一种基于孪生网络的知识感知虚假新闻检测方法
文献发布时间:2024-04-18 19:48:15
技术领域
本发明属于人工智能领域,具体涉及社交网络数据,对社交媒体中出现的新闻,提出了一种基于孪生网络的知识感知虚假新闻检测方法。
背景技术
当前的信息化时代,互联网实现跨越式发展。社交媒体凭借信息丰富、信息分享方便、传播快速且广泛等特点,使其成为大多数人获取和交流信息的平台。随着时代的发展,公众获取新闻的渠道也发生了变化。在前互联网时代,主要通过官方媒体获取新闻。在目前所处的移动互联网时代,专业媒体、自媒体、微信、微博、抖音、今日头条等都成为新闻发布和传播的平台。
随着网络媒体数量的增加,网络新闻用户规模也呈现逐年递增的趋势。由于社交网络使用方便,用户数量逐年增长,越来越多的用户在网络上发布和传播新闻,使得社交媒体上的虚假新闻数量飞速增长。虚假新闻通过扭曲真实事实或根据个人意愿随意编造产生,由于编写者往往会紧贴当下的热点事件,所以虚假新闻能够激发用户共情,更容易被用户转发和分享。虚假新闻具有传播速度快、传播影响强的特点,它的广泛传播会给社会和民众造成极大的负面影响,如影响媒体的权威性和公信力,破坏健康的网络舆论环境,损坏相关组织或个人的利益等。因此,进行社交媒体虚假新闻检测是一个亟需研究的问题。
虚假新闻检测目前的方法主要包括手工构建特征并输入到分类器模型中进行分类预测,以及使用各种深度神经网络自动提取新闻中的特征并完成新闻分类。由于新闻蕴含丰富的信息,仅通过新闻文本难以判定新闻的真假,越来越多的研究者开始关注新闻文本特征之外的信息,如用户的基本信息、社交网络特征等,希望能够更加充分的利用各类特征,从而在实际应用中进一步提高虚假新闻检测的准确性。
尽管已有的虚假新闻检测方法取得了比较好的检测效果,但它们往往忽略了人们在判断新闻真假时通常会用的外部知识。虚假新闻检测是一项复杂并且很具有挑战性的任务,由于新闻本身具有的及时性、蕴含信息丰富等特点,使得仅根据新闻本身很难对新闻内容进行较好的理解。为解决上述问题,在虚假新闻检测中引入外部知识十分必要。此外,考虑到同类别的新闻之间存在相似性特征,不同类新闻之间存在差异性特征,且每条新闻对应的知识在一定程度上反应新闻的真假性。因此,本发明提出一个两阶段的基于孪生网络的知识感知虚假新闻检测方法,利用构建的孪生网络捕捉相同类别的新闻或实体知识之间存在的相似性特征以及不同类别的新闻或实体知识之间存在的差异性特征,并将这些特征与新闻相融合,辅助进行虚假新闻检测。
综上所述,基于孪生网络的知识感知虚假新闻检测是一项创新的研究问题,具有重要的研究意义和应用价值。
发明内容
本发明的目的是解决现有的虚假新闻检测方法中对新闻文本理解不充分的问题。为捕捉并融合同类别的新闻之间存在相似性特征,不同类新闻之间存在的差异性特征,以及每条新闻对应的知识在一定程度上反应新闻的真假性特征,创新性的提出了一种基于孪生网络的知识感知虚假新闻检测方法。本方法以深度神经网络为框架,捕捉同类别新闻或实体之间存在相似性特征,不同类别或实体之间存在差异性特征,这些特征反映同类新闻之间的共性以及不同类新闻之间的差异性,并通过有效的方式将新闻或实体之间的相似性特征以及差异性特征融合到新闻文本,对新闻文本的真实性进行分类。
本发明的技术方案
基于孪生网络的知识感知虚假新闻检测方法,该方法的详细内容如下:
第1、数据集获取;
