基于积分强化学习的多消防巡检协作机器人系统
文献发布时间:2023-06-19 11:55:48
技术领域
本发明属于机器人领域,涉及基于积分强化学习的多消防巡检协作机器人系统。
背景技术
目前常见的消防巡检机器人主要结构为:在驱动方面采用轮式驱动;在机器人的四周安装火焰探测器和温度传感器以便于火情的检测;机器人前方配备摄像头以便将巡检画面通过无线模块传输到控制室;在机器人上方还安装了底盘固定但可旋转的消防喷头,用于外接水管或小型水泵实现对着火点的扑灭;在机器人控制方面,随着多机协同思想和理论的发展,为了完成对大型区域的巡检,同时为了提高巡检效率和降低巡检难度性,通常会采用多个消防巡检机器人相互配合完成作业,在多消防巡检机器人的协同控制上采用集中式控制的方式,即通过一个主控程序,完成对所有机器人的巡检任务分配以及工作调度,巡检实现具体方式是将事先将使用激光雷达构建好的地图和规划好的巡检路线经过区域划分后分别导入到各个机器人的内部,每个机器人启动后便会自动按照它们所获取到的规划路线对地图上标注的重点区域进行巡检,另外在需要远程完成一些特定的灭火或巡检操作时,由消防人员通过遥控器远程进行操作。
但上述系统也存在许多缺陷,首先轮式驱动使得机器人在应对阶梯和崎岖路面的通过性能较差,且转向和旋转的灵活性不够高;而且利用火焰探测器和温度传感器对火焰检测的准确度和及时性不能得到很好的保证,且火焰检测的范围也较小;其次在检测到火焰之后,只能实现报警功能和将着火点的位置和通过摄像头获取到达火情状况图像传输到消防控制室,少数的消防巡检机器人还可以配合自身携带的消防喷头,在消防人员的远程遥控下实现对着火点的扑灭,但总体来说缺乏在火情应对方面的灵活性和主动性;最后在多机器人协作控制方面,集中式控制的方式使得每个单独的机器人没有自己选择动作和相互协调的能力,使得整个系统的巡检效率、鲁棒性和可扩展性都较差,而且每个机器人在巡检过程中的时间最优和能量最优也不能得到保证,这样会降低整体的续航能力和对外界的抗扰动能力,且在自主控制方面和智能化程度上还有待提高。
发明内容
有鉴于此,本发明的目的在于提供一种基于积分强化学习的多消防巡检协作机器人系统。
为达到上述目的,本发明提供如下技术方案:
基于积分强化学习的多消防巡检协作机器人系统,包括硬件层、交互层、感知层和控制层;
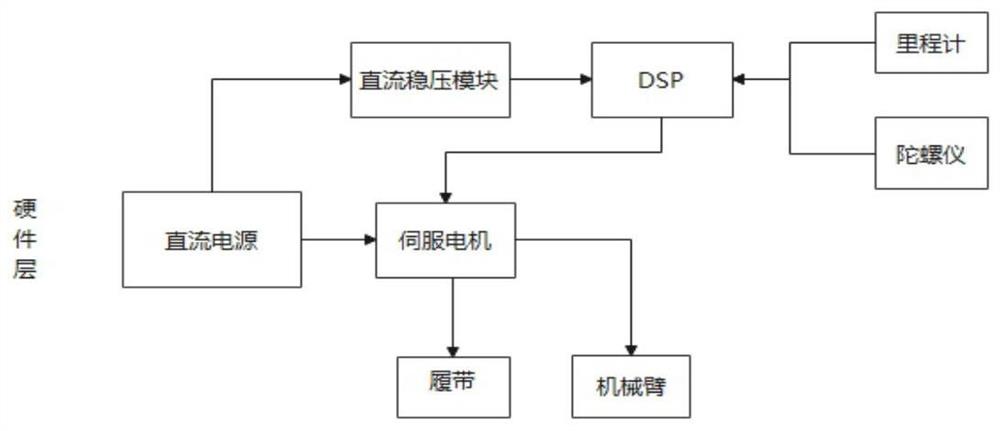
所述硬件层采用DSP作为控制器,将里程计和陀螺仪采集到的数据送入DSP内部进行处理,实时计算出机器人在巡检地图中的位置。通过上位机向DSP发送速度指令,DSP将获取到速度信息编码后以控制伺服电机的运转;消防巡检机器人采用的是履带式驱动;当机械臂需要动作时,由上位机中的ros系统通过在moveit!平台对机械臂将要移动到的目标点进行运动轨迹规划,将规划好的运动轨迹离散化后发送到DSP中,DSP获得的各个轴的角速度、加速度后控制机械臂的伺服电机运动以到达目标点。
1、履带驱动系统
履带为两段,每段由单独的伺服电机驱动。前段履带用于在遇到较高障碍物时将机器人的底盘抬起以便顺利通过,通过调整前段履带来调整机器人的高度,为机械臂提供更大的操作半径;后半段履带主要起机器人的驱动作用,由一个伺服电机同轴驱动,转向时将一侧的履带进行减速制动即可。伺服电机的额定电压为24V,输出功率为100W,上层PC发布的x,y轴的速度信息通过DSP编码后转化伺服电机的转速,以实现转向和驱动。
2、机械臂伺服控制
