一种全局音频特征增强的模态顺序感知的多模态情感分类方法及系统
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及深度学习、自然语言处理、多模态融合等技术,具体涉及一种全局音频特征增强的模态顺序感知的多模态情感分类方法及系统。
背景技术
近年来,网络媒体中的信息呈爆炸式增长,这些信息中往往蕴含着丰富的情感。对这些信息的情感进行准确的分析,是许多场景的现实需求。比如,对一个商品的评论类信息进行情感分析,可以得知人们对该商品的满意度,这对商品设计、营销等具有重要意义。再比如,对某个事件的点评类信息进行分析,可以得知人们对该事件的主流态度和其它不同的态度,这对舆情分析和引导具有重要意义。另外,当前的许多信息不只是以文字的形式呈现,还会以视频的形式出现,比如自媒体中对某部电影的测评视频,以及对某个事件的点评视频。视频中包含了文字、音频、视觉三个模态,这三个模态对情感的判断都起着不可或缺的作用。有时候仅凭文字无法做出准确的情感分类,甚至有可能做出完全相反的分类。比如“我现在很好”这句话,只看文字可能会被认为是包含积极的情感,但是如果视频中说话者说这句话的时候带着阴阳怪气的语调或者悲伤的表情,那么整个视频就会表现出一种消极的情感。因此,如何融合不同模态的信息并且对视频的情感做出准确的判断,已经成为了一项非常实用且有意义的研究课题。
多模态情感分析技术就是一项针对一段视频,利用其中文本、音频、视觉等模态的信息,对整个视频表达的情感做出分类和判断的技术。当下该技术的对象一般为评论者发表的评论,故视频中三个模态的特征都是按照时间线对应的。该技术的核心在于如何有效融合三个模态的特征,目前绝大多数方法都是平等地对待三个模态,即将三个模态的特征视为同等重要、相同等级的信息,在融合时没有区分不同模态的重要程度。但是,根据生活经验和之前工作的结果,三个模态对情感的贡献是不一致的。文本往往占据核心地位,因为它提供了最基础的语义信息。音频提供了声调变化等特征,也在情感分析中发挥着重要作用。视觉模态中人脸表情变化等信息也对情感分类有帮助,但是表情的变化有时没有声调变化那样更容易被捕捉,而且画面中常常会出现其他无关人员,甚至没有人出镜的场景,这给情感分析带来了消极的噪声。因此,三个模态对情感的贡献并不是一致的,需要分层次、按顺序地融合。此外,目前的方法都是将视频分成若干帧,在帧等级上提取音频和视觉特征,再在与文本单词对应的时间段内合并。这样做损失了视频全局的声调变化信息,而这对视频的情感分类来说,是至关重要的。
发明内容
针对上述技术问题,本发明提出一种全局音频特征增强的模态顺序感知的多模态情感分类方法及系统,以解决之前方法中没有区分不同模态重要性和没有利用全局音频特征的问题。
为了解决上述技术问题,本发明的技术方案如下:
一种全局音频特征增强的模态顺序感知的多模态情感分类方法,包括如下步骤:
分别获得视频的文本、音频、视觉三个模态的信息;
将文本、音频、视觉三个模态的信息输入到全局音频特征增强的模态顺序感知的多模态情感分类模型AMOA(global Acoustic feature enhanced Modal-Order-Awarenetwork)中,进行分类预测;
根据预测结果,获取视频的情感类别。
进一步地,所述分别获得视频的文本、音频、视觉三个模态的信息,包括:分别获得视频的文本、音频和视觉的原始文件,其中文本为若干特征组成的句子,音频文件为视频转化而来的wav文件,视觉文件为原视频去掉声音的mp4文件。
进一步地,所述全局音频特征增强的模态顺序感知的多模态情感分类模型的构建方法,包括:
(1)分别对三个模态的信息进行编码,得到单模态嵌入向量,即单模态特征向量;
(2)将步骤(1)中得到的单模态特征向量输入到顺序感知的模态融合网络中,按照文本-音频-视觉的顺序先后融合三个模态的特征,得到模态融合特征向量;
(3)提取视频的全局音频特征,得到对应特征向量,并进行编码,得到全局音频特征向量;
(4)将步骤(2)得到的模态融合特征向量和步骤(3)得到的全局音频特征向量对齐并且融合后,输入到分类网络进行分类预测,之后和步骤(1)、(2)、(3)一起,通过反向传播算法进行训练;