本发明中使用的数据集均为英文数据集,新闻内容来自Twitter平台。通过对爬取的新闻数据进行观察,发现数据中包含一些符号组合,特殊字符,重复新闻等问题。针对这些问题,本发明分别设计不同的过滤规则,使用正则表达式等方式对新闻数据进行清洗和过滤。
完成数据清洗工作后,对新闻文本进行过滤停用词处理。停用词是指新闻文本中出现频率较高但其本身并不具备丰富含义的词。停用词主要为语言中包含的功能词,与其他词相比没有实际的含义,如句子中的“the”、“on”、“which”等词。适当的去掉停用词,可以提升关键词出现的频率,使得句子中的关键词更为突出。
对社交媒体上的新闻进行处理后,抽取出新闻源文本S和真实性标签y作为新闻样本,构造新闻数据集。
第2、根据新闻文本,通过实体链接识别出新闻中的实体提及并链接到知识图谱中对应实体,并抽取实体作为外部知识;
根据实体链接工具tagme识别出新闻中的实体提及并链接到知识图谱中的对应实体;如新闻中的实体提及“Oxxx”与知识图谱中的实体“Barack Oxxx”相对应。通过实体链接后,可以获得新闻文本对应的实体序列E={e
定义1:实体链接,定义如下:
将文本中所提及的实体链接到知识库中相应实体的过程。实体链接的输入通常包括实体的指代(提及)和上下文,以及待链接的知识库;实体链接的输出是实体提及所对应的知识库中的实体。
定义2:知识图谱,定义如下:
知识图谱是一种以实体为节点,以关系为边的有向图,边可以描述两个实体之间的关系。知识图谱以三元组的形式存储。
第3、构造新闻样本对和实体样本对;
样本对的形式为三元组(x
在进行样本对构造时,当新闻中的真新闻数量为a,假新闻数量为b时,通过样本组合的方式构造样本对,可以得到相似样本对的数量为
第4、构建新闻孪生网络,进行新闻样本对相似性判断任务;
孪生网络由两个神经网络分支组成,输入是一个样本对,输出是样本对是否相似。本方法中采用Transformer编码器作为新闻孪生网络中的基础网络,原因是Transformer能够很好的学习句子中的长距离依赖关系,并且具有较强的特征提取能力。新闻孪生网络的输入为新闻样本对,通过孪生网络中的两个分支分别对样本对中的两个新闻样本进行编码。网络中的两个分支共享网络参数W,使得模型需要学习的参数更少,并确保语义空间中成对表示的一致性,因此,孪生网络需要的训练数据相对较少,也不太容易产生过拟合现象。新闻样本对中的新闻S
c
其中,N为新闻样本对的数量,p
第5、构建实体孪生网络,进行实体样本对相似性判断任务;
实体孪生网络与新闻孪生网络相似,均采用Transformer编码器作为两个分支的基本网络。网络中的参数W由两个分支共享,每个实体样本对中的实体序列E
p
其中,N为新闻样本对的数量,p
第6、构建虚假新闻检测模型;
第6.1编码新闻表示;
采用Transformer编码器作为编码新闻文本的核心模块,给定一条长度为n的新闻文本S={w
u
其中pos
在一层的编码器中,输入编码u首先经过多头自注意力机制子层,输出表示被输入到前馈神经网络子层中,每个子层后应用残差连接和正则化层,最后,Transformer编码器的输出p作为新闻的表示。
第6.2通过训练好的新闻孪生网络分支编码新闻,获取新闻孪生表示;
为了获得相同类别新闻之间的相似特征以及不同类别新闻之间的差异性特征,使用训练好的新闻孪生网络的一个分支对新闻进行编码,并将输出的p
第6.3通过训练好的实体孪生网络分支编码实体,获取实体孪生表示;
