整情感交互场景任务的难度级别。比如说,在用户执行完毕客厅聊天场景交互任务时,确定到用户的情绪为“高兴”,那么就继续增大情感交互场景任务的难度级别;在用户执行完毕客厅聊天场景交互任务时,确定到用户的情绪为“厌恶”,那么就降低情感交互场景任务的难度级别。
该实施例提供了一种实现上述多模态情感交互方法的智能设备。参见图5所示,该智能设备包括多模态输入参数采集模块11、处理模块12和行为表现模块13,多模态输入参数采集模块1包括第一摄像采集单元111、第二摄像采集单元112和语音采集装置113,第二摄像采集单元112采用Kinect深度相机,第一摄像采集单元111、第二摄像采集单元112和语音采集装置113分别连接处理模块12,行为表现模块13包括显示单元131、语音播放装置132和肢体动作执行装置133,显示单元131、语音播放装置132和肢体动作执行装置133分别连接处理模块12。其中:
第一摄像采集单元111采集用户的面部图像,以得到表征用户情绪的面部表情信息;
第二摄像采集单元112采集用户的肢体动作图像,以得到表征用户情绪的肢体动作信息;
语音采集装置113采集用户的语音数据,尤其是对话时的语音数据,以得到表征用户情绪的语音对话信息;
处理模块2,连接多模态输入参数采集模块11,根据确定的多模态输入参数集合,确定用户的当前情绪状态,以及根据所确定用户的当前情绪状态和预设的情绪回应库,确定反馈给用户的行为表现;其中,预设的情绪回应库包括多个预设的情绪状态以及与每一个预设的情绪状态相对应的行为表现,行为表现包括反馈给用户的面部表情、姿态动作、对话文本、对话语音以及音乐音频中的至少一种;
行为表现模块13将处理模块2确定的所述行为表现对应的反馈给用户。具体地:
显示单元131,至少显示与用户当前情绪状态相对应的面部表情,将该面部表情展示给用户;
语音播放装置132,至少播放与用户当前情绪状态相对应的语音信息,将该语音信息反馈给用户;
肢体动作执行装置133,至少执行与用户当前情绪状态相对应的肢体动作,将该肢体动作展示给用户。该智能设备可以根据需要做成各种形状。例如,可以是动物的形状、人体的形状或者其他所需要的形状。
另外,该实施例提供了一种多模态情感交互系统,该多模态情感交互系统应用有上述的智能设备。
不仅如此,该实施例也提供了另外一种多模态情感交互系统。参见图6所示,该多模态情感交互系统包括虚拟智能体生成装置10’、多模态输入参数采集模块11’和处理模块12’,虚拟智能体生成装置10’和多模态输入参数采集模块11’分别连接处理模块12’。其中:
虚拟智能体生成装置10’,形成展示给用户的虚拟智能体外形;
多模态输入参数采集模块11’,采集表征用户情绪的多模态输入参数集合;其中,多模态输入参数集合至少包括表征用户情绪的面部表情信息、语音对话文本信息和肢体动作信息;此处的多模态输入参数采集模块11’与图5中所示的多模态输入参数采集模块11具有相同的组成部件;
处理模块12’,分别连接虚拟智能体生成装置10’和多模态输入参数采集模块11’,根据确定的多模态输入参数集合,确定用户的当前情绪状态,以及根据所确定用户的当前情绪状态和预设的情绪回应库,确定上述虚拟智能体反馈给用户的行为表现;其中,预设的情绪回应库包括多个预设的情绪状态以及与每一个预设的情绪状态相对应的行为表现,行为表现包括反馈给用户的面部表情、姿态动作、对话文本、对话语音以及音乐中的至少一种;
其中,虚拟智能体生成装置10’根据处理模块12’确定的所述行为表现做出处理,以由其形成的虚拟智能体将所述行为表现反馈给用户。
此处的虚拟智能体生成装置10’可以是一种投射设备,该投射设备(即虚拟智能体生成装置10’)可以投射出虚拟智能体动态形象(虚拟人物模型或者虚拟动物模型);当然,虚拟智能体生成装置10’也可以根据需要采用显示屏,由显示屏把形成的虚拟智能体(如虚拟人物模型或者虚拟动物模型)展示给用户。
例如,经过处理模块12’的处理,确定反馈给用户当前情绪的行为表现为:面部表情是“高兴”、语音对话是“祝您生日快乐”以及肢体动作是“挥手”,那么,虚拟智能体生成装置10’就把该行为表现做处理,然后由其形成的虚拟智能体表现出“高兴”的面部表情、发出“祝您生日快乐”的语音(实际为语音播放装置播放)以及展示出“挥手”的肢体动作。
当然,该实施例还提供了一种电子设备。该电子设备包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,该处理器执行计算机程序时,实现上述的多模态情感交互方法。电子设备可以是计算机或者其他设备。
不仅如此,该实施例也提供了一种可读存储介质。具体地,该可读存储介质上存储有计算机程序,该计算机程序被处理器执行时,实现上述的多模态情感交互方法。此处的可读存储介质可以包括:通用串行总线闪存盘(USB,Universal Serial Bus flash drive)、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random AccessMemory)、磁碟或者光盘等各种可以存储程序代码的存储介质。
本发明实施例中的各功能单元可以集成在一个处理单元中,或者各个单元也可以均是独立的物理模块。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实施例的技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备,例如可以是个人计算机、服务器或者网络设备等,或处理器执行本发明各个实施例所述方法的全部或部分步骤。
计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
在本发明所提供的实施例中,应该理解到,所揭示的系统、设备和方法,也可以通过其它方式实现。以上所描述的实施例仅仅是示意性的。流程图或框图中的每个方框可以代表一个模块、程序段或代码的一部分,上述模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
尽管以上详细地描述了本发明的优选实施例,但是应该清楚地理解,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 多模态情感交互方法、智能设备、系统、电子设备及介质
- 多模态情感交互方法、智能设备、系统、电子设备及介质