一种基于M-Bert的恶意网站检测模型的训练及检测方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及互联网网络安全技术领域,特别涉及一种基于M-Bert恶意网站检测模型的训练及检测方法。
背景技术
随着互联网的普及,网址诈骗成为了一种普遍存在的网络犯罪行为。网址诈骗指的是利用虚假或伪装的网站诱骗用户泄露个人信息或进行欺诈活动的行为,这种行为可能会导致用户的财产、隐私以及个人信息的泄露和被盗用。例如,钓鱼网站通常会伪装成银行、电商等网站,诱骗用户输入用户名和密码,以获取用户的账户信息。还有一些恶意网站可能会利用漏洞攻击用户的设备,植入恶意软件,甚至导致用户的设备被感染病毒,影响设备的正常使用。在这个大数据时代,解决恶意网址的检测成为了一个亟待解决的问题。最近,随着生成式预训练大模型的发行,几个月期间更大的生成式模型也横空出世,各个领域都在向大模型靠拢,国内外的研究者在恶意网址检测领域都取得了一定的成果,但是面对多变、时效的恶意网址依然束手无策。基于机器学习的研究,大多数都需要自己提取相关网址特征,不仅耗时,面对现在多变的涉诈网址也是无能为力。而基于LSTM与CNN等深度学习等模型提出的恶意网址检测方法,虽然能够自动提取特征,但是对于恶意网址的特点,比如时效性短,变化频繁和迅速,对于其不断更改替换的各种特征也手足无策。
在现有技术中,针对恶意网站的检测方法主要包括三种途径:黑白名单数据库、机器学习(ML)算法,以及深度学习(DL)技术。
黑白名单数据库方法是一种最传统的恶意网站检测方式。它依赖于维护一个数据库,其中包含已知的恶意URL,这些URL会被列入黑名单。同样地,已知的良性URL会被列入白名单。当新的URL出现时,系统会对其进行检查,如果在黑名单中找到匹配项,就会被识别为恶意网站,否则被视为良性。尽管这种方法在处理已知恶意网址上可能有效,但其主要缺点在于无法及时检测新出现的、未被列入黑名单的恶意URL,从而使得新型恶意网站容易逃避检测。
其次,机器学习算法被应用于恶意网站检测的第二种方法。研究人员通过采用诸如逻辑回归和决策树等常见的机器学习算法,将URL、域名和域名长度等数值特征输入模型,以进行分类和识别恶意网站。尽管这种方法在一定程度上提高了检测准确率,但由于需要人工设计特征和进行广泛的特征选择,其应对恶意网站不断演变的能力有限。
第三种方法采用深度学习技术,其中包括卷积神经网络(CNN)和长短期记忆(LSTM)模型。这些深度学习模型在恶意网站检测方面取得了更高的准确率。然而,恶意网站的不断变化和多样性使得CNN和LSTM模型难以捕捉到恶意网站的复杂特征和语义理解,因此,在面对新型恶意网站时,这些模型可能表现不佳。
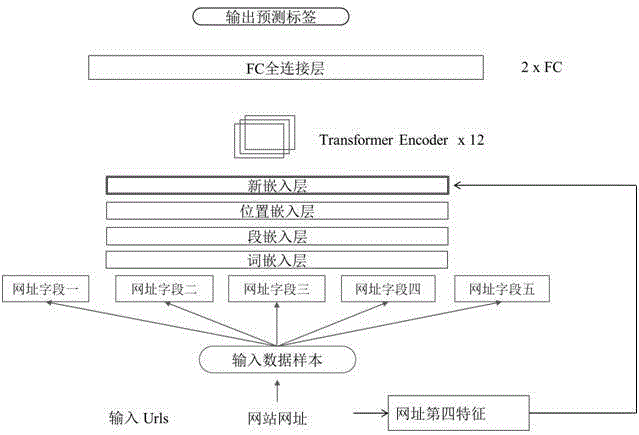
在现有技术中,也有采用Bert模型进行恶意网址检测的方式,Bert模型是基于Transformer编码器的一种预训练模型,它可以用于各种自然语言处理任务。Bert模型的输入嵌入层包括了三个嵌入层,其中词嵌入层是对每个词的静态表示,位置嵌入层是对每个词的位置信息进行编码,段嵌入层用于区分两个句子中的词。输入嵌入层接收一个词序列作为输入,并将每个词都映射到一个d维向量上,包括:词向量Token Embedding、位置向量Position Embedding、分割向量Segment Embedding 。经过嵌入之后,再经过多层的Transformer Encoder模块即可完成整个Bert模型,其中Bert模型如图1所示。可以直观的看到输入文本经过输入嵌入层后得到了一个向量表示结果,再经过12层TransformerEncoder模块后,得到了最后的输出表征。但是,现有的Bert模型除了可以输入文本信息,对于其他的信息无法嵌入,然而,恶意网址具有非常多的特征,比如域名、域名长度、小数点的数量,现有的Bert模型对这些信息无法进行融合。
综上所述,现有技术在恶意网站检测方面仍面临一系列挑战,包括缺乏及时性、特征选择的主观性和深度学习模型的理解能力限制。
发明内容
基于以上问题,本发明的第一目的在于提供一种基于M-Bert的恶意网站检测模型的训练方法,该方法对现有的Bert模型进行了创新,在现有Bert模型基础上引入新嵌入层,得到一种新的M-Bert模型,使得在恶意网址识别时能嵌入更多特征,不仅包含域名长度、小数点的数量,也可以嵌入网页图片、网页文本、网页源代码,这样训练出来的基于M-Bert的恶意网站检测模型能够提高恶意网站检测的准确性和有效性,并能更好地应对新型的恶意网站威胁。
