基于外部注意力机制的光学相干层析超分辨率成像方法
文献发布时间:2023-06-19 12:19:35
技术领域
本发明涉及一种光学相干层析超分辨率成像方法。
背景技术
光学相干断层血管成像(Optical coherence tomography angiography简称OCTA)是一种非侵入、非接触和无损伤的成像技术,主要基于多普勒干涉原理,当入射光照射到流动的红细胞时,由于多普勒效应的存在,反射光信号会产生相位和强度的变化,通过分析反射光与参考光的干涉信号,可以区分静态组织和血流组织。相比其它成像技术如光学相干成像(optical coherence tomography,简称OCT),计算机断层扫描(ComputedTomography,简称CT)和核磁共振成像(Magnetic Resonance Imaging简称MRI),OCTA有着高分辨率,无辐射、结构简单、速度快等优点,在医学疾病诊断特别是微血管疾病诊断上具有重要作用。
然而,由于OCTA成像时要求的设备稳定性和设备分辨较高,其重建图像分辨率往往较低,并且容易受测量人操作以及环境等因素的影响,这限制了OCTA技术的进一步推广。OCTA分辨率较低在图像上表现为血管图像不清晰,模糊,影响医生的临床诊断。传统超分辨率方法通过学习低分辨率和高分辨率图像的自相似性以及基于稀疏特征的方法对低分辨率图像进行重建。最近,一些机器学习的重建方法被提出,如聚类,随机森林等,而基于卷积神经网络的重建算法也属于此类。
近几年来,伴随着深度学习在计算机视觉和图像处理领域的迅速发展和广泛应用,众多深度网络特别是卷积神经网络(Convolutional Neural Network简称CNN)也纷纷被引入到医学成像领域中来。这些数据驱动的新型成像技术被视为医学成像领域继解析法、迭代法后的第三个发展阶段,它们利用由大量数据训练好的网络,来补充或代替传统成像算法中人为定义的模型,将大数据内在的信息自动地融入到成像过程中。其中一种较为简便易行的办法是在图像域设计并训练一个对粗糙的重建图像加以后处理的CNN,使CNN能学习到医学成像过程中产生的噪声以及伪影等,并在输出图像中移除这些不利因素,这可以被视为一个图像增强或者说图像变换过程,在计算机视觉和图像处理领域这方面已经有许多有效而易于使用的网络模型。2017年,Kang等人在《医学物理》杂志提出了一种将小波变换融入DCNN的CT图像降噪方法(A deep convolutional neural network usingdirectional wavelets for low-dose X-ray CT reconstruction)。对输入图像进行小波变换,用DCNN去除小波域中的噪声,再进行小波重构得到输出图像。通过将他们的方法,可以使用原来于四分之一剂量的进行腹部CT扫描,他们能够在不影响器官边界可视化的情况下降低图像噪声。2017年,Kinam Kwon等人在《Medical Physics》上提出了改进MRI成像的方法(A parallel MR imaging method using multilayer perceptron)。该方法使用多层感知器(MLP)模型对下采样k空间数据进行训练,模型输出为没有混叠现象的k空间数据的全采样数据[27]。MLP模型利用了k空间的多通道信息,从而消除了在k空间的混叠现象。2019年,Maarten G等人在《Scientific Reports》杂志上提出了获取更高保真度的CT图像的方法(Physics-informed Deep Learning for Dual-Energy Computed TomographyImage Processing)。该方法提出可以通过训练了一个卷积神经网络(CNN)来开发一个框架,利用Dect图像生成过程的底层物理原理以及通过训练获得的真实图像的解剖信息,可以生成更高保真度的Dect图像。解决由于基于基本衰减过程的材料分解算法的限制,导致在特定图像的低信噪比这一问题。2019年,Mehmet