(5)将需要情感分类的视频的三个模态的信息输入到训练完成的AMOA中,预测出对应的情感分类。
进一步地,所述模型AMOA的构建方法的步骤(1)的具体方法包括:
(1-1)对文本模态,使用已预训练好的语言模型BERT进行编码,得到文本特征向量,这里的BERT是可训练的;
(1-2)对音频模态,使用openSMILE工具包,以一定帧率逐帧提取音频特征,再根据文本的单词对应时间段,和文本进行对齐,之后使用Transformer编码端对特征进行编码,得到音频特征向量;
(1-3)对视觉模态,使用OpenFace2工具包,以一定帧率逐帧提取特征向量,再根据文本的单词对应时间段,和文本进行对齐,之后使用Transformer编码端对特征进行编码,得到视觉特征向量;
更进一步地,步骤(1)中得到的三个模态的特征向量,在对齐后的形状是一致的,即前两维都是批大小和序列长度,只有最后一维不同,分别是不同的嵌入长度。因此在进行下一步骤即步骤(2)前,需要经过一个前馈神经网络,将三个模态特征向量的嵌入长度进行统一,这样做有助于后面在模态顺序感知网络的融合。
进一步地,所述模型AMOA的构建方法的步骤(2)的具体方法包括:
(2-1)首先将文本和音频特征向量输入到一个N层的跨模态融合模块中,该跨模态融合模块是基于Transformer的编码段进行设计的;在跨模态融合模块的每一层,首先以文本为K和V,音频为Q,进行多头注意力的计算,之后经过残差和标准化,再经过一个前馈神经网络,最后再经过残差和标准化,将结果输入到下一层,最后得到文本和音频的融合特征向量;其中K表示注意力机制中的键,V表示注意力机制中的值,O表示注意力机制中的查询;
(2-2)类似步骤(2-1),将文本音频融合特征向量和视觉向量输入到一个N层的跨模态融合模块中,最后得到文本-音频-视觉的模态融合特征向量E
进一步地,所述模型AMOA的构建方法的步骤(3)的具体方法包括:
(3-1)使用openSMILE提取全局的音频特征,与步骤(1-2)不同的是,本步骤是直接对整个视频提取而不是在帧等级上提取;
(3-2)使用Transformer编码端对提取的音频特征进行编码,得到全局音频特征向量E
进一步地,因为步骤(2)得到的模态融合特征和步骤(3)得到的全局音频特征分别处在不同的语义空间,不能直接拼接,所以需要在拼接分类前进行对齐,步骤(4)中我们使用对比学习的方法将两者对齐。
进一步地,所述模型AMOA的构建方法的步骤(4)的具体方法包括:
(4-1)构建一个队列,用来存储模态融合特征和全局音频特征组成的特征对,即队列中每一个样例对为
(4-2)当需要对一个视频样例进行分类时,该样例经过步骤(1)、(2)、(3)后,得到了模态融合特征和全局音频特征,两者互为正样本,而该样例的模态融合特征与队列中的所有全局音频特征互为负样本,样例中的全局音频特征与队列中的所有模态融合特征互为负样本;
(4-3)使用余弦相似度,计算待处理样例与正样本、负样本之间的相似度分数,这里要注意,正样本对有一组,是待处理样例内的模态融合特征与对应的全局音频特征,而负样本有两组,是样例中的模态融合特征与队列中的全局音频特征,以及样例中的全局音频特征与队列中的模态融合特征,然后使用NCE损失函数计算损失值loss_c,该损失函数使正样本之间的相似度趋于增大,使样例与负样本之间的相似度趋于减小;
(4-4)处理完该样例后,将其变成一个新的
(4-5)将步骤(2)中得到的模态融合特征和步骤(3)中得到的全局音频特征拼接起来,输入到一个前馈神经网络,进行分类,并且使用MSE损失函数计算分类损失值loss_f;
(4-6)将loss_f和loss_c以一定比重相加,得到最终的损失值,并由这个损失值,根据反向传播算法进行模型的训练。
一种全局音频特征增强的模态顺序感知的多模态情感分类系统,包括:
单模态特征提取模块,用于提取视频的文本、音频、视觉三个模态的单模态特征向量;
模态顺序感知融合模块,用于将三个模态的单模态特征向量输入到顺序感知的模态融合模型中,得到模态融合特征向量;
