用于快速全网代码溯源检测的代码库设计方法及检测方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明提供一种用于快速全网代码溯源检测的代码库设计方法及基于代码库快速全网代码溯源检测方法,属于软件工程技术领域。
背景技术
随着开源软件的蓬勃发展,网上积累了海量的优秀开源软件资源,软件开发也越来越多地使用开源代码。开源代码的使用在提高软件开发效率的同时,也引入了风险,比如如果不了解开源代码的来源,就不能对该开源代码后续的漏洞修复同步更新,同时还会将自己暴露在许可证合规风险和知识产权等法律风险之中,带来不同程度的安全威胁及经济或名誉损失。著名的开源风险案例是心脏出血漏洞(heartbleed)。它是一个出现在加密程序库OpenSSL的安全漏洞,该程序库广泛用于实现互联网的传输层安全协议。它于2012年被引入了OpenSSL中,2014年4月首次向公众披露。只要使用的是存在缺陷的OpenSSL实例,无论是服务器还是客户端,都可能因此而受到攻击。因此,对软件产品中的代码进行溯源检测对于软件产品至关重要。
为了实现软件产品的代码溯源检测,需要构建用于代码匹配搜索的代码库,代码库中包含的代码数量和构建方式直接影响代码溯源检测的准确度和效率。囿于大型代码库构建的难度,现有代码溯源检测技术大都是在假设已有海量代码库的前提下提出高效的代码检测算法,比如,研究从海量的开源软件库中选取代码最有可能被使用的开源软件参与溯源比对。而缺乏如何构建代码库的有效技术。现有技术中,通常采用下载若干开源软件到本地以形成代码库。但是,这些代码库存在项目涵盖范围小而不足于支撑对代码进行全网溯源检测、代码库架构设计不良导致进行代码溯源检测效率不高等问题。
发明内容
针对现有技术存在的技术问题,本发明提供了一种用于快速全网代码溯源检测的代码库设计方法,并基于代码库实现快速全网代码溯源检测,采用本发明方法生成的代码库可以支持对代码在文件粒度上的快速全网溯源检测,检测效率高。同时,该代码库可以定期高效地更新。
本发明中,“全网代码”指的是搜集的绝大多数开源代码托管平台的代码数据。托管在代码托管平台上的仓库称为远程仓库;将远程仓库克隆到本地后为本地仓库;本发明设计用于快速全网代码溯源检测的代码库是将远程仓库克隆到本地形成本地仓库,再从本地仓库中提取数据而形成的数据库。
本发明提供的用于快速全网代码溯源检测的代码库设计利用了Git的内部原理和哈希值,具体包括:
1)通过git clone命令可以将远程仓库下载到本地,通过git fetch命令可以将远程仓库的更新传送回本地。git fetch通过比较本地仓库和远程仓库的heads来计算出本地仓库相比远程仓库缺少什么对象,然后远程仓库将这些缺少的对象传输回本地。
2)Git使用四种类型的数据对象进行版本控制,这些对象的引用是基于该对象的内容计算的SHA1值。commit对象表示对项目的一次更改,包含一个包括提交父对象(如果有的话)的SHA1、文件夹(tree对象)、作者ID和时间戳、提交者ID和时间戳,以及提交信息。tree对象表示项目内的一个文件夹,是一个列表,其中包含了该文件夹中的文件(blob)和子文件夹(其他tree对象)的SHA1,以及它们相关的模式、类型和名称。blob对象是某个版本的文件内容(源代码)的压缩版本。tag对象是一个用于将可读名称与版本库的特定版本关联的字符串。一个commit代表一次代码更改,通常包括对若干个文件(blob)的修改。
3)哈希值是依据文件内容计算出的若干位的散列值,不同的文件内容会生成不同的哈希值,因此可以用哈希值来唯一地对文件进行索引。
本发明采用一种面向全网代码溯源检测的代码库设计方法,针对全网使用Git的开源项目内的Git对象进行高效存储而得到代码库,可用于代码溯源检测和分析,同时提供代码库的高效更新方案。具体来说,用于代码全网溯源检测的代码库的设计构建包括:项目发现,数据提取,数据存储,代码信息映射构建和数据更新。数据存储部分,本发明设计了一种与传统Git存储方式不同的按Git对象分类型分块存储的存储模式,该存储模式可以大幅减少代码库的存储空间并提高全网检索的效率,是本发明的首创方法;代码信息映射构建部分也是本发明的首创做法,本发明提出构建代码文件到代码文件的信息(包含它的项目和commit、创建它的作者和时间、它的文件名)间的关系映射,可以快速对代码文件的全网信息进行检索;本发明提出了对构建的超大规模的代码库的高效更新方式,基于Libgit2函数库提出定制化的git fetch协议,以构建的代码库为后端,该定制化的协议可以以极小的时间代价和空间代价正确获得远程仓库的新增的Git对象数据。最后本发明还提供一种对代码在文件粒度上的快速全网溯源检测方案。
本发明的技术方案是:
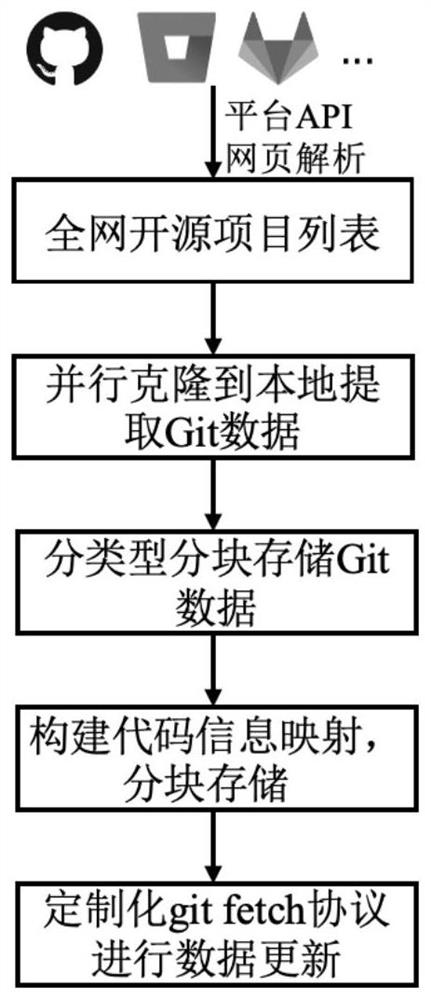
一种用于快速全网代码溯源检测的代码库设计方法,针对全网使用Git开源项目内的Git对象进行高效存储而得到代码库,并实现代码库的高效更新;提出按Git对象分类型分块存储的存储模式,以减少代码库的存储空间并提高全网检索的效率;构建代码文件到代码文件信息之间的关系映射,可对代码文件的全网信息进行快速检索;并对构建的超大规模的代码库采用高效更新方式,基于Libgit2函数库提出定制化的git fetch协议,以构建的代码库为后端,可高效获得远程仓库的新增的Git对象数据;用于快速全网代码溯源检测的代码库设计包括:项目发现、数据提取、数据存储、代码信息映射构建和数据更新过程;具体包括如下步骤:
