一种基于改进图卷积网络的图像生成方法
文献发布时间:2023-06-19 10:08:35
技术领域
本发明属于图像处理领域,具体而言,是一种基于改进图卷积网络的图像生成方法。
背景技术
计算机视觉包括图像生成、语义分割、目标检测等诸多领域,其中通过自然语言描述引导图像生成一直都是图像生成领域的挑战性任务,近年来,深度学习的出现,促进了自然语言描述引导图像生成的发展,并且已经得到了很大的进展。
现阶段,生成对抗网络(Generative Adversarial Network,GAN)在图像生成领域已经得到广泛应用。由文本描述引导图像生成是近几年的热门研究领域,其主要的任务就是通过一段文本描述生成一张与描述内容相互对应的图片。由文本描述引导图像生成方法主要是利用生成对抗网络的原理来完成图像的生成工作。
起初,Reed等人提出GAN-INT-CLS网络,GAN-INT-CLS是以条件生成对抗网络(Conditional Generative Adversarial Networks,CGAN)为模型主干,将文本描述编码为全局向量作为生成器和鉴别器的约束,GAN-INT-CLS有效地生成了分辨率为64x64的可信赖图像,但是图像缺少生动的对象细节。随后,Zhang等人为了生成高分辨率的图像,提出了分阶段的堆栈生成对抗网络(Stacked Generative Adversarial Networks,StackGAN)模型,StackGAN的训练策略是先通过文本描述生成包含基本形状、颜色的64x64低分辨率图像,再利用生成的低分辨率图像和文本描述修补丢失的细节信息,最后生成256×256高分辨率图像。在后续工作中,Zhang等人提出了端到端的堆栈生成对抗网络(StackGAN-v2),StackGAN-v2将生成对抗网络扩展成树状结构,利用多个生成器和多个鉴别器进行并行训练,稳定地完成不同分辨率(如64x64,128x128,256x256)的图像的生成。继StackGAN-v2之后,Xu等人又在此基础之上提出了注意生成对抗网络(Attentional GenerativeAdversarial Networks,AttnGAN),AttnGAN在StackGAN-v2的基础上增加了注意力机制,着重关注文本描述中的相关单词,并将其编码为单词向量输入到网络模型中,生成器和鉴别器针对最相关的单词向量进行精准优化,有效地生成了256x256高质量图像。然而,AttnGAN在处理多个交互对象的复杂场景时,就会显得十分困难。而后,Johnson等人提出了一种利用场景图生成图像的模型(Sg2im)。Sg2im通过场景图推断出对象以及其关系,将所获得的对象及其关系预测出对象的边界框和分割掩模,得到一个关于文本描述的场景布局,接着将场景布局输入到后续的生成网络中生成相互对应的图像。在复杂场景下,Sg2im生成的图像更能反映文本描述内容。但是结果中存在伪影、对象重叠、对象缺失等问题。