机器人上方设置四轴的机械臂,机械臂前段设置能够转动的爪状夹持装置,夹持装置上设置灭火装置;加装灭火装置后配合机械臂实现对着火点实现精准扑灭;四轴的机械臂由四个伺服电机驱动每个轴的运动,每个轴的运动信息由上位机ros系统中的moveit!进行路径规划后产生。
①完成“眼在手外”下对机械臂的标定
通过“眼在手外”的标定形式完成将目标点在世界坐标系下的坐标到相对于机械臂坐标系的坐标变换。对与“眼在手外”的标定方式,机械手基座坐标系Tg到相机坐标系Tc的变换矩阵Tgc是恒定的,标定板坐标系Tb到机械臂末端坐标系Te的变换矩阵Tbe是恒定的,坐标变换的关系满足下式:
对第i个时刻:Tbc
第i+1个时刻:Tbc
整理得:(Teg
则A=(Teg
②利用moveit!完成对机械臂的运动轨迹规划
利用Moveit!将控制机械臂的各个独立功能部件组合起来,然后通过ROS中的action和service通信方式供用户使用。在moveit!中,创建一个符合机械臂真实尺寸和轴数的模型URDF模型,输入模型之后,利用moveit!的setup assistant按照自己的设定生成相应的配置文件,内容包括机械臂的碰撞矩阵以避免规划出的轨迹使得各轴之间发生碰撞,各个关节的连接信息以及定义的初始位置等。然后再添加机械臂的控制插件controller,controller包括定义follow_joint_trajectory节点和设置各个轴的名字,最后再编写程序实现PC与机械臂通过socket通信方式连接,通过订阅joint_state话题在rviz中观察到机械臂的实时运动轨迹。先由快速卷积神经网络完成对火焰的识别检测,识别成功后通过深度摄像头的点云数据得到着火点相对于机器人的三维坐标,再通过TF坐标变化就能得知机械臂末端需要到达的位置,之后由内部集成好的算法完成对轨迹的求解。求解出来的轨迹信息是由大量离散的点构成的,轨迹信息包括要达到该点每个轴的角速度、角加速度。当求解出的点足够多时,拟合出一条十分光滑的运动轨迹,将这些离散的点的信息通过话题发布和订阅之后使得机械臂按照规划的点平滑地运动至目标点。
所述感知层用于建图的激光雷达、避障的红外线传感器、检测火焰的火焰探测器、温度传感器和realsenseD435i深度摄像头、里程计和陀螺仪。
①红外传感器避障
利用红外传感器实时检测巡检机器人在巡检过程中遇到的障碍物,当前方有障碍物时,红外传感器检测出机器人与障碍物之间的欧几里得距离,将这些距离与DSP中获得的里程计和陀螺仪数据推算出障碍物的具体坐标。获取坐标后,立即由控制算法设计出避障路径,该避障路径是弧形的,并且在整个过程中要求保持与障碍物有一个最小距离,避障结束后,要立即回到先前规划好的最优巡检路径。
②基于快速卷积神经网络的火焰识别
采用快速卷积神经网络Faster R-CNN对火焰特征进行提取检测,步骤如下:
②-1:输入拍摄到的火焰图片;
②-2.:将图片送入卷积神经网络CNN中进行特征提取;
②-3:特征提取后特征映射,特征映射将共同作用于后续的全连接层和区域生成网络RPN;
②-3.1:特征映射进入RPN,首先经过一系列的区域候选建议框,将这些建议框再分别馈入到两个1×1的卷积层,其中第一个卷积层用于进行区域分类,即通过计算生成建议框的交并比IOU值来区分正负样本;另一个由于边界框回归判定,通过非最大化抑制后以生成更精确的目标检测框。
②-3.2:特征映射进入ROI池化层,用于后续网络的计算。
②-4:将池化后的特征映射经过全连接层后,再次利用softmax对建议框进行分类,识别检测框框中的是否为物体,对建议框再次进行边界框回归判定。
RPN生成检测框的具体方法是通过一个滑动框对输入特征映射上滑动,在每个像素点上生成9个建议框,这些建议框的大小为128