A.通过多种项目发现方法获取全网开源软件项目列表;
开源软件项目大都托管在一些流行的开发协作平台如GitHub,Bitbucket,GitLab和SourceForge。本发明采用多种方法包括利用开发协作平台提供的API、解析平台的网页等方法来发现项目,再将发现的项目集合的并集作为最终的开源项目列表,从而获取开源项目列表。
具体实施时,在一台普通的服务器(如Intel E5-2670 CPU服务器)上即可完成,对硬件的要求低。本发明将项目发现过程的脚本打包进docker镜像中。
B.数据提取:将步骤A获取的开源项目列表中的项目下载到本地并提取其中的Git对象;
具体实施时,通过git clone克隆命令在本地创建一份远程仓库的拷贝。批量拷贝开源项目后,通过Git将克隆下来的开源项目内的所有Git对象批量提取出来。
数据提取可以在(云)服务器上并行完成。本发明使用Git的C语言接口Libgit2,先列出项目内所有的Git对象,然后按对象类型分类,最后把各对象的内容提取出来。本发明具体采用一个拥有36个结点、每个结点的CPU为16核的Intel E5-2670 CPU,内存为256GB的集群,每个结点开启16个线程完成上述Git对象提取工作。一个结点在2个小时可以处理大约5万个项目。将克隆下来的项目内的Git数据提取出来后,把克隆下来的项目删除掉,然后开始新的克隆-提取过程。
C.Git对象数据存储:按照Git对象类型分类型分块存储Git对象数据,降低数据存储空间,提高并行处理效率;具体包括:
a.不保存开源项目包括的二进制文件(比如PDF和图片);
b.按照Git对象类型分类型存储Git对象数据,即数据库的类型包括commit数据库、tree数据库、blob数据库(不包含二进制blob)和tag数据库。这种存储方式将数据存储空间降至百TB级别,同时还能够快速地检索数据是否保存在代码库中。
c.每类Git对象的数据库包括缓存数据和内容数据,分别保存在缓存数据库和内容数据库中,以加快检索速度;每类数据库(即commit数据库、tree数据库、blob数据库、tag数据库)包含的缓存数据库和内容数据库可分成多份(如128份)用于并行;缓存数据库用于快速确定某个Git对象是否已经存储在数据库中,并且是数据提取所必需的(如果存在,就不提取这个Git对象,进而节省时间)。此外,缓存数据库也有助于确定是否需要克隆一个仓库。如果一个仓库的head(保存在.git/refs/heads中的每个分支指向的commit对象)已经在缓存数据库中,就不需要克隆。
d.缓存数据库是一个键值数据库;内容数据库采用拼接的方式保存,以方便更新。
缓存数据库是一个键值数据库,其中键为Git对象的SHA1值(20个字节),值为利用Perl的compress库压缩后的该Git对象在内容数据库中的偏移位置和大小。内容数据库包含连续拼接在一起的Git对象的压缩后的内容。内容数据库是采用拼接的方式保存的,可以快速完成更新,只需把新的内容拼接到对应的文件末尾即可。对于commit和tree对象,分别另外创建了一个随机查找键值数据库,其中键是Git对象的SHA1,值是对应Git对象的压缩内容。键值数据库随机查询性能比较快,每个线程每秒可查询170K以上的git对象。
e.利用SHA1值实现并行化。
本发明使用Git对象的SHA1值第一个字节的后7位将各类型的数据库分割成128份。这样一来,四种类型的Git对象都有128个缓存数据库和128个内容数据库。此外commit对象和tree对象还分别有128个随机查找键值数据库,共有128*(4+4+2)个数据库,这些数据库可以放在一台服务器上加速并行。具体实施时,单个内容数据库的大小从tag对象的20MB到blob对象的0.8TB,单个缓存数据库最大是tree对象,大小为2Gb。
f.本发明使用C语言编写的数据库TokyoCabinet(类似于berkeley db)。
TokyoCabinet使用哈希作为索引,可以提供比MongoDB或Cassandra等各种常见键值数据库快约十倍的读取查询性能。更快的读取查询速度和极强的可移植性刚好符合面向全网代码溯源检测的代码库的构建需求,因此本发明采用数据库TokyoCabinet而非功能更全的NoSQL数据库。
D.代码信息映射构建:
本发明设计的代码库的目标是可以快速对代码进行全网溯源检测,支持对软件项目的安全和合规性进行分析,本发明构建了代码文件(blob)到包含它的项目,代码文件到包含它的commit,代码文件到它的作者,代码文件到它的文件名和代码文件到它的创建时间的关系映射,这些关系映射以数据库的形式保存,可以快速得到一个代码文件的全网信息,比如包含它的项目和commit、创建它的作者和创建它的时间,实现对这些代码信息映射的构建。针对一个代码文件,获得这些信息对于软件项目的安全和合规性的全面评估是有用的。
本发明以commit为中心构建关系映射,具体包括:
