一种基于语言模型的医疗实体零样本分类方法
文献发布时间:2023-06-19 10:41:48
技术领域
本发明涉及一种实体分类技术,尤其涉及一种基于语言模型的医疗实体零样本分类方法。
背景技术
医疗健康领域信息抽取与人们的生活息息相关,随着科技的发展,医疗文本数量急剧增加,仅靠人力已远远无法满足医疗实体识别的需求。因此,医疗文本中的医疗实体分类,成为目前医疗健康领域的热点问题。医疗实体分类是理解语言的重要一步,医疗实体分类结果的好坏,对后续的问答系统等自然语言处理任务的结果有着很大的影响。医疗实体分类任务的目标是给定一个实体以及其所在医疗文本的上下文,把该实体分类到预先定义好的分类体系之中。
近年来随着深度学习技术取得的重大突破,相关的技术被广泛应用于自然语言处理领域(NLP,Natural Language Processing)中,例如BiLSTM+CRF、BERT等。但是,目前大多实体分类问题都需要大量的训练语料来训练模型,而语料的标注质量,语料的多少都很大程度上影响了训练后模型的准确性。另一方面,预料的标注也是一个费时费力的活。
发明内容
针对现有技术中的实体分类方案中所存在的不足,本发明提供了一种基于语言模型的医疗实体零样本分类方法,只需要训练医疗领域的bert模型,就可实现不需要标注实体分类训练语料的零样本的实体分类。
本发明采用以下技术方案:
一种基于语言模型的医疗实体零样本分类方法,包括如下步骤:
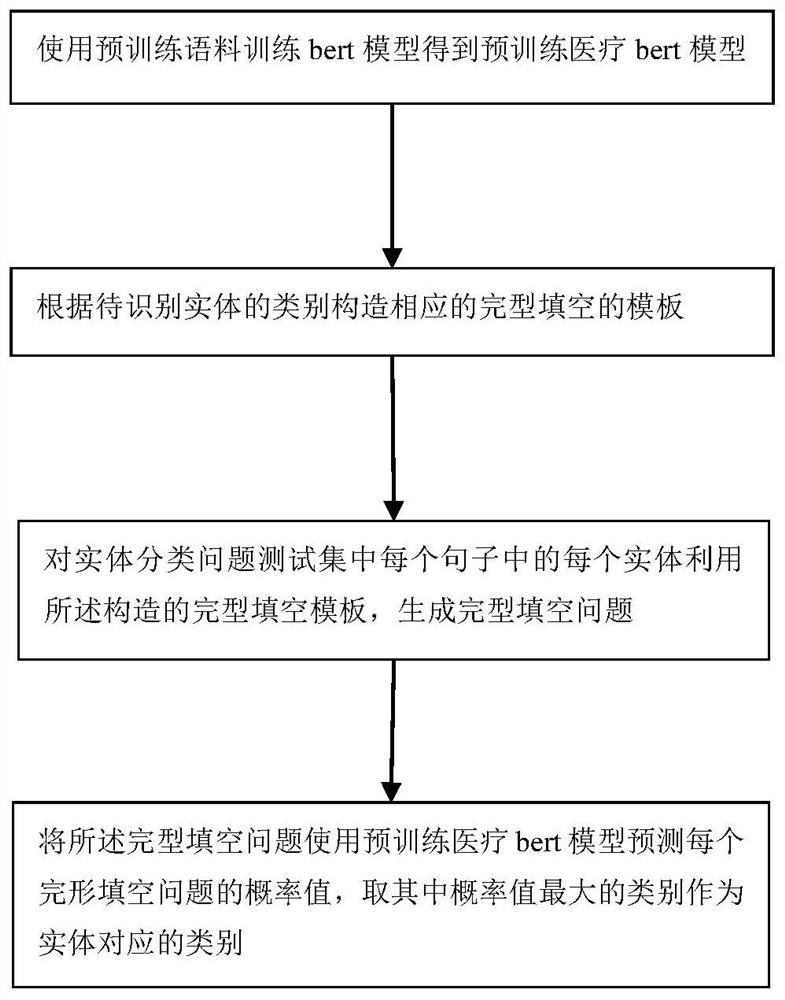
S1:使用预训练语料训练bert模型得到预训练医疗bert模型;
S2:根据待识别实体的类别构造相应的完型填空的模板;
S3:对实体分类问题测试集中每个句子中的每个实体利用所述构造的完型填空模板,生成完型填空问题;
S4:将所述完型填空问题使用预训练医疗bert模型预测每个完形填空问题的概率值,取其中概率值最大的类别作为实体对应的类别。
具体的,S1中预先训练医疗bert模型包括如下步骤:
S11:准备预训练bert模型需要的语料以及对应的词典,读取每个文件,对每篇文章进行正则分句后存储到texts列表中。对于texts中的每一个text,使用jieba分词进行分词处理,得到分词结果words列表,为每个词对应的生成一个0~1之间的随机数。遍历所有的words,对word使用bert分词器按词典中存在的字符分成更小的字符即:word_tokens,并得到对应词典中的word_token_ids,把word_token_ids追加到该单句的token_ids中。设置mask_rate=0.15,比较该word的rand值与mask_rate的大小。如果rand值大于或等于mask_rate,表示当前word不被mask掉,则每个字符对应的word_mask_ids都是0;如果rand值小于mask_rate,则依次处理每个字符,以80%的几率替换为[MASK],以10%的几率保持不变,以10%的几率替换为一个随机token,得到token_ids,mask_ids,对token_ids和mask_ids最多取前510个字符,然后在开头和结尾增加[CLS]和[SEP],如果当前token_ids与instance的长度之和大于512则对其进行截断,反之则进行padding,变为长度为512,放入到instances中。把处理好token_ids与instance的数据包含写入tfrecord;
S12:构建模型输入接口,ID序列:ids,句子序列segments_ids,位置序列:pos,掩盖矩阵:mask(其中mask用全1表示);