为了进一步解决生成图像中伪影、对象重叠、对象缺失的问题,本发明在从场景图生成图像的网络模型的基础上提出了一种结合场景描述的生成对抗网络模型。该模型引入了布局鉴别器,重点关注场景布局与图像之间的差距,弥合此差距,预测出更真实的场景布局,缓解生成图像中出现伪影、对象缺失的现象。同时引入掩模生成网络对数据集进行预处理,生成对象分割掩模向量,使用对象分割掩模向量作为约束,通过描述文本训练布局预测网络,更精确地预测出各个对象在场景布局具体的位置和大小,改善生成的图像中出现多个对象相互重叠的现象,提高生成图像的质量。
发明内容
本方法为了克服现有方法忽略同一句子中不同目标之间的依存关系的不足,提出了一个基于多目标依存建模的图卷积网络模型。模型首先对输入文本进行语义编码,再通过GCN、attention层得到目标的隐层表示,最后再对多个目标之间的依存建模,得到目标的最终表示。
本发明的技术方案:
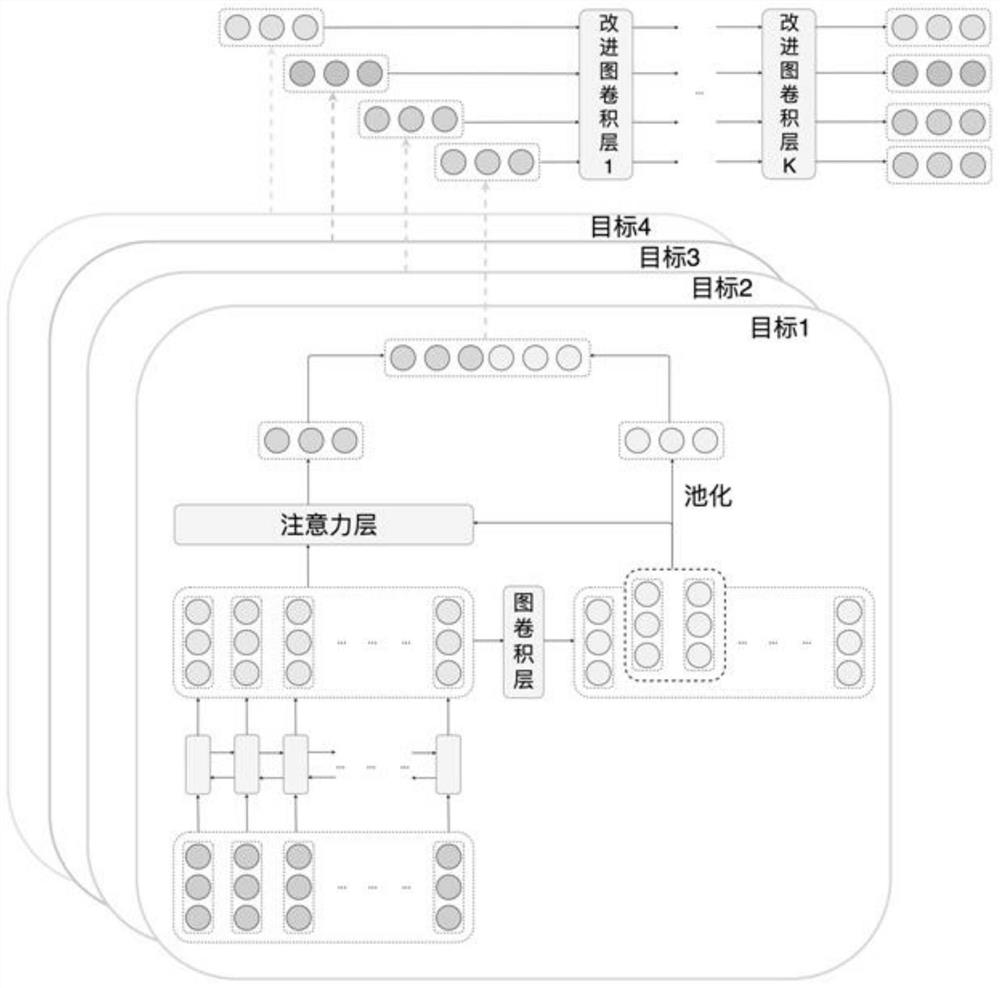
一种基于改进图卷积网络的图像生成方法,本方法中的模型总体框架图如图1所示,本方法包含以下步骤:
步骤1:建立输入层
在输入层中,利用预训练好的词向量将句子中的单词映射成一个低维、连续的词向量。具体如下:
模型首先利用预训练好的词向量将一个句子
步骤2:建立Bi-LSTM层
Bi-LSTM由正向LSTM和反向LSTM组成,将正向LSTM输出和反向LSTM输出进行拼接得到Bi-LSTM层。在步骤1得到句子的词向量表示后,将词向量
将正向LSTM输出和反向LSTM输出进行拼接后得到Bi-LSTM层的输出向量组
步骤3:构建目标向量的隐层表示
首先通过GCN层,在句法上,来混合目标与句子中其他词的信息。再使用注意力机制来计算与目标相关的上下文表示,最后将GCN层的目标向量池化后与注意力层的输出拼接得到目标向量的隐层表示。
步骤4:构建MDGCN层
首先根据依存句法树构建句子的多目标依存图,在根据多目标依存图生成邻接对称矩阵,再对邻接对称矩阵归一化后,使用图卷积网络对同一句子的多个目标进行建模。
步骤5:建立输出层
用一个全连接层将输出最终表示转换维度,再通过softmax函数将其转换为概率表示,实现如下:
其中,p
步骤6:模型训练
模型使用交叉熵误差函数和L2权重衰退共同作为损失函数,实现如下:
其中p
步骤7:图像生成
利用步骤6训练好的模型进行图像的生成。
作为本发明的进一步限定,所述步骤3中的构建目标向量的隐层表示过程如下:
步骤3-1:建立GCN层
首先构建句子的依存句法树,依存句法树上每一个词都与该词句法上有联系的词相连接,再根据依存句法树构建邻接对称矩阵A
其中,
由于目标的依存性是由其周边词决定,其本身并不包含依存性,所以将目标置为零向量,方便目标下一步混合在句法上有联系的词的信息,公式如下:
给出邻接对称矩阵
其中,
步骤3-2:建立注意力层
使用注意力机制来计算与目标相关的上下文表示,给出H
其中,
步骤3-3:池化与拼接
为了能使结果更为准确,提升目标表示的准确性,本方法充分利用模型中间向量值,将
h
作为本发明的进一步限定,所述步骤4中的建立MDGCN层的过程如下:
步骤4-1:构建多目标依存图