构建commit和项目之间的相互映射、构建commit和作者、时间的关系映射、构建作者到commit的关系映射、构建commit到代码文件(blob)之间的相互映射和commit到文件名之间的相互映射。
包含一个代码文件(blob)的项目列表可以通过代码文件(blob)到commit和commit到项目的关系组合确定;代码文件(blob)的创建时间可以通过代码文件(blob)到commit和commit到时间的关系组合确定,代码文件(blob)的作者可以通过代码文件(blob)到commit和commit到作者的关系组合确定。
还构建了代码文件和文件名之间的相互关系映射来支持特定代码片段的溯源。
利用TokyoCabinet数据库保存这些关系映射,以进行快速检索。本发明仍使用分块存储来提高检索效率,具体来说本发明将每类关系映射分成32个子数据库。对于commit和(代码文件)blob,使用它们SHA1的第一个字符的后5位进行划分。对于作者、项目和文件名,本发明使用他们的FNV-1Hash的第一个字节的后5位进行划分。
E.数据更新
Git对象是不可改变的(即已有的Git对象会保持不变,只会有新的Git对象存在),因此,只需获取这些新的Git对象。本发明具体使用两种方法对代码库进行更新:
a.识别新的Git项目,克隆然后提取其中的Git对象。
b.通过获取已收集仓库的远程仓库的分支的最新的commit来识别更新的项目,然后通过修改git fetch协议,使得该协议可以在没有本地Git仓库(在步骤B提取出数据后就把克隆的Git仓库删除了以节省空间)的情况下,以构建的代码库为后端,获取远程仓库的新增的Git对象,并提取出新增的Git对象到代码库中。本发明通过Libgit2中实现gitfetch功能的源代码,还原出git fetch的流程,具体包括以下步骤:
b1)将远程仓库添加到本地仓库中。在Libgit2中用git_remote结构体来表示远程仓库,在创建这个结构体的时候,会将本地仓库内.git/refs/heads文件夹内的所有分支引用都填充到该结构体内的一个成员变量(ref)中;
b2)本地仓库建立到远程仓库的连接;
b3)建立连接后,远程仓库会进行回复(respond),将远程仓库的所有的分支引用(.git/refs/heads文件夹内的内容)发送到本地;
b4)本地仓库接收到远程仓库发回的引用后,会逐个检查这些引用指向的对象是否在本地仓库中,如果在本地仓库中,就标记它表明这一分支没有更新,不需要请求远程仓库发送更新。然后将这些引用插入到第b1步提到的成员变量中
b5)本地仓库检查完所有这些引用后,会将这个成员变量发回到远程仓库(包括标记过的引用),与远程仓库“谈判”(negotiate)。这里本地会等待远程仓库发回的ACK信号。Libgit2在这里等待的方式是将本地仓库内的commit对象按照时间顺序排序,然后按从最近的commit开始往前遍历,对于每个commit对象,将其发送给远程仓库告诉它本地有这个对象,然后再发送给远程仓库一次检查完的引用。这样重复至多256次,直到收到远程仓库发回的ACK信号。
b6)与远程仓库谈判完毕后(即告诉远程仓库:本地仓库分支最新的commit是什么,想要哪些),远程仓库可以计算出要把哪些Git对象发回到本地。远程仓库将这些对象打包成packfile格式的文件,发回本地。
b7)本地仓库接收到发回的数据后,会根据packfile的格式,解析它,并构建出对应的索引(index)文件,方便检索。构建index文件时需要根据本地Git仓库中的Git对象来恢复。
从git fetch的步骤可以看出,除了第b5)步和第b7)步外,其他过程都不涉及除分支引用指向的其他Git对象,git fetch是通过比较远程仓库的分支引用与本地的不同来判断远程仓库是否有更新的。我们提出对git fetch进行如下修改:
1)修改原始git fetch第b3步:将远程仓库发回的分支引用保存到本地,判断这些分支引用是否保存在本地代码库中,如果存在,说明远程仓库无更新,如果不存在说明远程仓库有更新,进入下一步。
2)修改原始git fetch第b5步:原始的git fetch协议对commit排序并发送到远程仓库,只是为了等待远程仓库的ACK信号,并没有什么特别的作用,所以本发明换一种等待方法:每次都发送主分支最新的commit对象,重复至多256次直到收到远程仓库的ACK信号
3)修改原始git fetch第b6步:将远程仓库发回的packfile格式的文件保存到本地,依据代码库中的Git对象解析packfile文件,不进行第b7步。
对git fetch进行上述修改后,可以使git fetch以构建的代码库为后端进行更新,不需要每次更新都需要克隆完整的仓库,同时减少网络带宽开销和时间开销。
具体实施时,本发明还提供一种基于代码库对代码在文件粒度上的快速全网代码溯源检测方法,包括如下步骤:
1)针对一个代码文件,计算其SHA1值
2)根据步骤D构建的代码信息映射,以代码文件的SHA1为键,查询该代码文件的全网信息,包括包含该代码文件的项目列表、commit列表和对应的文件名和作者等信息,反馈给用户。
与现有技术相比,本发明的有益效果是:
通过本发明所提供的一种代码库设计,可以支持对代码进行高效的全网溯源检测。通过本发明的技术方案和提供的实施例,无需大量的服务器即可完成对全网包括GitHub在内的多个代码托管平台上的开源Git仓库构建本地代码库;无需特别多的带宽,即可完成对代码库的增量更新。
本发明的技术方案和提供的实施例,为构建面向全网代码溯源检测的代码库提供了详细的指导,弥补了在代码溯源检测领域海量代码库构建技术的空缺。
附图说明
图1为本发明实施例中用于快速全网代码溯源检测的代码库设计方法的流程框图
图2为本发明实施例中代码库更新策略的流程框图。
图3为本发明实施例中定制化的git fetch过程的流程框图。
图4为本发明实施例中基于定制化的git fetch协议获取远程仓库更新的流程框图。
图5为本发明实施例中基于构建的代码库的快速全网代码溯源检测方法的流程框图。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供一种用于快速全网代码溯源检测的代码库设计方法,具体包括以下步骤:
A.通过多种项目发现方法获取全网开源软件项目列表。实现方法为:
目前开源软件项目大都托管在一些流行的开发协作平台如GitHub,Bitbucket,GitLab和SourceForge。还有一部分开源项目是托管在个人或特定项目的网站。因此,为了支持对代码的全网溯源检测,需要获取尽可能完整的开源项目列表。针对此挑战,本发明结合多种方法如利用平台提供的API、解析平台的网页等方法来发现项目。最后将这些方法发现的项目集合的并集作为最终的开源项目列表。
B.数据提取:将步骤A中开源项目列表中的项目下载到本地并提取其中的Git对象;
这一步负责将步骤A发现的项目下载到本地并提取其中的Git对象。通过gitclone命令在本地创建一份远程仓库的拷贝。批量拷贝项目后,通过Git将克隆下来的项目内的所有Git对象批量提取出来。这一步可以在(云)服务器上并行完成。
C.数据存储:按照Git对象类型分类型分块存储,降低数据存储空间,提高并行处理效率;
开源项目间可能会因为复用代码、pull-request开发模式等原因存在很多重复的Git对象。同时,开源项目还会包括很多二进制文件,比如PDF和图片。如果不去除这种冗余和二进制文件,估计需要的数据存储空间将超过1.5PB,如此巨大的数据量将导致代码溯源任务几乎不可能实现。为了避免仓库间Git对象的冗余,加上代码库的设计是面向全网代码溯源检测的,因此本发明不保存二进制文件,本发明按照Git对象类型分类型存储,即commit数据库、tree数据库、blob数据库(不包含二进制blob)和tag数据库。这种存储方式将数据存储空间降至百TB级别的同时,还能够快速地检索数据是否保存在代码库中。
D.代码信息映射构建:
本代码库的目标是可以快速对代码进行全网溯源检测,支持对软件项目的安全和合规性进行分析,为此本发明构建了代码文件(blob)到包含它的项目,代码文件到包含它的commit,代码文件到它的作者,代码文件到它的文件名和代码文件到它的创建时间的关系映射,这些关系映射以数据库的形式保存,可以快速得到一个代码文件的全网信息,比如包含它的项目和commit、创建它的作者和创建它的时间,实现对这些代码信息映射的构建。针对一个代码文件,获得这些信息对于软件项目的安全和合规性的全面评估是有用的。
E.数据更新
保持代码库的最新对于代码溯源检测任务是至关重要的。随着现有仓库规模的增长和新仓库的出现,克隆所有仓库的过程需要的时间越来越长。目前,要克隆所有的git仓库(包括fork在内超过1亿3千万个),估计总时间需要六百台单线程服务器运行一周,结果将占用超过1.5PB的磁盘空间。幸运的是,git对象是不可改变的(即已有的Git对象会保持不变,只会有新的Git对象存在),因此,只需获取这些新的Git对象。具体来说,本发明提出使用两种策略对代码库进行更新:
1.识别新的Git项目,克隆然后提取其中的Git对象。
2.通过获取已收集仓库的远程仓库所有分支的最新的commit来识别更新的项目,然后通过修改git fetch协议,使得该协议可以在没有本地Git仓库(在步骤B提取出数据后就把克隆的Git仓库删除了以节省空间)的情况下,以构建的代码库为后端,获取远程仓库的更新,并提取出新增的Git对象到代码库中。本发明通过Libgit2中实现git fetch功能的源代码,还原出git fetch的流程,如图2所示,具体包括以下7步:
1)将远程仓库添加到本地仓库中。在Libgit2中用git_remote结构体来表示远程仓库,在创建这个结构体的时候,会将本地仓库内.git/refs/heads文件夹内的所有分支引用都填充到该结构体内的一个成员变量(ref)中;
2)本地仓库建立到远程仓库的连接;
3)建立连接后,远程仓库会进行回复(respond),将远程仓库的所有的分支引用(.git/refs/heads文件夹内的内容)发送到本地;
4)本地仓库接收到远程仓库发回的引用后,会逐个检查这些引用指向的对象是否在本地仓库中,如果在本地仓库中,就标记它表明这一分支没有更新,不需要请求远程仓库发送更新。然后将这些引用插入到第1步提到的成员变量中
