一种多元时间序列检索方法及系统
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及时间序列检索领域,特别是涉及一种多元时间序列检索方法及系统。
背景技术
多元时间序列广泛的存在于我们的日常生活及实际应用中,如可穿戴设备、磁盘监控以及状态监控等。随着计算机技术和传感器技术的不断发展,多元时间序列的数据量越来越庞大。因此,基于多元时间序列的研究也面临着较大的挑战。其中,对于给定的一个时间序列,从以往时间序列中检索出相似片段这一技术(时间序列检索)广泛应用于状态识别、异常检测等领域,是一个极为重要的研究方向。
目前,针对时间序列检索已经有了较多的研究。已有的研究工作主要采用支持离散傅里叶变换(DFT)、离散小波变换(DWT)等传统机器学习方法以及长短期记忆网络(LSTM)等基本的神经网络对时间序列进行编码表示,采用欧氏距离或动态时间规整(DTW)等方法,通过计算特征空间中的成对距离度量时间序列的相似性度。这些方法在实验一元时间序列检索方面取得了一定的成果,但是面对复杂的多元时间序列数据,这些方法的效果并不理想:第一,一元时间序列仅有一个属性,而多元时间序列具有多重属性,现有方法不能学习到多元时间序列多个属性之间的相关性;第二,现有的相似性度量方法计算复杂,当时间序列片段较长时需要花费很大的计算成本;第四,现有方法只是简单对根据时间序列的特征进行编码,而且编码后的时间序列很复杂,不仅需要依赖专业人员的先验知识,而且进一步加大了相似性度量的计算量,增大了出错率。
因此,如何减少多元时间序列检索过程中的计算量,提高多元时间序列检索的速度和准确性,是亟待解决的问题。
发明内容
本发明的目的是提供一种多元时间序列检索方法及系统,能够减少多元时间序列检索过程中的计算量,提高多元时间序列检索的速度和准确性。
为实现上述目的,本发明提供了如下方案:
一种多元时间序列检索方法,包括:
获取测试集和待检索多元时间序列;所述测试集包括多个编码后的测试时序特征矩阵;所述编码后的测试时序特征矩阵是将测试多元时间序列输入训练后的编码器后得到的;
将所述待检索多元时间序列输入所述训练后的编码器中,得到编码后的待检索时序特征矩阵;
分别计算所述待检索时序特征矩阵与每个所述测试时序特征矩阵之间的汉明距离;
将所述汉明距离进行升序排列,并将前预设个数的汉明距离所对应的测试多元时间序列均确定为所述待检索多元时间序列的相似多元时间序列;
根据所述相似多元时间序列的状态确定所述待检索多元时间序列所表征的状态。
可选的,在获取测试集和待检索多元时间序列之后,还包括:
获取样本集;所述样本集包括多个真多元时间序列;
将所述样本集划分为训练集和验证集;
使用所述训练集对所述编码器进行训练,得到训练后的编码器;
使用所述验证集对所述训练后的编码器进行验证,判断调整超参数的次数是否达到第一预设迭代次数;若否,则调整超参数并执行步骤“使用所述训练集对所述编码器进行训练,得到训练后的编码器”;若是则输出训练后的编码器。
可选的,所述使用所述训练集对所述编码器进行训练,得到训练后的编码器,具体包括:
构建对抗网络;所述对抗网络包括编码器、解码器和鉴别器;
将随机二进制编码和均匀随机分布的连接输入所述解码器,得到多个假多元时间序列;
将多个所述真多元时间序列和多个所述假多元时间序列均输入所述鉴别器中进行训练,调整所述鉴别器的参数直至对抗损失函数小于第一阈值;
将多个所述真多元时间序列输入所述编码器中进行训练,根据所述鉴别器的鉴别结果调整所述编码器的参数直至相似对损失函数小于第二阈值,执行步骤“将多个真多元时间序列随机输入所述解码器,得到多个假多元时间序列”直至迭代次数达到第二预设迭代次数。
可选的,所述相似对损失函数为:
式中,s
