一种用于高速公路的驾驶行为决策方法
文献发布时间:2023-06-19 12:13:22
技术领域
本发明属于智能驾驶领域,具体涉及一种用于高速公路的驾驶行为决策方法。
背景技术
自动驾驶技术是智能交通的核心技术,能够极大的提高车辆安全性和道路的运输能力。自动驾驶的功能实现可以分为环境感知、决策规划、车辆控制三个模块。环境感知负责监测环境中的障碍物,相当于人类驾驶员的感官。决策规划模块根据感知信息做出变道、跟车、加速等驾驶决策,并规划出一条安全的可行驶轨迹。车辆控制模块控制转向、油门和制动踏板实现轨迹的跟踪。
决策规划功能是自动驾驶车辆智能化程度的主要体现,一个拟人化程度高的决策系统能大大提高智能车的安全性和乘坐舒适性以及周尾交通参与者的接收度。目前常用的决策规划方法大致可以分为基于规则的方法和基于学习的方法以及两者的结合。基于规则的方法包括有限状态机模型、决策树模型等。首先按照一定的经验和规则将行驶环境划分为不同等级的子场景,对不同的场景设定不同的驾驶决策,实际行驶过程进行搜索决策。基于学习的方法包括基于深度学习和强化学习的决策方法。将驾驶环境抽象为状态量,通过构建复杂的神经网络将状态空间映射至驾驶行为,通过仿真或实车驾驶数据来训练网络。
强化学习因其强大的自主学习能力被广泛地应用于决策规划技术。强化学习是基于行为主义心理学的方法,不需要大量带有标签的训练数据,通过不断地与环境交互,从环境中获取状态动作的奖励反馈,从而学习到具有最大奖励值的状态和动作,以实现最优任务规划。强化学习在应用于多目标的决策问题时,最关键的问题是如何设置合理的奖励函数。目前研究较多的用于复杂环境下部分可观测Markov决策问题的强化学习有基于值函数的DQN和基于策略梯度的DDPG算法。
鉴于此,目前亟待提出一种具有自主学习能力的用于高速公路的驾驶行为决策方法。
发明内容
为此,本发明所要解决的技术问题是提供一种具备自主学习能力、学习能力好的高速公路的驾驶行为决策方法。
本发明的高速公路的驾驶行为决策方法,包括:
S1,将自动驾驶车辆在高速公路上的决策过程定义为部分可观测的马尔可夫决策过程;
S2,定义自动驾驶车辆的策略;
S3,训练自动驾驶车辆;
S4,将自动驾驶车辆神经网络模型部署于车载终端,并实现驾驶行为决策。
进一步的步骤S1的具体过程为:
S101,设智能体观测到的状态空间为
S102,设智能体的动作空间为连续的纵向加速度
S103,设置奖励函数:
其中,
S104,对奖励函数分量分别进行归一化处理,得到新奖励函数,然后,对新奖励函数进行归一化处理,计算奖励。
进一步,步骤S104中的归一化处理的具体过程包括:
S104a,定义碰撞惩罚,
S104b,定义速度奖励范围为[
其中,
S104c,定义位置奖励范围为[
其中,
S104d,各奖励分量进行归一化处理后,新的奖励函数的边界为
进一步,步骤S2中定义智能体的策略具体为π:
进一步,步骤S3中训练自动驾驶车辆的具体过程包括:
S301,定义步骤S2中的四种神经网络的学习率以及目标网络的学习率,经验池的尺寸,强化学习的折扣因子
S302,初始化观测状态
S303,循环执行步骤S302,直至填满经验池;
S304,在循环执行步骤S302的同时,循环执行噪声交互,直至满足回合结束条件或发生碰撞;
S305,保存自动驾驶车辆的神经网络模型。
进一步,步骤S304的具体过程为:
S304a,初始化观测状态
S304b,从经验池中随机采样经验,并估计回报值
S304c,通过随机梯度下降法更新评价网络参数,定义其损失函数为:
[
其中,
S304d,通过随机梯度下降法更新策略网络参数,定义其损失函数为:
-
S304e,将更新后的策略网络参数和评价网络参数赋值给目标策略网络和目标评价网络。
进一步,步骤S4的决策过程包括,当观测到的车道线为实线时,且输出的动作为转向角时,则最终输出转向角为0,速度保持原车速的决策。
进一步,定义一个安全距离阈值