5)本地仓库检查完所有这些引用后,会将这个成员变量发回到远程仓库(包括标记过的引用),与远程仓库“谈判”(negotiate)。这里本地会等待远程仓库发回的ACK信号。Libgit2在这里等待的方式是将本地仓库内的commit对象按照时间顺序排序,然后按从最近的commit开始往前遍历,对于每个commit对象,将其发送给远程仓库告诉它本地有这个对象,然后再发送给远程仓库一次检查完的引用。这样重复至多256次,直到收到远程仓库发回的ACK信号。
6)与远程仓库谈判完毕后(即告诉远程仓库:本地仓库分支最新的commit是什么,想要哪些),远程仓库员可以计算出要把哪些Git对象发回到本地。远程仓库将这些对象打包成packfile格式的文件,发回本地。
7)本地仓库接收到发回的数据后,会根据packfile的格式,解析它,并构建出对应的索引(index)文件,方便检索。构建index文件时需要根据本地Git仓库中的Git对象来恢复。
从git fetch的步骤可以看出,除了第5)步和第7)步外,其他过程都不涉及除分支引用指向的其他Git对象,git fetch是通过比较远程仓库的分支引用与本地仓库的分支引用的不同来判断远程仓库是否有更新的。本发明提出对git fetch进行如下修改:
1)修改原始git fetch第3步:将远程仓库发回的分支引用保存到本地,判断这些分支引用是否保存在本地代码库中,如果存在,说明远程仓库无新增的Git对象数据,如果不存在说明远程仓库有新增的Git对象数据,进入下一步。
2)修改原始git fetch第5步:原始的git fetch协议对commit排序并发送到远程仓库,只是为了等待远程仓库的ACK信号,并没有什么特别的作用,所以本发明换一种等待方法:每次都发送主分支最新的commit对象,重复至多256次直到收到远程仓库的ACK信号
3)修改原始git fetch第6步:将远程仓库发回的packfile格式的文件保存到本地,依据代码库中的Git对象解析packfile文件,不进行第7步。
对git fetch进行上述修改后,可以使git fetch以构建的代码库为后端进行更新,不需要每次更新都需要克隆完整的仓库,同时减少网络带宽开销和时间开销。
最后,本发明提供一种对代码在文件粒度上的快速全网溯源检测方案,具体来说包括两步:
1.针对一个代码文件,计算其SHA1值
2.根据步骤D构建的代码信息映射工具数据库,以该代码文件的SHA1为键,查询该代码文件的全网信息,包括包含该代码文件的项目列表,commit列表和对应的文件名和作者等信息,反馈给用户。
作为一种优选方案,所述步骤B使用Git的C语言接口Libgit2(因为C语言更高效,速度更快)完成提取任务。
作为一种优选方案,所述步骤C和步骤D使用TokyoCabinet数据库。
作为一种优选方案,所述步骤E使用Git的C语言接口Libgit2来实现定制化的Gitfetch协议。
图2所示为本发明实施例中用于快速全网代码溯源检测的代码库设计方法的流程,包括以下具体实施步骤:
A.项目发现:
为了获取尽可能完整的开源项目列表,本发明结合多种启发式方法,包括使用开发协作平台的API,解析平台的网页等来发现项目。最后将这些方法发现的项目集合的并集作为最终的开源项目列表。本发明将项目发现过程的脚本打包进docker镜像中。具体来说,本发明采用的项目发现方法如下:
1.使用开发协作平台的API。一些代码托管平台如GitHub会提供API,这些API可以被用来发现这个平台上完整的开源项目集合。这些API是平台特定的,会有不同的使用方式,因此需要针对不同的平台的API设计不同的API查询。但这些API一般都会针对用户或IP地址有访问速率限制,可以通过构建用户ID池来突破这种限制。对于GitHub平台,我们使用GitHub的GraphQL API,获取有更新的GitHub仓库列表,具体操作是将需要获取的仓库的时间段按照用户ID池中的用户ID数量均分,然后每个用户ID负责一个时间段内的更新仓库数量,查询条件是:{is:public archived:false pushed:start_time..end_time},这里在每个时间段内以10分钟为区间替换start_time和end_time,获取每10分钟区间内的更新的仓库数量;对于Bitbucket平台,使用的api查询是https://api.bitbucket.org/2.0/repositories/?pagelen=100&after=date,这里将date替换成特定的时间比如2017-11-18,就能获得在2017-11-18日之后创建的Bitbucket仓库;对于SourceForge平台,该平台提供了XML格式的项目列表,XML文件的地址在https://sourceforge.net/sitemap.xml,下载XML解析即可得到SourceForge上所有的项目列表;对于GitLab平台,使用的API查询是https://gitlab.com/api/v4/projects?archived=false&membership=false&order_by=created_a t&owned=false&page={}&per_page=99&simple=false&sort=desc&starred=false&statisti cs=false&with_custom_attributes=false&with_issues_enabled=false&with_merge_request s_enabled=false,这里将page的参数设置为1,然后递增获取所有的gitlab上的项目。