神经网络自2018年以后逐渐被应用到医学相关图像的超分辨率成像过程中。但是对OCTA图像的俯视图(enface图)目前应用还比较少。目前对于OCTA图像的超分辨率重建多是基于全深度图像的超分辨率重建,但是在实际医生诊断时,任意深度enface的重建更为重要。而且使用单个神经网络对于任意深度的超分辨率重建效果不佳。需要在任意深度重建时加入深度信息,这样能够帮助重建质量更高的OCTA图像。2018年,Wei Ouyang1等人在《nature》杂志上使用生成对抗网络,从低帧率的超分辨率光学显微图像重建出高帧率的超分辨率光学显微图像(Deep learning massively accelerates super-resolutionlocalization microscopy)。该项工作使用人工神经网络(ANNs)来学习数值输入和输出之间的复杂非线性映射,进而从大量取样不足的定位显微镜数据中重建高质量的图像。2018年,Elias Nehme等人在《Journal of biophotonics》提出了使用卷积神经网络模型可以减少在每一个深度位置(z轴)所需要的b scan次数(A deep learning based pipeline foroptical coherence tomography angiography)。在该项工作中,每个z轴位置需要的bscan次数从48减少至4个连续的b scan,但是成像质量与使用使用48个b scan一致。2019年,Wang,Hongda等人在《自然》杂志上的文章提出基于训练生成对抗网络(GAN)将有限衍射输入图像转换为超分辨图像(Deep learning enables cross-modality super-resolution in fluorescence microscopy)。该方法通过GAN模型对低数值孔径物镜图像的训练,提高了低数值孔径物镜获取的大视场图像的分辨率,与高数值孔径物镜获取的分辨率相匹配。2020年TING ZHOU在《Image and Video Processing》杂志提出了提高全深度enface的超分辨率重建方法(Digital resolution enhancement in low transversesampling optical coherence),该方法使用循环生成对抗网络学习,从采集设备为感受野为8×8的低分辨率图像重建高分辨率图像,其成像效果与采集设备为3×3的感受野的成像质量相当。
相关文献:
[1]Schmitt,J..“Optical coherence tomography(OCT):a review.”IEEEJournal of Selected Topics in Quantum Electronics 5(1999):1205-1215.
[2]Carlo,Talisa E de et al.“A review of optical coherence tomographyangiography(OCTA).”International Journal of Retina and Vitreous 1(2015):n.pag.
[3]Kang E,Min J,Ye JC.A deep convolutional neural network usingdirectional wavelets for low-dose X-ray CT reconstruction.Med Phys.2017;44:e360–e375.
[4]Kwon K,Kim D,Park HW.A parallel MR imaging method using multilayerperceptron[J].Medical Physics,2017,44(12).
[5]Poirot MG,Bergmans RHJ,Thomson BR,et al.Physics-informed DeepLearning for Dual-Energy Computed Tomography Image Processing[J].ScientificReports,2019,9(1)
[6]
[7]Ouyang,W.et al.“Deep learning massively accelerates super-resolution localization microscopy.”Nature Biotechnology 36(2018):460-468.
[8]Wang,H.et al.“Deep learning enables cross-modality super-resolution in fluorescence microscopy.”Nature Methods 16(2018):103-110.
[9]Zhou,T.et al.“Digital resolution enhancement in low transversesampling optical coherence tomography angiography using deep learning.”arXiv:Image and Video Processing(2019):n.pag.
