分类方法、装置、终端及存储介质
文献发布时间:2024-04-18 19:58:53
技术领域
本申请涉及计算机技术领域,具体而言,涉及一种分类方法、装置、终端及存储介质。
背景技术
车辆设置的终端具有语音采集功能,通过终端采集不同车主的语音,并识别不同车主的语音,可获取到不同车主的诉求、性格等特质,以实现不同车主的分类。
目前,针对不同车主的分类,主要通过终端获取不同车主的语音,直接对不同车主的语音进行相似度计算,进而通过计算得到的相似度对不同车主进行分类。
但是,采用上述方法对不同车主进行分类,会出现相似度高,但是分类不准确的问题。
发明内容
本申请的主要目的在于提供一种分类方法、装置、终端及存储介质,以解决相关技术中对不同车主进行分类,会出现相似度高,但是分类不准确的的问题。
为了实现上述目的,第一方面,本申请提供了一种分类方法,包括:
获取不同车主的语音文本;
计算不同车主的语音文本的情感得分、文本相似度以及权重;
基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,以基于不同车主间的情感相似度确定不同车主的类型。
在一种可能的实现方式中,不同车主至少包括第一车主和第二车主,不同车主的语音文本至少包括第一车主的第一语音文本和第二车主的第二语音文本;
计算不同车主的语音文本的情感得分、文本相似度以及权重,包括:
分别对第一语音文本和第二语音文本进行预处理,得到第一语音文本对应的第一词向量和第二语音文本对应的第二词向量;
采用细粒度情感词典分别计算第一词向量对应的第一情感得分以及第二词向量对应的第二情感得分;
计算第一语音文本和第二语音文本的相似度,得到文本相似度;
基于第一情感得分、第二情感得分和文本相似度,计算第一车主对应的第一权重和第二车主对应的第二权重。
在一种可能的实现方式中,分别对第一语音文本和第二语音文本进行预处理,得到第一语音文本对应的第一词向量和第二语音文本对应的第二词向量,包括:
分别对第一语音文本和第二语音文本进行分词处理,得到分词后的第一语音文本和分词后的第二语音文本;
采用TF-IDF算法分别对分词后的第一语音文本和分词后的第二语音文本进行向量化处理,得到第一词向量和第二词向量。
在一种可能的实现方式中,采用细粒度情感词典分别计算第一词向量对应的第一情感得分以及第二词向量对应的第二情感得分,包括:
分别将第一词向量和第二词向量中的每个词向量与细粒度情感词典中预设的词向量进行比对,确定第一词向量中的每个词向量的情感分值以及第二词向量中的每个词向量的情感分值;
基于第一词向量中的每个词向量的情感分值,计算第一情感得分,以及基于第二词向量中的每个词向量的情感分值,计算第二情感得分。
在一种可能的实现方式中,基于第一情感得分、第二情感得分和文本相似度,计算第一车主对应的第一权重和第二车主对应的第二权重,包括:
对第一情感得分、第二情感得分和文本相似度进行归一化处理,得到归一化后的第一情感得分、归一化后的第二情感得分和归一化后的文本相似度;
基于归一化后的第一情感得分和归一化后的文本相似度计算第一信息熵,以及基于归一化后的第二情感得分和归一化后的文本相似度计算第二信息熵;
基于第一信息熵和第一语音文本的文本编码,计算第一权重,以及基于第二信息熵和第二语音文本的文本编码,计算第二权重。
在一种可能的实现方式中,不同车主间的情感相似度至少包括第一车主和第二车主的情感相似度;
基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,包括:
基于第一权重、第二权重、第一情感得分、第二情感得分和文本相似度,计算第一车主和第二车主的情感相似度。
在一种可能的实现方式中,第一车主和第二车主的情感相似度的计算公式为:
score=wi*EscoreA*EscoreB+wj*similarity(A,B)
其中,score表示第一车主和第二车主的情感相似度,wi表示第一权重,wj表示第二权重,EscoreA表示第一情感得分,EscoreB表示第二情感得分,similarity(A,B)表示文本相似度。
第二方面,本发明实施例提供了一种分类装置,包括:
获取模块,用于获取不同车主的语音文本;
计算模块,用于计算不同车主的语音文本的情感得分、文本相似度以及权重;
分类模块,用于基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,以基于不同车主间的情感相似度确定不同车主的类型。