一种多元时间序列检索系统,包括:
数据获取模块,用于获取测试集和待检索多元时间序列;所述测试集包括多个编码后的测试时序特征矩阵;所述编码后的测试时序特征矩阵是将测试多元时间序列输入训练后的编码器后得到的;
待检索时序特征矩阵编码模块,用于将所述待检索多元时间序列输入所述训练后的编码器中,得到编码后的待检索时序特征矩阵;
汉明距离计算模块,用于分别计算所述待检索时序特征矩阵与每个所述测试时序特征矩阵之间的汉明距离;
相似多元时间序列确定模块,用于将所述汉明距离进行升序排列,并将前预设个数的汉明距离所对应的测试多元时间序列均确定为所述待检索多元时间序列的相似多元时间序列;
状态确定模块,用于根据所述相似多元时间序列的状态确定所述待检索多元时间序列所表征的状态。
可选的,所述系统,还包括:
样本集获取模块,用于获取样本集;所述样本集包括多个真多元时间序列;
样本集划分模块,用于将所述样本集划分为训练集和验证集;
编码器训练模块,用于使用所述训练集对所述编码器进行训练,得到训练后的编码器;
编码器验证模块,用于使用所述验证集对所述训练后的编码器进行验证,判断调整超参数的次数是否达到第一预设迭代次数;若否,则调整超参数并执行步骤“使用所述训练集对所述编码器进行训练,得到训练后的编码器”;若是则输出训练后的编码器。
可选的,所述编码器训练模块,具体包括:
对抗网络构建单元,用于构建对抗网络;所述对抗网络包括编码器、解码器和鉴别器;
解码单元,用于将随机二进制编码和均匀随机分布的连接输入所述解码器,得到多个假多元时间序列;
鉴别器训练单元,用于将多个所述真多元时间序列和多个所述假多元时间序列均输入所述鉴别器中进行训练,调整所述鉴别器的参数直至对抗损失函数小于第一阈值;
编码器训练单元,用于将多个所述真多元时间序列输入所述编码器中进行训练,根据所述鉴别器的鉴别结果调整所述编码器的参数直至相似对损失函数小于第二阈值,执行步骤“将多个真多元时间序列随机输入所述解码器,得到多个假多元时间序列”直至迭代次数达到第二预设迭代次数。
可选的,所述相似对损失函数为:
式中,s
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明提供了一种多元时间序列检索方法及系统,方法包括获取测试集和待检索多元时间序列;测试集包括多个编码后的测试时序特征矩阵;编码后的测试时序特征矩阵是将测试多元时间序列输入训练后的编码器后得到的;将待检索多元时间序列输入训练后的编码器中,得到编码后的待检索时序特征矩阵;分别计算待检索时序特征矩阵与每个测试时序特征矩阵之间的汉明距离;将汉明距离进行升序排列,并将前预设个数的汉明距离所对应的测试多元时间序列均确定为待检索多元时间序列的相似多元时间序列;根据相似多元时间序列的状态确定待检索多元时间序列所表征的状态。本发明提供的方法及系统,通过将相似的多元时间序列进行相似的二进制编码,通过汉明距离判断多元时间序列之间度相似程度,能够减少多元时间序列检索过程中的计算量,提高多元时间序列检索的速度和准确性,进而能够提高待检索多元时间序列状态识别的准确性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中提供的多元时间序列检索方法流程图;
图2为本发明实施例中提供的编码器训练方法流程图;
图3为本发明实施例中提供的多元时间序列检索系统的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种多元时间序列检索方法及系统,能够减少多元时间序列检索过程中的计算量,提高多元时间序列检索的速度和准确性。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