S13:构建词嵌入层token_emb、位置嵌入层pos_emb、句子嵌入层segments_emb,分别通过词向量矩阵W
S14:构建12层二维掩盖矩阵的多头注意力层multi_head_2D_mask
S15:构建逆嵌入层reverse_emb,将特征矩阵逆向转换成对应单词的概率分布,具体公式为:
S16:根据输入接口ids、segments_ids、pos、mask,以及token_emb、pos_emb、segments_emb、multi_head_2D_mask
emb=ln(add(token
S17:根据所构建的ids、segments_ids、pos、mask,输入所述的模型,计算得到模型的实际输出p_pred,根据所构建的output和所述的p_pred,通过交叉熵计算得到模型对当前批次数据的loss,设置模型batch_size为4069,learning_rate为0.00176,weight_decay_rate为0.01,并对模型中的参数求导得到梯度,使用Adam优化器,更新模型中的参数,得到预训练模型。
具体的,步骤S2中构造待识别实体的类别的完型填空的模板过程包括如下步骤:
S21:构造待识别实体的类别列表list;
S22:定义完型填空问题:
P(W|S
其中W表示的是一个分类类别,S
S23:对类别列表list中的每一个类别分别构造带上下文和不带上下文的完型填空模板,完型填空模板包含待识别实体的一段文本[text],待识别的实体[entity]以及待识别实体的类别[type];
其中,带上下文关系的模板表示为:
S1(text,entity,type)=[text],上文中的[entity]是一种[mask],
W1(type)=[type]
不带上下文的模板表示为:
S2(entity,type)=[entity]是一种[mask]。
W2(type)=[type]。
具体的,步骤S3中使用完型填空模板生成完型填空问题的过程包括如下步骤:
S31:把实体分类问题测试集中的每个句子作为text,然后标记句子中的所有实体以及该实体在句子中位置,得到训练和测试的原始数据,其格式为:
{text:some text,entities[type,start
其中text表示的是一个句子,type表示的是实体的类别,start
S32:对于S31数据中的每个句子text中的每个实体使用所述构造的完型填空模板生成完型填空问题,其中,每一个实体要生成N个完型填空问题,N为事先构造的实体的类别的数量。
具体的,步骤S4中预测完型填空问题概率的过程包括如下步骤:
S41:定义分类模型,模型架构为S1中的bert模型架构;
S42:对S3中的完型填空问题进行序列化,并转变为id表示;
S43:构建输入token_ids=[CLS]+[x]
输出序列output_ids=[0,……entity
S44:token_ids、segment_ids和output_idss作为模型的输入,
模型输出为完型填空问题每个字符的概率:
P(x
其中,S表示输入的句子,x
S46:把这个概率序列转换为完型填空输出的概率值,其转换公式为:
S47:将同一个实体构造了N个完型填空问题,对这N个完型填空问题输入模型,模型输出N个概率值,最后取其中概率值最大的完型填空问题所对应的类别作为该实体最终对应的类别。
S44:S3中对与同一个实体构造了N个完型填空问题,其中,N为事先构造的实体的类别的数量,对这N个完型填空问题输入模型,模型输出N个概率值,最后取其中概率值最大的完型填空问题所对应的类别作为该实体最终对应的类别。