本发明的上述技术方案,相比现有技术具有以下优点:
已有的强化学习决策规划方法通常是先决策出一个离散的驾驶动作,比如变道、跟车、加减速等宏观动作,再采用其他方法规划转向角和加速度。此外,现有的基于强化学习的驾驶决策规划都采用离散的奖励函数,这将导致训练不稳定或结果不收敛等问题。本发明针对高速公路驾驶环境,提出一种基于深度强化学习的决策规划方法及装置,直接将驾驶环境状态空间映射到纵向加速度和横向转向角,省去了中间规划过程,可以显著提高决策效率和驾驶安全性,采用DDPG算法处理连续动作空间的决策规划问题,对策略网络和评价网络分别加入目标策略网络和目标评价网络,以增强算法训练稳定性。同时将奖励函数进行归一化处理,使每一个动作所能获得的奖励具有确定的边界,提高算法的适用性和收敛速度。训练好智能体后,在实际应用时,为进一步增强决策安全性,引入基于规则的硬约束,当观测到车道线为实线,而强化学习决策模块输出的动作为转向角时,则最终输出转向角为0,速度保持原车速的决策;定义一个安全距离dmin或安全时间阈值tmin,当智能体与同一车道的前车的距离或碰撞时间小于阈值时,此时不允许采取加速动作,或与旁边车道的前车距离或碰撞时间小于阈值时,不允许采取变道动作,若强化学习模块输出有加速或转向,则最终输出为维持原速度和转向角的决策。
附图说明
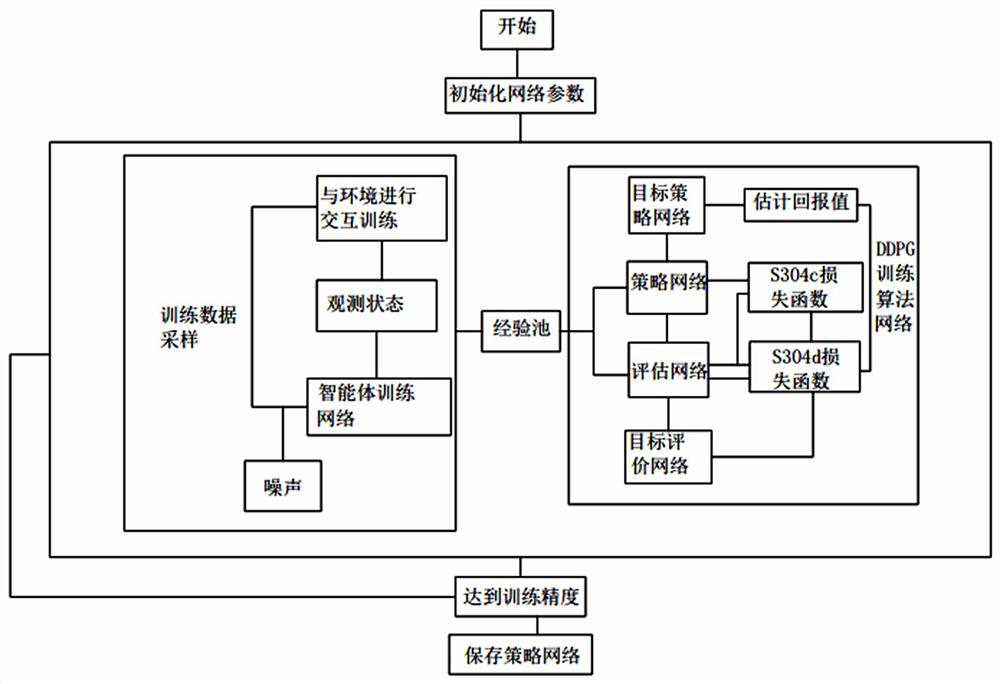
图1是本发明实施例提供的流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本实施例的用于高速公路的决策方法,如图1所示,包括如下步骤:
S1,将自动驾驶车辆在高速公路上的决策过程定义为部分可观测的马尔可夫决策过程。
优选地,步骤S1具体包括以下步骤。
S101,设智能体观测到的状态空间为
S102,设智能体的动作空间为连续的纵向加速度
S103,设置奖励函数:
其中,
S104,对奖励函数各分量分别进行归一化处理,得到新奖励函数,然后,对新奖励函数进行归一化处理,计算奖励。具体地,对奖励函数进行归一化处理后的奖励函数
由于通常基于强化学习的决策系统采用三个目标的离散奖励,而这会导致训练不稳定甚至不收敛,因次本实施例的S104对奖励函数进行归一化处理。
步骤S104中的归一化处理的具体过程包括,S104a,定义碰撞惩罚,
S104b,定义速度奖励范围为[
其中,
S104c,定义位置奖励范围为[
其中,
S2,定义自动驾驶车辆的策略,具体为π:
S3,训练自动驾驶车辆,训练自动驾驶车辆的具体过程包括以下步骤。
S301,定义步骤S2中的四种神经网络的学习率以及目标网络的学习率,经验池的尺寸,强化学习的折扣因子
S302,初始化观测状态
S303,循环执行步骤S302,直至填满经验池。
S304,在循环执行步骤S302的同时,循环执行噪声交互,直至满足回合结束条件或发生碰撞。
步骤S304的具体过程为,S304a,初始化观测状态
S304b,从经验池中随机采样经验,并估计回报值
S304c,通过随机梯度下降法更新评价网络参数,定义其损失函数为:
[
S304d,通过随机梯度下降法更新策略网络参数,定义其损失函数为:
-
其中,
本实施例中的随机梯度下降法为通用的参数更新方法,在此不再赘述。
S304e,将更新后的策略网络参数和评价网络参数赋值给目标策略网络和目标评价网络。
S305,保存自动驾驶车辆的神经网络模型。
S4,将自动驾驶车辆神经网络模型部署于车载终端,并实现驾驶行为决策。
其中,驾驶行为决策的过程包括:当观测到的车道线为实线时,且输出的动作为转向角时,则最终输出转向角为0,速度保持原车速的决策;定义一个安全距离阈值
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
- 一种用于高速公路的驾驶行为决策方法
- 一种应用于自动驾驶车辆的高速公路超车行为决策方法