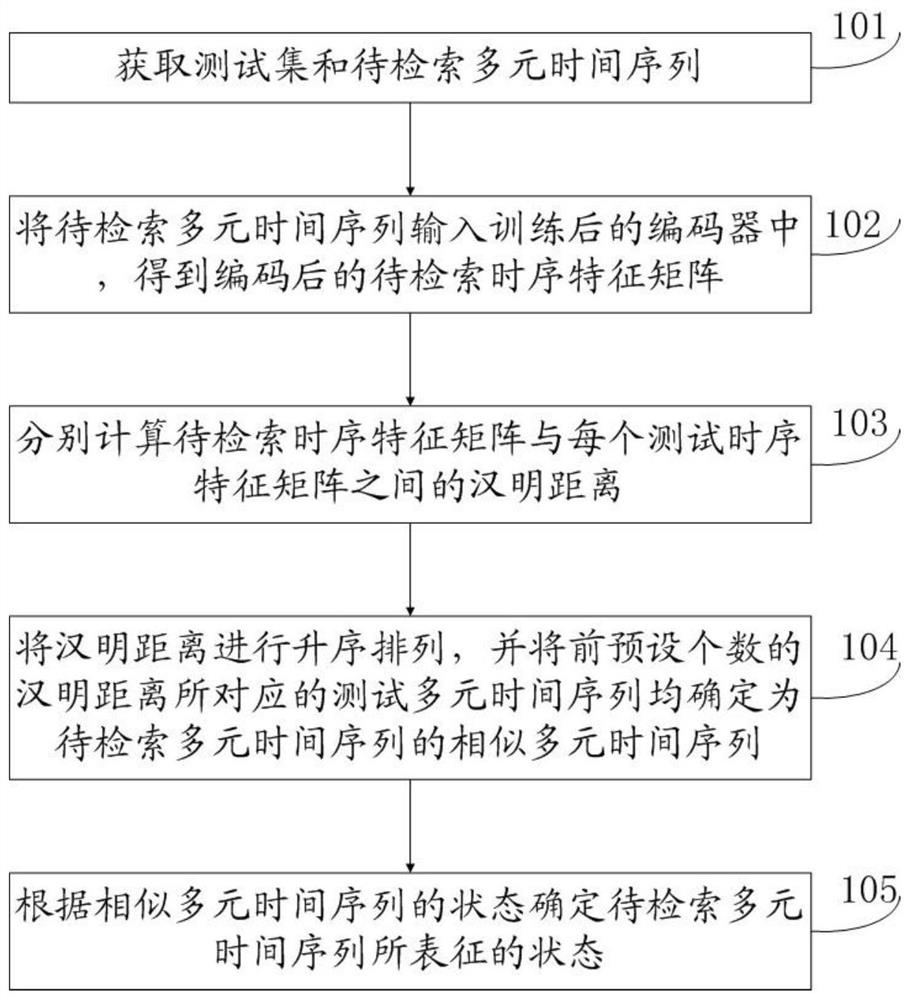
图1为本发明实施例中提供的多元时间序列检索方法流程图,如图1所示,本发明提供了一种多元时间序列检索方法,包括:
步骤101:获取测试集和待检索多元时间序列;测试集包括多个编码后的测试时序特征矩阵;编码后的测试时序特征矩阵是将测试多元时间序列输入训练后的编码器后得到的;
步骤102:将待检索多元时间序列输入训练后的编码器中,得到编码后的待检索时序特征矩阵;
步骤103:分别计算待检索时序特征矩阵与每个测试时序特征矩阵之间的汉明距离;
步骤104:将汉明距离进行升序排列,并将前预设个数的汉明距离所对应的测试多元时间序列均确定为待检索多元时间序列的相似多元时间序列;
步骤105:根据相似多元时间序列的状态确定待检索多元时间序列所表征的状态。
本发明提供的多元时间序列检索方法,在步骤101之后还包括:获取样本集;样本集包括多个真多元时间序列;将样本集划分为训练集和验证集;使用训练集对编码器进行训练,得到训练后的编码器;使用验证集对训练后的编码器进行验证,判断调整超参数的次数是否达到第一预设迭代次数;若否,则调整超参数并执行步骤“使用训练集对编码器进行训练,得到训练后的编码器”;若是则输出训练后的编码器。
具体的,使用训练集对编码器进行训练,得到训练后的编码器,具体包括:
构建对抗网络;对抗网络包括编码器、解码器和鉴别器;
将随机二进制编码和均匀随机分布的连接输入解码器,得到多个假多元时间序列;
将多个真多元时间序列和多个假多元时间序列均输入鉴别器中进行训练,调整鉴别器的参数直至对抗损失函数小于第一阈值;
将多个真多元时间序列输入编码器中进行训练,根据鉴别器的鉴别结果调整编码器的参数直至相似对损失函数小于第二阈值,执行步骤“将多个真多元时间序列随机输入解码器,得到多个假多元时间序列”直至迭代次数达到第二预设迭代次数。
其中,相似对损失函数为:
式中,式中,s
图2为本发明实施例中提供的编码器训练方法流程图具体的,本发明提供的多元时间序列检索方法中,编码器训练包括以下步骤:
步骤1:获取三个待训练的多元时间序列数据集。
获取脑电图眼睛状态数据集(EEG Eye State,EES)、身体活动监测数据集(Physical Activity Monitoring,PAMAP2)和苏塞克斯华为移动数据集(Sussex-HuaweiLocomotion Dataset,SHL),其中,脑电图眼睛状态数据集是从情绪脑电图耳机的连续脑电图测量得到,“1”表示闭眼,“0”表示睁眼;PAMAP2数据集是一个监测身体活动的数据集,包含不同身体活动的数据,如步行,骑自行车,踢足球等;苏塞克斯华为移动数据集是关于移动用户移动和运输模式的多功能注释数据集。
步骤2:将步骤1中数据集的数据转化成类似图像的二维特征形式,构造时序特征矩阵,并对时序特征矩阵进行归一化处理,使得每个属性的取值在[0,1]之间,并划分训练集、验证集和测试集。
多元时间序列两个重要属性为时序属性和多元之间的相关性,所以我们应用滑动窗口来获取时间序列数据的滞后特征(深层特征),以体现多元时间序列的时序属性,并将时间序列片段构造成类似图像的二维矩阵,通过一种类似图像的张量模式来表示多元时间序列,以学习变量之间的相互作用,从而将其应用到卷积神经网络。
为了表示从t-w+1时刻到t时刻的多元时间片段不同时序对之间的关系,根据时间片段中不同时序对的成对内积构造了n×n的时序特征矩阵M
其中,κ=w
式中,κ为缩放因子,w为滑动窗口的大小,δ为时刻。某一多元时间序列的所有时序片段对之间的时序特征即构成了时序特征矩阵M
步骤3:预训练获取时序相似矩阵用于构造相似对损失函数,训练编码器,提高时间片段的可鉴别性,促使相似的时间序列有相似的二进制编码,不同的时间序列有不同的编码。