引入新闻对应的外部知识可以提供更多的补充信息,减少新闻中实体提及引起的歧义。然而,新闻中只有部分单词或短语在知识图谱中有对应的实体,使得获得的实体序列相对比较稀疏。为了从相对稀疏的实体序列中学习更多特征,以及学习同一类别新闻对应实体之间的共同特征和不同类别新闻对应实体的差异特征,使用训练好的实体孪生网络的分支对新闻对应的实体序列进行编码,并将输出q
第7、融合新闻表示、新闻孪生表示和实体孪生表示,通过深度神经分类器进行分类。
通过将新闻编码p、新闻孪生表示p
P=softmax(W
其中,[,]是数据拼接操作,W
算法中选用的损失函数为交叉熵损失函数:
其中,D表示整个训练语料库,y
本发明的优点和积极效果是:
本发明开创性地提出了一种基于孪生网络的知识感知虚假新闻检测方法,提出利用知识图谱中的实体信息作为外部知识,并设计新闻孪生网络和实体孪生网络,来获得新闻之间以及实体之间存在的共性特征和差异性特征,从而更合理有效的将这些特征融合到新闻文本表示中。本发明有效地建模新闻文本和外部知识,并且能够捕捉并融合新闻之间以及知识之间存在的反映新闻类别信息的特征,从而在很大程度上提高了虚假新闻检测任务的准确性。
附图说明
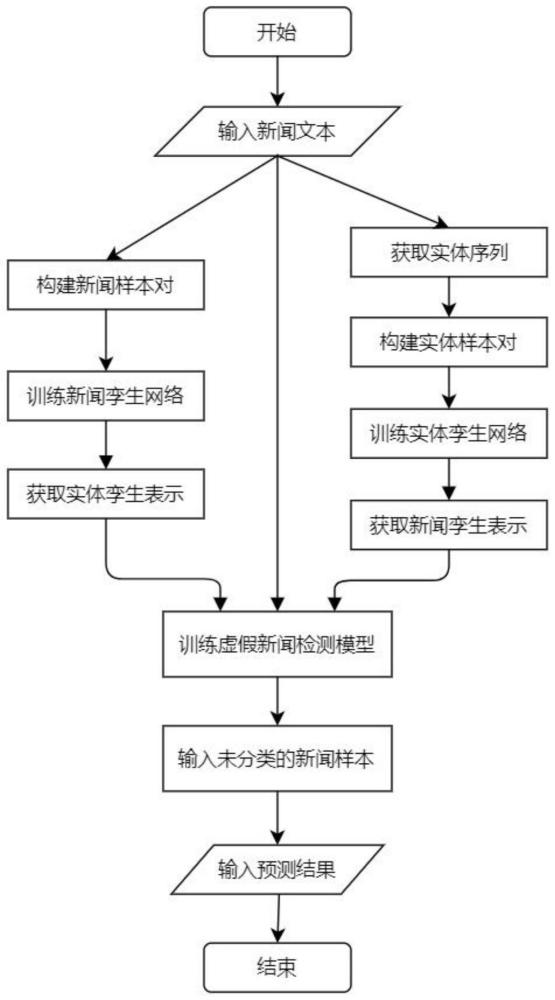
图1为基于孪生网络的知识感知的虚假新闻检测过程示意图。
图2为新闻数据集中的新闻样例。
图3为社交网络中新闻及其包含的实体提及示例图。
图4孪生网络示意图。
图5新闻/实体孪生网络示意图。
图6虚假新闻检测模型结构示意图。
图7Transformer编码器结构示意图。
图8为新闻数据集及样本对的统计信息图。
图9为与基于新闻文本的检测方法的对比结果示意图。
图10为与融合外部知识检测方法的对比结果示意图。
图11为消融实验结果。
具体实施方式
本发明提出一种基于孪生网络的知识感知虚假新闻检测方法,方法的主要流程如图1所示。下面结合附图详细说明本发明的具体实施方式。
本发明的具体实施过程分为七个步骤:获取新闻数据集;抽取知识图谱中的相关实体作为外部知识;构造新闻样本对和实体样本对;构建新闻孪生网络,对新闻样本对相似性进行判断;构建实体孪生网络,对实体样本对相似性进行判断;构建虚假新闻检测模型,融合新闻表示、新闻孪生表示和实体孪生表示,通过深度神经网络分类器进行分类;进行虚假新闻检测。以下是七个步骤的实施过程的具体说明:
第1、数据集获取;
获取来自社交媒体上的新闻后,进行数据处理后,抽取出新闻源文本S和真实性标签y作为新闻样本,构造新闻数据集。图2为典型的社交媒体新闻样本,样本中的被标记的词为实体提及,可以看到,新闻文中包含大量的实体提及,这些提及对于新闻文本的理解起至关重要的作用。
第2、根据新闻文本,抽取知识图谱中的相关实体作为外部知识;
根据实体链接识别出新闻中的实体提及并链接到知识图谱中的对应实体。通过实体链接后,将新闻文本中的每一个实体提及和知识图谱中每一个实体相对应,如图3中所示,新闻中的被标记的实体提及“第33区”与知识图谱中的实体“纽约第33选区”相对应,通过将新闻中的每个实体提及与知识图谱中的实体相对齐后,可以获得新闻文本对应的实体序列E={e
第3、构造新闻样本对和实体样本对;
本方法中采用样本组合的方式构造样本对。对于新闻样本对的构造,将同类别的两条新闻构造成相似新闻样本对,即两条新闻均为真新闻或均为假新闻,用(S
第4、构建新闻孪生网络,进行新闻样本对相似性判断任务;
