一种基于卷积神经网络的高清视频人脸对齐的方法
文献发布时间:2023-06-19 10:27:30
技术领域
本发明涉及人脸对齐技术领域,具体为一种基于卷积神经网络的高清视频人脸对齐的方法。
背景技术
卷积神经网络(Convolutional Neural Networks,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一,卷积神经网络具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类,因此也被称为“平移不变人工神经网络;
近些年大部分的高清视频人脸对齐方法都和普通图片的识别方法类似,都是基于形状索引特征,在这类方法中图片特征或者经过机器学习转换得到特征都是从围绕着特征点区域片段中抽取计算得到的,然后这些特征被反复用在这些特征点位置的微调,这种方法在普通照片上可能还行,但在高清照片或者视频上其效率非常低下,并且效果也很差,这是因为在高清照片或者视频中获得这些片段无法给出足够的信息,导致信息不全面,所以往往会训练获得局部最优点,而不是整体最优点,这样带来的问题影响整个模型的效率和效果。
发明内容
本发明提供一种基于卷积神经网络的高清视频人脸对齐的方法,可以有效解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种基于卷积神经网络的高清视频人脸对齐的方法,包括如下步骤:
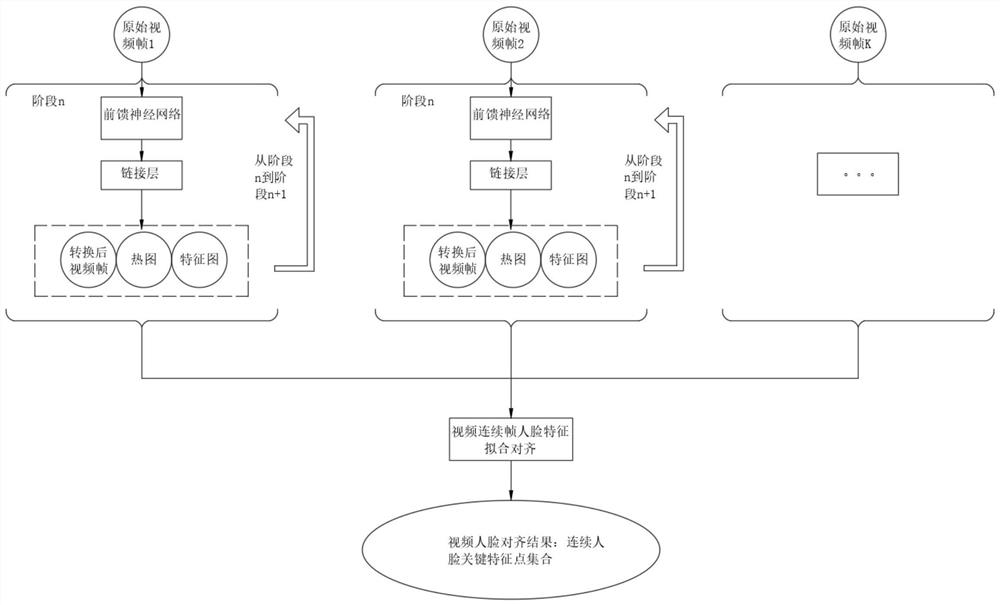
S1、处理过程的每个阶段分成以下步骤,这个过程会执行关键特征点的位置估计和全连接网络的下一阶段输入数据准备;
S2、从最初的第一个阶段开始,之后经过n轮计算,每一轮都进一步微调上一轮得到最新关键特征点位置,通过可视化引入热图和特征图,我们在每一阶段都保持传递了关键信息;
S3、视频每一帧的关键特征点位置确定后,根据时间线拟合整个视频的连续帧的特征点的连续位置;
S4、检验对齐全视频人脸关键点特征位置,输出用于各类该视频人脸处理用途。
根据上述技术方案,所述S1中还包括如下步骤:
a、在当前阶段,通过前馈神经网络的估值计算得到转换增量,并进一步计算得到帧图片转换矩阵和关键特征点转换矩阵;
b、使用图片转换矩阵转换原始视频帧图片,得到这个执行阶段的转换过的视频帧图片;
c、使用关键特征点转换矩阵转换当前阶段的关键特征点位置,得到这个执行阶段的转换过的关键特征点位置;
d、通过计算步骤c中得到的特征点位置,得到当前步骤的可视化热图输出;
e、通过当前执行阶段的全连接网络获得下个阶段所要使用的特征图;
f、转换后的视频帧图片、热图和特征图都作为下一阶段要用到的输入,通过链接层进入下个阶段。
