基于疑问词分类器的神经网络问题生成方法及生成系统
文献发布时间:2023-06-19 11:45:49
技术领域
本发明涉及互联网技术领域,具体涉及一种基于疑问词分类器的神经网络问题生成方法及生成系统。
背景技术
随着计算机技术发展,计算机算力逐渐加强,机器学习、深度学习技术进一步得到发展,自然语言处理逐渐应用到各个场景,例如利用文本分类技术在电影评论、购物的商品评论中挖掘用户偏好、利用摘要生成技术对新闻等文章进行归纳总结,或是通过机器翻译技术,实现同步翻译等。大量的应用场景需要技术,同时随着国内互联网用户的增加,其产生的信息也越来越多。对于海量数据,自动化处理文本信息更凸显其重要意义。因此,由于自然语言处理技术的不可代替及其对于文本处理的超高效率,受到社会广泛关注。
在自然语言处理领域,问题生成(Question Generation,QG)是一个新兴的热门研究课题。传统意义上,QG的定义是给定一篇文本,里面包含一些重要的事实,将这些事实作为待提问答案,由机器自动提出合理的问题。简单的说,QG可以定义为一个优化问题,即在给定文本和答案的前提下,最大化生成合理问题的概率。问题生成具有丰富的实践意义和价值,其应用场景包括:在教育领域,问题生成可以帮助学生思考和提问,以提高阅读理解的能力;在对话系统中,问题生成可以作为冷启动来开始一个话题或者通过对用户的陈述展开提问,提高用户体验;在医药领域,可以用于自动问诊系统,作为一种辅助工具等等。
随着深度学习的发展,端到端神经网络技术已经普遍应用于自然语言处理领域。所谓“端到端”,是指输入端和输出端都是文本序列。端到端神经网络模型通常由一个编码器和一个解码器组成,编码器负责对输入序列进行编码,提取重要的特征,解码器负责识别这些特征,并输出目标序列。而编码器和解码器分别是由神经网络组成,常用的神经网络包括循环神经网络(Recurrent Neural Network,RNN)以及卷积神经网络(ConvolutionalNeural Network,CNN)。相较于传统的机器学习方法,端到端神经网络模型不用人工设计算法提取特征,特征的提取全部是由神经网络完成,减少了人力劳动成本,并且性能更加优越。现有技术多采用基于注意力机制的端到端神经网络模型和其改进。
首次提出基于端到端神经网络问题生成模型的(Learning to Ask:NeuralQuestion Generation for Reading Comprehension,学习去提问:阅读理解的神经问题生成)的文章中,提出将一段文本输入端到端神经网络模型,生成一个问题:
首先,将原始文本转换成词向量的形式,输入到一个编码器中,获取文本的语义特征向量;其次,将特征向量输入到一个解码器中,并添加注意力机制强化对输入文本的理解能力,获取解码后的向量;最后,通过一个全连接层,在每个时刻输出一个单词,最终组成一个问题。该模型的编码器是由一个双向长短期记忆神经网络(Bi-LSTM:BidirectionalLong Short Term Memory)组成,解码器是由一个单向LSTM组成。其中,LSTM是循环神经网络的一种。
如图1所示,现有技术之一的(Paragraph-level Neural Question Generationwith Maxout Pointer and Gated Self-attention Networks,基于最大输出指针和门控自注意力的段落级神经问题生成)的文章中,提到用门控自注意力(Gated Self-attention)和最大输出指针(Maxout Pointer)技术,对更长的输入文本生成问题并减少重复词的产生:
图1中,m