发明内容
本发明的目的在于提供一种可以提到重建图像分辨率的光学相干层析超分辨率成像方法。技术方案如下:
一种基于外部注意力机制的光学相干层析超分辨率成像方法,包括步骤如下:
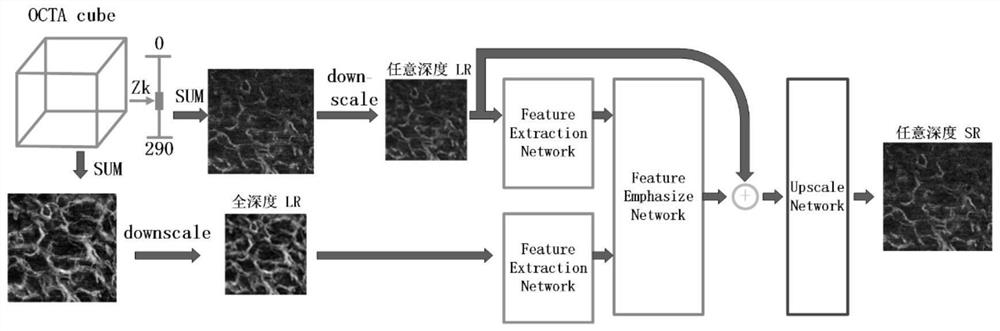
第一步,读入光学相干层析成像立方体数据,构建数据集并进行数据预处理,得到全深度低分辨enface图像和任意深度低分辨enface图像,作为卷积神经网络模型的输入,将未经过下采样的任意深度enface图像作为训练的标签。
第二步,构建包含注意力机制的卷积神经网络,卷积神经网络模型主要包括特征提取模块,外部空间注意力模块,外部通道注意力模块和特征上采样模块:
特征提取模块,使用权值共享的两个特征提取模块分别提取来自全深度低分辨enface图像,任意深度低分辨enface图像的特征,得到全深度特征图和任意深度特征图;
外部空间注意力模块,使用任意深度空间注意力分支和全深度空间注意力分支分别提取任意深度特征图,全深度特征图的有效特征,两个空间注意力分支都包括一个1×1的卷积层和一个最大池化,一个平均池化层,sigmoid函数;每个空间注意力分支提取特征图的有效特征都能够得到一张空间注意力图,再将两个空间注意力分支得到的空间注意力图进行点乘,然后分别乘以全深度特征图和任意深度特征图,从而得到任意深度空间注意力特征图I
外部通道注意力模块,使用任意深度通道注意力分支和全深度通道注意力分支分别提取I
特征上采样模块,包括一个全局跳跃连接,一个sub-pixel层,以及一个3×3卷积层,全局跳跃连接将底层特征和经外部空间和通道注意力模块强调后的特征图I
第三步,模型训练,将经过第一步数据预处理后的全深度低分辨enface图像和任意深度低分辨enface图像,作为卷积神经网络模型的输入,设置网络学习速率;计算最终重建的超分辨率SR图像和高分辨率HR图像误差,将其作为网络的损失经方向传播到网络各层,更新网络参数;误差优化器采用ADAM优化器。
进一步地,第一步的方法如下:
1)读入光学相干层析成像立方体数据,选定全部深度,并沿深度轴进行像素值的累加,构成全深度enface图像;选定任意深度Z
2)使用双三次差值方法对任意深度enface图像和全深度enface图像进行下采样,得到全深度低分辨enface图像和任意深度低分辨enface图像,作为卷积神经网络模型的输入,将未经过下采样的任意深度enface图像作为训练的标签。
进一步地,第二步,基于tensorflow,构建包含注意力机制的卷积神经网络。
进一步地,第二步中的特征提取模块中,每个特征提取模块使用三个包含注意力机制的基本特征提取单元,然后将三个基本特征提取单元的输出都连接到一起,使用1×1和3×3的卷积层将通道数压缩回64,这样得到全深度特征图或任意深度特征图。
进一步地,第三步中,设置网络学习速率,并且将学习速率设置为随着网络训练的迭代周期增加而逐渐减少。误差函数使用均方根误差。
本发明的实质性特点和有益效果为:构建与实际检测情况尽可能相符的训练数据集,并根据OCTA的特性建立训练用于OCTA卷积神经网络模型。本发明提出了深度先验信息的OCTA图像的超分辨率重建模型。为了更充分利用深度先验信息,还引入了外部注意力机制,该注意力机制能够强调在任意深度上应该具有的血流信号,抑制在本深度上不应该具有血流信号。同时为了更有效的提取深度信息特征,任意深度信息特征,使用了权值共享的特征提取网络提取任意深度和全深度的特征提取网络,该网络引入了目前在RGB图像超分辨率重建领域中十分有效的本地,局部,长跳跃连接,通道和空间注意力机制,以及连续残差结构。在分别提取了任意深度和全深度的高级特征后,使用外部注意力机制强调任意深度上的血流信号,最后使用跳跃结构连接低级特征和高级特征,经亚像素卷积层进行上采样后得到分辨率高的重建图像。由于在重建过程中引入了深度先验信息以及外部注意力机制,重建图像的分辨率得到了提高。