第三方面,本发明实施例提供了一种终端,包括存储器、处理器以及存储在存储器中并可在处理器上运行的计算机程序,处理器执行计算机程序时实现如上任一种分类方法的步骤。
第四方面,本发明实施例提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现如上任一种分类方法的步骤。
本发明实施例提供了一种分类方法、装置、终端及存储介质,包括:先获取不同车主的语音文本,然后计算不同车主的语音文本的情感得分、文本相似度以及权重,再基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,以基于不同车主间的情感相似度确定不同车主的类型。本发明通过将相似度计算与情感相结合,计算不同车主的情感相似度,以提升不同车主的分类准确度。
附图说明
构成本申请的一部分的附图用来提供对本申请的进一步理解,使得本申请的其它特征、目的和优点变得更明显。本申请的示意性实施例附图及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1是本发明实施例提供的一种分类方法的实现流程图;
图2是本发明实施例提供的一种分类装置的结构示意图;
图3是本发明实施例提供的终端的示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。
应当理解,在本发明的各种实施例中,各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。
应当理解,在本发明中,“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
应当理解,在本发明中,“多个”是指两个或两个以上。“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。“包含A、B和C”、“包含A、B、C”是指A、B、C三者都包含,“包含A、B或C”是指包含A、B、C三者之一,“包含A、B和/或C”是指包含A、B、C三者中任1个或任2个或3个。
应当理解,在本发明中,“与A对应的B”、“与A相对应的B”、“A与B相对应”或者“B与A相对应”,表示B与A相关联,根据A可以确定B。根据A确定B并不意味着仅仅根据A确定B,还可以根据A和/或其他信息确定B。A与B的匹配,是A与B的相似度大于或等于预设的阈值。
取决于语境,如在此所使用的“若”可以被解释成为“在……时”或“当……时”或“响应于确定”或“响应于检测”。
下面以具体地实施例对本发明的技术方案进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图通过具体实施例来进行说明。
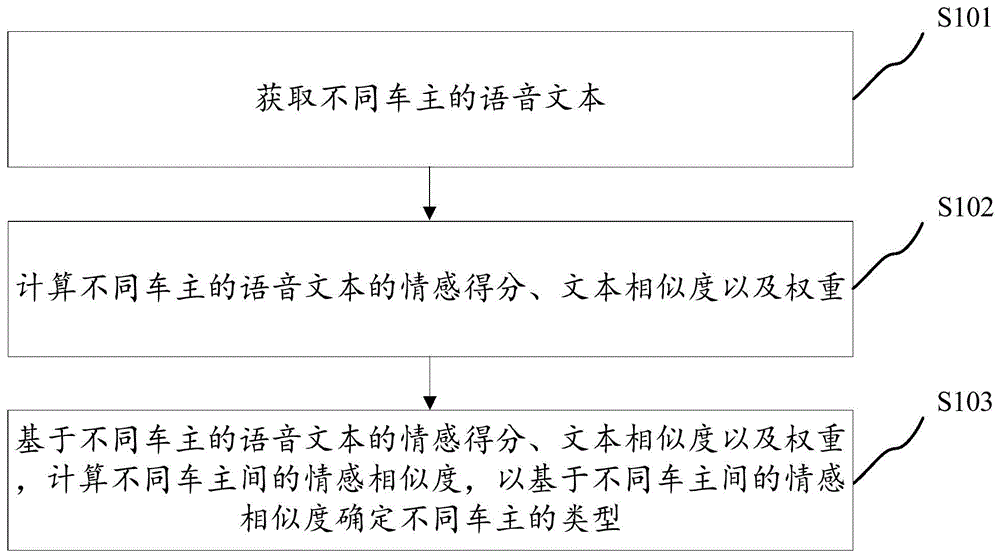
在一个实施例中,如图1所示,提供了一种分类方法,包括以下步骤:
步骤S101:获取不同车主的语音文本。
车主驾驶的车辆均设置有语音采集功能的设备,通过采集不同车主的语音,可直接获取到不同车主的语音文本。其中,设备包括但不限设置于车辆上的麦克风、手机或者采集器等。
步骤S102:计算不同车主的语音文本的情感得分、文本相似度以及权重。
其中,不同车主的数量不限,可根据具体情况设定,如2个、3个、10等。
在不同车主至少包括第一车主和第二车主,不同车主的语音文本至少包括第一车主的第一语音文本和第二车主的第二语音文本的情况下,计算不同车主的语音文本的情感得分、文本相似度以及权重,需要分别对第一语音文本和第二语音文本进行预处理,得到第一语音文本对应的第一词向量和第二语音文本对应的第二词向量,然后采用细粒度情感词典分别计算第一词向量对应的第一情感得分以及第二词向量对应的第二情感得分,再计算第一语音文本和第二语音文本的相似度,得到文本相似度,最后基于第一情感得分、第二情感得分和文本相似度,计算第一车主对应的第一权重和第二车主对应的第二权重。
其中,分别对第一语音文本和第二语音文本进行预处理,得到第一语音文本对应的第一词向量和第二语音文本对应的第二词向量,需要分别对第一语音文本和第二语音文本进行分词处理,得到分词后的第一语音文本和分词后的第二语音文本,然后采用TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)算法分别对分词后的第一语音文本和分词后的第二语音文本进行向量化处理,得到第一词向量和第二词向量。