孪生网络由两个神经网络分支组成,输入是一个样本对,输出是样本对是否相似,如图4所示。本方法中采用Transformer编码器作为新闻孪生网络中的基础网络。新闻孪生网络的输入为新闻样本对,通过孪生网络中的两个分支分别对样本对中的两个新闻样本进行编码,网络中的两个分支共享网络参数W。新闻样本对中的新闻S
c
其中,N为新闻样本对的数量,p
第5、构建实体孪生网络,进行实体样本对相似性判断任务;
实体孪生网络与新闻孪生网络相似,均采用Transformer编码器作为两个分支的基本网络。网络中的参数W由两个分支共享,每个实体样本对中的实体序列E
p
其中,N为新闻样本对的数量,p
第6、构建虚假新闻检测模型,融合新闻表示、新闻孪生表示和实体孪生表示,通过深度神经分类器进行分类;
完成新闻孪生网络和实体孪生网络的训练后,开始进行虚假新闻检测任务,虚假新闻检测任务的模型结构如图6所示。
第6.1编码新闻表示;
采用Transformer编码器作为编码新闻文本的核心模块,给定一条长度为n的新闻文本S={w
u
其中pos
在一层的编码器中,输入编码u首先经过多头自注意力机制子层,输出表示被输入到前馈神经网络子层中,每个子层后应用残差连接和正则化层,最后,Transformer编码器的输出p作为新闻的表示。新闻文本编码的过程如图7所示。
第6.2通过训练好的新闻孪生网络分支编码新闻,获取新闻孪生表示;
为了获得相同类别新闻之间的相似特征以及不同类别新闻之间的差异性特征,使用训练好的新闻孪生网络的一个分支对新闻文本进行编码,并将输出的p
第6.3通过训练好的实体孪生网络分支编码实体,获取实体孪生表示;
引入新闻对应的外部知识可以提供更多的补充信息,减少新闻中实体提及引起的歧义。然而,新闻中只有部分单词或短语在知识图谱中有对应的实体,使得获得的实体序列相对比较稀疏。为了从相对稀疏的实体序列中学习更多特征,以及学习同一类别新闻对应实体之间的共同特征和不同类别新闻对应实体的差异特征,使用训练好的实体孪生网络的分支对新闻对应的实体序列进行编码,并将输出q
第6.4融合新闻表示、新闻孪生表示和实体孪生表示,通过深度神经分类器进行分类;
通过将新闻编码p、新闻孪生表示p
P=softmax(W
其中,[,]是数据拼接操作,W
算法中选用的损失函数为交叉熵损失函数:
其中,D表示整个训练语料库,y
第7、虚假新闻检测
本方法中评估虚假新闻检测准确度的主要指标是准确率、召回率、精确度、F1和AUC。实验结果表明,本发明在新闻检测的准确度方面领先于其他方法。
本方法在两个真实的英文虚假新闻检测数据集上进行实验。第一个数据集PolitiFact来自用于虚假新闻检测的基准数据FakeNewsNet。第二个数据集是PHEME,由Twitter平台上的推文组成,收集5种类型的突发新闻。由于PHEME数据集中新闻样本较多,如果使用全部的新闻样本构造样本对,会导致样本对数量过多,因此,在样本对相似性任务中选取该数据集中的部分样本进行样本对构造,正负样本对的选取方式为随机抽取。数据集中的新闻分为真实新闻和虚假新闻两类,数据集的统计信息如图8所示。
本发明中提出的虚假新闻检测方法名为TSN,通过将TSN与基于新闻内容的检测方法的实验结果进行对比可知,本方法在虚假新闻检测的准确度方面取得了较大地提高,实验结果如图9所示。通过对比实验结果可以发现,深度学习方法普遍优于传统方法,这是由于传统方法通过手工特征或者规则进行构建,与深度学习相比,学习特征的能力较差,这也验证了深度学习模型具有较强的自动捕捉新闻本文特征并学习的能力。