附图说明
图1为本发明中训练数据集构建方法的流程图;
图2为本发明中特征提取网络基本组成单元的示意图;
图3为本发明中CNN模型的完整示意图;
图4为本发明的外部注意力机制。
图5为enface图像重建效果,并与其他深度学习模型的对比结果,并使用峰值信噪比(PNSR)和结构相似系数(SSIM)进行评价。
图6为基线模型的PSNR和SSIM评价指标随深度变化曲线图。
具体实施方式
结合附图和实施例对本发明的基于卷积神经网络的光学相干断层血管成像图像重建方法加以说明。
本发明的基于卷积神经网络的光学相干断层血管成像图像重建方法,实施例中针对人体皮肤微血管enface图像的特殊应用形式,以皮肤微血管任意深度的enface图像和全深度enface图像作为CNN模型的输入,重建的高分辨率图像作为CNN模型的输出。
图1是本发明中对皮肤微血管的预处理与训练集数据建立流程图,其主要步骤如下:
第一步,构建数据集并进行数据预处理
1)使用python工具读入OCTA成像立方体数据,OCTA图像立方体大小为250×250×291,设定深度为291,并沿深度轴进行相加,构成全深度enface数据,全深度enface图像的大小为250×250×3.。选定任意深度Z
2)为了模拟实际中由于设备分辨等因素造成的低分辨率enface图像的情况,使用双三次差值方法对任意深度和全深度图像进行下采样,将其视为实际情况中的低分辨率图像,作为模型的输入,将未经过下采样的作为训练的标签。进行三倍下采样时,输入图像的大小为84×84×3.进行二倍下采样时,输入的图像大小为126×126×3。因而模型输入为低分辨率enface大小为84×84×3,或126×126×3,模型的标签图像为252×252×3
3)使用旋转,平移,裁剪等数据增强方法对数据集进行扩增,最终得到了13000幅低分辨enface图像和高分辨率enface图像。选取其中的10000幅作为训练集,其余的选为测试集。
第二步,使用tensorflow进行CNN网络的训练,CNN模型主要包括特征提取模块,特征融合模块,特征上采样模块,下面进行详细介绍。
1)在特征提取模块的每一个分支中,输入的LR图像都是84×84×3或126×126×3大小,经过一个3×3的卷积后,输出的特征空间为64,因而将3通道的图像映射到了64通道的特征空间。
2)我们将每一个特征基本提取单元称为RARDB(residual attention residualdense block),每个基本特征提取单元包括三个分支,局部跳跃分支,卷积层和RDB结构分支,通道和空间注意力分支。第一个分支为局部跳跃结构分支,这一分支的作用为将上一层RARDB结构的特征空间直接连到本RARDB结构的输出,此分支的输出大小为84×84×64或126×126×64。第二个分支为注意力机制分支,使用通道注意力机制和空间注意力机制提取上一个RARDB结构中最为有效的特征。第三个分支为卷积层和RDB结构分支,使用RDB结构进一步精炼上一个RARDB结构的输出,以便于提取输入图像的高阶特征。在三个分支中,每个分支得到的特征空间都为84×84×64或126×126×64,为了精炼浅层特征,我们融合了三个分支的特征,融合的具体方式是点对点相加,最终得到的本RARDB模块输出大小也为84×84×64或126×126×64。RDB结构使用了连续稠密残差结构,在网络中每个RARDB中的RDB包括了8个卷积层,8个RELU层,将每个卷积层的输出连接到后面的卷积层作为输入,因而每个卷积核的输入都为前N个卷积层的输出,8个卷积层的输入通道数为设置为64×N,N为在RDB结构中第N个卷积层,每个卷积层的输出通道都被设置为1.最后为了减少网络参数量,再使用1×1和3×3的卷积将RDB模块的输出通道缩减为64.RARDB和RDB结构如图2所示。