本发明实现其第一发明目的所采用的技术方案是,一种基于M-Bert的恶意网站检测模型的训练方法,其步骤包括:
S1、采集数据集,将人工采集的数据集以及网络上开源的数据集,没有标签的进行标注,标注后将数据集以预定的比例划分成训练数据集与测试数据集;
S2、对多元交叉熵损失函数、AdamW优化器进行初始化,其中多元交叉熵损失函数为:
式中:p为概率分布,i为类别序号,p
S3、在PyTorch深度学习平台中使用Dataloader数据加载器加载和处理数据,Dataloader数据加载器将训练数据集和测试数据集转换为PyTorch张量并分成预定数量批次,每个训练批次包含一组输入样本和其对应的标签;
S4、从所述步骤S3中得到的预定数量批次数据中取出一个批次的数据送入M-Bert模型,进行前向传播操作,所述M-Bert模型包括词嵌入层、位置嵌入层、段嵌入层、以及新嵌入层共四个嵌入层,其中新嵌入层用于嵌入网址第四特征;前向传播操作具体为:数据通过所述四个嵌入层分别得到恶意网址的词向量Token Embedding、位置向量PositionEmbedding、分割向量Segment Embedding、以及新特征向量New Embedding共四个向量;所述四个向量再经过M-Bert模型的12层Transformer Encoder模块,得到一个更强的网址向量表征;将更强的网址向量表征前向传播进入M-Bert模型的两层FC全连接层进行分类得到输出,即为预测标签,预测标签用于计算多元交叉熵损失函数;
S5、使用多元交叉熵损失函数将上述步骤S4中得到的预测标签与实际标签进行比较计算损失值,绘制损失曲线,通过损失曲线判断M-Bert模型的训练情况,如果损失值小于一个预定值,则停止训练,得到基于M-Bert的恶意网站检测模型,否则,转入步骤S6;
S6、进行反向传播操作,将步骤S5中得到的损失值回传到M-Bert模型的权重参数,更新这些参数以最小化损失,所述反向传播操作通过求解多元交叉熵损失函数对模型参数的梯度实现,使用步骤S2中初始化完成的AdamW优化器根据梯度更新M-Bert模型参数,再转入步骤S4。
进一步,步骤S1中,数据集按照训练数据集:测试数据集=7:3的比例划分。
进一步,步骤S4中,所述网址第四特征至少包括下述元素之一:域名长度、小数点的数量、网页图片、网页文本、网页源代码。
进一步,步骤S5中,所述预定值等于0.0005。
本发明的第二目的在于提供一种基于M-Bert的恶意网站检测模型的检测方法,该方法能实现对恶意网站的准确、有效检测。
本发明实现其第二发明目的所采用的技术方案是,一种基于M-Bert的恶意网站检测模型的检测方法,其步骤包括:
A1、在PyTorch深度学习平台中,将根据上述的一种基于M-Bert的恶意网站检测模型的训练方法得到的基于M-Bert的恶意网站检测模型设置为推理模式;
A2、将待检测的网址输入步骤 A1中已设置为推理模式的所述检测模型,经过检测模型的推理,得到该待检测的网址的预测结果。
本发明的有益效果为:
一、提高了恶意网站检测的准确性
M-Bert模型融合了更多的网址特征,相较于传统的基于规则或特征工程的方法,可以更全面地捕捉恶意网址的特征,进一步提高了恶意网址识别的准确性。例如,M-Bert模型可以利用字符级别、词级别、域名级别等不同级别的网址特征,从而提高模型对恶意网址的识别能力。
二、提高了模型的泛化能力
M-Bert模型基于现有BERT模型进行改进,在Transformer Encoder模块上与BERT相同,可以适应各种自然语言处理任务,并具有很强的泛化能力。这使得M-Bert模型可以更好地处理不同领域、不同语种的网址数据,具有更好的泛化能力。
三、增强了模型对网址的理解能力
M-Bert模型引入一个新嵌入层用于融合更多的网址特征,可以更全面地理解网址的含义和特征。例如,该嵌入层可以将字符级别、词级别、域名级别等不同级别的网址特征进行融合,从而更好地捕捉网址的语义信息和结构信息,提高模型对网址的理解能力。
四、可扩展性强
M-Bert模型可以通过Fine-tuning的方式适应不同的自然语言处理任务,具有很强的可扩展性。这意味着,可以将M-Bert模型用于其他与文本相关的任务,如文本分类、情感分析等。此外,M-Bert模型可以使用大规模的已标记数据进行预训练,可以提高模型的泛化能力和稳定性,同时也为Fine-tuning提供了更好的初始化模型。
附图说明
图1为现有Bert模型结构示意图;
图2为本发明实施例M-Bert模型结构示意图。