例如,在有两个车主的情况下,第一个车主的第一语音文本为“这个导航太好用了”,第二个车主的第二语音文本为“这个导航太不好用了”。分别对第一语音文本为“这个导航太好用了”和第二语音文本为“这个导航太不好用了”进行分词处理,则分词后的第一语音文本为“这、个、导、航、太、好、用、了”,而第二语音文本为“这、个、导、航、太、不、好、用、了”。
然后对第一语音文本为“这、个、导、航、太、好、用、了”,而第二语音文本为“这、个、导、航、太、不、好、用、了”进行向量化处理,得到第一词向量和第二词向量。其中,向量化处理的方式不作具体限定。
当获取到第一次向量和第二词向量后,需要采用细粒度情感词典分别计算第一词向量对应的第一情感得分以及第二词向量对应的第二情感得分,具体的,需要分别将第一词向量和第二词向量中的每个词向量与细粒度情感词典中预设的词向量进行比对,确定第一词向量中的每个词向量的情感分值以及第二词向量中的每个词向量的情感分值,然后基于第一词向量中的每个词向量的情感分值,计算第一情感得分,以及基于第二词向量中的每个词向量的情感分值,计算第二情感得分。
其中,细粒度情感词典中有预设的词向量,预设的词向量可以是不同情感对应的分值,如将所有情感分为六类,包括正向、负向、中性、喜爱、厌恶、愤怒,且每一类具有自己的分值,即正向、负向、中性、喜爱、厌恶、愤怒分别对应的分值为1,-1,0,2,-2,-3。
将第一词向量和第二词向量中的每个词向量与上述情感类型对应的分值进行一一比对匹配,则可以获取到第一词向量中的每个词向量的情感分值以及第二词向量中的每个词向量的情感分值。
然后将第一词向量中的每个词向量的情感分值进行和计算,得到第一情感得分,以将第二词向量中的每个词向量的情感分值进行和计算,得到第二情感得分。
同时,还需要计算第一语音文本和第二语音文本间的文本相似度,则计算公式为:
其中,similarity(A,B)代表第一语音文本和第二语音文本间的文本相似度,A代表第一语音文本,B代表第二语音文本。
当计算得到第一情感得分、第二情感得分和文本相似度后,需要基于第一情感得分、第二情感得分和文本相似度,计算第一车主对应的第一权重和第二车主对应的第二权重,具体的,先对第一情感得分、第二情感得分和文本相似度进行归一化处理,得到归一化后的第一情感得分、归一化后的第二情感得分和归一化后的文本相似度,然后基于归一化后的第一情感得分和归一化后的文本相似度计算第一信息熵,以及基于归一化后的第二情感得分和归一化后的文本相似度计算第二信息熵,再基于第一信息熵和第一语音文本的文本编码,计算第一权重,以及基于第二信息熵和第二语音文本的文本编码,计算第二权重。
其中,归一化处理包括但不限于极差法等处理方式。
对第一情感得分EscoreA、第二情感得分EscoreB和文本相似度similarity(A,B)进行归一化处理后,可采用熵权法对归一化后的第一情感得分和归一化后的文本相似度进行计算得到第一信息熵E
然后可根据第一信息熵E
其中,i=1,2,...,n。
以及根据第一信息熵E
其中,j=1,2,...,n。
步骤S103:基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,以基于不同车主间的情感相似度确定不同车主的类型。
在不同车主间的情感相似度至少包括第一车主和第二车主的情感相似度的情况下,基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,需先基于第一权重、第二权重、第一情感得分、第二情感得分和文本相似度,计算第一车主和第二车主的情感相似度。
具体的,第一车主和第二车主的情感相似度的计算公式为:
score=wi*EscoreA*EscoreB+wj*similarity(A,B)
其中,score表示第一车主和第二车主的情感相似度,wi表示第一权重,wj表示第二权重,EscoreA表示第一情感得分,EscoreB表示第二情感得分,similarity(A,B)表示文本相似度。