3)每个RARDB结构包含了不同层级的特征,为了充分利用各个层级的特征,我们使用了长长跳跃结构将每个RARDB结构的输出连接到一起,此时的特征空间大小为84×84×192或126×126×192(由于GPU显存的限制,只能设置RARDB结构数量设置为3)。为了缩减通道数以及合并通道信息,我们使用了3×3和1×1的卷积层对连接后的特征空间进行通道缩减操作。经过两层卷积的特征空间通道数重新为压缩为64.为了缩减网络模型的参数量,我们将全深度和任意深度的特征提取模块的参数设置为权值共享。
4)外部空间注意力模块的输入为来自任意深度和全深度两个特征提取分支的特征空间,其大小为84×84×64或126×126×64。在外部空间注意力机制中,每个分支都包括最大和平均池化,一个3×3卷积层,点乘操作,sigmoid函数激活。经过最大和平均池化后,两种池化方式的特征空间被缩减为84×84×1或126×126×1,然后将两种池化方式的特征空间连接起来,此时的特征空间大小84×84×2或126×126×2,为了融合两种池化方式或统计方式所得到的空间信息,使用1×1的卷积层将特征空间压缩到1,此时的特征空间大小为为84×84×1或126×126×1。最后为了生成最后的空间注意力图以及将深度先验信息附加到任意深度的特征空间上,我们将两个分支得到的注意力图进行点乘,此时得到的特征图大小仍为84×84×1或126×126×1,此时得到的空间注意力图为附加了深度先验信息的注意力图。最后为了将深度先验信息作用于输入图像上,分别乘以外部空间注意力的输入,此时得到的两个特征空间为I
外部通道注意力模块的输入为I
最后将外部空间注意力模块的输入,即两个来自于不同深度的图像经特征提取网络得到的特征空间进行点乘,再将乘积的结果与外部通道注意力的输出进行点加,得到了的最终输出。
5)使用长跳跃结构将原始浅层特征和经外部注意力强调后的高级特征进行点加,得到的特征图大小仍为84×84×64或126×126×64。将其送入sub-pixel层进行上采样,得到的特征图为252×252×64,最后使用3×3的卷积层将特征空间通道压缩到3,得到最终的图像,其大小为252×252×3。
第三步,模型训练
计算模型的输出SR图像与未经下采样的HR图像的均方根误差,将其通过反向传播,更新中间各层的参数。并且使用ADAM优化器,将均方根误差优化至最小。初始学习率设为0.001,训练样本分批进行处理,每批数目为128,L2范数项正则化参数为0.005,每次训练共计迭代100次。软件平台采用tensorflow,在一块Titan XP GPU(12GB显存)上完成一次训练耗时大约5个小时。Epoch设置为100.
第四步,模型性能测试
输入测试图像,计算生成的SR图像的峰值信噪比以及结构相似系数。将其作为评判模型效果的指标。图5中给出了提出模型与其他深度学习模型的对比方法,BICUBIC为传统线性插值重建方法。VDSR为16年提出的RGB图像的超分辨率图像重建网络,EDSR为17年提出的RGB图像的超分辨率图像重建网络,RDN为18年提出的RGB图像的超分辨率图像重建网络,RCAN为18年提出的RGB图像的超分辨率图像重建网络。图6给出了在每个深度上基线模型和本发明的结构相似系数和峰值信噪比的对比
以上所述实施例为本发明的几个较佳模型,本发明不局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的精神下完成的等效或修改,都在本发明保护的范围。
- 基于外部注意力机制的光学相干层析超分辨率成像方法
- 一种提高扫频光学相干层析成像分辨率方法