首先,将原始文本的词向量和答案标签向量进行拼接,输入到Bi-LSTM的编码器中;其次,将获取的语义特征向量输入到一个门控自注意力模块,抽取文本中和答案相关的信息向量;最后,将所得向量输入到一个单层LSTM的解码器中,利用Maxout Pointer技术,从原始文本中复制有用的单词作为答案的一部分。如果没有合适的复制单词则从词表中选择一个进行输出,最终生成一个完整的问题。本发明的神经网络问题生成模型就是基于这篇论文的成果。
在研究的过程中发现,对于上述现有技术中,存在以下缺点:
生成的问题往往疑问词不准确,例如答案是一个人名,应该以疑问词“who”提问,但生成的问题却是以“where”、“when”等,直接导致生成的问题发生根本性的错误。
发明内容
本发明为解决现有基于分类器的网络模型存在生成问题中的疑问词不准确,导致存在根本性错误等问题,提供一种基于疑问词分类器的神经网络问题生成方法及生成系统。
基于疑问词分类器的神经网络问题生成方法,包括以下步骤:
步骤一、将语料按照真实疑问词的类别进行划分,通过降采样和过采样使得每个类别的样本数量达到均衡;
步骤二、对原始输入文本中的答案词两边添加答案位置标记符,获得预处理后的数据;
步骤三、构建疑问词分类器,所述疑问词分类器由预训练语言模型BERT和前馈神经网络FNN组成;
步骤三一、预训练语言模型BERT模型作为文本特征提取器,对于输入原始文本提取特征向量C;
步骤三二、将BERT模型提取到的特征向量C输入到FNN中,首先通过一个训练参数矩阵W
P=softmax(W
步骤四、将步骤二的预处理后的数据划分为训练集、评估集和测试集,分别用于对步骤三所述的疑问词分类器进行训练、评估和测试;
步骤五、采用步骤四测试后的疑问词分类器进行预测,将预测后的疑问词添加到所述原始输入文本的句首,获得预测后的文本;
步骤六、利用词向量映射表,将步骤五获得的预测后的文本映射为向量形式表示,输入的文本即数值化为每个字符向量列连接成的数值矩阵;
步骤七、将步骤六获得的数值矩阵输入到神经网络问题生成模型,输出完整的问题。
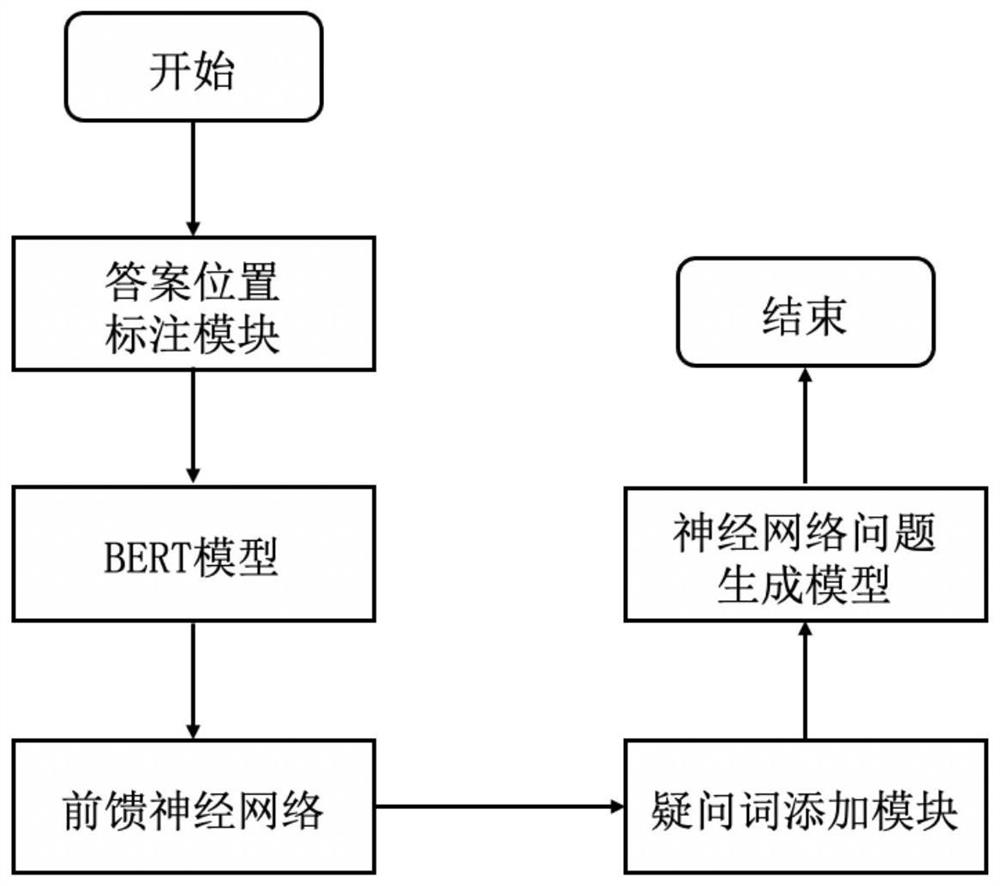
基于疑问词分类器的神经网络问题生成系统,该生成系统包括答案位置标注模块、疑问词分类器、疑问词添加模块以及神经网络问题生成模型;
所述答案位置标注模块用于对原始输入文本中的答案词两边添加答案位置标记符,获得预处理后的数据;
所述疑问词分类器由预训练语言模型BERT和前馈神经网络FNN组成;采用预训练语言模型BERT对原始输入文提取特征向量C,并将提取的特征向量C输入至前馈神经网络FNN中,
所述前馈神经网络FNN对特征向量C进行映射,每个元素对应一个类别,再通过softmax函数,计算每个类别的概率,输出0-7中的概率最大的类别的id标识;
采用预处理后的数据对疑问词分类器进行训练和测试;并将预测后的疑问词通过疑问词添加模块添加到所述原始输入文本的句首,获得预测后的文本;
将所述预测后的文本映射为向量形式表示,即:将文本数值化为每个字符向量列连接成的数值矩阵;
所述数值矩阵输入到所述神经网络问题生成模型,通过该模型输出完整的问题。
本发明的有益效果:本发明所述的基于疑问词分类器的神经网络问题生成方法由两个模块组成,一个是疑问词分类器,另一个是基于端到端神经网络的问题生成模型,对包含答案的文本先输入到一个疑问词分类器,确定所生成的问题应该以何种疑问词提问最准确,然后将疑问词和原始文本一起输入到神经网络问题生成模型,模型能够自适应选择合理的疑问词展开提问,最终减小所生成问题和真实问题的差异,有效提高生成问题的质量。
本发明所述的基于疑问词分类器的神经网络问题生成方法,将问题生成任务中的疑问词预测任务建模为独立的分类任务,利用现有较先进的预训练语言模型BERT实现该疑问词分类器,再将疑问词分类器与传统的神经网络问题生成模型相结合,将疑问词分类器预测的结果和原始文本输入到问题生成模型中,生成完整的问题。疑问词分类器可以有效提高生成疑问词的准确率和可解释性。