除目前常用的基于新闻内容的检测方法外,还将TSN方法与目前已有的融合外部知识的虚假新闻检测方法进行对比。在融合外部知识的检测方法中,通常使用深度学习模型,并且在融合外部知识的帮助下,虚假新闻检测效果较基于新闻内容的方法有了很大的提升。图10展示了TSN方法与其他融合知识的虚假新闻检测方法的实验结果,实验结果表明,TSN方法取得的效果最优。可以证明,通过孪生网络捕捉的新闻样本对和实体样本对的相似性特征及差异性特征,能够与新闻文本本身的特征互补,对于模型判断新闻的真假类别很有利。此外,借助实体孪生网络的方式融合实体知识,在融合实体知识的同时,也对不同实体序列之间的相似性和差异性特征进行融合,能够更充分的利用实体知识。
TSN方法取得较好的效果,其优势归因于三个方面:1)TSN利用新闻孪生网络来捕捉同类新闻样本对的相似性特征,不同类别新闻样本对的差异性特征,并通过新闻孪生网络来学习新闻孪生表示,为新闻文本表示提供与新闻类别相关的补充信息。2)TSN通过实体孪生网络来融合实体序列,可以消除新闻中实体提及引起的歧义,并获得新闻实体之间相似和差异信息。3)通过使用训练好的新闻孪生网络和实体孪生网络来编码新闻和实体,获得两者的表示与新闻表示互补,增强模型的检测能力。
为深入探究TSN方法中各个主要组成部分的重要性,分别设计消除TSN模型中借助新闻孪生网络学习到的新闻孪生表示(News Siamese Representation,NSR)和借助实体孪生网络学习到的实体孪生表示(Entities Siamese Representation,ESR)的消融实验,获得TSN方法去掉NSR的变体TSN\NSR和去掉ESR的TSN\ESR,以分析缺少某些部分时对本章模型的影响。图11清晰的展示TSN方法在两个真实新闻数据集上执行虚假新闻检测任务的消融实验结果。
由消融实验的结果可知,TSN方法整体上比其余消除某些部分的TSN变体检测效果要好。这证明消融实验中的新闻孪生表示和实体孪生表示都是TSN方法的重要组成部分,缺少其中任意一个,TSN模型的检测效果都会有所下降。通过对比两数据集上TSN与TSN\NSR的实验结果,可以发现去掉新闻孪生表示后,实验结果降低,证明新闻孪生表示能够学习到新闻表示之外的特征,并且能够为新闻表示提供辅助信息,有助于判断新闻的真假。通过将表中的TSN与TSN\ESR实验结果进行对比可以发现,去掉实体孪生表示后,实验结果下降明显,由此可以推断,融合与新闻相关的实体知识可以起到消除新闻中实体提及带来歧义的问题,而且通过训练好的实体孪生网络来编码实体序列,可以额外捕捉到与其他实体序列的联系或差异特征。基于此可以推出结论:通过融合基于孪生网络的新闻孪生表示和实体孪生表示对虚假新闻检测十分有益。
综上可知,本发明提出的TSN方法,其一方面能够通过构建的新闻孪生网络来捕捉新闻之间的相似性或差异性特征,另一方面使用构建的知识孪生网络捕捉新闻对应的知识反应新闻真假性的特征。在新闻文本特征的基础上,增加蕴含新闻类别相关的新闻信息和实体知识信息,来进行虚假新闻检测。本发明在两个真实数据集上进行了大量的实验,并与其他虚假新闻检测方法进行对比,证实了本方法的有效性。此外,消融实验表明新闻孪生表示和实体孪生表示对于虚假新闻检测十分有益。
- 一种基于知识感知注意力网络的虚假新闻检测方法
- 一种基于知识感知注意力网络的虚假新闻检测方法