其中x,y为像素点坐标,F(x,y)表示生成的火焰颜色掩码,为1则该像素点生成建议框,0则不生成,m
另外利用边界回归判定去修正检测框的原理为将原始的建议框A经过映射G得到一个更接近真实情况的回归建议框F。这种映射G通过平移和缩放得到:
先平移:F
F
再缩放:F
F
其中x,y,w,h分别表示建议框的中心坐标,宽、高,d
输出是识别为火焰的概率。
所述交互层为:在巡检过程中需要实时将摄像头所捕捉到的画面通过无线网络发送到控制室和移动终端,并配套开发有相应的APP,在远程终端对巡检机器人进行相应的控制,以实现操作人员对想要再次巡检的区域的巡查。在检测到火焰后,立即向控制室发出警报信号并且能立即自动的做出相应的灭火措施。在实施灭火措施之后,若火情仍然得不到抑制,即将自动模式切换到远程操控模式,由控制室内的专业人员全面接管巡检机器人的控制,手动控制履带运转和机械臂动作以实现对着火点的精准扑灭,并根据火情判断是否需要做出切断电源、关闭燃气阀门、转移易燃物操作。将每个巡检机器都能人与整个消防系统进行并网,若采取措施后火情仍然较大,向控制室发出接管消防网络的请求,在得到控制室同意下或消防控制室一分钟内未做出应答,将建筑内局部的喷淋管网打开,同时发出全面消防警报,打开所有消防通道与应急照明设施。在机器人顶端安装急停按键。在火情扑灭后,将着火点在巡检地图上标注为重点巡检区域。
所述控制层为:
设整个消防巡检区域下共有N个机器人协同巡检,N个机器人从各自的初始位置(x
则考虑第i个消防巡检机器人的二阶线性动力学模型为:
其中系统矩阵为A,输入矩阵为B,输出矩阵为C,干扰矩阵为D,
将全局动力学模型写为:
其中
为使N个消防巡检机器人在未知的扰动下实现在连续时间、连续状态和控制输入空间中的最小时间和能量的最优控制,并且在整个过程中要避免碰撞,考虑以下成本函数:
其中ζ>0,用于表示巡检过程中时间的比重,R为正定矩阵。为求解机器人最小到达时间T未知的路径规划问题,引入双曲正切函数将成本函数改写成无穷积分的形式以便求解,另外为避免执行器饱和,还想要对输入进行约束,因此将常见的U(t)
V(X(t),U(t))=∫
其中ζ为正常数,tanh为双曲正切函数,该函数为单调递增的奇函数且连续可微,成本函数是IRL可解的形式。将ζ改写为ζtanh(L(t)-L
将U(t)
其中输入约束为|U(t)|≤λ,λ和σ均为正常数,R=diag(r
为避免任何一对巡检机器人发生碰撞,加入人工势场函数f
其中s越大则排斥函数的陡度就越大,σ越大排斥范围也越大。为捕捉排斥距离r
f
其中0<K
通过权重矩阵Λ
Λ
当机器人原理目标点时Λ
下面利用(4-4)中的成本函数求解最优控制输入,(4-4)式两边对t求导,贝尔曼方程写为:
V(x(t)),U(t))=-ζtanh(L(t)-L
令F
V*(X(t),U(t))=min∫
根据(4-10)式定义HJB方程为:
其中
在稳定性条件下有
移项后得最优控制输入u
将(4-14)代入到(4-5)中得:
其中l为全为一的列向量,将(4-14)代入(4-15)中得:
其中
利用基于积分强化学习的策略迭代算法求解HJB方程,积分强化学习使用(t,t+T)内的信号用于学习,不需要知道系统具体的动力学模型。
首先将值函数改写成积分差值的形式,得到如下的贝尔曼方程:
为能够在线实时地求解(4-18),引入actor-critic神经网络算法来实现策略迭代过程中的实时更新。首先通过critic神经网络对值函数V(X)进行近似逼近,因为