与现有技术相比,本发明的有益效果:本发明结构科学合理,使用安全方便,本方法分成多个局部阶段,每个n+1阶段改进人脸关键点的位置都是基于第n个阶段,也就是上一个阶段,我们在所有阶段中,都用到了完整的人脸帧或图片,与只依赖于局部片段区域的识别方法有很大的区别,关键点热图提供了通过可是化的方式提供了方法中前序阶段所提取得到的关键点位置信息,这使得整个全画幅处理过程成为可能,因为保持使用整张脸的画幅,而不是局部特征位置片段,使得这个方法能够处理差异化很大的人脸视频帧或高清图片,比如头的摆放位置,高难度的起始状态等,这能够大幅降低人脸特征点提取与对齐过程中错误率。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是本发明的方法步骤结构示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例:如图1所示,本发明提供技术方案,一种基于卷积神经网络的高清视频人脸对齐的方法,包括如下步骤:
S1、处理过程的每个阶段分成以下步骤,这个过程会执行关键特征点的位置估计和全连接网络的下一阶段输入数据准备;
S2、从最初的第一个阶段开始,之后经过n轮计算,每一轮都进一步微调上一轮得到最新关键特征点位置,通过可视化引入热图和特征图,我们在每一阶段都保持传递了关键信息;
S3、视频每一帧的关键特征点位置确定后,根据时间线拟合整个视频的连续帧的特征点的连续位置;
S4、检验对齐全视频人脸关键点特征位置,输出用于各类该视频人脸处理用途。
根据上述技术方案,S1中还包括如下步骤:
a、在当前阶段,通过前馈神经网络的估值计算得到转换增量,并进一步计算得到帧图片转换矩阵和关键特征点转换矩阵;
b、使用图片转换矩阵转换原始视频帧图片,得到这个执行阶段的转换过的视频帧图片;
c、使用关键特征点转换矩阵转换当前阶段的关键特征点位置,得到这个执行阶段的转换过的关键特征点位置;
d、通过计算步骤c中得到的特征点位置,得到当前步骤的可视化热图输出;
e、通过当前执行阶段的全连接网络获得下个阶段所要使用的特征图;
f、转换后的视频帧图片、热图和特征图都作为下一阶段要用到的输入,通过链接层进入下个阶段。
与现有技术相比,本发明的有益效果:本发明结构科学合理,使用安全方便,本方法分成多个局部阶段,每个n+1阶段改进人脸关键点的位置都是基于第n个阶段,也就是上一个阶段,我们在所有阶段中,都用到了完整的人脸帧或图片,与只依赖于局部片段区域的识别方法有很大的区别,关键点热图提供了通过可是化的方式提供了方法中前序阶段所提取得到的关键点位置信息,这使得整个全画幅处理过程成为可能,因为保持使用整张脸的画幅,而不是局部特征位置片段,使得这个方法能够处理差异化很大的人脸视频帧或高清图片,比如头的摆放位置,高难度的起始状态等,这能够大幅降低人脸特征点提取与对齐过程中错误率。
最后应说明的是:以上仅为本发明的优选实例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于卷积神经网络的高清视频人脸对齐的方法
- 一种基于多约束条件卷积神经网络的密集人脸对齐方法