本发明实施例提供了一种分类方法,包括:先获取不同车主的语音文本,然后计算不同车主的语音文本的情感得分、文本相似度以及权重,再基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,以基于不同车主间的情感相似度确定不同车主的类型。本发明通过将相似度计算与情感相结合,计算不同车主的情感相似度,以提升不同车主的分类准确度。
应理解,上述实施例中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。
以下为本发明的装置实施例,对于其中未详尽描述的细节,可以参考上述对应的方法实施例。
图2示出了本发明实施例提供的一种分类装置的结构示意图,为了便于说明,仅示出了与本发明实施例相关的部分,一种分类装置包括获取模块201、计算模块202和分类模块203,具体如下:
获取模块201,用于获取不同车主的语音文本;
计算模块202,用于计算不同车主的语音文本的情感得分、文本相似度以及权重;
分类模块203,用于基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,以基于不同车主间的情感相似度确定不同车主的类型。
在一种可能的实现方式中,不同车主至少包括第一车主和第二车主,不同车主的语音文本至少包括第一车主的第一语音文本和第二车主的第二语音文本;
计算模块202还用于分别对第一语音文本和第二语音文本进行预处理,得到第一语音文本对应的第一词向量和第二语音文本对应的第二词向量;
采用细粒度情感词典分别计算第一词向量对应的第一情感得分以及第二词向量对应的第二情感得分;
计算第一语音文本和第二语音文本的相似度,得到文本相似度;
基于第一情感得分、第二情感得分和文本相似度,计算第一车主对应的第一权重和第二车主对应的第二权重。
在一种可能的实现方式中,计算模块202还用于分别对第一语音文本和第二语音文本进行分词处理,得到分词后的第一语音文本和分词后的第二语音文本;
采用TF-IDF算法分别对分词后的第一语音文本和分词后的第二语音文本进行向量化处理,得到第一词向量和第二词向量。
在一种可能的实现方式中,计算模块202还用于分别将第一词向量和第二词向量中的每个词向量与细粒度情感词典中预设的词向量进行比对,确定第一词向量中的每个词向量的情感分值以及第二词向量中的每个词向量的情感分值;
基于第一词向量中的每个词向量的情感分值,计算第一情感得分,以及基于第二词向量中的每个词向量的情感分值,计算第二情感得分。
在一种可能的实现方式中,计算模块202还用于对第一情感得分、第二情感得分和文本相似度进行归一化处理,得到归一化后的第一情感得分、归一化后的第二情感得分和归一化后的文本相似度;
基于归一化后的第一情感得分和归一化后的文本相似度计算第一信息熵,以及基于归一化后的第二情感得分和归一化后的文本相似度计算第二信息熵;
基于第一信息熵和第一语音文本的文本编码,计算第一权重,以及基于第二信息熵和第二语音文本的文本编码,计算第二权重。
在一种可能的实现方式中,不同车主间的情感相似度至少包括第一车主和第二车主的情感相似度;
分类模块203还用于基于第一权重、第二权重、第一情感得分、第二情感得分和文本相似度,计算第一车主和第二车主的情感相似度。
在一种可能的实现方式中,第一车主和第二车主的情感相似度的计算公式为:
score=wi*EscoreA*EscoreB+wj*similarity(A,B)
其中,score表示第一车主和第二车主的情感相似度,wi表示第一权重,wj表示第二权重,EscoreA表示第一情感得分,EscoreB表示第二情感得分,similarity(A,B)表示文本相似度。
本发明实施例提供了一种分类装置,可具体用于先获取不同车主的语音文本,然后计算不同车主的语音文本的情感得分、文本相似度以及权重,再基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,以基于不同车主间的情感相似度确定不同车主的类型。本发明通过将相似度计算与情感相结合,计算不同车主的情感相似度,以提升不同车主的分类准确度。
图3是本发明实施例提供的终端的示意图。如图3所示,该实施例的终端3包括:处理器301、存储器302以及存储在存储器302中并可在处理器301上运行的计算机程序303。处理器301执行计算机程序303时实现上述各个分类方法实施例中的步骤,例如图1所示的步骤101-步骤103。或者,处理器301执行计算机程序303时实现上述各个分类装置实施例中各模块/单元的功能,例如图2所示模块/单元201-203的功能。