2.解析网站的网页。对于Bioconductor平台,通过解析http://git.bioconductor.org网页,可以得到该网站上的所有项目;对于repo.or.cz平台,通过解析https://repo.or.cz/?a=project_list网页,即可得到该网站上的所有项目;对于Android平台,通过解析https://android.googlesource.com/网页,即可得到该网站上的所有项目;
对于ZX2C4平台,解析https://git.zx2c4.com网页,即可得到该平台上的所有项目;对于eclipse平台,解析http://git.eclipse.org/网页,即可得到该平台上的所有项目;对于PostgreSQL平台,解析http://git.postgresql.org网页,即可得到该平台上的所有项目;
对于Kernel.org平台,解析http://git.kernel.org网页,即可得到该平台上的所有项目;对于Savannah平台,解析http://git.savannah.gnu.org/cgit网页,即可得到该平台上的所有项目。
这一步在一台普通的服务器(如Intel E5-2670 CPU服务器)上即可完成,对硬件的要求很低。截至2020年9月,我们检索到有1亿3千多万个不同的仓库(不包括标记为fork的GitHub仓库和没有内容的仓库)。
B.数据提取:
这一步可以在非常多的服务器上并行完成,但需要大量的网络带宽和存储空间。通过git clone命令把远程仓库批量克隆到本地,经过测算,在一台Intel E5-2670 CPU服务器上,一个单线程shell进程在没有网络带宽的限制下24小时可以克隆2万到5万个随机选择的项目(时间随仓库的大小和平台的不同而变化很大)。为了在一星期内克隆所有的项目(超过1亿3千万个),需要约400-800台服务器,需要的代价是很高的。因此,本发明通过在每台服务器上运行多个线程来优化检索,并只检索自上次检索以来发生变化的一小部分仓库。本发明目前使用拥有300个结点、带宽高达56Gb/s的计算集群平台上的5个数据传输结点完成克隆任务。此外,这一步可以使用云服务器代替计算集群来完成,可以在克隆的时间购买定制的符合自己需求的云服务资源,然后批量克隆结束之后再释放这些资源。云服务器可以达到更高的带宽,克隆速度更快。
将项目克隆到本地后,需要将项目内所有的Git对象全部提取出来。Git客户端只能挨个显示一个Git对象的内容,不利于自动化批量处理。本发明使用Git的C语言接口Libgit2,先列出项目内所有的Git对象,然后按对象类型分类,最后把各对象的内容提取出来。本发明目前在一个拥有36个结点、每个结点的CPU为16核的Intel E5-2670 CPU,内存为256GB的集群上,每个结点开启16个线程完成上述Git对象提取工作。一个结点在2个小时可以处理大约5万个项目。将克隆下来的项目内的Git数据提取出来后,把克隆下来的项目删除掉,然后开始新的克隆-提取过程。
C.数据存储:按照Git对象类型分类型分块存储,且不保存二进制文件,降低数据存储空间,增加并行处理速度。
本发明按git对象类型分类型存储以避免冗余,减少存储开销;面向代码溯源检测,存储时不保存二进制文件;每种Git对象数据库包含缓存数据和内容数据,分别存储在缓存数据库和内容数据库中,以加快检索速度;为了可以并行,每种Git对象的缓存数据库和内容数据库可分成多份(如128份)用于并行;内容数据库采用拼接的方式保存以方便更新。
具体地,本发明按照Git对象的类型分别存储以避免冗余,因此共有4种类型的数据库:commit数据库、blob数据库、tree数据库和tag数据库。每种数据库包含缓存数据和内容数据,分别保存在缓存数据库和内容数据库中。缓存数据库用于快速确定某个特定的对象是否已经存储在我们的数据库中,并且是上述数据提取所必需的(如果存在,就不提取这个Git对象,进而节省时间)。此外,缓存数据库也有助于确定是否需要克隆一个仓库。如果一个仓库的head(保存在.git/refs/heads中的每个分支指向的commit对象)已经在我们的缓存数据库中,说明这个仓库没有更新,就不需要克隆这个仓库。
缓存数据库是一个键值数据库,其中键为Git对象的SHA1值(20个字节),值是利用Perl的compress库压缩后的该Git对象在内容数据库中的偏移位置和大小。内容数据库包含连续拼接在一起的Git对象的压缩后的内容。内容数据库是采用拼接的方式保存的,这样可以保证更新的快速完成,只需把新的内容拼接到对应的文件末尾即可。虽然这种存储方式可以快速扫描整个数据库,但对于需要的随机查找来说并不是最佳选择,例如,在计算一个commit作出的修改时,我们需要遍历两遍commit数据库,来获取这个commit对象指向的tree对象和它的父commit对象指向的tree对象,然后再多次遍历tree数据库,获取这两个tree对象包含的内容,找出有差异的文件,最后遍历一次blob数据库,计算出修改,每次遍历都会造成重复的额外的时间开销。因此,对于commit和tree,本发明还分别另外创建了一个随机查找键值数据库,其中键是git对象的SHA1,值对应Git对象的压缩内容。这个键值数据库随机查询性能比较快,经过测试:在一台CPU为Intel E5-2623的服务器上的单线程能够在6秒内随机查询100万个git对象,即每个线程每秒查询170K以上的git对象。