仅通过对抗损失和对输入的重构不足以使二进制编码具备较为精确的检索能力。所以,在多元时间序列检索中引入了相似对损失函数,通过训练促使二进制编码保持相似矩阵的结构。
大量的研究表明,将训练集输入深层架构提取多元时间序列中每个片段的深层特征,基于深层特征构建时序相似矩阵。其中,深层架构是基于卷积神经网络,使用LSTM编码对大量时间序列数据进行训练得到的。
根据深层特征,利用公式
根据第三阈值,对余弦相似度矩阵进行二值化处理:令余弦相似度矩阵中小于或等于第三阈值的元素的值均为1,令余弦相似度矩阵中大于第三阈值的元素的值均为-1。
构造相似对损失函数:
式中,s
步骤4:用一种基于CNN和深度非监督二进制对抗网络(Deep Unsupervised CNNBinary Adversarial Network,DUCBA)对时序特征矩阵数据集进行训练。
该网络包括一个解码器、一个编码器和一个鉴别器。其中鉴别器和编码器除了最后一层外,共享所有参数。解码器输入是随机二进制编码和均匀随机分布这两个随机分布数据的连接,从而生成假时序特征矩阵;将真时序特征矩阵(训练集)和假时序特征矩阵输入鉴别器,鉴别器输出其判断;将真的时序特征矩阵输入到编码器进行二进制编码。在训练过程中,引入重构损失、对抗损失和相似对损失分别对解码器、鉴别器和鉴别器进行补偿直至迭代次数达到第二预设迭代次数,其中相似对损失用于刻画训练的结果相对于时序相似矩阵的偏离程度。
步骤5:根据步骤4所获取的训练模型,使用验证集对步骤4中的编码器进行验证,更新超参数(学习率、编码位数、各损失函数的权重和批量大小)返回步骤4对模型进行重新训练,重复步骤4至步骤5直到超参数都训练完毕(即调整超参数的次数达到第一预设迭代次数),获取最优的训练模型。
步骤6:从数据集中随机抽取多元时间序列为待检索多元时间序列;将待检索多元时间序列和测试集分别输入到训练后的编码器中进行二进制编码,分别计算待检索时序特征矩阵与每个测试时序特征矩阵之间的汉明距离;将汉明距离进行升序排列,并将前预设个数的汉明距离所对应的测试多元时间序列均确定为待检索多元时间序列的相似多元时间序列。根据相似多元时间序列的状态确定待检索多元时间序列所表征的状态。
在确定出多个(预设个数个)检测结果(相似多元时间序列)后,计算检测精度指标(Precision@k、MAP和MAP@k)判断本发明的检测精度:
其中,
式中,tp@k为前k个查询结果中与前k个实际结果相同的个数,fp@k为前k个查询结果中与前k个实际结果不同的个数,Precision@k为前k个精确率(排名前k个查询结果在前k个实际结果中的比例),AP为每个查询结果的平均精度,rel(k)为指示函数(正相关时为1,不相关时为0),n表示正相关的数量,MAP为所有查询结果的平均精度,Q为查询总数,q为查询次数,AP(q)为第q次查询的平均精度,AP@k(q)表示前k个查询结果的平均精度,MAP@k为多次查询时前k个查询结果平均精度的平均值。
获取数据集并对其进行的清洗工作,通过将1D多元时间序列数据转化为2D类似图像表示的矩阵,使用滑动窗口来获取时间序列数据的滞后特征,并通过一种类似图像的张量模式来表示多元时间序列,以学习变量之间的相互作用,从而将其应用到卷积神经网络。这样有利于利用卷积神经网络的自动特征提取的优势,进而利于使用该模型提取域不变特征。同传统的相似多元时间序列检索方法相比,本发明中的方法在Precision@k、MAP@k和MAP等评价指标上有一定的性能提升。实验部分的超参数:学习率,编码位数,损失函数的3个权重,批量大小,其中学习率为{1e-6,1e-5,1e-4,1e-3},编码位数为{32,64,128},损失函数权重为{1,1,0.001},批量大小位100。