附图说明
图1为现有基于最大输出指针(Maxout Pointer)和门控自注意力网络(GatedSelf-attention Networks)的问题生成模型示意图。
图2为本发明所述的基于疑问词分类器的神经网络问题生成方法中基于BERT的文本分类模型的示意图。
图3为本发明所述的基于疑问词分类器的神经网络问题生成方法中前馈神经网络示意图。
图4为本发明所述的基于疑问词分类器的神经网络问题生成系统的原理框图。
具体实施方式
具体实施方式一、结合图2和图3说明本实施方式,基于疑问词分类器的神经网络问题生成方法,该方法由以下步骤实现:
步骤一、将语料按照真实疑问词的类别进行划分,通过降采样和过采样使得每个类别的样本数量达到均衡;
将常见的疑问词分成8个类别,数字0-7表示对应类别id::what(0)、which(1)、who(2)、when(3)、where(4)、how(5)、why(6)、other(7),其中other是指以助动词和情态动词为疑问词的类别。对于样本数量较少的类别通过降采样方法,即通过重复利用,补充到与其它类别数量相同。对于数量较多的类别,通过过采样方法随机抽取部分样本,直到与其它类别数量相同。本实施方式中利用大规模的斯坦福问答数据集(SQuAD:The Stanford QuestionAnswering Dataset),得到样本总量为3.2万的可用数据集,每个类别的样本数量为4000条。
步骤二、数据集预处理,对原始输入文本中的答案词两边添加答案位置标记符,目的是使得模型识别答案特征,有针对性地进行分类任务;
本实施方式中,添加答案位置标记符是在答案词的前后添加“[ANS]”标记符,并且将[ANS]标记符作为一个特殊单词添加到词表中。如:[ANS]The owner[ANS]produces alist of requirement for…,其中The owner为答案词。目的为了让模型能知道哪个词是答案,以针对性的提出问题。
步骤三、构建疑问词分类器,疑问词分类器由预训练语言模型BERT和一个前馈神经网络组成;构建疑问词分类器的具体步骤如下:
S1、BERT模型为文本特征提取器,对于输入文本提取特征,并以向量的形式输出,记为C。具体而言,本文采用的BERT模型是BERT-Base-Uncased模型,该模型由12层transformer组成,隐藏向量维度为768,共110M个参数,Uncased是指输入文本不区分大小写。
S2、将BERT提取到的特征向量C输入到FNN中,首先通过一个可训练参数矩阵W
P=softmax(W
本实施方式中,构建疑问词分类器,疑问词分类器是由BERT模型和一个前馈神经网络的组合。BERT是谷歌AI团队于2018年10月发布的预训练模型,被认为是NLP领域的极大突破,刷新了11个NLP任务的当前最优结果。BERT的全称是Bidirectional EncoderRepresentation from Transformers,即基于Transformers的双向编码表征模型通过左、右两侧上下文来预测当前词和通过当前句子预测下一个句子,预训练的BERT表征可以仅用一个额外的输出层进行微调,在不对任务特定架构做出大量修改条件下,就可以为很多任务创建当前最优模型。BERT基于Transformers的双向编码表征模型,该模型的主要创新点都在预训练方法上,即用了掩蔽语言模型(MaskedLM)和下一句预测(Next SentencePrediction)两种方法分别捕捉词语和句子级别的表示。如图2所示,是基于BERT的文本分类模型,模型最终将[CLS]标记符对应的输出向量C作为输入文本的语义特征表示,再输入到一个前馈神经网络进行分类。
设定Tok