目前,本发明检索到200多亿个Git对象(包括23亿多个commit对象,91亿多个blob对象,94亿多个tree对象和1800多万个tag对象),数据存储空间约150TB。如果不进行并行处理,那么处理这么大容量的数据将会变得特别低效。本发明利用SHA1值实现并行化。本发明使用Git对象的SHA1值第一个字节的后7位将各类型的数据库分割成128份。这样一来,四种类型的Git对象都有128个缓存数据库和128个内容数据库。此外commit对象和tree对象还分别有128个随机查找键值数据库,共有128*(4+4+2)个数据库,这些数据库可以放在一台服务器上加速并行。目前单个内容数据库的大小从tag对象的20MB到blob对象的0.8TB,单个缓存数据库最大是tree对象,大小为2Gb。
尽管如此,数据库的规模限制了对数据库的选择。例如,像neo4j这样的图数据库对于存储和查询关系,包括传递关系是非常有用的,但是它并不能(至少在普通的服务器上)处理千亿级别的关系。除了neo4j之外,本发明还尝试了许多传统的数据库。本发明评估了常见的关系型数据库MySQL和PostgreSQL以及键值数据库(NoSQL)数据库MongoDB、Redis和Cassandra。SQL像所有的集中式数据库一样,在处理PB级别的数据方面有局限性。因此本发明专注于NoSQL数据库,这类数据库是为大规模数据的存储和在大量商用服务器上进行大规模并行数据处理而设计的。
经过测试,本发明使用了一个名为TokyoCabinet的C语言编写的数据库(类似于berkeley db)。TokyoCabinet使用哈希作为索引,可以提供比MongoDB或Cassandra等各种常见键值数据库快约十倍的读取查询性能。更快的读取查询速度和极强的可移植性刚好符合面向全网代码溯源检测的代码库的构建需求,因此我们用它来代替功能更全的NoSQL数据库。
D.代码信息映射构建,包括:
设计并生成可以快速对代码文件(blob)到它的信息间的关系映射,代码文件的信息包括包含它的项目和commit,创建它的作者和时间,它的文件名,这些关系映射以数据库的形式保存,可以对代码文件的全网信息进行快速检索
本代码库的目标是可以快速对代码进行全网溯源检测,支持对软件项目的安全和合规性进行分析。因此本发明生成了代码文件(blob)到它的信息(包括包含它的项目和commit、创建它的作者和时间以及文件名)的关系映射,并以数据库的形式保存下来,进而可以对代码文件的全网信息进行检索。。代码文件的全网信息对于软件项目的安全和合规性的全面评估是有用的,是全网代码溯源检测的重要内容。
代码文件的信息包括包含它的项目和commit,它的文件名,创建它的作者和时间。其中,创建它的作者和时间是包含在创建它的commit里的,同时commit到项目的关系映射和项目到commit的关系映射在步骤B数据提取就能完成。因此,本发明以commit为中心,构建关系映射,具体来说:构建commit和项目之间的相互映射、构建commit和作者、时间的关系映射、构建作者到commit的关系映射、构建commit到代码文件(blob)之间的相互映射和commit到文件名之间的相互映射。然后,包含一个代码文件(blob)的项目列表可以通过代码文件(blob)到commit和commit到项目的关系组合确定;类似的,一个代码文件(blob)的创建时间可以通过代码文件(blob)到commit和commit到时间的关系组合确定,代码文件(blob)的作者可以通过代码文件(blob)到commit和commit到作者的关系组合确定。
从commit到作者、时间和项目的映射并不难实现,因为作者和时间是commit对象的一部分,commit和项目之间的映射是在步骤B数据提取时就能获得。但是一个commit引入或删除的代码文件(blob)与commit没有直接关系,需要通过递归遍历commit和其父commit的tree对象来计算。一个commit包含仓库的一次快照,包含了所有的tree(文件夹)和blobs(代码文件)。为了计算一个commit和它的父commit之间的差异,即新的代码文件(blob),我们分别从commit对象指向的tree对象开始,遍历每个子tree并提取所有的代码文件(blob)。通过比较每个commit的所有代码文件(blob),可以得到一个commit引入的新的代码文件(blob)。平均来说,在单线程中获取一万个commit的变更的文件名和代码文件(blobs)大约需要1分钟。经过估计,对于23亿多个commit,单线程的整体时间需要104天,通过在一台16核Intel E5-2623 CPU的服务器上运行16个线程,可以在一星期内完成。此外,这些关系是增量的,只需生成一次,然后在每次更新的commit上进行上述操作即可,然后插入已有数据库中。根据代码文件(blob)到commit和commit到文件名的关系组合,不能确定代码文件(blob)和文件名的对应关系,因为一个commit会修改多个文件。本发明还构建了代码文件和文件名之间的相互关系映射来支持特定代码片段的溯源。例如,如果要对一段Python代码进行溯源检查,那么要对所有的Python文件进行检查。那么文件名到代码文件的映射,可以获取所有以.py结尾的Python文件,然后针对这些文件进行代码溯源检查。