与现有技术相比,本发明具有以下优点或者有益效果:将实体分类问题通过构造自然语言的query转换为一种完型填空问题,把分类问题转换为完形填空问题。另一方面,不需要标注训练数据,无需训练模型,只需要构造对应实体分类的完型填空问题就可实现实体分类。本方法在CCKS2019数据集上Precision达到85.60,Recall达到85.60,F-score达到85.60。
附图说明
读者在参照附图阅读了本发明的具体实施方式以后,将会更清楚地了解本发明的各个方面。
图1示出依据本发明的一实施方式,基于语言模型的医疗实体零样本分类方法的流程框图。
具体实施方式
为了使本申请所揭示的技术内容更加详尽与完备,可参照附图以及本发明的下述各种具体实施例,附图中相同的标记代表相同或相似的组件。然而,本领域的普通技术人员应当理解,下文中所提供的实施例并非用来限制本发明所涵盖的范围。此外,附图仅仅用于示意性地加以说明,并未依照其原尺寸进行绘制。
下面参照附图,对本发明各个方面的具体实施方式作进一步的详细描述。
图1示出依据本发明的一实施方式,一种基于语言模型的医疗实体零样本分类方法,包括如下步骤:
S1:使用预训练语料训练bert模型得到预训练医疗bert模型;
S2:根据待识别实体的类别构造相应的完型填空的模板;
S3:对实体分类问题测试集中每个句子中的每个实体利用所述构造的完型填空模板,生成完型填空问题;
S4:将所述完型填空问题使用预训练医疗bert模型预测每个完形填空问题的概率值,取其中概率值最大的类别作为实体对应的类别。
具体的,S1中预先训练医疗bert模型包括如下步骤:
S11:准备预训练bert模型需要的语料以及对应的词典,读取每个文件,对每篇文章进行正则分句后存储到texts列表中。对于texts中的每一个text,使用jieba分词进行分词处理,得到分词结果words列表,为每个词对应的生成一个0~1之间的随机数。遍历所有的words,对word使用bert分词器按词典中存在的字符分成更小的字符即:word_tokens,并得到对应词典中的word_token_ids,把word_token_ids追加到该单句的token_ids中。设置mask_rate=0.15,比较该word的rand值与mask_rate的大小。如果rand值大于或等于mask_rate,表示当前word不被mask掉,则每个字符对应的word_mask_ids都是0;如果rand值小于mask_rate,则依次处理每个字符,以80%的几率替换为[MASK],以10%的几率保持不变,以10%的几率替换为一个随机token,得到token_ids,mask_ids,对token_ids和mask_ids最多取前510个字符,然后在开头和结尾增加[CLS]和[SEP],如果当前token_ids与instance的长度之和大于512则对其进行截断,反之则进行padding,变为长度为512,放入到instances中。把处理好token_ids与instance的数据包含写入tfrecord;
S12:构建模型输入接口,ID序列:ids,句子序列segments_ids,位置序列:pos,掩盖矩阵:mask(其中mask用全1表示);
S13:构建词嵌入层token_emb、位置嵌入层pos_emb、句子嵌入层segments_emb,分别通过词向量矩阵W
S14:构建12层二维掩盖矩阵的多头注意力层multi_head_2D_mask
S15:构建逆嵌入层reverse_emb,将特征矩阵逆向转换成对应单词的概率分布,具体公式为:
S16:根据输入接口ids、segments_ids、pos、mask,以及token_emb、pos_emb、segments_emb、multi_head_2D_mask
emb=ln(add(token
S17:根据所构建的ids、segments_ids、pos、mask,输入所述的模型,计算得到模型的实际输出p_pred,根据所构建的output和所述的p_pred,通过交叉熵计算得到模型对当前批次数据的loss,设置模型batch_size为4069,learning_rate为0.00176,weight_decay_rate为0.01,并对模型中的参数求导得到梯度,使用Adam优化器,更新模型中的参数,得到预训练模型。
具体的,步骤S2中构造待识别实体的类别的完型填空的模板过程包括如下步骤:
S21:构造待识别实体的类别列表list;
S22:定义完型填空问题:
P(W|S
其中W表示的是一个分类类别,S
S23:对类别列表list中的每一个类别分别构造带上下文和不带上下文的完型填空模板,完型填空模板包含待识别实体的一段文本[text],待识别的实体[entity]以及待识别实体的类别[type];
其中,带上下文关系的模板表示为:
S1(text,entity,type)=[text],上文中的[entity]是一种[mask],
W1(type)=[type]
不带上下文的模板表示为:
S2(entity,type)=[entity]是一种[mask]。
W2(type)=[type]。
具体的,步骤S3中使用完型填空模板生成完型填空问题的过程包括如下步骤:
S31:把实体分类问题测试集中的每个句子作为text,然后标记句子中的所有实体以及该实体在句子中位置,得到训练和测试的原始数据,其格式为:
{text:some text,entities[type,start
其中text表示的是一个句子,type表示的是实体的类别,start
S32:对于S31数据中的每个句子text中的每个实体使用所述构造的完型填空模板生成完型填空问题,其中,每一个实体要生成N个完型填空问题,N为事先构造的实体的类别的数量。
具体的,步骤S4中预测完型填空问题概率的过程包括如下步骤:
S41:定义分类模型,模型架构为S1中的bert模型架构;
S42:对S3中的完型填空问题进行序列化,并转变为id表示;
S43:构建输入token_ids=[CLS]+[x]
输出序列output_ids=[0,……entity
S44:token_ids、segment_ids和output_idss作为模型的输入,
模型输出为完型填空问题每个字符的概率:
P(x
其中,S表示输入的句子,x
S46:把这个概率序列转换为完型填空输出的概率值,其转换公式为:
S47:将同一个实体构造了N个完型填空问题,对这N个完型填空问题输入模型,模型输出N个概率值,最后取其中概率值最大的完型填空问题所对应的类别作为该实体最终对应的类别。
S44:S3中对与同一个实体构造了N个完型填空问题,其中,N为事先构造的实体的类别的数量,对这N个完型填空问题输入模型,模型输出N个概率值,最后取其中概率值最大的完型填空问题所对应的类别作为该实体最终对应的类别。
综上所述,使用对本发明提出了一种基于语言模型的医疗实体零样本分类方法,将实体分类问题通过构造自然语言的query转换为一种完型填空问题。利用语言模型预测完型填空问题答案概率,求出完型填空问题答案作为实体类别。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
- 一种基于语言模型的医疗实体零样本分类方法
- 一种基于类型注意力的神经零样本细粒度实体分类方法