本实施方式中,前馈神经网络(feedforward neural network,FNN),简称前馈网络,是人工神经网络的一种。如图3所示,前馈神经网络采用一种单向多层结构。其中每一层包含若干个神经元。在此种神经网络中,各神经元可以接收前一层神经元的信号,并产生输出到下一层。第0层叫输入层,最后一层叫输出层,其他中间层叫做隐含层(或隐藏层、隐层)。隐层可以是一层,也可以是多层。图中,x
步骤四、将步骤二预处理后的数据划分为训练集、评估集和测试集,训练疑问词分类器,并测试分类器的性能;
将数据集按照7:2:1的比例划分为训练集、评估集和测试集,对疑问词分类器进行训练,即对BERT模型进行微调(fine-tune),使BERT模型自适应本次疑问词分类任务。至此,一个疑问词分类器训练完成。之后,采用测试集对其进行性能测试。
步骤五、将疑问词分类器预测得到的疑问词添加到原始输入文本的句首;
步骤六、利用词向量映射表,将步骤五所得文本映射为向量表示,输入的文本即数值化为每个字符向量列连接而成的数值矩阵;
所述词向量映射表采用Glove词表,将每个单词用词表中的向量进行表示,每个词向量维度为300。如果单词不在词向量表中,则随机初始化为一个300维的向量。假设输入文本长度为M,则数值矩阵大小为M×300。
步骤七、将数值矩阵输入到神经网络问题生成模型,输出完整的问题。
采用的神经网络问题生成模型为较为先进的基于门控自注意力的段落级问题生成模型,在该模型的基础上对比添加疑问词分类器前后的结果,表明疑问词分类器的有效性。
本实施方式中,通过构建一个基于BERT模型和前馈神经网络的疑问词分类器。通过大规模问答数据集Squad训练该疑问词分类器。在传统的神经网络问题生成模型之前,添加疑问词分类器,目的是在直接生成之前,先识别以哪种疑问词进行提问,提高了疑问词生成的准确率和可解释性,从而提高了问题的质量。
具体实施方式二、结合图4说明本实施方式,本实施方式为具体实施方式一所述的基于疑问词分类器的神经网络问题生成方法的生成系统,该生成系统包括答案位置标注模块、疑问词分类器、疑问词添加模块以及神经网络问题生成模型;
所述答案位置标注模块用于对原始输入文本中的答案词两边添加答案位置标记符,获得预处理后的数据;
所述疑问词分类器由预训练语言模型BERT和前馈神经网络FNN组成;采用预训练语言模型BERT对原始输入文提取特征向量C,并将提取的特征向量C输入至前馈神经网络FNN中,
所述前馈神经网络FNN对特征向量C进行映射,每个元素对应一个类别,再通过softmax函数,计算每个类别的概率,输出0-7中的概率最大的类别的id标识;
采用预处理后的数据对疑问词分类器进行训练和测试;并将预测后的疑问词通过疑问词添加模块添加到所述原始输入文本的句首,获得预测后的文本;
将所述预测后的文本映射为向量形式表示,即:将文本数值化为每个字符向量列连接成的数值矩阵;
所述数值矩阵输入到所述神经网络问题生成模型,通过该模型输出完整的问题。
本实施方式在神经网络问题生成任务的基础上,将疑问词预测任务建模为一个独立的分类任务,即在神经网络问题生成模型之前,引入一个疑问词分类器,先通过疑问词分类器识别最可能提问的疑问词,再生成完整的问题。目的是提高疑问词生成的准确率和可解释性,最终减小所生成问题和真实问题的差异,提高问题的质量。疑问词分类器由大规模预训练模型BERT和一个前馈神经网络组成。将常见疑问词划分为8类,对大规模问答数据集SQuAD进行数据预处理,得到符合该分类任务的数据集,然后训练并测试疑问词分类器。将疑问词分类器预测的疑问词添加到原始输入文本中,输入到神经网络问题生成模型,最终生成完整的问题。疑问词分类器可以提高疑问词生成的准确率和可解释性,从而提高生成问题的质量。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 基于疑问词分类器的神经网络问题生成方法及生成系统
- 一种基于问题生成和卷积神经网络的常识问答方法