实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。
实施例
本发明的第一种具体实施方式,一种基于M-Bert的恶意网站检测模型的训练方法,其步骤包括:
S1、采集数据集,将人工采集的数据集以及网络上开源的数据集,没有标签的进行标注,标注后将数据集以7:3比例划分成训练数据集与测试数据集,数据集包含恶意网址的域名、域名的长度、网页源代码、响应网址的图片或文本信息;所述训练数据集用于模型训练,测试数据集用于模型评估;
本实施例中,共采集了600万条数据,按照训练数据集:测试数据集=7:3的比例划分,其中训练数据集包含420万条数据,测试数据集包含180万条数据;
S2、对多元交叉熵损失函数、AdamW优化器进行初始化,其中多元交叉熵损失函数为:
式中:p为概率分布,i为类别序号,p
S3、在PyTorch深度学习平台中使用Dataloader数据加载器加载和处理数据,Dataloader数据加载器将训练数据集和测试数据集转换为PyTorch张量并分成预定数量批次,每个训练批次包含一组输入样本和其对应的标签;
本实施例中,每个训练批次包含512条数据的样本及其对应的标签;
S4、从所述步骤S3中得到的预定数量批次数据中取出一个批次的数据送入M-Bert模型,进行前向传播操作,所述M-Bert模型包括词嵌入层、位置嵌入层、段嵌入层、以及新嵌入层共四个嵌入层,其中新嵌入层用于嵌入网址第四特征;所述网址第四特征至少包括下述元素之一:域名长度、小数点的数量、网页图片、网页文本、网页源代码;前向传播操作具体为:数据通过所述四个嵌入层分别得到恶意网址的词向量Token Embedding、位置向量Position Embedding、分割向量Segment Embedding、以及新特征向量New Embedding共四个向量;所述四个向量再经过M-Bert模型的12层Transformer Encoder模块,得到一个更强的网址向量表征;将更强的网址向量表征前向传播进入M-Bert模型的两层FC全连接层进行分类得到输出,即为预测标签,预测标签用于计算多元交叉熵损失函数;在多元交叉熵损失函数中,总类别数C即来自于两层FC全连接层进行分类的结果;所述M-Bert模型如图2所示;
S5、使用多元交叉熵损失函数将上述步骤S4中得到的预测标签与实际标签进行比较计算损失值,绘制损失曲线,通过损失曲线判断M-Bert模型的训练情况,如果损失值小于一个预定值,则停止训练,得到基于M-Bert的恶意网站检测模型,否则,转入步骤S6;
本实施例中,所述预定值等于0.0005。
S6、进行反向传播操作,将步骤S5中得到的损失值回传到M-Bert模型的权重参数,更新这些参数以最小化损失,所述反向传播操作通过求解多元交叉熵损失函数对模型参数的梯度实现,使用步骤S2中初始化完成的AdamW优化器根据梯度更新M-Bert模型参数,再转入步骤S4。
实施例
本发明的第二种具体实施方式,一种基于M-Bert的恶意网站检测模型的检测方法,其步骤包括:
A1、在PyTorch深度学习平台中,将上述通过实施例1得到的基于M-Bert的恶意网站检测模型设置为推理模式;
A2、将待检测的网址输入步骤A1中已设置为推理模式的所述检测模型,经过检测模型的推理,得到该待检测的网址的预测结果。
模型评估:
为了对本发明的基于M-Bert的恶意网站检测模型准确性进行评估,将测试数据集输入训练完成的检测模型,具体方法为:
在PyTorch深度学习平台中,将训练完成的基于M-Bert的恶意网站检测模型设置为推理模式,再将测试数据集中待检测的网址输入已设置为推理模式的检测模型,经过检测模型的推理,得到该网址的预测结果,分析预测结果,检查M-Bert模型是否将待检测的网址分类为恶意网址或其他类别,并与测试数据集网址的实际标签比较,评估检测模型准确性。
同时,对其他一些常用的模型,如Bert、gpt2等模型进行了评估比较,评估结果如下表所示:
训练评估结果表:
可以看出,使用本发明的基于M-Bert的恶意网站检测模型,其准确率高达94.42%,比其他模型准确率明显提升。
本发明的上述实施例仅仅是为说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化和变动。这里无法对所有的实施方式予以穷举。凡是属于本发明的技术方案所引申出的显而易见的变化或变动仍处于本发明的保护范围之列。
- 一种欺诈检测模型训练方法和装置及欺诈检测方法和装置
- 一种恶意软件检测模型训练、恶意软件检测方法及装置
- 恶意网页检测模型训练方法、恶意网页检测方法及系统