而其中第一项为易求得的二次型,只对第二项进行逼近,并设
其中w
将(4-20)两边对X求微分得:
将(4-20)代入到(4-18)中得到新的贝尔曼方程:
其中ε
为确定w
其中
令
将(4-25)式两边对
其中β
将E
将得到的理想权重系数代入到(4-14)中可得最优控制策略,然而通过critic逼近的值函数所求得的最优策略却并不能保证闭环系统的稳定性,要为执行器引入actor神经网络来保证收敛到最优解的同时还能够保证系统的稳定性:
当w
其中K
基于(4-19)、(4-27)、(4-28)和(4-30)式,分别利用critic和actor算法实现对值函数和策略函数的同步更新,设计一种基于策略迭代的在线积分强化学习算法来求解HJB方程,以求解最优控制输入。
算法:基于策略迭代的在线IRL算法
初始化:给定一个可行的执行器输入
Step1:策略评估,给定初始
Step2:策略改进,将
Step3:令
本发明的有益效果在于:
1.本发明在多消防巡检协作机器人系统中采用分布式控制方式,使得系统下各个机器人的自主性、灵活性、可靠性和响应速度都得到了提高。
2.本发明在每个消防巡检机器人的顶部设计了一款四轴的机械臂,利用该机械臂配合特制的灭火器可以在发现火情之后自主对着火点做出精准扑灭,还可以由消防人员远程手动控制机械臂完成关闭电源开关、燃气阀门和移除可燃物等操作,显著提高了在发现火情后的主动性与可操作性。
3.本发明为更加精准地识别火焰、降低虚警率,配合深度摄像头realsense D435i获取到的画面,提出了一种基于视觉识别的改进快速卷积神经网络完成对火焰的识别检测,同时引入通过引导锚定的方法使得快速卷积神经网络中的RPN检测速度得到了提高。
4.本发明在控制器算法中设计的近似值函数可以将最优路径规划问题中最小到达时间T未知的有限积分转化成无穷积分的形式以便于求解,并引入了非二次型性能函数用于逼近最小能量成本和捕获输入约束。
5.本发明引入了人工势场函数来避免多消防巡检协作机器人系统在巡检过程中机器人之间发生碰撞,并设计了一个特殊的权重系数矩阵来抵消非零尾部。
6.本发明在多机器人控制算法中使用积分强化学习算法以解决巡检机器人系统矩阵未知的问题,并利用critic和actor神经网络算法在线实时同步迭代求解贝尔曼方程以获得最优策略,显著地提高了多消防巡检协作机器人系统的巡检效率与鲁棒性。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
图1为硬件底层图;
图2为坐标变换示意图;
图3为运动轨迹生成流程图;
图4为消防巡检机器人避障流程图;
图5为快速卷积神经网络训练过程;
图6为消防巡检机器人交互结构;
图7为消防巡检机器人整体结构图;
图8为多消防巡检协作机器人系统巡检示意图;
图9为操作机械臂扑灭火情工作流程图;
图10为消防巡检机器人工作流程图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
针对每个单独的消防巡检机器人,本发明为快速准确地发现火情,在配合火焰探测器和温度传感器的基础上加入了深度摄像头realsense D435i,该深度摄像头可以通过对场景的特征提取,实现较远距离的火情识别,且识别准确度和快速性与传感器相比都有所提高。同时该深度摄像头将巡检图像实时传输到主控室与移动终端便于控制人员观察,且可以随时接受控制室和移动终端发出的控制指令。巡检机器人发现火情后应立即向主控室发出警报信号,但这远远不够,因此为了提高巡检机器人发现火情后的处理能力,在机器人的上方还装配了一个四轴的机械臂,该机械臂前端配有夹爪,设置为夹爪装可以有利于后续设备添加;可以在发现火情之后,在必要情况下,可以在消防人员远程控制下通过机械臂完成对电源的切断、燃气阀门和可燃物的移除等工作。另外可以在机械臂的夹爪处安装特制的灭火装置(如特制的小型灭火器)以配合机械臂实现对着火点的精确扑灭,从而在最大程度上避免火势蔓延,造成更大的经济损失。