本发明从三个数据集提取的数据如表1所示,对于每个数据集的采集片段,每个时间片段长度为10。
表1数据集数据提取
为了验证本发明对于多元时间序列检索的有效性,我们在三个数据集上都进行了较为全面的实验,并且比较了二进制编码分别为32位、64位和128位时Precision@k、MAP@k和MAP指标,比较结果如表2所示。其中k表示前k个查询结果,b表示二进制编码位数。EEGEye State(k=100),PAMAP2(k=500),SHL(k=1000),
表2本发明编码不同位数时的精度指标
如表2所示,本发明在三个数据集上都有较好的效果,且在二进制编码位数为128位时,检索效果最优。
此外,技术人员还将本发明与其他时序检索方法的精度指标进行了对比,比较结果如表3所示。其中,方法1为局部敏感哈希法(Locality Sensitive Hashing,LSH),方法2为迭代量化法(Iterative Quantization,ITQ),方法3本发明不使用相似对损失函数训练的模型;方法4为本发明使用相似对损失函数训练的模型。
表3不同时序检索方法的检索精度比较
由表3可知,本发明在多元时间序列检索方面的检索效果比其他三种方法更优,验证了本发明对于多元时间序列检索的有效性。特别地,从3和方法4的数据可知本发明中添加的相似对损失提高了模型的检索效果。
图3为本发明实施例中提供的多元时间序列检索系统的结构示意图,如图3所示,本发明还提供了一种多元时间序列检索系统,包括:
数据获取模块301,用于获取测试集和待检索多元时间序列;测试集包括多个编码后的测试时序特征矩阵;编码后的测试时序特征矩阵是将测试多元时间序列输入训练后的编码器后得到的;
待检索时序特征矩阵编码模块302,用于将待检索多元时间序列输入训练后的编码器中,得到编码后的待检索时序特征矩阵;
汉明距离计算模块303,用于分别计算待检索时序特征矩阵与每个测试时序特征矩阵之间的汉明距离;
相似多元时间序列确定模块304,用于将汉明距离进行升序排列,并将前预设个数的汉明距离所对应的测试多元时间序列均确定为待检索多元时间序列的相似多元时间序列;
状态确定模块304,用于根据相似多元时间序列的状态确定待检索多元时间序列所表征的状态。
本发明提供的多元时间序列检索系统,还包括:
样本集获取模块,用于获取样本集;样本集包括多个真多元时间序列;
样本集划分模块,用于将样本集划分为训练集和验证集;
编码器训练模块,用于使用训练集对编码器进行训练,得到训练后的编码器;
编码器验证模块,用于使用验证集对训练后的编码器进行验证,判断调整超参数的次数是否达到第一预设迭代次数;若否,则调整超参数并执行步骤“使用训练集对编码器进行训练,得到训练后的编码器”;若是则输出训练后的编码器。
具体的,编码器训练模块,具体包括:
对抗网络构建单元,用于构建对抗网络;对抗网络包括编码器、解码器和鉴别器;
解码单元,用于将随机二进制编码和均匀随机分布的连接输入解码器,得到多个假多元时间序列;
鉴别器训练单元,用于将多个真多元时间序列和多个假多元时间序列均输入鉴别器中进行训练,调整鉴别器的参数直至对抗损失函数小于第一阈值;
编码器训练单元,用于将多个真多元时间序列输入编码器中进行训练,根据鉴别器的鉴别结果调整编码器的参数直至相似对损失函数小于第二阈值,执行步骤“将多个真多元时间序列随机输入解码器,得到多个假多元时间序列”直至迭代次数达到第二预设迭代次数。
其中,相似对损失函数为:
式中,式中,s
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种多元时间序列检索方法及系统
- 一种基于全卷积注意力的多元时间序列分类方法及系统