同一个句子中可能存在多个目标,考虑到目标之间可能存在联系,本方法提出多目标依存图来表示目标之间的关系,通过对目标之间情感依存性的处理,使情感预测更为准确。
多目标依存图由该句的依存句法树转换而来,由于目标通常是由多个词组成的短语,为了选定一个词来代表整个短语,本方法选择将由短语生成的依存句法树中的根节点词,来代表整个短语,多目标依存图中的节点仅保留了依存句法树中的目标的根节点词,图中的边存在权重,其值由依存句法树中相对应点之间的距离决定。
之后再构建多目标依存图的邻接对称矩阵A
最后再对A
其中,
步骤4-2:建立MDGCN层
得到多目标依存图后,给出邻接对称矩阵
其中
本发明采用以上技术方法与现有技术方法相比,具有以下优势:
(1)根据句子的依存句法树,构建多目标依存图来表示目标之间的关系。
(2)提出一个全新的改进图卷积模型来建模同一句中多个目标之间的依存关系。
(3)通过割断多目标依存图中不同权重的边来提高结果准确性。
实验结果表示,本方法相比标准图卷积网络模型结果有显著提高。
附图说明
图1是本发明方法的模型整体框架图。
图2是依存句法树转换为多目标依存图的一个例子。
具体实施方式
为了验证本方法的有效性,在Visual Genome数据集上进行实验,本方法采用IS(Inception score)和FID(Fréchet Inception Distance)为定量评估指标,其中IS评估指标主要是衡量模型生成图像的多样性,IS值越大,生成图像的多样性越好;FID评估指标主要是衡量模型生成图像的质量,FID值越小,生成图像的质量越好。本方法词向量均采用预训练好GloVe词向量,向量维度选取d=300,所有不在词向量字典中的词,均随机初始化[-1,1]间均匀分布的300维词向量。
步骤1:建立MDGCN模型
步骤2:训练MDGCN模型
设定超参数,将训练集输入到MDGCN模型,得到损失函数值,再反向传播得到梯度,通过梯度值更新参数,经过设置的迭代次数的迭代之后,得到训练好的MDGCN模型。
步骤2-1:将训练集中的句子读到内存中,作为embedding层的输入
步骤2-2:设定dropout=0.5,学习率η=0.01,用来控制模型的学习进度
步骤2-3:设定最小化交叉熵误差函数,
步骤2-4:设定迭代次数epoches,开始迭代训练
步骤2-5:计算训练数据集,在当前迭代次数i下,训练得到模型的损失函数值E
步骤2-6:模型权重参数更新,采用SGD的方式更新,
步骤2-7:判断迭代是否结束,若i 步骤3:预测 MDGCN模型完成训练后,将要预测的测试集输入模型,即可得到IS和FID值。数据集Visual Genome在MDGCN模型的IS、FID值及和其他模型的IS、FID对比如表1所示。从表1可以看出,本发明方法的IS和FID值好于其他方法,说明了本发明的有效性。 表1不同方法的结果比较
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于改进图卷积网络的图像生成方法
- 一种基于层级图卷积网络的群体场景图生成方法