在多消防巡检机器人协同控制上,要求多机器人在巡检过程中要完成在避碰、执行器输入存在约束、外界扰动未知下可以做到最小到达时间T未知的最优在线路径规划,另外整个系统的巡检效率、鲁棒性和可扩展性都要得到保证,且整个巡检过程中机器人之间不能发生碰撞。
为达到上述要求,本发明的软硬件设计方案如下:
本发明设计的新型多消防巡检协作机器人系统采用分层设计的思想,分别由硬件层、交互层、感知层和控制层组成,第一部分至第三部分介绍整个多消防巡检协作机器人系统下每个机器人的具体软硬件结构,第四部分介绍实现多消防巡检协作机器人系统的具体控制算法实现。
第一部分消防巡检机器人的硬件层设计
硬件层由DSP作为控制器,将里程计和陀螺仪采集到的数据送入DSP内部进行处理,可以实时计算出机器人在巡检地图中的位置。通过上位机向DSP发送速度指令,DSP将获取到速度信息编码后以控制伺服电机的运转;消防巡检机器人采用的是履带式驱动旨在提高消防巡检机器人的复杂路段的通过能力(如阶梯)与转向灵活性。当机械臂需要动作时,由上位机中的ros系统通过在moveit!平台对机械臂将要移动到的目标点进行运动轨迹规划,将规划好的运动轨迹离散化后发送到DSP中,DSP获得的各个轴的角速度、加速度后控制机械臂的伺服电机运动以到达目标点。
硬件层的底层设计发案图如图1所示。
1、履带驱动系统
为适应各种巡检环境,提高巡检过程中的灵活性与通过性,该巡检机器人采用了履带式驱动。履带结构设计成两段,每段由单独的伺服电机驱动。前段履带主要用于在遇到较高障碍物时可以将机器人的底盘抬起以便顺利通过,另外还可以通过调整前段履带来调整机器人的高度,可以为机械臂提供更大的操作半径;后半段履带主要起机器人的驱动作用,由一个伺服电机同轴驱动,转向时将一侧的履带进行减速制动即可。伺服电机的额定电压为24V,输出功率为100W,上层PC发布的x,y轴的速度信息通过DSP编码后转化伺服电机的转速,以实现转向和驱动。
2、机械臂伺服控制
为提高巡检机器人发现火情时的处理能力,在机器人上方安装了一个四轴的机械臂。该机械臂前段安装了一个可以转动的爪状夹持装置,可以根据具体需要在夹持装置上安装特制的小型灭火装置(如灭火器和小型水泵等)。加装灭火装置后可以配合机械臂实现对着火点实现精准扑灭;未加装灭火装置也可以在发现火情时,根据火情程度,决定是否由消防人员手动控制机械臂将局部电源切断、关闭燃气阀门、将周围的易燃物移除和将防火门关闭等,争取在最大程度上阻止火势蔓延,减小经济损失。四轴的机械臂由四个伺服电机驱动每个轴的运动,每个轴的运动信息由上位机ros系统中的moveit!进行路径规划后产生。
①完成“眼在手外”下对机械臂的标定
通过“眼在手外”(Eye-To-Hand)的标定形式完成将目标点在世界坐标系下的坐标到相对于机械臂坐标系的坐标变换。对与“眼在手外”的标定方式,机械手基座坐标系Tg到相机坐标系Tc的变换矩阵Tgc是恒定的,标定板坐标系Tb到机械臂末端坐标系Te的变换矩阵Tbe是恒定的,坐标变换的关系满足下式:
对第i个时刻:Tbc
第i+1个时刻:Tbc
整理得:(Teg
则A=(Teg
坐标变换的示意图如图2所示。
②利用moveit!完成对机械臂的运动轨迹规划