本发明还提供一种可读存储介质,可读存储介质中存储有计算机程序,计算机程序被处理器执行时用于实现上述的各种实施方式提供的一种分类方法,包括:
获取不同车主的语音文本;
计算不同车主的语音文本的情感得分、文本相似度以及权重;
基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,以基于不同车主间的情感相似度确定不同车主的类型。
在一种可能的实现方式中,不同车主至少包括第一车主和第二车主,不同车主的语音文本至少包括第一车主的第一语音文本和第二车主的第二语音文本;
计算不同车主的语音文本的情感得分、文本相似度以及权重,包括:
分别对第一语音文本和第二语音文本进行预处理,得到第一语音文本对应的第一词向量和第二语音文本对应的第二词向量;
采用细粒度情感词典分别计算第一词向量对应的第一情感得分以及第二词向量对应的第二情感得分;
计算第一语音文本和第二语音文本的相似度,得到文本相似度;
基于第一情感得分、第二情感得分和文本相似度,计算第一车主对应的第一权重和第二车主对应的第二权重。
在一种可能的实现方式中,分别对第一语音文本和第二语音文本进行预处理,得到第一语音文本对应的第一词向量和第二语音文本对应的第二词向量,包括:
分别对第一语音文本和第二语音文本进行分词处理,得到分词后的第一语音文本和分词后的第二语音文本;
采用TF-IDF算法分别对分词后的第一语音文本和分词后的第二语音文本进行向量化处理,得到第一词向量和第二词向量。
在一种可能的实现方式中,采用细粒度情感词典分别计算第一词向量对应的第一情感得分以及第二词向量对应的第二情感得分,包括:
分别将第一词向量和第二词向量中的每个词向量与细粒度情感词典中预设的词向量进行比对,确定第一词向量中的每个词向量的情感分值以及第二词向量中的每个词向量的情感分值;
基于第一词向量中的每个词向量的情感分值,计算第一情感得分,以及基于第二词向量中的每个词向量的情感分值,计算第二情感得分。
在一种可能的实现方式中,基于第一情感得分、第二情感得分和文本相似度,计算第一车主对应的第一权重和第二车主对应的第二权重,包括:
对第一情感得分、第二情感得分和文本相似度进行归一化处理,得到归一化后的第一情感得分、归一化后的第二情感得分和归一化后的文本相似度;
基于归一化后的第一情感得分和归一化后的文本相似度计算第一信息熵,以及基于归一化后的第二情感得分和归一化后的文本相似度计算第二信息熵;
基于第一信息熵和第一语音文本的文本编码,计算第一权重,以及基于第二信息熵和第二语音文本的文本编码,计算第二权重。
在一种可能的实现方式中,不同车主间的情感相似度至少包括第一车主和第二车主的情感相似度;
基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,包括:
基于第一权重、第二权重、第一情感得分、第二情感得分和文本相似度,计算第一车主和第二车主的情感相似度。
在一种可能的实现方式中,第一车主和第二车主的情感相似度的计算公式为:
score=wi*EscoreA*EscoreB+wj*similarity(A,B)
其中,score表示第一车主和第二车主的情感相似度,wi表示第一权重,wj表示第二权重,EscoreA表示第一情感得分,EscoreB表示第二情感得分,similarity(A,B)表示文本相似度。
其中,可读存储介质可以是计算机存储介质,也可以是通信介质。通信介质包括便于从一个地方向另一个地方传送计算机程序的任何介质。计算机存储介质可以是通用或专用计算机能够存取的任何可用介质。例如,可读存储介质耦合至处理器,从而使处理器能够从该可读存储介质读取信息,且可向该可读存储介质写入信息。当然,可读存储介质也可以是处理器的组成部分。处理器和可读存储介质可以位于专用集成电路(ApplicationSpecific Integrated Circuits,ASIC)中。另外,该ASIC可以位于用户设备中。当然,处理器和可读存储介质也可以作为分立组件存在于通信设备中。可读存储介质可以是只读存储器(ROM)、随机存取存储器(RAM)、CD-ROM、磁带、软盘和光数据存储设备等。
本发明还提供一种程序产品,该程序产品包括执行指令,该执行指令存储在可读存储介质中。设备的至少一个处理器可以从可读存储介质读取该执行指令,至少一个处理器执行该执行指令使得设备实施上述的各种实施方式提供的一种分类方法,包括:
获取不同车主的语音文本;
计算不同车主的语音文本的情感得分、文本相似度以及权重;
基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,以基于不同车主间的情感相似度确定不同车主的类型。
在一种可能的实现方式中,不同车主至少包括第一车主和第二车主,不同车主的语音文本至少包括第一车主的第一语音文本和第二车主的第二语音文本;
计算不同车主的语音文本的情感得分、文本相似度以及权重,包括:
分别对第一语音文本和第二语音文本进行预处理,得到第一语音文本对应的第一词向量和第二语音文本对应的第二词向量;
采用细粒度情感词典分别计算第一词向量对应的第一情感得分以及第二词向量对应的第二情感得分;
计算第一语音文本和第二语音文本的相似度,得到文本相似度;
基于第一情感得分、第二情感得分和文本相似度,计算第一车主对应的第一权重和第二车主对应的第二权重。
在一种可能的实现方式中,分别对第一语音文本和第二语音文本进行预处理,得到第一语音文本对应的第一词向量和第二语音文本对应的第二词向量,包括:
分别对第一语音文本和第二语音文本进行分词处理,得到分词后的第一语音文本和分词后的第二语音文本;
采用TF-IDF算法分别对分词后的第一语音文本和分词后的第二语音文本进行向量化处理,得到第一词向量和第二词向量。
在一种可能的实现方式中,采用细粒度情感词典分别计算第一词向量对应的第一情感得分以及第二词向量对应的第二情感得分,包括:
分别将第一词向量和第二词向量中的每个词向量与细粒度情感词典中预设的词向量进行比对,确定第一词向量中的每个词向量的情感分值以及第二词向量中的每个词向量的情感分值;
基于第一词向量中的每个词向量的情感分值,计算第一情感得分,以及基于第二词向量中的每个词向量的情感分值,计算第二情感得分。
在一种可能的实现方式中,基于第一情感得分、第二情感得分和文本相似度,计算第一车主对应的第一权重和第二车主对应的第二权重,包括:
对第一情感得分、第二情感得分和文本相似度进行归一化处理,得到归一化后的第一情感得分、归一化后的第二情感得分和归一化后的文本相似度;
基于归一化后的第一情感得分和归一化后的文本相似度计算第一信息熵,以及基于归一化后的第二情感得分和归一化后的文本相似度计算第二信息熵;
基于第一信息熵和第一语音文本的文本编码,计算第一权重,以及基于第二信息熵和第二语音文本的文本编码,计算第二权重。
在一种可能的实现方式中,不同车主间的情感相似度至少包括第一车主和第二车主的情感相似度;
基于不同车主的语音文本的情感得分、文本相似度以及权重,计算不同车主间的情感相似度,包括:
基于第一权重、第二权重、第一情感得分、第二情感得分和文本相似度,计算第一车主和第二车主的情感相似度。
在一种可能的实现方式中,第一车主和第二车主的情感相似度的计算公式为:
score=wi*EscoreA*EscoreB+wj*similarity(A,B)
其中,score表示第一车主和第二车主的情感相似度,wi表示第一权重,wj表示第二权重,EscoreA表示第一情感得分,EscoreB表示第二情感得分,similarity(A,B)表示文本相似度。
在上述设备的实施例中,应理解,处理器可以是中央处理单元(CentralProcessing Unit,CPU),还可以是其他通用处理器、数字信号处理器(Digital SignalProcessor,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本发明所公开的方法的步骤可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及软件模块组合执行完成。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围,均应包含在本发明的保护范围之内。
- 数据分类方法、装置、终端设备和存储介质
- 一种文本分类方法、装置、终端及计算机可读存储介质
- 一种图像分类方法、装置、终端设备及可读存储介质
- 一种文本分类方法、装置、终端及存储介质
- 移动终端桌面图标布局方法、装置、终端及可读存储介质
- 目标分类方法、目标分类装置、终端设备及存储介质
- 一种终端的分类方法、分类装置及计算机可读存储介质