全局音频增强模块,用于对整个视频提取全局的音频特征,再进行编码,得到全局音频特征向量,然后使用对比学习将其与模态融合特征进行对齐;
分类预测模块,用于将模态融合特征和全局音频特征拼接后输入前馈神经网络进行分类,获得视频的情感类别。
进一步地,所述单模态特征提取模块:对视频中的原始文本,使用BERT编码,得到文本嵌入词向量,作为文本特征向量;对原始音频文件,使用openSMILE工具提取特征后再使用Transformer编码端进行编码,作为音频特征向量;对原始视频文件,使用OpenFace2工具提取特征后再使用Transformer编码端进行编码,作为视觉特征向量。
进一步地,所述全局音频增强模块对整个视频使用openSMILE工具提取全局的音频特征,再使用Transformer编码端进行编码,得到全局音频特征向量,然后使用对比学习将其与模态融合特征进行对齐。
本发明的有益效果在于:针对多模态情感分类任务中的两个问题,一是不同模态对情感贡献不一致,二是传统多模态分类方法忽略了视频整体的音调变化,提出了全局音频特征增强的模态顺序感知的多模态情感分类模型来对视频进行情感分类,具体为:在提取三个模态的特征向量后,以文本-音频-视觉的顺序先后融合三个模态的特征,以充分利用文本和音频模态的信息,并且较少视觉模态中噪声的影响;提取视频的全局音频信息,以捕捉视频整体的音调变化;将模态融合特征和全局音频特征对齐后,进行拼接和分类。这样,本发明一是通过一定顺序的融合方式来解决不同模态贡献不一致的问题,二是通过利用全局的音频特征来捕捉整体的音调变化,从而提高了情感分类的准确率,具有良好的实用性。
附图说明
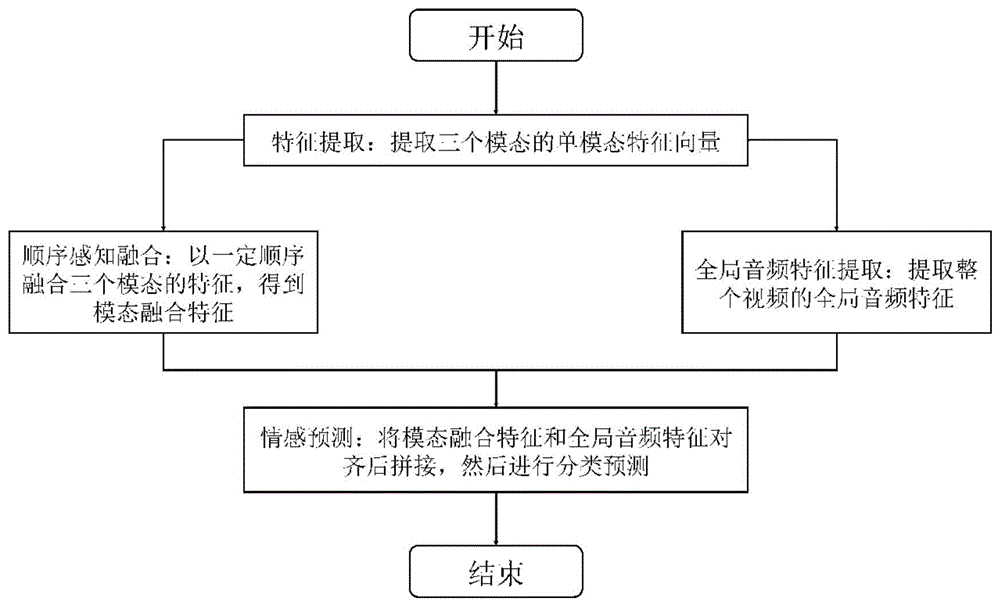
图1为本发明实施例提供的全局音频特征增强的模态顺序感知的多模态情感分类流程图;
图2为本发明实施例的神经网络模型结构图;
图3为图2的模型图中跨模态融合模块的具体结构图,其中T、A、V分别表示文本、音频和视觉,CMT表示跨模态融合模块,Encoder表示编码器,A(global)表示全局音频特征,MLP表示多层感知机。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面通过具体实施案例并结合附图,对本发明做进一步详细说明。
图1为全局音频特征增强的模态顺序感知的多模态情感分类方法的流程图,如图所示,该方法主要包括四个阶段,分别是单模态特征提取阶段、模态顺序感知融合阶段、全局音频特征提取阶段和最后的情感分类预测阶段。整个方法是需要先在训练数据上进行训练后,再被应用到实际的分类预测中。
(一)单模态特征提取阶段
步骤1,对文本,将原句直接输入到已经预训练好的BERT-base-uncased模型中,得到文本特征向量
步骤2,对音频,使用openSMILE工具,以10ms的帧移和25ms的帧大小进行音频特征的提取,提取的特征中包含MFCC、PLP等低级特征描述符以及对它们应用不同函数后得到高级特征描述符,将这些特征值拼成向量,得到
步骤3,对视觉,使用OpenFace2工具,以10ms的帧移和25ms的帧大小进行视觉特征的提取,然后像音频一样,使用P2FA进行对齐,然后使用Transformer编码端进行编码,得到视觉特征向量
(二)模态顺序感知融合阶段
步骤1,首先融合文本和音频模态,这里以Transformer编码端为基础,设计了跨模态融合模块CMT,如图2、图3所示,CMT是一个多层结构,每一层接收base和addition两个输入,并且输出融合特征。其中用作K和V的输入称为base,用作Q的输入是新加入的信息,称为addition。进一步地,详细介绍CMT的内部结构:
步骤1-1,在CMT的第一层,输入的文本特征向量是base,音频特征向量是addition,首先是一个多头注意力模块,该模块以base作为K和V,以addition作为Q:
Z=MHA(addition,base,base)
MHA为多头自注意力模块,然后经过一个对Q的残差、相加和标准化模块:
Z′=Norm(Z+addition)
之后经过一个前馈神经网络:
Z″=FeedForward(Z′)
然后再经过一个对Z′的残差和标准化模块:
得到的
步骤1-2,在CMT的第二层和后面各层中,输入的base仍然是初始的文本特征不变,而addition是上一层的输出,是不断更新的:
得到的
步骤2,融合视觉模态,仍然使用跨模态融合模块CMT,在第一层以文本音频融合特征为base,以视觉模态特征为addition,在第二层及之后的的每层,仍然以文本音频融合特征为base不变,而addition是上一层的输出,不断更新,整个步骤可以表达为:
E
之后经过一个dropout层和maxpooling层,得到模态融合特征:
E
其中
(三)全局音频特征提取阶段
步骤1,对音频,使用openSMILE工具,不分帧,直接提取整个视频的声学特征,这些特征与阶段(一)提取的单模态音频特征是相同的,得到一个一维的向量
步骤2,使用Transformer的编码端对X
步骤3,因为模态融合特征E
步骤3-1,构造一个队列,存储(E
步骤3-2,在训练和预测时,为了加快速度,一般是同时处理一个批的样本,假设批大小为B,将这一批中的所有的E
步骤3-3,待处理的一批样本中,每个样例的E
其中S
步骤3-4,负样本有两组,分别是
其中
步骤3-5,将三个相似度矩阵拼接成一个大矩阵:
其中S∈R
步骤3-6,使用NCE损失函数计算损失值,使S矩阵的第一列的值增大,其余列的值减小:
其中S
步骤3-7,将这一批的样本加入到队列中,如果此时队列大小超过了K,则从队首弹出一定数量的样本对使得队列大小不超过K。
(四)情感分类预测阶段
步骤1,将模态融合特征和全局音频特征拼接起来:
R=Concat(E
步骤2,将R输入一个前馈神经网络,对输出结果进行分类:
其中
步骤3,在训练时,使用MSE损失函数计算分类的损失值loss_f,和loss_c以一定权重α相加,得到最后总的损失值:
loss=(1-α)·loss_f+α·loss_c
由上述方案可以看出,本方案针对多模态情感分类任务中的两个问题,一是不同模态对情感贡献不一致,二是传统多模态分类方法忽略了视频整体的音调变化,提出了全局音频特征增强的模态顺序感知的多模态情感分类模型来对视频进行情感分类,可以提高模型预测的性能,具有良好的实用性。
本发明的另一实施例提供一种全局音频特征增强的模态顺序感知的多模态情感分类系统,包括:
单模态特征提取模块,用于提取视频的文本、音频、视觉三个模态的单模态特征向量;
模态顺序感知融合模块,用于将三个模态的单模态特征向量输入到顺序感知的模态融合模型中,得到模态融合特征向量;
全局音频增强模块,用于对整个视频提取全局的音频特征,再进行编码,得到全局音频特征向量,然后使用对比学习将其与模态融合特征进行对齐;
分类预测模块,用于将模态融合特征和全局音频特征拼接后输入前馈神经网络进行分类,获得视频的情感类别。
其中各模块的具体实施过程参见前文对本发明方法的描述。例如,单模态特征提取模块对视频中的原始文本,使用BERT编码,得到文本嵌入词向量,作为文本特征向量;对原始音频文件,使用openSMILE工具提取特征后再使用Transformer编码端进行编码,作为音频特征向量;对原始视频文件,使用OpenFace2工具提取特征后再使用Transformer编码端进行编码,作为视觉特征向量。全局音频增强模块对整个视频使用openSMILE工具提取全局的音频特征,再使用Transformer编码端进行编码,得到全局音频特征向量,然后使用对比学习将其与模态融合特征进行对齐。
本发明的另一实施例提供一种计算机设备(计算机、服务器、智能手机等),其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
本发明的另一实施例提供一种计算机可读存储介质(如ROM/RAM、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现本发明方法的各个步骤。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明构思的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明保护范围内。