ROS(Robot Operating System)是专门用于实现机器人系统控制的操作系统,可在Linux环境下进行开发,由于其操作方式简单、功能强大、可扩展能力强,尤其适用于机器人这种具有复杂、多节点的控制系统。在机械臂控制中,ROS系统中有专门的集成工具用于完成机械臂的运动轨迹规划,它就是moveit!。Moveit!可以看作是一个“集成器”,利用它可以将控制机械臂的各个独立功能部件组合起来,然后通过ROS中的action和service通信方式供用户使用。在moveit!中,先要创建一个符合机械臂真实尺寸和轴数的模型(URDF模型),输入模型之后,利用moveit!的setup assistant按照自己的设定生成相应的配置文件,内容包括机械臂的碰撞矩阵以避免规划出的轨迹使得各轴之间发生碰撞,各个关节的连接信息以及定义的初始位置等。然后再添加机械臂的控制插件(controller),该controller主要包括定义follow_joint_trajectory节点和设置各个轴的名字,最后再编写程序实现PC与机械臂通过socket通信方式连接,通过订阅joint_state话题可以在rviz中观察到机械臂的实时运动轨迹。先由快速卷积神经网络完成对火焰的识别检测,识别成功后通过深度摄像头的点云数据可以得到着火点相对于机器人的三维坐标,再通过TF坐标变化就能得知机械臂末端需要到达的位置,之后由内部集成好的算法(通常采用三次样条插补)立即完成对轨迹的求解。求解出来的轨迹信息是由大量离散的点构成的,这些点的信息包括要达到该点每个轴的角速度、角加速度。当求解出的点足够多时,就能拟合出一条十分光滑的运动轨迹,将这些点的信息通过话题发布和订阅之后就可以使得机械臂按照规划的点平滑地运动至目标点。Moveit!生成运动轨迹的流程图如图3所示。
第二部分消防巡检机器人感知层设计
消防巡检机器人的感知层设计主要包括用于建图的激光雷达、避障的红外线传感器、检测火焰的火焰探测器、温度传感器和realsenseD435i深度摄像头、里程计和陀螺仪等。
①红外传感器避障
利用红外传感器实时检测巡检机器人在巡检过程中遇到的障碍物,当前方有障碍物时,红外传感器可以检测出机器人与障碍物之间的欧几里得距离,将这些距离与DSP中获得的里程计和陀螺仪数据就可以推算出障碍物的具体坐标。获取坐标后,可以立即由控制算法设计出避障路径,该避障路径通常是弧形的,并且在整个过程中要求保持与障碍物有一个最小距离,避障结束后,要立即回到先前规划好的最优巡检路径。避障流程图如图4所示。
②基于快速卷积神经网络的火焰识别
在巡检过程中,对火焰的检测是尤为关键的,随着计算机技术的快速发展,利用视觉对火焰进行检测比固定的火焰探测器更加的快速准确。但由于在巡检场景下存在较多与火焰颜色相似的物体,且火焰的形状和纹理较为多样,因此在图像中检测火焰的位置是一项较为困难的任务。本发明采用快速卷积神经网络(Faster R-CNN)对火焰特征进行提取检测,不仅可以准确的识别出火焰,还能精确的计算出火焰产生的位置,可以最大程度上的降低火焰检测的虚警率。
该快速卷积神经网络的训练步骤如下:
②-1.输入拍摄到的火焰图片;
②-2.将图片送入卷积神经网络(CNN)中进行特征提取;
②-3.特征提取后特征映射(featuremaps),这些特征映射将共同作用于后续的全连接层和RPN(区域生成网络);
②-3.1特征映射进入RPN,首先经过一系列的区域候选建议框,也就是锚(anchors),将这些建议框再分别馈入到两个1×1的卷积层,其中第一个卷积层用于进行区域分类,即通过计算生成建议框的IOU(交并比)值来区分正负样本;另一个由于边界框回归判定,通过非最大化抑制后以生成更精确的目标检测框。