与步骤C数据存储部分类似,本发明利用TokyoCabinet数据库保存这些关系映射,来进行快速检索。本发明扔使用分块存储来提高检索效率,具体来说本发明将每类关系映射分成32个子数据库。对于commit和(代码文件)blob,本发明使用它们SHA1的第一个字符的后5位进行划分。对于作者、项目和文件名,本发明使用他们的FNV-1Hash的第一个字节的后5位进行划分。
E.数据更新
保持代码库的最新对于代码溯源检测任务是至关重要的。为了获得可以接受的更新时间,本发明采用以下方式完成数据的更新:
1.识别新的Git项目,克隆然后提取其中的Git对象。通过步骤A发现的新的开源项目列表,然后与上一次的开源项目列表比较,确定其中新增的项目,然后将其克隆到本地,提取其中的Git对象。
2.识别更新的项目,然后只克隆更新的项目,并提取出新增的Git对象。本发明基于Libgit2对其中的git fetch协议进行如下修改:
1)修改原始git fetch第3步:将远程仓库发回的分支引用保存到本地。在Libgit2的src/fetch.c文件中的filter_wants函数调用git_remote_ls函数后,将git_remote_ls收到的远程仓库发回的heads的SHA1值保存到文件中。
2)修改原始git fetch第5步:修改Libgit2的src/transports/smart_protocol.c文件,修改git_smart__negotiate_fetch函数:注释掉关于git_revwalk_next的调用,添加git_reference_name_to_id调用,使得每次都发送主分支最新的commit对象,重复至多256次直到收到远程仓库的ACK信号。
3)修改原始git fetch第6步:修改Libgit2的/src/transports/smart_protocol.c文件中的git_smart__negotiate_fetch函数,将远程仓库发回数据(git_pkt_progress
*p)保存到本地文件中,直接return返回,不进行第7步。
进行上述修改后,重新编译Libgit2库,然后使用修改后的git fetch协议去获取远程仓库的新增的Git对象数据,具体步骤如下:
1.初始化一个空的Git仓库
2.从构建的代码库中提取出一个仓库的所有分支引用的SHA1值和内容,填充到这个空的git仓库里。填充方式如下:构造分支引用的头部信息,格式是:对象类型+空格
+对象内容长度+一个空字节(null byte),比如“blob 12\u0000”。然后将头部信息和原始数据拼接起来,用zlib的compress函数压缩拼接后的内容。最后在这个空的git仓库中的.git/objects文件夹中创建名为SHA1的前两位的子目录,在这个子目录里面创建名以SHA1后38位的文件,将压缩的内容写进这个文件中
3.在这个空的Git仓库中的.git/refs/heads文件夹中创建名为分支名(如master)的文件,然后将该分支引用的commit的SHA1值写进这个文件
本发明把新增的Git对象的数据根据类型及其SHA1值将其直接拼接到对应的内容数据库中,并在缓存数据库中记录其SHA1值,在内容文件中的偏移和大小,更新相应的关系映射数据库。
该代码库构建完成后,可以对代码在文件粒度上进行快速全网溯源检测。步骤如下:
1.计算代码文件的SHA1值。这里使用python2的hashlib库的sha1函数进行计算。比如https://github.com/fchollet/deep-learning-models/blob/master/resnet50.py文件包含深度学习模型ResNet50的实现,计出算其SHA1值是e8cf3d7c248fbf6608c4947dc53cf368449c8c5f
2.根据步骤D构建的代码信息映射工具数据库,以该代码文件的SHA1为键,查询该代码文件的全网信息,包括包含该代码文件的项目列表,commit列表和对应的文件名和作者等信息,反馈给用户。通过blob到commit的映射,得到包含该blob的commit有192个,通过commit到project的映射,得到包含该blob的project有377个。上述过程只需0.831s。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 用于快速全网代码溯源检测的代码库设计方法及检测方法
- 一种复用代码库构建方法、复用代码快速溯源方法及系统