②-3.2特征映射进入ROI池化层,用于后续网络的计算。
②-4.将池化后的特征映射经过全连接层后,会再次利用softmax对建议框进行分类,即识别检测框框中的是否为物体,同时为了进一步提高目标检测框的精确度,会对建议框再次进行边界框回归判定。
训练过程示意图如图5所示。
上述步骤利用RPN生成检测框(anchors)是FasterR-CNN相比与传统检测算法的最大优势。RPN生成检测框的具体方法是通过一个滑动框对输入特征映射上滑动,在每个像素点上生成9个建议框,这些建议框的大小可以为128
其中x,y为像素点坐标,F(x,y)表示生成的火焰颜色掩码,为1则该像素点生成建议框,0则不生成,m
另外利用边界回归判定(boundingboxregression)去修正检测框的原理为将原始的建议框A经过映射G得到一个更接近真实情况的回归建议框F。这种映射关系G通常可以通过平移和缩放得到:
先平移:F
F
再缩放:F
F
其中x,y,w,h分别表示建议框的中心坐标,宽、高,d
输出是识别为火焰的概率。
第三部分消防巡检机器人交互层设计
在巡检过程中需要实时将摄像头所捕捉到的画面通过无线网络发送到控制室和移动终端,并配套开发有相应的APP,可以随时随地在PC、web、手机、pad等终端接受到巡检画面和报警信号,并可以在远程终端对巡检机器人进行相应的控制,以实现操作人员对想要再次巡检的区域的巡查。在检测到火焰后,应该立即向控制室发出警报信号并且能立即自动的做出相应的灭火措施。在实施灭火措施之后,若火情仍然得不到抑制,应该能够立即将自动模式切换到远程操控模式,由控制室内的专业人员全面接管巡检机器人的控制,手动控制履带运转和机械臂动作以实现对着火点的精准扑灭,并根据火情判断是否需要做出切断电源、关闭燃气阀门、转移易燃物等操作。另外,可将每个巡检机器都能人与整个消防系统进行并网,若采取措施后火情仍然较大,均可以向控制室发出接管消防网络的请求,在得到控制室同意下或消防控制室一分钟内未做出应答,可以将建筑内局部的喷淋管网打开,同时发出全面消防警报,打开所有消防通道与应急照明设施,以便最大程度的减少财产损失和人员伤亡和为救援争取宝贵时间。同时为了避免巡检机器人的在巡检过程中的突发故障,应该在机器人顶端安装急停按键,避免对周围人员造成伤害。在火情扑灭后,会将该着火点在巡检地图上标注为重点巡检区域,以便后期巡检。消防巡检机器人的交互结构示意图如图6所示。
第四部分多消防巡检协作机器人系统控制算法
由于通常的消防巡检任务都需要由多个机器人协同完成,且在整个多机器人控制过程中要求实现在巡检过程中最小到达时间下的最优路径规划,这样才能在保证对巡检范围全面覆盖的同时又可以保证多机器人巡检系统的续航时间;且在巡检过程中通常对巡检环境存在的干扰是未知的。另外为避免执行器饱和,一般都要求对执行器的输入进行约束;同时为了安全起见,整个巡检过程中机器人之间不能发生碰撞。针对上述多消防巡检协作机器人系统的控制要求,需要设计一款最小到达时间T和对外界扰动未知、系统部分模型未知、输入存在约束,且要求机器人二者之间能避免碰撞,另外对于实际情况下很难采取到精确的外部信息,因此要将离线求解改为在线求解,所以本发明设计了一款基于积分强化学习和AC神经网络算法的最优控制器。
设整个消防巡检区域下共有N个机器人协同巡检,N个机器人从各自的初始位置(x
则考虑第i个消防巡检机器人的二阶线性动力学模型为:
其中系统矩阵为A,输入矩阵为B,输出矩阵为C,干扰矩阵为D,
将全局动力学模型写为:
其中
为了使N个消防巡检机器人可以在未知的扰动下实现在连续时间、连续状态和控制输入空间中的最小时间和能量的最优控制,并且在整个过程中要避免碰撞,因此考虑以下成本函数:
其中ζ>0,用于表示巡检过程中时间的比重,R为正定矩阵。为求解机器人最小到达时间T未知的路径规划问题,引入双曲正切函数将成本函数改写成无穷积分的形式以便求解,另外为避免执行器饱和,还想要对输入进行约束,因此将常见的U(t)
V(X(t),U(t))=∫
其中ζ为正常数,tanh为双曲正切函数,该函数为单调递增的奇函数且连续可微,因此改写之后的成本函数依旧是IRL可解的形式。将ζ改写为ζtanh(L(t)-L
又因为机器人系统通常对输入有约束,所以将常见的U(t)
其中输入约束为|U(t)|≤λ,λ和σ均为正常数,R=diag(r
为了避免任何一对巡检机器人发生碰撞,我们加入了人工势场函数f
其中s越大则排斥函数的陡度就越大,σ越大排斥范围也越大。为了捕捉排斥距离r
f
其中0<K
通过权重矩阵Λ
Λ
可以看出,当机器人原理目标点时Λ
下面利用(4-4)中的成本函数求解最优控制输入,显然V可微,(4-4)式两边对t求导,所以贝尔曼方程可写为:
V(x(t),U(t))=-ζtanh(L(t)-L
令F
V
根据(4-10)式定义HJB方程为:
其中
在稳定性条件下有
移项后可得最优控制输入u
将(4-14)代入到(4-5)中得:
其中l为全为一的列向量,将(4-14)代入(4-15)中得:
其中
但在实际情况下,HJB方程很难直接求解,且由于系统模型部分未知,HJB方程中的
首先将值函数改写成积分差值的形式,可得到如下的贝尔曼方程:
为了能够在线实时地求解(4-18),引入了actor-critic神经网络算法来实现策略迭代过程中的实时更新。首先通过critic神经网络对值函数V(X)进行近似逼近,因为
而其中第一项为易求得的二次型,因此只需要对第二项进行逼近,并设
其中w
将(4-20)两边对X求微分可得:
将(4-20)代入到(4-18)中可以得到新的贝尔曼方程:
其中ε
但由于critic神经网络的系数w
其中
令
将(4-25)式两边对
其中β
将E
将得到的理想权重系数代入到(4-14)中可得最优控制策略,然而通过critic逼近的值函数所求得的最优策略却并不能保证闭环系统的稳定性,因此要为执行器引入actor神经网络来保证收敛到最优解的同时还能够保证系统的稳定性:
可以证明,当w
其中K
基于(4-19)、(4-27)、(4-28)和(4-30)式,分别利用critic和actor算法实现对值函数和策略函数的同步更新,设计一种基于策略迭代的在线积分强化学习算法来求解HJB方程,以求解最优控制输入。
算法:基于策略迭代的在线IRL算法
初始化:给定一个可行的执行器输入
Step1:策略评估,给定初始
Step2:策略改进,将
Step3:令
消防巡检机器人整体结构图如图7所示。
多消防巡检协作机器人系统巡检示意图如图8所示。
其中整个正方形框为待巡检的区域,虚线为区域划分线,浅色五角星表示重点巡检区域,深色五角星表示火情发现点,双向箭头表示机器人之间存在信息交互。
操作机械臂扑灭火情工作流程图如图9所示。
消防巡检机器人工作流程图如图10所示。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 基于积分强化学习的多消防巡检协作机器人系统
- 一种基于强化学习的多组机器人协作控制方法及控制系统